12 wrz 2025·8 min
Pakiet startowy obserwowalności produkcyjnej na dzień pierwszy
Pakiet startowy obserwowalności produkcyjnej na dzień pierwszy: minimalne logi, metryki i trace'y do dodania oraz prosty flow triage dla zgłoszeń „to jest wolne”.
Pakiet startowy obserwowalności produkcyjnej na dzień pierwszy: minimalne logi, metryki i trace'y do dodania oraz prosty flow triage dla zgłoszeń „to jest wolne”.
Pierwsza rzecz, która się psuje, rzadko obejmuje całą aplikację. Zwykle to jeden krok, który nagle robi się zajęty, jedno zapytanie, które w testach było w porządku, albo jedna zależność, która zaczyna timoutować. Prawdziwi użytkownicy dodają prawdziwą różnorodność: wolniejsze telefony, niestabilne sieci, dziwne wejścia i skoki ruchu w niewygodnych momentach.
Kiedy ktoś mówi „to jest wolne”, może mieć na myśli bardzo różne rzeczy. Strona może ładować się zbyt długo, interakcje mogą się przycinać, jedno wywołanie API może timoutować, zadania tła mogą się kumulować, albo zewnętrzna usługa może wszystko spowalniać.
Dlatego potrzebujesz sygnałów zanim potrzebujesz dashboardów. W dniu pierwszym nie potrzebujesz perfekcyjnych wykresów dla każdego endpointu. Potrzebujesz wystarczająco logów, metryk i śledzeń, żeby szybko odpowiedzieć na jedno pytanie: gdzie ucieka czas?
Jest też realne ryzyko nadmiernego instrumentowania na początku. Za dużo zdarzeń tworzy szum, kosztuje pieniądze i może nawet spowolnić aplikację. Co gorsza, zespoły przestają ufać telemetryce, bo wydaje się chaotyczna i niespójna.
Realistyczny cel na dzień pierwszy jest prosty: kiedy dostaniesz zgłoszenie „to jest wolne”, potrafisz znaleźć wolny krok w mniej niż 15 minut. Powinieneś móc powiedzieć, czy wąskie gardło jest w renderowaniu po stronie klienta, w handlerze API i jego zależnościach, w bazie/cache, czy w zadaniu tła lub usłudze zewnętrznej.
Przykład: nowy flow checkout wydaje się wolny. Nawet bez góry narzędzi chcesz być w stanie powiedzieć „95% czasu to wywołania dostawcy płatności” albo „zapytanie koszyka skanuje za dużo wierszy”. Jeśli budujesz aplikacje szybko z narzędziami takimi jak Koder.ai, ta baza na dzień pierwszy ma jeszcze większe znaczenie, bo szybkie wdrażanie pomaga tylko wtedy, gdy potrafisz też szybko debugować.
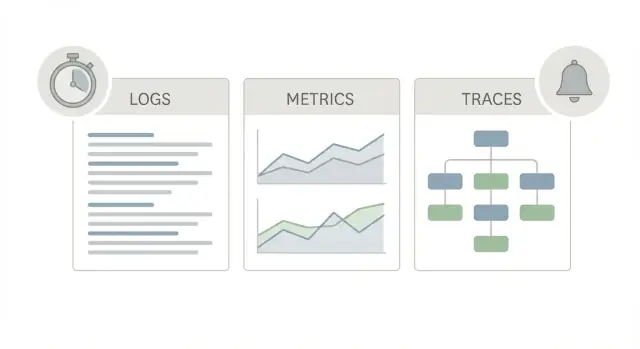
Dobry pakiet startowy obserwowalności produkcyjnej używa trzech różnych „widoków” tej samej aplikacji, bo każdy odpowiada na inne pytanie.
Logi to opowieść. Mówią, co się wydarzyło dla jednego żądania, jednego użytkownika lub jednego zadania tła. Wiersz logu może mówić „płatność nieudana dla zamówienia 123” albo „timeout DB po 2s”, plus szczegóły jak request ID, user ID i komunikat błędu. Gdy ktoś zgłasza dziwny, jednorazowy problem, logi często są najszybszym sposobem, by potwierdzić, że się zdarzył i kogo dotyczył.
Metryki to tablica wyników. To liczby, które możesz trendować i na które możesz ustawiać alerty: liczba żądań, rate błędów, percentyle latencji, CPU, głębokość kolejki. Metryki mówią, czy coś jest rzadkie czy powszechne i czy się pogarsza. Jeśli latencja skoczyła dla wszystkich o 10:05, metryki to pokażą.
Śledzenia to mapa. Trace podąża za jednym żądaniem, gdy przemieszcza się przez system (web -> API -> baza -> zewnętrzne). Pokazuje, gdzie spędzany jest czas, krok po kroku. To ważne, bo „to jest wolne” prawie nigdy nie jest jedną wielką tajemnicą. Zwykle to jedno wolne ogniwo.
Podczas incydentu praktyczny flow wygląda tak:
Prosta reguła: jeśli po kilku minutach nie potrafisz wskazać jednego wąskiego gardła, nie potrzebujesz więcej alertów. Potrzebujesz lepszych trace'ów i spójnych ID, które łączą trace'y z logami.
Większość incydentów „nie możemy tego znaleźć” nie wynika z brakujących danych. Dzieje się tak, ponieważ ta sama rzecz jest zapisywana inaczej w różnych usługach. Kilka wspólnych konwencji na dzień pierwszy sprawia, że logi, metryki i trace'y zgadzają się, gdy potrzebujesz odpowiedzi szybko.
Zacznij od wybrania jednej nazwy usługi na jednostkę deployowalną i utrzymania jej stabilnej. Jeśli „checkout-api” staje się „checkout” na połowie dashboardów, tracisz historię i psujesz alerty. Zrób to samo dla etykiet środowiska. Wybierz mały zestaw, np. prod i staging, i używaj ich wszędzie.
Następnie spraw, by każde żądanie było łatwe do śledzenia. Generuj request ID na krawędzi (API gateway, serwer WWW lub pierwszy handler) i przekaż go przez wywołania HTTP, kolejki wiadomości i zadania tła. Jeśli ticket wsparcia mówi „było wolno o 10:42”, pojedyncze ID pozwala wyciągnąć dokładne logi i trace bez zgadywania.
Zestaw konwencji, który dobrze działa na dzień pierwszy:
Uzgodnij jednostki czasu wcześnie. Wybierz milisekundy dla latencji API i sekundy dla dłuższych zadań i trzymaj się tego. Mieszane jednostki tworzą wykresy, które wyglądają poprawnie, ale opowiadają błędną historię.
Konkretny przykład: jeśli każdy API loguje duration_ms, route, status i request_id, to raport „checkout jest wolny dla tenant 418” staje się szybkim filtrem, a nie debatą, od czego zacząć.
Jeśli zrobisz tylko jedną rzecz w pakiecie startowym obserwowalności produkcyjnej, spraw, by logi były łatwe do przeszukania. To zaczyna się od ustrukturyzowanych logów (zwykle JSON) i tych samych pól we wszystkich usługach. Logi tekstowe są w porządku do lokalnego devu, ale przy prawdziwym ruchu, retryach i wielu instancjach zamieniają się w hałas.
Dobra zasada: loguj to, czego faktycznie użyjesz podczas incydentu. Większość zespołów musi odpowiedzieć: Jakie to było żądanie? Kto to zrobił? Gdzie to zawiodło? Co to dotknęło? Jeśli wiersz logu nie pomaga w jednej z tych rzeczy, prawdopodobnie nie powinien istnieć.
Na dzień pierwszy trzymaj mały, spójny zestaw pól, aby móc filtrować i łączyć zdarzenia między usługami:
Gdy wystąpi błąd, zaloguj go raz, z kontekstem. Dołącz typ błędu (lub kod), krótki komunikat, stack trace dla błędów serwera i zależność upstream (np. postgres, payment provider, cache). Unikaj powtarzania tego samego stack trace przy każdym retry. Zamiast tego dołącz request_id, by móc śledzić łańcuch.
Przykład: użytkownik zgłasza, że nie może zapisać ustawień. Jedno wyszukanie po request_id pokazuje 500 na PATCH /settings, potem downstream timeout do Postgres z duration_ms. Nie potrzebowałeś pełnych payloadów, tylko route, user/session i nazwę zależności.
Prywatność jest częścią logowania, nie zadaniem później. Nie loguj haseł, tokenów, nagłówków auth, pełnych ciał żądań ani wrażliwych PII. Jeśli musisz identyfikować użytkownika, loguj stabilne ID (lub jego hasz) zamiast e-maili czy numerów telefonu.
Jeśli budujesz aplikacje na Koder.ai (React, Go, Flutter), warto wpleść te pola w każdą generowaną usługę od początku, żeby nie kończyć na „poprawianiu logów” podczas pierwszego incydentu.
Dobry pakiet startowy zaczyna się od małego zestawu metryk, które szybko odpowiadają na pytanie: czy system jest teraz zdrowy, a jeśli nie, to gdzie boli?
Większość problemów produkcyjnych pojawia się jako jeden z czterech „golden signals”: latency (odpowiedzi są wolne), traffic (obciążenie się zmieniło), errors (coś zawodzi) i saturation (wspólny zasób jest wykorzystany do granic). Jeśli widzisz te cztery sygnały dla każdego głównego fragmentu aplikacji, możesz triage'ować większość incydentów bez zgadywania.
Latencja powinna być mierzona percentylami, nie średnimi. Śledź p50, p95 i p99, żeby zobaczyć, kiedy mała grupa użytkowników ma zły czas. Dla ruchu zacznij od requests per second (lub jobs per minute dla workerów). Dla błędów rozdziel 4xx vs 5xx: rosnące 4xx często oznaczają zmianę zachowania klienta lub walidacji; rosnące 5xx wskazują na twoją aplikację lub jej zależności. Saturacja to sygnał „kończą nam się zasoby” (CPU, pamięć, połączenia DB, backlog kolejki).
Minimalny zestaw obejmujący większość aplikacji:
Konkretne przyklady: jeśli użytkownicy zgłaszają „to jest wolne” i p95 API skacze przy stałym ruchu, sprawdź saturację. Jeśli użycie puli DB jest bliskie maxa i rosną timeouts, znalazłeś prawdopodobne wąskie gardło. Jeśli DB wygląda dobrze, a głębokość kolejki szybko rośnie, praca tła może zabierać współdzielone zasoby.
Jeśli używasz Koder.ai, traktuj tę checklistę jako część definicji „done” na dzień pierwszy. Łatwiej dodać te metryki, gdy aplikacja jest mała niż podczas pierwszego prawdziwego incydentu.
Gdy użytkownik mówi „to jest wolne”, logi często mówią, co się wydarzyło, a metryki jak często to występuje. Trace'y mówią, gdzie poszedł czas wewnątrz jednego żądania. Ta pojedyncza oś czasu zmienia niejasne narzekanie w jasną poprawkę.
Zacznij po stronie serwera. Instrumentuj przychodzące żądania na krawędzi aplikacji (pierwszy handler, który odbiera żądanie), tak aby każde żądanie mogło wygenerować trace. Trace'y po stronie klienta mogą poczekać.
Dobry trace na dzień pierwszy ma spany, które odpowiadają częściom zwykle powodującym opóźnienia:
Aby trace'y były wyszukiwalne i porównywalne, przechwyć kilka kluczowych atrybutów i trzymaj je spójnie między usługami.
Dla span'a przychodzącego żądania zapisz route (użyj szablonu jak /orders/:id, nie pełnego URL), metodę HTTP, kod statusu i latencję. Dla spanów DB zapisz system DB (PostgreSQL, MySQL), typ operacji (select, update) i nazwę tabeli, jeśli łatwo ją dodać. Dla zewnętrznych wywołań zapisz nazwę zależności (payments, email, maps), host docelowy i status.
Sampling ma znaczenie na dzień pierwszy, inaczej koszty i szum szybko rosną. Użyj prostej reguły head-based: śledź 100% błędów i wolnych żądań (jeśli SDK to wspiera), i próbkuj mały procent normalnego ruchu (np. 1–10%). Zaczynaj wyżej przy niskim ruchu, potem redukuj.
Co oznacza „dobrze”: jeden trace, w którym możesz przeczytać historię od góry do dołu. Przykład: GET /checkout trwał 2.4s, DB zużył 120ms, cache 10ms, a zewnętrzne wywołanie płatności zajęło 2.1s z retryem. Teraz wiesz, że problem leży po stronie zależności, nie twojego kodu. To sedno pakietu startowego obserwowalności produkcyjnej.
Kiedy ktoś mówi „to jest wolne”, najszybszy sukces to zamienić to niejasne odczucie w kilka konkretnych pytań. Ten flow triage działa nawet jeśli twoja aplikacja jest świeża.
Zacznij od zawężenia problemu, potem podążaj za dowodami w kolejności. Nie skacz od razu do bazy danych.
Po ustabilizowaniu sytuacji zrób jedną małą poprawkę: zapisz, co się stało i dodaj jeden brakujący sygnał. Na przykład, jeśli nie dało się określić, czy spowolnienie było tylko w jednym regionie, dodaj tag regionu do metryk latencji. Jeśli widziałeś długi span bazy bez wskazania, które zapytanie, dodaj etykiety zapytań ostrożnie lub pole „query name”.
Szybki przykład: jeśli p95 dla checkout skacze z 400 ms do 3 s, a trace'y pokazują span płatności trwający 2.4 s, możesz przestać debatować nad kodem aplikacji i skupić się na providerze, retryach i timeoutach.
Gdy ktoś mówi „to jest wolne”, możesz zmarnować godzinę tylko na ustalenie, co miało na myśli. Pakiet startowy obserwowalności jest użyteczny tylko, jeśli pomaga szybko zawęzić problem.
Zacznij od trzech wyjaśniających pytań:
Potem spójrz na kilka liczb, które zwykle mówią, gdzie iść dalej. Nie szukaj idealnego dashboardu. Chcesz tylko „gorsze niż normalnie” sygnały.
Jeśli p95 rośnie, a błędy są stabilne, otwórz jeden trace dla najwolniejszej trasy z ostatnich 15 minut. Pojedynczy trace często pokaże, czy czas spędzany jest w bazie, zewnętrznym API czy czekaniu na locki.
Następnie wykonaj jedno wyszukiwanie w logach. Jeśli masz konkretne zgłoszenie użytkownika, szukaj po request_id (lub trace_id jeśli go zapisujesz) i czytaj timeline. Jeśli nie, wyszukaj najczęstszy komunikat błędu w tym samym oknie czasowym i sprawdź, czy pokrywa się ze spowolnieniem.
Na końcu zdecyduj, czy od razu łagodzić sytuację, czy dalej drążyć. Jeśli użytkownicy są zablokowani i saturacja jest wysoka, szybkie działanie (scale up, rollback lub wyłączenie nieistotnej flagi funkcjonalnej) może kupić czas. Jeśli wpływ jest mały i system stabilny, kontynuuj dochodzenie z trace'ami i logami slow query.
Kilka godzin po releasie support zaczyna otrzymywać tickety: „Checkout trwa 20–30 sekund.” Nikt nie potrafi tego odtworzyć na laptopie, więc zaczyna się zgadywanie. Tutaj pakiet startowy się opłaca.
Najpierw idź do metryk i potwierdź symptom. Wykres p95 dla żądań HTTP pokazuje wyraźny spike, ale tylko dla POST /checkout. Inne trasy wyglądają normalnie, a rate błędów jest stabilny. To zawęża problem z „cała strona jest wolna” do „jeden endpoint spowolnił po releasie”.
Następnie otwórz trace dla wolnego żądania POST /checkout. Kaskada trace'a ujawnia winowajcę. Dwa częste wyniki:
Teraz zweryfikuj logami, używając tego samego request ID z trace'a (lub trace ID jeśli go przechowujesz w logach). W logach dla tego żądania widzisz powtarzające się ostrzeżenia jak „payment timeout reached” lub „context deadline exceeded”, plus retrye dodane w nowym releasie. Jeśli to ścieżka DB, logi mogą pokazywać komunikaty o czekaniu na locki lub treść wolnego zapytania przekraczającego próg.
Gdy wszystkie trzy sygnały są zgodne, naprawa jest prosta:
Kluczowe jest to, że nie zgadywałeś. Metryki wskazały endpoint, trace'y wskazały wolny krok, a logi potwierdziły tryb awarii z dokładnym żądaniem w ręku.
Większość czasu incydentu jest tracona na uniknione luki: dane są, ale są hałaśliwe, ryzykowne lub brakuje jednego drobnego detalu, który łączy symptomy z przyczyną. Pakiet startowy działa tylko, jeśli pozostaje użyteczny pod stresem.
Jedną pułapką jest logowanie za dużo, zwłaszcza surowych ciał żądań. Brzmi pomocnie, dopóki nie płacisz za ogromne przechowywanie, wyszukiwanie stanie się wolne i przypadkowo nie złapiesz haseł, tokenów czy danych osobowych. Preferuj ustrukturyzowane pola (route, status code, latency, request_id) i loguj tylko małe, jawnie dozwolone fragmenty wejścia.
Innym marnotrawstwem czasu są metryki wyglądające na szczegółowe, ale nieagregowalne. Etykiety wysokiej kardynalności jak pełne user ID, e-maile czy unikalne numery zamówień mogą eksplodować liczbę serii metrycznych i uczynić dashboardy zawodnymi. Używaj etykiet ogólnych (nazwa trasy, metoda HTTP, klasa statusu, nazwa zależności), a wszystko specyficzne dla użytkownika trzymaj w logach.
Błędy, które najczęściej blokują szybką diagnozę:
Mały praktyczny przykład: jeśli p95 dla checkout rośnie z 800ms do 4s, chcesz odpowiedzieć na dwa pytania w minutach: czy zaczęło się zaraz po deployu i czy czas jest spędzany w twojej aplikacji czy w zależności (DB, payment provider, cache)? Z percentylami, tagiem wersji i trace'ami z nazwami tras i zależności jesteś tam szybko. Bez nich tracisz okno incydentu na zgadywanie.
Prawdziwy zysk to spójność. Pakiet startowy obserwowalności pomaga tylko wtedy, gdy każda nowa usługa shipuje z tymi samymi podstawami, nazwanymi tak samo i łatwymi do znalezienia, gdy coś psuje się.
Zamień wybory dnia pierwszego w krótki szablon, którego zespół będzie używał. Trzymaj go małego, ale konkretnego.
Stwórz jeden widok „home”, który każdy może otworzyć podczas incydentu. Jeden ekran powinien pokazywać requests per minute, rate błędów, p95 latency i główną metrykę saturacji, z filtrem dla środowiska i wersji.
Trzymaj alertowanie minimalne na początku. Dwa alerty obejmują dużo: spike rate błędów na kluczowej trasie i spike p95 latency na tej samej trasie. Jeśli dodajesz więcej, upewnij się, że każdy ma jasną akcję.
Na koniec ustaw comiesięczny przegląd. Usuń hałaśliwe alerty, popraw nazewnictwo i dodaj jeden brakujący sygnał, który zaoszczędziłby czasu przy ostatnim incydencie.
Aby wpleść to w proces budowy, dodaj „observability gate” do checklisty wydania: brak deployu bez request ID, tagów wersji, widoku home i dwóch podstawowych alertów. Jeśli deployujesz z Koder.ai, możesz zdefiniować te sygnały dnia pierwszego w trybie planowania przed wdrożeniem, potem iterować bezpiecznie używając snapshotów i rollbacku, gdy trzeba szybko poprawić sytuację.
Zacznij od pierwszego miejsca, w którym użytkownicy wchodzą do systemu: serwera WWW, API gateway lub pierwszego handlera.
request_id i przekaż go przez wszystkie wewnętrzne wywołania.route, method, status i duration_ms dla każdego żądania.To samo w sobie zwykle szybko prowadzi do konkretnego endpointu i okna czasowego.
Cel na dzień pierwszy: potrafić zidentyfikować wolny etap w mniej niż 15 minut.
Nie potrzebujesz idealnych dashboardów od razu. Potrzebujesz wystarczająco sygnałów, żeby odpowiedzieć na pytania:
Podczas incydentu: potwierdź wpływ metrykami, znajdź wąskie gardło śledzeniami, wyjaśnij je logami.
Wybierz mały zestaw konwencji i stosuj wszędzie:
Domyślnie stosuj ustrukturyzowane logi (najczęściej JSON) z tymi samymi kluczami we wszystkich usługach.
Pola minimalne, które od razu się przydają:
Zacznij od czterech „golden signals” dla każdego głównego komponentu:
Dodatkowo mały checklist po komponencie:
Instrumentuj najpierw po stronie serwera, żeby każde przychodzące żądanie mogło stworzyć trace.
Dobre day-one trace zawiera spany odpowiadające częściom, które zwykle powodują opóźnienia:
Uczyń spany wyszukiwalnymi przez konsekwentne atrybuty: (w formie szablonu), , i jasna nazwa zależności (np. , , ).
Prosty, bezpieczny domyślny plan:
Zacznij od wyższego próbkowania przy niskim ruchu, potem zmniejszaj. Cel: mieć wystarczająco przykładów wolnej ścieżki bez eksplozji kosztów i szumu.
Użyj powtarzalnego flow, które podąża za dowodami:
Te błędy zabierają najwięcej czasu (i często pieniędzy):
service_name, environment (np. prod/staging) i versionrequest_id generowany na krawędzi i propagowany przez wywołania i zadaniaroute, method, status_code i tenant_id (jeśli multi-tenant)duration_ms)Celem jest to, by jeden filtr działał przez wszystkie usługi, zamiast zaczynać od zera przy każdym incydencie.
timestamp, level, service_name, environment, versionrequest_id (i trace_id jeśli dostępne)route, method, status_code, duration_msuser_id lub session_id (stabilny identyfikator, nie e-mail)Loguj błędy raz z kontekstem (typ błędu/kod + wiadomość + nazwa zależności). Unikaj powielania tego samego stack trace przy każdym retry.
routestatus_codepaymentspostgrescacheZapisz jedną brakującą sygnaturę, która pomogłaby następnym razem, i dodaj ją potem.
Proste zasady: stabilne ID, percentyle, jasne nazwy zależności i znaczniki wersji wszędzie.