Dlaczego REST Roy Fieldinga wciąż ma znaczenie
Roy Fielding to nie tylko nazwisko przy buzzwordzie. Był jednym z kluczowych autorów specyfikacji HTTP i URI, a w swojej rozprawie doktorskiej opisał styl architektoniczny zwany REST (Representational State Transfer), żeby wyjaśnić, dlaczego Web działa tak dobrze.
To źródło ma znaczenie, bo REST nie powstał po to, by „ładnie wyglądały endpointy”. Był sposobem opisania ograniczeń, które pozwoliły globalnej, chaotycznej sieci skalować się: wielu klientów, wiele serwerów, pośrednicy, cache, częściowe awarie i ciągłe zmiany.
Co zyskasz, czytając ten wpis
Jeśli kiedykolwiek zastanawiałeś się, dlaczego dwa „REST API” potrafią być zupełnie różne — albo dlaczego mała decyzja projektowa zamienia się później w koszmar paginacji, zagmatwane cache’owanie lub łamiące zmiany — ten przewodnik ma zmniejszyć liczbę takich niespodzianek.
Wyniesiesz z niego:
- jaśniejsze podejmowanie decyzji przy projektowaniu i ocenie API
- lepsze słownictwo do omawiania kompromisów z zespołem
- praktyczne wyczucie, które idee REST są istotne w realnych projektach
REST w skrócie: styl, nie standard
REST nie jest checklistą, protokołem ani certyfikatem. Fielding opisał go jako styl architektoniczny: zestaw ograniczeń, które razem dają systemy skalujące się jak Web — proste w użyciu, zdolne do ewolucji i przyjazne pośrednikom (proxy, cache, bramki) bez potrzeby stałej koordynacji.
Problem, który REST rozwiązywał
Wczesny Web musiał działać przez wiele organizacji, serwerów, sieci i typów klientów. Musiał rosnąć bez centralnej kontroli, przetrwać częściowe awarie i pozwalać na pojawianie się nowych funkcji bez łamania starych. REST radzi sobie z tym, faworyzując niewielką liczbę szeroko współdzielonych koncepcji (identyfikatory, reprezentacje, standardowe operacje) zamiast niestandardowych, ściśle sprzężonych kontraktów.
„Ograniczenia architektoniczne” — prostym językiem
Ograniczenie to reguła ograniczająca swobodę projektową w zamian za korzyści. Na przykład możesz zrezygnować ze stanów sesji po stronie serwera, żeby dowolny węzeł mógł obsłużyć żądanie — co poprawia niezawodność i skalowalność. Każde ograniczenie REST robi podobny kompromis: mniej doraźnej elastyczności, więcej przewidywalności i zdolności do ewolucji.
REST kontra „REST-podobne” API
Wiele API HTTP zapożycza pomysły REST (JSON na HTTP, endpointy URL, może kody stanu), ale nie stosuje pełnego zestawu ograniczeń. To nie jest „błąd” — często wynika z terminów projektowych lub potrzeb wewnętrznych. Warto jednak nazwać różnicę: API może być zorientowane na zasoby bez bycia w pełni REST.
Model mentalny w jednym akapicie
Myśl o systemie REST jako o zasobach (rzeczach, które możesz nazwać URL-em), z którymi klienci wchodzą w interakcję przez reprezentacje (aktualny widok zasobu, jak JSON czy HTML), kierując się linkami (kolejne akcje i powiązane zasoby). Klient nie potrzebuje ukrytych reguł — podąża za standardową semantyką i linkami, tak jak przeglądarka porusza się po Webie.
Zasoby i reprezentacje: podstawowe pojęcia
Zanim zgubisz się w ograniczeniach i szczegółach HTTP, REST zaczyna się od prostego przesunięcia w myśleniu: myśl w kategoriach zasobów, nie akcji.
Zasób = rzeczownik, którą możesz zidentyfikować
Zasób to adresowalna „rzecz” w twoim systemie: użytkownik, faktura, kategoria produktu, koszyk. Ważne, że to rzeczownik z tożsamością.
Dlatego /users/123 brzmi naturalnie: identyfikuje użytkownika o ID 123. W porównaniu do URL-i w formie akcji, jak /getUser czy /updateUserPassword, które opisują czasowniki — operacje, a nie rzecz, na której operujesz.
REST nie mówi, że nie możesz wykonywać akcji. Mówi, że akcje powinny być wyrażone przez uniform interface (dla API HTTP zwykle metody GET/POST/PUT/PATCH/DELETE) działające na identyfikatorach zasobów.
Reprezentacja = widok zasobu
Reprezentacja to to, co wysyłasz po sieci jako migawkę lub widok zasobu w danym momencie. Ten sam zasób może mieć wiele reprezentacji.
Na przykład zasób /users/123 może być reprezentowany jako JSON dla aplikacji lub HTML dla przeglądarki.
GET /users/123
Accept: application/json
Może zwrócić:
{
"id": 123,
"name": "Asha",
"email": "[email protected]"
}
Podczas gdy:
GET /users/123
Accept: text/html
Może zwrócić stronę HTML renderującą te same dane użytkownika.
Kluczowa idea: zasób to nie jest JSON i nie jest to HTML. To tylko formaty używane do jego reprezentacji.
Dlaczego to zmienia projekt API
Gdy modelujesz API wokół zasobów i reprezentacji, kilka praktycznych decyzji staje się łatwiejszych:
- Nazewnictwo zostaje stabilne.
/users/123 pozostaje ważne nawet jeśli UI, workflowy czy model danych ewoluują.
- Endpointy są prostsze. Zamiast wymyślać nowy URL dla każdej operacji, używasz URL-i zasobów i zmieniasz metodę lub reprezentację.
- Kod klienta jest mniej sprzężony. Klienci skupiają się na „pobierz użytkownika” lub „zaktualizuj pola użytkownika”, zamiast pamiętać katalog endpointów akcji.
To podejście „najpierw zasoby” jest podstawą, na której opierają się ograniczenia REST. Bez niego „REST” często sprowadza się do „JSON przez HTTP z ładnymi wzorcami URL”.
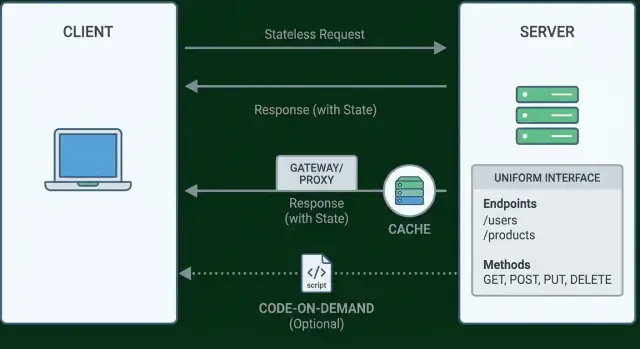
Ograniczenie 1: separacja klient–serwer
Separacja klient–serwer to sposób REST na wymuszenie czystego podziału obowiązków. Klient skupia się na doświadczeniu użytkownika (co ludzie widzą i robią), serwer na danych, regułach i trwałości (co jest prawdą i co jest dozwolone). Gdy utrzymujesz te obawy oddzielnie, każda strona może się zmieniać bez przymuszania do przepisania drugiej.
Co należy do klienta, a co do serwera?
W codziennym rozumieniu klient to „warstwa prezentacji”: ekrany, nawigacja, lokalna walidacja dla szybkiego feedbacku i optymistyczne zachowanie UI (np. natychmiastowe pokazanie nowego komentarza). Serwer to „źródło prawdy”: uwierzytelnianie, autoryzacja, reguły biznesowe, przechowywanie, audyt i wszystko, co musi być spójne między urządzeniami.
Praktyczna zasada: jeśli decyzja wpływa na bezpieczeństwo, pieniądze, uprawnienia lub spójność współdzielonych danych — powinna być po stronie serwera. Jeśli dotyczy tylko wyglądu doświadczenia (układ, podpowiedzi wejściowe, stany ładowania) — po stronie klienta.
Dlaczego to pasuje do współczesnych aplikacji
To ograniczenie mapuje się bezpośrednio na popularne zestawy:
- SPA + API: aplikacja webowa (React/Vue itp.) iteruje nad UI, podczas gdy API ciągle serwuje zasoby.
- Aplikacje mobilne: klienci iOS i Android mogą współdzielić te same reguły i endpointy serwera.
- Integracje zewnętrzne: partnerzy konsumują te same możliwości serwera bez potrzeby twojego UI.
Separacja klient–serwer sprawia, że „jeden backend, wiele frontendów” jest realistyczne.
Typowa pułapka: wyciek stanu UI do sesji serwera
Częstym błędem jest przechowywanie stanu przepływu UI po stronie serwera (np. „na którym kroku checkoutu jest użytkownik”) w sesji serwerowej. To sprzęża backend z konkretnym flow ekranu i utrudnia skalowanie.
Lepsze jest przesyłanie niezbędnego kontekstu z każdym żądaniem (albo wyprowadzenie go z zasobów), tak aby serwer skupiał się na zasobach i regułach — a nie na zapamiętywaniu, jak konkretny UI postępuje.
Ograniczenie 2: bezstanowe interakcje
Bezstanowość oznacza, że serwer nie musi pamiętać nic o kliencie między żądaniami. Każde żądanie zawiera wszystkie informacje potrzebne do jego zrozumienia i poprawnego przetworzenia — kto wywołuje, czego chce i jaki jest kontekst.
Dlaczego to ma znaczenie
Gdy żądania są niezależne, możesz dodawać lub usuwać serwery za load balancerem bez martwienia się, „który serwer zna moją sesję”. To poprawia skalowalność i odporność: dowolna instancja może obsłużyć żądanie.
Ułatwia to też operacje. Debugowanie jest często prostsze, bo pełen kontekst widoczny jest w żądaniu (i logach), zamiast być ukrytym w pamięci serwera.
Kompromisy, które odczujesz w praktyce
Bezstanowe API zwykle wysyłają trochę więcej danych przy każdym wywołaniu. Zamiast polegać na zapisanej sesji serwerowej, klient dołącza za każdym razem poświadczenia i kontekst.
Trzeba też jawnie obsługiwać „stanowe” przepływy użytkownika (paginacja, wieloetapowe checkouty). REST nie zabrania doświadczeń wieloetapowych — po prostu przenosi stan na klienta lub na zasoby serwera, które są identyfikowalne i dostępne.
Praktyczne wzorce (i co rozwiązują)
- Tokeny auth (np. Bearer JWT): Każde żądanie zawiera nagłówek
Authorization: Bearer …, dzięki czemu dowolny serwer może je uwierzytelnić.
- Klucze idempotencyjne: Dla operacji typu „create payment” klient wysyła
Idempotency-Key, żeby ponowienia nie tworzyły duplikatów.
- Correlation ID: Nagłówek typu
X-Correlation-Id pozwala śledzić jedną akcję użytkownika przez usługi i logi.
Dla paginacji unikaj „serwer pamięta stronę 3”. Wol preferować parametry ?cursor=abc lub link next, aby stan nawigacji był w odpowiedziach, a nie w pamięci serwera.
Ograniczenie 3: cache’owalne odpowiedzi
Go with PostgreSQL backend
Spin up a Go API with a PostgreSQL schema from a plain English spec.
Cache’owanie polega na ponownym użyciu wcześniejszej odpowiedzi bez konieczności pytania serwera o tę samą pracę. Dobrze wykonane, zmniejsza opóźnienia dla użytkowników i obciążenie twoich serwerów — bez zmieniania znaczenia API.
Co znaczy „cache’owalny” w praktyce
Odpowiedź jest cache’owalna, gdy bezpiecznie można ją ponownie zwrócić innemu żądaniu przez pewien czas. W HTTP komunikujesz to nagłówkami cache:
Cache-Control: główny przełącznik (jak długo trzymać, czy może przechowywać cache współdzielony itd.)ETag i Last-Modified: walidatory pozwalające klientom zapytać „czy się zmieniło?” i otrzymać tanią odpowiedź „not modified”Expires: starszy sposób wyrażania świeżości, wciąż spotykany
To jest większe niż „cache przeglądarki”. Proxies, CDN-y, bramki API, a nawet aplikacje mobilne mogą ponownie użyć odpowiedzi, gdy zasady są jasne.
Co zwykle bezpiecznie cache’ować (a czego nie)
Dobre kandydaty:
- Publiczne, identyczne dla wszystkich dane (katalog produktów, dokumentacja, flagi funkcji, które nie są specyficzne dla użytkownika)
- Zasoby tylko do odczytu, które rzadko się zmieniają (statyczna konfiguracja, dane referencyjne)
- GET-owe odpowiedzi, które nie zależą od cookies ani autoryzacji
Zwykle złe kandydaty:
- Dane osobiste powiązane z kontem (profile, zamówienia, wiadomości)
- Odpowiedzi związane z auth (wymiana tokenów, stan sesji)
- Cokolwiek, co różni się per użytkownik, chyba że obsłużysz to eksplicitnie (np.
private)
Praktyczne skutki, które zauważysz
- Szybsze strony i responsywniejsze aplikacje (mniej czekania na sieć)
- Niższe koszty serwera i bazy danych (mniej powtarzanych obliczeń)
- Mniej incydentów z limitami (cache zmniejsza liczbę żądań)
Kluczowa idea: cache’owanie to nie dodatek. To ograniczenie REST, które nagradza API, które jasno komunikują świeżość i walidację.
Uniform interface bywa błędnie rozumiane jako „używaj GET do czytania i POST do tworzenia”. To tylko mały fragment. Pomysł Fieldinga jest szerszy: API powinno być na tyle spójne, żeby klienci nie potrzebowali specjalnej wiedzy dla każdego endpointu.
-
Identyfikacja zasobów: Nazwywaj rzeczy stabilnymi identyfikatorami (zwykle URL), nie akcjami. Myśl /orders/123, nie /createOrder.
-
Manipulacja przez reprezentacje: Klienci zmieniają zasób, wysyłając reprezentację (JSON, HTML itd.). Serwer kontroluje zasób; klient wymienia reprezentacje.
-
Samodeskryptywne komunikaty: Każde żądanie/odpowiedź powinno zawierać wystarczającą informację, by zrozumieć, jak je przetworzyć — metodę, kod statusu, nagłówki, typ mediów i ciało. Jeśli znaczenie jest ukryte w dokumentacji poza wiadomością, klienci stają się silnie sprzężeni.
-
Hypermedia (HATEOAS): Odpowiedzi powinny zawierać linki i dozwolone akcje, aby klient mógł podążać za workflow bez hardcodowania każdego wzoru URL.
Dlaczego to redukuje sprzężenie
Spójny interfejs sprawia, że klienci są mniej zależni od szczegółów po stronie serwera. Z czasem oznacza to mniej breaking changes, mniej „specjalnych przypadków” i mniej przepisanego kodu przy ewolucji endpointów.
Praktyczne heurystyki do zastosowania
- Używaj kodów stanu konsekwentnie: np.
200 dla udanych odczytów, 201 dla stworzenia zasobu (z Location), 400 dla walidacji, 401/403 dla auth, 404 gdy zasób nie istnieje.
- Standaryzuj format błędów w całym API. Przykładowe pola:
code, message, details, requestId.
- Nadaj znaczenie mediom i nagłówkom (
Content-Type, nagłówki cache), żeby komunikaty się tłumaczyły same.
Uniform interface to ostatecznie przewidywalność i zdolność do ewolucji, nie tylko „poprawne czasowniki”.
Samodeskryptywne komunikaty: projektowanie pod zrozumienie
Caching done right
Add Cache-Control and ETag handling to GET responses without manual boilerplate.
„Samodeskryptywna” wiadomość to taka, która mówi odbiorcy, jak ją zinterpretować — bez potrzeby wiedzy poza samą wiadomością. Jeśli klient (lub pośrednik) nie potrafi zrozumieć, co odpowiedź znaczy, patrząc tylko na nagłówki HTTP i ciało, stworzyłeś prywatny protokół osadzony na HTTP.
Używaj typów mediów, by wyjaśnić ładunek
Najprostsze ulepszenie to jawne Content-Type (co wysyłasz) i często Accept (co chcesz otrzymać). Odpowiedź z Content-Type: application/json mówi klientowi podstawowe zasady parsowania, ale można iść dalej poprzez vendorowe lub profilowe typy mediów, gdy znaczenie jest istotne.
Przykłady podejść:
- Generic media type + stabilne pola:
application/json ze starannie utrzymanym schematem. Najprostsze dla większości zespołów.
- Vendor media types:
application/vnd.acme.invoice+json by zaznaczyć konkretną reprezentację.
- Profile: zachowaj
application/json, dodaj parametr profile lub link do profilu definiującego semantykę.
Wersjonowanie i kompatybilność (bez łamania klientów)
Wersjonowanie powinno chronić istniejących klientów. Popularne opcje:
- Wersjonowanie w URL (
/v1/orders): widoczne, ale może zachęcać do rozgałęziania reprezentacji zamiast ich ewolucji.
- Wersjonowanie przez nagłówki lub typ mediów (przez
Accept): utrzymuje URL stabilnym i umieszcza „co to znaczy” w wiadomości.
- Ewolucja addytywna: preferuj dodawanie pól i zostawianie starych działających; deprecjonuj stopniowo.
Cokolwiek wybierzesz, dąż do wstecznej kompatybilności domyślnie: nie zmieniaj nazw pól lekkomyślnie, nie zmieniaj znaczeń w sposób ukryty i traktuj usunięcia jako zmiany łamiące.
Spójne błędy i jasne nazwy
Klienci uczą się szybciej, gdy błędy wyglądają tak samo wszędzie. Wybierz jedną strukturę błędu (np. code, message, details, traceId) i używaj jej w całym API. Używaj czytelnych, przewidywalnych nazw pól (createdAt vs. created_at) i trzymaj się jednej konwencji.
Dokumentacja pomaga — ale jasność musi żyć w wiadomości
Dobra dokumentacja przyspiesza adopcję, ale nie może być jedynym miejscem, gdzie istnieje znaczenie. Jeśli klient musi czytać wiki, żeby wiedzieć, czy status: 2 znaczy „opłacone” czy „oczekujące”, to komunikat nie jest samodeskryptywny. Dobrze zaprojektowane nagłówki, typy mediów i czytelne ładunki zmniejszają tę zależność i ułatwiają ewolucję systemów.
Hypermedia (w skrócie HATEOAS: Hypermedia As The Engine Of Application State) oznacza, że klient nie musi „znać” następnych URL-i z góry. Zamiast tego każda odpowiedź zawiera odkrywalne kolejne kroki jako linki: dokąd iść dalej, jakie akcje są możliwe i czasem jaką metodę HTTP użyć.
Jak to wygląda w praktyce
Zamiast hardcodować ścieżki typu /orders/{id}/cancel, klient podąża za linkami dostarczonymi przez serwer. Serwer mówi w ten sposób: „Biorąc pod uwagę bieżący stan tego zasobu, oto dozwolone ruchy”.
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
Jeśli zamówienie później stanie się paid, serwer może przestać dołączać cancel i dodać refund — bez łamania poprawnie zachowującego się klienta.
Hypermedia sprawdza się, gdy przepływy ewoluują: kroki onboardingowe, checkout, zatwierdzenia, subskrypcje lub każdy proces, gdzie „co jest dozwolone dalej” zmienia się w zależności od stanu, uprawnień lub reguł biznesowych.
Redukuje też hardcodowane URL-e i kruche założenia klienta. Możesz reorganizować trasy, wprowadzać nowe akcje lub wycofywać stare, zachowując funkcjonalność klientów, jeśli tylko utrzymasz znaczenie relacji linków.
Dlaczego zespoły to pomijają (i co przez to tracą)
Zespoły często pomijają HATEOAS, bo wydaje się to dodatkową pracą: definiowanie formatu linków, ustalanie nazw relacji i nauka deweloperów klienckich, by podążali za linkami zamiast konstruować URL-e.
Co tracisz, to kluczowa korzyść REST: luźne sprzężenie. Bez hypermedia wiele API staje się „RPC przez HTTP” — używa HTTP, ale klienci zależą od dokumentacji i stałych szablonów URL.
Ograniczenie 5: system warstwowy
System warstwowy oznacza, że klient nie musi wiedzieć (i często nie może stwierdzić), czy rozmawia z „prawdziwym” serwerem origin, czy z pośrednikami po drodze. Warstwy mogą obejmować API gateway, reverse proxy, CDN, usługi auth, WAF, service mesh, a nawet wewnętrzne routingi między mikroserwisami.
Dlaczego warstwy są użyteczne
Warstwy tworzą czyste granice. Zespoły bezpieczeństwa mogą wymusić TLS, limity zapytań, uwierzytelnianie i walidację po stronie edge bez zmiany każdego backendu. Zespoły operacyjne mogą skalować horyzontalnie za gatewayem, dodać caching w CDN lub przerzucać ruch w czasie incydentów. Dla klientów to upraszcza sprawę: jeden stabilny punkt API, spójne nagłówki i przewidywalne formaty błędów.
Kompromisy odczuwalne w praktyce
Pośrednicy mogą wprowadzać ukryte opóźnienia (dodatkowe skoki, dodatkowe handshake) i utrudniać debugowanie: błąd może leżeć w regułach gateway, cache CDN, lub w kodzie origin. Cache także może mylić, jeśli różne warstwy cache’ują inaczej lub bramka przepisuje nagłówki wpływające na klucze cache.
Praktyczne wskazówki, aby warstwy nie szkodziły
- Używaj trace ID end-to-end: przyjmuj lub generuj request ID i propaguj je przez każdy hop; dołączaj je do odpowiedzi i logów.
- Jasno propaguj błędy: standaryzuj ciała błędów i mapuj awarie upstream jasno (nie zamieniaj wszystkiego w ogólny 500).
- Ustal timeouty per hop: timeouty gateway, upstream i klienta powinny być zgrane, aby uniknąć „tajemniczych” rozłączeń.
- Dokumentuj zachowanie cache: jasno wskaż, które odpowiedzi są cache’owalne i które nagłówki pośrednicy muszą zachować.
Warstwy są potęgą — jeśli system pozostaje obserwowalny i przewidywalny.
Ograniczenie 6 (opcjonalne): code-on-demand
Hypermedia for evolving flows
Model links and allowed actions so clients stay resilient as rules change.
Code-on-demand to jedyne ograniczenie REST, które jest wyraźnie opcjonalne. Oznacza, że serwer może rozszerzyć klienta, wysyłając wykonywalny kod, który uruchamia się po stronie klienta. Zamiast dostarczać każdą funkcjonalność w kliencie przed użyciem, klient może pobierać nową logikę w razie potrzeby.
Znany przykład z Web: JavaScript
Jeśli kiedykolwiek załadowałeś stronę, która potem staje się interaktywna — waliduje formularz, rysuje wykres, filtruje tabelę — już używałeś code-on-demand. Serwer dostarcza HTML i dane oraz JavaScript, który działa w przeglądarce, by zapewnić zachowanie.
To duży powód, dla którego Web może się szybko ewoluować: przeglądarka pozostaje klientem ogólnego przeznaczenia, a serwisy dostarczają nową funkcjonalność bez instalowania nowej aplikacji.
Dlaczego jest opcjonalne (i dlaczego wiele API z tego rezygnuje)
REST „działa” bez code-on-demand, ponieważ pozostałe ograniczenia już zapewniają skalowalność, prostotę i interoperacyjność. API może być czysto zorientowane na zasoby — serwując reprezentacje jak JSON — podczas gdy klienci implementują własne zachowania.
Wiele współczesnych API celowo unika wysyłania wykonywalnego kodu, bo to komplikuje:
- Bezpieczeństwo: wykonywalny kod to większa powierzchnia ataku (iniekcje, problemy z łańcuchem dostaw, złośliwe skrypty).
- Polityki treści: przeglądarki egzekwują Content Security Policy (CSP), a organizacje mogą blokować inline-scripts lub nieznane źródła.
- Audyt i zgodność: trudniej udowodnić, jaki kod wykonał się na kliencie w danym czasie, szczególnie gdy pobierany jest dynamicznie.
Kiedy code-on-demand ma sens
Może być użyteczne, gdy kontrolujesz środowisko klienta i chcesz szybko wdrażać zachowania UI, albo gdy chcesz cienki klient, który pobiera „wtyczki” lub reguły z serwera. Jednak traktuj to jako narzędzie dodatkowe, nie wymóg.
Kluczowe przesłanie: możesz w pełni realizować REST bez code-on-demand — i wiele produkcyjnych API tak robi — ponieważ to ograniczenie dotyczy opcjonalnej rozszerzalności, a nie fundamentu interakcji opartych na zasobach.
Zastosowanie REST dziś: praktyczne wybory i częste błędy
Większość zespołów nie odrzuca REST — przyjmuje styl „REST-ish”, który trzyma HTTP jako transport, a jednocześnie cicho porzuca kluczowe ograniczenia. To może być w porządku, jeśli jest to świadomy kompromis, a nie przypadek, który wyjdzie później jako kruche klienty i kosztowne przepisywanie.
Typowe skróty „REST-ish” (i dlaczego się pojawiają)
Często pojawiają się wzorce:
- RPC endpoints:
/doThing, /runReport, /users/activate — łatwe do nazwania, proste do podłączenia.
- URL-e pełne czasowników:
/createOrder, /updateProfile, /deleteItem — metody HTTP stają się drugorzędne.
- Ukryte sesje: „bezstanowe” API, które jednak polegają na sticky sessions, pamięci serwera lub implicitnym stanie workflow.
Takie wybory często wydają się produktywne na początku, bo odzwierciedlają nazwy funkcji wewnętrznych i operacje biznesowe.
Jakie są konsekwencje później
- Kruche klienty: Jeśli klienci zależą od kształtu konkretnych endpointów i niestandardowych zachowań, drobne refaktory serwera stają się breaking changes.
- Trudne wersjonowanie: Gdy URL koduje akcje zamiast stabilnych zasobów, wersjonujesz zachowanie zamiast ewoluować reprezentacje.
- Cache misses (i większe opóźnienia): Ignorowanie nagłówków cache lub używanie POST do wszystkiego odbiera pośrednikom (i przeglądarkom) możliwość pomocy.
- Problemy ze skalowaniem: Ukryty stan serwera utrudnia skalowanie poziome i utrudnia odzyskiwanie po awariach.
Pragmatyczna lista kontrolna: na ile naprawdę jesteśmy REST?
Użyj tego jako przeglądu „jak bardzo REST jesteśmy, naprawdę?”:
- Nazwij zasoby, nie akcje: preferuj
/orders/{id} zamiast /createOrder.
- Używaj metod HTTP świadomie: GET do odczytu, POST do tworzenia, PUT/PATCH do aktualizacji, DELETE do usuwania.
- Uczyń żądania niezależnymi: brak pamięci serwera wymaganej do zrozumienia, na jakim kroku jest klient.
- Wykorzystaj cache tam, gdzie bezpiecznie: definiuj
Cache-Control, ETag i Vary dla GET.
- Standaryzuj błędy i typy mediów: spójne kody stanu i kształty odpowiedzi redukują wyjątki.
Gdzie to widać podczas budowy
Ograniczenia REST to nie tylko teoria — to wytyczne, które poczujesz podczas deploymentu. Gdy szybko generujesz API (np. scaffoldując frontend React z backendem Go + PostgreSQL), najłatwiejszy błąd to pozwolić, by „to, co najszybciej podpiąć” definiowało interfejs.
Jeśli używasz platformy typu Koder.ai do budowy aplikacji z czatu, warto wprowadzić te ograniczenia REST już na etapie rozmowy — nazwać zasoby najpierw, pozostać bezstanowym, zdefiniować spójny kształt błędów i zdecydować, gdzie cache jest bezpieczny. W ten sposób nawet szybka iteracja da API przewidywalne i łatwiejsze do rozwijania. (A ponieważ Koder.ai wspiera eksport kodu źródłowego, możesz dalej dopracowywać kontrakt API i implementację w miarę dojrzewania wymagań.)
Wnioski dla zespołów API i web app
Zdefiniuj najpierw kluczowe zasoby, potem świadomie wybierz ograniczenia: jeśli rezygnujesz z cache lub hypermedia, udokumentuj dlaczego i co zamiast tego stosujesz. Celem nie jest czystość — celem jest jasność: stabilne identyfikatory zasobów, przewidywalna semantyka i jawne kompromisy, które utrzymują klientów odpornymi w miarę rozwoju systemu.