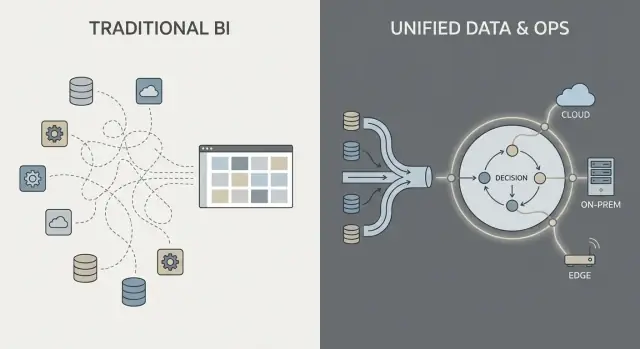
Co w tym wpisie oznacza „Palantir” i „tradycyjne oprogramowanie przedsiębiorstw"
Ludzie często używają nazwy „Palantir” jako skrótu dla kilku powiązanych produktów i ogólnego sposobu budowania operacji opartych na danych. Aby porównanie było czytelne, warto wyjaśnić, o czym dokładnie mówimy — i czego nie obejmuje.
Co w tym tekście oznacza „Palantir”
Gdy mówimy „Palantir” w kontekście korporacyjnym, zwykle mamy na myśli jedno (lub więcej) z poniższych:
- Foundry: komercyjna platforma Palantir, skoncentrowana na integracji danych, ich modelowaniu i umożliwieniu podejmowania decyzji operacyjnych.
- Gotham: często kojarzony z użyciem w obronie i sektorze publicznym, podobne tematy, inna historia i pozycjonowanie.
- Apollo: system wdrożeń i dostarczania używany do dystrybucji i zarządzania oprogramowaniem w wielu środowiskach (w tym w ograniczonych).
W tym wpisie „podejście w stylu Palantir” opisuje połączenie (1) silnej integracji danych, (2) warstwy semantycznej/ontologii, która uzgadnia znaczenia między zespołami, oraz (3) wzorców wdrożeń obejmujących chmurę, on‑prem i środowiska rozłączone.
Co oznacza „tradycyjne oprogramowanie przedsiębiorstw”
„Tradycyjne oprogramowanie przedsiębiorstw” to nie jeden produkt — to typowy stos, który organizacje składają z czasem, na przykład:
- Systemy ERP i CRM (systemy zapisów dla finansów, łańcucha dostaw, sprzedaży)
- Hurtownia danych lub jezioro danych plus dashboardy BI (narzędzia do raportowania i analiz)
- Middleware integracyjne (ETL/ELT, iPaaS, kolejki komunikatów, API)
W tym podejściu integracja, analityka i operacje często są obsługiwane przez oddzielne narzędzia i zespoły, połączone projektami i procesami governance.
Czym jest (i czym nie jest) to porównanie
To porównanie podejść, a nie rekomendacja konkretnego dostawcy. Wiele organizacji odnosi sukcesy z konwencjonalnymi stosami; inne zyskują na bardziej zintegrowanym modelu platformowym.
Praktyczne pytanie brzmi: jakich kompromisów dokonujesz w szybkości, kontroli i tym, jak bezpośrednio analityka łączy się z codzienną pracą?
Aby tekst był konkretny, skupimy się na trzech obszarach:
- Integracja danych: jak dane są łączone, utrzymywane i kto za nie odpowiada
- Analityka operacyjna: jak analiza wychodzi poza dashboardy i trafia do decyzji
- Modele wdrożeń: chmura, on‑prem i rzeczywistość środowisk rozłączonych
Integracja danych: potoki i odpowiedzialności
W większości „tradycyjnych” prac z danymi korporacyjnymi przebiega znany łańcuch: pobierz dane z systemów (ERP, CRM, logi), przetwórz je, załaduj do hurtowni/jeziora, a potem twórz dashboardy BI i kilka aplikacji downstream.
Ten schemat może działać, ale często zmienia integrację w serię kruchych przekazań: jeden zespół odpowiada za skrypty ekstrakcji, inny za modele w hurtowni, kolejny za definicje dashboardów, a zespoły biznesowe trzymają arkusze kalkulacyjne, które po cichu redefiniują „prawdziwą liczbę”.
Tradycyjny wzorzec: ETL/ELT jako wyścig sztafetowy
Przy ETL/ELT zmiany mają tendencję do rozchodzenia się falami. Nowe pole w systemie źródłowym może zepsuć potok. „Szybka poprawka” tworzy drugi potok. Wkrótce masz zduplikowane metryki („przychód” w trzech miejscach) i nie jest jasne, kto odpowiada, gdy liczby się nie zgadzają.
Przetwarzanie wsadowe jest tu powszechne: dane lądują nocą, dashboardy odświeżają się rano. Prawie‑czas rzeczywisty jest możliwy, ale często staje się osobnym stosem streamingowym z własnymi narzędziami i właścicielami.
Wzorzec w stylu Palantir: integruj, ujednólczaj znaczenie, a potem używaj wszędzie
Podejście w stylu Palantir dąży do złączenia źródeł i zastosowania spójnej semantyki (definicje, relacje, reguły) wcześniej, a następnie udostępnienia tych samych skuratowanych danych do analiz i workflowów operacyjnych.
Prościej: zamiast każdemu dashboardowi czy aplikacji „odkrywać na nowo”, co oznacza klient, zasób, sprawa czy przesyłka, to znaczenie definiuje się raz i używa w wielu miejscach. To zmniejsza powielanie logiki i ułatwia wyjaśnienie, kto jest odpowiedzialny — bo gdy definicja się zmienia, wiadomo, gdzie żyje i kto ją zatwierdza.
Częste problemy do obserwowania
Integracja zwykle zawodzi przez niejasne odpowiedzialności, nie przez brak konektorów:
- Kruche potoki, które psują się przy drobnych zmianach w źródle
- Zduplikowane metryki definiowane inaczej przez różne zespoły
- Niejasna własność jakości danych, definicji i napraw
Kluczowe pytanie to nie tylko „Czy możemy podłączyć system X?” lecz „Kto odpowiada za potok, definicje metryk i biznesowe znaczenie w czasie?”.
Warstwa semantyczna i ontologia: inny punkt ciężkości
Tradycyjne oprogramowanie przedsiębiorstw często traktuje „znaczenie” jako dodatek: dane są przechowywane w wielu schematach aplikacyjnych, definicje metryk żyją w poszczególnych dashboardach, a zespoły po cichu utrzymują własne wersje „czym jest zamówienie” czy „kiedy sprawa jest zamknięta”. Efekt to różne liczby w różnych miejscach, długie spotkania uzgadniające i niejasna odpowiedzialność, gdy coś się nie zgadza.
Ontologia — w prostych słowach
W podejściu w stylu Palantir warstwa semantyczna to nie tylko wygoda raportowania. Ontologia działa jak wspólny model biznesowy, który definiuje:
- Byty (rzeczy ważne dla biznesu): Zamówienie, Klient, Zasób, Przesyłka, Sprawa
- Relacje (jak te rzeczy się łączą): Zamówienie należy do Klienta; Przesyłka realizuje Zamówienie; Zasób jest zainstalowany na Miejscu
- Akcje (co się z nimi robi): zatwierdzić, wysłać, eskalować, wycofać, zwrócić
To staje się „centrum ciężkości” dla analiz i operacji: wiele źródeł danych może istnieć, ale mapują się na wspólny zbiór obiektów biznesowych z jednolitymi definicjami.
Dlaczego semantyka ma większe znaczenie niż się wydaje
Wspólny model zmniejsza rozbieżności liczb, bo zespoły nie wymyślają definicji na nowo w każdym raporcie czy aplikacji. Poprawia też odpowiedzialność: jeśli „Dostawa na czas” jest liczona względem zdarzeń Przesyłki w ontologii, łatwiej określić, kto odpowiada za dane i logikę biznesową.
Praktyczne przykłady do wyobrażenia
- Zamówienia: sprzedaż, finanse i wsparcie widzą ten sam obiekt Zamówienie — status, wartość, zatwierdzenia i wyjątki — bez oddzielnych „tabel zamówień” dla każdego działu.
- Zasoby: utrzymanie, operacje i zgodność dzielą rekord Zasobu z lokalizacją, historią inspekcji i flagami ryzyka.
- Sprawy: sprawy wsparcia łączą się z klientami, zamówieniami i przesyłkami, więc reguły eskalacji i metryki usług nie dryfują między zespołami.
Dobrze wdrożona ontologia nie tylko porządkuje dashboardy — przyspiesza codzienne decyzje i zmniejsza spory.
Analityka operacyjna kontra dashboardy BI
Dashboardy BI i tradycyjne raportowanie dotyczą głównie raczkującej retrospektywy i monitoringu. Odpowiadają na pytania typu „Co się stało w zeszłym tygodniu?” lub „Czy jesteśmy na ścieżce do KPI?”. Dashboard sprzedażowy, raport zamknięcia finansowego czy karta wyników dla zarządu są wartościowe — ale często kończą się na widoczności.
Analityka operacyjna różni się tym, że to analityka osadzona w codziennych decyzjach i wykonaniu. Zamiast odrębnego „miejsca analityki”, analiza pojawia się wewnątrz workflowu, gdzie praca jest wykonywana, i popycha konkretny następny krok.
BI: obserwuj i wyjaśniaj
BI/raportowanie skupia się zazwyczaj na:
- Ustandaryzowanych metrykach i definicjach KPI
- Zaplanowanych odświeżeniach i przeglądach tygodniowych/miesięcznych
- Widokach agregowanych (zespoły, regiony, okresy czasu)
- Badaniu przyczyn po zajściu zdarzeń
To świetne do governance, zarządzania wynikami i rozliczalności.
Analityka operacyjna: decyduj i wykonuj
Analityka operacyjna koncentruje się na:
- Sygnalach w czasie rzeczywistym lub prawie rzeczywistym
- Wsparciu decyzji w chwili działania
- Rekomendacjach, priorytetyzacji i obsłudze wyjątków
- Pętlach zwrotnych (czy działanie zadziałało i co się zmieniło?)
Konkretnie wygląda to mniej jak „wykres”, a bardziej jak kolejka zadań z kontekstem:
- Dyspozycja: wybór, które zadanie skierować do której ekipy, biorąc pod uwagę lokalizację, umiejętności, SLA i dostępność części
- Alokacja zapasów: decydowanie, gdzie wysłać ograniczone stany, aby zmniejszyć braki i opóźnienia
- Triage fraudów: ocenianie spraw według ryzyka i kierowanie do śledczych z odpowiednimi dowodami
- Planowanie konserwacji: przewidywanie awarii i planowanie przestojów wokół ograniczeń produkcyjnych
Kluczowa zmiana: z „widoku” do „akcji”
Najważniejsza zmiana polega na tym, że analiza jest powiązana z konkretnym krokiem workflowu. Dashboard może pokazywać „opóźnienia wzrosły”. Analityka operacyjna przekształca to w „oto 37 przesyłek zagrożonych dziś, ich prawdopodobne przyczyny i rekomendowane interwencje”, z możliwością natychmiastowego wykonania lub przypisania kolejnego kroku.
Od insightów do działań: projektowanie wokół workflowów
Tradycyjna analityka kończy się często przy widoku dashboardu: ktoś zauważa problem, eksportuje dane do CSV, wysyła e‑mail i inny zespół „coś z tym zrobi” później. Podejście w stylu Palantir ma na celu skrócenie tej luki poprzez osadzenie analityki bezpośrednio w workflowie, gdzie decyzje zapadają.
Człowiek w pętli — nie autopilot
Systemy projektowane wokół workflowów zwykle generują rekomendacje (np. „priorytetyzuj te 12 przesyłek”, „zaznacz tych 3 dostawców”, „zaplanuj konserwację w ciągu 72 godzin”), ale nadal wymagają eksplicytnego zatwierdzenia. Krok zatwierdzenia ma znaczenie, bo tworzy:
- Odpowiedzialność decyzji: kto zatwierdził, kiedy i na jakiej podstawie
- Ścieżki audytu: zapisany łańcuch od danych wejściowych → logiki/modelu → rekomendacji → działania
- Kontrolowane wyjątki: operatorzy mogą nadpisać decyzję z uzasadnieniem, zamiast omijać narzędzie
To szczególnie ważne w regulowanych lub wysokostawkowych operacjach, gdzie „model tak powiedział” nie wystarczy.
Workflowy zastępują „przekaz raportu”
Zamiast traktować analitykę jako odrębne miejsce, interfejs może przepływać insighty do zadań: przypisz do kolejki, poproś o zatwierdzenie, wyślij powiadomienie, otwórz sprawę lub utwórz zlecenie. Ważne jest, że wyniki są śledzone w tym samym systemie — dzięki temu możesz mierzyć, czy działania faktycznie zmniejszyły ryzyko, koszt lub opóźnienia.
Doświadczenia role‑based i prawa decyzyjne
Projektowanie wokół workflowu zwykle rozdziela doświadczenia według ról:
- Operatorzy frontowi: szybkie kolejki, jasna kolejna najlepsza akcja, minimalny potrzebny kontekst
- Analitycy: głębsze drążenie, testowanie scenariuszy i monitorowanie jakości danych/modeli
- Zarząd: KPI powiązane z przepustowością operacyjną i wąskimi gardłami, nie tylko wykresy
Czynnik sukcesu to dopasowanie produktu do praw decyzyjnych i procedur operacyjnych: kto może działać, jakie zatwierdzenia są potrzebne i co oznacza „zrobione” w praktyce.
Governance, bezpieczeństwo i zaufanie do danych
Zachowaj pełną kontrolę
Przejmij wygenerowany kod źródłowy i kontynuuj w własnym pipeline’ie.
Governance to miejsce, w którym wiele programów analitycznych albo odnosi sukces, albo stoi w miejscu. To nie tylko „ustawienia bezpieczeństwa” — to praktyczny zestaw reguł i dowodów, które pozwalają ludziom ufać liczbom, bezpiecznie je udostępniać i używać do rzeczywistych decyzji.
Co governance musi obejmować (poza logowaniem)
Większość przedsiębiorstw potrzebuje tych podstawowych kontroli, niezależnie od dostawcy:
- Kontrole dostępu: kto może widzieć, edytować lub zatwierdzać dane, modele i wyniki operacyjne
- Lineage danych: skąd pochodzi metryka, jakie źródła ją zasilały i jakie transformacje zaszły
- Logi audytu: defensowalny zapis, kto co i kiedy zmienił
- Zatwierdzenia i kontrola zmian: szczególnie dla „oficjalnych” metryk, współdzielonych datasetów i workflowów produkcyjnych
To nie jest biurokracja dla samej biurokracji. To sposób na zapobieganie problemowi „dwóch wersji prawdy” i zmniejszenie ryzyka, gdy analityka zbliża się do operacji.
„Bezpieczeństwo na poziomie dashboardu” vs bezpieczeństwo w całym łańcuchu
Tradycyjne wdrożenia BI często koncentrują bezpieczeństwo głównie na warstwie raportów: użytkownicy widzą określone dashboardy, a administratorzy zarządzają tymi uprawnieniami. To działa, gdy analityka jest głównie opisowa.
Podejście w stylu Palantir rozszerza bezpieczeństwo i governance na cały łańcuch: od surowego pobrania danych, przez warstwę semantyczną (obiekty, relacje, definicje), aż po modele i nawet działania wyzwalane przez insighty. Celem jest, by decyzja operacyjna (np. wysłanie zespołu, zwolnienie zapasu, priorytetyzacja spraw) odziedziczyła te same kontrole co dane, na których się opiera.
Zasada najmniejszych uprawnień i segregacja obowiązków (prosto)
Dwa proste zasady mają znaczenie dla bezpieczeństwa i odpowiedzialności:
- Najmniejsze uprawnienia: ludzie mają tylko dostęp niezbędny do wykonania pracy
- Segregacja obowiązków: osoba, która buduje lub zmienia logikę, nie jest tą samą osobą, która ją zatwierdza do produkcji
Przykład: analityk proponuje definicję metryki, steward danych ją zatwierdza, a operacje używają jej z jasnym śladem audytu.
Dlaczego governance napędza adopcję
Dobre governance to nie tylko dla zespołów compliance. Gdy użytkownicy biznesowi mogą kliknąć lineage, zobaczyć definicje i polegać na spójnych uprawnieniach, przestają się kłócić o arkusz kalkulacyjny i zaczynają działać na podstawie insightu. To zaufanie zamienia analitykę z „interesujących raportów” w rzeczywiste zachowania operacyjne.
Modele wdrożeniowe: chmura, on‑prem i środowiska rozłączone
Gdzie działa oprogramowanie korporacyjne to nie detal IT — to determinuje, co możesz robić z danymi, jak szybko możesz wprowadzać zmiany i jakie ryzyka możesz zaakceptować. Kupujący zwykle oceniają cztery wzorce wdrożeń.
Chmura publiczna
Chmura publiczna (AWS/Azure/GCP) optymalizuje szybkość: provisioning jest szybki, usługi zarządzane redukują pracę infra, a skalowanie jest proste. Główne pytania kupującego dotyczą rezydencji danych (region, kopie zapasowe, dostęp wsparcia), integracji z systemami on‑prem i czy model bezpieczeństwa toleruje dostęp sieciowy do chmury.
Chmura prywatna
Chmura prywatna (single‑tenant lub zarządzane przez klienta Kubernetes/VM) wybierana jest, gdy potrzebujesz automatyzacji chmurowej, ale silniejszych granic sieciowych i wymogów audytowych. Można zmniejszyć pewne tarcia compliance, ale nadal trzeba prowadzić dyscyplinę operacyjną (patchowanie, monitoring, przeglądy dostępu).
On‑prem
Wdrożenia on‑prem pozostają powszechne w przemyśle, energetyce i silnie regulowanych sektorach, gdzie kluczowe systemy i dane nie mogą opuszczać zakładu. Kosztem jest obciążenie operacyjne: cykl życia sprzętu, planowanie pojemności i więcej pracy, aby utrzymać spójność środowisk dev/test/prod. Jeśli organizacja ma problemy z rzetelnym uruchamianiem platform, on‑prem może spowolnić time‑to‑value.
Środowiska rozłączone / air‑gapped
Środowiska rozłączone (air‑gapped) to szczególny przypadek: obrona, infrastruktura krytyczna lub miejsca z ograniczoną łącznością. Tutaj model wdrożenia musi wspierać ścisłą kontrolę aktualizacji — podpisane artefakty, kontrolowane promowanie wydań i powtarzalną instalację w izolowanych sieciach.
Ograniczenia sieci wpływają też na przemieszczanie danych: zamiast ciąg-synchronizacji możesz polegać na etapowych transferach i workflowach „eksport/import”.
Kluczowe kompromisy
W praktyce to trójkąt: elastyczność (chmura), kontrola (on‑prem/air‑gapped) i szybkość zmian (automatyzacja + aktualizacje). Wybór zależy od reguł rezydencji, realiów sieciowych i tego, ile operacji platformy chce wziąć na siebie Twój zespół.
Operationalizacja aktualizacji: co zmienia dostarczanie w stylu Apollo
Pokaż, nie tłumacz
Hostuj prototyp i udostępnij go interesariuszom, by zebrać prawdziwe opinie.
„Dostarczanie w stylu Apollo” to praktycznie ciągłe dostarczanie w środowiskach o wysokich wymaganiach: możesz wysyłać poprawki często (cotygodniowo, codziennie, nawet kilka razy dziennie), utrzymując stabilność operacji.
Celem nie jest „szybko i łam”, lecz „często i bezpsucia”.
Ciągłe dostarczanie — prosto
Zamiast ładować zmiany do dużego kwartalnego wydania, zespoły dostarczają małe, odwracalne aktualizacje. Każda aktualizacja jest łatwiejsza do przetestowania, łatwiejsza do wytłumaczenia i łatwiejsza do wycofania, jeśli coś pójdzie nie tak.
Dla analityki operacyjnej to ma znaczenie, bo „oprogramowanie” to nie tylko UI — to potoki danych, logika biznesowa i workflowy, na których polegają ludzie. Bezpieczniejszy proces aktualizacji staje się częścią codziennych operacji.
Jak to różni się od tradycyjnych cykli enterprise
Tradycyjne aktualizacje oprogramowania w enterprise wyglądają często jak projekty: długie okna planowania, koordynacja przestojów, obawy o kompatybilność, szkolenia i twarda data przełączenia. Nawet gdy dostawcy oferują poprawki, wiele organizacji odkłada aktualizacje, bo ryzyko i wysiłek są nieprzewidywalne.
Narzędzia w stylu Apollo mają uczynić aktualizowanie rutynowym, a nie wyjątkowym—bardziej jak utrzymanie infrastruktury niż migrację.
Oddzielenie „budowania” od „wysyłania"
Nowoczesne narzędzia wdrożeniowe pozwalają zespołom rozwijać i testować w izolowanych środowiskach, a potem „promować” ten sam build przez etapy (dev → test → staging → prod) z zachowaniem kontroli. To oddzielenie pomaga redukować niespodzianki spowodowane różnicami między środowiskami.
Pytania do dostawców
- Jak wygląda rollback — jedno kliknięcie, częściowy rollback, czy skomplikowane kroki odzyskiwania?
- Jakie wersjonowanie istnieje dla potoków, modeli i zmian ontologii (nie tylko UI)?
- Jak działa promowanie środowisk i kto może to zatwierdzić?
- Czy można uruchamiać canary release’y lub feature flags?
- Jaki ślad audytu pokazuje, kto co wypuścił, kiedy i dlaczego?
- Jaki jest oczekiwany czas przestoju — najlepiej brak — dla typowych aktualizacji?
Wdrożenie i time‑to‑value: co rzeczywiście wymaga wysiłku
Time‑to‑value to mniej kwestia szybkości instalacji, a bardziej tego, jak szybko zespoły potrafią uzgodnić definicje, podłączyć nieporządne dane i zamienić insighty w codzienne decyzje.
Style implementacji: konfiguruj, składaj lub buduj
Tradycyjne oprogramowanie przedsiębiorstw często stawia na konfigurację: przyjmujesz predefiniowany model danych i workflowy, a potem mapujesz biznes do nich.
Platformy w stylu Palantir zwykle mieszają trzy tryby:
- Konfiguracja dla kontroli dostępu, połączeń danych i standardowych komponentów
- Wielokrotnego użytku bloki budulcowe (szablony, komponenty, wzorce) do składania nowych przypadków użycia
- Niestandardowy rozwój aplikacji gdy workflow jest unikalny (zatwierdzenia, obsługa wyjątków, przekazanie operacyjne)
Obietnica to elastyczność — ale oznacza też, że trzeba jasno rozróżnić, co budujesz, a co standaryzujesz.
Jedną praktyczną opcją na etapie discovery jest prototypowanie aplikacji workflowowych szybko — zanim zaangażujesz się w duże wdrożenie. Na przykład zespoły czasem używają Koder.ai (platforma vibe‑coding) do przemiany opisu workflowu w działającą aplikację webową za pomocą czatu, a następnie iterują z interesariuszami używając planning mode, snapshots i rollback. Ponieważ Koder.ai wspiera eksport kodu źródłowego oraz typowe stosy produkcyjne (React w web; Go + PostgreSQL w backendzie; Flutter na mobile), może być niskoprogową metodą walidacji UX „insight → task → ślad audytu” i wymagań integracyjnych podczas proof‑of‑value.
Gdzie zespoły rzeczywiście wkładają wysiłek
Najwięcej pracy zwykle idzie na cztery obszary:
- Onboarding danych: uzyskanie dostępu od właścicieli źródeł, dokumentowanie pól, obsługa braków jakości i ustalenie oczekiwań odświeżania
- Modelowanie i semantyka: uzgadnianie definicji biznesowych (co liczy się jako „aktywny”, „opóźniony”, „dostępny”) i utrzymanie ich spójności
- Projektowanie workflowów: ustalanie, kto reaguje na alerty, jakie decyzje są dopuszczalne i co oznacza „wykonane”
- Szkolenie i adopcja: zamiana narzędzia w nawyk — szczególnie dla użytkowników frontowych, którzy nie będą tolerować złożoności
Czerwone flagi, które spowalniają lub zabijają wartość
Uważaj na niejasną własność (brak odpowiedzialnego właściciela danych/produktu), zbyt wiele niestandardowych definicji (każdy zespół tworzy własne metryki) i brak drogi z pilota do skali (demo, które nie da się operacjonalizować, wspierać ani objąć governance).
Jak zaprojektować pilota, który można skalować
Dobry pilot jest celowo wąski: wybierz jeden workflow, zdefiniuj konkretne użytkownicy, i zobowiąż się do mierzalnego wyniku (np. skrócenie czasu realizacji o 15%, zmniejszenie backlogu wyjątków o 30%). Zaprojektuj pilota tak, aby te same dane, semantyka i kontrole mogły rozciągnąć się na następny przypadek użycia — zamiast zaczynać od zera.
Rozmowy o kosztach potrafią być trudne, bo „platforma” łączy w sobie zdolności, które zwykle kupuje się jako osobne narzędzia. Klucz to mapować cenę do rezultatów, których potrzebujesz (integracja + modelowanie + governance + aplikacje operacyjne), a nie tylko do pozycji „oprogramowanie”.
Większość umów platformowych kształtują kilka zmiennych:
- Liczba użytkowników i role: budowniczowie (inżynierowie, modelarze) vs konsumenci (operatorzy, analitycy)
- Moc obliczeniowa i storage: cięższe obciążenia (dane w czasie rzeczywistym, symulacje, duże joiny) podnoszą koszty infra
- Liczba środowisk: dev/test/prod oraz środowiska regulowane lub rozłączone, każde dodaje koszty
- Wymagania wsparcia i dostępności: 24/7, SLA incydentów, dedykowane zespoły success zmieniają cenę
- Usługi profesjonalne: początkowy onboarding danych, projekt ontologii i budowa workflowów to często realny wczesny koszt
Co „ukrywa” koszt tradycyjnego stosu
Podejście z rozwiązaniami punktowymi może wyglądać taniej na początku, ale całkowity koszt rozkłada się na:
- Wiele licencji (ETL/ELT, BI, katalog, governance, workflow, feature store itd.)
- Prace integracyjne między narzędziami (konektory, tożsamość, synchronizacja metadanych)
- Utrzymanie (aktualizacje wersji, łamane potoki, zduplikowane definicje metryk)
Platformy często redukują narastanie narzędzi, ale wymieniasz to na większy, bardziej strategiczny kontrakt.
Przy zakupie platformy potraktuj ją jak wspólną infrastrukturę: zdefiniuj zakres enterprise, domeny danych, wymogi bezpieczeństwa i kamienie milowe dostawy. Proś o jasne rozdzielenie między licencją, chmurą/infrastrukturą i serwisami, aby porównać oferty „jabłko do jabłka”.
Prosty checklist budżetowy
- Które zespoły będą aktywnie budować, a które jedynie przeglądać?
- Które workflowy muszą działać w produkcji (nie tylko dashboardy)?
- Ile środowisk i regionów jest wymaganych?
- Czy są miejsca air‑gapped lub offline?
- Spodziewany wzrost wolumenu danych/częstotliwości odświeżeń?
- Usługi potrzebne na pierwsze 90 dni?
Jeśli chcesz szybki sposób na uporządkowanie założeń, zobacz /pricing.
Kiedy podejścia w stylu Palantir pasują (a kiedy nie)
Ujednolić znaczenie
Modeluj Zamówienia, Zasoby i Zgłoszenia jako współdzielone obiekty, których zespoły mogą używać ponownie.
Platformy w stylu Palantir błyszczą, gdy problem jest operacyjny (ludzie muszą podejmować decyzje i działać między systemami), a nie tylko analityczny (ludzie potrzebują raportu). Kosztem jest to, że wdrażasz bardziej styl „platformowy” — potężny, ale wymagający od organizacji więcej niż proste wdrożenie BI.
Scenariusze, gdzie pasuje dobrze
Podejście w stylu Palantir zwykle dobrze sprawdza się, gdy praca przebiega przez wiele systemów i zespołów i nie możesz sobie pozwolić na kruche przekazania.
Typowe przykłady: koordynacja łańcucha dostaw, operacje fraudowe i ryzyka, planowanie misji, zarządzanie sprawami, flota i workflowy utrzymaniowe — tam, gdzie te same dane muszą być interpretowane spójnie przez różne role.
Pasuje też, gdy uprawnienia są złożone (dostęp wierszowy/kolumnowy, reguły need‑to‑know) i gdy potrzebny jest jasny ślad audytu użycia danych. Dobrze sprawdza się też w regulowanych lub ograniczonych środowiskach: wymagania on‑prem, wdrożenia air‑gapped lub ścisła akredytacja bezpieczeństwa.
Scenariusze słabsze
Jeśli celem jest głównie proste raportowanie — tygodniowe KPI, kilka dashboardów, podstawowe zliczenia finansowe — tradycyjne BI na dobrze zarządzanej hurtowni może być szybsze i tańsze.
Może też być overkillem dla małych zestawów danych, stabilnych schematów lub analityki jednego działu, gdzie jeden zespół kontroluje źródła i definicje, a główna „akcja” dzieje się poza narzędziem.
Kryteria decyzyjne (dopasowanie do problemu)
Zadaj trzy praktyczne pytania:
- Pilność: Czy zespoły potrzebują działających workflowów w tygodniach, czy to długi program modernizacyjny?
- Złożoność danych: Czy kluczowe decyzje blokują niespójne definicje i rozproszone źródła?
- Zdolność do zmian: Czy macie product ownership, SME i pasmo governance, by przyjąć platformę i ją utrzymywać?
Najlepsze wyniki pochodzą z traktowania tego jako „dopasowanie do problemu”, a nie „jedno narzędzie wszystko zastąpi”. Wiele organizacji utrzymuje istniejące BI do raportowania ogólnego, a podejście w stylu Palantir stosuje do najbardziej krytycznych obszarów operacyjnych.
Checklist kupującego i następne kroki
Kupno platformy w stylu Palantir kontra tradycyjne oprogramowanie przedsiębiorstw to mniej lista cech, a bardziej jasność, gdzie spocznie rzeczywista praca: integracja, wspólne znaczenie (semantyka) i codzienne użycie operacyjne. Użyj poniższej listy, aby wymusić przejrzystość wcześnie, zanim utkniesz w długiej implementacji lub wąskim narzędziu punktowym.
Praktyczny checklist porównania dostawców
Poproś każdego dostawcę o konkretne odpowiedzi na pytania kto co robi, jak to pozostaje spójne i jak jest używane w realnych operacjach.
- Wysiłek integracji: Jakie źródła danych są typowe (ERP, logi, arkusze, feedy partnerów)? Co jest prebuilt, a co wymaga customu? Kto utrzymuje potoki po uruchomieniu — IT, data engineering czy dostawca?
- Spójność semantyczna: Jak zapobiegają temu, by pięć zespołów definiowało „klienta”, „zasób” czy „gotowość misji” na różne sposoby? Czy pokażą warstwę biznesową (ontologię/warstwę semantyczną) i jak zmiany się propagują?
- Wsparcie workflowów: Czy zespoły frontowe mogą wykonać zadanie (triage, zatwierdź, wyślij, zbadaj) w produkcie, czy to „analizuj tutaj, działaj gdzie indziej”? Jak obsługiwane są wyjątki?
- Governance i bezpieczeństwo: Drobne uprawnienia, logi audytu i zarządzanie politykami — czy właściciele danych kontrolują, kto co widzi, na jakim poziomie i dlaczego?
- Ograniczenia wdrożeniowe: Czy to da się uruchomić w wymaganym środowisku (chmura, on‑prem, air‑gapped)? Co przestaje działać przy ograniczonej łączności? Jaka jest ścieżka aktualizacji?
Pytania dowodowe na demo (nie akceptuj slajdów)
- Pokaż lineage: Wybierz jedną krytyczną KPI i prześledź ją od źródła do końcowej metryki. Gdzie może się pogubić i jak to wykryjecie?
- Pokaż workflow end‑to‑end: Zacznij od surowych danych, potem alert → decyzja → akcja → ślad audytu. Uwzględnij zatwierdzenia i „kto co zmienił”.
- Zasymuluj outage/rollback: Co się dzieje, jeśli potok padnie lub wydanie powoduje regresję? Czy potrafią się szybko cofnąć i jak?
Kto powinien być w pokoju
Zaproś interesariuszy, którzy będą żyć z kompromisami:
- IT i właściciele platformy (własność integracji, niezawodność, koszt)
- Bezpieczeństwo i compliance (kontrole, audyt, zatwierdzenia wdrożeń)
- Właściciele danych/stewardzi (definicje, reguły dostępu, odpowiedzialność)
- Liderzy operacji (wpływ na procesy, adopcja)
- Użytkownicy frontowi (czy naprawdę pomaga im szybciej wykonywać pracę?)
Następne kroki
Przeprowadź proof‑of‑value ograniczony czasowo, skoncentrowany na jednym krytycznym workflowie (nie na ogólnym dashboardzie). Zdefiniuj kryteria sukcesu z wyprzedzeniem: czas podjęcia decyzji, redukcja błędów, audytowalność i odpowiedzialność za bieżącą pracę z danymi.
Jeśli chcesz więcej wskazówek o wzorcach oceny, zobacz /blog. Jeśli potrzebujesz pomocy w zakreskowaniu proof‑of‑value lub shortlistingu dostawców, skontaktuj się poprzez /contact.