21 paź 2025·7 min
Renderowanie po stronie serwera (SSR) w witrynach: jasny przewodnik
Dowiedz się, co oznacza SSR (renderowanie po stronie serwera), jak działa i kiedy wybrać je zamiast CSR lub SSG ze względu na SEO, szybkość i UX.
SSR w witrynach: prosta definicja
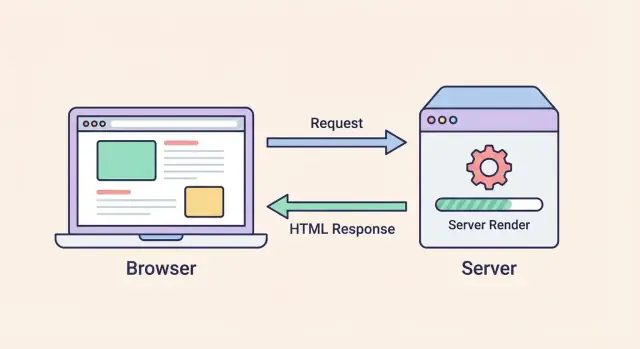
Server-side rendering (SSR) to sposób budowania stron, w którym serwer generuje HTML strony w momencie, gdy ktoś o nią prosi, a następnie wysyła gotowy do wyświetlenia HTML do przeglądarki.
Mówiąc prosto, SSR odwraca zwykły wzorzec „najpierw pusta powłoka”: zamiast wysyłać w przeglądarkę w dużej mierze pustą stronę i prosić ją o szybkie złożenie treści, serwer wykonuje początkowe renderowanie.
Co użytkownicy naprawdę odczuwają
Dzięki SSR ludzie zwykle widzą treść strony szybciej — teksty, nagłówki i układ mogą pojawić się szybko, ponieważ przeglądarka od razu otrzymuje prawdziwy HTML.
Po tym stronie przeglądarki wciąż potrzebny jest JavaScript, by strona stała się w pełni interaktywna (przyciski, menu, formularze, dynamiczne filtry). Typowy przebieg to:
- HTML przychodzi i się wyświetla (możesz przeczytać treść)
- JavaScript się pobiera i uruchamia
- Strona staje się interaktywna
Ten schemat „pokaż treść najpierw, potem dodaj interaktywność” jest powodem, dla którego SSR często pojawia się w rozmowach o wydajności (zwłaszcza o odczuwanej szybkości).
SSR to strategia renderowania, nie typ hostingu
SSR nie oznacza „hostowane na serwerze” (prawie wszystko jest). Chodzi konkretnie o to, gdzie powstaje początkowy HTML:
- Przy renderowaniu po stronie serwera HTML jest tworzony na serwerze dla każdego żądania (lub przy cache miss).
- Inne podejścia mogą tworzyć HTML w przeglądarce albo z wyprzedzeniem w czasie budowania.
Możesz korzystać z SSR na różnych środowiskach hostingu — tradycyjne serwery, funkcje serverless czy runtime’y edge — w zależności od frameworka i wdrożenia.
Co porównamy dalej
SSR to tylko jedna opcja wśród powszechnych strategii renderowania. Dalej porównamy SSR vs CSR (renderowanie po stronie klienta) i SSR vs SSG (statyczne generowanie stron), oraz wyjaśnimy konsekwencje dla szybkości, doświadczenia użytkownika, strategii cache i wyników SEO.
Jak działa renderowanie po stronie serwera
SSR oznacza, że serwer przygotowuje HTML strony zanim dotrze on do przeglądarki. Zamiast wysyłać pustą powłokę HTML i pozwalać przeglądarce zbudować stronę od zera, serwer wysyła „gotową do czytania” wersję strony.
Przepływ żądania SSR (krok po kroku)
- Żądanie: Osoba odwiedza URL (np.
/products/123). Przeglądarka wysyła żądanie do twojego serwera. - Pobranie danych: Serwer ustala, jakie dane są potrzebne do strony — może zapytać bazę danych, wywołać wewnętrzne usługi lub pobrać z zewnętrznych API.
- Renderowanie HTML na serwerze: Używając szablonu lub renderer’a frameworka (React/Vue itp. uruchamianego na serwerze), serwer łączy layout z pobranymi danymi i tworzy pełny HTML dla tej trasy.
- Odpowiedź: Serwer zwraca ten HTML do przeglądarki, dzięki czemu treść może pojawić się szybko.
Dlaczego nadal wysyłasz JavaScript
SSR zwykle wysyła HTML plus paczkę JavaScript. HTML służy do natychmiastowego wyświetlenia; JavaScript umożliwia zachowania po stronie klienta, takie jak filtry, modale czy „dodaj do koszyka”.
Po załadowaniu HTML przeglądarka pobiera paczkę JS i dołącza obsługę zdarzeń do istniejącego markup’u. Ten przekaz nazywa się często hydracją.
Co to oznacza w praktyce
Przy SSR serwer wykonuje więcej pracy dla każdego żądania — pobiera dane i renderuje markup — więc wynik zależy mocno od szybkości API/bazy danych i od tego, jak dobrze buforujesz wynik.
SSR i hydracja: dlaczego interaktywność nadal potrzebuje JavaScriptu
SSR wysyła „gotową do czytania” stronę HTML z serwera. To świetnie do szybkiego pokazania treści, ale samo w sobie nie czyni strony interaktywną.
Typowy wzorzec: SSR + hydracja
Bardzo powszechna konfiguracja wygląda tak:
- Serwer renderuje HTML dla trasy (tekst, linki, szczegóły produktu, layout).
- Przeglądarka natychmiast wyświetla ten HTML.
- JavaScript pobiera się i uruchamia, by zahydrować stronę — podłączyć obsługę zdarzeń i stan do już wyrenderowanego HTML.
SSR może poprawić to, jak szybko ludzie widzą stronę, podczas gdy hydracja sprawia, że strona zachowuje się jak aplikacja.
Co oznacza „hydracja” (i dlaczego dodaje pracy w przeglądarce)
Hydracja to proces, w którym JavaScript klienta przejmuje statyczny HTML i podłącza do niego interaktywność: obsługę kliknięć, walidację formularzy, menu, dynamiczne filtry i stan UI.
Ten dodatkowy krok kosztuje czas procesora i pamięć na urządzeniu użytkownika. Na wolniejszych telefonach lub w kartach obciążonych innymi zadaniami, hydracja może być wyraźnie opóźniona — nawet jeśli HTML dotarł szybko.
Gdy JavaScript jest wolny — lub się nie powiedzie
Kiedy JavaScript wolno się ładuje, użytkownicy mogą zobaczyć treść, ale doświadczyć „martwego” interfejsu przez chwilę: przyciski nie reagują, menu się nie otwierają, a pola mogą mieć opóźnienia.
Jeśli JavaScript w ogóle nie zadziała (zablokowany, błąd sieci, awaria skryptu), SSR wciąż pozwala wyświetlić podstawową treść. Jednak funkcje aplikacyjne zależne od JS nie będą działać, chyba że zaprojektowano fallbacky (np. linki, które normalnie nawigują, czy formularze wysyłające dane bez kodu po stronie klienta).
SSR nie znaczy „bez JavaScriptu”
SSR dotyczy miejsca generowania HTML. Wiele stron SSR nadal wysyła znaczną ilość JavaScriptu — czasem niemal tyle, co aplikacja CSR — ponieważ interaktywność nadal wymaga kodu działającego w przeglądarce.
SSR vs CSR: co się zmienia dla szybkości i UX
SSR i CSR mogą dać stronę o tym samym wyglądzie, lecz kolejność pracy jest inna — a to zmienia, jak szybko strona się „odczuwa”.
Co przeglądarka dostaje najpierw
Przy CSR przeglądarka zwykle pobiera najpierw pakiet JavaScript, a potem go uruchamia, by zbudować HTML. Dopóki ten proces się nie zakończy, użytkownik może widzieć pusty ekran, spinner lub „szkielet” UI. To może sprawiać wrażenie wolnego pierwszego widoku, nawet jeśli aplikacja działa szybko po załadowaniu.
Przy SSR serwer wysyła gotowy do wyświetlenia HTML od razu. Użytkownik może szybciej zobaczyć nagłówki, tekst i układ, co często poprawia odczuwalną prędkość — zwłaszcza na wolniejszych urządzeniach czy łączach.
Interaktywność i „czas do używalności”
CSR często błyszczy po początkowym załadowaniu: nawigacja między ekranami jest szybka, bo aplikacja już działa w przeglądarce.
SSR może wydawać się szybszy na początku, ale strona nadal potrzebuje JavaScriptu, by stać się w pełni interaktywna (przyciski, menu, formularze). Jeśli JavaScript jest ciężki, użytkownicy mogą zobaczyć treść szybko, ale doświadczyć krótkiego opóźnienia zanim wszystko zareaguje.
Kompromisy wpływające na UX
- Zalety SSR: szybsze widoczne treści, lepsze pierwsze wrażenie, często lepsze dla stron o dużej ilości treści.
- Zalety CSR: prostsze hostowanie, mniej problemów z renderowaniem na serwerze, dobre dla bardzo interaktywnych doświadczeń wewnątrz aplikacji.
- Koszty SSR: większe obciążenie serwera, więcej elementów do ogarnięcia (cache, personalizacja, obsługa błędów).
Proste przykłady
- Strony marketingowe, blogi, dokumentacja: SSR często poprawia pierwszy widok i czytelność.
- Panele administracyjne, narzędzia wewnętrzne: CSR może pasować lepiej, bo użytkownicy logują się i intensywnie wchodzą w interakcje; szybka nawigacja w aplikacji jest ważniejsza niż pierwszy paint.
SSR vs SSG: kiedy strony są budowane
Udowodnij crawlability szybko
Szybko sprawdź SEO (metadane i indeksowalny HTML) dzięki działającemu prototypowi.
SSR i SSG mogą wyglądać podobnie dla odwiedzających — obie często wysyłają prawdziwy HTML do przeglądarki. Kluczowa różnica to kiedy ten HTML jest tworzony.
SSG: strony budowane podczas wdrożenia
Przy SSG strona generuje HTML z wyprzedzeniem — zwykle podczas procesu buildu przy wdrożeniu. Pliki te można serwować z CDN jak zwykłe zasoby statyczne.
To sprawia, że SSG jest:
- bardzo szybkie w dostawie (świetna cacheowalność)
- przewidywalne przy nagłych skokach ruchu
- proste w zabezpieczeniu i obsłudze (brak renderowania na żądanie)
Wady to świeżość: jeśli treść zmienia się często, trzeba przebudowywać i wdrażać lub użyć technik przyrostowych.
SSR: strony budowane w czasie żądania
W SSR serwer generuje HTML przy każdym żądaniu (lub przy cache miss). Przydaje się to, gdy treść musi odzwierciedlać najnowsze dane dla konkretnego odwiedzającego lub chwili.
SSR pasuje do:
- często zmieniających się stron (ceny, stan magazynu, panele na żywo)
- widoków spersonalizowanych (zalogowany stan, rekomendacje)
- treści zależnej od kontekstu żądania (lokalizacja, testy A/B)
Kompromis to czas budowania vs czas żądania: unikasz długich rebuildów, ale wprowadzisz pracę per-request, co wpływa na TTFB i koszty operacyjne.
Strony hybrydowe: mieszanie SSG i SSR
Wiele nowoczesnych stron jest hybrydowych: strony marketingowe i dokumentacja są SSG, a obszary kont i wyniki wyszukiwania są SSR.
Praktyczne pytania decyzyjne:
- Czy ta strona musi być świeża przy każdej wizycie?
- Czy można ją bezpiecznie cache'ować przez minuty/godziny?
- Czy przebudowa całego serwisu przy każdej zmianie byłaby akceptowalna?
Wybór strategii per-route często daje najlepszy balans prędkości, kosztów i aktualności treści.
SSR i SEO: co pomaga (a co nie)
Renderowanie po stronie serwera często poprawia SEO, ponieważ wyszukiwarki widzą pełną, znaczącą treść od razu po zapytaniu. Zamiast otrzymywać prawie pustą powłokę HTML, która wymaga JS do wypełnienia, crawlerzy dostają od razu pełny tekst, nagłówki i linki.
Co pomaga SSR
Szybsze odkrywanie treści. Gdy HTML zawiera treść od razu, crawlerzy mogą ją indeksować szybciej i bardziej wiarygodnie — szczególnie na dużych serwisach, gdzie budżet crawl’a i czas mają znaczenie.
Bardziej przewidywalne renderowanie. Nowoczesne wyszukiwarki potrafią wykonywać JavaScript, ale nie zawsze robią to natychmiast ani przewidywalnie. Część botów renderuje wolniej, odkłada wykonanie JS lub pomija je przy ograniczonych zasobach. SSR zmniejsza zależność od tego, czy crawler uruchomi mój JS.
Podstawowe sygnały SEO już w HTML. SSR ułatwia umieszczenie w początkowej odpowiedzi HTML istotnych elementów, takich jak:
- tagi title i meta description
- meta Open Graph/Twitter do podglądów udostępniania
- tagi canonical, by unikać problemów z duplikatami
- dane strukturalne (JSON-LD) widoczne od razu
Czego SSR nie naprawi automatycznie
Jakość i trafność treści. SSR pomoże wyszukiwarkom dostępować twoją treść, ale nie sprawi, że treść będzie wartościowa, oryginalna czy dopasowana do zapytań użytkowników.
Struktura witryny i linkowanie wewnętrzne. Jasna nawigacja, logiczna struktura URL i silne linkowanie wewnętrzne nadal mają znaczenie.
Higiena techniczna SEO. Problemy takie jak cienkie strony, duplikaty URL, złe kanoniki czy zablokowane zasoby nadal mogą blokować dobre wyniki, nawet przy SSR.
Traktuj SSR jako poprawę niezawodności crawlowania i renderowania — silna podstawa, nie skrót do dobrych pozycji w rankingach.
Podstawy wydajności: TTFB, LCP i odczuwalna prędkość
Wyślij testowe wdrożenie
Wdróż i hostuj prototyp SSR, aby przetestować wydajność na rzeczywistym ruchu.
Rozmowy o wydajności SSR zwykle sprowadzają się do kilku kluczowych metryk — i jednego odczucia użytkownika: „Czy strona pojawiła się szybko?”. SSR może poprawić to, co użytkownik widzi na początku, ale może też przenieść pracę na serwer i na etap hydracji.
Metryki, które mają znaczenie
TTFB (Time to First Byte) to czas, zanim serwer zacznie wysyłać czegokolwiek. Przy SSR TTFB staje się ważniejszy, bo serwer może potrzebować pobrać dane i wyrenderować HTML zanim odpowie. Jeśli serwer jest wolny, SSR może pogorszyć TTFB.
FCP (First Contentful Paint) to moment, gdy przeglądarka maluje pierwszą treść (tekst, tło itp.). SSR często pomaga FCP, bo przeglądarka otrzymuje gotowy do wyświetlenia HTML zamiast pustej powłoki.
LCP (Largest Contentful Paint) to moment, gdy największy element głównej zawartości (np. hero, obraz, tytuł produktu) staje się widoczny. SSR może pomóc LCP — pod warunkiem, że HTML przychodzi szybko i krytyczny CSS/zasoby nie blokują renderu.
Gdzie SSR może tworzyć wąskie gardła
SSR dodaje pracę serwerowi przy każdym żądaniu (chyba że odpowiedź jest cache’owana). Dwa częste wąskie gardła to:
- Opóźnienie serwera: czas CPU potrzebny do wyrenderowania komponentów i ewentualne kolejkowanie przy dużym obciążeniu.
- Pobieranie danych: czekanie na bazy danych i API. Jeśli strona SSR potrzebuje trzech zewnętrznych wywołań, czas odpowiedzi może zależeć od najwolniejszego z nich.
Praktyczny wniosek: wydajność SSR często ma więcej wspólnego z twoją ścieżką danych niż z frameworkiem frontendowym. Redukcja rund tripów do API, szybsze zapytania lub preobliczanie części strony często daje większy efekt niż optymalizacje po stronie UI.
Odczuwalna prędkość vs rzeczywista interaktywność
SSR świetnie poprawia „pierwszy widok”: użytkownicy widzą treść szybciej, mogą przewijać i mają wrażenie responsywności. Ale hydracja ciągle wymaga JS, by przypiąć przyciski, menu i formularze.
To tworzy kompromis:
- Szybszy pierwszy paint (lepsza odczuwalna wydajność)
- Możliwy czas oczekiwania na pełną interaktywność (koszt hydracji), szczególnie na słabych urządzeniach lub przy ciężkich stronach
Cache to główna dźwignia
Najszybsze SSR to często SSR z cache. Jeśli możesz cache'ować wyrenderowany HTML (na CDN, reverse proxy lub w aplikacji), unikasz ponownego renderowania i powtarzających się wywołań danych przy każdym żądaniu — poprawiając TTFB, a tym samym LCP.
Kluczowe jest dopasowanie strategii cache do rodzaju treści (publiczna vs spersonalizowana), żeby uzyskać szybkość bez przypadkowego serwowania cudzych danych.
Cacheowanie stron SSR bez serwowania złej treści
SSR może być powolne, jeśli każde żądanie zmusza serwer do renderowania HTML od zera. Cache to naprawia — ale tylko wtedy, gdy będziesz ostrożny odnośnie tego, co można bezpiecznie cache'ować.
Popularne warstwy cache (i do czego się nadają)
W większości stacków SSR znajdziesz kilka warstw cache:
- Cache CDN: przechowuje pełny HTML blisko użytkowników. Świetne dla publicznych stron (marketing, dokumentacja, strony kategorii).
- Reverse proxy (np. Nginx/Varnish): stoi przed aplikacją, cache'uje odpowiedzi i chroni serwer SSR przy skokach ruchu.
- Cache w aplikacji: kod cache'uje kosztowne obliczenia lub fragmenty (Redis, pamięć lokalna), dzięki czemu renderowanie jest szybsze nawet jeśli nie cache'ujesz całej strony.
- Cache bazy danych: indeksy, cache zapytań lub read replicas zmniejszają koszt pobierania danych potrzebnych do renderu.
Klucze cache: co odróżnia jedną „stronę” od drugiej
Odpowiedź cache’owana jest poprawna tylko wtedy, gdy klucz cache uwzględnia wszystkie elementy wpływające na wynik. Poza ścieżką URL, typowe wariacje to:
- Locale (jezyk/region)
- Klasa urządzenia (mobile vs desktop), jeśli renderujesz inny markup
- Stan uwierzytelnienia (zalogowany vs niezalogowany)
- Eksperymenty (bucket A/B)
HTTP pomaga: używaj nagłówka Vary, gdy odpowiedź zmienia się w zależności od nagłówków żądania (np. Vary: Accept-Language). Ostrożnie z Vary: Cookie — może zniszczyć trafność cache.
Nagłówki i wzorce rewalidacji
Używaj Cache-Control, by zdefiniować zachowanie:
public, max-age=0, s-maxage=600(cache na CDN/proxy przez 10 minut)stale-while-revalidate=30(serwuj lekko przestarzały HTML podczas odświeżania w tle)- ETag lub Last-Modified dla zapytań warunkowych (szybkie odpowiedzi 304)
Duże ostrzeżenie: strony spersonalizowane
Nigdy nie cache'uj HTML zawierającego prywatne dane użytkownika, chyba że cache jest ściśle per-user. Bezpieczniejszy wzorzec to: cache'uj publiczny szkielet strony, a potem pobieraj dane spersonalizowane po załadowaniu (lub renderuj po stronie serwera, ale oznacz odpowiedź private, no-store). Jeden błąd może spowodować wyciek danych między kontami.
Wady SSR i typowe pułapki
Prototypuj SSR w minutach
Szybko prototypuj trasę SSR, a następnie zmierz TTFB i LCP na rzeczywistym kodzie.
SSR może sprawić, że strony będą odczuwalnie szybsze przy pierwszym wejściu, ale przenosi też złożoność na serwer. Zanim się na niego zdecydujesz, warto wiedzieć, co może pójść nie tak i co zwykle zaskakuje zespoły.
Więcej elementów do ogarnięcia: runtime, wdrożenia, monitoring
Z SSR twoja strona to już nie tylko statyczne pliki na CDN. Masz teraz serwer (lub funkcje serverless) renderujące HTML na żądanie.
To oznacza odpowiedzialność za konfigurację runtime, bezpieczne wdrożenia (rollbacky mają znaczenie) oraz monitorowanie zachowania w czasie rzeczywistym: wskaźniki błędów, wolne żądania, użycie pamięci i awarie zależności. Złe wdrożenie może zepsuć każde żądanie do strony, a nie tylko pobieranie jednej paczki JS.
Wyższe koszty infrastruktury
SSR często zwiększa użycie CPU na żądanie. Nawet jeśli renderowanie HTML jest szybkie, to i tak jest praca, którą serwery muszą wykonać przy każdej wizycie.
W porównaniu z hostingiem statycznym koszty mogą wzrosnąć z powodu:
- większego zużycia CPU (renderowanie komponentów)
- konieczności większej liczby instancji lub większego użycia serverless
- dodatkowych warstw cache, by utrzymać stabilną wydajność
Tryby awarii, których nie ma na stronach statycznych
Ponieważ SSR odbywa się w czasie żądania, możesz napotkać przypadki typu:
- timeouty, gdy renderowanie trwa za długo
- limity szybkości (twoje lub dostawcy) przy skokach ruchu
- wolne API stron trzecich opóźniające generowanie strony
Jeśli kod SSR wywołuje zewnętrzne API, jedna wolna zależność może spowolnić całą stronę główną. Dlatego timeouty, fallbacky i cache nie są opcjonalne.
Hydracja i błędy „mismatch” UI
Typowy błąd deweloperski to sytuacja, gdy HTML wygenerowany na serwerze nie zgadza się dokładnie z tym, co klient wyrenderuje podczas hydracji. W efekcie mogą pojawić się ostrzeżenia, migotanie lub popsuta interaktywność.
Częste przyczyny: wartości losowe, znaczniki czasu, dane specyficzne dla użytkownika lub API dostępne tylko w przeglądarce podczas początkowego renderu — wszystko to trzeba odpowiednio zabezpieczyć.
Popularne frameworki SSR i powiązane terminy
Wybór „SSR” zwykle oznacza wybór frameworka, który potrafi renderować HTML na serwerze i potem uczynić go interaktywnym w przeglądarce. Oto popularne opcje i terminy, które napotkasz.
Popularne frameworki z obsługą SSR
Next.js (React) jest powszechnym wyborem. Wspiera SSR per-route, generowanie statyczne, streaming i wiele opcji wdrożenia (serwery Node, serverless, edge).
Nuxt (Vue) oferuje podobne doświadczenie dla zespołów Vue, z routowaniem plikowym i elastycznymi trybami renderowania.
Remix (React) kładzie nacisk na standardy webowe i zagnieżdżone routy. Często wybierany przy aplikacjach ciężkich od danych, gdzie routing i pobieranie danych są ściśle powiązane.
SvelteKit (Svelte) łączy SSR, statyczne wyjście i adaptery dla różnych hostów, z lekkim podejściem i prostym pobieraniem danych.
Powiązane terminy (krótkie definicje)
- SSR (Server-Side Rendering): HTML generowany jest na serwerze dla każdego żądania (lub wielu żądań przy użyciu cache).
- SSG (Static Site Generation): HTML generowany jest w czasie buildu.
- ISR (Incremental Static Regeneration): „statyczne” strony są odświeżane po wdrożeniu na harmonogram lub na żądanie.
- Streaming: serwer wysyła HTML w kawałkach, by użytkownik zobaczył zawartość wcześniej.
- Edge rendering: SSR uruchamiany bliżej użytkownika (lokalizacje CDN/edge), by zmniejszyć latencję.
Routing i pobieranie danych: co się różni
- Next.js / Nuxt / SvelteKit: zwykle używają routingu plikowego; dane są pobierane w hookach serwerowych przypisanych do tras.
- Remix: używa zagnieżdżonych tras z loaderami/actions per route, więc każda trasa deklaruje, jak pobiera dane i obsługuje wysyłanie formularzy.
Jak wybrać
Wybierz według biblioteki UI zespołu, sposobu hostingu (serwer Node, serverless, edge) i poziomu kontroli nad cache, streamowaniem i pobieraniem danych.
Jeśli chcesz szybko eksperymentować zanim zaangażujesz się w pełny stack SSR, platforma taka jak Koder.ai może pomóc prototypować aplikację w kształcie produkcyjnym z interfejsem chatowym — zwykle z frontendem React i backendem Go + PostgreSQL — a potem iterateować z funkcjami jak tryb planowania, migawki i rollback. Dla zespołów oceniających kompromisy SSR, pętla „prototyp → wdrożenie” ułatwia zmierzenie rzeczywistego wpływu na TTFB/LCP zamiast zgadywania.
Często zadawane pytania
Co to jest renderowanie po stronie serwera (SSR) w prostych słowach?
SSR (server-side rendering) oznacza, że serwer generuje HTML strony w momencie, gdy użytkownik żąda adresu URL, a następnie wysyła gotowy do wyświetlenia HTML do przeglądarki.
To różni się od „bycia hostowanym na serwerze” (prawie wszystko jest). SSR konkretnie opisuje gdzie powstaje początkowy HTML: na serwerze na każde żądanie (lub przy cache miss).
Jak działa SSR krok po kroku?
Typowy przepływ SSR wygląda tak:
- Przeglądarka żąda trasy (np.
/products/123). - Serwer pobiera potrzebne dane (DB/API/usługi).
- Serwer renderuje HTML przy użyciu frameworka/szablonu.
- Przeglądarka natychmiast pokazuje HTML, a potem pobiera JavaScript, by dodać interaktywność.
Główna różnica UX polega na tym, że użytkownicy często mogą wcześniej przeczytać treść, ponieważ do przeglądarki trafia prawdziwy HTML.
Czy SSR eliminuje potrzebę JavaScriptu?
SSR poprawia to, jak szybko użytkownicy mogą zobaczyć treść, ale JavaScript wciąż jest wymagany do zachowań typowych dla aplikacji.
Większość stron SSR wysyła:
- HTML dla szybkiego pierwszego wyświetlenia
- pakiet JS, który uruchamia się w przeglądarce, aby przypiąć obsługę zdarzeń i stan
Zatem SSR to zazwyczaj „najpierw treść, potem interaktywność”, a nie „brak JavaScriptu”.
Czym jest hydracja i dlaczego strony SSR mogą nadal wolno reagować?
Hydracja to krok po stronie przeglądarki, w którym Twój JavaScript „aktywuje” serwerowo wyrenderowany HTML.
W praktyce hydracja:
- łączy obsługę kliknięć, logikę formularzy i stan z istniejącym markupiem
- kosztuje CPU/pamięć na urządzeniu użytkownika
Na wolniejszych urządzeniach lub przy dużych pakietach użytkownicy mogą zobaczyć treść szybko, ale doświadczyć krótkiego okresu „martwego interfejsu”, dopóki hydracja się nie zakończy.
Czym SSR różni się od CSR (renderowania po stronie klienta)?
CSR (client-side rendering) zwykle pobiera najpierw pakiet JavaScript, a następnie buduje HTML w przeglądarce — przez co przez chwile użytkownik widzi pusty ekran, spinner lub szkielet interfejsu.
SSR wysyła gotowy do wyświetlenia HTML jako pierwszy, co często poprawia odczuwalną szybkość przy pierwszym wejściu.
Zasadniczo:
- SSR: lepszy pierwszy widok dla stron treściowych i SEO
- CSR: prostsze hostowanie i szybka nawigacja wewnątrz aplikacji po załadowaniu
Czym SSR różni się od SSG (statycznego generowania stron)?
SSG (Static Site Generation) tworzy HTML w czasie buildu/deployu i serwuje go jak plik statyczny — bardzo cacheowalny i przewidywalny przy dużym ruchu.
SSR generuje HTML w czasie żądania (lub przy cache miss), co pomaga, gdy strony muszą być świeże, spersonalizowane lub zależne od kontekstu żądania.
Wiele serwisów miesza oba podejścia: SSG dla stabilnych stron marketingowych/dokumentacji, SSR dla wyników wyszukiwania, informacji o stanie magazynu czy stron zależnych od użytkownika.
Czy SSR poprawia SEO, a czego nie naprawi?
SSR może pomóc SEO, ponieważ umieszcza znaczącą treść i metadane bezpośrednio w początkowej odpowiedzi HTML, co ułatwia crawlowanie i indeksowanie.
SSR pomaga w:
- szybszym odkrywaniu treści (mniejsza zależność od wykonania JS)
- wygenerowaniu istotnych elementów: tagów title, meta, JSON-LD od razu
SSR nie naprawi jednak:
- słabej jakości treści
Jak SSR wpływa na TTFB, LCP i odczuwalną wydajność?
Najważniejsze metryki to:
- TTFB: może wzrosnąć przy SSR, jeśli pobieranie danych/renderowanie jest wolne
- FCP/LCP: często poprawiają się, bo HTML przychodzi gotowy do renderu
- Time to interactive/usable: może być opóźniony przez hydrację i duże pakiety JS
Wydajność SSR często zależy bardziej od (opóźnienia API/DB, liczba zapytań) i niż od samego frameworka frontendowego.
Jak cacheować strony SSR bez serwowania błędnej, spersonalizowanej treści?
Cacheowanie wyjścia SSR jest potężne, ale musisz unikać serwowania HTML jednego użytkownika innemu.
Praktyczne zabezpieczenia:
Jakie są największe wady i typowe pułapki SSR?
Typowe pułapki SSR to:
- Wolne zależności upstream: jedno powolne API/DB spowalnia stronę.
- Timeouty i gwałtowne skoki ruchu: renderowanie w czasie żądania może przeciążyć serwery bez odpowiedniego cache.
- Niezgodności podczas hydracji: HTML serwerowy różni się od tego, co klient renderuje (np. losowe wartości, znaczniki czasu, API tylko przeglądarki).
- Złożoność operacyjna: monitorowanie, rollbacky i runtime mają wpływ na każde żądanie.