05 paź 2025·8 min
RabbitMQ dla Twoich Aplikacji: wzorce, konfiguracja i operacje
Dowiedz się, jak używać RabbitMQ w aplikacjach: podstawy, wzorce (pub/sub, work queues, DLQ), niezawodność, skalowanie, bezpieczeństwo i monitoring dla produkcji.
Dowiedz się, jak używać RabbitMQ w aplikacjach: podstawy, wzorce (pub/sub, work queues, DLQ), niezawodność, skalowanie, bezpieczeństwo i monitoring dla produkcji.
RabbitMQ to broker wiadomości: stoi pomiędzy częściami systemu i niezawodnie przenosi „pracę” (wiadomości) od producentów do konsumentów. Zespoły aplikacyjne sięgają po niego, gdy bezpośrednie, synchroniczne wywołania (HTTP między usługami, współdzielone bazy danych, cron) zaczynają tworzyć kruche zależności, nierównomierne obciążenie i łańcuchy błędów trudne do zdiagnozowania.
Skoki ruchu i nierównomierne obciążenie. Jeśli twoja aplikacja dostaje 10× więcej rejestracji lub zamówień w krótkim czasie, natychmiastowe przetwarzanie może przytłoczyć downstream. Z RabbitMQ producenci szybko zapisują zadania, a konsumenci przetwarzają je w kontrolowanym tempie.
Ścisłe powiązanie usług. Gdy Usługa A musi wywołać Usługę B i czekać, awarie i opóźnienia się propagują. Messaging rozwiązuje to: A publikuje wiadomość i kontynuuje; B przetwarza ją, kiedy jest gotowa.
Bezpieczniejsze obsługiwanie błędów. Nie każdy błąd powinien od razu stać się widoczny dla użytkownika. RabbitMQ pozwala na ponawiania w tle, izolowanie „trujących” wiadomości i unikanie utraty pracy podczas przejściowych przerw.
Zespoły zazwyczaj zyskują gładsze obciążenie (buforowanie szczytów), odseparowane usługi (mniej zależności w czasie wykonywania) oraz kontrolowane ponawiania (mniej ręcznego przetwarzania). Równie ważne — łatwiej jest ustalić, gdzie praca się zablokowała: u producenta, w kolejce czy w konsumencie.
Ten przewodnik skupia się na praktycznym użyciu RabbitMQ przez zespoły aplikacyjne: podstawowe koncepcje, typowe wzorce (pub/sub, work queues, ponawiania i dead-letter queues) oraz kwestie operacyjne (bezpieczeństwo, skalowanie, obserwowalność, debugowanie).
Nie jest to pełne opracowanie specyfikacji AMQP ani dogłębne omówienie wszystkich wtyczek RabbitMQ. Celem jest pomóc w projektowaniu przepływów wiadomości, które pozostaną utrzymywalne w rzeczywistych systemach.
RabbitMQ to broker wiadomości, który routuje wiadomości między częściami systemu, dzięki czemu producenci mogą przekazywać pracę, a konsumenci przetwarzać ją, gdy będą gotowi.
W bezpośrednim wywołaniu HTTP Usługa A wysyła żądanie do Usługi B i zazwyczaj czeka na odpowiedź. Jeśli Usługa B jest wolna lub nie działa, A się nieudanie kończy lub zawiesza, a w każdym wywołującym musisz obsługiwać timeouty, ponowienia i backpressure.
Z RabbitMQ (często przez AMQP) Usługa A publikuje wiadomość do brokera. RabbitMQ przechowuje i routuje ją do odpowiedniej kolejki(y), a Usługa B konsumuje asynchronicznie. Kluczowa zmiana polega na komunikacji przez trwałą warstwę pośrednią, która buforuje skoki i wygładza nierównomierne obciążenie.
Messaging jest dobrym wyborem, gdy:
Messaging nie jest dobry, gdy:
Synchronicznie (HTTP):
Serwis checkout wywołuje serwis fakturowania przez HTTP: „Utwórz fakturę.” Użytkownik czeka na zakończenie fakturowania. Jeśli fakturowanie jest wolne, wzrasta opóźnienie checkout; jeśli jest niedostępne, checkout nie powiedzie się.
Asynchronicznie (RabbitMQ):
Checkout publikuje invoice.requested z identyfikatorem zamówienia. Użytkownik dostaje natychmiast potwierdzenie przyjęcia zamówienia. Fakturujący konsumuje wiadomość, generuje fakturę, a następnie publikuje invoice.created do wykorzystania przez e-mail/ powiadomienia. Każdy krok może ponawiać niezależnie, a przejściowe awarie nie łamią całego przepływu.
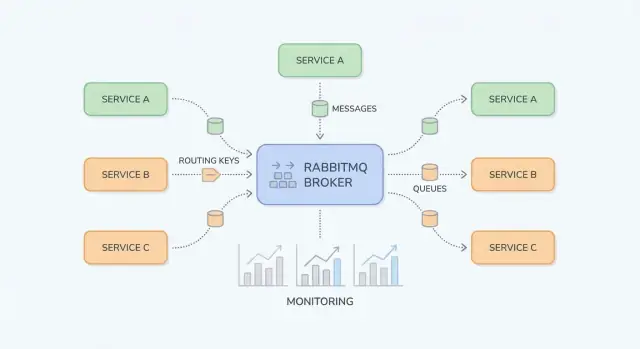
RabbitMQ najłatwiej zrozumieć, separując „gdzie publikowane są wiadomości” od „gdzie są przechowywane”. Producenci publikują do exchange; exchange routuje do kolejek; konsumenci czytają z kolejek.
Exchange nie przechowuje wiadomości. Oceni reguły i przekaże wiadomość do jednej lub więcej kolejek.
billing lub email).region=eu AND tier=premium), ale stosuj tylko w specjalnych przypadkach, bo jest trudniejszy do rozumienia.Kolejka to miejsce, gdzie wiadomości czekają, aż konsument je przetworzy. Kolejka może mieć jednego konsumenta lub wielu (competing consumers), a wiadomości zwykle dostarczane są do jednego konsumenta naraz.
Binding łączy exchange z kolejką i definiuje regułę routingu. To działa tak: „Gdy wiadomość trafi do exchange X z routing key Y, dostarcz ją do kolejki Q.” Możesz powiązać wiele kolejek z tą samą wymianą (pub/sub) lub związać jedną kolejkę pod wieloma kluczami routingu.
Dla direct exchange routing jest dokładny. Dla topic exchange klucze routingu wyglądają jak kropkami rozdzielone słowa, np.:
orders.createdorders.eu.refundedBindingi mogą zawierać wildcardy:
* pasuje dokładnie do jednego słowa (np. orders.* pasuje do orders.created)# pasuje do zera lub więcej słów (np. orders.# pasuje do orders.created i orders.eu.refunded)To pozwala dodawać nowych konsumentów bez zmiany producentów — wystarczy stworzyć nową kolejkę i związać ją z odpowiednim wzorcem.
Po dostarczeniu wiadomości, konsument raportuje wynik:
Uważaj z requeue: wiadomość, która zawsze zawodzi, może krążyć w kółko i blokować kolejkę. Wiele zespołów łączy nacky ze strategią ponowień i dead-letter queue, żeby awarie były obsługiwane przewidywalnie.
RabbitMQ błyszczy, gdy trzeba przenosić pracę lub powiadomienia między częściami systemu bez zmuszania wszystkiego do czekania na jeden wolny krok. Poniżej praktyczne wzorce pojawiające się w produktach.
Gdy wielu konsumentów powinno zareagować na to samo zdarzenie — bez wiedzy wydawcy — pub/sub jest dobrym wyborem.
Przykład: gdy użytkownik aktualizuje profil, możesz równolegle powiadomić indeksowanie wyszukiwania, analitykę i synchronizację CRM. Z fanout broadcastujesz do wszystkich powiązanych kolejek; z topic routujesz selektywnie (np. user.updated, user.deleted). To unika ścisłego powiązania usług i pozwala dodawać subskrybentów bez zmiany producenta.
Jeśli zadanie trwa, wrzuć je do kolejki i pozwól workerom przetwarzać asynchronicznie:
To utrzymuje szybkie żądania webowe i pozwala skalować workerów niezależnie. Kolejka staje się „listą zadań”, a liczba workerów — „pokrętłem przepustowości”.
Wiele workflowów przekracza granice usług: order → billing → shipping. Zamiast jedna usługa wywołująca kolejną i blokującej, każda publikuje zdarzenie po zakończeniu swojego kroku. Downstream konsumuje zdarzenia i kontynuuje workflow.
To poprawia odporność (przejściowa awaria shipping nie psuje checkout) i klaruje odpowiedzialność: każda usługa reaguje na zdarzenia, które ją interesują.
RabbitMQ może być buforem między aplikacją a zależnościami, które są wolne lub niestabilne (API zewnętrzne, systemy legacy, bazy batch). Szybko enqueuj żądania, potem przetwarzaj z kontrolowanymi ponowieniami. Jeśli zależność jest niedostępna, praca kumuluje się bezpiecznie i odpływa później — zamiast powodować timeouty w całej aplikacji.
Jeśli planujesz wprowadzać kolejki stopniowo, mały „async outbox” lub pojedyncza kolejka zadań w tle to często dobry pierwszy krok (zobacz blog/next-steps-rollout-plan).
Konfiguracja RabbitMQ jest przyjemna, gdy trasy są przewidywalne, nazwy spójne, a payloady ewoluują bez łamania starszych konsumentów. Zanim dodasz kolejną kolejkę, upewnij się, że „historia” wiadomości jest oczywista: skąd pochodzi, jak jest routowana i jak kolega może ją debugować end-to-end.
Dobór właściwej wymiany zmniejsza doraźne bindingi i niespodziewane fan-outy:
billing.invoice.created).billing.*.created, *.invoice.*). To najczęstszy wybór dla utrzymywalnego routingu zdarzeń.Zasada: jeśli wymyślasz skomplikowaną logikę routingu w kodzie, prawdopodobnie należy użyć topic exchange.
Traktuj ciało wiadomości jak publiczne API. Używaj jawnego wersjonowania (np. pole schema_version: 2) i dąż do kompatybilności wstecznej:
To pozwala starszym konsumentom działać, podczas gdy nowe adaptują się we własnym tempie.
Ułatw debugowanie przez standardyzację metadanych:
correlation_id: łączy polecenia/zdarzenia należące do jednej akcji biznesowej.trace_id (lub W3C traceparent): łączy wiadomości ze śledzeniem rozproszonym przez HTTP i przepływy asynchroniczne.Gdy każdy wydawca ustawia je konsekwentnie, możesz śledzić jedną transakcję przez wiele usług bez zgadywania.
Używaj przewidywalnych, możliwych do wyszukania nazw. Jeden powszechny wzorzec:
<domain>.<type> (np. billing.events)<domain>.<entity>.<verb> (np. billing.invoice.created)<service>.<purpose> (np. reporting.invoice_created.worker)Spójność bije pomysłowość: przyszły ty (i rota on-call) podziękuje.
Niezawodne messaging to w dużej mierze planowanie awarii: konsumenci padają, downstream API timeoutują, a niektóre zdarzenia są po prostu niepoprawne. RabbitMQ daje narzędzia, ale kod aplikacji musi współpracować.
Popularna konfiguracja to at-least-once delivery: wiadomość może być dostarczona więcej niż raz, ale nie powinna być cicho utracona. Dzieje się tak, gdy konsument otrzyma wiadomość, zacznie pracę, a potem padnie przed potwierdzeniem — RabbitMQ ponownie ją dostarczy.
W praktyce: duplikaty są normalne, więc handler musi być bezpieczny do wielokrotnego uruchamiania.
Idempotencja oznacza „przetworzenie tej samej wiadomości dwa razy daje taki sam efekt jak przetworzenie raz”. Przydatne podejścia:
message_id (lub klucz biznesowy jak order_id + event_type + version) i zapisuj w tabeli/cache przetworzone ID z TTL.PENDING) lub ograniczeń unikalności w bazie, by zapobiec podwójnym tworzeniom.Ponawiania lepiej traktować jako osobny przepływ, nie ciasną pętlę w konsumencie.
Typowy wzorzec:
To tworzy backoff bez trzymania wiadomości jako niepotwierdzonych.
Część wiadomości nigdy nie zadziała (zły schemat, brak danych referencyjnych, błąd w kodzie). Wykrywaj je po:
Skieruj takie wiadomości do DLQ jako operacyjna skrzynka odbiorcza: analizuj payloady, naprawiaj problem, a następnie ręcznie odtwarzaj wybrane wiadomości (najlepiej przez kontrolowane narzędzie/skrypt), zamiast wrzucać wszystko z powrotem do głównej kolejki.
Wydajność RabbitMQ jest zwykle ograniczona przez kilka praktycznych czynników: jak zarządzasz połączeniami, jak szybko konsumenci mogą bezpiecznie przetwarzać pracę i czy kolejki są używane jako „magazyn”. Celem jest stała przepustowość bez narastającego backlogu.
Częstym błędem jest otwieranie nowego połączenia TCP dla każdego producenta lub konsumenta. Połączenia są cięższe niż myślisz (handshake, heartbeaty, TLS), więc trzymaj je długotrwale i ponownie używaj.
Używaj kanałów do multipleksowania pracy na mniejszej liczbie połączeń. Reguła: kilka połączeń, wiele kanałów. Nie twórz jednak tysięcy kanałów bezmyślnie — każdy kanał ma narzut, a biblioteka klienta może mieć swoje limity. Preferuj mały pool kanałów na usługę i ponowną ich używalność do publikacji.
Jeśli konsumenci pobierają zbyt wiele wiadomości naraz, zobaczysz skoki pamięci, długie czasy przetwarzania i nierówne opóźnienia. Ustaw prefetch (QoS), by każdy konsument miał kontrolowaną liczbę niepotwierdzonych wiadomości.
Praktyczne wskazówki:
Duże wiadomości zmniejszają przepustowość i zwiększają presję pamięciową (u producentów, brokera i konsumentów). Jeśli payload jest duży (dokumenty, obrazy, duże JSON-y), rozważ przechowywanie go gdzie indziej (object storage lub baza) i wysyłanie tylko ID + metadanych przez RabbitMQ.
Dobra heurystyka: trzymaj wiadomości w zakresie KB, nie MB.
Wzrost kolejki to objaw, nie strategia. Dodaj backpressure, by producenci zwalniali, gdy konsumenci nie nadążają:
W razie wątpliwości zmieniaj jedną rzecz naraz i mierz: publish rate, ack rate, długość kolejki i end-to-end latency.
Bezpieczeństwo RabbitMQ to głównie uszczelnianie „brzegów”: jak klienci się łączą, kto może co robić i jak trzymać poświadczenia z dala od niepowołanych rąk. Użyj poniższej checklisty jako bazę i dostosuj do wymagań compliance.
Uprawnienia RabbitMQ są pomocne, gdy używasz ich konsekwentnie.
Dla utwardzania operacyjnego (porty, firewalle, audyt) miej krótki runbook wewnętrzny i odwołanie do dokumentacji wewnętrznej dotyczącej bezpieczeństwa.
Gdy RabbitMQ zawodzi, symptomy często widać najpierw w aplikacji: wolne endpointy, timeouty, brak aktualizacji lub zadania, które „nigdy się nie kończą”. Dobra obserwowalność pozwala potwierdzić, czy broker jest przyczyną, wskazać wąskie gardła (producent, broker czy konsument) i zareagować zanim użytkownicy to zauważą.
Zacznij od niewielkiego zestawu sygnałów:
Alertuj na trendy, nie tylko progi absolutne.
Logi brokera pomogą odróżnić „RabbitMQ padł” od „klienci go źle używają”. Szukaj błędów uwierzytelniania, blokad zasobów (resource alarms) i częstych błędów kanałów. Po stronie aplikacji loguj każdą próbę przetworzenia z correlation_id, nazwą kolejki i wynikiem (acked, rejected, retried).
Jeśli używasz rozproszonego śledzenia, propaguj nagłówki trace przez właściwości wiadomości, by połączyć „żądanie API → opublikowana wiadomość → praca konsumenta”.
Zbuduj jeden dashboard na krytyczny przepływ: publish rate, ack rate, depth, unacked, requeues i liczba konsumentów. Dodaj odnośniki w dashboardzie do wewnętrznego runbooka i checklistę „co sprawdzić najpierw” dla osoby on-call.
Gdy coś „po prostu przestaje się ruszać”, powstrzymaj chęć natychmiastowego restartu. Większość problemów jest oczywista, gdy spojrzysz na (1) bindingi i routing, (2) zdrowie konsumentów i (3) alarmy zasobów.
Jeśli producenci raportują „wysłano pomyślnie”, ale kolejki są puste (lub zapełnia się niewłaściwa kolejka), sprawdź routing zanim zajrzysz do kodu.
Zacznij od UI Management:
topic).Jeśli kolejka ma wiadomości, ale nikt ich nie konsumuje, sprawdź:
Duplikaty zwykle wynikają z ponowień (konsument padł po przetworzeniu, ale przed ack), przerwań sieciowych lub ręcznego requeue. Rozwiązaniem jest idempotencja handlerów (np. deduplikacja po message ID w bazie).
Przetwarzanie poza kolejnością jest oczekiwane przy wielu konsumentach lub requeue. Jeśli kolejność ma znaczenie, użyj pojedynczego konsumenta dla tej kolejki lub partycjonuj według klucza do wielu kolejek.
Alarmy oznaczają, że RabbitMQ chroni siebie.
Zanim odtworzysz, napraw przyczynę i zapobiegaj pętlom „trujących” wiadomości. Odtwarzaj w małych partiach, dodaj limit ponowień i dodawaj metadane błędu (liczba prób, ostatni błąd). Rozważ wysyłanie odtwarzanych wiadomości najpierw do oddzielnej kolejki, by szybko zatrzymać proces, jeśli błąd się powtórzy.
Wybór narzędzia do messagingu to mniej kwestia „najlepsze” a bardziej dopasowania do wzorca ruchu, tolerancji błędów i komfortu operacyjnego.
RabbitMQ sprawdza się, gdy potrzebujesz niezawodnej dostawy wiadomości i elastycznego routingu między komponentami aplikacji. To mocny wybór dla klasycznych workflowów asynchronicznych — komend, zadań w tle, powiadomień fan-out i wzorców request/response — szczególnie gdy chcesz:
Jeśli twoje aplikacje są event-driven, a głównym celem jest przenoszenie pracy zamiast utrzymywania długiej historii zdarzeń, RabbitMQ jest często komfortowym wyborem domyślnym.
Kafka i podobne platformy są budowane pod kątem wysokiego przepływu i długotrwałych logów zdarzeń. Wybierz system typu Kafka, gdy potrzebujesz:
Kosztem jest większy narzut operacyjny i projektowanie pod przepustowość (batching, strategie partycjonowania). RabbitMQ z reguły jest prostszy dla niskiego-do-średniego ruchu z niższym end-to-end latency i bardziej złożonym routingiem.
Jeśli masz jedną aplikację produkującą zadania i jeden pool workerów je konsumujący — i akceptujesz prostszą semantykę — kolejka oparta na Redis (lub zarządzana usługa zadań) może wystarczyć. Zespół zwykle „wyrasta” z tego, gdy potrzebuje silniejszych gwarancji dostawy, dead-letterów, wielu wzorców routingu lub wyraźnego oddzielenia producentów od konsumentów.
Projektuj kontrakty wiadomości tak, jakbyś mógł kiedyś przejść dalej:
Jeśli później potrzebujesz replayowalnych strumieni, często możesz przepiąć zdarzenia z RabbitMQ do systemu logowego, zachowując RabbitMQ dla operacyjnych workflowów. Dla praktycznego planu rollout zobacz blog/rabbitmq-rollout-plan-and-checklist.
Wprowadzanie RabbitMQ najlepiej traktować jak produkt: zacznij od małego zakresu, zdefiniuj właścicieli i udowodnij niezawodność zanim rozszerzysz użycie.
Wybierz jeden workflow, który skorzysta z asynchronicznego przetwarzania (np. wysyłka maili, generowanie raportów, sync do API zewnętrznego).
Jeśli potrzebujesz wzorca referencyjnego dla nazewnictwa, poziomów retry i podstawowych polityk, trzymaj go w centralnej dokumentacji.
W miarę implementacji ustandaryzuj szablony między zespołami. Na przykład zespoły używające Koder.ai często generują szkielet producenta/konsumenta z promptu (wraz z konwencjami nazewnictwa, wiringiem retry/DLQ i nagłówkami trace/correlation), potem eksportują kod do przeglądu i iterują w trybie planowania przed rolloutem.
RabbitMQ działa, gdy „ktoś jest właścicielem kolejki”. Ustal to przed produkcją:
Jeśli formalizujesz wsparcie lub hosting zarządzany, uzgodnij oczekiwania wcześnie (wspomniane w źródle informacji o cenach i kontakcie).
Użyj RabbitMQ, gdy chcesz rozłączyć usługi, wchłonąć skoki ruchu lub przenieść długotrwałą pracę poza ścieżkę żądania.
Dobre zastosowania to zadania w tle (maile, generowanie PDF-ów), powiadomienia dla wielu konsumentów oraz workflowy, które mają działać podczas przejściowych awarii zależności.
Unikaj go, gdy naprawdę potrzebujesz natychmiastowej odpowiedzi (proste odczyty/walidacja) lub gdy nie możesz zaangażować się w wersjonowanie wiadomości, ponawiania i monitoring — w produkcji to nie są opcje do pominięcia.
Publikuj do wymiany, a następnie routuj do kolejek:
orders.* lub orders.#.Większość zespołów domyślnie wybiera topic exchanges dla utrzymywalnego routingu zdarzeń.
Kolejka przechowuje wiadomości do momentu ich przetworzenia; binding to reguła łącząca wymianę z kolejką.
Aby debugować problemy z routingiem:
Te trzy kontrole wyjaśniają większość przypadków „opublikowano, ale nie zużyto”.
Użyj work queue, gdy chcesz, żeby jedno z wielu workerów przetworzyło zadanie.
Praktyczne wskazówki:
At-least-once delivery oznacza, że wiadomość może zostać dostarczona więcej niż raz (np. gdy konsument padnie po wykonaniu pracy, ale przed ack).
Uczyń konsumentów bezpiecznymi przez:
message_id (lub klucza biznesowego) i rejestrowanie przetworzonych ID z TTL.PENDING), ograniczenia unikalności w bazie.Unikaj ciasnych pętli requeue w konsumencie. Popularne podejście: „kolejki retry” + DLQ:
Odtwarzaj z DLQ dopiero po naprawieniu przyczyny i rób to w małych partiach.
Traktuj kontrakty wiadomości jak publiczne API:
schema_version do ładunku.Standaryzuj też metadane:
Skoncentruj się na kilku sygnałach pokazujących, czy praca przepływa:
Alertuj o trendach (np. „backlog rośnie od 10 minut”), a w logach umieszczaj nazwę kolejki, correlation_id i wynik przetwarzania (acked/retried/rejected).
Rób podstawy konsekwentnie:
Miej krótki wewnętrzny runbook, by zespoły trzymały się jednego standardu (np. odwołanie z tekstu o dokumentacji).
Zlokalizuj, gdzie przepływ się zatrzymuje:
Restart rzadko jest pierwszym lub najlepszym krokiem.
Zakładaj, że duplikaty są normalne i projektuj pod to.
correlation_id do powiązania zdarzeń/komend z jednym biznesowym działaniem.trace_id (lub nagłówki W3C) do łączenia pracy asynchronicznej z rozproszonym śledzeniem.To ułatwia wdrożenia i reakcję na incydenty.