08 paź 2025·8 min
Rozproszone bazy SQL: kiedy użyć Spanner, Cockroach, Yugabyte
Dowiedz się, czym jest Distributed SQL, jak różnią się Spanner, CockroachDB i YugabyteDB oraz które przypadki użycia uzasadniają wieloregionalne, silnie spójne SQL.
Dowiedz się, czym jest Distributed SQL, jak różnią się Spanner, CockroachDB i YugabyteDB oraz które przypadki użycia uzasadniają wieloregionalne, silnie spójne SQL.
„Distributed SQL” to baza danych, która wygląda i działa jak tradycyjna relacyjna baza danych — tabele, wiersze, joiny, transakcje i SQL — ale jest zaprojektowana do pracy jako klaster na wielu maszynach (i często w wielu regionach), zachowując się jak jedna logiczna baza danych.
To połączenie jest ważne, bo próbuje dostarczyć trzy rzeczy naraz:
Klasyczny RDBMS (jak PostgreSQL czy MySQL) zwykle jest najprostszy w obsłudze, gdy wszystko działa na jednym węźle głównym. Można skalować odczyty replikami, ale skalowanie zapisów i przetrwanie awarii regionalnych zwykle wymaga dodatkowej architektury (sharding, ręczny failover i ostrożna logika po stronie aplikacji).
Wiele systemów NoSQL przyjęło przeciwne podejście: najpierw skalowanie i wysoką dostępność, czasem kosztem gwarancji spójności lub z prostszym modelem zapytań.
Distributed SQL szuka środkowej drogi: zachowuje model relacyjny i transakcje ACID, ale automatycznie rozprowadza dane, aby obsłużyć wzrost i awarie.
Bazy Distributed SQL powstają dla problemów takich jak:
Dlatego rozwiązania takie jak Google Spanner, CockroachDB i YugabyteDB często są brane pod uwagę do wdrożeń wieloregionalnych i usług „zawsze dostępnych”.
Distributed SQL nie jest automatycznie „lepsze”. Akceptujesz więcej ruchomych części i inne realia wydajności (przejścia sieciowe, konsensus, opóźnienia między regionami) w zamian za odporność i skalę.
Jeśli twoje obciążenie mieści się na pojedynczej dobrze zarządzanej bazie z prostą replikacją, konwencjonalny RDBMS może być prostszy i tańszy. Distributed SQL się opłaca, gdy alternatywą jest ręczne shardowanie, skomplikowany failover lub wymagania biznesowe, które wymagają wieloregionalnej spójności i dostępności.
Distributed SQL ma sprawiać wrażenie znajomej bazy SQL, jednocześnie przechowując dane na wielu maszynach (i często w wielu regionach). Trudne jest skoordynowanie wielu komputerów, by zachowywały się jak jeden niezawodny system.
Każda część danych jest zwykle kopiowana na kilka węzłów (replikacja). Jeśli jeden węzeł padnie, inna kopia nadal może obsługiwać odczyty i przyjmować zapisy.
Aby zapobiec rozjechaniu się replik, systemy Distributed SQL używają protokołów konsensusu — najczęściej Raft (CockroachDB, YugabyteDB) lub Paxos (Spanner). Na wysokim poziomie konsensus oznacza:
Ta „większość” daje ci silną spójność: po zatwierdzeniu transakcji inni klienci nie zobaczą starszej wersji danych.
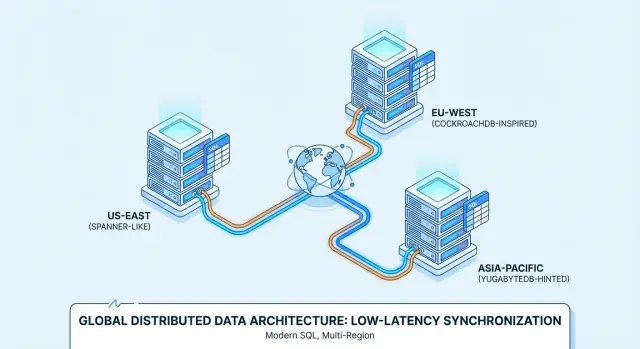
Żaden pojedynczy komputer nie pomieści wszystkiego, więc tabele są dzielone na mniejsze kawałki zwane shardami/partycjami (Spanner nazywa je splits; CockroachDB — ranges; YugabyteDB — tablets).
Każda partycja jest replikowana (przez konsensus) i umieszczana na określonych węzłach. Umieszczenie nie jest losowe: można je sterować politykami (np. trzymać rekordy klientów z UE w regionach UE lub umieszczać gorące partycje na szybszych węzłach). Dobre rozmieszczenie zmniejsza liczbę wywołań między sieciami i poprawia przewidywalność wydajności.
W bazie na jednym węźle transakcja może często zatwierdzić się przy lokalnej pracy dysku. W Distributed SQL transakcja może dotykać wielu partycji — potencjalnie na różnych węzłach.
Bezpieczne zatwierdzenie zwykle wymaga dodatkowej koordynacji:
Te kroki wprowadzają rundy sieciowe, dlatego transakcje rozproszone zwykle zwiększają latencję—zwłaszcza gdy dane rozciągają się między regionami.
Gdy wdrożenia obejmują regiony, systemy próbują trzymać operacje „blisko” użytkowników:
To jest sedno wieloregionalnego kompromisu: możesz optymalizować responsywność lokalną, ale silna spójność na dużych odległościach nadal pociąga koszt sieciowy.
Zanim sięgniesz po distributed SQL, sprawdź swoje potrzeby. Jeśli masz jeden główny region, przewidywalne obciążenie i mały zespół operacyjny, konwencjonalna relacyjna baza (albo zarządzany Postgres/MySQL) zwykle pozwoli szybciej wypuszczać funkcje. Często da się wycisnąć bardzo wiele z pojedynczego regionu przy pomocy replik odczytowych, cache'owania i optymalizacji schematu/indeksów.
Distributed SQL warto rozważyć, gdy jedno (lub więcej) z poniższych jest prawdą:
Systemy rozproszone dodają złożoność i koszty. Bądź ostrożny, jeśli:
Jeśli na dwa lub więcej pytań odpowiesz „tak”, distributed SQL prawdopodobnie warto ocenić:
Distributed SQL brzmi jak „otrzymujesz wszystko naraz”, ale realne systemy wymuszają wybory—szczególnie gdy regiony mają problemy z łącznością.
Pomyśl o partycji sieci jako o „łączu między regionami jest niestabilne lub zerwane”. W tym momencie baza może priorytetyzować:
Systemy Distributed SQL zwykle są budowane tak, aby w pierwszej kolejności dbać o spójność dla transakcji. Zwykle zespoły tego chcą — dopóki partycja sieci nie wymusi oczekiwania lub odrzucenia niektórych operacji.
Silna spójność oznacza, że po zatwierdzeniu transakcji każdy kolejny odczyt zwróci tę wartość—nie ma sytuacji „zrobione w jednym regionie, ale nie w innym”. To jest krytyczne dla:
Jeśli obietnicą produktu jest „jeśli potwierdzimy, to jest to prawdziwe”, silna spójność to funkcja, nie luksus.
Dwie praktyczne właściwości mają znaczenie:
Silna spójność między regionami zwykle wymaga konsensusu (kilka replik musi się zgodzić przed zatwierdzeniem). Gdy repliki rozciągają się między kontynentami, prędkość światła staje się ograniczeniem produktu: każdy zapis międzyregionowy może dodać od dziesiątek do setek milisekund.
Kompromis jest prosty: więcej geograficznego bezpieczeństwa i poprawność często oznaczają wyższą latencję zapisu, chyba że starannie wybierzesz, gdzie dane żyją i gdzie transakcje mogą być zatwierdzane.
Google Spanner to rozproszona baza SQL oferowana głównie jako usługa zarządzana w Google Cloud. Zaprojektowana do wdrożeń wieloregionalnych, gdy chcesz jednej logicznej bazy z replikacją danych między węzłami i regionami. Spanner obsługuje dwa dialekty SQL — GoogleSQL (własny dialekt) oraz dialekt zgodny z PostgreSQL — więc przenośność zależy od wybranego dialektu i używanych funkcji.
CockroachDB to rozproszona baza SQL, która ma przypominać zespołom pracującym z PostgreSQL. Używa protokołu wire PostgreSQL i obsługuje dużą część stylu SQL Postgresa, ale nie jest bit-do-bitu zamiennikiem Postgresa (pewne rozszerzenia i zachowania kątowe mogą się różnić). Można ją uruchomić jako usługę zarządzaną (CockroachDB Cloud) lub hostować samodzielnie.
YugabyteDB to rozproszona baza z kompatybilnym API SQL PostgreSQL (YSQL) i dodatkowym API zgodnym z Cassandra (YCQL). Podobnie jak CockroachDB, jest często oceniana przez zespoły, które chcą ergonomii deweloperskiej typu Postgres przy skalowaniu na wiele węzłów i regionów. Dostępna zarówno w modelu self-hosted, jak i zarządzanym (YugabyteDB Managed), z wdrożeniami od HA w jednym regionie po konfiguracje wieloregionalne.
Usługi zarządzane zwykle redukują pracę operacyjną (upgrade’y, backupy, integracje monitoringu), podczas gdy self-hosting daje większą kontrolę nad siecią, typami instancji i fizycznym umiejscowieniem danych. Spanner jest najczęściej używany jako usługa zarządzana na GCP; CockroachDB i YugabyteDB występują zarówno w modelach zarządzanych, jak i self-hosted, w tym w multi-cloud i on-prem.
Wszystkie trzy „mówią” SQL, ale codzienna kompatybilność zależy od wyboru dialektu (Spanner), pokrycia funkcji Postgresa (CockroachDB/YugabyteDB) i od tego, czy aplikacja korzysta z konkretnych rozszerzeń, funkcji lub specyficznych semantyk transakcyjnych Postgresa.
Warto poświęcić czas na planowanie: testuj zapytania, migracje i zachowanie ORM wcześnie, zamiast zakładać, że wszystko będzie drop-in kompatybilne.
Klasycznym dopasowaniem dla distributed SQL jest produkt B2B SaaS z klientami w Ameryce Północnej, Europie i APAC — narzędzia wsparcia, platformy HR, pulpity analityczne czy marketplace’y.
Wymaganie biznesowe jest proste: użytkownicy chcą „lokalnej” responsywności, a firma chce jednej logicznej bazy, która jest zawsze dostępna.
Wiele zespołów SaaS spotyka mieszane wymagania:
Distributed SQL może to modelować czysto przez lokalność per-tenant: umieszczasz podstawowe dane najemcy w określonym regionie (lub zestawie regionów), zachowując ten sam schemat i model zapytań w całym systemie. To pozwala uniknąć „bazy na region” rozrostu i jednocześnie spełnić wymagania dotyczące lokalizacji.
Aby utrzymać szybkość aplikacji, zwykle dążysz do:
To ma znaczenie, ponieważ rundy międzyregionalne dominują postrzeganą przez użytkownika latencję. Nawet przy silnej spójności, dobra lokalność sprawia, że większość żądań nie płaci ceny za międzykontynentalne opóźnienia.
Techniczne korzyści znaczą tylko wtedy, gdy operacje pozostają możliwe do zarządzania. Dla globalnego SaaS zaplanuj:
Dobrze wykonane, distributed SQL daje pojedyncze doświadczenie produktu, które nadal „czuje się lokalnie” — bez dzielenia zespołu inżynierów na „stos EU” i „stos APAC”.
Systemy finansowe to miejsce, gdzie "eventual consistency" może oznaczać realne straty pieniędzy. Jeśli klient składa zamówienie, autoryzacja płatności przechodzi, a saldo jest aktualizowane, te kroki muszą zgadzać się co do jednej prawdy—tu i teraz.
Silna spójność ma znaczenie, bo zapobiega sytuacjom, w których dwa regiony (lub dwa serwisy) podejmują „rozsądną” decyzję, która razem daje błędny wynik w księdze.
W typowym przepływie—stwórz zamówienie → zarezerwuj środki → przechwyć płatność → zaktualizuj saldo/księgę—chcesz gwarancji takich jak:
Distributed SQL pasuje tu, bo daje transakcje ACID i ograniczenia rozciągnięte na węzły (i często regiony), dzięki czemu inwarianty księgi utrzymują się nawet podczas awarii.
Integracje płatnicze zwykle są retry-heavy: time-outy, powtórzenia webhooków i ponowne przetwarzanie zadań są normalne. Baza powinna pomóc uczynić retry bezpiecznym.
Praktyczne podejście to połączenie kluczy idempotencji po stronie aplikacji z restrykcjami wymuszonymi przez bazę:
idempotency_key dla każdej próby płatności/klienta.(account_id, idempotency_key).Wtedy druga próba stanie się bezskuteczna zamiast podwójnego obciążenia.
Wydarzenia sprzedażowe i przetwarzanie płac mogą powodować nagłe partie zapisów (autoryzacje, capture’y, przelewy). Z distributed SQL można zwiększyć przepustowość przez dodanie węzłów, zachowując ten sam model spójności.
Kluczowe jest planowanie wobec gorących kluczy (np. jeden rachunek przyjmujący cały ruch) i stosowanie wzorców schematu, które rozkładają obciążenie.
Przepływy finansowe zwykle wymagają niemutowalnych śladów audytu, śledzenia (kto/co/kiedy) i przewidywalnych reguł retencji. Nawet bez wskazywania konkretnych regulacji zakładaj: wpisy księgi tylko-do-dodawania, znaczniki czasowe, kontrolowany dostęp i zasady archiwizacji/retencji, które nie psują możliwości audytu.
Inwentarz i rezerwacje wydają się proste, dopóki masz wiele regionów obsługujących ten sam ograniczony zasób: ostatnie miejsce na koncercie, limitowana pula produktów czy pokój hotelowy na konkretną noc.
Trudność nie polega na odczytaniu dostępności—tylko na zapobieganiu, by dwie osoby nie zarezerwowały tego samego przedmiotu niemal jednocześnie.
W konfiguracji wieloregionalnej bez silnej spójności każdy region może chwilowo wierzyć, że ma dostępny inwentarz bazując na nieco przeterminowanych danych. Jeśli dwie osoby z różnych regionów finalizują checkout w tym okienku, oba transakcje mogą zostać zaakceptowane lokalnie i dopiero później pojawi się konflikt podczas reconciliacji.
Tak powstaje oversell między regionami: nie dlatego, że system jest "zły", lecz dlatego, że dopuścił chwile rozbieżnych prawd.
Distributed SQL jest tu często wybierany, bo może wymusić jedną autorytatywną wynikową decyzję przy zapisie—więc „ostatnie miejsce” naprawdę jest przydzielone tylko raz, nawet jeśli żądania przychodzą z różnych kontynentów.
Hold + confirm: Umieść tymczasową rezerwację (record hold) w transakcji, a dopiero potem potwierdź płatność w drugim kroku.
Wygaszenia: Holdy powinny wygasać automatycznie (np. po 10 minutach), aby zapobiec blokowaniu inwentarza, gdy użytkownik porzuci checkout.
Transakcyjny outbox: Gdy rezerwacja jest potwierdzona, zapisz w tej samej transakcji wiersz „zdarzenie do wysłania”, a potem dostarcz go asynchronicznie do e-maila, fulfillmentu, analityki lub busa wiadomości—bez ryzyka „zarezerwowane, ale nie wysłano potwierdzenia”.
Wniosek: jeśli firma nie może tolerować podwójnego przydziału między regionami, gwarancje transakcyjne stają się funkcją produktu, a nie technicznym miłym dodatkiem.
Wysoka dostępność (HA) dobrze pasuje do Distributed SQL, gdy przestój jest kosztowny, nieprzewidywalne awarie są nieakceptowalne, a chcesz, by prace konserwacyjne były nudne.
Cel nie jest „nigdy się nie psuć” — chodzi o spełnienie mierzalnych SLO (np. 99.9% lub 99.99% dostępności) nawet gdy węzły padają, strefy stają się niedostępne, lub robisz upgrade.
Przekształć „zawsze dostępne” w mierzalne oczekiwania: maksymalny miesięczny czas przestoju, RTO i RPO.
Systemy Distributed SQL mogą dalej obsługiwać odczyty/zapisy podczas wielu typowych awarii, ale tylko jeśli twoja topologia odpowiada SLO, a aplikacja poprawnie radzi sobie z przejściowymi błędami (retry, idempotencja).
Planned maintenance też ma znaczenie. Rolling upgrades i wymiana instancji są prostsze, gdy baza może przenieść liderów/repliki z dala od wpływanych węzłów bez wyłączania całego klastra.
Multi-zone chroni przed awarią jednej AZ/strefy i wieloma awariami sprzętowymi, zwykle z niższą latencją i kosztem. Często wystarcza, gdy zgodność i baza użytkowników są głównie w jednym regionie.
Multi-region chroni przed awarią całego regionu i umożliwia failover regionalny. Kompromisem jest wyższa latencja zapisów dla silnie spójnych transakcji obejmujących regiony oraz bardziej złożone planowanie pojemności.
Nie zakładaj, że failover jest natychmiastowy lub niewidoczny. Zdefiniuj, co „failover” znaczy dla twojej usługi: krótkie skoki błędów? okresy tylko do odczytu? kilka sekund podwyższonej latencji?
Przeprowadzaj "game days":
Nawet przy synchronicznej replikacji zachowaj backupy i ćwicz przywracanie. Backupy chronią przed błędami ludzkimi (złe migracje, przypadkowe usunięcia), błędami aplikacji i korupcją, która się replikowała.
Sprawdź odzyskiwanie do konkretnego punktu w czasie (jeśli dostępne), szybkość przywracania i możliwość odtworzenia środowiska bez dotykania produkcji.
Wymogi dotyczące lokalizacji danych pojawiają się, gdy regulacje, umowy lub wewnętrzne polityki mówią, że określone rekordy muszą być przechowywane (i czasem przetwarzane) w konkretnym kraju/regionie.
Dotyczy to danych osobowych, informacji medycznych, danych płatniczych, obciążeń rządowych lub „danych należących do klienta”, gdzie umowa dyktuje miejsce przetwarzania.
Distributed SQL jest rozważany, bo potrafi utrzymać jedną logiczną bazę jednocześnie fizycznie umieszczając dane w różnych regionach—bez konieczności uruchamiania oddzielnego stacku aplikacji na każde terytorium.
Jeśli regulator lub klient wymaga „dane zostają w regionie”, nie wystarczy mieć pobliskich replik. Możesz musieć zagwarantować, że:
To popycha zespoły do architektur, w których lokalizacja jest elementem pierwszorzędnym, a nie myślana ad hoc.
Typowy wzorzec w SaaS to umieszczanie danych per-tenant. Na przykład: dane klientów z UE przypisane są do regionów UE, dane z USA do regionów USA.
Zwykle łączysz:
Celem jest utrudnienie przypadkowego naruszenia zasad lokalizacji przez dostęp operatorski, przywracanie backupu lub replikację między regionami.
Obowiązki związane z lokalizacją i zgodnością różnią się w zależności od kraju, branży i umowy. Zmieniają się też w czasie.
Traktuj topologię bazy jako element programu zgodności i weryfikuj założenia z odpowiednią poradą prawną (i audytorem, gdy to konieczne).
Topologie przyjazne lokalizacji mogą komplikować „globalny widok” biznesu. Jeśli dane klientów są świadomie trzymane w oddzielnych regionach, analityka i raportowanie mogą:
W praktyce wiele zespołów oddziela obciążenia operacyjne (silnie spójne, z uwzględnieniem lokalizacji) od analitycznych (magazyny danych ograniczone regionalnie lub starannie zarządzane zestawy agregatów), by zachować zgodność bez spowalniania codziennych raportów produkcyjnych.
Distributed SQL może oszczędzić przed bolesnymi przestojami i ograniczeniami regionalnymi, ale rzadko sam w sobie obniża koszty. Planowanie z wyprzedzeniem pomaga uniknąć płacenia za „ubezpieczenie”, którego nie potrzebujesz.
Budżet zwykle dzieli się na cztery koszyki:
Systemy Distributed SQL dodają koordynację—szczególnie dla silnie spójnych zapisów, które muszą być potwierdzone przez kworum.
Praktyczny sposób estymacji wpływu:
To nie znaczy „nie rób tego”, ale oznacza, że powinieneś projektować ścieżki, by redukować sekwencyjne zapisy (batching, idempotentne retry, mniej rozmownych transakcji).
Jeśli użytkownicy są głównie w jednym regionie, jednoregionowy Postgres z replikami odczytowymi, dobrymi backupami i przetestowanym planem failover może być tańszy i prostszy—i szybki.
Distributed SQL zwraca koszty, gdy naprawdę potrzebujesz wieloregionowych zapisów, surowych RPO/RTO lub umieszczania danych ze względu na zgodność.
Traktuj wydatki jako wymianę:
Jeśli uniknięte straty (przestoje + odpływ klientów + ryzyko zgodności) są większe niż premia operacyjna, projekt wieloregionalny się opłaca. Jeśli nie, zacznij prościej i miej plan ewolucji.
Adopcja distributed SQL to mniej „podnoszenie i przenoszenie” bazy, a bardziej udowodnienie, że twoje konkretne obciążenie dobrze się zachowuje, gdy dane i konsensus są rozproszone na węzłach (i ewentualnie regionach). Lekki plan pomaga uniknąć niespodzianek.
Wybierz jedno obciążenie, które reprezentuje prawdziwy ból: np. checkout/booking, provisioning konta lub zapisy księgowe.
Zdefiniuj metryki sukcesu przed rozpoczęciem:
Jeśli chcesz przyspieszyć w fazie PoC, pomocne bywa zbudowanie małej „realistycznej” aplikacji (API + UI) zamiast wyłącznie benchmarków syntetycznych. Dla przykładu zespoły czasem używają Koder.ai, by szybko postawić starter React + Go + PostgreSQL w czacie, a potem zamienić warstwę bazy na CockroachDB/YugabyteDB (lub podłączyć Spanner), by testować wzorce transakcyjne, retry i zachowanie przy awariach end-to-end. Cel nie jest w konkretnym stacku startowym—chodzi o skrócenie pętli od "pomysł" do "mierzalne obciążenie".
Baza danych Distributed SQL zapewnia relacyjny interfejs SQL (tabele, joiny, ograniczenia, transakcje), ale działa jako klaster na wielu maszynach—często w różnych regionach—zachowując się jak jedna logiczna baza danych.
W praktyce stara się połączyć:
Pojedynczy węzeł lub konfiguracja primary/replica w RDBMS jest zwykle prostsza, tańsza i szybsza dla OLTP w jednym regionie.
Distributed SQL staje się atrakcyjne, gdy alternatywą są:
Większość systemów opiera się na dwóch podstawowych ideach:
Dzięki temu uzyskujesz silną spójność nawet przy awariach—ale kosztem dodatkowej koordynacji sieciowej.
Dzielą tabele na mniejsze fragmenty (często nazywane partycjami/shardami, lub specyficznie: ranges/tablets/splits). Każda partycja:
Zazwyczaj wpływasz na rozmieszczenie przez polityki, tak aby „gorące” dane i główni zapisujący znajdowali się blisko siebie i redukowali wywołania między sieciami.
Transakcje rozproszone często obejmują wiele partycji, potencjalnie na różnych węzłach lub w regionach. Bezpieczne zatwierdzenie może wymagać:
Te dodatkowe rundy sieciowe są główną przyczyną zwiększonej latencji zapisu—szczególnie gdy konsensus obejmuje różne regiony.
Rozważ distributed SQL, gdy spełnione są co najmniej dwa z poniższych:
Jeśli aplikacja mieści się w jednym regionie z replikami i cache, konwencjonalne RDBMS często będzie lepszym wyborem.
Silna spójność oznacza, że po zatwierdzeniu transakcji kolejne odczyty zwrócą już zaktualizowaną wartość.
W praktyce chroni przed:
Kosztem jest to, że podczas partycji sieciowej system preferujący spójność może zablokować lub odrzucić pewne operacje zamiast dopuszczać różne prawdy w różnych regionach.
Opieraj się na ograniczeniach bazodanowych + transakcjach:
idempotency_key (lub podobny) dla każdego żądania/próby(account_id, idempotency_key)Dzięki temu powtórzenia stają się no-opami zamiast duplikatów—krytyczne dla płatności, provisioning i ponownego przetwarzania zadań w tle.
Praktyczne rozróżnienie:
Zanim wybierzesz, przetestuj swoje ORM/migracje i używane rozszerzenia Postgresa—nie zakładaj pełnej wymienialności.
Zacznij od skoncentrowanego PoC wokół jednego krytycznego przepływu (checkout, rezerwacja, zapisy księgowe). Zdefiniuj wcześniej metryki sukcesu:
W PoC warto postawić małą aplikację (API + UI), a nie tylko benchmarki syntetyczne—skraca to pętlę od "pomysłu" do "mierzalnego obciążenia". Koder.ai może pomóc szybko wystartować ze starterem React + Go i podmienić warstwę bazy, by przetestować wzorce transakcyjne i zachowanie przy awariach end-to-end.