Co w praktyce oznaczają spójność i dostępność
Gdy baza danych jest rozproszona na kilku maszynach (replikach), zyskujesz szybkość i odporność — ale wprowadzasz też okresy, gdy te maszyny nie zgadzają się całkowicie albo nie mogą się niezawodnie komunikować.
Spójność (prosto)
Spójność oznacza: po udanym zapisie każdy odczyt zwraca tę samą wartość. Jeśli zaktualizujesz swój adres e‑mail w profilu, następny odczyt — niezależnie od tego, która replika odpowie — zwróci nowy adres.
W praktyce systemy, które priorytetyzują spójność, mogą opóźniać lub odrzucać niektóre żądania podczas awarii, aby uniknąć sprzecznych odpowiedzi.
Dostępność (prosto)
Dostępność oznacza: system odpowiada na każde żądanie, nawet jeśli niektóre serwery są wyłączone lub odłączone. Możesz nie dostać najnowszych danych, ale otrzymujesz odpowiedź.
W praktyce systemy, które priorytetyzują dostępność, mogą akceptować zapisy i obsługiwać odczyty nawet gdy repliki się nie zgadzają, a różnice rozwiązywać później.
Co ten kompromis znaczy dla rzeczywistych aplikacji
„Kompromis” oznacza, że nie da się maksymalizować obu celów jednocześnie w każdej sytuacji awaryjnej. Gdy repliki nie mogą się skoordynować, baza musi albo:
- czekać/odrzucać niektóre żądania, aby chronić jednolitą prawdę (faworyzować spójność), albo
- nadal odpowiadać użytkownikom, ryzykując przestarzałe lub sprzeczne dane (faworyzować dostępność)
Prosty przykład: koszyk sklepu kontra przelew bankowy
- Koszyk sklepu: jeśli liczba przedmiotów chwilowo jest inna na innym urządzeniu, to denerwujące, ale zwykle akceptowalne. Wiele zespołów woli wyższą dostępność i późniejsze pogodzenie danych.
- Przelew bankowy: jeśli przenosisz 500 USD i saldo chwilowo pokazuje dwie różne wartości, to poważny problem. Tutaj częściej warto zaakceptować sporadyczne komunikaty „spróbuj ponownie” na rzecz silnej spójności.
Nie ma jednego najlepszego wyboru
Właściwa równowaga zależy od tego, jakie błędy możesz znieść: krótką przerwę w działaniu czy chwilę niepoprawnych/starych danych. Większość systemów wybiera punkt pośrodku i jawnie określa kompromis.
Dlaczego rozproszenie zmienia zasady gry
Baza jest „rozproszona”, gdy przechowuje i serwuje dane z wielu maszyn (węzłów), które koordynują się przez sieć. Dla aplikacji może to nadal wyglądać jak jedna baza — ale pod maską żądania mogą obsługiwać różne węzły w różnych miejscach.
Replikacja: dlaczego zespoły dodają węzły
Większość rozproszonych baz replikuje dane: ten sam rekord jest przechowywany na wielu węzłach. Robi się to, aby:
- utrzymać usługę, gdy jedna maszyna padnie
- zmniejszyć opóźnienie, obsługując użytkowników z pobliskiego węzła
- skalować odczyty (a czasem zapisy) na więcej zasobów
Replikacja jest potężna, ale od razu pojawia się pytanie: jeśli dwa węzły mają kopię tych samych danych, jak zagwarantować, że zawsze będą się zgadzać?
Częściowe awarie są normą, nie wyjątkiem
Na jednym serwerze „awaria” jest zwykle oczywista: maszyna działa albo nie. W systemie rozproszonym awaria często jest częściowa. Jeden węzeł może być żywy, ale wolny. Łącze sieciowe może gubić pakiety. Cały regał może stracić łączność, gdy reszta klastra nadal działa.
To ma znaczenie, bo węzły nie mogą natychmiast wiedzieć, czy inny węzeł jest naprawdę nieaktywny, tymczasowo nieosiągalny, czy po prostu opóźniony. Gdy czekają, muszą zdecydować, co zrobić z przychodzącymi odczytami i zapisami.
Gwarancje zmieniają się, gdy komunikacja nie jest pewna
Na jednym serwerze jest jedno źródło prawdy: każdy odczyt widzi najnowszy udany zapis.
Na wielu węzłach „najnowsze” zależy od koordynacji. Jeśli zapis powiedzie się na węźle A, ale węzeł B jest nieosiągalny, czy baza powinna:
- zablokować zapis, dopóki B go nie potwierdzi (chroniąc spójność), czy
- zaakceptować zapis mimo to (chroniąc dostępność)?
To napięcie — spowodowane niedoskonałością sieci — właśnie zmienia reguły gry.
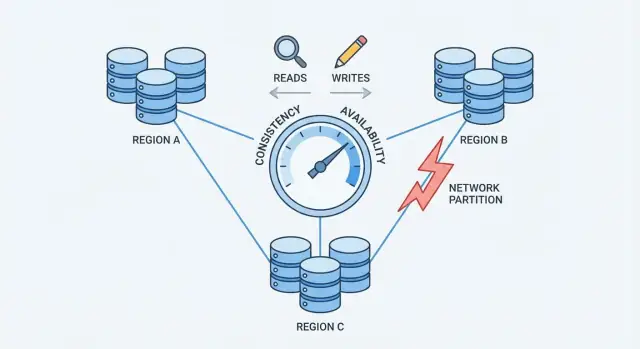
Partycje sieciowe: kluczowy problem
Partycja sieciowa to przerwa w komunikacji między węzłami, które mają działać jak jedna baza. Węzły mogą być nadal uruchomione i zdrowe, ale nie mogą niezawodnie wymieniać wiadomości — z powodu uszkodzonego switcha, przeciążonego łącza, błędnej zmiany routingu, źle skonfigurowanego firewalla lub nawet „hałaśliwego sąsiada” w chmurze.
Dlaczego partycje są nieuniknione w skali
Gdy system jest rozproszony na wiele maszyn (często na różne regały, strefy albo regiony), nie kontrolujesz już każdego przeskoku między nimi. Sieci gubią pakiety, wprowadzają opóźnienia i czasem dzielą się na „wyspy”. Na małą skalę zdarzenia te są rzadkie; w dużej skali są rutynowe. Nawet krótkie zaburzenie wystarczy, bo bazy potrzebują stałej koordynacji, by uzgodnić, co się wydarzyło.
Jak partycje tworzą sprzeczne „najnowsze” dane
Podczas partycji obie strony nadal przyjmują żądania. Jeśli użytkownicy mogą zapisywać po obu stronach, każda strona może zaakceptować aktualizacje, których druga nie widzi.
Przykład: Węzeł A aktualizuje adres użytkownika na Nowa Ulica. W tym samym czasie węzeł B aktualizuje go na Stara Ulica lok. 2. Każda strona uważa swój zapis za najnowszy, bo nie ma sposobu, by porównać notatki w czasie rzeczywistym.
Objawy widoczne dla użytkownika
Partycje nie pojawiają się jako ładne komunikaty o błędach; objawiają się jako mylące zachowanie:
- Timeouty: baza czeka na potwierdzenie zapisu lub odczytu z innego węzła.
- Przestarzałe odczyty: odświeżasz i nadal widzisz stare dane, bo trafiłeś na replikę, która nie otrzymała aktualizacji.
- Split-brain: różni użytkownicy widzą różne „prawdy”, zależnie od tego, do której strony dotarli.
To jest punkt nacisku, który wymusza decyzję: gdy sieć nie gwarantuje komunikacji, rozproszona baza musi zdecydować, czy priorytetem jest spójność czy dostępność.
Twierdzenie CAP bez żargonu
CAP to zwięzły sposób opisania tego, co się dzieje, gdy baza jest rozproszona na wiele maszyn.
Trzy terminy (po ludzku)
- Spójność (C): po zapisie każdy późniejszy odczyt zwraca tę samą wartość.
- Dostępność (A): każde żądanie dostaje nie‑błądową odpowiedź, nawet gdy niektóre serwery mają problemy.
- Tolerancja partycji (P): system działa dalej, nawet gdy sieć się dzieli i serwery nie mogą się pewnie komunikować.
Najważniejszy wniosek
Gdy nie ma partycji, wiele systemów może wyglądać na spójne i dostępne jednocześnie.
Gdy jest partycja, trzeba wybrać, co priorytetyzować:
- Wybierz spójność: odrzucaj lub opóźniaj niektóre żądania, aż serwery się uzgodnią.
- Wybierz dostępność: akceptuj żądania po obu stronach podziału, nawet jeśli odpowiedzi tymczasowo będą się różnić.
Prosty harmonogram, który można sobie wyobrazić
- 10:00 Klient zapisuje
balance = 100 na Serwerze A.
- 10:01 Partycja sieciowa: Serwer A nie może dotrzeć do Serwera B.
- 10:02 Klient czyta z Serwera B.
- Jeśli priorytet to spójność, Serwer B musi odmówić lub poczekać.
- Jeśli priorytet to dostępność, Serwer B odpowie, ale może powiedzieć
balance = 80.
Popularne nieporozumienie
CAP nie mówi „zawsze wybierz tylko dwie”. Mówi, że podczas partycji nie można zagwarantować jednocześnie spójności i dostępności. Poza partycjami często da się uzyskać obie cechy w praktyce — aż do kolejnej awarii sieci.
Wybór spójności: co zyskujesz, a co tracisz
Wybierając spójność, baza stawia na to, by „wszyscy widzieli tę samą prawdę” zamiast „zawsze odpowiadać”. W praktyce zwykle oznacza to silną spójność, często opisywaną jako zachowanie liniaryzowalne: gdy zapis zostanie potwierdzony, każdy późniejszy odczyt (skądkolwiek) zwróci tę wartość, jakby istniała jedna, zawsze aktualna kopia.
Co się dzieje podczas partycji
Gdy sieć się podzieli i repliki nie mogą się pewnie komunikować, system o silnej spójności nie może bezpiecznie akceptować niezależnych aktualizacji po obu stronach. Aby chronić poprawność, zazwyczaj:
- Blokuje żądania, czekając na koordynację, lub
- Odrzuca żądania (zwraca błędy/timeouty), jeśli nie może dotrzeć do wymaganych replik/lidera.
Z perspektywy użytkownika może to wyglądać jak przestój, choć niektóre maszyny nadal działają.
Co zyskujesz
Główną korzyścią jest prostsze myślenie. Kod aplikacji może zachowywać się, jakby rozmawiał z jedną bazą, a nie z wieloma replikami, które mogą się różnić. To redukuje „dziwne momenty”, takie jak:
- odczytywanie starszych danych zaraz po udanej aktualizacji
- widzenie dwóch różnych wartości w zależności od trafionej repliki
- łamanie inwariantów (np. nadmierna sprzedaż) z powodu równoległych, konfliktowych zapisów
Dostajesz też czytelniejsze modele myślenia do audytów, rozliczeń i wszystkiego, co musi być poprawne za pierwszym razem.
Co tracisz
Spójność ma realne koszty:
- Wyższe opóźnienia: wiele operacji musi czekać na koordynację (często między maszynami lub regionami).
- Więcej błędów podczas awarii: partycje, wolne repliki lub problemy z liderem mogą przekładać się na timeouty albo komunikat „spróbuj później”.
Jeśli produkt nie może tolerować odrzuconych żądań podczas częściowych awarii, silna spójność może wydawać się zbyt kosztowna — nawet jeśli to właściwy wybór dla poprawności.
Wybór dostępności: co zyskujesz, a co tracisz
Plan your architecture in chat
Zmapuj model danych, endpointy i zasady spójności przed pisaniem implementacji.
Wybierając dostępność, optymalizujesz prostą obietnicę: system odpowiada, nawet gdy część infrastruktury jest niezdrowa. W praktyce „wysoka dostępność” nie znaczy „brak błędów” — znaczy raczej, że większość żądań wciąż otrzymuje odpowiedź podczas awarii węzłów, przeciążeń czy przerw sieciowych.
Co się dzieje podczas partykcji
Gdy sieć się dzieli, repliki nie mogą się pewnie komunikować. Baza, która faworyzuje dostępność, zwykle nadal obsługuje ruch z dostępnej strony:
- Odczyty są obsługiwane lokalnie z danych, które replika ma obecnie.
- Zapisy są akceptowane lokalnie i kolejkowane/replicowane później, gdy łączność wróci.
To utrzymuje aplikacje w ruchu, ale oznacza, że różne repliki mogą tymczasowo akceptować różne prawdy.
Co zyskujesz
Otrzymujesz lepszą dostępność: użytkownicy mogą przeglądać, dodawać przedmioty do koszyka, publikować komentarze czy zapisywać zdarzenia, nawet jeśli region jest odizolowany.
Masz też płynniejsze doświadczenie użytkownika w stresie. Zamiast timeoutów aplikacja może kontynuować działanie z rozsądnym komunikatem („twoja aktualizacja została zapisana”) i zsynchronizować się później. Dla wielu zastosowań konsumenckich i analitycznych taki kompromis jest akceptowalny.
Co tracisz
Kosztem jest to, że baza może zwracać przestarzałe odczyty. Użytkownik może zaktualizować profil na jednej replice, a zaraz potem odczytać z innej i nie zobaczyć swojej zmiany.
Ryzykujesz też konfliktami zapisów. Dwóch użytkowników (lub ten sam użytkownik w dwóch miejscach) może zaktualizować ten sam rekord po różnych stronach partycji. Gdy partycja zniknie, system musi pogodzić rozbieżne historie. W zależności od reguł, jeden zapis może „wygrać”, pola mogą zostać scaliowane, albo konflikt może wymagać logiki aplikacji.
Projektowanie z naciskiem na dostępność polega na zaakceptowaniu tymczasowego nieporozumienia, tak aby produkt nadal odpowiadał — a następnie zainwestowaniu w wykrywanie i naprawę rozbieżności później.
Kworum i głosowanie: rozwiązanie pośrednie
Kworum to praktyczna technika „głosowania”, której wiele replikowanych baz używa, by wyważyć spójność i dostępność. Zamiast ufać pojedynczej replice, system pyta wystarczającą liczbę replik o zgodę.
Pomysł (N, R, W)
Często kworum opisuje się trzema liczbami:
- N: ile replik istnieje dla fragmentu danych
- W: ile replik musi potwierdzić zapis, żeby był uznany za udany
- R: ile replik jest konsultowanych przy odczycie
Zwykła zasada to: jeśli R + W > N, to każdy odczyt ma część wspólną z ostatnim udanym zapisem przynajmniej na jednej replice, co zmniejsza szansę odczytu przestarzałych danych.
Intuicyjne przykłady
Jeśli masz N=3 replik:
- Podejście z jedną repliką (R=1, W=1): szybkie i bardzo dostępne, ale łatwo trafić na nieaktualną replikę.
- Głosowanie większości (R=2, W=2): zapis musi dotrzeć do 2 replik, a odczyt konsultuje 2 repliki. Zwiększa to prawdopodobieństwo zobaczenia najnowszej wartości, bo zestawy odczytu i zapisu nachodzą na siebie.
Niektóre systemy idą dalej, ustawiając W=3 (wszystkie repliki) dla silniejszej spójności, ale to może powodować więcej niepowodzeń zapisu, gdy którakolwiek replika jest wolna lub niedostępna.
Co kworum robi podczas partycji
Kworum nie usuwa problemów partycji — definiuje, kto ma prawo iść naprzód. Jeśli sieć dzieli się 2–1, strona z 2 replikami nadal może spełnić R=2 i W=2, podczas gdy odizolowana pojedyncza replika nie może. To zmniejsza liczbę konfliktujących aktualizacji, ale znaczy też, że część klientów zobaczy błędy lub timeouty.
Kompromisy
Kworum zwykle oznacza wyższe opóźnienie (więcej węzłów do kontaktu), wyższe koszty (więcej ruchu między węzłami) i bardziej zniuansowane zachowanie przy awariach (timeouty mogą wyglądać jak niedostępność). Korzyścią jest jednak regulowany środek: możesz ustawić R i W bliżej świeższych odczytów lub wyższego prawdopodobieństwa powodzenia zapisu, w zależności od tego, co jest ważniejsze.
Eventual consistency i typowe anomalie
Eventual consistency oznacza, że repliki mogą być tymczasowo niespójne, o ile z czasem zbiegną się do tej samej wartości.
Konkretna analogia
Pomyśl o sieci kawiarni aktualizującej wspólny znak "wyprzedane" dla ciastka. Jeden sklep oznacza wyprzedane, ale aktualizacja dociera do innych sklepów kilka minut później. W tym oknie inny sklep może nadal pokazywać "dostępne" i sprzedać ostatni egzemplarz. System nie jest "zepsuty" — aktualizacje po prostu się doganiają.
Typowe anomalie, które zauważysz
Gdy dane się propagują, klienci mogą obserwować zaskakające zachowania:
- Przestarzałe odczyty: odczytujesz stare dane z repliki, która nie otrzymała najnowszego zapisu.
- Braki typu read-your-writes: zapisujesz aktualizację, a zaraz potem odczytujesz z innej repliki i nie widzisz własnej zmiany.
- Aktualizacje w złej kolejności: dwie aktualizacje docierają w różnych sekwencjach do różnych replik, chwilowo tworząc niespójne widoki.
Techniki pomagające replikom zbiegać się
Systemy z eventual consistency zwykle dodają mechanizmy w tle, aby zmniejszyć okno niespójności:
- Read repair: jeśli odczyt wykryje niezgodne repliki, system aktualizuje przestarzałe repliki w tle.
- Hinted handoff: jeśli replika jest nieaktywna, inny węzeł tymczasowo przechowuje "wskazówki" o zapisach, które przekaże po powrocie.
- Anti-entropy (synchronizacja): okresowe porównywanie i naprawianie dryfu (np. przy użyciu drzew Merkle'a lub sum kontrolnych).
Kiedy eventual consistency działa dobrze
Pasuje tam, gdzie dostępność jest ważniejsza niż absolutna świeżość: feedy aktywności, liczniki wyświetleń, rekomendacje, cache profili, logi/telemetria i inne dane niekrytyczne, gdzie „zgodne za chwilę” jest akceptowalne.
Rozwiązywanie konfliktów: jak pogodzone są rozbieżne zapisy
Instrument for the trade off
Dodaj metryki opóźnienia, wskaźnik błędów i stalenia danych do aplikacji i iteruj progi.
Gdy baza akceptuje zapisy na wielu replikach, może mieć konflikty: dwie lub więcej aktualizacji tego samego elementu, które wystąpiły niezależnie na różnych replikach zanim te repliki się zsynchronizowały.
Klasyczny przykład to użytkownik zmieniający adres wysyłki na jednym urządzeniu i numer telefonu na drugim. Jeśli każda aktualizacja trafiła na inną replikę podczas tymczasowego rozłączenia, system musi zdecydować, który rekord jest „prawdziwy”, gdy repliki wymienią dane.
Last-write-wins (LWW): proste, ale ryzykowne
Wiele systemów zaczyna od last-write-wins: która aktualizacja ma nowszy znacznik czasu, ta nadpisuje pozostałe.
To jest atrakcyjne, bo proste do wdrożenia i szybkie do obliczenia. Minusem jest to, że może cicho utracić dane. Jeśli "najnowsze" wygrywa, starsza, ale ważna zmiana może zostać odrzucona — nawet gdy aktualizacje dotyczyły różnych pól.
Zakłada też, że znaczniki czasu są wiarygodne. Różnice zegarów między maszynami (clock skew) mogą spowodować, że "zły" zapis wygra.
Przechowywanie historii: wektory wersji i pokrewne pomysły
Bezpieczniejsze podejście do konfliktów zwykle wymaga śledzenia przyczynowej historii.
Na poziomie koncepcyjnym wektory wersji (i prostsze warianty) dołączają do rekordu mały fragment metadanych, który podsumowuje "która replika widziała które aktualizacje". Gdy repliki wymieniają wersje, baza może wykryć, czy jedna wersja zawiera drugą (brak konfliktu), czy też się rozeszły (konflikt wymagający rozwiązania).
Niektóre systemy używają znaczników logicznych (np. zegary Lamporta) lub hybrydowych zegarów logicznych, by zmniejszyć poleganie na czasie ściennym, a jednocześnie dostarczyć wskazówkę porządkowania.
Scalanie zamiast nadpisywania
Po wykryciu konfliktu masz wybory:
- Scalenie na poziomie aplikacji: aplikacja decyduje, jak połączyć pola, poprosić użytkownika o wybór lub przechować obie wersje do przeglądu.
- CRDT: struktury danych zaprojektowane tak, by automatycznie i deterministycznie się scalać (przydatne dla liczników, zbiorów, tekstów współpracujących itp.). Unikają często podejścia "zwycięzca bierze wszystko" przy jednoczesnym zachowaniu wysokiej dostępności.
Najlepsze podejście zależy od tego, co znaczy „poprawne” dla twoich danych — czasem utrata zapisu jest akceptowalna, a czasem to krytyczny błąd biznesowy.
Jak wybrać dla swojego przypadku użycia
Wybór postawy wobec spójności/dostępności to decyzja produktowa, nie filozoficzna. Zacznij od pytania: jaki jest koszt bycia w błędzie przez moment i jaki koszt powiedzenia użytkownikowi "spróbuj ponownie później"?
Przyporządkuj ryzyko biznesowe do potrzeb spójności
Niektóre domeny potrzebują jednoznacznej odpowiedzi w czasie zapisu, bo "prawie poprawne" dalej jest błędem:
- Pieniądze i rozliczenia: podwójne obciążenia, debety i zwroty zwykle wymagają silnej spójności.
- Tożsamość i uprawnienia: logowanie, reset hasła, kontrola dostępu i zmiany ról powinny unikać split-brain.
- Zapas i pojemność: jeśli overselling jest niedopuszczalny (bilety, limitowane stany), postaw na spójność lub zaprojektuj rezerwacje.
Jeśli skutki tymczasowej niespójności są niewielkie lub odwracalne, zwykle możesz skłonić się ku większej dostępności.
Zdecyduj, ile przestarzałości możesz tolerować
Wiele doświadczeń użytkownika dobrze działa ze lekko starymi odczytami:
- Feedy i timeliney: post może pojawić się z kilkusekundowym opóźnieniem.
- Analityka i pulpity: partie danych opóźnione są często oczekiwane.
- Cache i indeksy wyszukiwania: użytkownicy akceptują "jeszcze nie zaktualizowane", jeśli jest szybkie i stabilne.
Określ jawnie, jak bardzo może być przestarzałe: sekundy, minuty czy godziny. Ten budżet czasowy kieruje twoimi wyborami replikacji i kworum.
Wybierz tryb awarii, który najbardziej zirytuje użytkownika najmniej
Gdy repliki nie mogą się zgodzić, zwykle kończysz z jednym z trzech UX:
- Kółko ładowania / oczekiwanie (priorytet poprawności, może być powolne)
- Błąd / ponówienie (szczery, ale uciążliwy)
- Przestarzały wynik (płynne, ale okazjonalnie zaskakujące)
Wybierz najmniej szkodliwą opcję dla danej funkcji, nie globalnie.
Szybka lista kontrolna
Skłaniaj się ku C (spójność), jeśli błędne wyniki tworzą ryzyko finansowe/prawne, problemy bezpieczeństwa lub działania nieodwracalne.
Skłaniaj się ku A (dostępność), jeśli użytkownicy cenią responsywność, przestarzałość danych jest tolerowalna, a konflikty można bezpiecznie rozwiązać później.
W razie wątpliwości rozdziel system: trzymaj krytyczne rekordy spójne, a widoki pochodne optymalizuj pod dostępność.
Wzorce projektowe zmniejszające ból wynikający z kompromisu
Validate long workflows
Zaprojektuj prototyp sagi z kompensującymi akcjami, aby obsłużyć częściowe awarie czysto.
Rzadko musisz wybrać jedną ustawę spójności dla całego systemu. Wiele nowoczesnych rozproszonych baz pozwala wybrać spójność per operacja — i inteligentne aplikacje korzystają z tego, by utrzymać UX bez udawania, że kompromisu nie ma.
Używaj poziomów spójności per operacja
Traktuj spójność jak pokrętło, które ustawiasz w zależności od działania użytkownika:
- Krytyczne aktualizacje (płatności, zmniejszenia zapasów, zmiany haseł): używaj silniejszej spójności (np. zapisy kworum/linearizowalne).
- Nie‑krytyczne odczyty (feedy, pulpity, "ostatnio widziany"): pozwól na słabsze odczyty (lokalne/jedna replika/eventual) dla szybkości i odporności.
To pozwala nie płacić kosztu najsilniejszej spójności za wszystko, a jednocześnie chroni operacje, które tego naprawdę potrzebują.
Mieszaj silne i słabe w jednym przepływie
Popularny wzorzec to silne dla zapisów, słabsze dla odczytów:
- Zapisz z surowym poziomem, aby system miał autorytatywny rekord.
- Czytaj luźniej, a jeśli wykryjesz coś niepokojącego (brak pozycji, przestarzały licznik), odśwież odczyt silniejszym trybem lub pokaż komunikat "wciąż aktualizujemy".
Czasem odwrotnie działa lepiej: szybkie zapisy (kolejkowane/eventual) i silne odczyty, gdy trzeba potwierdzić wynik ("Czy moje zamówienie zostało złożone?").
Projektuj pod kątem ponowień: idempotencja
Gdy sieć chwiejnie działa, klienci ponawiają. Uczyń ponowienia bezpiecznymi za pomocą kluczy idempotentności, aby "złóż zamówienie" wykonane dwukrotnie nie tworzyło dwóch zamówień. Przechowuj i zwracaj pierwszy rezultat, gdy zobaczysz ten sam klucz ponownie.
Długie przepływy: sagi i kompensacje
Dla wieloetapowych akcji między usługami użyj sagi: każdy krok ma odpowiadającą mu akcję kompensującą (zwrot, zwolnienie rezerwacji, anulowanie wysyłki). To utrzymuje system możliwym do odzyskania, nawet gdy częściowo się rozbiegną lub zawiodą.
Testowanie i obserwowalność kompromisu spójność vs dostępność
Nie możesz zarządzać kompromisem, jeśli go nie widzisz. Problemy produkcyjne często wyglądają jak "losowe awarie" dopóki nie dodasz właściwych pomiarów i testów.
Co mierzyć (i dlaczego)
Zacznij od kilku metryk, które bezpośrednio odnoszą się do wpływu na użytkownika:
- Opóźnienie (p50/p95/p99): obserwuj skoki podczas failoverów, zmian lidera lub retrajów kworum.
- Wskaźnik błędów: rozdziel "twarde" błędy (timeouty, 5xx) od "miękkich" (wynik z fallbacku, częściowe rezultaty).
- Procent przestarzałych odczytów: odsetek odczytów zwracających dane starsze niż twój cel (np. starsze niż 2 sekundy).
- Wskaźnik konfliktów: jak często równoległe zapisy wymagają pogodzenia (w tym nadpisania LWW).
Jeśli możesz, otaguj metryki wg trybu spójności (kworum vs lokalny) i regionu/strefy, aby wyłapać miejsca, gdzie zachowanie się różni.
Testuj partycje celowo
Nie czekaj na prawdziwą awarię. W stagingu uruchamiaj eksperymenty chaosowe symulujące:
- gubienie pakietów i wysokie opóźnienia między replikami
- jeden region staje się nieosiągalny
- częściowe partycje, gdzie tylko niektóre węzły się komunikują
Sprawdzaj nie tylko "system nadal działa", ale jakie gwarancje są zachowane: czy odczyty pozostają świeże, czy zapisy się blokują, czy klienci dostają jasne błędy?
Alerty, które wychwytują kompromis wcześnie
Dodaj alerty dla:
- opóźnienia replikacji przekraczającego tolerowany próg stalenia
- błędów kworum (nie można osiągnąć wystarczającej liczby replik) i rosnącej liczby retry
- wzrostu konfliktów zapisu lub zaległości w ich rozwiązywaniu
Na koniec, jawnie określ, jakie gwarancje system daje w normalnej pracy i podczas partycji, oraz przeszkol zespoły produktowe i wsparcia, jakie objawy użytkownicy mogą zobaczyć i jak reagować.
Szybsze prototypowanie wyborów CAP (bez przebudowy wszystkiego)
Jeśli eksplorujesz te kompromisy w nowym produkcie, warto wcześniej zweryfikować założenia — zwłaszcza dotyczące trybów awarii, zachowań przy ponawianiu i tego, jak wygląda "przestarzałe" w UI.
Praktyczne podejście to prototypowanie małej wersji przepływu (ścieżka zapisu, ścieżka odczytu, retry/idempotencja i zadanie pogodzeniowe) przed decyzją o pełnej architekturze. Z Koder.ai zespoły mogą szybko wystartować aplikacje webowe i back-endy przez chatowy workflow, iterować modele danych i API oraz testować różne wzorce spójności (np. ścisłe zapisy + luźne odczyty) bez narzutów tradycyjnego procesu build. Gdy prototyp odwzorowuje oczekiwane zachowanie, możesz wyeksportować kod źródłowy i rozwijać go dalej.