18 maj 2025·8 min
Projekt schematu najpierw: szybsze aplikacje zamiast wczesnego strojenia zapytań
Wczesne zyski wydajności zwykle wynikają z lepszego projektu schematu: właściwe tabele, klucze i ograniczenia zapobiegają wolnym zapytaniom i kosztownym przepisywaniom później.
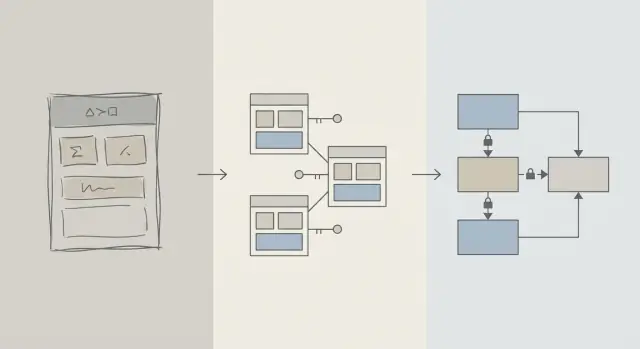
Schemat a optymalizacja zapytań: co mamy na myśli
Gdy aplikacja działa wolno, pierwszym odruchem jest często „naprawić SQL”. Ten impuls ma sens: pojedyncze zapytanie jest widoczne, mierzalne i łatwo je obwinić. Możesz uruchomić EXPLAIN, dodać indeks, poprawić JOIN i czasem od razu zobaczyć poprawę.
Ale we wczesnej fazie produktu problemy ze szybkością równie dobrze mogą wynikać ze sposobu organizacji danych, co z konkretnego tekstu zapytania. Jeśli schemat zmusza cię do walki z bazą, strojenie zapytań zamienia się w grę w „bicie mole’a”.
Projekt schematu (po ludzku)
Projekt schematu to sposób, w jaki organizujesz dane: tabele, kolumny, relacje i zasady. Obejmuje decyzje takie jak:
- Jakie „rzeczy” zasługują na własną tabelę (users, orders, events)
- Jak tabele się ze sobą łączą (one-to-many, many-to-many)
- Co musi być unikalne lub wymagane (ograniczenia)
- Jak reprezentujesz stany i historię (timestamps, pola statusu, rekordy audytu)
Dobry projekt schematu sprawia, że naturalny sposób zadawania pytań jest też szybkim sposobem.
Optymalizacja zapytań (po ludzku)
Optymalizacja zapytań to usprawnianie sposobu pobierania lub aktualizowania danych: przepisywanie zapytań, dodawanie indeksów, redukowanie zbędnej pracy i unikanie wzorców powodujących pełne skany.
Oba są ważne — liczy się kolejność
Ten artykuł nie głosi „schemat dobry, zapytania złe”. Chodzi o porządek działań: najpierw ustaw fundamenty schematu bazy, potem stroj zapytań, które naprawdę tego potrzebują.
Dowiesz się, dlaczego decyzje schematu dominują nad wydajnością we wczesnej fazie, jak rozpoznać, kiedy to naprawdę schemat jest wąskim gardłem, oraz jak bezpiecznie ewoluować schemat w miarę wzrostu aplikacji. To napisane dla zespołów produktowych, założycieli i developerów budujących aplikacje rzeczywiste — nie dla specjalistów od baz danych.
Dlaczego projekt schematu napędza większość wczesnej wydajności
We wczesnej fazie wydajność rzadko zależy od sprytnego SQL — częściej od tego, ile danych baza jest zmuszona przetworzyć.
Struktura decyduje, ile skanujesz
Zapytanie może być tak selektywne, jak pozwala model danych. Jeśli przechowujesz „status”, „type” lub „owner” w luźno ustrukturyzowanych polach (lub rozrzucasz je po niespójnych tabelach), baza często musi przeskanować znacznie więcej wierszy, żeby znaleźć dopasowania.
Dobry schemat naturalnie zawęża przestrzeń wyszukiwania: klarowne kolumny, spójne typy danych i sensownie wydzielone tabele sprawiają, że zapytania filtrują wcześniej i czytają mniej stron z dysku lub pamięci.
Brak kluczy generuje kosztowną pracę
Gdy brakuje kluczy głównych i obcych (albo nie są egzekwowane), relacje stają się domysłami. To przerzuca pracę na warstwę zapytań:
- JOINy stają się większe, bo nie ma niezawodnej, indeksowanej ścieżki do łączenia.
- Filtry komplikują się, bo kompensujesz duplikaty, null-e i „prawie pasujące” wartości.
Bez ograniczeń złe dane się kumulują — więc zapytania stają się coraz wolniejsze w miarę rośnięcia liczby wierszy.
Indeksy podążają za schematem (i nie naprawią wszystkiego)
Indeksy są najbardziej przydatne, gdy pasują do przewidywalnych ścieżek dostępu: łączenia po kluczach obcych, filtrowanie po dobrze zdefiniowanych kolumnach, sortowanie po popularnych polach. Jeśli schemat przechowuje kluczowe atrybuty w niewłaściwej tabeli, miesza znaczenia w jednej kolumnie lub polega na parsowaniu tekstu, indeksy cię nie uratują — nadal będziesz skanować i przekształcać zbyt dużo.
Szybko domyślnie
Przy czystych relacjach, stabilnych identyfikatorach i rozsądnych granicach tabel wiele codziennych zapytań staje się „szybkimi domyślnie”, ponieważ dotykają mniej danych i używają prostych, przyjaznych indeksom predykatów. Strojenie zapytań staje się wtedy krokiem wykończeniowym — a nie stałą akcją gaśniczą.
Rzeczywistość wczesnego etapu: zmiany są stałe
Produkty we wczesnej fazie nie mają „stabilnych wymagań” — mają eksperymenty. Funkcje wypuszczane są, przepisywane albo znikają. Mały zespół żongluje presją roadmapy, wsparciem i infrastrukturą, mając ograniczony czas na poprawianie starych decyzji.
Co zmienia się najczęściej
Rzadko najpierw zmienia się tekst SQL. Zmienia się znaczenie danych: nowe stany, nowe relacje, pola typu „o, trzeba jeszcze śledzić…”, całe przepływy, których nie przewidziano przy starcie. Taka zmienność jest normalna — i to właśnie dlatego wybory schematu mają tak duże znaczenie we wczesnej fazie.
Dlaczego poprawianie schematu później jest trudniejsze niż poprawianie zapytania
Przepisywanie zapytania zwykle jest odwracalne i lokalne: możesz wypuścić poprawkę, zmierzyć efekt i wycofać, jeśli trzeba.
Przepisywanie schematu to inna para kaloszy. Gdy przechowujesz realne dane klientów, każda zmiana strukturalna staje się projektem:
- Migracje blokujące tabele lub spowalniające zapisy w godzinach szczytu
- Backfille w celu wypełnienia nowych kolumn lub przebudowy pochodnych danych
- Dual-write lub tabele cieniowe, żeby aplikacja działała podczas przejścia
- Ryzyko przestojów, jeśli zmiany nie da się przeprowadzić online
Nawet przy dobrych narzędziach zmiany schematu wprowadzają koszty koordynacji: aktualizacje kodu aplikacji, sekwencjonowanie wdrożeń i walidację danych.
Jak wczesne decyzje się kumulują
Gdy baza jest mała, niezgrabny schemat może wydawać się „w porządku”. W miarę jak liczba wierszy rośnie z tysięcy do milionów, ten sam projekt powoduje większe skany, cięższe indeksy i droższe joiny — a każda nowa funkcja budowana jest na tym fundamencie.
Celem we wczesnej fazie nie jest perfekcja. Chodzi o wybór schematu, który może wchłaniać zmiany bez wymuszania ryzykownych migracji za każdym razem, gdy produkt czegoś się nauczy.
Podstawy projektowania, które zapobiegają wolnym zapytaniom
Większość problemów z "wolnymi zapytaniami" na początku nie wynika z trików SQL — wynika z niejednoznaczności w modelu danych. Jeśli schemat utrudnia zrozumienie, co reprezentuje rekord, lub jak rekordy się odnoszą, każde zapytanie staje się droższe do napisania, uruchomienia i utrzymania.
Zacznij od małego zestawu kluczowych encji
Zacznij od nazwania kilku rzeczy, bez których produkt nie może funkcjonować: users, accounts, orders, subscriptions, events, invoices — cokolwiek jest naprawdę centralne. Następnie zdefiniuj relacje explicite: one-to-many, many-to-many (zwykle z tabelą łączącą) i własność (kto „zawiera” co).
Praktyczny test: dla każdej tabeli powinieneś móc dokończyć zdanie „Wiersz w tej tabeli reprezentuje ___.” Jeśli nie potrafisz, tabela prawdopodobnie miesza koncepcje, co później wymusi skomplikowane filtrowanie i joiny.
Uczyń nazewnictwo i właścicielstwo nudno konsekwentnymi
Konsekwencja zapobiega przypadkowym joinom i mylącemu zachowaniu API. Wybierz konwencje (snake_case vs camelCase, *_id, created_at/updated_at) i się ich trzymaj.
Określ też, kto jest właścicielem pola. Na przykład: czy "billing_address" należy do order (snapshot w czasie), czy do user (bieżący domyślny)? Oba mogą być poprawne — ale mieszanie ich bez jasnego zamiaru tworzy powolne, podatne na błędy zapytania, które mają „ustalić prawdę”.
Wybieraj typy danych zgodne z rzeczywistością
Używaj typów unikających konwersji w czasie wykonania:
- Używaj timestampli z jasnymi regułami strefy czasowej.
- Używaj decimal dla pieniędzy (nie float).
- Używaj enumów/tablic referencyjnych dla znanych kategorii.
Gdy typy są niewłaściwe, baza nie może porównywać efektywnie, indeksy tracą na użyteczności, a zapytania często wymagają rzutowania.
Nie duplikuj faktów bez planu
Przechowywanie tej samej informacji w wielu miejscach (np. order_total i sum(line_items)) powoduje dryf. Jeśli cachujesz wartość pochodną, udokumentuj to, zdefiniuj źródło prawdy i zapewnij spójne aktualizacje (często przez logikę aplikacji plus ograniczenia).
Klucze i ograniczenia: szybkość zaczyna się od integralności danych
Szybka baza to zwykle przewidywalna baza. Klucze i ograniczenia czynią dane przewidywalnymi, zapobiegając „niemożliwym” stanom — brakującym relacjom, zduplikowanym tożsamościom czy wartościom, które nie znaczą tego, co aplikacja myśli. Ta czystość bezpośrednio wpływa na wydajność, ponieważ baza może przyjmować lepsze założenia przy planowaniu zapytań.
Klucze główne: każda tabela potrzebuje stabilnego identyfikatora
Każda tabela powinna mieć primary key (PK): kolumnę (lub niewielki zestaw kolumn), która jednoznacznie identyfikuje wiersz i nigdy się nie zmienia. To nie tylko zasada teoretyczna — to to, co pozwala efektywnie łączyć tabele, bezpiecznie cachować i odwoływać się do rekordów bez zgadywania.
Stabilny PK także unika kosztownych obejść. Jeśli tabela nie ma prawdziwego identyfikatora, aplikacje zaczynają „identyfikować” wiersze przez email, nazwę, timestamp lub wiązkę kolumn — prowadząc do szerszych indeksów, wolniejszych joinów i przypadków brzegowych, gdy te wartości się zmieniają.
Klucze obce: integralność, która pomaga optymalizatorowi
Foreign keys (FK) wymuszają relacje: orders.user_id musi wskazywać na istniejące users.id. Bez FK wkradają się nieprawidłowe odniesienia (zamówienia dla usuniętych użytkowników, komentarze dla brakujących postów), a każde zapytanie musi defensywnie filtrować, lewoskojarzać i obsługiwać null-e.
Z FK w miejscu planner zapytań często może optymalizować joiny pewniej, bo relacja jest jawna i zagwarantowana. Rzadziej też zbierasz sieroty, które z czasem zapełniają tabele i indeksy.
Ograniczenia jako bariery dla czystych, szybkich danych
Ograniczenia to nie biurokracja — to barierki:
- UNIQUE zapobiega duplikatom, które zmuszają aplikację do dodatkowych sprawdzeń i porządkowania. Przykład: jeden kanoniczny
users.email. - NOT NULL unika logiki trójstanowej i zaskakujących gałęzi obsługi nulli w zapytaniach.
- CHECK trzyma wartości w znanym zbiorze (np.
status IN ('pending','paid','canceled')).
Czystsze dane to prostsze zapytania, mniej warunków zapasowych i mniej dodatkowych joinów „na wszelki wypadek”.
Typowe antywzorce, które spowalniają
- Brak kluczy obcych: zapłacisz później zadaniami porządkującymi sieroty i skomplikowaną logiką zapytań.
- Duplikowanie pola "email" (np.
users.emailicustomers.email): prowadzi do konfliktujących tożsamości i zduplikowanych indeksów. - Wolno sformatowane statusy: literówki jak "Cancelled" vs "canceled" tworzą ukryte segmenty, które psują filtry i raportowanie.
Jeśli chcesz szybkości na start, utrudnij zapisywanie złych danych. Baza odwdzięczy się prostszymi planami, mniejszymi indeksami i mniejszą liczbą niespodzianek wydajnościowych.
Normalizacja vs denormalizacja: praktyczna równowaga
Pracuj z całym zespołem
Wybierz plan odpowiedni dla jednej osoby, zespołu lub firmy.
Normalizacja to prosta idea: przechowuj każdy „fakt” w jednym miejscu, żeby nie duplikować danych po całej bazie. Gdy ta sama wartość jest kopiowana do wielu tabel, aktualizacje stają się ryzykowne — jedna kopia się zmienia, inna nie, i aplikacja zaczyna pokazywać sprzeczne odpowiedzi.
Normalizacja (domyślnie): jeden fakt, jeden dom
W praktyce normalizacja oznacza oddzielanie encji, by aktualizacje były czyste i przewidywalne. Na przykład nazwa i cena produktu należą do products, a nie powtarzane w każdym wierszu zamówienia. Nazwa kategorii należy do categories, referencjonowana przez ID.
To redukuje:
- duplikację danych (mniej miejsca, mniej niespójności)
- błędy aktualizacji (zmieniasz raz, efekt widać wszędzie)
- niejasność "która wartość jest poprawna?"
Kiedy nadmierna normalizacja szkodzi
Normalizacja może być przesadzona, gdy dzielisz dane na bardzo dużo małych tabel, które muszą być łączone non-stop dla codziennych ekranów. Baza nadal może zwracać poprawne wyniki, ale zwykłe odczyty stają się wolniejsze i bardziej złożone, bo każde żądanie wymaga wielu joinów.
Typowy objaw we wczesnej fazie: „prosta” strona (np. lista historii zamówień) wymaga joinu 6–10 tabel, a wydajność zależy od ruchu i ciepła cache'a.
Podejście praktyczne: normalizuj fakty, denormalizuj gorące odczyty
Rozsądna równowaga:
- Normalizuj kluczowe fakty i własność (źródło prawdy). Trzymaj atrybuty produktu w
products, nazwy kategorii wcategories, relacje przez klucze obce. - Denormalizuj ostrożnie dla najczęstszych odczytów — ale tylko wtedy, gdy potrafisz wytłumaczyć korzyść i jak zachować poprawność.
Denormalizacja to świadome dublowanie małego kawałka danych, żeby uczynić częste zapytanie tańszym (mniej joinów, szybsze listy). Słowo klucz: ostrożnie: każde powielone pole potrzebuje planu utrzymania spójności.
Przykład: produkty, kategorie i pozycje zamówienia
Znormalizowana struktura może wyglądać tak:
products(id, name, price, category_id)categories(id, name)orders(id, customer_id, created_at)order_items(id, order_id, product_id, quantity, unit_price_at_purchase)
Zauważ subtelną korzyść: order_items przechowuje unit_price_at_purchase (rodzaj denormalizacji), ponieważ potrzebujesz historycznej dokładności, nawet gdy cena produktu się zmieni później. To powielenie jest zamierzone i stabilne.
Jeśli najczęściej wyświetlanym ekranem jest „zamówienia z podsumowaniem pozycji”, możesz również denormalizować product_name do order_items, żeby unikać joinowania products przy każdej liście — ale tylko jeśli jesteś przygotowany, żeby to zsynchronizować (albo zaakceptować, że to migawka w momencie zakupu).
Strategia indeksów podąża za schematem, nie odwrotnie
Indeksy często traktuje się jak magiczny „przycisk szybkości”, ale działają dobrze tylko wtedy, gdy struktura tabeli ma sens. Jeśli wciąż zmieniasz nazwy kolumn, dzielisz tabele lub zmieniasz sposób powiązań rekordów, zestaw indeksów będzie się zmieniać. Indeksy najlepiej działają, gdy kolumny (i sposób filtrowania/sortowania przez aplikację) są wystarczająco stabilne, żeby nie przebudowywać ich co tydzień.
Zacznij od pytań, które najczęściej zadaje aplikacja
Nie potrzebujesz idealnej przewidywalności, ale potrzebujesz krótkiej listy zapytań, które mają największe znaczenie:
- „Znajdź użytkownika po emailu.”
- „Pokaż ostatnie zamówienia klienta.”
- „Lista faktur według statusu, najnowsze pierwsze.”
Te zdania przekładają się bezpośrednio na kolumny, które zasługują na indeks. Jeśli nie potrafisz ich wypowiedzieć na głos, zwykle to problem nie indeksowania, lecz niejasności schematu.
Indeksy złożone, wyjaśnione prosto
Indeks złożony obejmuje więcej niż jedną kolumnę. Kolejność kolumn ma znaczenie, bo baza użyje indeksu efektywnie od lewej do prawej.
Na przykład, jeśli często filtrujesz po customer_id i potem sortujesz po created_at, indeks na (customer_id, created_at) zwykle jest użyteczny. Odwrotność (created_at, customer_id) może nie pomagać temu samemu zapytaniu tak bardzo.
Nie indeksuj wszystkiego
Każdy dodatkowy indeks ma koszt:
- Wolniejsze zapisy: insert/update musi też aktualizować każdy indeks.
- Większe zużycie przestrzeni: indeksy mogą stać się znaczącą częścią rozmiaru bazy.
- Większa złożoność: dodatkowe indeksy utrudniają utrzymanie i strojenie.
Czysty, spójny schemat zawęża „właściwe” indeksy do małego zestawu pasującego do realnych wzorców dostępu — bez ciągłego podatku za zapisy i miejsce.
Wydajność zapisów: ukryty koszt nieuporządkowanego schematu
Eksportuj swój kod źródłowy w dowolnym momencie
Zachowaj kontrolę, eksportując kod źródłowy w miarę ewolucji schematu i funkcji.
Wolne aplikacje nie zawsze hamowane są przez odczyty. Wiele wczesnych problemów wydajności pojawia się przy insertach i update'ach — rejestracje użytkowników, finalizacja zakupów, zadania w tle — ponieważ nieuporządkowany schemat powoduje dodatkową pracę przy każdej zmianie.
Dlaczego zapisy stają się kosztowne
Kilka wyborów schematu cicho mnoży koszt każdej zmiany:
- Szerokie wiersze: wpychanie dziesiątek (albo setek) kolumn do jednej tabeli często oznacza większe wiersze, więcej I/O i większe zamiany w cache — nawet jeśli większość kolumn rzadko jest używana.
- Zbyt wiele indeksów: indeksy przyspieszają odczyty, ale każdy insert/update musi też zaktualizować indeksy.
- Triggery i kaskady: triggery mogą ukrywać pracę (dodatkowe insert/update) za prostym
INSERT. Kaskadowe FK mogą być poprawne i pomocne, ale nadal dodają pracy w czasie zapisu, która rośnie wraz z powiązanymi danymi.
Read-heavy vs write-heavy: wybierz świadomie, gdzie chcesz cierpieć
Jeśli obciążenie jest read-heavy (feed, strony wyszukiwania), możesz sobie pozwolić na więcej indeksów i czasem selektywną denormalizację. Jeśli jest write-heavy (ingest zdarzeń, telemetryka, duża liczba zamówień), priorytetem powinien być schemat upraszczający zapisy, a optymalizacje odczytów dodawaj tylko tam, gdzie trzeba.
Typowe wzorce we wczesnej fazie, które szkodzą zapisom
- Logi audytu: dobre dla zgodności, ale unikaj logowania ogromnych snapshotów przy każdej aktualizacji.
- Tabele zdarzeń: append-only skaluje dobrze, ale może się zapełnić, jeśli przechowujesz redundantne payloady.
- Soft deletes: wygodne, ale zwiększają rozmiar indeksów i mogą spowalniać update'y i zapytania, jeśli nie są przemyślane.
Utrzymuj zapisy proste, zachowując historię
Podejście praktyczne:
- Przechowuj „aktualny stan” w jednej tabeli, a historię w osobnej tabeli append-only.
- Trzymaj wiersze historii wąskie (tylko to, co naprawdę potrzebne: kto/kiedy/co zmieniono).
- Dodaj indeksy do historii zgodnie z realnymi wzorcami dostępu (zwykle
entity_id,created_at). - Na początku unikaj triggerów dla audytu; preferuj jawne zapisy z aplikacji, żeby koszt był widoczny i testowalny.
Czyste ścieżki zapisu dają zapas mocy — i ułatwiają późniejsze strojenie zapytań.
Jak ORM-y i API wzmacniają decyzje schematu
ORM-y sprawiają, że praca z bazą wydaje się bez wysiłku: definiujesz modele, wywołujesz metody i dane się pojawiają. Ale ORM może też ukryć kosztowny SQL, aż zacznie doskwierać.
ORM-y: wygoda, która może maskować wolne wzorce
Dwa powszechne pułapki:
- Nieskuteczne joiny: pozornie prosty
.include()lub zagnieżdżony serializer może stać się szerokim joinem, duplikującymi się wierszami lub dużymi sortowaniami — zwłaszcza jeśli relacje nie są jasno zdefiniowane. - N+1 queries: pobierasz 50 rekordów, a ORM cicho uruchamia 50 kolejnych zapytań, żeby załadować powiązane dane. Często działa to w devie i zawala się przy prawdziwym ruchu.
Dobry schemat zmniejsza szansę pojawienia się tych wzorców i ułatwia ich wykrycie.
Jasne relacje czynią użycie ORM bezpieczniejszym
Gdy tabele mają explicite foreign keys, unique constraints i not-null rules, ORM może generować bezpieczniejsze zapytania, a twój kod może polegać na spójnych założeniach.
Na przykład wymuszenie, że orders.user_id istnieje (FK) i że users.email jest unikalny zapobiega klasie przypadków brzegowych, które inaczej zamieniają się w sprawdzenia na poziomie aplikacji i dodatkową pracę zapytań.
API przekłada decyzje schematu na zachowanie produktu
Twoje API jest downstream od schematu:
- Stabilne ID (i spójne typy kluczy) upraszczają URL-e, cache i stan po stronie klienta.
- Paginacja działa najlepiej, gdy możesz sortować po indeksowanej, monotonicznej kolumnie (często
created_at+id). - Filtrowanie staje się przewidywalne, gdy kolumny reprezentują prawdziwe atrybuty (nie przeciążone stringi czy JSON BLOBy) i ograniczenia trzymają wartości w ryzach.
Traktuj to jako proces, nie akcję ratunkową
Traktuj decyzje schematu jako pierwszy priorytet inżynieryjny:
- Używaj migracji dla każdej zmiany, przeglądanych jak kod (w repozytorium migrations).
- Dodaj lekkie „przeglądy schematu” dla nowych endpointów: jakie tabele, jakie klucze, jakie ograniczenia, jaki kształt zapytań.
- Na stagingu loguj zapytania generowane przez ORM i wykrywaj wzorce N+1 zanim trafią na produkcję.
Jeśli budujesz szybko z workflow napędzanym czatem (np. generujesz aplikację React plus backend Go/PostgreSQL w Koder.ai), warto uczynić „przegląd schematu” częścią rozmowy wcześnie. Możesz iterować szybko, ale chcesz, żeby ograniczenia, klucze i plan migracji były przemyślane — zwłaszcza przed pojawieniem się ruchu.
Wczesne sygnały ostrzegawcze, że to schemat jest wąskim gardłem
Niektóre problemy wydajnościowe to nie „zły SQL”, lecz baza walcząca z kształtem twoich danych. Jeśli widzisz te same problemy w wielu endpointach i raportach, to często sygnał schematu, a nie okazja do strojenia pojedynczych zapytań.
Typowe objawy, na które warto uważać
Wolne filtry to klasyczny znak. Jeśli proste warunki jak „znajdź zamówienia klienta” lub „filtruj po dacie utworzenia” są stale oporne, problem może leżeć w brakujących relacjach, niepasujących typach lub kolumnach, których nie da się efektywnie zindeksować.
Innym czerwonym flagiem jest wybuchowa liczba joinów: zapytanie, które powinno łączyć 2–3 tabele, kończy łączeniem 6–10 tabel tylko po to, by odpowiedzieć na podstawowe pytanie (często przez nadmierną normalizację, wzorce polymorficzne lub projekt „wszystko w jednej tabeli”).
Obserwuj też niespójne wartości w kolumnach, które zachowują się jak enumy — szczególnie pola statusu ("active", "ACTIVE", "enabled", "on"). Niespójność wymusza defensywne zapytania (LOWER(), COALESCE(), OR-chains), które pozostają wolne niezależnie od strojenia.
Lista kontrolna schematu (szybka do weryfikacji)
- Brakujące indeksy na kluczach obcych (joiny stają się pełnymi skanami wraz z rozrostem tabel).
- Nieprawidłowe typy danych (np. ID przechowywane jako string, daty jako tekst, pieniądze jako float).
- Tabele EAV (Entity–Attribute–Value) używane dla kluczowych danych: na początku elastyczne, ale filtry/sorty zamieniają się w wiele joinów i trudne do zindeksowania predykaty.
Proste, niezależne od narzędzi diagnostyki
Zacznij od sprawdzeń rzeczywistości: liczba wierszy w tabelach i kardynalność kluczowych kolumn (ile różnych wartości). Jeśli kolumna "status" powinna mieć 4 oczekiwane wartości, a znajdziesz 40, schemat już wycieka złożoność.
Potem obejrzyj plany zapytań dla wolnych endpointów. Jeśli wielokrotnie widzisz skany sekwencyjne na kolumnach joinujących lub duże pośrednie zestawy wyników, schemat i indeksowanie są prawdopodobnie źródłem problemu.
Włącz też i przejrzyj logi wolnych zapytań. Gdy wiele różnych zapytań jest wolnych w podobny sposób (te same tabele, te same predykaty), zwykle to strukturalny problem wart naprawy na poziomie modelu.
Bezpieczna ewolucja schematu w miarę wzrostu
Generuj indeksy dla rzeczywistych zapytań
Opisz najważniejsze endpointy i otrzymaj pomysły na indeksy pasujące do filtrów i sortowań.
Wczesne wybory schematu rzadko przetrwają pierwszy kontakt z realnymi użytkownikami. Celem nie jest "zrobić idealnie" — lecz zmieniać schemat bez łamania produkcji, utraty danych czy przerywania pracy zespołu na tydzień.
Lekki, powtarzalny proces zmian
Praktyczny workflow, który skaluje od aplikacji jednej osoby do większego zespołu:
- Modeluj: opisz nowy kształt (tabele/kolumny, relacje i co będzie źródłem prawdy). Dołącz przykładowe rekordy i przypadki brzegowe.
- Migruj: dodawaj nowe struktury w sposób kompatybilny wstecz (najpierw nowe kolumny/tabele; unikaj natychmiastowego usuwania czy zmiany nazwy).
- Backfill: wypełnij nowe pola z istniejących danych partiami. Śledź postęp, żeby móc wznowić.
- Waliduj: dodaj ograniczenia dopiero po oczyszczeniu danych (np. NOT NULL, foreign keys). Uruchom sprawdzenia porównujące stare i nowe wyjścia.
Flagi funkcji i dual writes (stosuj oszczędnie)
Większość zmian schematu nie wymaga skomplikowanych wzorców rollout. Preferuj „expand-and-contract”: pisz kod, który może czytać zarówno stare, jak i nowe struktury, a przełączaj zapisy dopiero, gdy jesteś pewien.
Używaj feature flags lub dual writes tylko wtedy, gdy naprawdę potrzebujesz stopniowego przełączenia (duży ruch, długie backfille lub wiele usług). Jeśli dual-write, dodaj monitoring wykrywający dryft i zdefiniuj, która strona wygrywa przy konflikcie.
Cofanie zmian i testowanie migracji w realistycznych warunkach
Bezpieczne rollbacki zaczynają się od migracji, które są odwracalne. Przećwicz ścieżkę „undo”: usunięcie nowej kolumny jest proste; odzyskanie nadpisanych danych — nie.
Testuj migracje na danych o realistycznej wielkości. Migracja trwająca 2 sekundy na laptopie może w produkcji blokować tabele przez minuty. Użyj zbliżonych do produkcyjnych liczby wierszy i indeksów, i zmierz czas wykonania.
Tu narzędzia platformy mogą zmniejszyć ryzyko: niezawodne wdrożenia, snapshoty/rollbacky i możliwość eksportu kodu ułatwiają bezpieczne iteracje schematu i logiki aplikacji razem. Jeśli korzystasz z Koder.ai, polegaj na snapshotach i trybie planowania przed wprowadzeniem migracji wymagających ostrożnego sekwencjonowania.
Dokumentuj decyzje dla następnej osoby (w tym przyszłego siebie)
Prowadź krótki log zmian schematu: co zmieniono, dlaczego i jakie kompromisy przyjęto. Podlinkuj go w /docs lub README repo. Zawieraj notatki typu „ta kolumna jest świadomie denormalizowana” lub "foreign key dodany po backfillu 2025-01-10", żeby przyszłe zmiany nie powielały dawnych błędów.
Kiedy optymalizować zapytania (i rozsądna kolejność działań)
Optymalizacja zapytań ma znaczenie — ale najbardziej opłaca się wtedy, gdy schemat ci nie przeszkadza. Jeśli tabele nie mają klarownych kluczy, relacje są niespójne lub „jeden wiersz na rzecz” jest naruszony, możesz spędzić godziny na strojeniu zapytań, które i tak zostaną przeprojektowane w następnym tygodniu.
Praktyczna kolejność priorytetów
-
Najpierw usuń blokery schematu. Zacznij od wszystkiego, co utrudnia poprawne zapytanie: brak PK, niespójne FK, kolumny mieszczące wiele znaczeń, duplikowane źródła prawdy lub typy niepasujące do rzeczywistości (np. daty jako stringi).
-
Ustabilizuj wzorce dostępu. Gdy model danych odzwierciedla zachowanie aplikacji (i prawdopodobne zachowanie na kolejne sprints), strojenie zapytań staje się trwałe.
-
Optymalizuj najważniejsze zapytania — nie wszystkie. Użyj logów/APM, żeby znaleźć najwolniejsze i najczęściej wywoływane zapytania. Jeden endpoint trafiany 10 000 razy dziennie zwykle bije rzadki raport admina.
Zasada 80/20 strojenia zapytań na start
Większość wczesnych zwycięstw pochodzi z małego zestawu posunięć:
- Dodaj właściwy indeks dla najczęstszych filtrów i joinów (i sprawdź, że jest używany).
- Zwracaj mniej kolumn (unikaj
SELECT *, zwłaszcza na szerokich tabelach). - Unikaj zbędnych joinów — czasem join istnieje tylko dlatego, że schemat zmusza do „odkrywania” podstawowych atrybutów.
Ustal oczekiwania: to proces, ale fundamenty są pierwsze
Prace nad wydajnością nigdy się nie kończą, ale celem jest uczynienie ich przewidywalnymi. Z czystym schematem każda nowa funkcja dodaje obciążenie stopniowo; z nieuporządkowanym schematem każda funkcja mnoży zamieszanie.
Checklist na ten tydzień
- Wypisz top 5 najwolniejszych i top 5 najczęściej wywoływanych zapytań.
- Dla każdego potwierdź: primary key obecny, joiny są key-to-key, a typy są poprawne.
- Dodaj jeden indeks dopasowany do dominującego filtru/sortowania.
- Zastąp
SELECT *w jednym gorącym miejscu. - Pomierz ponownie i zapisz proste „przed/po” jako notatkę na następny sprint.