10 lip 2025·7 min
Proste wzorce kolejek zadań w tle dla e-maili i webhooków
Poznaj proste wzorce kolejek zadań w tle do wysyłki e-maili, uruchamiania raportów i dostarczania webhooków z retry, backoff i obsługą dead-letter, bez ciężkich narzędzi.
Poznaj proste wzorce kolejek zadań w tle do wysyłki e-maili, uruchamiania raportów i dostarczania webhooków z retry, backoff i obsługą dead-letter, bez ciężkich narzędzi.
Wszystko, co może trwać dłużej niż sekundę lub dwie, nie powinno działać w ramach żądania użytkownika. Wysyłanie e-maili, generowanie raportów i dostarczanie webhooków zależą od sieci, usług zewnętrznych lub wolnych zapytań. Czasem się zatrzymują, zwracają błędy lub po prostu zajmują więcej czasu niż się spodziewasz.
Jeśli wykonujesz taką pracę, gdy użytkownik czeka, od razu to widać. Strony się zawieszają, przyciski „Zapisz” kręcą się, a żądania kończą się timeoutem. Retry mogą też dziać się w złym miejscu. Użytkownik odświeża stronę, load balancer próbuje ponownie albo frontend wysyła ponownie i kończysz z duplikatami e-maili, wielokrotnymi wywołaniami webhooków lub z dwoma uruchomieniami raportu konkurującymi o zasoby.
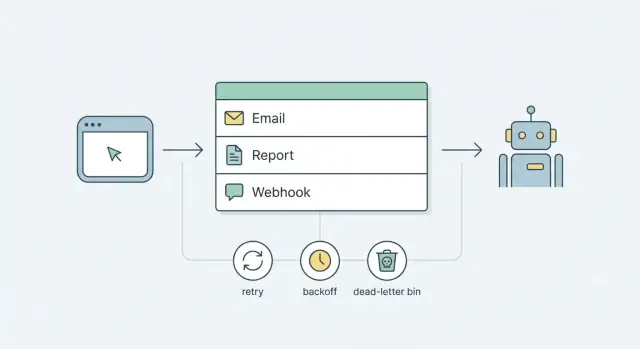
Zadania w tle rozwiązują to, utrzymując żądania małymi i przewidywalnymi: przyjmij akcję, zapisz zadanie do wykonania później, odpowiedz szybko. Zadanie wykonuje się poza ścieżką żądania, na warunkach które kontrolujesz.
Trudna część to niezawodność. Gdy praca wychodzi ze ścieżki żądania, nadal musisz odpowiedzieć na pytania takie jak:
Wiele zespołów odpowiada dodając „ciężką infrastrukturę”: broker wiadomości, oddzielne floty workerów, dashboardy, alerty i playbooki. Te narzędzia są przydatne, kiedy naprawdę ich potrzebujesz, ale dodają też nowe elementy i nowe sposoby awarii.
Lepszy cel startowy to prostota: niezawodne zadania z wykorzystaniem elementów, które już masz. Dla większości produktów to oznacza kolejkę opartą na bazie danych plus mały proces worker. Dodaj jasną strategię retry i backoff oraz wzorzec dead-letter dla zadań, które ciągle zawodzą. Otrzymujesz przewidywalne zachowanie bez zobowiązania do złożonej platformy od pierwszego dnia.
Nawet jeśli szybko budujesz z użyciem narzędzia napędzanego czatem jak Koder.ai, to rozdzielenie nadal ma sens. Użytkownicy powinni dostać szybką odpowiedź teraz, a system powinien dokończyć powolną, zawodną pracę bezpiecznie w tle.
Kolejka to linia oczekujących zadań. Zamiast robić wolne lub zawodnę zadania podczas żądania użytkownika (wysłać mail, zbudować raport, wywołać webhook), zapisujesz mały rekord w kolejce i odsyłasz szybko. Później osobny proces pobiera ten rekord i wykonuje pracę.
Kilka słów, które często się pojawiają:
Najprostszy przebieg wygląda tak:
Enqueue: aplikacja zapisuje rekord zadania (typ, payload, czas uruchomienia).
Claim: worker znajduje następne dostępne zadanie i „blokuje” je, aby tylko jeden worker je wykonał.
Run: worker wykonuje zadanie (wysyła, generuje, dostarcza).
Finish: oznacz je jako wykonane albo zapisz błąd i ustaw następny czas uruchomienia.
Jeśli wolumen zadań jest umiarkowany i już masz bazę danych, kolejka oparta na bazie często wystarcza. Łatwo ją zrozumieć, prosto debugować i pokrywa typowe potrzeby jak przetwarzanie e-maili czy niezawodność dostarczania webhooków.
Platformy streamingowe zaczynają mieć sens, gdy potrzebujesz bardzo dużej przepustowości, wielu niezależnych konsumentów lub możliwości odtwarzania ogromnej historii zdarzeń w wielu systemach. Jeśli uruchamiasz dziesiątki usług z milionami zdarzeń na godzinę, narzędzia jak Kafka mogą pomóc. Do tego momentu tabela w bazie plus pętla workera pokrywa wiele realnych przypadków.
Kolejka oparta na bazie danych pozostaje sensowna, jeśli każdy rekord zadania szybko odpowiada na trzy pytania: co zrobić, kiedy spróbować ponownie i co wydarzyło się ostatnio. Zrób to dobrze, a operacje staną się nudne (a to jest cel).
Przechowuj najmniejsze wejście potrzebne do wykonania pracy, a nie cały wygenerowany output. Dobre payloady to ID i kilka parametrów, np. { "user_id": 42, "template": "welcome" }.
Unikaj przechowywania dużych blobów (pełnych HTML e-maili, dużych danych raportu, ogromnych treści webhooków). Powoduje to szybszy wzrost bazy i utrudnia debugowanie. Jeśli zadanie potrzebuje dużego dokumentu, przechowaj referencję: report_id, export_id lub klucz do pliku. Worker pobierze pełne dane podczas działania.
Przynajmniej zarezerwuj miejsce na:
job_type wybiera handler (send_email, generate_report, deliver_webhook). payload trzyma małe wejścia jak ID i opcje.queued, running, succeeded, failed, dead).attempt_count i max_attempts, by przestać retryować gdy ewidentnie nie zadziała.created_at i next_run_at (kiedy staje się kwalifikowalne). Dodaj started_at i finished_at, jeśli chcesz lepszą widoczność powolnych zadań.idempotency_key, by zapobiec podwójnym efektom, oraz last_error, by zobaczyć dlaczego zawiodło bez grzebania w logach.Idempotencja brzmi poważnie, ale idea jest prosta: jeśli to samo zadanie uruchomi się dwa razy, druga próba powinna wykryć to i nie zrobić nic niebezpiecznego. Np. zadanie dostarczenia webhooka może używać klucza webhook:order:123:event:paid, żeby nie wysłać tego samego zdarzenia dwa razy, jeśli retry nachodzi na timeout.
Zbieraj też kilka podstawowych liczb od razu. Nie potrzebujesz dużego dashboardu na start, wystarczą zapytania, które powiedzą: ile zadań jest w kolejce, ile zawodzą i jaki jest wiek najstarszego zadania.
Jeśli już masz bazę danych, możesz zacząć z kolejką w tle bez dodawania nowej infrastruktury. Zadania to wiersze, worker to proces, który stale wybiera należne wiersze i wykonuje pracę.
Trzymaj tabelę małą i prostą. Chcesz wystarczająco pól, by uruchamiać, retryować i debugować zadania później.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued', -- queued, running, done, failed
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Jeśli budujesz na Postgresie (częste przy back-endach w Go), jsonb to praktyczny sposób na przechowywanie danych zadania jak { "user_id":123,"template":"welcome" }.
Gdy akcja użytkownika powinna wywołać zadanie (wysłać mail, odpal webhook), zapisz wiersz zadania w tej samej transakcji bazy co główna zmiana gdy to możliwe. Zapobiega to sytuacji „użytkownik utworzony, ale brak zadania” jeśli nastąpi crash zaraz po głównym zapisie.
Przykład: gdy użytkownik się rejestruje, wstaw w tej samej transakcji wiersz user i zadanie send_welcome_email.
Worker powtarza cykl: znajdź jedno należne zadanie, zarezerwuj je, przetwórz, oznacz za zakończone lub zaplanuj retry.
W praktyce oznacza to:
status='queued' i next_run_at <= now().SELECT ... FOR UPDATE SKIP LOCKED to częste podejście).status='running', locked_at=now(), locked_by='worker-1'.done/succeeded) lub zapisz last_error i ustaw następny termin próby.Kilka workerów może działać jednocześnie. Krok claim zapobiega podwójnemu pobraniu.
Przy zamykaniu procesu przestań pobierać nowe zadania, dokończ bieżące, a potem wyjdź. Jeśli proces umrze w trakcie pracy, użyj prostej zasady: traktuj zadania w running starsze niż timeout jako kwalifikujące się do ponownego wystawienia przez periodyczny „reaper”.
Jeśli budujesz w Koder.ai, ten wzorzec kolejki opartej na bazie to solidny domyślny wybór dla e-maili, raportów i webhooków zanim dodasz wyspecjalizowane usługi kolejkujące.
Retry to sposób, w jaki kolejka radzi sobie z chaosem świata. Bez jasnych reguł retry zmienia się w hałaśliwą pętlę, która spamuje użytkowników, wali w API i ukrywa prawdziwy błąd.
Zacznij od decyzji, co retryować, a co porzucić od razu.
Retryuj problemy tymczasowe: timeouts sieciowe, 502/503, limity rate, krótkie problemy z bazą.
Porzucaj od razu, gdy zadanie nie ma szans: brak adresu e-mail, 400 od webhooka z powodu nieprawidłowego payloadu, czy żądanie raportu dla skasowanego konta.
Backoff to przerwa między próbami. Linearny backoff (5s, 10s, 15s) jest prosty, ale może tworzyć fale. Eksponencjalny backoff (5s, 10s, 20s, 40s) rozkłada obciążenie lepiej i jest zwykle bezpieczniejszy dla webhooków i dostawców zewnętrznych. Dodaj jitter (małe, losowe opóźnienie), żeby tysiąc zadań nie retryował dokładnie w tej samej sekundzie po awarii.
Reguły, które dobrze się sprawdzają:
Max attempts ogranicza szkody. Dla wielu zespołów 5–8 prób wystarcza. Po tym przestań retryować i zaparkuj zadanie do przeglądu (dead-letter) zamiast robić pętlę w nieskończoność.
Timeouty zapobiegają „zombie” zadaniom. E-maile mogą mieć timeout 10–20 sekund na próbę. Webhooki często potrzebują krótszego limitu, np. 5–10 sekund, bo odbiorca może być niedostępny i chcesz iść dalej. Generowanie raportu może pozwolić na minuty, ale powinno mieć twardy cutoff.
Jeśli budujesz to w Koder.ai, traktuj should_retry, next_run_at i klucz idempotencji jako pola pierwszej klasy. Te drobne detale utrzymują system w ryzach, gdy coś idzie nie tak.
Stan dead-letter to miejsce, gdzie trafiają zadania, gdy retry już nie ma sensu. Zmienia ciche porażki w coś, co można zobaczyć, wyszukać i na co zareagować.
Zapisz wystarczająco, by zrozumieć co się stało i móc odtworzyć zadanie bez zgadywania, ale uważaj na sekrety.
Trzymaj:
Jeśli payload zawiera tokeny lub dane osobowe, zamaskuj je lub zaszyfruj przed zapisaniem.
Gdy zadanie trafi do dead-letter, podejmij szybką decyzję: retry, naprawić lub zignorować.
Retry to przypadki outage zewnętrznych usług i timeoutów. Naprawić to złe dane (brak e-maila, zły URL webhooka) lub błąd w kodzie. Ignorować powinno zdarzać się rzadko, ale ma sens, gdy zadanie jest już nieistotne (np. klient usunął konto). Jeśli ignorujesz, zapisz powód, żeby nie wyglądało jakby zadanie zniknęło.
Ręczne ponowne wystawienie jest najbezpieczniejsze, gdy tworzy nowe zadanie i pozostawia stary niezmienny. Oznacz dead-letter, kto i kiedy go ponownie wystawił oraz dlaczego, a potem enqueue’uj świeżą kopię z nowym ID.
Do alertów obserwuj sygnały oznaczające prawdziwy problem: szybki wzrost liczby dead-letterów, ten sam błąd powtarzający się w wielu zadaniach i stare zadania w kolejce, które nie są pobierane.
Jeśli używasz Koder.ai, snapshoty i rollback pomagają, gdy zła wersja wywoła nagły wzrost błędów — możesz szybko cofnąć zmiany i zbadać problem.
Na koniec dodaj zawory bezpieczeństwa na wypadek outage dostawcy. Ogranicz wysyłki na dostawcę i użyj circuit-breakera: jeśli endpoint webhooka mocno zawodzi, wstrzymaj nowe próby na krótki czas, żeby nie zalać ich (ani siebie) żądaniami.
Kolejka działa najlepiej, gdy każdy typ zadania ma jasne reguły: co liczy się za sukces, co retryować i co nigdy nie powinno się zdarzyć dwa razy.
E-maile. Większość błędów e-maili jest tymczasowa: timeouts dostawcy, limity, krótkie awarie. Traktuj je jako retryowalne, z backoffem. Największe ryzyko to duplikaty, więc e-mail joby powinny być idempotentne. Przechowuj stabilny klucz deduplikujący, np. user_id + template + event_id i odmawiaj wysyłki jeśli ten klucz jest już oznaczony jako wysłany.
Warto też zapisać nazwę i wersję szablonu (lub hash wygenerowanego subject/body). Jeśli trzeba ponownie uruchomić joby, możesz wybrać, czy wysłać identyczną treść czy wygenerować ją od nowa z najnowszego szablonu. Jeśli dostawca zwraca message ID, zapisz go, by wsparcie mogło śledzić, co się stało.
Raporty. Raporty zawodzą inaczej. Mogą trwać minuty, natrafić na limity paginacji lub skończyć pamięć, jeśli wszystko robisz na raz. Podziel pracę na mniejsze kawałki. Częsty wzorzec: jedno zadanie „report request” tworzy wiele zadań „page” (lub „chunk”), z których każde przetwarza fragment danych.
Przechowuj wyniki do późniejszego pobrania zamiast trzymać użytkownika w oczekiwaniu. To może być tabela w bazie kluczowana przez report_run_id albo referencja pliku plus metadane (status, liczba wierszy, created_at). Dodaj pola postępu, żeby UI mogło pokazać „processing” vs „ready” bez zgadywania.
Webhooki. Webhooki to dostarczanie, a nie prędkość. Podpisuj każde żądanie (np. HMAC z shared secret) i dołączaj znacznik czasu, by zapobiec replayom. Retry tylko wtedy, gdy odbiorca może się później udać.
Prosty zestaw reguł:
Kolejność i priorytet. Większość zadań nie potrzebuje ścisłej kolejności. Kiedy kolejność ma znaczenie, zwykle dotyczy konkretnego klucza (na użytkownika, fakturę, endpoint webhooka). Dodaj group_key i pozwól na tylko jedno zadanie w locie na dany klucz.
Dla priorytetu oddziel pilne prace od wolnych. Duże backlogi raportów nie powinny opóźniać e-maili do resetu hasła.
Przykład: po zakupie enqueue’ujesz (1) e-mail potwierdzający zamówienie, (2) webhook do partnera i (3) zadanie aktualizacji raportu. E-mail retryuje szybko, webhook retryuje dłużej z backoffem, a raport uruchamia się później z niskim priorytetem.
Użytkownik rejestruje się w aplikacji. Trzy rzeczy powinny się wydarzyć, ale żadna nie powinna spowolnić strony rejestracji: wyślij mail powitalny, powiadom CRM webhookiem i dodaj użytkownika do nocnego raportu aktywności.
Zaraz po utworzeniu rekordu użytkownika zapisz trzy wiersze w tabeli kolejki. Każdy wiersz ma typ, payload (np. user_id), status, liczbę prób i timestamp next_run_at.
Typowy cykl życia wygląda tak:
queued: utworzone i czekające na workerarunning: worker je zarezerwowałsucceeded: zakończone, koniec pracyfailed: nie powiodło się, zaplanowane ponownie lub brak próbdead: za dużo nieudanych prób, wymaga uwagi człowiekaJob powitalny ma klucz idempotencji jak welcome_email:user:123. Przed wysyłką worker sprawdza tabelę zakończonych kluczy idempotencji (lub wymusza unikalność). Jeśli zadanie uruchomi się ponownie z powodu crashtu, druga próba zauważy klucz i pominie wysyłkę. Brak podwójnego maila powitalnego.
Teraz endpoint CRM jest niedostępny. Zadanie webhooka kończy się timeoutem. Worker planuje retry z backoffem (np. 1 minuta, 5 minut, 30 minut, 2 godziny) plus jitter, żeby wiele zadań nie retryowało dokładnie w tej samej sekundzie.
Po przekroczeniu max attempts zadanie trafia do dead. Użytkownik się zarejestrował, dostał mail powitalny, a zadanie nocnego raportu może działać normalnie. Tylko powiadomienie CRM jest utknięte i jest widoczne.
Następnego ranka support (lub on-call) może to obsłużyć bez grzebania godzinami w logach:
webhook.crm).Jeśli budujesz aplikacje na platformie jak Koder.ai, ten sam wzorzec się stosuje: utrzymuj flow użytkownika szybkim, przerzucaj efekty uboczne do jobów i sprawiaj, żeby błędy było łatwo podejrzeć i uruchomić ponownie.
Najszybszy sposób, by zepsuć kolejkę, to traktować ją jako opcjonalną. Zespoły często zaczynają od „tym razem po prostu wyślij e-mail w żądaniu”, bo wydaje się to prostsze. Potem to się rozrasta: reset hasła, potwierdzenia, webhooki, eksporty raportów. Wkrótce aplikacja jest wolna, timeouts rosną, a jakikolwiek problem z zewnętrznym serwisem staje się twoim outage.
Inna pułapka to pominięcie idempotencji. Jeśli zadanie może się uruchomić dwa razy, nie powinno tworzyć dwóch rezultatów. Bez idempotencji retry prowadzą do duplikatów e-maili, powtarzających się zdarzeń webhook itp.
Trzeci problem to brak widoczności. Jeśli o błędach dowiadujesz się tylko z ticketów supportu, kolejka już szkodzi użytkownikom. Nawet podstawowy widok wewnętrzny pokazujący liczbę zadań po statusie i przeszukiwalny last_error oszczędza czas.
Kilka problemów pojawia się szybko, nawet w prostych kolejkach:
Backoff zapobiega samozrobionym outage’om. Nawet podstawowy harmonogram jak 1 minuta, 5 minut, 30 minut, 2 godziny czyni awarie bezpieczniejszymi. Ustaw także limit prób, żeby złamane zadanie zatrzymało się i stało widoczne.
Jeśli budujesz na platformie jak Koder.ai, dobrze jest wypuścić te podstawy razem z funkcją, a nie tygodnie później jako sprzątanie.
Zanim dodasz więcej narzędzi, upewnij się, że podstawy działają. Kolejka oparta na bazie działa dobrze, gdy każde zadanie jest łatwe do zarezerwowania, retryowania i obejrzenia.
Szybka lista kontrolna niezawodności:
Następnie wybierz pierwsze trzy typy zadań i zapisz ich reguły. Na przykład: e-mail resetu hasła (szybkie retry, krótki max), nightly report (kilka retry, dłuższe timeouty), delivery webhook (więcej retry, dłuższy backoff, stop przy stałych 4xx).
Jeśli nie wiesz, kiedy kolejka w bazie przestaje wystarczać, obserwuj sygnały takie jak contention na poziomie wiersza przy wielu workerach, potrzeby ścisłej kolejności dla wielu typów zadań, duży fan-out (jedno zdarzenie wyzwala tysiące zadań) albo konsumcja cross-service, gdzie różne zespoły mają różnych workerów.
Jeśli chcesz szybki prototyp, możesz naszkicować flow w Koder.ai (koder.ai) w trybie planowania, wygenerować tabelę jobs i pętlę workera, a potem iterować ze snapshotami i rollbackem przed wdrożeniem.
Jeśli zadanie może zająć więcej niż sekundę-dwie albo zależy od wywołania sieciowego (dostawca e-maili, endpoint webhooka, wolne zapytanie), przenieś je do background job.
Skup żądanie użytkownika na walidacji danych, zapisaniu głównej zmiany, zapisaniu zadania do kolejki i szybkim zwróceniu odpowiedzi.
Zacznij od kolejki opartej na bazie danych gdy:
Dodaj broker/streaming gdy potrzebujesz bardzo dużej przepustowości, wielu niezależnych konsumentów lub możliwości odtwarzania zdarzeń między usługami.
Śledź podstawowe informacje, które odpowiadają: co zrobić, kiedy spróbować ponownie i co się wydarzyło ostatnio.
Praktyczne minimum:
Przechowuj wejścia, nie duże wyjścia.
Dobre payloady:
user_id, template, report_id)Unikaj:
Kluczem jest atomowy krok „claim”, żeby dwóch workerów nie pobrało tego samego zadania.
Popularne podejście w Postgres:
FOR UPDATE SKIP LOCKED)running i ustaw locked_at/locked_byDzięki temu workery mogą skalować się poziomo bez podwójnego przetwarzania.
Zakładaj, że zadania czasem się uruchomią dwukrotnie (crashe, timeouts, retry). Uczyń efekt uboczny bezpiecznym.
Proste wzorce:
idempotency_key jak welcome_email:user:123To szczególnie ważne dla e-maili i webhooków, żeby uniknąć duplikatów.
Użyj jasnej polityki i trzymaj się jej:
Fail fast przy błędach stałych (brak adresu e-mail, nieprawidłowy payload, większość 4xx z webhooków).
Dead-letter oznacza „przestań retryować i pokaż to”. Używaj, gdy:
max_attemptsZapisz wystarczający kontekst do działania:
Radź sobie ze „zawieszonymi” zadaniami dwoma zasadami:
running starsze niż próg i re-queue’uje je (lub oznacza jako failed)To pozwala systemowi wrócić do działania po crashu workera bez ręcznego sprzątania.
Oddziel powolne od pilnych prac:
Jeśli kolejność ma znaczenie, zwykle dotyczy klucza (per user, per endpoint). Dodaj group_key i pozwól na jedno zadanie w locie na klucz, by zachować lokalną kolejność bez globalnej blokady.
job_type, payloadstatus (queued, running, succeeded, failed, dead)attempts, max_attemptsnext_run_at, plus created_atlocked_at, locked_bylast_erroridempotency_key (lub inny mechanizm deduplikacji)Jeśli zadanie potrzebuje dużych danych, przechowaj referencję (np. report_run_id lub klucz pliku) i pobierz zawartość w workerze.
last_error i ostatni kod statusu (dla webhooków)Przy replayu tworzy się nowego joba, pozostawiając dead-letter niezmieniony.