15 wrz 2025·8 min
David Patterson, myślenie RISC i trwały wpływ co‑designu
Poznaj, jak myślenie Davida Patersona o RISC i co‑design sprzęt‑oprogramowanie poprawiło wydajność na wat, ukształtowało projektowanie CPU i wpłynęło na RISC‑V dziś.
Dlaczego Patterson i RISC wciąż mają znaczenie
David Patterson jest często przedstawiany jako „pionier RISC”, ale jego trwały wpływ wykracza poza pojedynczy projekt procesora. Pomógł spopularyzować praktyczny sposób myślenia o komputerach: traktuj wydajność jako coś, co można zmierzyć, uprościć i poprawić kompleksowo — od instrukcji, które rozpoznaje chip, po narzędzia programowe, które te instrukcje generują.
„Myślenie RISC” prostymi słowami
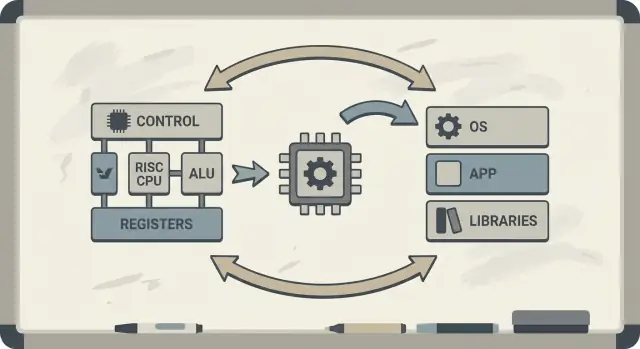
RISC (Reduced Instruction Set Computing) to idea, że procesor może działać szybciej i przewidywalniej, gdy koncentruje się na mniejszym zestawie prostych instrukcji. Zamiast implementować w sprzęcie ogromne menu złożonych operacji, uczynisz najczęściej wykonywane operacje szybkimi, regularnymi i łatwymi do pipeliningu. Zysk nie polega na „mniejszej funkcjonalności” — polega na tym, że proste bloki budowane i wykonywane efektywnie często wygrywają w rzeczywistych obciążeniach.
Co‑design: jak sprzęt i kod wzajemnie się ulepszają
Patterson promował też co‑design sprzęt–oprogramowanie: pętlę sprzężenia zwrotnego, w której architekci chipów, autorzy kompilatorów i projektanci systemów iterują wspólnie.
Jeśli procesor jest zaprojektowany tak, by dobrze wykonywać proste wzorce, kompilatory potrafią niezawodnie generować takie wzorce. Jeśli kompilatory ujawnią, że programy spędzają czas na pewnych operacjach (np. dostęp do pamięci), sprzęt można dostosować, by lepiej obsługiwał te przypadki. Dlatego dyskusje o ISA naturalnie łączą się z optymalizacjami kompilatora, cache’ami i pipeliningiem.
Co zyskasz czytając ten artykuł
Dowiesz się, dlaczego idee RISC łączą się z wydajnością na wat (a nie tylko surową prędkością), jak „przewidywalność” sprawia, że współczesne CPU i układy mobilne są bardziej efektywne, oraz jak te zasady pojawiają się w dzisiejszych urządzeniach — od laptopów po serwery w chmurze.
Jeśli chcesz mapę kluczowych koncepcji przed dalszym zgłębianiem, przejdź do /blog/key-takeaways-and-next-steps.
Problem, na który odpowiadał RISC
Wczesne mikroprocesory projektowano w silnych ograniczeniach: chipy miały niewiele miejsca na układy, pamięć była droga, a magazyny wolne. Projektanci starali się dostarczyć komputery tanie i „wystarczająco szybkie”, często z małymi cache’ami (lub bez), umiarkowanymi częstotliwościami taktowania i bardzo ograniczoną pamięcią główną w porównaniu z oczekiwaniami oprogramowania.
Dawne założenie: złożone instrukcje = szybsze programy
Popularnym pomysłem było, że jeśli CPU zaoferuje potężniejsze, wysokopoziomowe instrukcje — takie, które potrafią wykonać kilka kroków na raz — programy będą działać szybciej i łatwiej się je będzie pisało. Jeśli jedna instrukcja potrafi „zrobić pracę kilku”, myślano, że potrzeba mniej instrukcji ogółem, oszczędzając czas i pamięć.
To intuicja stojąca za wieloma projektami CISC (Complex Instruction Set Computing): daj programistom i kompilatorom dużą skrzynkę wyszukanych operacji.
Niezgodność: co CPU oferowały vs co było używane
Pułapka polegała na tym, że rzeczywiste programy (i kompilatory je tłumaczące) nie wykorzystywały konsekwentnie tej złożoności. Wiele z najbardziej wymyślnych instrukcji było rzadko używanych, podczas gdy mały zestaw prostych operacji — ładowanie danych, zapis, dodawanie, porównanie, skok — pojawiał się wciąż i wciąż.
Tymczasem wspieranie ogromnego menu złożonych instrukcji sprawiało, że CPU były trudniejsze w budowie i wolniejsze do optymalizacji. Złożoność pochłaniała przestrzeń na chipie i wysiłek projektowy, który mógł zostać przeznaczony na to, by sprawić, że typowe ścieżki będą działać przewidywalnie i szybko.
RISC odpowiedział na tę lukę: skoncentruj CPU na tym, co oprogramowanie naprawdę robi najczęściej, i spraw, by te ścieżki były szybkie — a kompilatory niech wykonają więcej pracy „koordynacyjnej” w sposób systematyczny.
RISC vs CISC: pomysł prostymi słowami
Prosty sposób myślenia o CISC vs RISC to porównanie narzędzi.
CISC jest jak warsztat pełen wyspecjalizowanych, wyszukanych narzędzi — każde potrafi dużo w jednym ruchu. Pojedyncza „instrukcja” może załadować dane z pamięci, wykonać obliczenie i zapisać wynik, wszystko w pakiecie.
RISC jest jak noszenie mniejszego zestawu niezawodnych narzędzi, których używasz cały czas — młotek, śrubokręt, miarka — i budowanie wszystkiego z powtarzalnych kroków. Każda instrukcja zwykle wykonuje jedno małe, jasne zadanie.
Dlaczego „prostsze” może być szybsze
Gdy instrukcje są prostsze i bardziej jednorodne, CPU może je wykonywać przy użyciu czystszej linii montażowej (pipeline). Ta linia jest łatwiejsza do zaprojektowania, łatwiejsza do uruchomienia przy wyższych częstotliwościach i łatwiejsza do utrzymania w pełni zajętej.
W przypadku stylu CISC, CPU często musi i tak zdekodować i rozbić złożoną instrukcję na mniejsze wewnętrzne kroki. To dodaje złożoności i utrudnia utrzymanie płynności pipeline’u.
Przewidywalność ma znaczenie
RISC dąży do przewidywalnego czasu wykonania instrukcji — wiele instrukcji zajmuje mniej więcej tyle samo czasu. Przewidywalność pomaga CPU efektywnie planować pracę i pomaga kompilatorom generować kod, który utrzymuje pipeline zapełniony zamiast powodować przestoje.
Kompromisy (i dlaczego często się opłacają)
RISC zwykle wymaga więcej instrukcji, by wykonać to samo zadanie. To może oznaczać:
- nieco większy rozmiar programu (więcej bajtów kodu)
- więcej pobrań instrukcji z pamięci
Jednak to może być korzystne, jeśli każda instrukcja jest szybka, pipeline pozostaje płynny, a ogólny projekt jest prostszy.
W praktyce dobrze zoptymalizowane kompilatory i dobre pamięci podręczne mogą zrekompensować wadę „większej liczby instrukcji” — CPU spędza więcej czasu wykonując użyteczną pracę i mniej czasu rozplątując złożone instrukcje.
Berkeley RISC i podejście „mierz, potem projektuj”
Berkeley RISC to nie tylko nowy zestaw instrukcji. To postawa badawcza: nie zaczynaj od tego, co wydaje się eleganckie na papierze — zacznij od tego, co programy faktycznie robią, a potem dopasuj CPU do tej rzeczywistości.
Małe, szybkie jądro + sprytny kompilator
Na poziomie koncepcyjnym zespół z Berkeley dążył do jądra CPU na tyle prostego, by działać bardzo szybko i przewidywalnie. Zamiast upychać sprzęt wieloma wyszukanymi „sztuczkami” instrukcyjnymi, polegali na kompilatorze: wybierał proste instrukcje, dobrze je harmonogramował i trzymał dane w rejestrach jak najdłużej.
Ten podział ról miał znaczenie. Mniejsze, czystsze jądro łatwiej jest efektywnie pipeline’ować, prościej się je analizuje i często jest szybsze na tranzystor. Kompilator, widząc cały program, może planować z wyprzedzeniem w sposób, w jaki sprzęt nie potrafi łatwo robić w locie.
Mierz rzeczywiste obciążenia, nie założenia
David Patterson podkreślał pomiar, ponieważ projektowanie komputerów jest pełne kuszących mitów — cech, które brzmią użytecznie, ale rzadko pojawiają się w rzeczywistym kodzie. Berkeley RISC promował używanie benchmarków i śladów obciążeń, aby znaleźć gorące ścieżki: pętle, wywołania funkcji i dostęp do pamięci, które dominują czas wykonania.
To bezpośrednio wiąże się z zasadą „uczynić szybkim przypadek typowy”. Jeśli większość instrukcji to proste operacje i load/store, optymalizacja tych częstych przypadków przynosi większe korzyści niż przyspieszanie rzadkich, złożonych instrukcji.
RISC jako sposób myślenia
Trwały wniosek jest taki, że RISC to zarówno architektura, jak i sposób myślenia: upraszczaj to, co częste, weryfikuj dane i traktuj sprzęt i oprogramowanie jako jeden system, który można razem dostrajać.
Co oznacza co‑design sprzęt–oprogramowanie
Co‑design sprzęt–oprogramowanie oznacza, że nie projektujesz CPU w izolacji. Projektujesz chip i kompilator (a czasem system operacyjny) z myślą o sobie nawzajem, tak aby rzeczywiste programy działały szybko i efektywnie — nie tylko syntetyczne „najlepsze” sekwencje instrukcji.
Prosta pętla sprzężenia zwrotnego
Co‑design działa jak pętla inżynieryjna:
-
Wybory ISA: architektura zestawu instrukcji (ISA) decyduje, co CPU potrafi wyrazić łatwo (np. model „load/store”, dużo rejestrów, proste tryby adresowania).
-
Strategie kompilatora: kompilator się adaptuje — trzyma gorące zmienne w rejestrach, przestawia instrukcje, by unikać zatorów, i wybiera konwencje wywołań, które zmniejszają narzut.
-
Wyniki obciążeń: mierzysz rzeczywiste programy (kompilatory, bazy danych, grafika, kod systemowy) i widzisz, gdzie idzie czas i energia.
-
Następny projekt: na podstawie tych pomiarów dostrajasz ISA i mikroarchitekturę (głębokość pipeline’u, liczbę rejestrów, rozmiary cache’u).
Oto mała pętla (C), która ilustruje relację:
for (int i = 0; i < n; i++)
sum += a[i];
Na ISA w stylu RISC kompilator zwykle trzyma sum i i w rejestrach, używa prostych instrukcji load dla a[i] i wykonuje harmonogramowanie instrukcji, tak by CPU pozostał zajęty, gdy ładowanie jest w toku.
Dlaczego ignorowanie kompilatora marnuje krzem i energię
Jeśli chip dodaje złożone instrukcje lub specjalny układ, których kompilatory rzadko używają, ta część i tak zużywa moc i wysiłek projektowy. Tymczasem „nudne” rzeczy, na których kompilatory polegają — wystarczająco dużo rejestrów, przewidywalne pipeline’y, wydajne konwencje wywołań — mogą być niedofinansowane.
Myślenie RISC Patersona kładło nacisk na wydatkowanie krzemu tam, gdzie rzeczywiste oprogramowanie może odnieść korzyść.
Pipeline’y, przewidywalność i pomoc kompilatora
Przyspiesz cykle iteracji
Skróć pętlę build–measure dzięki szybszym iteracjom i większej mocy w Koder.ai.
Kluczową ideą RISC było ułatwienie utrzymania „linii montażowej” CPU w pracy. Ta linia to pipeline: zamiast kończyć jedną instrukcję całkowicie, zanim zaczniesz następną, procesor dzieli pracę na etapy (fetch, decode, execute, write‑back) i nakłada je na siebie. Gdy wszystko płynie, kończysz blisko jednej instrukcji na cykl — jak samochody przechodzące przez wielostanowiskową fabrykę.
Dlaczego prostsze instrukcje utrzymują linię w ruchu
Pipeline’y działają najlepiej, gdy każdy element na linii jest podobny. Instrukcje RISC zaprojektowano tak, by były względnie jednorodne i przewidywalne (często stałej długości, z prostym adresowaniem). To zmniejsza „specjalne przypadki”, gdy jedna instrukcja wymaga dodatkowego czasu lub nietypowych zasobów.
Gdy pipeline musi przystopować: hazardy i zatory
Rzeczywiste programy nie są idealnie gładkie. Czasem instrukcja zależy od wyniku poprzedniej (nie możesz użyć wartości, zanim zostanie obliczona). Innym razem CPU musi poczekać na dane z pamięci, albo nie wie jeszcze, którą ścieżkę wybierze skok.
Sytuacje te powodują stalls — krótkie pauzy, gdy część pipeline’u stoi bezczynnie. Intuicja jest prosta: zatory pojawiają się, gdy następny etap nie może robić użytecznej pracy, bo czegoś brakuje.
Kompilator jako kontroler ruchu
Tu widać wyraźnie co‑design sprzęt‑oprogramowanie. Jeśli sprzęt jest przewidywalny, kompilator może pomóc przez przestawianie kolejności instrukcji (bez zmiany znaczenia programu), aby wypełnić „luki”. Na przykład, podczas oczekiwania na wartość, kompilator może zaplanować niezależną instrukcję, która nie zależy od tej wartości.
Zysk jest wspólną odpowiedzialnością: CPU pozostaje prostszy i szybki w typowym przypadku, a kompilator bierze na siebie planowanie. Razem zmniejszają zatory i zwiększają przepustowość — często poprawiając rzeczywistą wydajność bez potrzeby używania bardziej złożonego zestawu instrukcji.
Cache’y i memory wall: gdzie co‑design się opłaca
CPU potrafi wykonać proste operacje w kilku cyklach, ale pobranie danych z pamięci głównej (DRAM) może zająć setki cykli. Ta luka istnieje, ponieważ DRAM jest fizycznie dalej, zoptymalizowany pod pojemność i koszt, i ograniczony zarówno opóźnieniem (jak długo trwa pojedyncze żądanie), jak i przepustowością (ile bajtów na sekundę można przesłać).
W miarę jak CPU przyspieszały, pamięć nie nadążała w tym samym tempie — rosnąca niespójność nazywana jest często memory wall.
Cache’y i lokalność
Cache’e to małe, szybkie pamięci umieszczone blisko CPU, by unikać kary DRAM przy każdym dostępie. Działają, ponieważ rzeczywiste programy mają lokalność:
- Lokalność czasowa: jeśli niedawno użyłeś wartości lub instrukcji, prawdopodobnie użyjesz jej wkrótce ponownie.
- Lokalność przestrzenna: jeśli dostępowałeś jednego adresu, prawdopodobnie następnym dostępem będą sąsiednie adresy.
Nowoczesne chipy układają cache’e warstwowo (L1, L2, L3), starając się trzymać „working set” kodu i danych blisko rdzenia.
Gdzie ISA i kompilatory wpływają na zachowanie cache’u
Właśnie tutaj co‑design sprzęt–oprogramowanie daje największe korzyści. ISA i kompilator razem kształtują, jak dużo nacisku na cache generuje program.
- Rozmiar kodu ma znaczenie. Większe binaria i cięższe sekwencje instrukcji mogą przepełnić cache instrukcji, powodując zatory. Wybory ISA poprawiające gęstość kodu (np. opcjonalne skompresowane instrukcje) mogą zwiększyć trafienia w cache instrukcji.
- Wzorce dostępów mają znaczenie. RISC‑owy model load/store czyni dostęp do pamięci jawny. Kompilatory mogą wtedy planować ładowania wcześniej, trzymać gorące wartości w rejestrach dłużej i zmniejszać niepotrzebny ruch w pamięci.
- Układ i blocking. Optymalizacje kompilatora jak loop tiling (blocking), przestawianie struktur danych i wskazówki prefetchingu mają na celu zamianę „losowych wypraw do DRAM” w przewidywalne trafienia cache’u.
Memory wall w rzeczywistej wydajności
Mówiąc prościej, memory wall tłumaczy, dlaczego CPU z wysokim zegarem może nadal wydawać się ospały: otwieranie dużej aplikacji, wykonanie zapytania do bazy, przewijanie feedu czy przetwarzanie dużego zbioru danych często blokuje się na brakach w cache i przepustowości pamięci — nie na surowej prędkości arytmetycznej.
Efektywność: wydajność na wat, nie tylko surowa szybkość
Wybierz plan dopasowany do potrzeb
Porównaj Free, Pro, Business i Enterprise, aby dopasować plan do sposobu, w jaki budujesz i wdrażasz.
Przez długi czas dyskusje o CPU przypominały wyścig: który chip skończy zadanie szybciej, ten „wygrywał”. Ale rzeczywiste komputery żyją w granicach fizycznych — bateria, ciepło, hałas wentylatorów i rachunki za prąd.
Dlatego performance per watt stało się kluczowym miernikiem: ile użytecznej pracy otrzymujesz za zużytą energię.
Co naprawdę znaczy „performance per watt”
Traktuj to jako efektywność, nie szczytową siłę. Dwa procesory mogą wydawać się podobnie szybkie w codziennym użyciu, a jednak jeden robi to, pobierając mniej mocy, chłodząc się lepiej i działając dłużej na tej samej baterii.
W laptopach i telefonach wpływa to bezpośrednio na żywotność baterii i komfort. W centrach danych wpływa na koszty zasilania i chłodzenia tysięcy maszyn oraz na gęstość serwerów, którą można umieścić bez przegrzewania.
Dlaczego prostsze rdzenie często zużywają mniej energii
Myślenie RISC skierowało projektowanie CPU ku wykonywaniu mniejszej liczby rzeczy w sprzęcie, bardziej przewidywalnie. Prostsze jądro może redukować zużycie energii na kilka sposobów:
- Mniej skomplikowana logika sterująca oznacza mniej wewnętrznych „ruchomych części” przełączających się w każdym cyklu.
- Bardziej przewidywalne wykonanie ułatwia utrzymanie pipeline’u zajętego bez kosztownego przywracania stanu.
- Projekty przyjazne kompilatorowi pozwalają oprogramowaniu planować pracę efektywniej, unikając kosztownego zgadywania przez sprzęt.
Chodzi nie o to, że „proste zawsze jest lepsze”. Chodzi o to, że złożoność ma swój koszt energetyczny, a dobrze dobrany ISA i mikroarchitektura mogą wymienić trochę sprytu na dużo efektywności.
Mobilne i serwery dążą do tego samego celu
Telefony dbają o baterię i ciepło; serwery o zasilanie i chłodzenie. Różne środowiska, ta sama lekcja: najszybszy chip nie zawsze jest najlepszym komputerem. Zwycięzcy to często projekty dostarczające stałą przepustowość przy kontrolowanym zużyciu energii.
Co RISC zrobił dobrze — i co było bardziej skomplikowane
RISC często podsumowuje się jako „prostsze instrukcje wygrywają”, ale trwalsza lekcja jest subtelniejsza: zestaw instrukcji ma znaczenie, ale wiele rzeczywistych zysków pochodziło z tego, jak chipy były budowane, nie tylko z tego, jak wyglądał ISA na papierze.
Debata „czy ISA ma znaczenie”
Wczesne argumenty RISC sugerowały, że czystszy, mniejszy zestaw instrukcji automatycznie uczyni komputery szybszymi. W praktyce największe przyspieszenia często wynikały z wyborów implementacyjnych ułatwionych przez RISC: prostsze dekodowanie, głębsze pipeline’y, wyższe zegary i kompilatory, które mogły harmonogramować pracę przewidywalnie.
Dlatego dwa CPU z różnymi ISA mogą skończyć blisko siebie pod względem wydajności, jeśli ich mikroarchitektury, rozmiary cache’u, przewidywanie skoków i proces technologiczny są różne. ISA ustala zasady; mikroarchitektura rozgrywa grę.
Pomiar bije listy funkcji
Kluczowa zmiana ery Patersona to projektowanie na podstawie danych, a nie przypuszczeń. Zamiast dodawać instrukcje, bo wydają się użyteczne, zespoły mierzyły, co programy faktycznie robią, i optymalizowały przypadek typowy.
To podejście często przewyższało projekty „napędzane funkcjami”, gdzie złożoność rosła szybciej niż korzyści. Pozwala też wyraźniej widzieć kompromisy: instrukcja, która oszczędza kilka linii kodu, może kosztować dodatkowe cykle, energię lub przestrzeń na chipie — a te koszty pojawiają się wszędzie.
To nie historia zwycięzcy bierze wszystko
Myślenie RISC nie ukształtowało jedynie „czystych RISC‑ów”. Z czasem wiele CPU CISC przyjęło techniki podobne do RISC (np. rozbijanie złożonych instrukcji na prostsze wewnętrzne operacje), zachowując zgodność z istniejącym ISA.
Wynik nie był „RISC pokonał CISC”. To była ewolucja w stronę projektów, które cenią pomiar, przewidywalność i ścisłą koordynację sprzęt–oprogramowanie — niezależnie od logo na ISA.
Od MIPS do RISC‑V: ciągłość myślenia
RISC nie pozostał w laboratorium. Jednym z najjaśniejszych wątków od wczesnych badań do praktyki jest linia od MIPS do RISC‑V — dwa ISA, które uczyniły prostotę i przejrzystość cechą, nie ograniczeniem.
MIPS: czysty ISA, który można zbudować (i nauczyć się)
MIPS pamięta się jako ISA do nauki i słusznie: reguły są łatwe do wytłumaczenia, formaty instrukcji spójne, a model load/store nie przeszkadza kompilatorowi.
Ta czytelność nie była tylko akademicka. Procesory MIPS trafiały do realnych produktów przez lata (od stacji roboczych po systemy wbudowane), częściowo dlatego, że prosty ISA ułatwia budowę szybkich pipeline’ów, przewidywalnych kompilatorów i efektywnych narzędzi. Gdy zachowanie sprzętu jest regularne, oprogramowanie może się do niego dostosować.
RISC‑V: otwarte, praktyczne i przyjazne co‑designowi
RISC‑V odnowił zainteresowanie myśleniem RISC, robiąc krok, którego MIPS nie podjął: to otwarty ISA. Zmienia to motywacje. Uczelnie, startupy i duże firmy mogą eksperymentować, wysyłać krzem i współdzielić narzędzia bez negocjacji o dostęp do samego zestawu instrukcji.
Dla co‑designu ta otwartość ma znaczenie, bo „strona oprogramowania” (kompilatory, systemy operacyjne, runtime’y) może ewoluować publicznie razem ze „stroną sprzętową”, z mniejszymi sztucznymi barierami.
Modularne rozszerzenia: dodawaj tylko to, czego potrzebujesz
Kolejny powód, dla którego RISC‑V dobrze pasuje do co‑designu, to podejście modułowe. Zaczynasz od małego podstawowego ISA, a potem dodajesz rozszerzenia do konkretnych potrzeb — np. obliczenia wektorowe, ograniczenia wbudowane, cechy bezpieczeństwa.
To zachęca do zdrowszych kompromisów: zamiast upychać wszystkie możliwe funkcje w jednym monolicie, zespoły mogą dopasować funkcje sprzętowe do oprogramowania, które rzeczywiście będą uruchamiać.
Jeśli chcesz głębszy wstęp, zobacz: /blog/what-is-risc-v.
Jak co‑design przejawia się we współczesnych systemach
Współpracuj nad co-designem
Pracuj razem nad tą samą aplikacją i utrzymuj jasność decyzji dzięki wspólnym planom.
Co‑design to nie historyczny przypis ery RISC — to sposób, w jaki współczesne obliczenia stają się szybsze i bardziej efektywne. Kluczowa idea pozostaje w stylu Patersona: nie „wygrywasz” samym sprzętem ani samym oprogramowaniem. Wygrywasz, gdy obie strony pasują do swoich mocnych stron i ograniczeń.
Myślenie RISC w urządzeniach, których używasz codziennie
Smartfony i wiele urządzeń wbudowanych mocno opierają się na zasadach RISC (często na ARM): prostsze instrukcje, przewidywalne wykonanie i silne nastawienie na zużycie energii.
Ta przewidywalność pomaga kompilatorom generować efektywny kod i projektantom budować rdzenie, które oszczędzają energię podczas przeglądania, ale potrafią nagle zwiększyć moc do pipeline’u kamery czy gry.
Laptopy i serwery coraz częściej dążą do tych samych celów — zwłaszcza wydajności na wat. Nawet jeśli ISA nie jest tradycyjnie „RISC‑owa”, wiele wewnętrznych wyborów projektowych ma na celu osiągnięcie efektywności w stylu RISC: głębokie pipeline’y, szerokie wykonywanie i agresywne zarządzanie energią dostrojone do rzeczywistego zachowania oprogramowania.
Akceleratory jako co‑design w praktyce
GPU, akceleratory AI (TPU/NPUs) i układy multimedialne to praktyczna forma co‑designu: zamiast zmuszać wszystko przez ogólnego przeznaczenia CPU, platforma dostarcza sprzęt dopasowany do typowych wzorców obliczeniowych.
To, co czyni to prawdziwym co‑designem (a nie tylko „dodatkowym sprzętem”), to otaczający stos oprogramowania:
- GPU zyskują prędkość dzięki modelom programowania jak CUDA i API typu Vulkan/Metal.
- Akceleratory AI polegają na kompilatorach i optymalizatorach grafów, które przekształcają model w preferowane operacje układu.
- Koderowanie/dekodowanie wideo się opłaca, bo systemy operacyjne, przeglądarki i aplikacje są napisane tak, by z nich korzystać.
Jeśli oprogramowanie nie celuje w akcelerator, teoretyczna szybkość pozostaje teoretyczna.
Stosy oprogramowania są częścią wydajności
Dwie platformy o podobnych specyfikacjach mogą odczuwać się bardzo różnie, ponieważ „prawdziwy produkt” obejmuje kompilatory, biblioteki i frameworki. Dobrze zoptymalizowana biblioteka matematyczna (BLAS), dobry JIT lub lepszy kompilator potrafią przynieść duże zyski bez zmiany chipa.
Dlatego współczesne projektowanie CPU jest często napędzane benchmarkami: zespoły sprzętowe patrzą, co kompilatory i obciążenia rzeczywiście robią, i dopasowują funkcje (cache, predykcja skoków, instrukcje wektorowe, prefetching), aby przyspieszyć przypadek typowy.
Krótka lista kontrolna: na co zwracać uwagę
Gdy oceniasz platformę (telefon, laptop, serwer lub płytkę embedded), szukaj sygnałów co‑designu:
- Dopasowanie obciążeń: Czy twoje aplikacje są ograniczone CPU, GPU, pamięcią czy akceleratorami?
- Dostępność akceleratorów: Czy jest NPU/GPU/silnik multimedialny — i czy twoje narzędzia faktycznie z tego korzystają?
- Dojrzałość toolchainu: Czy są zoptymalizowane buildy, dobre narzędzia profilujące i aktywne wsparcie?
- Ekosystem bibliotek: Czy kluczowe biblioteki (math, vision, crypto) są dostrojone pod ten sprzęt?
- Zachowanie energetyczne: Czy uzyskujesz utrzymaną wydajność w granicach termicznych/poborowych?
Postęp w nowoczesnych obliczeniach to mniej „szybszy pojedynczy CPU” a bardziej całe urządzenie sprzęt‑plus‑oprogramowanie, które zostało ukształtowane — zmierzone, a potem zaprojektowane — wokół rzeczywistych obciążeń.
Kluczowe wnioski i praktyczne następne kroki
Myślenie RISC i szersze przesłanie Patersona sprowadzają się do kilku trwałych lekcji: upraszczaj to, co musi być szybkie, mierz to, co się faktycznie dzieje, i traktuj sprzęt i oprogramowanie jako jeden system — bo użytkownicy doświadczają całości, nie pojedynczych komponentów.
Lekcje warte zapamiętania
Po pierwsze, prostota to strategia, nie estetyka. Czysty ISA i przewidywalne wykonanie ułatwiają kompilatorom generowanie dobrego kodu i CPU uruchamianie go efektywnie.
Po drugie, pomiar bije intuicję. Uruchamiaj benchmarki reprezentatywnych obciążeń, zbieraj profilowanie i niech realne wąskie gardła kierują decyzjami projektowymi — czy to przy strojenie optymalizacji kompilatora, wyborze SKU CPU czy przeprojektowaniu krytycznej gorącej ścieżki.
Po trzecie, co‑design to miejsce, gdzie korzyści się kumulują. Kod przyjazny pipeline’owi, struktury danych świadome cache’u i realistyczne cele wydajności na wat często dają więcej praktycznej prędkości niż gonitwa za szczytową przepustowością teoretyczną.
Praktyczne następne kroki dla zespołów produktowych
Jeśli wybierasz platformę (x86, ARM lub systemy oparte na RISC‑V), oceniaj ją tak, jak zrobią to twoi użytkownicy:
- Uruchamiaj benchmarki end‑to‑end (czas uruchamiania, stała przepustowość, opóźnienia ogona), nie tylko mikrobenchmarki.
- Śledź metryki efektywności (watty, termika, wpływ na baterię) obok wydajności.
- Iteruj: profiluj → zmień jedną rzecz → zmierz ponownie. Małe, zweryfikowane kroki składają się na duże rezultaty.
Jeśli częścią twojej pracy jest przekuwanie tych pomiarów w wypuszczone oprogramowanie, może pomóc skrócenie pętli build–measure. Na przykład zespoły używają Koder.ai do prototypowania i ewolucji rzeczywistych aplikacji przez workflow oparty na czacie (web, backend, mobile), a potem ponownie uruchamiają te same benchmarki end‑to‑end po każdej zmianie. Funkcje takie jak tryb planowania, snapshoty i rollback wspierają tę samą dyscyplinę „mierz, potem projektuj”, którą promował Patterson — zastosowaną dziś do rozwoju produktu.
Dla głębszego wprowadzenia w efektywność zobacz: /blog/performance-per-watt-basics. Jeśli porównujesz środowiska i potrzebujesz prostego sposobu oszacowania kompromisów koszt/wydajność, zobacz: /pricing.
Trwały wniosek: idee — prostota, pomiar i co‑design — wciąż się opłacają, nawet gdy implementacje ewoluują od pipeline’ów ery MIPS do nowoczesnych, heterogenicznych rdzeni i nowych ISA jak RISC‑V.
Często zadawane pytania
Co w praktyce znaczy „RISC”, poza „mniejszą liczbą instrukcji”?
RISC (Reduced Instruction Set Computing) kładzie nacisk na mniejszy zestaw prostych, regularnych instrukcji, które łatwo poddać pipeline’owi i optymalizacjom. Celem nie jest „mniejsza funkcjonalność”, lecz bardziej przewidywalne i wydajne wykonywanie operacji, których programy używają najczęściej (ładowania/zapisy, operacje arytmetyczne, skoki).
Jaka jest różnica między RISC a CISC w prostych słowach?
CISC oferuje wiele złożonych, wyspecjalizowanych instrukcji, często łączących kilka kroków w jednym poleceniu. RISC używa prostszych bloków konstrukcyjnych (zwykle model load/store i operacje ALU) i polega na kompilatorach, aby efektywnie łączyć te bloki. W nowoczesnych CPU granica jest rozmyta, bo wiele układów CISC tłumaczy złożone instrukcje na prostsze wewnętrzne operacje.
Dlaczego „prostsze instrukcje” mogą sprawić, że CPU będą szybsze?
Prostsze, bardziej jednolite instrukcje ułatwiają zbudowanie płynnego pipeline’u (linie montażowej wykonania instrukcji). To może poprawić przepustowość (blisko jednej instrukcji na cykl) i zmniejszyć czas poświęcany na obsługę wyjątków, co zwykle pomaga zarówno wydajności, jak i zużyciu energii.
Jak kompilatory wpisują się w historię RISC?
Przewidywalny ISA i model wykonania pozwalają kompilatorom na:
- trzymać gorące zmienne w rejestrach,
- przestawiać instrukcje, aby unikać zatorów,
- jawnie obsługiwać dostęp do pamięci (load/store).
To zmniejsza puste cykle w pipeline’ie i marnotrawstwo pracy, poprawiając rzeczywistą wydajność bez dodawania skomplikowanego sprzętu, którego oprogramowanie by nie wykorzystało.
Czym jest hardware–software co-design?
Hardware–software co-design to iteracyjna pętla, w której wybory ISA, strategie kompilatora i wyniki pomiarów obciążeń wzajemnie się kształtują. Zamiast projektować CPU w izolacji, zespoły dostrajają sprzęt, toolchain i czasem OS/runtime razem, aby rzeczywiste programy działały szybciej i efektywniej.
Co powoduje zatrzymania pipeline’u i dlaczego to ważne?
Zatory (stalls) pojawiają się, gdy pipeline nie może iść dalej, bo coś jest opóźnione:
- Hazardy danych: instrukcja potrzebuje wartości, która jeszcze nie jest gotowa
- Latencja pamięci: dostęp nie trafia do pamięci podręcznej i trzeba czekać na DRAM
- Skoki: CPU jeszcze nie wie, którą ścieżką pójść
RISC‑owa przewidywalność pomaga zarówno sprzętowi, jak i kompilatorom ograniczać częstotliwość i koszt takich przerw.
Czym jest „memory wall” i jak cache’y się do tego odnoszą?
„Memory wall” to rosnąca przepaść między szybkim wykonywaniem instrukcji przez CPU a wolnym dostępem do pamięci głównej (DRAM). Cache (L1/L2/L3) łagodzi ten problem, wykorzystując lokalność:
- lokalność czasowa: niedawno użyte wartości będą użyte ponownie
- lokalność przestrzenna: dostęp do jednego adresu często poprzedza dostęp do sąsiednich
Niemniej jednak brak trafień do cache’u może nadal zdominować czas wykonywania, przez co programy stają się ograniczone przez pamięć, nawet na szybkich rdzeniach.
Co oznacza „performance per watt” i dlaczego jest dziś kluczowe?
To miara efektywności: ile użytecznej pracy wykonasz na jednostkę energii. W praktyce wpływa na żywotność baterii, temperaturę, hałas wentylatorów oraz koszty zasilania i chłodzenia w centrach danych. Projekty inspirowane myśleniem RISC często dążą do przewidywalnego wykonania i mniejszego marnotrawstwa przełączeń, co poprawia wydajność na wat.
Czy RISC „pokonał” CISC, czy to złe ujęcie?
Wielu projektów CISC zaadaptowało techniki podobne do RISC (pipeline, proste wewnętrzne mikro‑operacje, nacisk na cache i predykcję), zachowując zgodność z istniejącym ISA. Długofalowym „zwycięstwem” była zmiana podejścia: mierzyć realne obciążenia, optymalizować przypadki często występujące i dopasowywać sprzęt do zachowania oprogramowania — niezależnie od logo ISA.
Dlaczego RISC‑V często opisywany jest jako współczesna kontynuacja myślenia RISC?
RISC‑V to otwarty ISA z małą bazą i modułowymi rozszerzeniami, co sprzyja co-designowi: zespoły mogą dopasowywać funkcje sprzętowe do konkretnych potrzeb programowych i rozwijać toolchain publicznie. To nowoczesne przedłużenie podejścia „prosty rdzeń + solidne narzędzia + pomiary”. Zobacz też: /blog/what-is-risc-v.