Co budujesz i dla kogo to jest
Budujesz aplikację webową, która stoi między Twoim API a osobami, które z niego korzystają. Jej zadaniem jest wydawanie kluczy API, kontrolowanie, jak można je używać, oraz wyjaśnianie, co się wydarzyło — w sposób zrozumiały dla deweloperów i osób nietechnicznych.
Minimalnie odpowiada na trzy praktyczne pytania:
- Kto wywołuje API? (który klient, która aplikacja, który klucz)
- Ile mogą używać? (kwoty, rate limits, zasady planu)
- Ile faktycznie użyli? (rzetelne metryki i analityka)
Jeśli chcesz działać szybko nad portalem i UI administracyjnym, narzędzia takie jak Koder.ai mogą pomóc w szybkim prototypowaniu i wdrożeniu produkcyjnego baseline'u (frontend w React + backend w Go + PostgreSQL), przy jednoczesnym zachowaniu pełnej kontroli przez eksport kodu źródłowego, snapshoty/rollback i wdrożenie/hosting.
Kto z tego korzysta
Aplikacja do zarządzania kluczami nie jest tylko dla inżynierów. Różne role pojawiają się z różnymi celami:
- Administratorzy / właściciele platformy chcą tworzyć polityki (limity, poziomy dostępu), szybko rozwiązywać incydenty i utrzymywać kontrolę nad wieloma klientami.
- Deweloperzy (Twoi klienci lub zespoły wewnętrzne) chcą samodzielnie tworzyć klucze, mieć proste dokumentacje i szybkie odpowiedzi, gdy coś się psuje („Dlaczego dostaję 429?”).
- Finanse i wsparcie chcą historii użycia, podsumowań na poziomie klienta i danych wspierających faktury, kredyty lub aktualizacje planów — bez czytania surowych logów.
Moduły rdzeniowe, których prawdopodobnie potrzebujesz
Większość udanych implementacji zbiega się do kilku modułów:
- Klucze: tworzenie kluczy, nadawanie nazw/tagów, zakresy uprawnień, rotacja, unieważnianie i podgląd ostatniego użycia.
- Kwoty i rate limiting: definiowanie limitów na klucz, klienta, endpoint i ich konsekwentne egzekwowanie.
- Metering użycia: rejestrowanie zdarzeń żądań (lub podsumowań), a następnie agregowanie w dzienne/miesięczne użycie.
- Analityka: pulpity wyjaśniające trendy użycia, najważniejsze endpointy, błędy i throttling.
- Alerty: powiadamianie o skokach użycia, zbliżaniu się do limitów, nadużyciu kluczy lub wzroście błędów.
Zakres: zacznij prosto, potem rozwijaj
Silne MVP skupia się na wydawaniu kluczy + podstawowych limitach + czytelnym raportowaniu użycia. Zaawansowane funkcje — automatyczne aktualizacje planów, procesy fakturowania, proporcjonalne rozliczenia i skomplikowane warunki umów — mogą pojawić się później, gdy zaufasz metryce i egzekwowaniu.
Praktyczna „północna gwiazda” dla pierwszego wydania: ułatwić komuś stworzenie klucza, zrozumienie limitów i zobaczenie użycia bez konieczności zgłaszania do wsparcia.
Lista wymagań (MVP vs później)
Zanim zaczniesz pisać kod, zdecyduj, co oznacza „zrobione” na pierwsze wydanie. Ten typ systemu szybko się rozrasta: rozliczenia, audyty i bezpieczeństwo korporacyjne pojawiają się wcześniej, niż myślisz. Jasne MVP pozwala dalej wysyłać release'y.
MVP: minimum tworzące realną wartość
Przynajmniej użytkownicy powinni móc:
- Tworzyć i unieważniać klucze API (z nazwą/etykietą i opcjonalnym wygaśnięciem)
- Ustawiać kwoty (np. żądania/dzień lub żądania/miesiąc) na klucz lub projekt
- Egzekwować rate limiting (np. żądania/min) w celu ochrony API
- Widzć wykresy użycia (proste sumy dzienne, top kluczy i wskaźniki błędów)
- Śledzić podstawowe zdarzenia audytu (utworzenie/unieważnienie klucza, zmiana kwoty) dla wsparcia i odpowiedzialności
Jeśli nie możesz bezpiecznie wystawić klucza, go ograniczyć i udowodnić, co robił — nie jest gotowe.
Niefunkcjonalne potrzeby, o których powinieneś zdecydować wcześniej
- Wydajność: jaka jest maksymalna liczba żądań/s, które musisz zliczać bez utraty zdarzeń?
- Niezawodność: czy potrzebujesz „nigdy nie tracimy zdarzeń”, czy wystarczy „dokładność ostateczna”?
- Przechowywanie danych: jak długo trzymasz surowe zdarzenia vs zagregowane podsumowania (np. 7 dni surowych, 13 miesięcy agregatów)?
Model tenantów: pojedyncza organizacja vs multi-tenant
Wybierz wcześnie:
- Pojedyncza org: szybsze do zbudowania, mniej krawędzi związanych z rolami/uprawnieniami.
- Multi-tenant SaaS: wymaga izolacji tenantów, kwot per-tenant i ról administracyjnych od pierwszego dnia.
Funkcje „na później” warte zaplanowania
Rotacja, powiadomienia webhook, eksporty do rozliczeń, SSO/SAML, kwoty per-endpoint, wykrywanie anomalii i bardziej rozbudowane logi audytu.
Mierzalne wskaźniki sukcesu
- Czas do wydania kluczy: np. poniżej 2 minut od rejestracji do pierwszego klucza
- Dokładność metryk: np. <0.5% rozbieżności między liczeniem w gateway a agregatami
- Obciążenie wsparcia: mniej zgłoszeń „dlaczego zostałem zablokowany?”; jasne wyjaśnienia limitów i rate-limitów
Opcje architektury wysokiego poziomu
Wybór architektury zaczyna się od jednego pytania: gdzie egzekwujesz dostęp i limity? Ta decyzja wpływa na opóźnienia, niezawodność i szybkość wdrażania.
Opcja 1: Egzekwowanie w API gateway
API gateway (zarządzany lub self-hosted) może weryfikować klucze, stosować rate limiting i emitować zdarzenia użycia zanim żądania trafią do usług.
Dobrze pasuje, kiedy masz wiele backendów, potrzebujesz spójnych polityk lub chcesz trzymać egzekwowanie poza kodem aplikacji. Wada: konfiguracja gatewaya może stać się osobnym „produktem”, a debugowanie wymaga dobrego śledzenia.
Opcja 2: Egzekwowanie w reverse proxy
Reverse proxy (np. NGINX/Envoy) może obsłużyć sprawdzanie kluczy i rate limiting przez wtyczki lub zewnętrzne hooki auth.
Działa dobrze jako lekka warstwa brzegowa, ale trudniej w nim modelować reguły biznesowe (plany, kwoty per-tenant, wyjątki) bez wspierających usług.
Opcja 3: Egzekwowanie w middleware aplikacji
Umieszczenie kontroli w aplikacji API (middleware) jest zwykle najszybsze dla MVP: jedna baza kodu, jedno wdrożenie, prostsze lokalne testy.
Może stać się kłopotliwe przy dodawaniu kolejnych usług — dryft polityk i zduplikowana logika są powszechne — więc zaplanuj przyszłe wyodrębnienie do współdzielonego komponentu lub warstwy edge.
Wczesne oddzielenie odpowiedzialności
Nawet przy małym starcie, trzymaj granice:
- Auth (czy klucz jest ważny?), quota/rate limit (czy teraz jest dozwolone?), metering (zarejestruj, co się wydarzyło), UI analityki (pokaż to).
Śledzenie synchroniczne vs asynchroniczne
Dla meteringu zdecyduj, co musi dziać się w ścieżce żądania:
- Synchronicznie: inkrementuj liczniki przed odpowiedzią (dokładne egzekwowanie, większe opóźnienie).
- Asynchronicznie: emituj zdarzenia do kolejki/logu do agregacji (szybsze odpowiedzi, ostateczna spójność raportów).
Planuj skalowanie: ścieżki hot vs cold
Sprawdzanie limitów to hot path (optymalizuj pod niskie opóźnienia, pamięć podręczną/Redis). Raporty i pulpity to cold path (optymalizuj zapytania i agregacje wsadowe).
Model danych dla kluczy, limitów i użycia
Dobry model danych oddziela trzy zmartwienia: kto ma dostęp, jakie limity obowiązują, i co faktycznie się wydarzyło. Jeśli to dobrze zaprojektujesz, rotacja, pulpity i rozliczenia staną się prostsze.
Podstawowe encje (co potrzebne od dnia 1)
Minimum to modele/tablice (kolekcje):
- Organization: granica tenanta (właściciel rozliczeń, członkowie).
- Project/App: kontener dla kluczy i ustawień (często mapuje się do jednego klienta API).
- API Key: metadane o poświadczeniu (nazwa, status, created_at, last_used_at).
- Plan: pakiet limitów i funkcji (np. Free, Pro).
- Quota: konkretne reguły limitu (np. 10k żądań/dzień, 60 req/min).
- Usage Event: surowy zapis użycia (timestamp, project_id, endpoint, status code, units).
Nigdy nie zapisuj surowych tokenów. Przechowuj tylko:
- prefiks klucza (pierwsze 6–8 znaków) do wyświetlania/wyszukiwania.
- werifier dla tokena (zwykle SHA-256 lub HMAC-SHA-256 z pepperem po stronie serwera nad losowym 32–64 bajtowym sekretem) do weryfikacji.
- Opcjonalnie: scopes, środowisko (prod/sandbox) i expires_at.
To pozwala pokazać „Key: ab12cd…”, jednocześnie czyniąc sekret nieodwracalnym.
Audytowalność nie jest opcjonalna
Dodaj tabele audytu wcześnie: KeyAudit i AdminAudit (lub jedną AuditLog) zawierającą:
- actor_id (użytkownik/usługa), akcja, target_type/id
- before/after (dla edycji limitów)
- ip/user_agent, timestamp
Gdy klient zapyta „kto unieważnił mój klucz?”, będziesz mieć odpowiedź.
Okna czasowe i liczniki
Modeluj kwoty z jawnie określonymi oknami: per_minute, per_hour, per_day, per_month.
Przechowuj liczniki w osobnej tabeli jak UsageCounter kluczowanej przez (project_id, window_start, window_type, metric). To sprawia, że resetowanie jest przewidywalne i przyspiesza zapytania analityczne.
Dla widoków portalu możesz agregować Usage Events do dziennych rollupów i odwoływać się do /blog/usage-metering dla głębszych szczegółów.
Uwierzytelnianie, autoryzacja i role
Jeśli Twój produkt zarządza kluczami i użyciem, dostęp do samej aplikacji musi być bardziej restrykcyjny niż typowy dashboard CRUD. Jasny model ról utrzymuje produktywność zespołów i zapobiega „wszyscy są adminami”.
Projekt ról odpowiadający prawdziwym zespołom
Zacznij od małego zestawu ról per organizacja (tenant):
- Owner: pełna kontrola, odpowiedzialność za rozliczenia, może usuwać organizację.
- Admin: zarządza użytkownikami, projektami, kluczami, limitami i ustawieniami bezpieczeństwa.
- Developer: może tworzyć/rotować klucze dla przypisanych projektów, przeglądać użycie, ale nie może zmieniać rozliczeń ani ustawień organizacyjnych.
- Read-only: może przeglądać klucze (maskowane), kwoty i analitykę.
- Finance: może przeglądać faktury/raporty kosztów użycia i eksportować dane, ale nie zarządza kluczami.
Utrzymuj uprawnienia jawne (np. keys:rotate, quotas:update), aby dodawać funkcje bez wymyślania ról od nowa.
Bezpieczne logowanie dla ludzi
Używaj standardowego username/password tylko jeśli musisz; w przeciwnym razie wspieraj OAuth/OIDC. SSO jest opcjonalne, ale MFA powinno być wymagane dla ownerów/adminów i mocno zalecane dla wszystkich.
Dodaj ochronę sesji: krótkotrwałe tokeny dostępu, rotacja tokenów odświeżania i zarządzanie urządzeniami/sesjami.
Uwierzytelnianie dla chronionych API
Oferuj domyślnie klucz API w nagłówku (np. Authorization: Bearer <key> lub X-API-Key). Dla zaawansowanych klientów dodaj opcjonalne podpisy HMAC (zapobiegają replay/tamperingowi) lub JWT (dobre dla krótkotrwałego, scentralizowanego dostępu). Dokumentuj to wyraźnie w portalu deweloperskim.
Izolacja tenantów: bez kompromisów
Egzekwuj izolację przy każdym zapytaniu: org_id wszędzie. Unikaj polegania tylko na filtrowaniu UI — stosuj org_id w ograniczeniach bazy danych, politykach na poziomie wiersza (jeśli dostępne) i w kontrolerach serwisów, oraz pisz testy próbujące dostępu między tenantami.
Cykl życia klucza: tworzenie, rotacja, unieważnienie
Iteruj bez obaw
Eksperymentuj bez obaw ze schematem i logiką egzekwowania dzięki snapshotom i rollbackowi.
Dobry cykl życia klucza utrzymuje klientów produktywnymi i daje szybkie sposoby redukcji ryzyka, gdy coś pójdzie nie tak. Zaprojektuj UI i API tak, by „happy path” był oczywisty, a bezpieczne opcje (rotacja, wygasanie) domyślne.
Tworzenie: uchwyć intencję, nie tylko ciąg
W flow tworzenia klucza poproś o nazwę (np. „Prod server”, „Local dev”) oraz scopes/permissions, aby klucz miał zasadę najmniejszych uprawnień od początku.
Jeśli pasuje do produktu, dodaj opcjonalne ograniczenia jak dozwolone originy (dla użycia w przeglądarce) lub dozwolone IP/CIDR (dla komunikacji serwer-serwer). Trzymaj je opcjonalne i wyraźnie ostrzegaj o możliwości zablokowania dostępu.
Po utworzeniu pokaż surowy klucz tylko raz. Zapewnij duży przycisk „Kopiuj” i krótką wskazówkę: „Przechowaj w managerze sekretów. Nie możemy go pokazać ponownie.” Wskaż bezpośrednio instrukcje konfiguracji, np. /docs/auth.
Rotacja: uczyn ją rutyną, nie incydentem
Rotacja powinna mieć przewidywalny wzorzec:
- Utwórz nowy klucz z tymi samymi zakresami i ograniczeniami.
- Wdróż/aktualizuj integrację, by używała nowego klucza.
- Zweryfikuj, że ruch leci.
- Unieważnij stary klucz.
W UI zapewnij akcję „Rotate”, która tworzy zastępczy klucz i oznacza poprzedni jako „Pending revoke”, aby zachęcić do sprzątania.
Unieważnianie i wygasanie: natychmiastowe i zaplanowane
Unieważnienie powinno wyłączać klucz natychmiast i logować kto oraz dlaczego.
Obsługuj też planowane wygasanie (np. 30/60/90 dni) i ręczne daty „expires on” dla wykonawców tymczasowych lub triali. Klucze wygasłe powinny zwracać przewidywalny błąd autoryzacji, aby deweloperzy wiedzieli, co naprawić.
Kwoty i rate limiting: jak egzekwować użycie
Rate limiting i kwoty rozwiązują różne problemy; mieszanie ich powoduje wiele pytań „dlaczego zostałem zablokowany?”.
Rate limiting vs kwoty
Rate limiting kontroluje skoki (np. „nie więcej niż 50 żądań na sekundę”). Chroni infrastrukturę i zapobiega, by jeden hałaśliwy klient degradująca działanie innych.
Kwoty ograniczają całkowite zużycie w okresie (np. „100 000 żądań miesięcznie”). Dotyczą sprawiedliwości planu i granic rozliczeniowych.
Wiele produktów stosuje oba: miesięczna kwota dla planu i limit na sekundę/minutę dla stabilności.
Wybierz algorytm egzekwowania
Dla real-time rate limiting wybierz algorytm, który łatwo wyjaśnić i wdrożyć:
- Token bucket: tokeny uzupełniają się w czasie; każde żądanie zużywa token. Dobre dla dopuszczania małych skoków przy zachowaniu średniej prędkości.
- Leaky bucket: żądania „kapieją” stałym tempem. Dobre do wygładzania ruchu, ale może być odczuwalnie surowsze.
Token bucket jest zwykle lepszym domyślem dla API skierowanego do deweloperów, bo jest przewidywalny i wyrozumiały.
Wybierz, gdzie przechowywać liczniki
Zwykle potrzebujesz dwóch magazynów:
- Redis (lub podobny) dla szybkich, atomowych, real-time sprawdzeń na gatewayu/bramie.
- Baza danych dla trwałego raportowania i historii rozliczeniowej.
Redis odpowiada „czy to żądanie może zostać obsłużone teraz?”. DB odpowiada „ile użyli w tym miesiącu?”.
Zdefiniuj, co liczy się jako użycie
Bądź jednoznaczny dla produktu i endpointu. Popularne miary to żądania, tokeny, przesłane bajty, waga endpointu lub czas obliczeń.
Jeśli używasz ważonych endpointów, opublikuj wagi w dokumentacji i portalu.
Twórz czytelne odpowiedzi błędów
Blokując żądanie, zwracaj jasne, spójne komunikaty:
- 429 Too Many Requests dla rate limiting. Dołącz
Retry-After i opcjonalnie nagłówki jak X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset.
- 402 Payment Required (lub 403) dla dostępu ponad kwotę na płatnych planach. Dołącz aktualne użycie okresu, limit i informację o /plans lub /billing.
Dobre komunikaty zmniejszają churn: deweloperzy mogą odczekać, dodać retry lub podnieść plan bez zgadywania.
Metering użycia: zbieranie i agregowanie zdarzeń
Metering użycia jest „źródłem prawdy” dla kwot, faktur i zaufania klienta. Cel jest prosty: zliczać, co się wydarzyło, konsekwentnie, bez spowalniania API.
Co logować dla każdego żądania (a czego nie)
Dla każdego żądania uchwyć mały, przewidywalny payload zdarzenia:
- timestamp (czas serwera)
- key_id (lub identyfikator tokena)
- endpoint (nazwa route, nie pełny URL)
- status (np. 200, 401, 429)
- units (ile liczyć: 1 żądanie, tokeny, bajty itp.)
Unikaj logowania ciał request/response. Domyślnie redaguj wrażliwe nagłówki (Authorization, cookies) i traktuj PII jako „opcjonalne, z silną potrzebą”. Jeśli musisz coś logować dla debugowania, przechowuj to oddzielnie z krótszym retencjonowaniem i restrykcyjnym dostępem.
Utrzymuj API szybkie przez potok zdarzeń
Nie agreguj metryk inline podczas żądania. Zamiast tego:
- API zapisuje zdarzenie do kolejki/strumienia (lub lekkiej tabeli append-only).
- Worker konsumuje zdarzenia i aktualizuje rollupy dzienne/godzinne.
To zachowuje stabilne opóźnienia nawet przy skokach ruchu.
Idempotentność, retry i podwójne policzenie
Kolejki mogą dostarczać wiadomości wielokrotnie. Dodaj unikalne event_id i wymuś deduplikację (unikatowy constraint lub cache „seen” z TTL). Workery powinny być bezpieczne do ponawiania, by awaria nie zafałszowała sum.
Retencja: surowe krótkoterminowo, agregaty długoterminowo
Przechowuj surowe zdarzenia krótko (dni/tygodnie) do audytu i dochodzeń. Przechowuj zagregowane metryki znacznie dłużej (miesiące/lata) dla trendów, egzekwowania limitów i przygotowania do fakturowania.
Pulpity analityczne, z których ludzie będą korzystać
Uruchom środowisko produkcyjne
Wdróż i hostuj swój portal, a potem dodaj własną domenę, gdy będziesz gotowy.
Pulpit użycia nie powinien być „ładną stroną z wykresem”. Powinien szybko odpowiadać na dwa pytania: co się zmieniło? i co mam zrobić dalej? Projektuj wokół decyzji — debugowanie skoków, zapobieganie nadwyżkom i dowodzenie wartości klientowi.
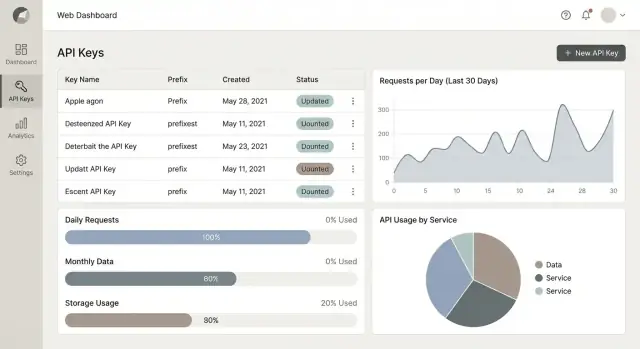
Podstawowe widoki do wypuszczenia najpierw
Zacznij od czterech paneli odpowiadających codziennym potrzebom:
- Użycie w czasie (żądania/dzień lub żądania/min), z porównaniem do poprzedniego okresu.
- Top endpointy (według wolumenu i kosztu/wagi, jeśli występuje ważenie).
- Wskaźnik błędów (4xx vs 5xx) by oddzielić błędy klienta od problemów serwisu.
- Latencja (opcjonalnie) p50/p95; dołącz tylko jeśli potrafisz to zmierzyć rzetelnie.
Uczyń to akcjonowalnym, nie dekoracyjnym
Każdy wykres powinien łączyć się z kolejnym krokiem. Pokaż:
- Pozostałą kwotę w bieżącym cyklu (np. 18 200 z 50 000)
- Prognozę użycia przy obecnym tempie, z prostym wskazaniem „przekroczy / pozostanie poniżej”
Gdy prawdopodobne jest przekroczenie, linkuj bezpośrednio do ścieżki aktualizacji planu: /plans.
Filtrowanie, które pasuje do pracy ludzi
Dodaj filtry, które zawężają śledztwa bez zmuszania użytkownika do budowania złożonych zapytań:
- Zakres czasu (ostatnie 24h, 7d, 30d, niestandardowy)
- Klucz API, projekt, środowisko (prod/staging)
- Endpoint i rodzina kodów statusu
Eksport i dostęp przez API
Dodaj CSV download dla finansów i wsparcia oraz lekkie API metryk (np. GET /api/metrics/usage?from=...&to=...&key_id=...) aby klienci mogli importować użycie do własnych narzędzi BI.
Alerty, powiadomienia i gotowość do rozliczeń
Alerty to różnica między „zauważyliśmy problem” a „klienci zauważyli pierwszy”. Projektuj je wokół pytań użytkowników pod presją: Co się stało? Kogo to dotyczy? Co mam zrobić dalej?
Na co alarmować (i kiedy)
Zacznij od progów związanych z kwotami. Prosty wzorzec, który działa, to 50% / 80% / 100% wykorzystania kwoty w okresie rozliczeniowym.
Dodaj kilka wysoce sygnałowych alarmów:
- Nienormalne skoki: użycie znacznie odbiegające od baseline tenantów (np. 3× średnia godzinowa)
- Błędy auth: nagły wzrost nieważnych kluczy lub błędów podpisu
- Presja rate-limitów: utrzymujące się zdarzenia throttlingu wskazujące na źle skonfigurowanego klienta
Utrzymuj alerty akcjonowalne: dołącz tenant, klucz/aplikację, grupę endpointów (jeśli dostępna), okno czasowe i odwołanie do odpowiedniego widoku w portalu (np. /dashboard/usage).
Kanały powiadomień
Email to baza — każdy ma. Dodaj webhooki dla zespołów, które chcą przekierować alerty do swoich systemów. Jeśli wspierasz Slack, traktuj to jako opcję i ułatw konfigurację.
Praktyczna zasada: dostarczaj politykę powiadomień per-tenant — kto dostaje które alerty i przy jakim priorytecie.
Proste raporty użycia, które ludzie czytają
Zaoferuj codzienne/tygodniowe podsumowanie z totalem żądań, top endpointami, błędami, throttlingiem i „zmianą vs poprzedni okres”. Interesariusze chcą trendów, nie surowych logów.
Gotowość do rozliczeń bez zobowiązań do fakturowania
Nawet jeśli fakturowanie jest „później”, zapisuj:
- Historię planów (który plan tenant miał i kiedy)
- Daty obowiązywania cen (by przeliczenia były spójne)
To pozwoli na odtworzenie faktur lub podglądów bez przepisywania modelu danych.
Szablon jasnej wiadomości
Każda wiadomość powinna mówić: co się stało, wpływ i następny krok (rotacja klucza, aktualizacja planu, zbadanie klienta lub kontakt z wsparciem na /support).
Podstawy bezpieczeństwa i zgodności
Szybko dodaj analitykę użycia
Generuj wykresy użycia, które odpowiadają na „co się zmieniło?” i „co dalej?”.
Bezpieczeństwo w aplikacji zarządzającej kluczami API mniej polega na wymyślnych funkcjach, a bardziej na rozsądnych domyślnych ustawieniach. Traktuj każdy klucz jako poświadczenie i zakładaj, że w końcu trafi w niewłaściwe miejsce.
Ochrona kluczy API
Nigdy nie przechowuj kluczy jawnie. Przechowuj werifier pochodzący od sekretu (zwykle SHA-256 lub HMAC-SHA-256 z pepperem po stronie serwera) i pokazuj użytkownikowi pełny sekret tylko raz w momencie tworzenia.
W UI i logach wyświetlaj tylko nieczuły prefiks (np. ak_live_9F3K…), aby można było zidentyfikować klucz bez ujawniania go.
Dostarczaj praktyczne wskazówki skanowania sekretów: przypominaj użytkownikom, by nie commitowali kluczy do Git i odnoś do narzędzi (np. GitHub secret scanning) w dokumentacji portalu pod /docs.
Ochrony adminów (często pomijane)
Atakujący lubią endpointy adminów, bo mogą tworzyć klucze, podnosić kwoty lub wyłączać limity. Nakładaj rate limiting również na API adminów i rozważ opcję allowlisty IP dla dostępu adminów (przydatne dla zespołów wewnętrznych).
Stosuj zasadę least privilege: rozdziel role (viewer vs admin) i ogranicz, kto może zmieniać kwoty lub rotować klucze.
Logi audytu i retencja
Rejestruj zdarzenia audytu dla tworzenia, rotacji, unieważniania kluczy, prób logowania i zmian limitów. Trzymaj logi w sposób niezmienny (append-only, ograniczony zapis i regularne kopie zapasowe).
Wdrażaj podstawy zgodności wcześnie: minimalizacja danych (przechowuj tylko to, co potrzebne), jasne zasady retencji (automatyczne usuwanie starych logów) i udokumentowane reguły dostępu.
Scenariusze zagrożeń do projektowania
Wycieki kluczy, replay attacky, skrobanie portalu oraz „głośni sąsiedzi” konsumujący współdzielone zasoby. Projektuj zabezpieczenia (hashing/werifiery, krótkotrwałe tokeny gdy to możliwe, rate limiting i kwoty per-tenant) wokół tych realiów.
UX dla panelu admina i portalu deweloperskiego
Świetny portal sprawia, że „bezpieczna ścieżka” jest najprostszą ścieżką: admini szybko zmniejszają ryzyko, a deweloperzy dostają działający klucz i testowe wywołanie bez pisania maili.
UX admina: szybkość, kontrola i pewność
Administratorzy zwykle przychodzą z pilnym zadaniem („unieważnij ten klucz teraz”, „kto to utworzył?”, „dlaczego skok użycia?”). Projektuj pod szybkie skanowanie i decyzje.
Użyj szybkiego wyszukiwania działającego na prefiksach kluczy, nazwach aplikacji, użytkownikach i nazwach workspace'ów. Sparuj to z czytelnymi wskaźnikami statusu (Active, Expired, Revoked, Compromised, Rotating) i znacznikami czasu jak „ostatnio użyty” i „utworzony przez”. Te dwa pola same w sobie zapobiegają wielu przypadkowym unieważnieniom.
Dla operacji masowych dodaj akcje zbiorcze z zabezpieczeniami: masowe unieważnianie, masowa rotacja, masowa zmiana tieru limitu. Zawsze pokazuj krok potwierdzenia z liczbą i podsumowaniem wpływu („38 kluczy zostanie unieważnionych; 12 użyto w ciągu ostatnich 24h”).
Zapewnij panel szczegółów klucza przyjazny audytowi: scopes, powiązana aplikacja, dozwolone IP (jeśli są), tier limitu i ostatnie błędy.
UX dewelopera: sukces natychmiastowy
Deweloperzy chcą skopiować, wkleić i iść dalej. Umieść czytelną dokumentację obok flow tworzenia klucza, nie ukrytą gdzieś indziej. Oferuj kopiowalne przykłady curl i przełącznik języka (curl, JS, Python) jeśli możesz.
Pokaż klucz raz z przyciskiem „kopiuj” i krótkim przypomnieniem o przechowywaniu. Następnie poprowadź przez krok „Test call”, który wykonuje prawdziwe żądanie do sandboxu lub niskiego ryzyka endpointu. Jeśli się nie powiedzie, podaj wyjaśnienia błędów prostym językiem i typowe naprawy:
- „Invalid key” → sprawdź nazwę nagłówka i spacje
- „Forbidden” → brakujący zakres/rola
- „Rate limited” → jak sprawdzić kwoty i
Retry-After
Samoobsługowe wdrożenie w minutach
Prosta ścieżka działa najlepiej: Utwórz pierwszy klucz → wykonaj testowe żądanie → zobacz użycie. Nawet malutki wykres użycia („Ostatnie 15 minut”) buduje zaufanie, że metryka działa.
Linkuj bezpośrednio do odpowiednich stron używając ścieżek względnych jak /docs, /keys i /usage.
Dostępność i przejrzystość
Używaj prostych etykiet („Żądania na minutę”, „Miesięczne żądania”) i trzymaj jednostki spójne na stronach. Dodaj dymki objaśnień dla terminów jak „scope” i „burst”. Zapewnij nawigację klawiaturą, widoczne stany focus oraz wystarczający kontrast — szczególnie dla badge'ów statusu i banerów błędów.
Wdrożenie, monitoring i testy
Wdrożenie takiego systemu to głównie dyscyplina: przewidywalne deploye, widoczność gdy coś się psuje i testy skupione na „hot pathach” (auth, sprawdzenia limitów, metering).
Konfiguracja wdrożenia (sekrety, zmienne środowiskowe, migracje)
Trzymaj konfigurację jawną. Przechowuj ustawienia nieczułe jako zmienne środowiskowe (np. domyślne rate-limit, nazwy kolejek, okna retencji) i trzymaj sekrety w zarządzanym magazynie sekretów (AWS Secrets Manager, GCP Secret Manager, Vault). Unikaj wbudowywania kluczy w obrazy.
Uruchamiaj migracje bazy jako krok pierwszorzędny w pipeline. Preferuj strategię „migrate then deploy” dla kompatybilnych zmian i planuj bezpieczne rollbacki (feature flags pomagają). W multi-tenantowych setupach dodaj sanity checks, aby zapobiec migracjom skanującym tabele wszystkich tenantów.
Jeśli budujesz system na Koder.ai, snapshoty i rollback mogą być praktyczną siatką bezpieczeństwa w wczesnych iteracjach (szczególnie przy dopracowywaniu logiki egzekwowania i schematu).
Obserwowalność odpowiadająca na realne pytania
Potrzebujesz trzech sygnałów: logów, metryk i śladów. Instrumentuj rate limiting i egzekwowanie limitów metrykami takimi jak:
- Zezwolone vs odrzucone żądania (wg klucza API, endpointu i tenant)
- „Kody powodu” odrzuceń (rate limit, quota exceeded, invalid key)
- Opóźnienie potoku meteringu (ingest zdarzeń → opóźnienie agregacji)
Stwórz pulpit specjalnie dla odrzuceń rate-limit, aby wsparcie mogło odpowiadać „dlaczego mój ruch nie przechodzi?” bez zgadywania. Tracing pomaga znaleźć wolne zależności na krytycznej ścieżce (zapytania DB o status klucza, cache misses itd.).
Kopie zapasowe i priorytety odzyskiwania
Traktuj dane konfiguracyjne (klucze, kwoty, role) jako wysokiego priorytetu, a zdarzenia użycia jako wysoką objętość. Często twórz kopie konfiguracji z możliwością point-in-time recovery.
Dla danych użycia skup się na trwałości i możliwości replay: write-ahead log/queue plus re-aggregacja często jest praktyczniejsza niż częste pełne backupy.
Testy i plan rolloutu
Testuj jednostkowo logikę limitów (przypadki brzegowe: granice okien, równoległe żądania, rotacja kluczy). Obciążeniowo testuj najgorętsze ścieżki: walidacja klucza + aktualizacje liczników.
Następnie wypuszczaj etapami: użytkownicy wewnętrzni → ograniczona beta (wybrani tenanci) → GA, z kill switchem do wyłączenia egzekwowania w razie potrzeby.