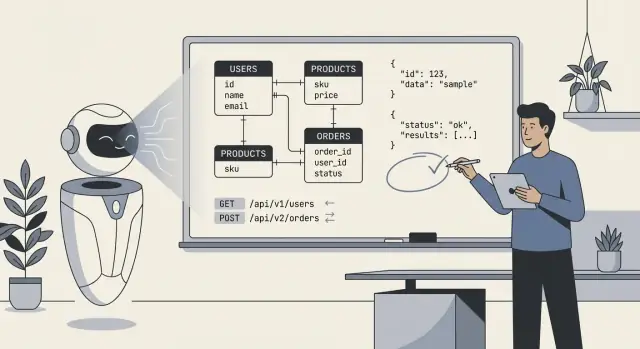
Co w praktyce znaczy „AI projektuje nasz backend”
Kiedy ludzie mówią „AI zaprojektowało nasz backend”, zwykle mają na myśli, że model wygenerował pierwszy szkic głównego technicznego planu: tabele bazy danych (lub kolekcje), jak te elementy się ze sobą łączą oraz API, które odczytują i zapisują dane. W praktyce to rzadziej „AI zbudowało wszystko”, a częściej „AI zaproponowało strukturę, którą możemy wdrożyć i dopracować”.
Co zazwyczaj zawiera backend zaprojektowany przez AI
Przynajmniej AI może wygenerować:
- Schematy i byty: tabele/kolekcje takie jak
users, orders, subscriptions, plus pola i podstawowe typy.
- Relacje: one-to-many i many-to-many (np. zamówienie ma wiele pozycji; produkt należy do wielu kategorii).
- Ograniczenia i walidacje: pola wymagane, klucze unikalne, proste zakresy, statusy typu enum oraz podstawowe reguły integralności referencyjnej.
- Powierzchnia API: endpointy CRUD, kształty żądań/odpowiedzi, wzorce paginacji, formaty błędów i czasem sugestie wersjonowania.
Czego nie zdecyduje bez kontekstu biznesowego
AI może wnioskować „typowe” wzorce, ale nie wybierze wiarygodnie właściwego modelu, gdy wymagania są niejednoznaczne lub specyficzne dla domeny. Nie będzie znać twoich realnych zasad dotyczących:
- Kto liczy się jako „użytkownik” (role? organizacje? konta gości?).
- Które pola są prawnie wymagane, wrażliwe lub objęte regułami retencji.
- Które akcje powinny być audytowalne, odwracalne lub wymagać zatwierdzenia.
- Prawdziwego znaczenia statusów (np.
cancelled vs refunded vs voided).
Właściwe oczekiwanie: copilota, nie ostateczny autorytet
Traktuj wynik AI jako szybki, ustrukturyzowany punkt wyjścia—przydatny do eksploracji opcji i wykrywania braków—ale nie jako specyfikację, którą można wdrożyć bez zmian. Twoim zadaniem jest dostarczyć jasne reguły i przypadki brzegowe, a następnie przejrzeć to, co AI wygenerowało, tak jakbyś przeglądał pierwszy szkic młodszego inżyniera: pomocny, czasem imponujący, okazjonalnie subtelnie błędny.
Wejścia, które decydują o jakości outputu AI
AI może szybko naszkicować schemat lub API, ale nie wymyśli brakujących faktów, które sprawiają, że backend „pasuje” do twojego produktu. Najlepsze rezultaty pojawiają się, gdy traktujesz AI jak szybkiego młodszego projektanta: dostarczasz jasne ograniczenia, a ono proponuje opcje.
Dane wejściowe, których AI naprawdę potrzebuje
Zanim poprosisz o tabele, endpointy lub modele, zapisz najważniejsze elementy:
- Główne byty i definicje: Jakie obiekty istnieją (np. User, Subscription, Order) i co każde z nich oznacza w twoim biznesie.
- Kluczowe przepływy: Główne ścieżki (rejestracja, checkout, zwroty, zatwierdzenia) i stany, przez które przechodzą.
- Role i uprawnienia: Kto może co robić (admin, personel, klient, audytor) i co trzeba ograniczyć.
- Potrzeby raportowe i analityczne: Pytania, na które musisz umieć odpowiedzieć później (miesięczne przychody, retencja kohortowa, metryki SLA), łącznie wymiary do grupowania.
- Integracje i zewnętrzne ID: Dostawcy płatności, CRMy, systemy tożsamości — oraz które ID należy przechowywać.
- Założenia dotyczące skali i wydajności: Przybliżony rząd wielkości (setki vs miliony rekordów) i oczekiwania dotyczące latencji.
- Zgodność i retencja: GDPR/CCPA, logi audytowe, zasady usuwania danych, lokalizacja danych, okresy przechowywania.
- Realia operacyjne: Backfille, importy, ręczne nadpisania i scenariusze „zespół wsparcia musi edytować X”.
Dlaczego niejasne wymagania tworzą kruche modele
Gdy wymagania są nieostre, AI ma tendencję do „zgadywania” domyślnych rozwiązań: pola opcjonalne wszędzie, ogólne kolumny statusu, niejasne własności i niespójne nazewnictwo. To często prowadzi do schematów, które wyglądają rozsądnie, ale zawodzą w realnym użyciu — zwłaszcza w obszarze uprawnień, raportowania i przypadków brzegowych (zwroty, anulowania, częściowe wysyłki, wieloetapowe zatwierdzenia). Potem zapłacisz za to migracjami, obejściami i mylącymi API.
Kopiowalny szablon wymagań
Użyj tego jako punktu wyjścia i wklejaj do promptu:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
Gdzie AI pomaga najbardziej: szybkość, spójność, pokrycie
AI sprawdza się najlepiej, gdy traktujesz je jak maszynę do szybkiego szkicowania: może naszkicować sensowny model danych i dopasowany zestaw endpointów w kilka minut. Ta szybkość zmienia sposób pracy — nie dlatego, że output jest magicznie „poprawny”, lecz dlatego, że natychmiast dostajesz coś konkretnego, na czym można iterować.
Szybkość: od pustej strony do działającego szkieletu
Największym zyskiem jest eliminacja zimnego startu. Podaj AI krótkie opisanie bytów, kluczowych przepływów i ograniczeń, a zaproponuje tabele/kolekcje, relacje i bazowy surface API. To szczególnie cenne, gdy potrzebujesz szybkiego demo lub eksplorujesz wymagania, które mogą się jeszcze zmienić.
Szybkość najbardziej opłaca się w:
- prototypach, gdzie trzeba szybko zweryfikować przepływ danych
- narzędziach wewnętrznych, gdzie „wystarczająco dobre” modelowanie ważniejsze niż perfekcja
- wczesnych iteracjach produktu, gdzie spodziewasz się przebudowy części rozwiązania
Spójność: nudne decyzje robione tak samo za każdym razem
Ludzie się męczą i odchodzą od konwencji. AI nie—więc świetnie powtarza konwencje w całym backendzie:
- spójne nazewnictwo (np.
createdAt, updatedAt, customerId)
- przewidywalne kształty endpointów (
/resources, /resources/:id) i payloadów
- standardowa paginacja i parametry filtrowania
Taka spójność ułatwia dokumentację, testowanie i przekazywanie backendu innemu deweloperowi.
Pokrycie: „czy zapomnieliśmy endpointu?”
AI dobrze radzi sobie z kompletnością. Jeśli poprosisz o pełen zestaw CRUD plus typowe operacje (wyszukiwanie, listowanie, masowe aktualizacje), zwykle wygeneruje bardziej kompleksowy surface niż pośpieszny szkic człowieka.
Szybki zysk to ustandaryzowane błędy: jednolita struktura błędu (code, message, details) we wszystkich endpointach. Nawet jeśli później ją zmienisz, posiadanie jednolitego kształtu od początku zapobiega mieszance ad-hoc odpowiedzi.
Kluczowa mentalność: pozwól AI wygenerować pierwsze 80% szybko, a czas poświęć na te 20% wymagające osądu—reguły biznesowe, przypadki brzegowe i „dlaczego” stojące za modelem.
Typowe tryby awarii w schematach generowanych przez AI
Schematy stworzone przez AI często wyglądają „czysto” na pierwszy rzut oka: uporządkowane tabele, sensowne nazwy i relacje pasujące do ścieżki szczęśliwego scenariusza. Problemy pojawiają się zwykle, gdy do systemu trafiają rzeczywiste dane, użytkownicy i przepływy.
Normalizacja: za dużo lub za mało
AI potrafi przechylać się w obie strony:
- Nadmierna normalizacja: rozdzielenie wszystkiego na wiele tabel (np. osobne tabele dla każdego atrybutu), co zwiększa liczbę joinów i utrudnia typowe zapytania.
- Niedostateczna normalizacja: upychanie powtarzających się pól w jednej tabeli (np. wiele kolumn adresowych, zdenormalizowane flagi statusu), co utrudnia walidację i aktualizację.
Szybki test: jeśli najczęściej odwiedzane strony potrzebują 6+ joinów, możesz być nadmiernie znormalizowany; jeśli aktualizacje wymagają zmiany tej samej wartości w wielu wierszach, możesz być niedostatecznie znormalizowany.
Brak przypadków brzegowych istotnych w produkcji
AI często pomija „nudne” wymagania, które kształtują realne projekty backendu:
- Multi-tenant: brak
tenant_id na tabelach lub brak egzekwowania zakresu tenantów w unique constraints.
- Soft deletes: dodanie
deleted_at, ale bez aktualizacji reguł unikalności lub wzorców zapytań, by wykluczały rekordy usunięte.
- Audytowanie: brak
created_by/updated_by, historii zmian lub niemutowalnych logów zdarzeń.
- Strefy czasowe: mieszanie
date i timestamp bez jasnej zasady (przechowywać UTC vs wyświetlać lokalnie), co prowadzi do błędów o jeden dzień.
Złe założenia o unikalności i cyklu życia
AI może założyć, że:
- pole jest globalnie unikalne, gdy powinno być unikalne per tenant (np.
invoice_number),
- pole jest wymagane, gdy w onboarding jest faktycznie opcjonalne,
- wystarczy jeden status, gdy w rzeczywistości potrzebne są stany cyklu życia (draft → active → suspended → archived).
Te błędy zwykle ujawniają się jako niezgrabne migracje i obejścia po stronie aplikacji.
Ślepe punkty wydajnościowe
Większość wygenerowanych schematów nie odzwierciedla sposobu zapytań:
- brak indeksów złożonych dla typowych filtrów (tenant_id + created_at),
- brak planu dla „gorących ścieżek” (najnowsze elementy, liczniki nieprzeczytanych),
- silne poleganie na polach JSON bez strategii indeksowania.
Jeśli model nie potrafi opisać 5 najważniejszych zapytań twojej aplikacji, nie zaprojektuje wiarygodnie schematu dla nich.
Projektowanie API: co AI robi dobrze, a co źle
AI często zaskakująco dobrze potrafi stworzyć API, które „wygląda standardowo”. Będzie odzwierciedlać wzorce znane z popularnych frameworków i publicznych API, co oszczędza czas. Ryzyko polega na tym, że może optymalizować pod kątem tego, co wydaje się prawdopodobne, zamiast tego, co jest poprawne dla twojego produktu, modelu danych i przyszłych zmian.
Co AI zwykle robi dobrze
Podstawy modelowania zasobów. Przy jasnej domenie AI wybierze sensowne rzeczowniki i struktury URL (np. /customers, /orders/{id}, /orders/{id}/items). Dobre jest też powielanie spójnych konwencji nazewnictwa.
Podstawowy szkic endpointów. AI często zawiera to, co niezbędne: listy vs szczegóły, create/update/delete oraz przewidywalne kształty żądań/odpowiedzi.
Konwencje bazowe. Jeśli poprosisz wyraźnie, może ustandaryzować paginację, filtrowanie i sortowanie. Na przykład: ?limit=50&cursor=... (paginacja kursorem) lub ?page=2&pageSize=25 (paginacja stronicowana), plus ?sort=-createdAt i filtry jak ?status=active.
Gdzie AI często się myli
Przeciekające abstrakcje. Klasyczny błąd to wystawianie wewnętrznych tabel bezpośrednio jako „zasobów”, szczególnie gdy schemat zawiera tabele łączące, zdenormalizowane pola lub kolumny audytu. Kończy się to endpointami typu /user_role_assignments, które odzwierciedlają szczegóły implementacyjne zamiast pojęcia użytkownika („role użytkownika”). To utrudnia użycie API i jego późniejsze zmiany.
Niespójne obsługi błędów. AI może mieszać style: czasem zwracać 200 z ciałem błędu, czasem używać kodów 4xx/5xx. Potrzebujesz jasnego kontraktu:
- Używaj odpowiednich kodów HTTP (
400, 401, 403, 404, 409, 422)
- Spójna koperta błędu (np. { "error": { "code": "...", "message": "...", "details": [...] } })
Wersjonowanie jako dodatek. Wiele projektów wygenerowanych przez AI pomija strategię wersjonowania dopóki nie zrobi się to bolesne. Zdecyduj od początku, czy używasz wersjonowania w ścieżce (/v1/...) czy w nagłówkach i zdefiniuj, co jest zmianą łamiącą. Nawet jeśli nigdy nie podniesiesz wersji, posiadanie reguł chroni przed przypadkowym złamaniem.
Zasada praktyczna
Używaj AI dla szybkości i spójności, ale traktuj projekt API jako interfejs produktowy. Jeśli endpoint odzwierciedla twoją bazę danych zamiast modelu mentalnego użytkownika, to znak, że AI zoptymalizowało pod łatwość generowania, a nie długoterminową użyteczność.
Praktyczny workflow, by używać AI bez utraty kontroli
Rozszerz poza backend
Generuj aplikacje webowe, serwerowe i mobilne z chatu, gdy backend będzie gotowy.
Traktuj AI jak szybkiego młodszego projektanta: świetne przy tworzeniu szkiców, ale nieodpowiedzialne za finalny system. Cel: wykorzystać jego szybkość, zachowując intencjonalną architekturę, przeglądalność i podejście oparte na testach.
Jeśli korzystasz z narzędzia vibe-coding takiego jak Koder.ai, to rozdzielenie odpowiedzialności jest jeszcze ważniejsze: platforma może szybko naszkicować i zaimplementować backend (np. serwisy w Go z PostgreSQL), ale nadal musisz zdefiniować inwarianty, granice autoryzacji i reguły migracji, z którymi jesteś w stanie żyć.
Powtarzalna pętla: prompt → szkic → przegląd → testy → poprawki
Zacznij od ścisłego promptu opisującego domenę, ograniczenia i „co oznacza sukces”. Poproś najpierw o model konceptualny (byty, relacje, inwarianty), nie o tabele.
Następnie iteruj w stałej pętli:
- Prompt: podaj wymagania, non-goals, założenia skalowania i reguły nazewnictwa.
- Szkic: poproś AI o model konceptualny + pierwszą wersję schematu + kontrakty API.
- Przegląd: sprawdź poprawność domenową, przypadki brzegowe i zgodność z decyzjami produktowymi.
- Testy: napisz lub wygeneruj testy, które zakodują decyzje (reguły walidacji, autoryzację, idempotencję, bezpieczeństwo migracji).
- Poprawki: przekaż AI, co nie przeszło (uwagi z przeglądu + nieudane testy) i poproś o poprawioną wersję.
Ta pętla działa, bo zamienia „propozycje AI” w artefakty, które można udowodnić lub odrzucić.
Oddziel model konceptualny od schematu fizycznego i kontraktów API
Zachowuj trzy warstwy oddzielnie:
- Model konceptualny: to, na czym zależy biznesowi (np. „Subskrypcja może być wstrzymana”, „Faktura musi odnosić się do okresu rozliczeniowego”).
- Schemat fizyczny: jak przechowujesz to w bazie (tabele/kolekcje, indeksy, ograniczenia, partycjonowanie).
- Kontrakty API: jak klienci wchodzą z tym w interakcję (zasoby, request/response, kody błędów, strategia wersjonowania).
Proś AI, by wypisało te sekcje osobno. Gdy coś się zmienia (np. nowy status lub reguła), najpierw aktualizujesz warstwę konceptualną, a dopiero potem godziszcze schemat i API. To zmniejsza przypadkowe sprzężenia i ułatwia refaktory.
Dokumentuj decyzje za pomocą krótkich notatek projektowych
Każda iteracja powinna zostawiać ślad. Stosuj krótkie podsumowania w stylu ADR (jedna strona lub mniej), które zawierają:
- Decyzję: co wybrano (np. „soft delete przez
deleted_at”).
- Racjonalizację: dlaczego (wymogi audytu, flow restore).
- Rozważane alternatywy: i dlaczego odrzucone.
- Konsekwencje: wpływ migracji, złożoność zapytań, zachowanie API.
Gdy wklejasz feedback z powrotem do AI, dołącz odpowiednie notatki decyzyjne dosłownie. To zapobiega „zapominaniu” wcześniejszych wyborów i pomaga zespołowi rozumieć backend miesiące później.
Promptowanie, które daje lepsze schematy i API
AI najłatwiej sprowokować, gdy traktujesz prompt jak zadanie pisania specyfikacji: definiuj domenę, podaj ograniczenia i żądaj konkretnych wyników (DDL, tabeli endpointów, przykłady). Celem nie jest „być kreatywnym”, tylko „być precyzyjnym”.
Prompty dla bytów i relacji (z ograniczeniami)
Poproś o model danych i reguły, które go utrzymują spójnym.
- „Zaprojektuj relacyjny schemat dla subskrypcji z bytami: User, Plan, Subscription, Invoice. Dołącz kardynalności, unikalne ograniczenia i strategię soft-delete. Reguły: jedna aktywna subskrypcja na użytkownika; faktury muszą referować niemutowalną cenę planu w momencie zakupu; walutę przechowuj jako kod ISO; znacznik czasu w UTC.”
Jeżeli masz już konwencje, powiedz o nich: styl nazewnictwa, typ ID (UUID vs bigint), polityka nullowalności i oczekiwania dotyczące indeksowania.
Prompty dla endpointów i kontraktów (z przykładami)
Żądaj tabelę API z wyraźnymi kontraktami, nie tylko listą tras.
- „Zaproponuj REST endpointy do zarządzania Subskrypcjami. Dla każdego endpointu: metoda, ścieżka, auth, query params, request JSON, response JSON, kody błędów i wytyczne idempotencji. Dołącz przykłady sukcesu i dwa przypadki błędne.”
Dodaj zachowanie biznesowe: styl paginacji, pola do sortowania i sposób filtrowania.
Prompty dla migracji i kompatybilności wstecznej
Zmusź model do myślenia w wydaniach.
- „Dodajemy
billing_address do Customer. Zapewnij bezpieczny plan migracji: SQL migracji w przód, kroki backfilla, rollout z feature-flagą i strategię rollbacku. API musi pozostać kompatybilne przez 30 dni; starsi klienci mogą pomijać pole.”
Antywzorce do unikania w promptach
Zbyt ogólne prompty dają nieostre systemy.
- „Zaprojektuj bazę dla aplikacji e-commerce” (za szerokie)
- „Zrób to skalowalnym i bezpiecznym” (brakuje mierzalnych wymagań)
- „Wygeneruj najlepszy schemat” (brak reguł domenowych)
- „Stwórz API dla wszystkiego” (brak priorytetyzacji)
Gdy chcesz lepszy rezultat, zawęż prompt: podaj reguły, przypadki brzegowe i format wyniku.
Lista kontrolna przeglądu przed wdrożeniem
Iteruj bez obaw
Eksperymentuj z migracjami i bezpiecznie wycofuj zmiany za pomocą snapshotów i rollbacku.
AI może naszkicować przyzwoity backend, ale bezpieczne wdrożenie wymaga ludzkiego sprawdzenia. Traktuj tę listę jako „bramę wydania”: jeśli nie możesz pewnie odpowiedzieć na punkt, wstrzymaj się i popraw zanim stanie się produkcyjnymi danymi.
Checklist schematu (tabele, kolekcje, kolumny)
- Klucze główne: Każda tabela ma jasny PK. Jeśli używasz UUID, potwierdź strategię generowania (DB vs aplikacja) i indeksowania.
- Klucze obce i ograniczenia: Dodaj FK tam, gdzie relacje są rzeczywiste. Zweryfikuj reguły ON DELETE/ON UPDATE (restrict vs cascade vs set null).
- Unikalność: Wymuszaj unikalność w bazie (nie tylko w kodzie): emaile, zewnętrzne ID, złożone ograniczenia (np.
(tenant_id, slug)).
- Nullowalność: Przejrzyj każde pole. Jeśli „nieznane” różni się od „pustego”, wymodeluj to explicite.
- Indeksy: Dodaj indeksy do częstych filtrów/sortów/joinów. Usuń przypadkowe indeksy na polach o niskiej kardynalności.
- Spójność nazewnictwa: Wybierz konwencje (liczba pojedyncza vs mnoga, sufiksy
_id, znaczniki czasu) i stosuj je konsekwentnie.
Decyzje dotyczące integralności danych (drogo zmienialne)
Zapisz zasady systemu na piśmie:
- Integralność referencyjna: Które relacje nigdy nie mogą zostać zerwane? Które mogą być „best-effort”?
- Reguły kaskady: Jeśli rodzic zostaje usunięty, czy dzieci powinny zostać usunięte, osierocone, czy operacja ma zostać zablokowana?
- Strategia soft delete: Jeśli używasz soft delete, upewnij się, że zapytania nie „wskrzeszą” usuniętych rekordów. Zdecyduj, czy unikalne ograniczenia ignorują miękko usunięte wiersze.
Checklist API (zachowanie i bezpieczeństwo)
- Autoryzacja i uprawnienia: Określ, kto może wywołać każdy endpoint i do czego ma dostęp (szczególnie w danych multi-tenant).
- Walidacja: Waliduj typy, zakresy, formaty i reguły międzypolowe. Nie polegaj na błędach bazy jako walidacji.
- Ograniczenia przepustowości i zabezpieczenia przed nadużyciami: Dodaj rozsądne domyślne limity, per user/token/IP gdzie właściwe.
- Idempotencja: Dla operacji tworzących/płatności wspieraj klucze idempotencji lub deterministyczne ID żądań.
- Spójne błędy: Ustandaryzuj kształt błędu i kody HTTP. Upewnij się, że komunikaty błędów nie wyciekają wrażliwych informacji.
Przed mergem, przeprowadź szybki przegląd: jedna poprawna prośba, jedna nieprawidłowa, jedna nieautoryzowana i jeden scenariusz dużego ruchu. Jeśli zachowanie API cię zaskakuje, zaskoczy też użytkowników.
Strategia testów dla backendów zaprojektowanych przez AI
AI może wygenerować wiarygodny schemat i surface API szybko, ale nie udowodni, że backend zachowuje się poprawnie pod realnym ruchem, z realnymi danymi i w przyszłych zmianach. Traktuj output AI jako szkic i zakotwicz go testami, które zamrażają zachowanie.
Testy kontraktowe dla API
Zacznij od testów kontraktowych, które walidują żądania, odpowiedzi i semantykę błędów — nie tylko „happy path”. Zbuduj mały zestaw uruchamiany przeciw realnej instancji (lub kontenerowi) serwisu.
Skup się na:
- Kodach statusu i ciałach błędów (np. 400 vs 404 vs 409)
- Przypadkach brzegowych walidacji (puste ciągi, za duże payloady, nieoczekiwane pola)
- Stabilności paginacji i sortowania (spójne porządkowanie, poprawność kursora)
- Idempotencji dla endpointów tworzących/operacji płatniczych (bezpieczne powtórzenia, klucze idempotencji, jeśli występują)
Jeśli publikujesz specyfikację OpenAPI, generuj z niej testy — ale dodaj też ręcznie przypadki dla trudnych obszarów, których spec nie odda (reguły autoryzacji, ograniczenia biznesowe).
Testy migracji i plany rollbacku
Schematy generowane przez AI często pomijają detale operacyjne: sensowne wartości domyślne, backfille i odwracalność. Dodaj testy migracji, które:
- stosują migracje na pustej DB i na „brudnej” starszej kopii
- weryfikują ograniczenia (unikalność, FK) po backfillu
- ćwiczą rollback (lub przynajmniej plan naprawczy) dla każdej migracji
Miej skryptowany plan rollbacku dla produkcji: co robić, jeśli migracja jest wolna, blokuje tabele lub łamie kompatybilność.
Testy obciążeniowe powiązane z realnymi wzorcami zapytań
Nie testuj generycznych endpointów. Zarejestruj reprezentatywne wzorce zapytań (top listy, wyszukiwania, joiny, agregacje) i obciąż je.
Mierz:
- p95/p99 latencji dla endpointów
- liczbę zapytań DB i wolne zapytania
- wykorzystanie indeksów (i brakujące indeksy)
Tu często zawodzi AI: „rozsądne” tabele produkują kosztowne joiny pod obciążeniem.
Podstawowe testy bezpieczeństwa
Dodaj automatyczne sprawdzenia dla:
- reguł AuthZ (użytkownik A nie ma dostępu do zasobów użytkownika B)
- wstrzyknięć (SQL/NoSQL, traversals, JSON injection)
- obsługi wrażliwych danych (brak sekretów w logach, prawidłowe maskowanie pól, szyfrowanie tam gdzie wymagane)
Nawet podstawowe testy bezpieczeństwa zapobiegają najkosztowniejszym błędom AI: endpointom, które działają, ale ujawniają za dużo.
Migracje, refaktory i długoterminowa utrzymywalność
AI może naszkicować dobry „wersja 0” schemat, ale backend żyje przez wersję 50. Różnica między systemem, który starzeje się dobrze, a takim, który się rozsypuje, to sposób ewolucji: migracje, kontrolowane refaktory i jasna dokumentacja intencji.
Bezpieczne ewoluowanie schematów wygenerowanych przez AI
Traktuj każdą zmianę schematu jak migrację, nawet jeśli AI sugeruje „po prostu alter table”. Stosuj wyraźne, odwracalne kroki: dodaj nowe kolumny najpierw, backfill, a dopiero potem zaostrzaj ograniczenia. Preferuj zmiany addytywne (nowe pola, nowe tabele) zamiast destrukcyjnych (rename/drop) dopóki nie udowodnisz, że nic nie zależy od starego kształtu.
Gdy prosisz AI o aktualizacje schematu, dołącz aktualny schemat i reguły migracji, których przestrzegasz (np. „nie usuwamy kolumn; używamy expand/contract”). Zmniejsza to ryzyko, że zaproponuje zmianę poprawną w teorii, ale ryzykowną w produkcji.
Zarządzanie breaking changes bez chaosu
Zmiany łamiące rzadko są jednorazowym wydarzeniem; to proces przejściowy.
- Deprecations: utrzymuj stare pola/endpointy działające, logując użycie.
- Dual-write: zapisuj zarówno do starej, jak i nowej struktury w oknie przejściowym.
- Backfills: uruchom zadania jednorazowe lub inkrementalne do wypełnienia nowych struktur.
AI może pomóc w tworzeniu planu krok po kroku (w tym fragmenty SQL i kolejność rolloutu), ale ty powinieneś zweryfikować wpływ w runtime: blokady, długotrwałe transakcje i czy backfill da się wznowić.
Refaktory danych bez przepisywania wszystkiego
Refaktory powinny izolować zmianę. Jeśli trzeba znormalizować, rozdzielić tabelę lub wprowadzić log zdarzeń, zachowaj warstwy kompatybilności: widoki, kod translacyjny lub tabele „cieniowe”. Poproś AI o propozycję refaktoru zachowującego istniejące kontrakty API i wypisującą, co musi się zmienić w zapytaniach, indeksach i ograniczeniach.
Dokumentuj założenia, aby przyszłe prompty były spójne
Większość długoterminowych rozbieżności pojawia się, gdy następny prompt zapomni pierwotny zamiar. Trzymaj krótką „umowę modelu danych”: zasady nazewnictwa, strategię ID, semantykę znaczników czasu, politykę soft-delete i inwarianty (np. „suma zamówienia jest wyprowadzana, nie przechowywana”). Umieszczaj ją w dokumentacji wewnętrznej i używaj w kolejnych promptach, aby system projektował w tych samych granicach.
Bezpieczeństwo i prywatność
Własna implementacja
Zachowaj pełną kontrolę, eksportując kod źródłowy gdy potrzebujesz dostosować implementację.
AI potrafi szybko naszkicować tabele i endpointy, ale nie „nosi” ryzyka. Traktuj bezpieczeństwo i prywatność jako wymagania pierwszej klasy, które dodajesz do promptu, a potem weryfikujesz w przeglądzie — szczególnie wokół danych wrażliwych.
Zacznij od klasyfikacji danych
Zanim zaakceptujesz schemat, oznacz pola według wrażliwości (publiczne, wewnętrzne, poufne, regulowane). Ta klasyfikacja powinna decydować, co trzeba szyfrować, maskować lub minimalizować.
Na przykład: hasła nigdy nie powinny być przechowywane w jawnej postaci (tylko zahashowane), tokeny krótkotrwałe i szyfrowane w spoczynku, a PII (email/telefon) może wymagać maskowania w widokach administracyjnych i eksportach. Jeśli pole nie jest niezbędne dla wartości produktu, nie przechowuj go—AI często doda „przydatne” atrybuty, które zwiększają powierzchnię ekspozycji.
Kontrola dostępu: RBAC vs ABAC
API generowane przez AI często domyślnie używa prostych „sprawdzeń ról”. RBAC jest łatwy do rozumienia, ale słabo radzi sobie z regułami własności („użytkownicy widzą tylko swoje faktury”) lub regułami kontekstowymi („support widzi dane tylko w aktywnym tickecie”). ABAC radzi sobie lepiej z tymi przypadkami, ale wymaga wyrażenia polityk.
Bądź jasny, którego wzorca używasz, i upewnij się, że każdy endpoint egzekwuje go konsekwentnie—zwłaszcza listy/wyszukiwania, które są częstymi punktami wycieków.
Zapobiegaj przypadkowemu logowaniu wrażliwych pól
Wygenerowany kod może logować całe ciała żądań, nagłówki lub wiersze DB podczas błędów. To może ujawnić hasła, tokeny autoryzacyjne i PII w logach i narzędziach APM.
Ustaw domyślnie: strukturalne logi, allowlistę pól do logowania, redagowanie sekretów (Authorization, cookies, reset tokens) i unikaj logowania surowych payloadów przy walidacji.
Prywatność, retencja i usuwanie
Projektuj możliwość usuwania od początku: usunięcia inicjowane przez użytkownika, zamknięcia konta i workflow „prawa do bycia zapomnianym”. Zdefiniuj okna retencyjne per klasę danych (np. zdarzenia audytowe vs zdarzenia marketingowe) i upewnij się, że potrafisz udowodnić, co i kiedy zostało usunięte.
Jeśli przechowujesz logi audytowe, trzymaj minimalne identyfikatory, zabezpieczaj je silniej i udokumentuj sposób eksportu lub usuwania danych na żądanie.
Kiedy używać AI (a kiedy nie)
AI sprawdza się najlepiej jako szybki młodszy architekt: świetne w tworzeniu pierwszego szkicu, słabsze w podejmowaniu decyzji krytycznych dla domeny. Pytanie brzmi nie „Czy AI może zaprojektować backend?”, ale „Które części AI może bezpiecznie naszkicować, a które wymagają eksperckiego nadzoru?”.
Dobre zastosowania: szkice, prototypy i dobrze znane wzorce
AI oszczędza czas, gdy budujesz:
- małe prototypy, narzędzia wewnętrzne i MVP, gdzie celem jest szybkie uczenie się,
- systemy CRUD z dobrze znanymi bytami (users, orders, subscriptions) i standardowymi ograniczeniami,
- momenty „pustej strony”: generowanie początkowego schematu, powierzchni API i konwencji nazewnictwa do iteracji.
Tutaj AI jest wartościowe dla szybkości, spójności i pokrycia—zwłaszcza gdy wiesz, jak produkt ma się zachowywać i potrafisz wychwycić błędy.
Złe zastosowania: regulowane, wysokiego ryzyka lub domenowo złożone systemy
Bądź ostrożny (lub traktuj AI jako inspirację) gdy pracujesz w:
- finansach: księgi, rozliczenia, ścieżki audytu i reguły idempotencji, które muszą być precyzyjne,
- opiece zdrowotnej: dane pacjentów, modele zgody, reguły retencji, interoperacyjność,
- domenach krytycznych dla bezpieczeństwa: gdzie „rozsądne założenie” może skończyć się incydentem.
W tych obszarach wiedza domenowa przewyższa szybkość AI. Subtelne wymagania—prawne, kliniczne, księgowe—często nie są obecne w promptach, a AI wypełni luki z przekonaniem.
Przewodnik decyzyjny: użyj AI do szkiców, wymagaj ludzkiego zatwierdzenia
Praktyczna zasada: pozwól AI proponować opcje, ale wymagalny jest finalny przegląd inwariantów modelu danych, granic autoryzacji i strategii migracji. Jeśli nie potrafisz wskazać osoby odpowiedzialnej za schemat i kontrakty API, nie wdrażaj backendu zaprojektowanego przez AI.
Następne kroki
Jeśli oceniasz workflowy i zabezpieczenia, zacznij od wewnętrznych przewodników i standardów. Jeśli chcesz pomocy we wdrożeniu tych praktyk w zespole, rozważ współpracę z dostawcami narzędzi lub konsultantami.
Jeśli wolisz end-to-end workflow, w którym iterujesz przez chat, generujesz działającą aplikację i nadal zachowujesz kontrolę przez eksport kodu i snapshoty rollbacku, Koder.ai jest zaprojektowane z myślą o takim stylu budowy i przeglądu.