02 wrz 2025·5 min
Protobuf vs JSON dla API: prędkość, rozmiar i zgodność
Porównanie Protobuf i JSON dla API: rozmiar payloadu, szybkość, czytelność, narzędzia, wersjonowanie i kiedy każdy format najlepiej pasuje do produktu.
Porównanie Protobuf i JSON dla API: rozmiar payloadu, szybkość, czytelność, narzędzia, wersjonowanie i kiedy każdy format najlepiej pasuje do produktu.
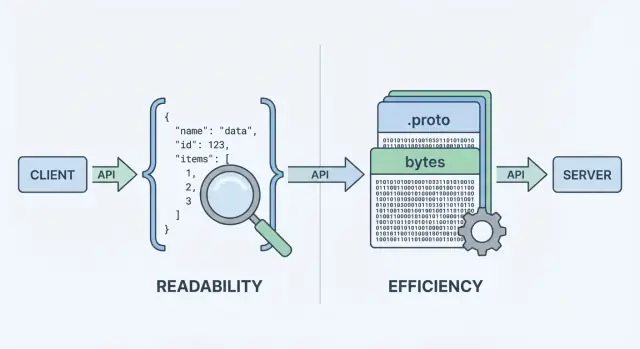
Kiedy twoje API wysyła lub odbiera dane, potrzebuje formatu danych — ustandaryzowanego sposobu reprezentowania informacji w ciałach żądań i odpowiedzi. Ten format jest potem serializowany (zamieniany na bajty) do przesłania przez sieć, a po drugiej stronie deserializowany z powrotem do obiektów użytecznych dla klienta i serwera.
Dwie z najczęściej wybieranych opcji to JSON i Protocol Buffers (Protobuf). Mogą reprezentować te same dane biznesowe (użytkownicy, zamówienia, znaczniki czasu, listy pozycji), ale robią różne kompromisy dotyczące wydajności, rozmiaru payloadu i workflowu deweloperskiego.
JSON (JavaScript Object Notation) to format oparty na tekście z prostymi strukturami jak obiekty i tablice. Jest popularny w REST API, bo jest łatwy do czytania, łatwy do logowania i wygodny do inspekcji w narzędziach typu curl czy DevTools w przeglądarce.
Duży powód, dla którego JSON jest wszechobecny: większość języków ma świetne wsparcie, a odpowiedź można wzrokowo odczytać i zrozumieć od razu.
Protobuf to binarny format serializacji stworzony przez Google. Zamiast wysyłać tekst, przesyła zwartą reprezentację binarną zdefiniowaną przez schemat (plik .proto). Schemat opisuje pola, ich typy i numeryczne tagi.
Dzięki temu, że jest binarny i oparty na schemacie, Protobuf zwykle daje mniejsze payloady i może być szybszy w parsowaniu — co ma znaczenie przy dużej liczbie żądań, sieciach mobilnych lub usługach wrażliwych na opóźnienia (często w zestawie z gRPC, choć nie ogranicza się do gRPC).
Ważne jest oddzielić co wysyłasz od jak to jest kodowane. "Użytkownik" z id, nazwą i emailem można zamodelować zarówno w JSON, jak i w Protobuf. Różnica to koszt, który ponosisz w postaci:
Nie ma uniwersalnej odpowiedzi. Dla wielu publicznych API JSON pozostaje domyślnym wyborem ze względu na dostępność i elastyczność. Dla wewnętrznej komunikacji między usługami, systemów wrażliwych na wydajność lub tam, gdzie potrzebne są ścisłe kontrakty, Protobuf może być lepszy. Celem tego przewodnika jest pomóc wybrać na podstawie ograniczeń — nie ideologii.
Gdy API zwraca dane, nie może wysłać „obiektów” bezpośrednio przez sieć. Musi je najpierw zamienić na strumień bajtów. Ta konwersja to serializacja — pomyśl o tym jak o zapakowaniu danych do formy możliwej do przesłania. Po drugiej stronie klient robi odwrotnie (deserializację), rozpakowując bajty z powrotem do struktur danych.
Typowy przepływ żądanie/odpowiedź wygląda tak:
To „kodowanie” to etap, gdzie wybór formatu ma znaczenie. Kodowanie JSON daje czytelny tekst jak {\"id\":123,\"name\":\"Ava\"}. Kodowanie Protobuf daje zwarte bajty binarne, które bez narzędzi nie mają sensu dla człowieka.
Ponieważ każda odpowiedź musi być zapakowana i rozpakowana, format wpływa na:
Styl API często sprzyja jednemu z wyborów:
curl i prosty do logowania/inspekcji.Możesz używać JSON z gRPC (przez transkodowanie) lub Protobufu przez zwykłe HTTP, ale ergonomia stosu — frameworki, bramki, biblioteki klienckie i przyzwyczajenia debugowania — często zdecydują, co łatwiej utrzymywać na co dzień.
Gdy ludzie porównują protobuf vs json, zwykle zaczynają od dwóch metryk: jak duży jest payload i ile trwa kodowanie/dekodowanie. Ogólna myśl: JSON to tekst i często bywa rozwlekły; Protobuf to binarny i zwykle bardziej zwarty.
JSON powtarza nazwy pól i używa tekstowej reprezentacji dla liczb, booleanów i struktur, więc często wysyła więcej bajtów. Protobuf zastępuje nazwy pól numerami tagów i pakuje wartości efektywnie, co zwykle daje zauważalnie mniejsze payloady — szczególnie dla dużych obiektów, powtarzanych pól i głęboko zagnieżdżonych danych.
Jednak kompresja może zmniejszyć różnicę. Przy gzip lub brotli, powtarzające się klucze JSON dobrze się kompresują, więc różnica "JSON vs Protobuf rozmiar" może się skurczyć w rzeczywistych wdrożeniach. Protobuf też można kompresować, ale względna przewaga często się zmniejsza.
Parsery JSON muszą tokenizować i walidować tekst, konwertować stringi na liczby i radzić sobie z edge-case’ami (escape, białe znaki, unicode). Dekodowanie Protobuf jest bardziej bezpośrednie: czytaj tag → czytaj wartość typu. W wielu usługach Protobuf zmniejsza zużycie CPU i tworzenie śmieci (garbage), co może poprawić tail latency przy obciążeniu.
W sieciach mobilnych lub przy połączeniach o dużym RTT, mniejsza liczba bajtów zwykle oznacza szybszy transfer i krótszy czas użycia radia (co także pomaga baterii). Ale jeśli odpowiedzi są już bardzo małe, narzut handshake, TLS i przetwarzanie po stronie serwera mogą dominować — wtedy wybór formatu staje się mniej zauważalny.
Mierz na prawdziwych payloadach:
To zamienia debatę o "serializacji API" w dane, na których możesz polegać dla swojego API.
W doświadczeniu deweloperskim JSON często wygrywa domyślnie. Możesz sprawdzić odpowiedź JSON praktycznie wszędzie: w DevTools, w curl, w Postmanie, w reverse proxy i prostych logach tekstowych. Gdy coś się psuje, "co dokładnie wysłaliśmy?" zwykle jest jedno copy/paste stąd.
Protobuf jest inny: zwarty i ścisły, ale nieczytelny dla człowieka. Jeśli logujesz surowe bajty Protobuf, zobaczysz base64 lub niezrozumiałe binarne. Aby zrozumieć payload, potrzebujesz właściwego schematu .proto i dekodera (np. protoc, narzędzia specyficzne dla języka lub generowanych typów usługi).
Z JSONem odtworzenie problemu jest proste: zabierz zalogowany payload, zredaguj sekrety, odtwórz curlem i masz bliski minimalny przypadek testowy.
Z Protobuf zwykle debugujesz, robiąc:
Ten dodatkowy krok jest wykonalny — pod warunkiem, że zespół ma powtarzalny workflow.
Strukturalne logowanie pomaga obu formatom. Loguj identyfikatory żądań, nazwy metod, identyfikatory użytkownika/konta i kluczowe pola zamiast całych ciał.
Dla Protobuf:
.proto użyto?".Dla JSONu rozważ logowanie kanonizowanego JSON (stabilne uporządkowanie kluczy), żeby ułatwić diffy i czytelność timeline’ów incidentów.
API nie tylko przenoszą dane — przenoszą znaczenie. Największa różnica między JSON a Protobuf to to, jak jasno znaczenie jest zdefiniowane i egzekwowane.
JSON jest domyślnie "bez schematu": możesz wysłać dowolny obiekt z dowolnymi polami i wielu klientów zaakceptuje go, jeśli "wygląda" rozsądnie.
Ta elastyczność jest wygodna na początku, ale może też ukrywać błędy. Typowe pułapki to:
userId w jednej odpowiedzi, user_id w innej, albo brakujące pola zależnie od ścieżki kodu."42", "true" lub "2025-12-23" — łatwo je wytworzyć i łatwo źle zinterpretować.null może znaczyć "nieznane", "nieustawione" albo "celowo puste" i różni klienci mogą to traktować inaczej.Możesz dodać JSON Schema lub OpenAPI, ale sam JSON tego nie wymusza.
Protobuf wymaga schematu zdefiniowanego w pliku .proto. Schemat to wspólny kontrakt, który mówi:
Ten kontrakt pomaga zapobiegać przypadkowym zmianom — jak zamiana integera na string — ponieważ wygenerowany kod oczekuje konkretnych typów.
W Protobuf liczby pozostają liczbami, enumy są ograniczone do znanych wartości, a timestampy zwykle modeluje się za pomocą well-known types (zamiast ad-hoc formatów stringowych). "Nieustawione" jest też jaśniejsze: w proto3 brak pola różni się od wartości domyślnej, jeśli używasz optional lub wrapperów.
Jeśli twoje API wymaga precyzyjnych typów i przewidywalnego parsowania pomiędzy zespołami i językami, Protobuf daje zabezpieczenia, których JSON zwykle osiąga jedynie przez konwencje.
API ewoluują: dodajesz pola, dopracowujesz zachowanie i wycofujesz stare elementy. Celem jest zmiana kontraktu bez zaskakiwania konsumentów.
Dobry plan ewolucji dąży do obu, ale kompatybilność wsteczna jest zwykle minimalnym progiem.
W Protobuf każde pole ma numer (np. email = 3). To numer — nie nazwa pola — idzie na drucie. Nazwy są głównie dla ludzi i generowanego kodu.
Dzięki temu:
Bezpieczne zmiany (zwykle)
Ryzykowne zmiany (często łamiące)
Najlepsza praktyka: używaj reserved dla starych numerów/nazw i prowadź changelog.
JSON nie ma wbudowanego schematu, więc kompatybilność zależy od wzorców:
Dokumentuj deprecacje wcześnie: kiedy pole zostanie wycofane, jak długo będzie wspierane i co je zastępuje. Opublikuj prostą politykę wersjonowania (np. "zmiany addytywne są niełamliwe; usunięcia wymagają nowej wersji major") i jej się trzymaj.
Wybór między JSON a Protobuf zależy często od tego, gdzie twoje API ma działać — i co zespół chce utrzymywać.
JSON jest praktycznie uniwersalny: każda przeglądarka i runtime backendowy potrafi go sparsować bez dodatkowych zależności. W aplikacji webowej fetch() + JSON.parse() to standard, a proxy, bramki i narzędzia obserwowalności często „rozumieją” JSON od razu.
Protobuf też może działać w przeglądarce, ale nie jest to zero-kosztowy wybór. Zwykle dodasz bibliotekę Protobuf (lub generowany kod JS/TS), zadbasz o rozmiar bundla i zdecydujesz, czy wysyłać Protobuf przez endpointy HTTP, które twoje narzędzia inspekcyjne łatwo odczytają.
Na iOS/Android i w językach backendowych (Go, Java, Kotlin, C#, Python itd.) wsparcie Protobuf jest dojrzałe. Różnica jest taka, że Protobuf zakłada użycie bibliotek na platformę i zwykle generowanie kodu z .proto.
Generowanie kodu przynosi realne korzyści:
Dodaje to też koszty:
.proto, pinowanie wersji)Protobuf jest ściśle powiązany z gRPC, który daje kompletną historię narzędzi: definicje usług, stuby klienckie, streaming i interceptory. Jeśli rozważasz gRPC, Protobuf jest naturalnym wyborem.
Jeśli budujesz tradycyjne REST JSON API, ekosystem JSON (DevTools, debugowanie curl, generczne bramki) zwykle jest prostszy — szczególnie dla publicznych API i szybkich integracji.
Jeśli nadal eksplorujesz powierzchnię API, warto szybko prototypować w obu stylach zanim się ustandaryzujesz. Na przykład zespoły używające Koder.ai często uruchamiają REST JSON dla szerokiej kompatybilności i wewnętrzny gRPC/Protobuf dla efektywności, a potem benchmarkują prawdziwe payloady przed ustaleniem domyślnych wyborów. Ponieważ Koder.ai może generować pełny stos aplikacji (React na web, Go + PostgreSQL na backend, Flutter na mobile) i wspierać tryb planowania oraz snapshoty/rollback, można iterować nad kontraktami bez konieczności wielkiego refaktoru.
JSON to format oparty na tekście, który łatwo czytać, logować i testować za pomocą standardowych narzędzi. Protobuf to zwarty format binarny zdefiniowany przez schemat w pliku .proto, często dający mniejsze payloady i szybsze parsowanie.
Wybieraj w zależności od ograniczeń: zasięg i łatwość debugowania (JSON) vs wydajność i ścisłe kontrakty (Protobuf).
API przesyłają bajty, nie obiekty pamięciowe. Serializacja koduje obiekty serwera do payloadu (tekst JSON lub binarny Protobuf) do transportu; deserializacja dekoduje te bajty z powrotem do obiektów po stronie klienta/serwera.
Wybór formatu wpływa na przepustowość, opóźnienie i CPU potrzebny do kodowania/dekodowania.
Często tak. Zwłaszcza dla dużych lub zagnieżdżonych obiektów i powtarzanych pól, Protobuf używa tagów numerycznych i efektywnego kodowania binarnego.
Jednak po włączeniu gzip/brotli, JSON dobrze się kompresuje (powtarzające się klucze), więc rzeczywista różnica rozmiaru może się zmniejszyć. Mierz zarówno surowy jak i skomprymowany rozmiar.
Może. Parsowanie JSON wymaga tokenizacji tekstu, obsługi escape’ów/unicode i konwersji ciągów na liczby. Dekodowanie Protobuf polega zwykle na prostym czytaniu taga → typowanej wartości, co często zmniejsza użycie CPU i alokacje.
Jeśli jednak payloady są malutkie, opóźnienia wynikające z TLS, RTT sieci i pracy aplikacji mogą dominować nad kosztami serializacji.
Domyślnie trudniej. JSON jest czytelny i łatwy do sprawdzenia w DevTools, logach, curl i Postmanie. Payloady Protobuf są binarne, więc zwykle potrzebujesz pasującego schematu .proto i narzędzi do dekodowania.
Praktycznym usprawnieniem jest logowanie dekodowanego, wyredagowanego widoku debugowego (np. reprezentacji JSON) obok identyfikatorów żądań i kluczowych pól.
JSON jest domyślnie „bez schematu”, chyba że wprowadzisz JSON Schema/OpenAPI. Ta elastyczność może prowadzić do niespójnych pól, wartości przechowywanych jako ciągi ("stringly-typed") i niejednoznacznych semantyk null.
Protobuf wymusza typy przez kontrakt w pliku .proto, generuje silnie typowane klasy i ułatwia ewolucję kontraktów — szczególnie gdy pracuje wiele zespołów i języków.
W Protobuf to numery pól (tagi) są istotne. Bezpieczne zmiany to zwykle dodawanie opcjonalnych pól z nowymi numerami. Zmiany łamiące obejmują ponowne użycie numeru pola do innego znaczenia lub niekompatybilną zmianę typu.
Dobre praktyki: używaj reserved dla starych numerów/nazw i prowadź changelog.
Tak. Użyj negocjacji treści:
Accept: application/json lub Accept: application/x-protobufContent-TypeVary: Accept, żeby cache nie mylił formatówJeśli negocjacja jest trudna z powodu narzędzi, tymczasowy, osobny endpoint (np. ) może pomóc.
To zależy od środowiska:
Przy wyborze Protobuf rozważ koszt utrzymania codegenu i wersjonowania współdzielonych schematów.
Nie zastępuje to standardowych praktyk bezpieczeństwa. Format nie jest warstwą zabezpieczeń — szyfrowanie transportu (TLS), autoryzacja, walidacja po stronie serwera i limity pozostają obowiązkowe.
Dobre zabezpieczenia obejmują:
Aktualizuj biblioteki parserów, żeby zmniejszyć ryzyko luk.
/v2/...