Co obejmuje ten wpis (i dlaczego to ważne)
Snowflake spopularyzował prostą, ale dalekosiężną ideę w chmurowych hurtowniach danych: oddziel przechowywanie danych od mocy obliczeniowej. To rozdzielenie zmienia dwa codzienne problemy zespołów danych — jak hurtownie się skalują i za co płacisz.
Zamiast traktować hurtownię jak jeden stały „pojemnik” (gdzie więcej użytkowników, więcej danych lub bardziej skomplikowane zapytania konkurują o te same zasoby), model Snowflake pozwala przechowywać dane raz i uruchamiać odpowiednią ilość compute wtedy, gdy jest potrzebna. Efekt to często szybszy czas uzyskania odpowiedzi, mniej wąskich gardeł podczas szczytów użycia i przejrzystsze sterowanie tym, co generuje koszty (i kiedy).
Motyw #1: wydajność i skalowanie bez zwykłych kompromisów
Ten wpis wyjaśnia prostym językiem, co naprawdę oznacza rozdzielenie storage i compute — oraz jak wpływa to na:
- Współbieżność (wiele osób uruchamia zapytania jednocześnie)
- Elastyczne skalowanie (zwiększanie i zmniejszanie mocy obliczeniowej)
- Zachowanie kosztów (płacisz za compute tylko gdy działa, plus stały koszt storage)
Wskażemy też miejsca, gdzie model nie rozwiązuje wszystkiego: niektóre niespodzianki kosztowe i wydajnościowe wynikają z projektowania obciążeń, a nie z samej platformy.
Motyw #2: dlaczego ekosystem może być równie ważny jak surowa wydajność
Szybka platforma to nie wszystko. Dla wielu zespołów czas do wartości zależy od tego, czy hurtownię można łatwo połączyć z narzędziami, których już używacie — pipeline’ami ETL/ELT, dashboardami BI, narzędziami katalogowymi/governance, kontrolami bezpieczeństwa i źródłami danych partnerów.
Ekosystem Snowflake (w tym wzorce udostępniania i dystrybucja w modelu marketplace) może skrócić czas wdrożenia i zmniejszyć konieczność tworzenia niestandardowego inżynieringu. Opisujemy, jak „głębokość ekosystemu” wygląda w praktyce i jak ją ocenić dla Twojej organizacji.
Dla kogo to jest
Ten przewodnik jest napisany dla liderów danych, analityków i decydentów nietechnicznych — wszystkich, którzy potrzebują zrozumieć kompromisy związane z architekturą Snowflake, skalowaniem, kosztami i integracją bez zanurzania się w żargon dostawcy.
Przed rozdzieleniem: dlaczego tradycyjne hurtownie napotykają ograniczenia
Tradycyjne hurtownie danych zakładały prostą zasadę: kupujesz (lub wynajmujesz) stałą ilość sprzętu, a potem uruchamiasz wszystko na tym samym pudełku lub klastrze. To działało, gdy obciążenia były przewidywalne i wzrost powolny — ale tworzyło ograniczenia, gdy wolumen danych i liczba użytkowników gwałtownie rosły.
Klasyczny model: stałe klastry i staranna planizacja pojemności
Systemy on‑premise (i wczesne wdrożenia chmurowe typu „lift-and-shift”) wyglądały zwykle tak:
- Jeden klaster MPP obsługiwał storage, CPU i pamięć razem.
- Rozmiar klastra dobierano pod szczytowe zapotrzebowanie, bo zmiana rozmiaru była wolna, ryzykowna lub wymagała przestoju.
- Planowanie pojemności stawało się cyklicznym projektem: prognozy wzrostu, uzasadnianie budżetu, zamawianie sprzętu, instalacja, migracja.
Nawet gdy dostawcy oferowali „węzły”, wzorzec pozostawał ten sam: skalowanie zwykle oznaczało dodanie większych lub większej liczby węzłów do jednego współdzielonego środowiska.
Problemy: wolne skalowanie, marnotrawstwo i kolejki
Taki design rodzi kilka typowych bolączek:
- Wolne skalowanie: gdy napływa potrzeba dodatkowej mocy (np. zamknięcie miesiąca), nie zawsze da się ją szybko dodać. Trzeba czekać albo nadmiarowo przygotować zasoby „na wszelki wypadek”.
- Bezczynne zasoby: klastry dobrane pod piki stoją niewykorzystane przez większość czasu — a mimo to za nie płacisz.
- Kolejkowanie przy obciążeniu: kiedy wiele zespołów uruchamia zapytania jednocześnie, konkurują o te same zasoby. Ciężkie zadania mogą blokować interaktywne dashboardy, prowadząc do timeoutów i reguł typu „nie uruchamiaj tego zapytania w godzinach pracy”.
Narzędzia i integracje: potężne, lecz często kruche
Ponieważ hurtownie były ściśle powiązane z infrastrukturą, integracje rosły często organicznie: customowe skrypty ETL, ręcznie budowane konektory i jednorazowe pipeline’y. Działały — dopóki nie zmieniła się struktura schematu, nie przesunęło się źródło lub nie pojawiło nowe narzędzie. Utrzymanie całości mogło przypominać stałą konserwację zamiast systematycznego rozwoju.
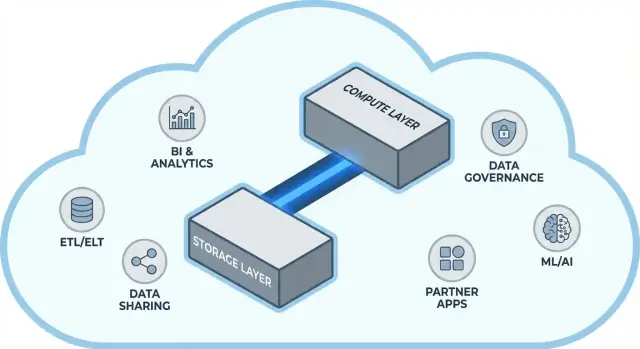
Główna idea: rozdzielenie storage i compute
Tradycyjne hurtownie często łączą dwie zupełnie różne role: storage (gdzie dane są przechowywane) i compute (moc obliczeniowa, która czyta, łączy, agreguje i zapisuje te dane).
Storage vs. compute (prosto)
Storage to jak spiżarnia długoterminowa: tabele, pliki i metadane przechowywane tanio, trwałe i dostępne cały czas.
Compute to zespół kucharzy: CPU i pamięć, które „przyrządzają” zapytania — wykonują SQL, sortują, skanują, budują wyniki i obsługują wielu użytkowników.
Kluczowa zmiana: skaluj je niezależnie
Snowflake rozdziela te dwie warstwy, żebyś mógł dopasować każdą bez przymusu zmiany drugiej.
- Gdy rośnie wolumen danych, dodajesz więcej storage (zwykle stopniowo i przewidywalnie).
- Gdy rośnie ruch raportowy, dodajesz więcej compute (skalowanie lub dodanie virtual warehouses) bez kopiowania danych.
W praktyce zmienia to codzienne operacje: nie musisz „kupować” dodatkowego compute tylko dlatego, że storage rośnie, i możesz izolować obciążenia (np. analitycy vs. ETL), żeby się nawzajem nie spowalniały.
Czego to nie jest
To rozdzielenie jest potężne, ale nie jest magią.
- To nie jest darmowe skalowanie. Większe lub dodatkowe warehouses zwykle oznaczają większe wydatki na compute.
- To nie gwarantuje oszczędności za każdym razem. Słabo napisane zapytania, niepotrzebne odświeżania czy zawsze włączone warehouses nadal generują koszty.
- To nie zwalnia z planowania. Nadal trzeba dobierać rozmiary warehouse, ustawiać auto-suspend i dopasowywać compute do wzorców biznesowych.
Wartość to kontrola: płacisz oddzielnie za storage i compute i dopasowujesz każde do rzeczywistych potrzeb zespołów.
Architektura Snowflake w prostych słowach
Snowflake najłatwiej zrozumieć jako trzy warstwy współpracujące ze sobą, które mogą skalować niezależnie.
1) Storage: obiektowy storage w chmurze
Twoje tabele ostatecznie są zapisane jako pliki danych w obiektowym magazynie chmurowym (np. S3, Azure Blob lub GCS). Snowflake zarządza formatami plików, kompresją i organizacją. Nie „podłączasz dysków” ani nie musisz ręcznie rozmiarować wolumenów — storage rośnie wraz z danymi.
2) Compute: virtual warehouses
Compute jest zapakowany jako virtual warehouses: niezależne klastry CPU/pamięci, które wykonują zapytania. Możesz uruchomić wiele warehouses jednocześnie odczytujących te same dane. To kluczowa różnica w porównaniu ze starszymi systemami, gdzie ciężkie obciążenia walczyły o wspólny pul zasobów.
Osobna warstwa usług obsługuje „mózg” systemu: uwierzytelnianie, parsowanie i optymalizację zapytań, zarządzanie transakcjami/metadanymi oraz koordynację. Ta warstwa decyduje, jak najlepiej wykonać zapytanie, zanim compute dotknie danych.
Jak przepływa zapytanie
Gdy wysyłasz SQL, warstwa usług Snowflake parsuje go, buduje plan wykonania, a następnie przekazuje plan do wybranego virtual warehouse. Warehouse czyta tylko niezbędne pliki z object storage (korzystając z cache, gdy to możliwe), przetwarza je i zwraca wyniki — bez trwałego przenoszenia bazowych danych do klastra.
Współbieżność i izolacja (bez żargonu)
Jeżeli wiele osób uruchamia zapytania jednocześnie, możesz:
- użyć oddzielnych warehouses dla różnych zespołów/obciążeń (izolacja obciążeń), lub
- włączyć multi-cluster warehouses, aby Snowflake mógł dodać kolejne klastry compute, gdy zapotrzebowanie rośnie, a potem ponownie je zwinąć.
To architektoniczne podwaliny wydajności Snowflake i kontroli nad „hałaśliwymi sąsiadami”.
Skalowanie i współbieżność: co się naprawdę zmienia
Dużą praktyczną zmianą w Snowflake jest to, że skalujesz compute niezależnie od danych. Zamiast „hurtownia robi się większa”, możesz dopasować zasoby per obciążenie — bez kopiowania tabel, reorganizacji dysków czy planowanych przestojów.
Elastyczność: zmieniaj rozmiar compute bez przenoszenia danych
W Snowflake virtual warehouse to silnik compute, który wykonuje zapytania. Możesz go zmienić (np. z Small na Large) w kilka sekund, a dane pozostają w miejscu. Oznacza to, że strojenie wydajności często sprowadza się do prostego pytania: „Czy to obciążenie potrzebuje teraz więcej mocy?”.
To też umożliwia tymczasowe piki: podnieś moc na zamknięcie miesiąca, a potem ją zmniejsz, gdy szczyt minie.
Współbieżność: mniej walk o zasoby
Tradycyjne systemy zmuszały zespoły do współdzielenia compute, co zamieniało godziny szczytu w kolejkę przy kasie.
Snowflake pozwala uruchamiać oddzielne warehouses dla różnych zespołów lub zastosowań (np. analitycy, dashboardy, ETL). Ponieważ wszystkie warehouses czytają te same bazowe dane, zmniejszasz problem „mój dashboard spowolnił Twój raport” i zwiększasz przewidywalność wydajności.
Kompromisy, które zauważysz
Elastyczny compute to nie gwarancja sukcesu. Typowe pułapki to:
- Cold starts: zawieszone warehouses potrzebują chwili na wznowienie, co może dodać opóźnienia dla rzadkich zadań.
- Wybory dotyczące rozmiaru: przewymiarowanie marnuje pieniądze; zbyt mały rozmiar daje wolne zapytania i frustrację.
- Konieczność guardraili: używaj auto-suspend/auto-resume, resource monitorów i jasnej odpowiedzialności, żeby warehouses nie działały bez potrzeby lub nie rozrastały się niekontrolowanie.
Zmiana netto: skalowanie i współbieżność przestają być projektami infrastrukturalnymi i stają się decyzjami operacyjnymi dnia codziennego.
Model kosztów: gdzie pojawiają się oszczędności (a gdzie nie)
Zaplanuj pilotaż Snowflake
Opracuj plan pilotażowy na 2–4 tygodnie i wdrażaj go krok po kroku w trybie planowania.
Jak naprawdę działa rozliczanie w Snowflake
„Płacisz za to, czego używasz” to w praktyce dwa równoległe liczniki:
- Compute: naliczany za czas działania virtual warehouse (w kredytach). Jeśli jest włączony, licznik tyka.
- Storage: naliczany za ilość przechowywanych danych (plus dodatkowe opcje retencji jak Time Travel/Fail-safe).
To rozdzielenie to miejsce, w którym mogą pojawić się oszczędności: możesz przechowywać dużo danych stosunkowo tanio i włączać compute tylko wtedy, gdy jest potrzebny.
Gdzie koszty rosną
Większość „nieoczekiwanych” wydatków pochodzi z zachowań compute, nie z samego storage. Typowe przyczyny:
- Przewymiarowane warehouses
- Zawsze włączone obciążenia (warehouses działające w nocy lub w weekendy)
- Nieefektywne zapytania (nieprzefiltrowane skany, zbędne joiny, ciężkie transformacje wykonywane wielokrotnie)
- Wzorce dużej współbieżności (wiele małych dashboardów odświeżających się ciągle)
Oddzielenie storage i compute nie sprawia, że zapytania stają się efektywne — zły SQL nadal może szybko spalić kredyty.
Praktyczne mechanizmy kontroli
Nie potrzebujesz działu finansów, by to kontrolować — wystarczy kilka zasad:
- Auto-suspend / auto-resume, żeby nie płacić za bezczynność
- Resource monitors, aby alertować lub ograniczać użycie kredytów per warehouse/ zespół
- Harmonogramy (uruchamiaj batchy w określonych oknach; wstrzymaj środowiska dev/test poza godzinami pracy)
- Dobieranie rozmiaru i testowanie mniejszych rozmiarów przed skalowaniem w górę
Przy dobrym użyciu model nagradza dyscyplinę: krótkotrwały, dobrze dopasowany compute połączony z przewidywalnym wzrostem storage.
Udostępnianie danych i współpraca jako element pierwszorzędny
Snowflake traktuje udostępnianie jako funkcję wbudowaną w platformę — nie jako dodatek polegający na eksportach, zrzutach plików czy jednorazowych ETL-ach.
Udostępnianie bez kopiowania (w wielu przypadkach)
Zamiast przesyłać ekstrakty, Snowflake może pozwolić innemu kontu zapytywać te same dane przez bezpieczny „share”. W wielu scenariuszach dane nie muszą być kopiowane do drugiej hurtowni ani wypychane do object storage do pobrania. Konsument widzi udostępnioną bazę/tabelę tak, jakby była lokalna, a dostawca zachowuje kontrolę nad tym, co jest udostępnione.
Takie podejście redukuje rozrastanie się kopii danych, przyspiesza dostęp i zmniejsza liczbę pipeline’ów do zbudowania i utrzymania.
Typowe wzorce współpracy
Udostępnianie partnerom i klientom: Dostawca może publikować wyselekcjonowane zestawy danych dla klientów (np. analitykę użycia lub dane referencyjne) z jasnymi granicami — tylko dozwolone schematy, tabele czy widoki.
Wewnętrzne udostępnianie domenowe: Zespoły centralne mogą udostępniać certyfikowane zbiory danych produktowi, finansom i operacjom bez każdorazowego tworzenia kopii. To wspiera kulturę „jednego źródła prawdy”, dając jednocześnie możliwość własnego uruchamiania compute przez zespoły.
Współpraca z controllami: Projekty zewnętrzne (agentury, dostawcy, spółki zależne) mogą pracować na wspólnym zbiorze danych z zamaskowanymi wrażliwymi kolumnami i audytowanym dostępem.
Ograniczenia, które trzeba zaplanować
Udostępnianie to nie „ustaw i zapomnij”. Potrzebujesz:
- Governance: jasna własność, przeglądy dostępu i polityki dla PII/danych regulowanych
- Kontrakty i oczekiwania: kto płaci za compute, SLA, retencja i co się dzieje przy zmianie definicji
- Odkrywalność: bez katalogu i dobrej nazewniczości ludzie nie znajdą albo nie zaufają odpowiednim udostępnieniom. Dopasuj shares do dokumentacji i katalogu danych, jeśli go masz.
Dlaczego ekosystem może być równie ważny jak wydajność
Szybka hurtownia jest wartościowa, ale sama prędkość rzadko decyduje, czy projekt zostanie wdrożony. Często różnicę robi ekosystem: gotowe integracje, narzędzia i wiedza, które zmniejszają konieczność pracy customowej.
W praktyce ekosystem obejmuje:
- Konektory do źródeł/destynacji (SaaS, bazy, narzędzia streamingowe)
- Narzędzia partnerskie do ingestu, transformacji, BI, jakości danych i obserwowalności
- Aplikacje i integracje natywne działające blisko danych
- Szablony i wzorce referencyjne (wspólne modele, schematy, przewodniki wdrożeniowe)
- Wiedza społeczności: przykłady, fora, meetup’y i dostępność kadry
Dlaczego ekosystem może przegonić benchmarki w czasie dostawy
Benchmarki mierzą wąski fragment wydajności w kontrolowanych warunkach. W realnych projektach większość czasu spędza się na:
- Doprowadzaniu danych niezawodnie i przyrostowo
- Modelowaniu, testowaniu i dokumentowaniu zbiorów danych
- Zadaniach operacyjnych (monitoring, alerty, kontrola kosztów)
- Przeglądach bezpieczeństwa, kontrolach dostępu i audytach
Jeżeli platforma ma dojrzałe integracje dla tych kroków, unikasz budowania i utrzymywania kodu „klejącego”. To zwykle skraca czas wdrożenia, poprawia niezawodność i ułatwia zmianę zespołów/dostawców bez przepisywania wszystkiego.
Prosta soczewka oceny: pokrycie, jakość, utrzymywalność
Przy ocenie ekosystemu szukaj:
- Pokrycia: czy obsługuje kluczowe źródła, narzędzia BI, orkiestrację i potrzeby governance?
- Jakości: czy konektory są aktywnie utrzymywane, dobrze udokumentowane i sprawdzone w Twojej skali?
- Utrzymywalności: ile pracy wymaga bieżące utrzymanie — aktualizacje, breaking changes, debugowanie i wsparcie?
Wydajność daje możliwości; ekosystem decyduje, jak szybko zamienisz je w realne rezultaty biznesowe.
Ekosystem integracji: jak dostać dane, użyć ich i wyprowadzić
Dobierz rozmiary z guardrailami
Uruchom szybkie narzędzie administracyjne do decyzji o rozmiarach warehouse i zasad izolacji obciążeń.
Snowflake może szybko wykonywać zapytania, ale wartość pojawia się, gdy dane płynnie przepływają przez Twój stack: od źródeł do Snowflake i dalej do narzędzi, z których ludzie korzystają na co dzień. „Ostatnia mila” zwykle decyduje, czy platforma wydaje się bezproblemowa, czy ciągle krucha.
Główne kategorie integracji do zaplanowania
Większość zespołów potrzebuje miksu:
- ELT/ETL do ingestu z baz, aplikacji SaaS, plików i object storage
- BI i analityka do dashboardów, eksploracji i warstw semantycznych
- Reverse ETL do wysyłania wyczyszczonych danych z powrotem do CRM, marketingu i systemów wsparcia
- Orkiestracja do harmonogramowania, zależności, backfilli i promocji środowisk
- Streaming do zdarzeń near‑real‑time i change data capture
- Narzędzia ML do pipeline’ów cech, treningu modeli i monitorowania modeli
Pytania przed wyborem konektorów
Nie wszystkie „kompatybilne ze Snowflake” narzędzia zachowują się tak samo. Przy ocenie koncentruj się na praktycznych detalach:
- Czy konektor jest certyfikowany/wspierany (przez kogo)? Jaka jest ścieżka eskalacji?
- Czy obsługuje przyrostowe ładowania (CDC, timestampy, high‑water marks)?
- Jak radzi sobie ze schema drift — nowymi kolumnami, zmianami typów, usuwaniem pól?
- Jakie są gwarancje dotyczące retry, deduplikacji oraz exactly‑once vs at‑least‑once?
Nie ignoruj operacji
Integracje wymagają też gotowości na dzień drugi: monitoring i alerty, hakowanie do lineage/katalogu oraz procedury incident response (ticketing, on‑call, runbooki). Silny ekosystem to nie tylko logotypy — to mniej niespodzianek, gdy pipeline’y padną o 2:00 w nocy.
Governance, bezpieczeństwo i zaufanie w skali
W miarę rozrostu zespołów najtrudniejsza część analityki to często nie prędkość, lecz zapewnienie, że właściwe osoby mają dostęp do właściwych danych w odpowiednim celu, z dowodem, że kontrole działają. Funkcje governance w Snowflake są zaprojektowane z myślą o tej rzeczywistości: wielu użytkownikach, produktach danych i częstym udostępnianiu.
Podstawy governance, które realnie działają
Zacznij od jasnych ról i zasady least privilege. Zamiast nadawać prawa bezpośrednio użytkownikom, definiuj role typu ANALYST_FINANCE czy ETL_MARKETING, a potem przypisuj im dostęp do konkretnych baz, schematów, tabel i — w razie potrzeby — widoków.
Dla wrażliwych pól (PII, identyfikatory finansowe) używaj masking policies, dzięki czemu ludzie mogą zapytywać zbiory bez widoku surowych wartości, chyba że ich rola to dopuszcza. Do tego dodaj audyt: śledź kto i kiedy wykonał zapytanie, aby zespoły bezpieczeństwa i compliance mogły odpowiadać na pytania bez domysłów.
Dlaczego governance zmienia udostępnianie i self‑service
Dobre governance sprawia, że udostępnianie jest bezpieczne i skalowalne. Gdy model udostępniania opiera się na rolach, politykach i audycie, możesz śmiało umożliwiać self‑service (więcej użytkowników eksplorujących dane) bez ryzyka przypadkowej eskpozycji.
To także zmniejsza tarcie w działaniach zgodności: polityki stają się powtarzalnymi kontrolami, a nie jednorazowymi wyjątkami. To ważne, gdy zbiory danych są wykorzystywane w wielu projektach, działach czy przez partnerów zewnętrznych.
Praktyczne wskazówki, które zapobiegają bólowi w przyszłości
- Konwencje nazewnicze: standaryzuj nazwy baz/schematów, które sygnalizują cel i czułość (np.
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). Spójność przyspiesza przeglądy i zmniejsza pomyłki.
- Oddzielenie środowisk: trzymaj DEV/TEST/PROD logicznie oddzielone, z ostrzejszymi kontrolami w PROD. Traktuj dane produkcyjne jako wyjątek, nie domyślne ustawienie.
- Przeglądy dostępu: ustal rytm (miesięcznie dla danych wysokiego ryzyka, kwartalnie dla pozostałych). Przeglądaj członkostwo w rolach, nieaktywne konta i role uprzywilejowane.
Zaufanie w skali to mniej „jednej idealnej kontroli”, a więcej systemu drobnych, niezawodnych nawyków, które utrzymują dostęp intencjonalnym i wyjaśnialnym.
Obciążenia i wzorce najlepszych praktyk
Otrzymuj nagrody za udostępnianie
Podziel się historią budowy lub poleć współpracownika i zdobądź kredyty na używanie Koder.ai.
Snowflake błyszczy, gdy wiele osób i narzędzi musi zapytywać te same dane z różnych powodów. Ponieważ compute jest zapakowany w niezależne „warehouses”, możesz dopasować każde obciążenie do kształtu i harmonogramu, który pasuje.
Typowe mapowanie obciążeń
Analityka i dashboardy: Umieść narzędzia BI na dedykowanym warehouse o rozmiarze dopasowanym do stałego, przewidywalnego ruchu. To chroni odświeżenia dashboardów przed spowolnieniem przez zapytania ad hoc.
Analiza ad hoc: Daj analitykom osobny warehouse (zwykle mniejszy) z włączonym auto-suspend. Dostajesz szybkie iteracje bez płacenia za bezczynność.
Data science i eksperymenty: Używaj warehouse o rozmiarze dla cięższych skanów i okazjonalnych pików. Jeśli eksperymenty rosną, skaluj ten warehouse tymczasowo bez wpływu na użytkowników BI.
Aplikacje danych i embedded analytics: Traktuj ruch aplikacji jak usługę produkcyjną — oddzielny warehouse, konserwatywne timeouty i resource monitory, by uniknąć niespodziewanych wydatków.
Jeśli budujesz lekkie wewnętrzne aplikacje danych (np. portal operacyjny, który pyta Snowflake i pokazuje KPI), szybkim sposobem jest wygenerować roboczy scaffold React + API i iterować z interesariuszami. Platformy takie jak Koder.ai (narzędzie „vibe‑coding”, które buduje aplikacje web/serwer/mobile z chatu) pomagają zespołom szybko prototypować aplikacje oparte na Snowflake, a potem eksportować kod źródłowy, gdy są gotowi do produkcji.
Wzorce najlepszych praktyk, które działają
Prosta zasada: oddziel warehouses według odbiorcy i celu (BI, ELT, ad hoc, ML, aplikacja). Połącz to ze zdrowymi nawykami zapytań — unikaj szerokiego SELECT *, filtruj wcześnie i zwracaj uwagę na nieefektywne joiny. Po stronie modelowania stawiaj na struktury pasujące do sposobu zapytań (czysta warstwa semantyczna lub dobrze zdefiniowane marts), zamiast nadmiernej optymalizacji układu fizycznego.
Kiedy rozważyć alternatywy lub uzupełnienia
Snowflake nie zastępuje wszystkiego. Dla obciążeń transakcyjnych o wysokiej przepustowości i niskich opóźnieniach (oltp) zwykle lepsza jest wyspecjalizowana baza, a Snowflake używa się do analityki, raportowania, udostępniania i produktów danych downstream. Hybrydowe rozwiązania są powszechne i często najbardziej praktyczne.
Rozważania przy migracji: co zaplanować przed przeniesieniem
Migracja do Snowflake rzadko jest „lift and shift”. Rozdzielenie storage i compute zmienia sposób, w jaki dobierasz rozmiary, stroisz i płacisz za obciążenia — więc plan z wyprzedzeniem zapobiega niespodziankom.
Praktyczna sekwencja migracji
Zacznij od inwentaryzacji: jakie źródła zasilają hurtownię, które pipeline’y ją transformują, jakie dashboardy są zależne i kto jest właścicielem poszczególnych elementów. Następnie priorytetyzuj według wpływu biznesowego i złożoności (np. najpierw krytyczne raporty finansowe, później sandboxy eksperymentalne).
Później konwertuj logikę SQL i ETL. Dużą część standardowego SQL da się przenieść, ale szczegóły jak funkcje, obsługa dat, kod proceduralny i wzorce temp‑tables często wymagają przeróbek. Waliduj wyniki wcześnie: uruchamiaj równoległe wyjścia, porównuj liczby wierszy i agregaty oraz sprawdzaj przypadki brzegowe (null‑y, strefy czasowe, logika deduplikacji). Na końcu zaplanuj cutover: okno zamrożenia, plan rollbacku i jasną definicję „zakończenia” dla każdego zestawu danych i raportu.
Typowe ryzyka
Najczęstsze są ukryte zależności: eksport do arkusza, hardkodowany connection string, downstream job o którym nikt nie pamięta. Niespodzianki wydajności pojawiają się, gdy stare założenia strojenia nie mają sensu (np. nadmierne używanie małych warehouses, lub uruchamianie wielu małych zapytań bez uwzględnienia współbieżności). Skoki kosztów zwykle wynikają z pozostawionych włączonych warehouses, niekontrolowanych retry albo duplikacji środowisk dev/test. Luki w uprawnieniach pojawiają się przy przejściu z grubych ról na bardziej szczegółowe governance — testy powinny obejmować uruchomienia z perspektywy „least privilege”.
Zarządzanie zmianą (nie pomijaj tego)
Ustal model własności (kto jest właścicielem danych, pipeline’ów i kosztów), przeprowadź szkolenia role‑based dla analityków i inżynierów oraz zdefiniuj plan wsparcia na pierwsze tygodnie po cutover (rotacja on‑call, runbook incydentów i miejsce do zgłaszania problemów).
Wybór nowoczesnej platformy danych to nie tylko szczytowa prędkość w benchmarkach. To dopasowanie do Twoich realnych obciążeń, sposobu pracy zespołu i narzędzi, na których polegasz.
Praktyczna lista kontrolna
Użyj tych pytań, by prowadzić shortlistę i rozmowy z dostawcami:
- Obciążenia: Czy głównie uruchamiacie zaplanowane dashboardy, analizę ad hoc, data science, ELT/ETL czy aplikacje klienckie? Potrzebujecie przewidywalnych okien batchowych czy elastycznych pików?
- Współbieżność: Ilu użytkowników/aplikacji zapyta jednocześnie i jak „skokowe” jest to użycie?
- Wymagania udostępniania: Czy trzeba udostępniać dane na żywo partnerom/jednostkom biznesowym bez przesyłania plików? Czy oczekujecie konsumpcji zestawów third‑party?
- Dopasowanie narzędzi: Czy BI, orkiestracja, katalog i CI/CD zintegrowane bez problemów? Co się psuje przy przenosinach?
- Governance i bezpieczeństwo: Potrzebujecie drobnoziarnistego dostępu, ścieżek audytu, maskowania, polityk retencji i separacji obowiązków?
- Ograniczenia kosztów: Które koszty są krytyczne — całkowite stałe, koszty w godzinach szczytu, czy możliwość wyłączania compute? Jak zapobiegniecie marnotrawstwu „zawsze włączonych”?
Krótki plan pilotażowy (2–4 tygodnie)
Wybierz 2–3 reprezentatywne zbiory (nie próbki): jedną dużą tabelę faktów, jedno nieuporządkowane źródło semi‑structured i jedną krytyczną domenę biznesową.
Uruchom rzeczywiste zapytania użytkowników: poranne szczyty dashboardów, eksploracje analityków, zaplanowane ładowania i kilka najbardziej kosztownych joinów. Mierz: czas zapytania, zachowanie przy współbieżności, czas ingestu, nakład operacyjny i koszt per obciążenie.
Jeśli ocena ma obejmować „jak szybko możemy coś wypuścić”, dodaj mały deliverable do pilota — np. wewnętrzną aplikację metryczną lub nadzorowany workflow żądań danych, który pyta Snowflake. Budowanie tej cienkiej warstwy często ujawnia integracyjne i bezpieczeństwa realia szybciej niż same benchmarki, a narzędzia jak Koder.ai potrafią przyspieszyć przejście od prototypu do produkcji, generując strukturę aplikacji przez chat i pozwalając wyeksportować kod.
Sugerowane kolejne kroki
Jeżeli chcesz pomocy przy szacowaniu wydatków i porównaniu opcji, zacznij od /pricing.
W kwestii migracji i governance zajrzyj do powiązanych artykułów w /blog.