10 paź 2025·8 min
Redis dla aplikacji: wzorce, pułapki i wskazówki
Poznaj praktyczne sposoby użycia Redis w aplikacjach: cache, sesje, kolejki, pub/sub i limitowanie żądań — plus skalowanie, persistence, monitoring i typowe pułapki.
Poznaj praktyczne sposoby użycia Redis w aplikacjach: cache, sesje, kolejki, pub/sub i limitowanie żądań — plus skalowanie, persistence, monitoring i typowe pułapki.
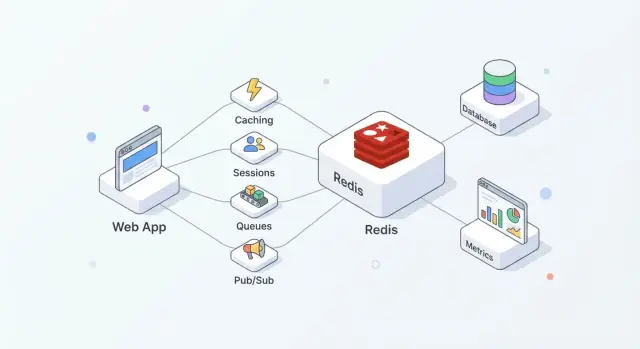
Redis to magazyn danych w pamięci często używany jako współdzielona „szybka warstwa” dla aplikacji. Zespoły go lubią, bo jest prosty do wdrożenia, bardzo szybki dla typowych operacji i na tyle elastyczny, że może pełnić więcej niż jedną funkcję (cache, sesje, liczniki, kolejki, pub/sub) bez wprowadzania nowego systemu dla każdej roli.
W praktyce Redis działa najlepiej, gdy traktujesz go jako szybkość + koordynację, a Twoja główna baza danych pozostaje źródłem prawdy.
Typowa konfiguracja wygląda tak:
Ten podział utrzymuje bazę skupioną na poprawności i trwałości, podczas gdy Redis absorbuje odczyty/zapisy o wysokiej częstotliwości, które w innym wypadku podniosłyby opóźnienia lub obciążenie.
Dobrze użyty Redis przynosi kilka praktycznych efektów:
Redis nie zastępuje głównej bazy danych. Jeśli potrzebujesz złożonych zapytań, długoterminowych gwarancji przechowywania lub raportowania analitycznego, baza danych jest właściwym miejscem.
Nie zakładaj też, że Redis jest „trwały domyślnie”. Jeśli utrata nawet kilku sekund danych jest nieakceptowalna, potrzebne będą staranne ustawienia persistence — albo inny system — zależnie od Twoich wymagań odzyskiwania.
Redis często opisywany jest jako „store klucz-wartość”, ale lepiej myśleć o nim jako bardzo szybkich serwerze, który przechowuje i manipuluje małymi fragmentami danych po nazwie (kluczu). Ten model zachęca do przewidywalnych wzorców dostępu: zwykle dokładnie wiesz, czego chcesz (sesja, zcache’owana strona, licznik), a Redis może to pobrać lub zaktualizować w jednej rundzie.
Redis trzyma dane w RAM, dlatego odpowiada w mikrosekundach do niskich milisekund. Kosztem jest to, że pamięć RAM jest ograniczona i droższa niż dysk.
Zdecyduj wcześnie, czy Redis będzie:
Redis może persistować dane na dysk (snapshoty RDB i/lub AOF append-only logs), ale persistence dodaje narzut zapisu i wymaga wyborów dotyczących trwałości (np. „szybko, ale można stracić sekundę” vs „wolniej, ale bezpieczniej”). Traktuj persistence jako pokrętło, które ustawiasz według wpływu biznesowego, a nie jako opcję, którą automatycznie włączasz.
Redis wykonuje polecenia głównie w jednym wątku, co brzmi jak ograniczenie, dopóki nie pamiętasz o dwóch rzeczach: operacje są zwykle małe, i nie ma narzutu blokowania między wieloma wątkami roboczymi. Jeśli unikasz droższych poleceń i zbyt dużych ładunków, ten model może być bardzo wydajny przy dużej konkurencyjności.
Twoja aplikacja rozmawia z Redis po TCP przez biblioteki klienckie. Używaj puli połączeń, trzymaj żądania małe i preferuj batchowanie/pipelining, gdy potrzebujesz wielu operacji.
Planuj timeouty i retry: Redis jest szybki, ale sieci nie są, i aplikacja powinna degradować się łagodnie, gdy Redis jest przeciążony lub chwilowo niedostępny.
Jeśli budujesz nowy serwis i chcesz szybko wystandaryzować te podstawy, platforma taka jak Koder.ai może pomóc w szybkim szkielecie aplikacji React + Go + PostgreSQL oraz dodaniu funkcji opartych na Redis (cache, sesje, limitowanie) przez workflow sterowany czatem — a jednocześnie pozwalając wyeksportować kod i uruchomić go gdziekolwiek potrzebujesz.
Cache pomaga tylko wtedy, gdy ma jasnego właściciela: kto go wypełnia, kto go unieważnia i co oznacza „wystarczająco świeże”.
Cache-aside oznacza, że to aplikacja — nie Redis — kontroluje odczyty i zapisy.
Typowy przebieg:
Redis to szybki store klucz-wartość; Twoja aplikacja decyduje, jak serializować, wersjonować i wygaśniać wpisy.
TTL to decyzja produktowa tak samo jak techniczna. Krótkie TTL zmniejszają nieświeżość, ale zwiększają obciążenie bazy; długie TTL oszczędzają pracę, ale ryzykują nieaktualne wyniki.
Praktyczne wskazówki:
user:v3:123), by stare cache’y nie łamały nowego kodu.Gdy gorący klucz wygasa, wiele żądań może trafić jednocześnie na miss.
Typowe obrony:
Dobrymi kandydatami są odpowiedzi API, kosztowne wyniki zapytań i obiekty obliczeniowe (rekomendacje, agregacje). Cache’owanie całych stron HTML działa, ale uważaj na personalizację i uprawnienia — cache’uj fragmenty, gdy logika jest specyficzna dla użytkownika.
Redis to praktyczne miejsce na krótkotrwały stan logowania: identyfikatory sesji, metadane refresh-tokenów i flagi „zapamiętaj to urządzenie”. Celem jest szybka autoryzacja przy jednoczesnej kontroli czasu życia sesji i unieważniania.
Powszechny wzorzec: aplikacja wydaje losowy identyfikator sesji, zapisuje kompaktowy rekord w Redis i zwraca ID do przeglądarki jako cookie HTTP-only. Przy każdym żądaniu sprawdzasz klucz sesji i dołączasz tożsamość użytkownika oraz uprawnienia do kontekstu żądania.
Redis sprawdza się, bo odczyty sesji są częste, a TTL sesji jest wbudowany.
Projektuj klucze tak, by łatwo je skanować i unieważniać:
sess:{sessionId} → ładunek sesji (userId, issuedAt, deviceId)user:sessions:{userId} → Set aktywnych sessionId (opcjonalne, do „wyloguj wszędzie”)Użyj TTL na sess:{sessionId} odpowiadającego czasowi życia sesji. Jeśli rotujesz sesje (zalecane), stwórz nowe sessionId i usuń stare natychmiast.
Uważaj na „sliding expiration” (wydłużanie TTL przy każdym żądaniu): może to utrzymywać sesje przy życiu nieskończenie długo dla intensywnych użytkowników. Bezpieczniejszym kompromisem jest wydłużanie TTL tylko gdy zbliża się do wygaśnięcia.
Aby wylogować jedno urządzenie, usuń sess:{sessionId}.
Aby wylogować wszystkie urządzenia, możesz:
user:sessions:{userId}, lubuser:revoked_after:{userId} jako znacznik czasu i traktować sesje wydane przed nim jako nieważneMetoda z timestampem unika dużego fan-outu przy usuwaniu.
Przechowuj minimum niezbędne w Redis — lepiej ID niż dane osobowe. Nigdy nie zapisuj surowych haseł ani długowiecznych sekretów. Jeśli musisz trzymać dane związane z tokenami, przechowuj hasze i stosuj krótkie TTL.
Ogranicz, kto może się połączyć z Redis, wymuś uwierzytelnianie i używaj wysokiej entropii dla ID sesji, by zapobiec zgadywaniu.
Limitowanie żądań to miejsce, w którym Redis błyszczy: jest szybki, współdzielony między instancjami aplikacji i oferuje atomowe operacje, które utrzymują spójność liczników przy dużym ruchu. Przydaje się do ochrony endpointów logowania, kosztownych wyszukiwań, resetów hasła i każdego API, które może zostać zeskrobane lub zaatakowane brute-force.
Fixed window: najprostszy — „100 żądań na minutę”. Liczysz żądania w bieżącym bucketcie. Łatwy, ale pozwala na skoki przy granicach (np. 100 o 12:00:59 i 100 o 12:01:00).
Sliding window: wygładza granice, patrząc na ostatnie N sekund/minut zamiast tylko aktualnego bucketa. Sprawiedliwszy, ale zwykle droższy w implementacji (może wymagać sorted setów lub więcej księgowości).
Token bucket: dobry do obsługi burstów. Użytkownicy „zarabiają” tokeny w czasie do pewnego limitu; każde żądanie zużywa token. Pozwala na krótkie skoki, utrzymując średnią prędkość.
Typowy wzorzec fixed-window:
INCR key — zwiększ licznikEXPIRE key window_seconds — ustaw TTLTrik polega na wykonaniu tego bezpiecznie. Jeśli uruchomisz INCR i EXPIRE jako oddzielne wywołania, awaria między nimi może stworzyć klucze bez wygaśnięcia.
Bezpieczniejsze podejścia:
INCR i ustawi EXPIRE tylko przy pierwszym tworzeniu licznika.SET key 1 EX <ttl> NX do inicjalizacji, a potem INCR (często i tak opakowane w skrypt, by uniknąć wyścigów).Atomowość ma największe znaczenie przy skokach ruchu: bez niej dwa żądania mogą „widzieć” tę samą pozostałą kwotę i oba przejdą.
Większość aplikacji potrzebuje wielowarstwowego podejścia:
rl:user:{userId}:{route})Dla burstujących endpointów token bucket (lub hojne fixed window plus krótki „burst window”) pomaga nie karać legalnych skoków, jak ładowanie strony czy reconnect mobilny.
Zdecyduj wcześniej, co oznacza „bezpieczeństwo”:
Częsty kompromis: fail-open dla mało ryzykownych tras i fail-closed dla wrażliwych (logowanie, reset hasła, OTP), z monitoringiem by natychmiast zauważyć, że limitowanie przestało działać.
Redis może napędzać zadania w tle, gdy potrzebujesz lekkiej kolejki do wysyłki e-maili, zmiany rozmiaru obrazów, synchronizacji danych czy zadań okresowych. Kluczem jest wybór odpowiedniej struktury danych i jasne zasady retry oraz obsługi błędów.
Listy są najprostszą kolejką: producenci LPUSH, workerzy BRPOP. Proste, ale potrzebujesz dodatkowej logiki dla „in-flight” jobów, retry i visibility timeout.
Sorted sets sprawdzają się, gdy ważne jest harmonogramowanie. Użyj score jako znacznika czasowego (lub priorytetu), a workerzy pobierają kolejne zadania, które nadeszły. Pasuje do zadań opóźnionych i kolejek priorytetowych.
Streams często są najlepszym domyślnym wyborem do trwałego rozdzielania pracy. Obsługują consumer groups, przechowują historię i pozwalają wielu workerom koordynować się bez wynajdowania własnej listy przetwarzania.
W Streams consumer groups worker czyta wiadomość, a potem ją ACKuje. Jeśli worker padnie, wiadomość zostaje jako pending i może ją przejąć inny worker.
Dla retry śledź liczbę prób (w payloadzie wiadomości lub w bocznym kluczu) i stosuj backoff wykładniczy (często przez sorted set jako harmonogram retry). Po osiągnięciu limitu przenoś zadanie do dead-letter queue (inny stream lub lista) do ręcznej analizy.
Zakładaj, że zadania mogą się wykonać dwukrotnie. Spraw, by handlery były idempotentne przez:
job:{id}:done) z SET ... NX przed efektami ubocznymiTrzymaj payloady małe (duże dane trzymane gdzie indziej, przekazuj referencje). Dodaj backpressure przez limitowanie długości kolejki, spowalnianie producentów przy rosnącym backlogu i skalowanie workerów na podstawie zaległości i czasu przetwarzania.
Redis Pub/Sub to najprostszy sposób broadcastu zdarzeń: wydawca wysyła wiadomość na kanał, a każdy podłączony subskrybent ją otrzymuje natychmiast. Nie ma pollingu — tylko lekkie „push”, które dobrze działa dla aktualizacji w czasie rzeczywistym.
Pub/Sub błyszczy, gdy zależy Ci na szybkości i fan-out, a nie na gwarantowanej dostawie:
Dobry model mentalny: Pub/Sub to stacja radiowa — każdy, kto jest „ustawiony”, usłyszy transmisję, ale nikt nie otrzyma automatycznego nagrania.
Pub/Sub ma istotne kompromisy:
Dlatego Pub/Sub nie nadaje się do workflowów, w których każde zdarzenie musi zostać przetworzone.
Jeśli potrzebujesz trwałości, retry, grup konsumentów lub backpressure, zwykle lepsze będą Redis Streams. Streams pozwalają przechowywać zdarzenia, przetwarzać je z potwierdzeniami i odzyskiwać po restarcie — bliżej lekkiej kolejki wiadomości.
W realnych wdrożeniach masz wiele instancji aplikacji subskrybujących. Kilka praktycznych wskazówek:
app:{env}:{domain}:{event} (np. shop:prod:orders:created).notifications:global, a użytkowników targetuj notifications:user:{id}.Użyte w ten sposób Pub/Sub jest szybkim sygnałem wydarzenia, podczas gdy Streams (lub inna kolejka) obsługuje zdarzenia, których nie możesz sobie pozwolić stracić.
Wybór struktury danych wpływa na zużycie pamięci, szybkość zapytań i prostotę kodu w dłuższej perspektywie. Dobra zasada: wybierz strukturę pasującą do pytań, które będziesz zadawać później (wzorce odczytów), nie tylko do tego, jak chcesz dziś przechować dane.
INCR/DECR.SISMEMBER i proste operacje na zbiorach.Operacje Redis są atomowe na poziomie polecenia, więc możesz bezpiecznie inkrementować liczniki bez warunków wyścigu. Wyświetlenia stron i liczniki limitów żądań zwykle używają stringów z INCR i expiry.
Rankingi to domena sorted sets: możesz aktualizować wyniki (ZINCRBY) i pobierać topkę (ZREVRANGE) wydajnie, bez skanowania wszystkich wpisów.
Jeśli tworzysz wiele kluczy jak user:123:name, user:123:email, user:123:plan, mnożysz narzut meta danego klucza i utrudniasz zarządzanie. Hash user:123 z polami (name, email, plan) trzyma powiązane dane razem i zwykle zmniejsza liczbę kluczy. Ułatwia też częściowe aktualizacje (zmiana jednego pola zamiast przepisywania całego JSON).
W razie wątpliwości zmodeluj małą próbkę i zmierz użycie pamięci przed podjęciem decyzji dla danych o wysokiej skali.
Redis często nazywany jest „in-memory”, ale masz wybór, co dzieje się przy restarcie węzła, zapełnieniu dysku czy utracie serwera. Odpowiednia konfiguracja zależy od tego, ile danych możesz stracić i jak szybko musisz się odzyskać.
RDB snapshoty zapisują punktowy zrzut zestawu danych. Są kompaktowe i szybkie do załadowania przy starcie, co przyspiesza restarty. Kosztem jest możliwość utraty najnowszych zapisów od ostatniego snapshotu.
AOF (append-only file) loguje operacje zapisu w czasie rzeczywistym. Zwykle zmniejsza potencjalną utratę danych, bo zapisuje zmiany częściej. Pliki AOF mogą rosnąć, a odtwarzanie przy starcie może trwać dłużej — Redis potrafi jednak przepisać/kompresować AOF, by utrzymać to w ryzach.
Wiele zespołów uruchamia oba: snapshoty dla szybszych restartów i AOF dla lepszej trwałości zapisu.
Persistence nie jest za darmo. Zapis na dysk, polityki fsync AOF i operacje background rewrite mogą generować skoki latencji, jeśli storage jest wolny lub przeciążony. Z drugiej strony persistence sprawia, że restarty są mniej przerażające: bez persistence nieplanowany restart oznacza pusty Redis.
Replikacja utrzymuje kopię danych na replikach, by móc przełączyć się przy awarii primary. Zwykle celem jest dostępność, nie absolutna spójność. Przy awarii repliki mogą być nieco opóźnione, a failover może spowodować utratę ostatnich potwierdzonych zapisów w niektórych scenariuszach.
Zanim cokolwiek stuningujesz, zapisz dwie liczby:
Użyj tych celów, by dobrać częstotliwość RDB, ustawienia AOF i czy potrzebujesz replik i automatycznego failoveru dla roli Redis — cache, store sesji, kolejka czy główny store.
Jedna instancja Redis potrafi zaskakująco dużo: jest prosta w obsłudze, łatwa do zrozumienia i często wystarczająco szybka dla wielu obciążeń cache, sesji czy kolejek.
Skalowanie staje się konieczne, gdy trafiasz na twarde limity — zwykle sufit pamięci, saturacja CPU lub węzeł staje się pojedynczym punktem awarii, którego nie możesz zaakceptować.
Rozważ dodanie węzłów, gdy spełniony jest któryś z warunków:
Praktyczny pierwszy krok to często rozdzielenie obciążeń (dwie niezależne instancje Redis) zanim skoczysz do klastra.
Sharding to dzielenie kluczy między wiele węzłów, tak by każdy węzeł trzymał część danych. Redis Cluster to wbudowany sposób, by robić to automatycznie: przestrzeń kluczy dzieli się na sloty, a każdy węzeł jest właścicielem niektórych slotów.
Zysk to więcej pamięci i większa łączna przepustowość. Cena to większa złożoność: operacje wielokluczowe mają ograniczenia (klucze muszą być na tym samym shardzie), a debugowanie wymaga więcej uwagi.
Nawet przy równym sharding’u ruch może być leworęczny. Jeden popularny klucz ("hot key") może przeciążyć jeden węzeł, podczas gdy inne będą bezczynne.
Sposoby łagodzenia: krótkie TTL z jitterem, podział wartości na wiele kluczy (key hashing) lub redesign wzorców dostępu, by rozłożyć odczyty.
Redis Cluster wymaga klienta, który potrafi odkryć topologię, routować żądania do odpowiedniego węzła i podążać za przekierowaniami, gdy sloty się przemieszczają.
Przed migracją upewnij się:
Skalowanie działa najlepiej jako planowana ewolucja: waliduj przez testy obciążeniowe, mierz opóźnienia kluczy i migruj ruch stopniowo, zamiast robić jednorazowy przełącznik.
Redis często traktowany jest jako „wewnętrzna instalacja”, właśnie dlatego jest częstym celem ataków: jeden otwarty port może prowadzić do wycieku danych lub przejęcia cache’u. Zakładaj, że Redis to wrażliwa infrastruktura, nawet jeśli przechowujesz tylko „tymczasowe” dane.
Zacznij od włączenia uwierzytelniania i używania ACL (Redis 6+). ACL pozwalają:
Unikaj współdzielenia jednego hasła ze wszystkimi komponentami. Wydawaj credy per-serwis i trzymaj uprawnienia wąskie.
Najskuteczniejszą kontrolą jest brak zasięgu. Bindowanie Redis do prywatnego interfejsu, umieszczenie go w prywatnej podsieci i ograniczanie ruchu przychodzącego regułami sieciowymi to podstawy.
Używaj TLS gdy ruch Redis przechodzi przez granice hostów, które nie są w pełni pod Twoją kontrolą (multi-AZ, sieci współdzielone, węzły Kubernetes, środowiska hybrydowe). TLS zapobiega podsłuchiwaniu i kradzieży poświadczeń — wartość dodana jest zwykle warta niewielkiego narzutu dla danych sesji czy tokenów.
Zablokuj polecenia, które mogą wyrządzić dużą szkodę przy nadużyciu. Przykłady do wyłączenia lub ograniczenia przez ACL: FLUSHALL, FLUSHDB, CONFIG, SAVE, DEBUG, EVAL (lub przynajmniej ostrożnie kontroluj skrypty). Podejście z rename-command może pomóc, ale ACL są zwykle czytelniejsze i łatwiejsze do audytu.
Przechowuj poświadczenia Redis w managerze sekretów (nie w kodzie ani obrazach kontenerów) i planuj rotację. Rotacja jest najprostsza, gdy klienci potrafią przeładować poświadczenia bez redeployu, albo gdy obsługujesz dwa ważne zestawy credów w oknie przejściowym.
Jeśli chcesz praktycznej checklisty, trzymaj ją w runbookach obok notatek /blog/monitoring-troubleshooting-redis.
Redis często „wydaje się w porządku”… aż ruch się zmieni, pamięć urośnie lub wolne polecenie zablokuje wszystko. Lekki monitoring i jasny checklist incydentowy zapobiegają większości niespodzianek.
Zacznij od małego zestawu, który każdy w zespole rozumie:
Gdy coś jest „wolne”, potwierdź to narzędziami Redisa:
KEYS, SMEMBERS czy dużych LRANGE to częsty sygnał alarmowy.Jeśli opóźnienia rosną przy normalnym CPU, sprawdź też sieć, nadmiarowe payloady lub zablokowane klientów.
Planuj wzrost, trzymając zapas (zwykle 20–30% wolnej pamięci) i przeglądaj założenia po uruchomieniach lub włączeniu funkcji. Traktuj „ciągłe evictions” jak awarię, nie ostrzeżenie.
W incydencie sprawdź (w tej kolejności): pamięć/evictions, opóźnienia, połączenia klientów, slowlog, lag replikacji i ostatnie deploye. Zapisz najczęściej powtarzające się przyczyny i popraw je na stałe — same alerty nie wystarczą.
Jeśli zespół szybko iteruje, pomocne może być wbudowanie tych oczekiwań operacyjnych w workflow deweloperski. Na przykład z trybem planowania i snapshotami w Koder.ai możesz prototypować funkcje z Redis (cache, rate limiting), testować je pod obciążeniem i bezpiecznie cofać — trzymając implementację w repozytorium przez eksport źródeł.
Redis najlepiej sprawdza się jako współdzielona, pamięciowa „szybka warstwa” do:
Utrzymuj dane trwałe i złożone zapytania w swojej głównej bazie danych. Traktuj Redis jako przyspieszacz i koordynator, nie jako system źródłowy.
Nie. Redis potrafi persistować dane, ale nie jest „trwały domyślnie”. Jeśli potrzebujesz złożonych zapytań, gwarancji trwałości czy analityki, trzymaj te dane w głównej bazie.
Jeśli utrata nawet kilku sekund danych jest nieakceptowalna, nie zakładaj, że ustawienia persistence w Redis spełnią wymagania bez starannej konfiguracji (albo rozważ inny system dla tego obciążenia).
Wybierz na podstawie dopuszczalnej utraty danych i zachowania przy restarcie:
Najpierw określ cele RPO/RTO, a potem dobierz ustawienia persistence.
W cache-aside logikę kontroluje aplikacja:
Sprawdza się, gdy aplikacja toleruje sporadyczne misses i gdy masz jasną strategię unieważniania/wygasania.
Wybieraj TTL pod kątem wpływu na użytkownika i obciążenia backendu:
user:v3:123) gdy kształt cache’u może się zmienić.Jeśli nie jesteś pewien, zacznij od krótszych TTL, zmierz obciążenie bazy, a potem dopasuj.
Użyj jednego (lub więcej) z tych rozwiązań:
Te wzorce zapobiegają jednoczesnym missom, które mogłyby przeciążyć bazę.
Powszechne podejście:
sess:{sessionId} z TTL dopasowanym do czasu życia sesji.user:sessions:{userId} jako Set aktywnych sessionId, by realizować „wyloguj wszędzie”.Unikaj rozszerzania TTL przy każdym żądaniu (sliding expiration) chyba że kontrolujesz to (np. tylko gdy zbliża się koniec ważności).
Używaj atomowych aktualizacji, by liczniki nie utknęły ani nie wystąpiły race condition:
INCR i EXPIRE jako oddzielnych, niesynchronizowanych wywołań.Przemyśl zakresy kluczy (per-user, per-IP, per-route) i zdecyduj, czy przy niedostępności Redis chcesz fail-open czy fail-closed — zwłaszcza dla wrażliwych endpointów.
Wybierz według potrzeb trwałości i operacyjnych wymagań:
LPUSH/BRPOP): proste, ale musisz samodzielnie obsłużyć retry, in-flight i timeouty.Używaj Pub/Sub do szybkich, real-time broadcastów, gdzie utrata wiadomości jest akceptowalna (presence, live dashboardy). Ma on:
Jeśli każde zdarzenie musi zostać przetworzone, wybierz Redis Streams dla trwałości, grup konsumentów, retry i backpressure. Dla porządku operacyjnego zabezpiecz Redis ACLami, izolacją sieciową i monitoruj opóźnienia/evictions; trzymaj runbook taki jak .
Przechowuj małe payloady; duże dane trzymaj poza Redis i przekazuj referencje.
/blog/monitoring-troubleshooting-redis