O czym naprawdę jest to porównanie
Większość debat „BI kontra Foundry” utknie na funkcjach: które narzędzie ma lepsze wykresy, szybsze zapytania lub ładniejsze pulpity. To rzadko jest decydujący czynnik. Prawdziwe porównanie dotyczy tego, co chcesz osiągnąć.
Pulpit może powiedzieć, co się stało (lub co się dzieje). Operacyjny system decyzyjny jest zbudowany, by pomóc ludziom zdecydować, co zrobić dalej — i żeby ta decyzja była powtarzalna, audytowalna i powiązana z wykonaniem.
Insight to nie to samo co działanie. Wiedza, że zapasy są niskie, to coś innego niż uruchomienie zamówienia uzupełniającego, przekierowanie dostaw, aktualizacja planu i śledzenie, czy decyzja zadziałała.
Czego nauczysz się z tego przewodnika
Ten artykuł rozkłada na części:
- Różnice funkcjonalne między tradycyjną inteligencją biznesową a operacyjnymi systemami decyzyjnymi
- Kompromisy: szybkość wdrożenia vs głębokość integracji, elastyczność vs standaryzacja, eksploracja vs wykonanie
- Praktyczne kryteria wyboru, abyś mógł zdecydować na podstawie modelu operacyjnego — nie języka marketingowego
Zakres (większy niż jeden dostawca)
Chociaż Palantir Foundry jest użytecznym punktem odniesienia, koncepcje tutaj mają szerokie zastosowanie. Każda platforma, która łączy dane, logikę decyzyjną i workflowy, będzie działać inaczej niż narzędzia zaprojektowane przede wszystkim do pulpitów i raportowania.
Dla kogo to jest
Jeśli zarządzasz operacjami, analityką lub funkcją biznesową, w której decyzje zapadają pod presją czasu (łańcuch dostaw, produkcja, obsługa klienta, ryzyko, prace terenowe), to porównanie pomoże dopasować narzędzia do tego, jak praca rzeczywiście jest wykonywana — i gdzie dziś decyzje się załamują.
Do czego zaprojektowano tradycyjne narzędzia BI
Tradycyjne narzędzia business intelligence (BI) są tworzone, aby pomóc organizacjom zobaczyć, co się dzieje, poprzez pulpity i raportowanie. Świetnie przekształcają dane w wspólne metryki, trendy i podsumowania, z których liderzy i zespoły mogą korzystać do monitorowania wydajności.
Pulpity: monitorowanie i widoczność wydajności
Pulpity służą szybkiej orientacji sytuacyjnej: Czy sprzedaż rośnie czy spada? Czy poziomy usług mieszczą się w celach? Które regiony są słabsze?
Dobre pulpity ułatwiają skanowanie kluczowych metryk, porównywanie i drążenie. Dają zespołom wspólny język („to jest liczba, której ufamy”) i pomagają szybko wychwycić zmiany — szczególnie gdy są połączone z alertami lub zaplanowanymi odświeżeniami.
Raportowanie: standaryzowane metryki i okresowe podsumowania
Raportowanie skupia się na spójności i powtarzalności: raporty miesiąc/koniec, tygodniowe pakiety operacyjne, podsumowania zgodności i karty wyników dla zarządu.
Celem są stabilne definicje i przewidywalna dostawa: te same KPI, liczone w ten sam sposób, rozsyłane według harmonogramu. Tutaj pojawiają się pojęcia warstwy semantycznej i certyfikowanych metryk — wszyscy muszą interpretować wyniki tak samo.
Analizy ad hoc: eksploracja i odpowiadanie na nowe pytania
Narzędzia BI też wspierają eksplorację, gdy pojawiają się nowe pytania: Dlaczego konwersja spadła w zeszłym tygodniu? Które produkty generują zwroty? Co zmieniło się po aktualizacji cen?
Analitycy mogą ciąć dane według segmentów, filtrować, budować nowe widoki i testować hipotezy bez czekania na pracę inżynierii. Ten niski próg dostępu do insightu jest główną przyczyną, dla której tradycyjne BI wciąż jest powszechne.
Gdzie BI jest najsilniejsze (i gdzie zwykle się zatrzymuje)
BI błyszczy, gdy wynik to zrozumienie: szybki czas do pulpitu, znajome UX i szerokie przyjęcie wśród użytkowników biznesowych.
Typowy limit pojawia się przy kolejnym kroku. Pulpit może wskazać problem, ale zwykle nie wykonuje odpowiedzi: nie przydziela pracy, nie wymusza logiki decyzyjnej, nie aktualizuje systemów operacyjnych ani nie śledzi, czy działanie nastąpiło.
Ta luka „i co z tego?” oraz „co teraz?” jest kluczowym powodem, dla którego zespoły szukają rozwiązań poza pulpitami i raportowaniem, gdy potrzebują prawdziwej analityki przekuwanej w działanie i workflowów decyzyjnych.
Co oznacza operacyjny system decyzyjny
Operacyjny system decyzyjny jest zbudowany pod kątem wyborów, które firma podejmuje w trakcie wykonywania pracy — nie po fakcie. Te decyzje są częste, wrażliwe na czas i powtarzalne: „Co powinniśmy zrobić dalej?” zamiast „Co wydarzyło się w zeszłym miesiącu?”.
Tradycyjne BI świetnie sprawdza się w pulpitach i raportowaniu. Operacyjny system decyzyjny idzie dalej, łącząc dane + logikę + workflow + odpowiedzialność, tak aby analityka mogła niezawodnie przekształcać się w działanie w ramach realnego procesu biznesowego.
Rodzaj decyzji, które wspiera
Decyzje operacyjne zwykle mają kilka cech:
- Zachodzą wiele razy dziennie (lub na godzinę)
- „Poprawna” odpowiedź zależy od najnowszych danych
- Spójność ma znaczenie: dwa zespoły powinny dojść do podobnych decyzji przy podobnych faktach
- Potrzeba wyjaśnienia i audytu dlaczego decyzja została podjęta
Jak wygląda wynik (to nie jest wykres)
Zamiast kafelka pulpitu, system produkuje wyniki możliwe do działania, które wpisują się w pracę:
- Rekomendowane akcje (z uzasadnieniem)
- Wyjątki wymagające uwagi
- Kroki zatwierdzające i podpisy
- Kolejki zadań i przypisania
Na przykład, zamiast pokazywać trendy zapasów, operacyjny system decyzyjny może generować sugestie zamówień uzupełniających z progami, ograniczeniami dostawców i etapem zatwierdzenia przez człowieka. Zamiast pulpitu obsługi klienta, może tworzyć priorytetyzację spraw z regułami, oceną ryzyka i śladem audytowym. W operacjach terenowych może proponować zmiany w harmonogramie bazując na dostępności i nowych ograniczeniach.
Jak mierzyć sukces
Sukces to nie „więcej odsłon raportów”. To lepsze wyniki procesu biznesowego: mniej braków w magazynie, szybsze czasy rozwiązywania, niższe koszty, wyższa zgodność ze SLA i jasna odpowiedzialność.
Od insightu do działania: open loop vs closed loop
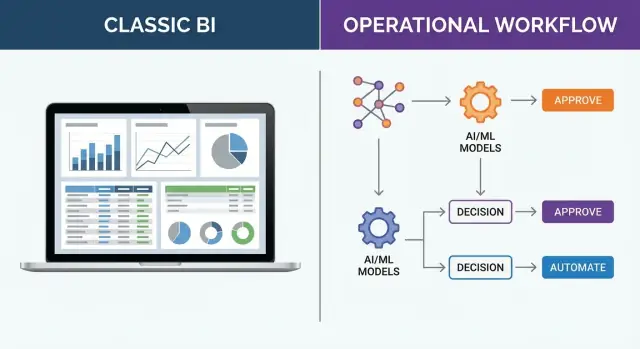
Najważniejsza różnica w Palantir Foundry vs BI nie dotyczy typu wykresu czy wyglądu pulpitu. Chodzi o to, czy system zatrzymuje się na insighcie (open loop), czy idzie dalej przez wykonanie i uczenie (closed loop).
Open loop: BI zamienia dane w widoki
Tradycyjne BI jest zoptymalizowane pod pulpity i raportowanie. Typowy przepływ wygląda tak:
- BI flow: ingest → model → visualize → human interprets
Ten ostatni krok jest kluczowy: „decyzja” zapada w czyjejś głowie, na spotkaniu lub w wątkach mailowych. To dobrze działa dla analiz eksploracyjnych, przeglądów kwartalnych i pytań, gdzie następny krok jest niejasny.
Gdzie pojawiają się opóźnienia w podejściach opartych tylko na BI, zwykle między „widzę problem” a „zrobiliśmy coś z tym”:
- właściwa osoba nie przegląda pulpitu
- definicje metryk są debatowane (niezgodności warstwy semantycznej)
- działania wymagają koordynacji między zespołami i narzędziami
- brak spójnego sposobu potwierdzenia, czy działanie zadziałało
Closed loop: systemy decyzyjne produktują działanie
Operacyjny system decyzyjny rozszerza pipeline poza insight:
- Decision system flow: ingest → model → decide → execute → learn
Różnica polega na tym, że „decide” i „execute” są częścią produktu, a nie ręcznym przekazaniem. Gdy decyzje są powtarzalne (zatwierdź/odrzuć, priorytetyzuj, alokuj, trasuj, planuj), ich zakodowanie jako workflowów plus logika decyzyjna zmniejsza opóźnienie i niespójność.
Dlaczego sprzężenie zwrotne zmienia rezultaty
Closed loop oznacza, że każda decyzja jest śledzalna względem wejść, logiki i wyników. Możesz mierzyć: Co wybraliśmy? Co się potem stało? Czy reguła, model lub próg powinny się zmienić?
Z czasem to tworzy ciągłe ulepszanie: system uczy się z rzeczywistych operacji, a nie tylko z tego, co ludzie pamiętają, żeby omówić później. To praktyczny most między analityką a działaniem.
Jak zwykle różnią się architektury
Szybko stwórz UI workflow
Szybko twórz lekkie ekrany operacyjne jak kolejki, formularze i widoki zadań bez ciężkiej inżynierii.
Tradycyjne wdrożenie BI to zazwyczaj łańcuch komponentów, każdy zoptymalizowany pod konkretny krok: magazyn danych lub jezioro do przechowywania, ETL/ELT do przemieszczania i kształtowania danych, warstwa semantyczna do standardyzacji metryk oraz pulpity/raporty do wizualizacji.
Działa to dobrze, gdy celem jest spójne raportowanie i analiza, ale „działanie” często ma miejsce poza systemem — przez spotkania, maile i ręczne przekazania.
Podejście w stylu Foundry częściej przypomina platformę, gdzie dane, logika transformacji i interfejsy operacyjne żyją bliżej siebie. Zamiast traktować analitykę jako koniec pipeline, traktuje ją jako składnik workflowu, który produkuje decyzję, wyzwala zadanie lub aktualizuje system operacyjny.
Produkty danych vs jednorazowe zestawy danych
W wielu środowiskach BI zespoły tworzą zestawy danych pod konkretny pulpit lub pytanie („sprzedaż według regionu za Q3”). Z czasem pojawia się wiele podobnych tabel, które dryfują od siebie.
W podejściu "produkt danych" celem jest wielokrotnego użytku, dobrze zdefiniowany zasób (wejścia, właściciele, zachowanie odświeżania, kontrole jakości i oczekiwani konsumenci). To ułatwia budowanie wielu aplikacji i workflowów na tych samych zaufanych blokach budulcowych.
Gdzie odbywa się obliczenie (i dlaczego to ważne)
Tradycyjne BI często opiera się na batchowych aktualizacjach: nocne ładowania, zaplanowane odświeżenia modeli, okresowe raporty. Decyzje operacyjne często potrzebują świeższych danych — czasem niemal w czasie rzeczywistym — bo koszt działania z opóźnieniem jest wysoki (nieodebrane przesyłki, braki, opóźnione interwencje).
Interfejsy poza wykresami
Pulpity są świetne do monitorowania, ale systemy operacyjne potrzebują często interfejsów, które rejestrują i kierują pracą: formularze, kolejki zadań, zatwierdzenia i lekkie aplikacje. To architektoniczna zmiana z „zobacz liczby” do „wykonaj krok”.
Potrzeby integracji danych są wyższe dla zastosowań operacyjnych
Pulpity czasem tolerują „w przybliżeniu poprawne” dane: jeśli dwa zespoły liczą klientów inaczej, nadal można zrobić wykres i wyjaśnić rozbieżność na spotkaniu. Operacyjne systemy decyzyjne nie mają tego luksusu.
Gdy decyzja wyzwala pracę — zatwierdź wysyłkę, priorytetyzuj ekipę serwisową, zablokuj płatność — definicje muszą być spójne między zespołami i systemami, inaczej automatyzacja szybko staje się niebezpieczna.
Spójne definicje między zespołami
Decyzje operacyjne zależą od wspólnych semantyk: co to jest „aktywny klient”, „zrealizowane zamówienie” czy „opóźniona dostawa”? Bez spójnych definicji jeden krok workflowu zinterpretuje ten sam rekord inaczej niż następny.
Tu warstwa semantyczna i dobrze zarządzane produkty danych są ważniejsze niż perfekcyjne wizualizacje.
Rozwiązywanie encji i uzgadnianie referencji
Automatyzacja przestaje działać, gdy system nie potrafi odpowiedzieć na podstawowe pytania typu „czy to ten sam dostawca?”. Operacyjne wdrożenia zwykle wymagają:
- Rozwiązywania encji (dopasowywanie rekordów między źródłami)
- Master data (autorytatywne identyfikatory i atrybuty)
- Uzgodnienia danych referencyjnych (waluty, lokalizacje, kody statusów, kalendarze)
Jeśli fundamenty te są brakujące, każda integracja staje się jednorazowym mapowaniem, które zawiedzie przy zmianie systemu źródłowego.
Problemy z jakością danych, które łamią automatyzację
Problemy jakości danych z wielu źródeł są powszechne — zduplikowane ID, brakujące znaczniki czasu, niespójne jednostki. Pulpit może filtrować lub adnotować; workflow operacyjny potrzebuje jawnej obsługi: reguły walidacji, fallbacky i kolejki wyjątków, aby ludzie mogli interweniować bez zatrzymania całego procesu.
Model dla decyzji, nie tylko raportowania
Modele operacyjne potrzebują encji, stanów, ograniczeń i reguł (np. „zamówienie → zapakowane → wysłane”, limity pojemności, wymogi zgodności).
Projektowanie pipelineów wokół tych koncepcji — i oczekiwanie zmian — pomaga uniknąć kruchej integracji, która załamie się przy nowych produktach, regionach czy politykach.
Governance, bezpieczeństwo i ślady audytu
Gdy przechodzisz od „oglądania insightów” do „wyzwalania akcji”, governance przestaje być kontrolą zgodności i staje się systemem bezpieczeństwa operacyjnego.
Automatyzacja może spotęgować skutki błędu: pojedyncze złe złączenie danych, przestarzała tabela lub zbyt szerokie uprawnienia może rozlać się na setki decyzji w minutach.
Dlaczego automatyzacja podnosi stawkę
W tradycyjnym BI złe dane często prowadzą do błędnej interpretacji. W operacyjnym systemie decyzyjnym złe dane mogą prowadzić do złego wyniku — przealokowania zapasów, przekierowania zamówień, odmówienia klientowi, zmiany cen.
Dlatego governance musi być umieszczone bezpośrednio na ścieżce: dane → decyzja → działanie.
Uprawnienia oparte na rolach: kto może widzieć, a kto działać
Pulpity zwykle koncentrują się na „kto może co zobaczyć”. Systemy operacyjne potrzebują dokładniejszego rozdziału:
- Uprawnienia do podglądu (inspekcja danych, metryk i wyjaśnień)
- Uprawnienia do działania (zatwierdzanie, wykonywanie lub wyzwalanie systemów downstream)
- Ograniczenia kontekstowe (działaj tylko w regionie, linii produktowej lub poziomie konta)
To zmniejsza ryzyko „dostęp do odczytu przypadkowo staje się zapisem”, szczególnie gdy workflowy integrują się z ticketingiem, ERP lub systemem zarządzania zamówieniami.
Lineage i audytowalność
Dobra lineage to nie tylko pochodzenie danych — to pochodzenie decyzji. Zespoły powinny móc prześledzić rekomendację lub działanie przez:
- kroki transformacji
- użyte wejścia i ich wersje
- zastosowaną logikę decyzyjną
- systemy źródłowe
Równie ważne jest audytowanie: zapisywanie dlaczego rekomendacja została wydana (wejścia, progi, wersja modelu, trafienia reguł), nie tylko co zarekomendowano.
Rozdział obowiązków i obsługa wyjątków
Decyzje operacyjne często wymagają zatwierdzeń, nadpisywań i kontrolowanych wyjątków. Rozdzielenie obowiązków — twórca vs zatwierdzający, rekomendujący vs wykonawca — pomaga zapobiegać cichym błędom i tworzy czytelny, możliwy do przeglądu ślad, gdy system napotka przypadki brzegowe.
Logika decyzyjna: reguły, optymalizacja i ML w kontekście
Prototypuj przepływ decyzyjny
Zbuduj pierwszą aplikację przepływu decyzyjnego w godzinach, nie tygodniach.
Pulpity odpowiadają „co się stało?”. Logika decyzyjna odpowiada „co powinniśmy zrobić dalej i dlaczego?”. W zastosowaniach operacyjnych ta logika musi być jawna, testowalna i bezpieczna do zmiany — bo może wyzwalać zatwierdzenia, przekierowania, zatrzymania lub działania wobec klientów.
Logika oparta na regułach: jasne polityki, spójne wyniki
Reguły sprawdzają się, gdy polityka jest prosta: „Jeśli zapas < X, przyspiesz” lub „Jeśli sprawa nie ma wymaganych dokumentów, poproś o nie przed przeglądem.”
Zaletą jest przewidywalność i możliwość audytu. Ryzyko to kruchość: reguły mogą wchodzić ze sobą w konflikt albo stać się nieaktualne, gdy biznes się zmienia.
Optymalizacja: podejmowanie decyzji przy ograniczeniach
Wiele realnych decyzji nie jest binarnych — to problemy alokacyjne. Optymalizacja pomaga, gdy masz ograniczone zasoby (godziny personelu, pojazdy, budżet) i cele konkurujące ze sobą (szybkość vs koszt vs sprawiedliwość).
Zamiast jednego progu definiujesz ograniczenia i priorytety, a system generuje „najlepszy dostępny” plan. Kluczowe jest, aby ograniczenia były czytelne dla właścicieli biznesowych, nie tylko modelerów.
ML scoring: priorytetyzacja z przeglądem człowieka
Uczenie maszynowe często pasuje jako krok punktowania: ranking leadów, flagowanie ryzyka, przewidywanie opóźnień. W workflowach operacyjnych ML zwykle powinien rekomendować, a nie cicho decydować — zwłaszcza gdy wynik wpływa na klientów lub zgodność z regulacjami.
Wyjaśnialność: zdobywanie zaufania i spełnianie wymogów
Ludzie muszą widzieć główne czynniki stojące za rekomendacją: użyte wejścia, kody powodów i co zmieniłoby wynik. To buduje zaufanie i wspiera audyty.
Monitorowanie dryfu i bezpieczne aktualizacje
Logika operacyjna musi być monitorowana: przesunięcia wejściowych danych, zmiany wydajności i niezamierzone biasy.
Stosuj kontrolowane wydania (np. tryb shadow, ograniczony rollout) i wersjonowanie, aby porównywać wyniki i szybko się wycofać.
Doświadczenie użytkownika: pulpity vs workflowy
Tradycyjne BI jest zoptymalizowane pod oglądanie: pulpit, raport, widok do cięcia i analizowania, który pomaga komuś zrozumieć, co się stało i dlaczego.
Operacyjne systemy decyzyjne są zoptymalizowane pod działanie. Głównymi użytkownikami są planujący, dyspozytorzy, pracownicy spraw i przełożeni — osoby podejmujące wiele małych, wrażliwych czasowo decyzji, gdzie „następny krok” nie może być spotkaniem lub zgłoszeniem w innym narzędziu.
Pulpity: świetne do świadomości, słabe w wykonaniu
Pulpity świetnie nadają się do szerokiej widoczności i opowiadania historii, ale często tworzą tarcie w momencie, gdy trzeba działać:
- Widzisz, że KPI się nie zgadza
- Kopiujesz identyfikatory do innego systemu
- Uzupełniasz brakujący kontekst między kartami
- Dokumentujesz decyzję gdzie indziej
To przełączanie kontekstu to miejsce, gdzie pojawiają się opóźnienia, błędy i niespójne decyzje.
Workflowy: działaj tam, gdzie widzisz sygnał
UX operacyjny używa wzorców projektowych, które prowadzą użytkownika od sygnału do rozwiązania:
- Alerty wyzwalane, gdy przekroczone są progi, wykryto anomalie lub ryzyko SLA
- Kolejki wyjątków priorytetyzujące „nieliczne elementy, które wymagają uwagi teraz”
- Guided workflows pokazujące wymagane pola, rekomendowane akcje i ograniczenia (polityka, pojemność, uprawnienia)
Zamiast „oto wykres”, interfejs odpowiada: Jaka decyzja jest potrzebna, jakie informacje są istotne i jakie działanie mogę podjąć tu i teraz?
W platformach takich jak Palantir Foundry często oznacza to osadzenie kroków decyzyjnych bezpośrednio w tym samym środowisku, które składa dane i logikę.
Mierzenie adopcji: poza odsłonami stron
Sukces BI często mierzy się użyciem raportów. Systemy operacyjne powinny być oceniane jak narzędzia produkcyjne:
- Wskaźniki ukończeń (ile spraw/elementów zostało rozwiązanych)
- Czas do decyzji (od alertu do działania)
- Wskaźniki nadpisywania (jak często użytkownicy omijają rekomendacje i dlaczego)
Te metryki pokazują, czy system rzeczywiście zmienia wyniki — nie tylko generuje insighty.
Przypadki użycia, w których systemy decyzyjne błyszczą
Unikaj vendor lock-in później
Zachowaj kontrolę dzięki eksportowi kodu źródłowego, gdy będziesz musiał przenieść lub sprawdzić implementację.
Systemy operacyjne decyzyjne się opłacają, gdy celem nie jest „wiedzieć, co się stało”, lecz „zdecydować, co zrobić dalej” — i robić to spójnie, szybko i z możliwością śledzenia.
Łańcuch dostaw: zapasy, alokacja i realizacja zamówień
Pulpity mogą wskazać braki lub opóźnienia; system operacyjny pomaga je rozwiązać.
Może rekomendować przealokowania między centrami dystrybucji, priorytetyzować zamówienia według SLA i marży oraz wyzwalać zamówienia uzupełniające — zapisując jednocześnie, dlaczego podjęto daną decyzję (ograniczenia, koszty i wyjątki).
Produkcja: jakość, utrzymanie i przepustowość
Gdy pojawi się problem jakościowy, zespoły potrzebują więcej niż wykresu wskaźników defektów. Workflow decyzyjny może skierować incydenty, zasugerować działania powstrzymujące, zidentyfikować partie objęte problemem i skoordynować zmianę linii.
Dla harmonogramowania utrzymania może równoważyć ryzyko, dostępność techników i cele produkcyjne — a następnie wysyłać zatwierdzony harmonogram do codziennych instrukcji pracy.
Opieka zdrowotna i ubezpieczenia: triage przypadków i planowanie pojemności
W operacjach klinicznych i likwidacji szkód wąskim gardłem jest priorytetyzacja. Systemy operacyjne mogą triage'ować sprawy według polityk i sygnałów (ciężkość, czas oczekiwania, brakujące dokumenty), przydzielać je do właściwych kolejek i wspierać planowanie pojemności „co jeśli” bez utraty audytowalności.
Podczas awarii decyzje muszą być szybkie i skoordynowane. System operacyjny może łączyć SCADA/telemetrię, pogodę, lokalizacje ekip i historię zasobów, aby rekomendować plany dysponowania, sekwencję przywracania i komunikację z klientami — a następnie śledzić wykonanie i aktualizacje w miarę zmiany warunków.
Back office: przegląd fraudu, operacje kredytowe i routing wsparcia
Zespoły zajmujące się fraudem i kredytami pracują w workflowach: przegląd, żądanie informacji, zatwierdzenie/odrzucenie, eskalacja. Systemy decyzyjne mogą ustandaryzować te kroki, zastosować spójną logikę decyzyjną i kierować sprawy do odpowiednich recenzentów.
W obsłudze klienta mogą kierować zgłoszenia na podstawie intencji, wartości klienta i wymaganych umiejętności — poprawiając wyniki, a nie tylko raportując je.
Podejście do wdrożenia, które zmniejsza ryzyko
Operacyjne systemy decyzyjne zawodzą rzadziej, gdy wdraża się je jak produkt, a nie „projekt danych”. Celem jest udowodnienie jednej pętli end-to-end — dane wchodzą, podejmowana jest decyzja, działanie wykonane i wyniki mierzone — przed skalowaniem.
Zacznij od jednej decyzji, którą możesz objąć
Wybierz jedną decyzję o jasnej wartości biznesowej i realnym właścicielu. Udokumentuj podstawy:
- Wejścia: jakie dane są potrzebne, skąd i jak świeże muszą być
- Właściciel: kto odpowiada za decyzję i eskalacje
- Częstotliwość: godzinowa, dzienna, tygodniowa
- SLA: jak szybko decyzja musi być podjęta i wykonana
To utrzymuje zakres wąski i ułatwia mierzenie sukcesu.
Zdefiniuj „zrobione” jako zmienione działanie
Insight nie jest linią mety. Zdefiniuj „zrobione” przez określenie, jakie działanie się zmienia i gdzie się zmienia — np. zmiana statusu w narzędziu ticketowym, zatwierdzenie w ERP, lista połączeń w CRM.
Dobra definicja obejmuje system docelowy, dokładne pole/stan, które się zmienia, i sposób weryfikacji, że zmiana nastąpiła.
Zbuduj minimalny wykonalny workflow (najpierw wyjątki)
Unikaj próby automatyzacji wszystkiego od razu. Zacznij od workflowu exceptions-first: system flaguje elementy wymagające uwagi, kieruje je do właściwej osoby i śledzi rozwiązanie.
Integruj tylko to, co musisz, z jasnymi ścieżkami zatwierdzeń
Priorytetyzuj kilka integracji o dużym wpływie (ERP/CRM/ticketing) i zrób kroki zatwierdzające jawne. To redukuje ryzyko przez zapobieganie „cichym decyzjom” poza systemem.
Planuj zarządzanie zmianą jako część budowy
Narzędzia operacyjne zmieniają zachowania. Włącz szkolenia, zachęty i nowe role (np. właściciele workflowów czy stewardzi danych) w plan wdrożenia, aby proces rzeczywiście się zakorzenił.
Szybsze prototypowanie workflowów (gdzie Koder.ai może pomóc)
Jednym z praktycznych wyzwań jest potrzeba lekkich aplikacji — kolejki, ekrany zatwierdzeń, obsługa wyjątków i statusy — zanim udowodnisz wartość.
Platformy takie jak Koder.ai mogą pomóc zespołom szybko prototypować te powierzchnie workflowowe za pomocą podejścia chat-driven i vibe-coding: opisz przepływ decyzji, encje danych i role, a otrzymasz początkową aplikację webową (często React) i backend (Go + PostgreSQL), którą możesz iterować.
To nie zastępuje potrzeby solidnej integracji danych i governance, ale może skrócić cykl „od definicji decyzji do użytecznego workflowu” — szczególnie gdy używasz trybu planowania do uzgodnienia interesariuszy oraz snapshotów/rollbacków do bezpiecznego testowania zmian. Jeśli później trzeba przenieść aplikację do innego środowiska, eksport kodu źródłowego może zredukować lock-in.