Dlaczego niektóre aplikacje webowe wydają się wolne nawet na dobrych urządzeniach
Użytkownicy rzadko opisują wydajność w technicznych słowach. Mówią, że aplikacja jest ciężka. Strony potrzebują chwili, zanim cokolwiek pokażą, przyciski reagują z opóźnieniem, a proste akcje jak otwarcie menu, wpisywanie w polu wyszukiwania czy przełączanie zakładek przycinają.
Objawy są znane: wolne pierwsze ładowanie (pusty lub półzbudowany interfejs), opóźnione interakcje (kliki realizowane po krótkiej pauzie, drżące przewijanie) oraz długie spinnery po akcjach, które powinny być natychmiastowe — zapisywanie formularza czy filtrowanie listy.
Wiele z tego to koszt w czasie wykonania. Mówiąc prosto: to praca, którą przeglądarka musi wykonać po załadowaniu strony, by aplikacja stała się używalna: pobrać więcej JavaScriptu, sparsować go, uruchomić, zbudować UI, podpiąć handlery i dalej wykonywać dodatkową pracę przy każdej aktualizacji. Nawet na szybkich urządzeniach istnieje limit, ile JavaScriptu da się przepuścić przez przeglądarkę, zanim doświadczenie zacznie się pogarszać.
Problemy z wydajnością pojawiają się też późno. Na początku aplikacja jest mała: kilka ekranów, lekkie dane, prosty UI. Potem produkt rośnie. Marketing dodaje trackery, design wzbogaca komponenty, zespoły dokładją stan, funkcje, zależności i personalizację. Każda zmiana wydaje się niegroźna, ale suma pracy narasta.
Dlatego zespoły zaczynają zwracać uwagę na pomysły nastawione na kompilator. Cel zwykle nie jest idealny wynik w benchmarkach. Chodzi o to, by dalej wypuszczać funkcje bez tego, by aplikacja stawała się wolniejsza z miesiąca na miesiąc.
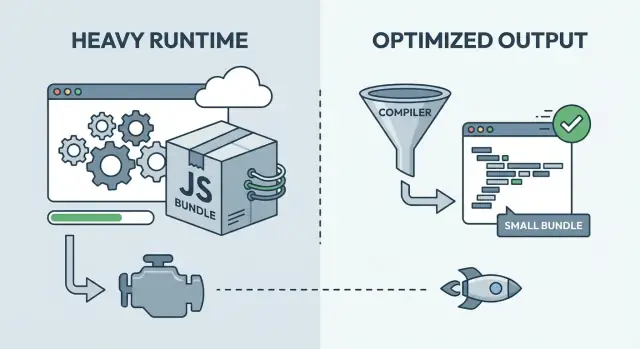
Runtime-heavy vs kompilacja: podstawowy pomysł
Większość frameworków frontendowych pomaga w dwóch rzeczach: zbudować aplikację i utrzymać UI w synchronizacji z danymi. Kluczowa różnica to moment, w którym dzieje się ta druga część.
W frameworku mocno obciążającym runtime więcej pracy odbywa się w przeglądarce po załadowaniu strony. Wysyłasz uniwersalny runtime, który radzi sobie z wieloma przypadkami: śledzeniem zmian, decydowaniem, co powinno się zaktualizować i stosowaniem tych aktualizacji. Ta elastyczność jest świetna dla rozwoju, ale często oznacza więcej JavaScriptu do pobrania, sparsowania i wykonania, zanim UI będzie gotowe.
Przy optymalizacji w czasie kompilacji, więcej tej pracy przenosi się do kroku budowania. Zamiast wysyłać do przeglądarki zestaw ogólnych reguł, narzędzie budujące analizuje komponenty i generuje bardziej bezpośredni, specyficzny dla aplikacji kod.
Użyteczny model mentalny:
- Runtime-heavy to jak wysyłanie instrukcji i skrzynki z narzędziami, a potem składanie w domu klienta.
- Compile-time to jak wysyłanie części już pociętych i opisanych, żeby składanie było szybsze.
Większość realnych produktów leży gdzieś pośrodku. Podejścia kompilatorowe nadal wysyłają trochę kodu runtime (routing, pobieranie danych, animacje, obsługa błędów). Frameworki nastawione na runtime także korzystają z technik build-time (minifikacja, code-splitting, renderowanie po stronie serwera), by zmniejszyć pracę po stronie klienta. Pytanie praktyczne nie brzmi, która grupa ma rację, lecz które połączenie pasuje do twojego produktu.
Rich Harris i dlaczego "framework to kompilator" ma znaczenie
Rich Harris jest jednym z najjaśniejszych głosów stojących za myśleniem kompilatorowym we frontendzie. Jego argument jest prosty: rób więcej z wyprzedzeniem, żeby użytkownicy pobierali mniej kodu, a przeglądarka wykonywała mniej pracy.
Motywacja jest praktyczna. Wiele frameworków obciążających runtime wysyła ogólny silnik: logikę komponentów, reaktywność, diffing, planowanie i pomocnicze narzędzia, które muszą działać dla każdej możliwej aplikacji. Ta elastyczność kosztuje bajty i CPU. Nawet gdy UI jest niewielkie, nadal płacisz za duży runtime.
Podejście kompilatorowe odwraca model. W czasie budowania kompilator sprawdza rzeczywiste komponenty i generuje konkretny kod aktualizacji DOM, którego potrzebują. Jeśli etykieta nigdy się nie zmienia, staje się zwykłym HTML-em. Jeśli zmienia się tylko jedna wartość, wygenerowana zostaje tylko ścieżka aktualizacji dla tej wartości. Zamiast wysyłać ogólny mechanizm UI, wysyłasz wynik dopasowany do twojego produktu.
To często prowadzi do prostego efektu: mniej kodu frameworka wysyłanego do użytkowników i mniej pracy wykonywanej przy każdej interakcji. Widać to szczególnie na urządzeniach słabszych, gdzie dodatkowy narzut runtime szybko staje się zauważalny.
Wciąż są kompromisy:
- Niektóre wzorce dynamiczne są trudniejsze, gdy kompilator nie potrafi ich przewidzieć z wyprzedzeniem.
- Jakość narzędzi ma większe znaczenie (szybkość budowania, debugowanie, source mapy).
- Konwencje w ekosystemie mogą się różnić, co wpływa na zatrudnianie i ponowne użycie.
- Nadal możesz potrzebować helperów runtime, tylko mniejszych i bardziej ukierunkowanych.
Praktyczna zasada: jeśli UI jest w dużej mierze poznawalne w czasie budowy, kompilator może wygenerować szczelny output. Jeśli UI jest wysoce dynamiczne lub oparte na wtyczkach, cięższy runtime może być wygodniejszy.
Co optymalizacja w czasie kompilacji poprawia w praktyce
Optymalizacja w czasie kompilacji przesuwa punkt podejmowania decyzji. Więcej rzeczy decyduje się podczas budowania, a mniej pracy zostawia się przeglądarce.
Jednym z widocznych efektów jest mniej wysyłanego JavaScriptu. Mniejsze paczki skracają czas sieci, parsowania i opóźnienie przed reakcją na tap lub klik. Na średniej klasy telefonach ma to większe znaczenie, niż wiele zespołów oczekuje.
Kompilatory mogą też generować bardziej bezpośrednie aktualizacje DOM. Gdy budowanie widzi strukturę komponentu, może wyprodukować kod, który dotyka tylko węzłów DOM, które naprawdę się zmieniły, bez tylu warstw abstrakcji przy każdej interakcji. To sprawia, że częste aktualizacje są bardziej responsywne, szczególnie w listach, tabelach i formularzach.
Analiza w czasie budowy może też wzmocnić tree-shaking i usuwanie martwego kodu. Zysk to nie tylko mniejsze pliki — to mniej ścieżek kodu, które przeglądarka musi pobrać i wykonać.
Hydratacja to kolejny obszar, gdzie decyzje build-time mogą pomóc. Hydratacja to krok, w którym strona wyrenderowana na serwerze staje się interaktywna przez dołączenie handlerów i odtworzenie stanu w przeglądarce. Jeśli build może oznaczyć, co potrzebuje interaktywności, można ograniczyć pracę przy pierwszym ładowaniu.
Jako efekt uboczny, kompilacja często poprawia zakresowanie CSS. Build może przepisać nazwy klas, usunąć nieużywane style i zmniejszyć przecieki stylów między komponentami. To obniża nieprzewidziane koszty wraz ze wzrostem UI.
Wyobraź sobie dashboard z filtrami i dużą tabelą danych. Podejście kompilatorowe może utrzymać lżejsze pierwsze ładowanie, aktualizować tylko zmienione komórki po kliknięciu filtra i unikać hydratacji części strony, które nigdy nie stają się interaktywne.
Gdzie frameworki runtime-heavy wciąż mają sens
Zaplanuj zanim się zaangażujesz
Zmapuj trasy, budżety i ograniczenia najpierw, a potem generuj tylko to, co potrzebne.
Większy runtime nie jest automatycznie zły. Często kupuje elastyczność: wzorce decydujące się w czasie wykonania, dużo komponentów od stron trzecich i sprawdzone przez lata workflowy.
Frameworki nastawione na runtime błyszczą, gdy reguły UI często się zmieniają. Jeśli potrzebujesz złożonego routingu, zagnieżdżonych layoutów, rozbudowanych formularzy i głębokiego modelu stanu, dojrzały runtime może działać jak siatka bezpieczeństwa.
Runtime płaci za wygodę
Runtime pomaga, gdy chcesz, by framework robił dużo podczas działania aplikacji, nie tylko przy budowaniu. To może przyspieszyć pracę zespołu na co dzień, nawet jeśli dodaje narzut.
Typowe korzyści: duży ekosystem, znane wzorce zarządzania stanem i pobierania danych, dobre narzędzia developerskie, łatwe rozszerzanie w stylu wtyczek i prostsze wdrażanie nowych osób do zespołu.
Znajomość zespołu to realny koszt i korzyść. Trochę wolniejszy framework, z którym zespół pewnie wypuszcza funkcje, może wygrać z szybszym podejściem wymagającym szkolenia, surowej dyscypliny lub niestandardowych narzędzi, żeby uniknąć pułapek.
Kiedy narzut runtime nie jest wąskim gardłem
Wiele skarg na „wolną aplikację” nie wynika z runtimeu frameworka. Jeśli strona czeka na wolne API, ciężkie obrazy, zbyt wiele fontów lub skrypty stron trzecich, zmiana frameworka nie rozwiąże głównego problemu.
Panel administracyjny wewnętrzny zwykle działa dobrze nawet z większym runtime, bo użytkownicy mają mocne urządzenia, a praca polega na tabelach, uprawnieniach i zapytaniach backendu.
„Dostatecznie szybkie” może być właściwym celem na początku. Jeśli wciąż weryfikujesz wartość produktu, utrzymuj szybkie tempo iteracji, ustal podstawowe budżety i podejmuj złożoność kompilatorową tylko wtedy, gdy masz dowody, że ma to znaczenie.
Wydajność kontra szybkość iteracji: prawdziwy kompromis w zespołach
Szybkość iteracji to czas do informacji zwrotnej: jak szybko ktoś może zmienić ekran, uruchomić go, zobaczyć, co się zepsuło, i naprawić. Zespoły, które utrzymują ten cykl krótko, wypuszczają częściej i szybciej się uczą. Dlatego frameworki runtime-heavy mogą wydawać się produktywne na początku: znane wzorce, szybkie rezultaty, dużo wbudowanego zachowania.
Praca nad wydajnością spowalnia ten cykl, kiedy jest wykonywana zbyt wcześnie lub zbyt szeroko. Jeśli każdy pull request staje się polemiką o mikrooptymalizacje, zespół przestaje podejmować ryzyko. Jeśli budujesz skomplikowany pipeline zanim poznasz produkt, ludzie walczą z narzędziami zamiast rozmawiać z użytkownikami.
Sztuka polega na zgodzeniu się, co oznacza „wystarczająco dobre” i iterowaniu w tym zakresie. Budżet wydajności daje taką ramę. Nie chodzi o pogoń za perfekcyjnymi wynikami, lecz o limity, które chronią doświadczenie, jednocześnie pozwalając rozwijać produkt.
Praktyczny budżet może obejmować:
- Strona staje się używalna w kilka sekund na średniej klasy telefonie.
- JavaScript na trasę pozostaje poniżej ustalonego limitu.
- Kluczowe interakcje (wyszukiwanie, dodanie do koszyka, zapis) odpowiadają szybko.
- Żadna pojedyncza funkcja nie może dodać więcej niż niewielką, stałą ilość JS lub CSS.
Jeśli ignorujesz wydajność, zwykle płacisz później. Gdy produkt rośnie, wolność zaczyna wynikać z decyzji architektonicznych, a nie tylko z małych poprawek. Późne przepisywanie może oznaczać zamrożenie funkcji, szkolenie zespołu i łamanie workflowów, które wcześniej działały.
Narzędzia kompilatorowe mogą przesunąć ten kompromis. Możesz zaakceptować nieco dłuższe budowania, ale redukujesz ilość pracy wykonywanej na każdym urządzeniu, przy każdej wizycie.
Przeglądaj budżety, gdy produkt się sprawdza. Na początku chroń podstawy. Gdy ruch i przychody rosną, zaostrzaj budżety i inwestuj tam, gdzie zmiany wpływają na realne metryki, nie na dumę.
Jak mierzyć wydajność, nie gubiąc się
Dyskusje o wydajności robią się chaotyczne, gdy nikt nie zgadza się, co znaczy „szybko”. Wybierz mały zestaw metryk, zapisz je i traktuj jak wspólną tablicę wyników.
Prosty zestaw startowy:
- Czas pierwszego używalnego ekranu
- Opóźnienie interakcji (jak długo dotknięcie/kliknięcie jest odczuwalnie zablokowane)
- Rozmiar pakietu (co przeglądarka musi pobrać i sparsować)
- Opóźnienie API (czas odpowiedzi backendu)
Mierz na reprezentatywnych urządzeniach, nie tylko na laptopie deweloperskim. Szybkie CPU, ciepła pamięć podręczna i serwer lokalny maskują opóźnienia widoczne na średnim telefonie przez przeciętny mobilny internet.
Trzymaj się przyziemnie: wybierz dwa lub trzy urządzenia odpowiadające twoim użytkownikom i wykonuj tę samą ścieżkę (ekran główny, logowanie, powszechne zadanie). Rób to konsekwentnie.
Zanim zmienisz framework, złap punkt odniesienia. Zrób pomiary dla dzisiejszego builda i zachowaj je jako zdjęcie „przed”.
Nie oceniaj wydajności po jednym wyniku labowym. Narzędzia laboratoryjne pomagają, ale mogą premiować niewłaściwe rzeczy (świetne pierwsze ładowanie), pomijając to, na co użytkownicy narzekają (przycinki w menu, wolne pisanie, opóźnienia po pierwszym ekranie).
Gdy liczby się pogarszają, nie zgaduj. Sprawdź, co zostało wdrożone, co blokowało renderowanie i gdzie poszedł czas: sieć, JavaScript czy backend.
Krok po kroku: ramy decyzyjne, które naprawdę możesz użyć
Obniż koszty eksperymentów
Dzielenie się nauką z budowy pozwala obniżyć koszty eksperymentów i zdobyć kredyty w programach Koder.ai.
Aby podjąć spokojną, powtarzalną decyzję, traktuj wybór frameworka i sposobu renderowania jak decyzję produktową. Celem nie jest najlepsza technologia, lecz właściwa równowaga między wydajnością a tempem, którego potrzebuje twój zespół.
- Zdefiniuj powierzchnie produktu. Oddziel strony marketingowe, dashboard zalogowany, mobile i narzędzia wewnętrzne. Każda powierzchnia ma innych użytkowników, urządzenia i oczekiwania.
- Ustal budżet wydajności. Wybierz 2–3 liczby, które będziesz chronić, np. pierwsze ładowanie na średnim telefonie i czas jednej kluczowej interakcji.
- Uszereguj ograniczenia. Bądź szczery, co teraz ma największe znaczenie: umiejętności zespołu, terminy, SEO, przepisy o prywatności danych i gdzie aplikacja musi działać.
- Wybierz podejście. Kompilator sprawdza się, gdy pierwsze ładowanie i szybkość interakcji są priorytetem. Runtime-first, gdy potrzebujesz maksymalnej elastyczności i szybkich iteracji. Hybryd często wygrywa: zachowaj powierzchnie wrażliwe na wydajność lekkie, a tam, gdzie interaktywność się opłaca, użyj cięższego runtime.
- Zweryfikuj cienki wycinek, potem utrwal wybór. Zbuduj jeden rzeczywisty flow użytkownika end-to-end, zmierz go względem budżetu i zapisz, co wybrałeś i dlaczego.
Cienki wycinek powinien zawierać najbrudniejsze części: prawdziwe dane, auth i najwolniejszy ekran.
Jeśli chcesz szybko prototypować taki wycinek, Koder.ai pozwala budować przepływy web, backend i mobilne przez czat, a następnie eksportować źródła. To pomaga przetestować prawdziwą trasę wcześnie i utrzymać eksperymenty odwracalnymi dzięki snapshotom i rollbackom.
Udokumentuj decyzję prostym językiem, włączając to, co sprawi, że ją zrewidujesz (wzrost ruchu, udział mobilny, cele SEO). To utrwala wybór przy zmianach w zespole.
Powszechne błędy zespołów przy wyborach dotyczących wydajności
Decyzje o wydajności zwykle się psują, gdy zespoły optymalizują to, co widzą dziś, a nie to, co użytkownicy odczują za trzy miesiące.
Jeden błąd to przesadna optymalizacja w pierwszym tygodniu. Zespół spędza dni na ścince milisekund na stronie, która wciąż zmienia się codziennie, podczas gdy prawdziwy problem to to, że użytkownicy jeszcze nie mają właściwych funkcji. Na początku przyspieszaj proces nauki. Głębszą optymalizację zamrażaj, gdy trasy i komponenty stabilizują się.
Inny błąd to ignorowanie wzrostu paczki aż do momentu, gdy zaczyna boleć. Wszystko wydaje się ok przy 200 KB, potem kilka „małych” dodatków i wysyłasz megabajty. Prosta praktyka: śledź rozmiar paczki w czasie i traktuj nagłe skoki jak bugi.
Zespoły też domyślnie wybierają renderowanie po stronie klienta dla wszystkiego, nawet gdy niektóre trasy są w dużej mierze statyczne (strony cenników, dokumentacja, kroki onboardingowe). Te strony można często dostarczyć przy mniejszym obciążeniu urządzenia.
Cichym zabójcą jest dodanie dużej biblioteki UI dla wygody bez zmierzenia jej kosztu w buildach produkcyjnych. Wygoda jest ważna — bądź jednak jasny, za co płacisz: dodatkowy JavaScript, CSS i wolniejsze interakcje na średnich telefonach.
Na koniec, mieszanie podejść bez jasnych granic tworzy aplikacje trudne do debugowania. Jeśli połowa aplikacji zakłada aktualizacje generowane przez kompilator, a druga połowa polega na runtimeowej magii, kończysz z niejasnymi zasadami i mylącymi awariami.
Kilka zasad, które sprawdzają się w realnych zespołach:
- Ustal budżet rozmiaru paczki na każdą główną trasę, nie tylko dla całej aplikacji.
- Zdecyduj, które trasy muszą być szybkie na pierwszym ładowaniu i projektuj renderowanie wokół tego.
- Dodawaj biblioteki dopiero po sprawdzeniu ich wagi w produkcji.
- Spisz granice (które części są zoptymalizowane kompilatorem, które polegają na runtime).
- Rewiduj decyzje po danych od użytkowników, nie wcześniej.
Realistyczny przykład: wysyłasz SaaS, nie zamykając się w kącie
Zbuduj cienki wycinek szybko
Zaprojektuj prototyp cienkiego wycinka przez czat i wcześnie zmierz rzeczywiste czasy ładowania i interakcji.
Wyobraź sobie 3-osobowy zespół tworzący SaaS do planowania i fakturowania. Ma dwie twarze: publiczny marketing (landing, cennik, dokumentacja) i uwierzytelniony dashboard (kalendarz, faktury, raporty, ustawienia).
Ścieżka runtime-first: wybierają setup oparty na dużym runtime, bo ułatwia szybkie zmiany UI. Dashboard staje się dużą aplikacją klient-side z wieloma komponentami, biblioteką stanu i bogatymi interakcjami. Iteracje są szybkie. Z czasem pierwsze ładowanie zaczyna być odczuwalnie ciężkie na średnich telefonach.
Ścieżka kompilatorowa: wybierają framework, który przenosi więcej pracy na czas budowy, by zmniejszyć JavaScript po stronie klienta. Częste przepływy jak otwieranie dashboardu, przełączanie zakładek i wyszukiwanie są bardziej responsywne. Kosztem jest większa ostrożność co do wzorców i narzędzi, a niektóre proste triki runtime nie są tak łatwe do wpięcia.
To, co wywołuje zmianę, rzadko jest estetyką. Zwykle presja narasta: wolniejsze strony obniżają konwersje, więcej użytkowników korzysta ze słabszych urządzeń, klienci enterprise pytają o przewidywalne budżety, dashboard jest ciągle otwarty i pamięć ma znaczenie, albo zgłoszenia supportu mówią o wolnym działaniu w realnych sieciach.
Hybryda często wygrywa. Zachowaj strony marketingowe lekkie (renderowane po stronie serwera lub w większości statyczne, minimalny kod klienta) i zaakceptuj większy runtime w dashboardzie tam, gdzie interaktywność ma sens.
Używając kroków decyzyjnych: nazywają kluczowe ścieżki (rejestracja, pierwsza faktura, cotygodniowe raporty), mierzą je na średnim telefonie, ustalają budżet i wybierają hybrydę. Domyślnie kompilator dla stron publicznych i współdzielonych komponentów, runtime-heavy tylko tam, gdzie ewidentnie przyspiesza eksperymentowanie.
Szybka lista kontrolna i następne kroki dla twojego produktu
Najłatwiej wdrożyć te pomysły krótkim, cotygodniowym cyklem.
Zacznij od 15-minutowego przeglądu: czy rozmiar paczki rośnie, które trasy wydają się powolne, jakie największe elementy UI są na tych trasach (tabele, wykresy, edytory, mapy) i które zależności najwięcej ważą. Potem wybierz jeden wąskie gardło, które naprawisz bez przepisywania całego stacku.
Na ten tydzień trzymaj to małe:
- Zmierz punkt odniesienia: zimne ładowanie najwolniejszej trasy i jedna powszechna akcja.
- Ustal jeden budżet pasujący do twojego produktu.
- Napraw jedno wąskie gardło (usuń zależność, rozdziel trasę, załaduj ciężki komponent asynchronicznie, ogranicz niepotrzebne rendery).
- Pomierz ponownie i zapisz, co się zmieniło.
Aby decyzje były odwracalne, wyznacz jasne granice między trasami i funkcjami. Preferuj moduły, które można później wymienić (wykresy, edytory tekstu, SDK analityczne) bez naruszania całej aplikacji.