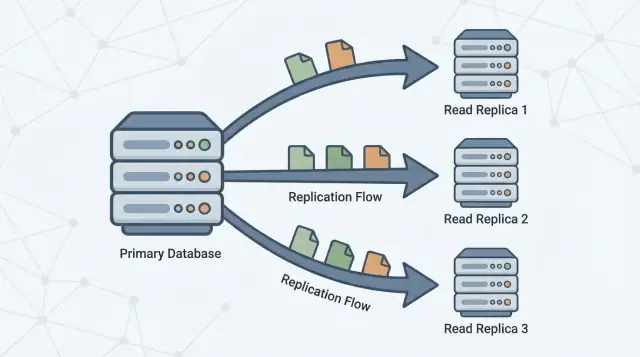
Czym jest replika odczytu (a czym nie jest)
Replika odczytu to kopia twojej głównej bazy danych (często nazywanej primary), która pozostaje aktualna, ciągle otrzymując zmiany z primary. Twoja aplikacja może wysyłać zapytania tylko do odczytu (np. SELECT) do repliki, podczas gdy primary nadal obsługuje wszystkie zapisy (np. INSERT, UPDATE, DELETE).
Podstawowa obietnica
Obietnica jest prosta: więcej mocy do odczytów bez zwiększania obciążenia primary.
Jeśli aplikacja ma dużo ruchu „pobierającego” — strony główne, strony produktów, profile użytkowników, dashboardy — przeniesienie części tych odczytów na jedną lub więcej replik może odciążyć primary, które może skupić się na pracy zapisu i krytycznych odczytach. W wielu konfiguracjach można to zrobić przy minimalnych zmianach w aplikacji: jedna baza pozostaje źródłem prawdy, a repliki dodajesz jako dodatkowe miejsca do wykonywania zapytań.
Czym replika nie jest
Repliki odczytu są przydatne, ale nie są magicznym przyciskiem wydajności. One nie:\n
- Zwiększają przepustowości zapisu. Wszystkie zapisy nadal trafiają na primary.\n- Naprawiają wolne zapytania. Jeśli zapytanie jest nieefektywne (brak indeksów, skanowanie dużych tabel, złe wzorce łączeń), będzie prawdopodobnie wolne także na replikach — tylko powolne gdzie indziej.\n- Zastępują dobrą strukturę danych i schemat. Repliki nie rozwiążą hot-spotów, zbyt dużych wierszy ani „tabeli wszystkiego”.\n- Eliminują konieczność monitorowania. Repliki dodają ruchome części: opóźnienie, limity połączeń i zachowania przy failover.
Ustawienie oczekiwań dla dalszej części przewodnika
Traktuj repliki jako narzędzie do skalowania odczytów z kompromisami. Reszta tego artykułu wyjaśnia, kiedy rzeczywiście pomagają, jak zwykle się nie sprawdzają oraz jak pojęcia takie jak opóźnienie replikacji i spójność ostateczna wpływają na to, co widzi użytkownik, gdy zaczynasz czytać z kopii zamiast z primary.
Po co istnieją repliki odczytu
Pojedynczy serwer bazy danych pełniący rolę primary często zaczyna jako „wystarczająco duży”. Obsługuje zapisy i odpowiada na wszystkie zapytania odczytowe (SELECT) z twojej aplikacji, dashboardów i narzędzi wewnętrznych.
Wraz ze wzrostem użycia, odczyty zwykle mnożą się szybciej niż zapisy: każde wyświetlenie strony może uruchomić kilka zapytań, ekrany wyszukiwania rozrastają się w wiele zapytań, a zapytania analityczne mogą skanować dużo wierszy. Nawet przy umiarkowanym wolumenie zapisów, primary nadal może stać się wąskim gardłem, bo musi wykonywać dwie role jednocześnie: przyjmować zmiany bezpiecznie i szybko oraz obsługiwać rosnący strumień odczytów przy niskich opóźnieniach.
Oddzielenie odczytów od zapisów
Repliki odczytu istnieją po to, by rozdzielić to obciążenie. Primary pozostaje skupione na przetwarzaniu zapisów i utrzymaniu „źródła prawdy”, podczas gdy jedna lub więcej replik obsługuje zapytania tylko do odczytu. Gdy aplikacja może kierować część zapytań do replik, zmniejszasz obciążenie CPU, pamięci i I/O na primary. To zwykle poprawia ogólną responsywność i zostawia więcej zasobów na nagłe skoki zapisów.
Replikacja w jednym zdaniu
Replikacja to mechanizm, który utrzymuje repliki aktualne, kopiując zmiany z primary na inne serwery. Primary zapisuje zmiany, a repliki je stosują, aby móc odpowiadać na zapytania używając prawie tych samych danych.
Wzorzec ten jest powszechny w wielu systemach bazodanowych i usługach zarządzanych (np. PostgreSQL, MySQL i ich chmurowe warianty). Dokładna implementacja może się różnić, ale cel jest ten sam: zwiększyć pojemność odczytów bez wiecznego skalowania primary w górę.
Jak działa replikacja (prosty model myślowy)
Wyobraź sobie primary jako „źródło prawdy”. Przyjmuje każdy zapis — tworzenie zamówień, aktualizację profili, rejestrację płatności — i nadaje tym zmianom ustalony porządek.
Jedna lub więcej replik następnie podąża za primary, kopiując te zmiany, aby móc odpowiadać na zapytania (np. „pokaż historię moich zamówień”) bez dodatkowego obciążenia primary.
Podstawowy przepływ
- Primary przyjmuje zapisy i zapisuje je w trwałym logu (nazwa zależy od bazy).
- Repliki strumieniują lub pobierają wpisy z logu z primary.
- Repliki odtwarzają te same zmiany w tej samej kolejności, stopniowo nadrabiając zaległości.
Odczyty mogą być obsługiwane z replik, ale zapisy nadal idą na primary.
Replikacja synchroniczna vs asynchroniczna (ogólnie)
Replikacja może działać w dwóch trybach:
- Synchroniczna: primary czeka, aż replika (lub quorum) potwierdzi otrzymanie zmiany, zanim uzna zapis za „zatwierdzony”. To zmniejsza ryzyko starych odczytów, ale może zwiększyć opóźnienia zapisu i uczynić zapisy wrażliwszymi na problemy sieciowe/replik.
- Asynchroniczna: primary zatwierdza zapis od razu, a repliki nadążają później. To utrzymuje szybkie zapisy i odporność, ale repliki mogą tymczasowo pozostawać w tyle.
Opóźnienie replikacji i „spójność ostateczna”
To opóźnienie — repliki będące w tyle za primary — nazywa się opóźnieniem replikacji. Nie jest to automatycznie błąd; to często normalny kompromis, który akceptujesz, aby skalować odczyty.
Dla użytkowników końcowych lag objawia się jako spójność ostateczna: po zmianie system stanie się spójny wszędzie, ale niekoniecznie natychmiast.
Przykład: aktualizujesz swój adres e‑mail i odświeżasz stronę profilu. Jeśli strona jest serwowana z repliki, która ma kilka sekund opóźnienia, możesz przez chwilę widzieć stary e‑mail — dopóki replika nie zastosuje zmian i nie „dogoni”.
Kiedy repliki odczytu rzeczywiście pomagają
Repliki pomagają, gdy primary jest zdrowe pod względem zapisów, ale jest przeciążone obsługą odczytów. Są najbardziej skuteczne, gdy możesz przenieść znaczący kawałek obciążenia SELECT bez zmieniania sposobu zapisu danych.
Objawy, że jesteś ograniczony odczytami (nie zapisami)
Szukaj wzorców takich jak:
- Wysokie CPU na primary podczas szczytów ruchu, przy normalnym przepływie zapisów
- Bardzo wysoki stosunek zapytań
SELECT do INSERT/UPDATE/DELETE
- Odczyty zwalniają w szczytach, choć zapisy pozostają stabilne
- Nasycenie puli połączeń spowodowane punktami końcowymi nastawionymi na odczyt (strony produktów, feedy, wyszukiwania)
Jak potwierdzić, że to odczyty są problemem (metryki do sprawdzenia)
Zanim dodasz repliki, zweryfikuj kilka sygnałów:
- CPU vs I/O: Czy primary ma CPU skrajnie obciążone, gdy rośnie opóźnienie odczytów? Czy to I/O dysku jest wąskim gardłem?
- Mieszanka zapytań: Odsetek czasu w
SELECT (z logu wolnych zapytań/APM).
- p95/p99 opóźnienia odczytów: Monitoruj oddzielnie opóźnienia endpointów odczytów i opóźnienia zapytań DB.
- Wskaźnik trafień w bufor/caches: Niski wskaźnik oznacza, że odczyty wymuszają dostęp do dysku.
- Top zapytań według łącznego czasu: Jedno kosztowne zapytanie może zdominować „obciążenie odczytami”.
Nie pomijaj tańszych rozwiązań
Często najlepszy pierwszy krok to dostrojenie: dodaj właściwy indeks, przebuduj zapytanie, ogranicz N+1 lub użyj cache’a dla gorących odczytów. Te zmiany bywają szybsze i tańsze w utrzymaniu niż operowanie replikami.
Krótka lista kontrolna: repliki vs optymalizacja
Wybierz repliki, gdy:
- Większość obciążenia to ruch odczytowy, a odczyty są już względnie zoptymalizowane
- Możesz tolerować okazjonalne przestarzałe odczyty dla zapytań przenoszonych na repliki
- Potrzebujesz dodatkowej pojemności szybko, bez ryzykownych zmian w schemacie/zapytaniach
Wybierz optymalizację najpierw, gdy:
- Kilka zapytań dominuje w czasie wykonywania
- Brakujące indeksy lub nieefektywne joiny są oczywiste
- Odczyty są wolne nawet przy niskim ruchu (znak problemów z zaprojektowaniem zapytań)
Najlepsze przypadki użycia
Repliki odczytu są najbardziej wartościowe, gdy primary jest zajęty obsługą zapisów (finalizacje zamówień, rejestracje, aktualizacje), a duża część ruchu to odczyty. W architekturze primary–replica puszczenie właściwych zapytań na repliki poprawia wydajność bazy bez zmieniania funkcji aplikacji.
1) Dashboardy i analityka, które nie powinny spowalniać transakcji
Dashboardy często uruchamiają długie zapytania: grupowania, filtrowania po dużych zakresach dat, łączenia wielu tabel. Te zapytania konkurują z pracą transakcyjną o CPU, pamięć i cache.
Dobra rola dla repliki:
- Obciążenia raportowe wewnętrzne
- Dashboardy administracyjne
- Widoki metryk dziennych/tygodniowych
Primary pozostaje skupione na szybkich, przewidywalnych transakcjach, a odczyty analityczne skalują się niezależnie.
2) Strony wyszukiwania i przeglądania z dużym wolumenem odczytów
Przegląd katalogu, profile użytkowników i feedy treści mogą generować duży wolumen podobnych zapytań. Gdy to odczyty są wąskim gardłem, repliki mogą przejąć ruch i zmniejszyć skoki opóźnień.
To jest szczególnie skuteczne, gdy odczyty często trafiają w cache‑miss (wiele unikalnych zapytań) lub gdy nie można polegać wyłącznie na cache’u aplikacyjnym.
3) Zadania tła skanujące dużą ilość danych
Exporty, backfille, przeliczanie podsumowań i „znajdź wszystkie rekordy pasujące do X” mogą obciążać primary. Uruchamianie takich skanów przeciwko replice jest często bezpieczniejsze.
Upewnij się tylko, że zadanie toleruje spójność ostateczną: przy opóźnieniu replikacji może nie widzieć najnowszych zmian.
4) Odczyty wieloregionalne dla niższego opóźnienia (z uwagami o staleness)
Jeśli obsługujesz użytkowników globalnie, umieszczenie replik bliżej nich może skrócić opóźnienia RTT. Kompromis to większe ryzyko starych odczytów podczas lagu lub problemów sieciowych, więc najlepiej dla stron, gdzie „prawie aktualne” jest akceptowalne (przeglądanie, rekomendacje, publiczne treści).
Gdzie repliki mogą zaszkodzić
Wprowadzaj zmiany z pewnością
Testuj migracje i rollbacki bez ryzyka, pracując nad kompromisami związanymi z replikacją.
Repliki odczytu są świetne, gdy „wystarczy blisko aktualne”. Zawiodą, gdy produkt zakłada, że każdy odczyt odzwierciedla najnowszy zapis.
Klasyczny objaw: „Właśnie to zaktualizowałem, dlaczego się nie zmieniło?”
Użytkownik edytuje profil, wysyła formularz lub zmienia ustawienia — a następne odświeżenie strony trafia do repliki, która ma kilka sekund opóźnienia. Zmiana się zapisała, ale użytkownik widzi stare dane, ponawia akcję, wysyła podwójnie lub traci zaufanie.
To jest szczególnie uciążliwe w przepływach, gdzie oczekuje się natychmiastowego potwierdzenia: zmiana e‑maila, przełączanie ustawień, wysłanie dokumentu, dodanie komentarza i przekierowanie z powrotem.
Ekrany, które muszą być aktualne (nie hazarduj tutaj)
Niektóre odczyty nie mogą być stale, nawet chwilowo:
- Koszyki i sumy przy finalizacji zamówienia
- Salda portfela, punkty lojalnościowe, stany magazynowe
- Ekrany „czy moja płatność przeszła?”
Jeśli replika jest w tyle, możesz wyświetlić błędny total koszyka, sprzedać produkt, którego nie ma, albo pokazać nieaktualne saldo. Nawet gdy system później się skoryguje, UX i liczba zgłoszeń do supportu ucierpią.
Narzędzia adminów i operacji potrzebują najświeższej prawdy
Dashboardy wewnętrzne często podejmują realne decyzje: przegląd oszustw, obsługa klienta, realizacja zamówień, moderacja, reakcja na incydenty. Jeśli narzędzie admina czyta z replik, ryzykujesz działanie na niekompletnych danych — np. refundowanie już zwróconego zamówienia albo brak zauważenia ostatniej zmiany statusu.
Praktyczne rozwiązanie: kierowanie „read-your-writes” na primary
Typowy wzorzec to warunkowe kierowanie ruchu:
- Po zapisie wysyłaj kolejne „potwierdzające” odczyty tego użytkownika na primary przez krótki okres (sekundy do minut).
- Trzymaj odczyty tła, anonimowe i niekrytyczne na replikach.
To zachowuje korzyści z replik bez zamiany spójności na ruletkę.
Zrozumienie opóźnienia replikacji i przestarzałych odczytów
Opóźnienie replikacji to czas pomiędzy zatwierdzeniem zapisu na primary a momentem, gdy ta zmiana staje się widoczna na replice. Jeśli aplikacja czyta z repliki w tym czasie, może zwrócić „przestarzałe” wyniki — dane, które chwilę wcześniej były prawdziwe, ale już nie są.
Dlaczego pojawia się lag
Lag jest normalny i zwykle rośnie pod obciążeniem. Typowe przyczyny:
- Skoki obciążenia na primary: dużo zapisów oznacza więcej zmian do przesłania i zastosowania.
- Replika zbyt słaba lub zajęta: nie nadąża z odtwarzaniem zmian (CPU, I/O dysku).
- Opóźnienia sieciowe lub jitter: opóźnienia w przesyłaniu strumienia replikacji.
- Duże transakcje / masowe aktualizacje: jedna duża zmiana może długo się serializować, przesyłać i odtwarzać.
Jak przestarzałe odczyty objawiają się w produkcie
Lag wpływa nie tylko na świeżość — wpływa na poprawność z punktu widzenia użytkownika:
- Użytkownik aktualizuje profil, a po odświeżeniu widzi starą wartość.
- Liczniki „nieprzeczytanych wiadomości” dryfują, bo obliczenia bazują na nieco starych wierszach.
- Ekrany raportowe/administracyjne pomijają najnowsze zamówienia, zwroty lub zmiany statusu.
Praktyczne sposoby radzenia sobie z tym
Zacznij od ustalenia, co funkcja może tolerować:
- Okno tolerancji: „Dane mogą być do 30 sekund przestarzałe” jest akceptowalne dla wielu dashboardów.
- Kierowanie read-after-write na primary: po zmianie user/session przypinaj je do primary na krótki TTL.
- Komunikacja w UI: ustaw oczekiwania („Aktualizacja...”, „Może pojawić się za kilka sekund”).
- Logika retry: jeśli krytyczny odczyt nie widzi właśnie zapisanego rekordu, spróbuj ponownie przeciwko primary lub po krótkim opóźnieniu.
Co monitorować i na co alertować
Śledź lag replik (czas/bajty za primary), szybkość stosowania zmian, błędy replikacji oraz CPU/dysk replik. Ustaw alert, gdy lag przekracza twoją tolerancję (np. 5s, 30s, 2m) i gdy lag rośnie w czasie (znak, że replika nie nadąży bez interwencji).
Skalowanie odczytów vs skalowanie zapisów (kluczowe kompromisy)
Szkielet bezpiecznej warstwy danych
Stwórz czystą warstwę dostępu do danych, którą później rozbudujesz o rozdzielanie odczytów i zapisów.
Repliki odczytu to narzędzie do skalowania odczytów: dodajesz więcej punktów obsługi SELECT. Nie są natomiast narzędziem do skalowania zapisów: zwiększania liczby INSERT/UPDATE/DELETE, które system może przyjąć.
Skalowanie odczytów: do czego repliki się nadają
Dodając repliki, zwiększasz pojemność odczytów. Jeśli aplikacja ma wąskie gardło w punktach odczytowych (strony produktu, feedy, lookupy), możesz rozłożyć zapytania na wiele maszyn.
To zwykle poprawia:
- Opóźnienia zapytań pod obciążeniem (mniej konkurencji na primary)
- Przepustowość odczytów (więcej CPU/pamięci/I/O dla
SELECT)
- Izolację ciężkich odczytów, tak by raporty nie przeszkadzały ruchowi transakcyjnemu
Skalowanie zapisów: czego repliki nie robią
Częsty mit: „więcej replik = większa przepustowość zapisów”. W standardowym układzie primary–replica wszystkie zapisy nadal idą na primary. Co więcej, więcej replik może nieco zwiększyć pracę primary, bo musi generować i wysyłać dane replikacyjne do każdej repliki.
Jeśli problemem jest przepustowość zapisów, repliki tego nie naprawią. Zwykle patrzysz wtedy na inne podejścia (dostrojenie zapytań/indeksów, batching, partycjonowanie/sharding, zmiana modelu danych).
Limity połączeń i pooling: ukryte wąskie gardło
Nawet jeśli repliki dostarczą więcej mocy CPU dla odczytów, możesz najpierw uderzyć w limity połączeń. Każdy węzeł DB ma maksymalną liczbę jednoczesnych połączeń, a dodanie replik może pomnożyć miejsca, z którymi aplikacja może się łączyć — bez zmniejszenia całkowitego zapotrzebowania.
Praktyczna zasada: używaj poolingu połączeń (lub poolera) i kontroluj liczbę połączeń per‑serwis. W przeciwnym razie repliki mogą stać się „kolejnymi bazami do przeciążenia”.
Opłaty: pojemność nie jest darmowa
Repliki dodają realne koszty:
- Więcej węzłów (koszty compute)
- Więcej przestrzeni (każda replika zwykle przechowuje pełną kopię)
- Więcej pracy operacyjnej (monitoring lag, backupy, migracje schematu, reakcja na incydenty)
Kompromis jest prosty: repliki kupują ci headroom odczytów i izolację, ale dodają złożoność i nie zwiększają sufitów zapisów.
Wysoka dostępność i failover: co mogą zrobić repliki
Repliki odczytu mogą poprawić dostępność odczytów: jeśli primary jest przeciążone lub chwilowo niedostępne, możesz wciąż obsługiwać część ruchu odczytowego z replik. To może utrzymać responsywność stron dla treści, które tolerują pewne opóźnienia i zmniejszyć obszar wpływu incydentu z primary.
To, czego repliki same w sobie nie dostarczają, to pełny plan wysokiej dostępności. Replika zwykle nie jest od razu gotowa do przyjmowania zapisów, a „istnieje czytelna kopia” różni się od „system może bezpiecznie i szybko przyjmować zapisy ponownie”.
Failover to zwykle: wykryj awarię primary → wybierz replikę → promuj ją na nowe primary → skieruj zapisy (i zazwyczaj odczyty) na promowany węzeł.
Niektóre zarządzane bazy automatyzują większość procesu, ale sedno pozostaje: zmieniasz, kto może przyjmować zapisy.
Kluczowe ryzyka do zaplanowania
- Dane replik mogą być przestarzałe: promując replikę możesz utracić najnowsze zapisy, które jeszcze nie zdążyły zreplikować.
- Unikanie split‑brain: trzeba zapobiec sytuacji, w której dwa węzły przyjmują zapisy jednocześnie. Dlatego promocje zwykle są kontrolowane przez pojedynczy autorytatywny mechanizm (panel zarządzania, quorum lub ścisłe procedury operacyjne).
- Trasowanie i cache: aplikacja potrzebuje niezawodnego sposobu zmiany celów — connection stringi, DNS, proxy albo router DB. Upewnij się, że ruch zapisu nie trafi „przypadkowo” do starego primary.
Testuj to jak funkcję
Traktuj failover jak coś, co trzeba ćwiczyć. Przeprowadzaj testy w stagingu (i ostrożnie w produkcji w oknach niskiego ryzyka): symuluj utratę primary, mierz czas przywrócenia, weryfikuj trasowanie i sprawdzaj, czy aplikacja radzi sobie z okresami tylko‑do‑odczytu i ponownymi połączeniami.
Praktyczne wzorce trasowania (rozdzielanie odczytów i zapisów)
Repliki pomagają tylko wtedy, gdy ruch faktycznie do nich trafia. „Read/write splitting” to zbiór reguł wysyłających zapisy na primary, a uprawnione odczyty na repliki — bez łamania poprawności danych.
Wzorzec 1: Rozdzielenie w aplikacji
Najprostsze podejście to explicite trasowanie w warstwie dostępu do danych:
- Wszystkie zapisy (
INSERT/UPDATE/DELETE, zmiany schematu) idą na primary.
- Tylko wybrane odczyty mogą korzystać z repliki.
To jest łatwe do zrozumienia i łatwe do wycofania. Możesz też tu zakodować reguły biznesowe typu „po zamówieniu zawsze czytaj status zamówienia z primary przez chwilę”.
Wzorzec 2: Rozdzielenie przez proxy lub driver
Niektóre zespoły wolą proxy DB lub inteligentny driver, który rozumie endpointy primary vs replica i trasuje na podstawie typu zapytania lub ustawień połączenia. To zmniejsza zmiany w kodzie aplikacji, ale uważaj: proxy nie zawsze wie, które odczyty są „bezpieczne” z punktu widzenia produktu.
Wybieranie zapytań bezpiecznych dla replik
Dobre kandydatury:
- Analityka, raporty, obciążenia reportingowe
- Strony wyszukiwania/przeglądania, gdzie dopuszczalna jest drobna stęchlizna danych
- Zadania tła, które retryują i nie potrzebują najnowszej wartości
Unikaj kierowania odczytów następujących bezpośrednio po zapisie (np. „aktualizuj profil → przeładuj profil”), jeśli nie masz strategii spójności.
Transakcje i spójność sesji
W obrębie transakcji trzymaj wszystkie odczyty na primary.
Poza transakcjami rozważ sesje „read‑your‑writes”: po zapisie przypinaj user/session do primary na krótki TTL albo kieruj konkretne zapytania follow‑up na primary.
Zacznij mało i mierź
Dodaj jedną replikę, kieruj ograniczoną grupę endpointów i porównaj przed i po:
- CPU primary i IOPS odczytów
- Wykorzystanie replik
- Błąd i percentyle opóźnień
- Incydenty związane z przestarzałymi odczytami
Rozszerz trasowanie tylko, gdy wpływ jest jasny i bezpieczny.
Monitorowanie i podstawy operacji
Zaplanuj architekturę gotową na repliki
Użyj Koder.ai, aby naszkicować plan architektury primary–replica zanim napiszesz linijkę backendowego kodu.
Repliki odczytu nie są „ustaw i zapomnij”. To dodatkowe serwery DB z własnymi limitami wydajności, trybami awarii i zadaniami operacyjnymi. Dyscyplina w monitoringu często rozróżnia „repliki pomogły” od „repliki dodały zamieszania”.
Co obserwować (kilka kluczowych metryk)
Skup się na wskaźnikach wyjaśniających symptomy widoczne dla użytkowników:
- Lag replik: jak bardzo replika jest w tyle (sekundy, bajty, pozycja WAL/LSN).
- Błędy replikacji: zerwane połączenia, problemy z auth, brak miejsca na dysku, problemy ze slotami replikacji.
- Opóźnienie zapytań (p50/p95) na replice vs primary: replika też może być wolna mimo zdrowego primary.
- Wskaźnik trafień cache: replika, która stale missuje, może mieć wyższe opóźnienia po restarcie lub przy przesunięciu ruchu.
Planowanie pojemności: ile replik potrzebujesz?
Zacznij od jednej repliki, jeśli celem jest odciążenie odczytów. Dodaj więcej, gdy masz wyraźne ograniczenie:
- Przepustowość odczytów: jedna replika nie zawsze wystarczy przy dużym QPS lub ciężkich zapytaniach analitycznych.
- Izolacja: dedykuj replikę do raportów, żeby dashboardy nie zabierały zasobów użytkownikom.
- Geografia: replika na region może skrócić opóźnienia, ale zwiększa overhead operacyjny.
Praktyczna zasada: skaluj repliki dopiero po potwierdzeniu, że to odczyty są wąskim gardłem (nie indeksy, wolne zapytania czy cache aplikacyjny).
Typowe zadania operacyjne
- Kopie zapasowe: zdecyduj, skąd robisz backupy. Robienie backupów z repliki może zmniejszyć obciążenie primary, ale sprawdź wymagania spójności i zdrowie repliki.
- Zmiany schematu: testuj migracje z replikacją w tle (długotrwałe DDL może zwiększyć lag). Koordynuj rollout tak, aby aplikacja i zmiany schematu były kompatybilne podczas propagacji.
- Okna konserwacji: patchowanie lub restart replik chwilowo redukuje pojemność odczytów. Planuj rotację, by nie spaść poniżej wymaganego headroom.
Lista kontroli przy rozwiązywaniu problemu: „repliki są wolne”
- Sprawdź lag replik: jeśli jest wysoki, użytkownicy mogą retryować lub widzieć stare dane.
- Porównaj logi wolnych zapytań na replice vs primary: często pokażą się zapytania raportowe.
- Zweryfikuj CPU, pamięć, I/O dysku i sieć na hoście repliki.
- Szukaj blokad lub długotrwałych transakcji na primary, które opóźniają replikację.
- Potwierdź, że twoje trasowanie odczytów nie przeciąża jednej repliki ( nierównomierne load balancing ).
- Zweryfikuj, że indeksy istnieją na replikach (powinny odzwierciedlać primary) i statystyki są aktualne.
Alternatywy i proste ramy decyzyjne
Repliki odczytu to jedno narzędzie do skalowania odczytów, ale rzadko pierwszy dźwignia do pociągnięcia. Zanim dodasz złożoność operacyjną, sprawdź, czy prostsze rozwiązanie da ten sam efekt.
Alternatywy do wypróbowania najpierw
Cache może usunąć całe klasy odczytów z bazy. Dla stron „read‑mostly” (szczegóły produktu, publiczne profile, konfiguracje) cache aplikacyjny lub CDN może dramatycznie obniżyć obciążenie — bez wprowadzania lagu replikacji.
Indeksy i optymalizacja zapytań często dają większy efekt niż repliki: dobrze dobrany indeks, ograniczenie kolumn w SELECT, eliminacja N+1 i naprawa złych joinów potrafią zmienić „musimy dodać repliki” w „wystarczy poprawić plan”.
Materialized views / pre‑aggregation pomagają, gdy obciążenie jest z natury ciężkie (analityka, dashboardy). Zamiast odtwarzać skomplikowane zapytania, przechowujesz obliczone wyniki i odświeżasz je zgodnie z harmonogramem.
Kiedy rozważyć sharding/partycjonowanie zamiast replik
Jeśli zapisy są wąskim gardłem (gorące wiersze, lock contention, limity I/O zapisu), repliki niewiele pomogą. Wtedy partycjonowanie tabel według czasu/klienta lub sharding po ID klienta może rozproszyć obciążenie zapisów i zmniejszyć kontencję. To większy krok architektoniczny, ale rozwiązuje prawdziwe ograniczenie.
Prosta rama decyzyjna
Zadaj cztery pytania:
- Jaki jest cel? Zmniejszyć opóźnienia odczytów, odciążyć raportowanie czy poprawić dostępność?
- Jak świeże muszą być odczyty? Jeśli nie możesz tolerować przestarzałych danych, repliki mogą wprowadzić problemy.
- Jaki budżet? Repliki dodają koszty infrastruktury i pracy operacyjnej.
- Ile złożoności możesz udźwignąć? Rozdzielenie odczytów i zapisów, obsługa spójności ostatecznej i testy failover to nienajmniejsze zadania.
Jeśli prototypujesz nowy produkt lub szybko uruchamiasz serwis, warto uwzględnić te ograniczenia już na etapie projektowania. Na przykład zespoły budujące na Koder.ai (platformie vibe‑coding, która generuje aplikacje React z backendem Go + PostgreSQL z interfejsu chatowego) często zaczynają od pojedynczego primary dla prostoty, a potem przechodzą do replik, gdy dashboardy, feedy lub raportowanie zaczynają konkurować z ruchem transakcyjnym. Przemyślane planowanie ułatwia wcześniejsze określenie, które endpointy mogą tolerować spójność ostateczną, a które muszą czytać „swoje zapisy” z primary.
Jeśli chcesz pomocy w wyborze ścieżki, zobacz stronę z cennikiem, albo przeglądaj powiązane poradniki w blogu.