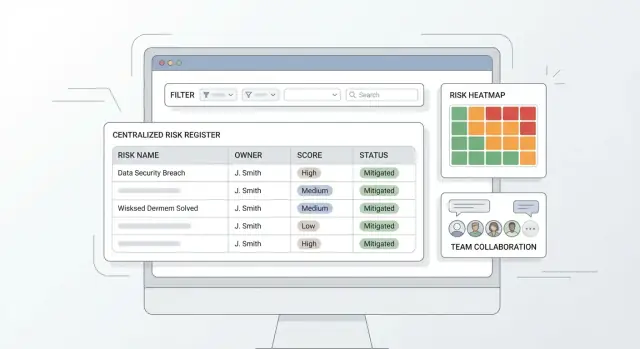
Co powinna rozwiązywać scentralizowana aplikacja rejestru ryzyk
Rejestr ryzyk zwykle zaczyna życie jako arkusz kalkulacyjny — i to działa, aż do momentu gdy wiele zespołów musi go aktualizować jednocześnie.
Dlaczego arkusze zawodzą
Arkusze mają problem z podstawami współdzielonej operacyjnej odpowiedzialności:
- Chaos wersji: „Final_v7_reallyfinal.xlsx” staje się normą i nikt nie wie, który plik jest aktualny.
- Niejasna odpowiedzialność: wiersz nie wymusza, kto ma przeglądać, zatwierdzać lub aktualizować ryzyko, więc odpowiedzialność rozmywa się.
- Ból raportowania: sumowanie ryzyk według działu, projektu czy kategorii często oznacza ręczne filtry, tabele przestawne i kopiuj‑wklej.
- Wymogi audytu: gdy kierownictwo lub audytorzy pytają „kto zmienił ocenę i dlaczego?”, arkusze rzadko dostarczają wiarygodnej historii zmian.
Scentralizowana aplikacja rozwiązuje te problemy, czyniąc aktualizacje widocznymi, możliwymi do prześledzenia i spójnymi — bez konieczności organizowania zebrań za każdym razem, gdy coś się zmienia.
Wyniki, do których warto dążyć
Dobra aplikacja rejestru ryzyk powinna dostarczyć:
- Jedno źródło prawdy: jeden rekord na ryzyko, z jasnym bieżącym statusem.
- Spójność: standardowe pola, wspólna taksonomia i jednolita metoda punktacji.
- Widoczność: wszyscy widzą ten sam obraz — odfiltrowany do ich zakresu.
- Rozliczalność: nazwani właściciele, terminy i wymagane przeglądy, które nie polegają na przypomnieniach w skrzynce e-mail.
Co właściwie oznacza „scentralizowany”?
„Scentralizowany” nie musi znaczyć „kontrolowany przez jedną osobę”. Oznacza:
- Jeden system (nie wiele plików)
- Wspólna taksonomia (wspólne kategorie, przyczyny, skutki, kontrolki)
- Standardowa punktacja (żeby „Wysokie” oznaczało to samo w różnych zespołach)
To odblokowuje raportowanie zbiorcze i porównywanie priorytetów między obszarami.
Ustal granicę: rejestr ryzyk vs pełne GRC
Scentralizowany rejestr ryzyk skupia się na przechwytywaniu, punktowaniu, śledzeniu i raportowaniu ryzyk od początku do końca.
Pełny pakiet GRC dodaje szersze funkcje jak zarządzanie politykami, mapowanie zgodności, programy oceny ryzyka dostawców, zbieranie dowodów i ciągły monitoring kontroli. Wczesne określenie tej granicy pomaga skupić pierwsze wydanie na przepływach pracy, których ludzie faktycznie będą używać.
Zdefiniuj użytkowników, role i governance
Zanim zaprojektujesz ekrany czy tabele w bazie danych, określ, kto będzie używać aplikacji i co operacyjnie oznacza „dobrze”. Większość projektów rejestru ryzyk nie zawodzi dlatego, że oprogramowanie nie potrafi przechować ryzyk, lecz dlatego, że nikt nie zgadza się, kto może co zmieniać — albo kto ponosi odpowiedzialność, gdy coś jest zaległe.
Kluczowe persony (utrzymaj niewielką liczbę)
Zacznij od kilku jasnych ról odpowiadających rzeczywistym zachowaniom:
- Właściciel ryzyka: odpowiada za ryzyko, aktualizuje status i prowadzi działania naprawcze.
- Recenzent/zatwierdzający: weryfikuje jakość (sformułowanie, punktację, kontrolki) i zatwierdza kluczowe zmiany.
- Administrator: zarządza szablonami, polami, użytkownikami i konfiguracją; rozwiązuje problemy z dostępem.
- Audytor: tylko do odczytu plus dostęp do dowodów; potrzebuje śledzalności i spójności.
- Wykonawczy widz: chce podsumowań i trendów, nie potrzebuje praw do edycji.
Jeśli dodasz za dużo ról na początku, stracisz czas na debatowanie szczególnych przypadków w MVP.
Uprawnienia ról (tworzenie, edycja, zatwierdzanie, zamykanie)
Zdefiniuj uprawnienia na poziomie akcji. Praktyczna baza:
- Tworzenie: właściciele ryzyk (czasem także admini).
- Edycja: właściciel, gdy ryzyko jest w Szkic; ograniczone zmiany po zatwierdzeniu.
- Zatwierdzanie: recenzent/zatwierdzający (nigdy ta sama osoba co właściciel przy wysokim ryzyku).
- Zamykanie: właściciel zgłasza prośbę o zamknięcie; recenzent potwierdza spełnienie kryteriów zamknięcia.
Zdecyduj też, kto może zmieniać pola wrażliwe (np. punktację, kategorię, datę docelową). Dla wielu zespołów te pola są tylko dla recenzentów, aby zapobiec „obniżaniu” ocen.
Zasady governance, które aplikacja może egzekwować
Zapisz zasady governance jako proste, testowalne reguły, które UI może wspierać:
- Pola obowiązkowe: minimalne informacje do działania (właściciel, wpływ, prawdopodobieństwo, dotknięty obszar, data docelowa).
- Kadencja przeglądu: np. kwartalny przegląd dla ryzyk średnich, miesięczny dla wysokich.
- Wyzwalacze eskalacji: zaległe działania, wysoka punktacja, powtarzające się incydenty lub nieskuteczne kontrolki.
Własność: ryzyka i kontrolki
Dokumentuj właścicielstwo oddzielnie dla każdego obiektu:
- Każde ryzyko ma dokładnie jednego odpowiedzialnego właściciela.
- Każda kontrolka (lub działanie łagodzące) ma właściciela i datę docelową.
Ta jasność zapobiega sytuacji „wszyscy są odpowiedzialni” i sprawia, że raportowanie ma sens.
Podstawowy model danych: pola ryzyka i relacje
Aplikacja rejestru ryzyk wygrywa lub przegrywa na modelu danych. Jeśli pola są zbyt skąpe, raportowanie jest słabe. Jeśli zbyt skomplikowane, ludzie przestają z tego korzystać. Zacznij od „minimum użytecznego” rekordu ryzyka, potem dodawaj kontekst i relacje, które czynią rejestr działającym.
Minimalne pola ryzyka (non-negotiables)
Minimum, które powinien przechowywać każdy rekord ryzyka:
- Tytuł: krótka, przeszukiwalna suma
- Opis: co może się stać i dlaczego to ma znaczenie
- Kategoria: np. operacyjne, zgodności, bezpieczeństwo, finansowe
- Właściciel: jedna odpowiedzialna osoba (nie grupa)
- Status: Szkic → Przegląd → Zatwierdzone → Monitorowane → Zamknięte
- Daty: data utworzenia, następny termin przeglądu, data docelowa, data zamknięcia (w razie potrzeby)
Te pola wspierają triage, odpowiedzialność i jasne „co się dzieje”.
Pola kontekstowe (co sprawia, że filtry i raporty są użyteczne)
Dodaj mały zestaw pól kontekstowych, które odpowiadają językowi twojej organizacji:
- Jednostka biznesowa (dział/pion)
- Proces/System (element narażony na ryzyko)
- Lokalizacja (siedziba/region)
- Projekt (inicjatywa/program)
- Dostawca (zaangażowany podmiot zewnętrzny)
Uczyń większość z nich opcjonalnymi, aby zespoły mogły zacząć rejestrować ryzyka bez blokad.
Powiązane obiekty (zamień ryzyka w pracę)
Modeluj te elementy jako oddzielne obiekty powiązane z ryzykiem, zamiast upychać wszystko w jednym długim formularzu:
- Kontrolki (co zmniejsza prawdopodobieństwo/ wpływ)
- Incydenty (zdarzenia, które się zmaterializowały lub bliskie przypadki)
- Działania/łagodzenia (zadania z przypisaniami i terminami)
- Dowody (potwierdzenie, że kontrolka lub działanie istnieje/zostało wykonane)
- Załączniki (pliki, zrzuty ekranu, dokumenty)
Taka struktura umożliwia czystą historię, lepsze ponowne użycie i jaśniejsze raportowanie.
Dołącz lekkie metadane wspierające stewardship:
- Tagi (elastyczne, definiowane przez użytkownika)
- Źródło (audyt, identyfikacja wewnętrzna, przegląd incydentu)
- Utworzone przez i ostatnia aktualizacja
- Data przeglądu (następne zaplanowane sprawdzenie)
Jeśli chcesz szablon do walidacji tych pól z interesariuszami, dodaj krótką „słownik danych” stronę w dokumentacji wewnętrznej (lub podaj odnośnik do strony pomocy takiej jak /blog/risk-register-field-guide).
Punktacja ryzyka i priorytetyzacja
Rejestr ryzyk staje się użyteczny, gdy ludzie szybko odpowiadają na dwa pytania: „Co powinniśmy załatwić najpierw?” i „Czy nasze działania działają?”. To zadanie punktacji ryzyka.
Uprość matematykę: prawdopodobieństwo × wpływ
Dla większości zespołów wystarcza prosty wzór:
Risk score = Likelihood × Impact
To łatwo wyjaśnić, łatwo audytować i łatwo wizualizować na mapie cieplnej.
Zdefiniuj jasne skale prostym językiem
Wybierz skalę pasującą do dojrzałości organizacji — zwykle 1–3 (prościej) lub 1–5 (więcej niuansów). Kluczowe jest zdefiniowanie, co każdy poziom oznacza, bez żargonu.
Przykład (1–5):
- Prawdopodobieństwo 1 (Rzadkie): Mało prawdopodobne w ciągu najbliższego roku
- Prawdopodobieństwo 3 (Możliwe): Może się zdarzyć kilka razy w roku
- Prawdopodobieństwo 5 (Prawie pewne): Oczekiwane częste występowanie
Zrób to samo dla Wpływu, używając przykładów rozpoznawalnych przez ludzi (np. „niewielka niedogodność dla klienta” vs „naruszenie regulacyjne”). Jeśli działasz między zespołami, pozwól na wskazówki dotyczące wpływu w podziale na kategorie (finansowy, prawny, operacyjny), ale wciąż generuj jedną ogólną liczbę.
Ryzyko wrodzone vs ryzyko pozostałe (i jak łagodzenia zmieniają wynik)
Wspieraj dwie oceny:
- Ryzyko wrodzone: przed kontrolkami/łagodzeniami
- Ryzyko pozostałe: po aktualnych kontrolkach/łagodzeniach
W aplikacji pokaż powiązanie: gdy działanie łagodzące jest oznaczone jako wdrożone (lub zaktualizowano jego skuteczność), poproś użytkowników o przegląd oceny pozostałego ryzyka. To utrzymuje punktację związaną z rzeczywistością, a nie jednorazową estymacją.
Zaplanuj wyjątki bez łamania systemu
Nie każde ryzyko pasuje do formuły. Projekt punktacji powinien obsługiwać:
- Ryzyka wyłącznie jakościowe: umożliwiaj opcję „Nie oceniano” z wymaganym uzasadnieniem
- Nieznany wpływ/prawdopodobieństwo: wspieraj „TBD” z przypomnieniem o ponownej ocenie do określonej daty
- Własne metryki: dla konkretnych zespołów pozwól na dodatkowe pole (np. „zaufanie klienta”) bez zmiany wspólnej punktacji
Priorytetyzacja może łączyć wynik z prostymi regułami jak „Wysoki wynik pozostały” lub „Zaległy przegląd”, żeby najbardziej pilne elementy były na górze listy.
Przepływ pracy od identyfikacji do zamknięcia
Scentralizowana aplikacja rejestru ryzyk jest użyteczna tylko wtedy, gdy wymuszony workflow ma sens. Celem jest, aby „kolejny poprawny krok” był oczywisty, jednocześnie pozwalając na wyjątki, gdy rzeczywistość jest nieporządna.
Zmapuj jasny lifecycle
Zacznij od małego zestawu statusów, które każdy zapamięta:
- Szkic: ryzyko zostało zarejestrowane, ale niezweryfikowane.
- Przegląd: właściciele merytoryczni potwierdzają opis, zakres i wstępną punktację.
- Zatwierdzone: ryzyko jest przyjęte do rejestru jako aktywny element.
- Monitorowane: kontrolki i działania są wdrożone; ryzyko jest monitorowane w czasie.
- Zamknięte: ryzyko nie jest już istotne, zostało zmitigowane lub związana aktywność została wycofana.
Trzymaj definicje statusów widoczne w UI (podpowiedzi lub panel boczny), żeby zespoły nietechniczne nie zgadywały.
Wymuszaj wymagane kroki na każdym etapie
Dodaj lekkie „bramki”, aby zatwierdzenia coś znaczyły. Przykłady:
- Przed przejściem Szkic → Przegląd wymagaj: tytułu, kategorii, właściciela, obszaru wpływu i wstępnego prawdopodobieństwa/ wpływu.
- Przed przejściem Przegląd → Zatwierdzone wymagaj: co najmniej jednej kontrolki (istniejącej lub planowanej) i jasnego uzasadnienia wybranej punktacji.
- Przed przejściem Zatwierdzone → Monitorowane wymagaj: co najmniej jednego działania/zadania z właścicielem i datą terminu.
- Przed przejściem Monitorowane → Zamknięte wymagaj: powodu zamknięcia i dowodu (upload pliku lub widoczny dowód).
Te kontrole zapobiegają pustym rekordom, nie zamieniając aplikacji w konkurs wypełniania formularzy.
Śledź działania jak mini‑plan projektu
Traktuj prace łagodzące jako dane pierwszej klasy:
- Zadania z właścicielem, terminem, statusem i notatkami o ukończeniu
- Dowody (dokumenty, zrzuty ekranu, linki do ticketów)
- Przypomnienia i eskalacje, gdy terminy są przekroczone
Ryzyko powinno pokazywać „co się robi” na pierwszy rzut oka, a nie być ukryte w komentarzach.
Wspieraj ponowną ocenę i ponowne otwarcie
Ryzyka się zmieniają. Zaimplementuj okresowe przeglądy (np. kwartalnie) i zapisuj każdą ponowną ocenę:
- data przeglądu, recenzent, zaktualizowane prawdopodobieństwo/ wpływ i notatki
- automatyczne przypomnienia, gdy zbliża się następny przegląd
- możliwość ponownego otwarcia zamkniętych ryzyk z obowiązkowym powodem i nowym cyklem przeglądu
To tworzy ciągłość: interesariusze widzą, jak zmieniała się punktacja i dlaczego podjęto decyzje.
UX i nawigacja dla zespołów nietechnicznych
Zachowaj kontrolę nad kodem
Gdy będziesz gotowy, wyeksportuj kod źródłowy, by przejąć pełną kontrolę nad aplikacją.
Aplikacja rejestru ryzyk wygrywa lub przegrywa na tym, jak szybko ktoś może dodać ryzyko, potem je znaleźć i zrozumieć, co dalej. Dla zespołów nietechnicznych dąż do „oczywistej” nawigacji, minimalnej liczby kliknięć i ekranów, które czytają się jak lista kontrolna — nie jak baza danych.
Kluczowe strony do zaprojektowania najpierw
Zacznij od małego zestawu przewidywalnych destynacji obejmujących codzienne przepływy:
- Lista ryzyk: baza do przeglądania, filtrowania i masowych aktualizacji.
- Szczegóły ryzyka: jedna czytelna strona odpowiadająca „co to jest, jak groźne, kto jest właścicielem, co się robi”.
- Biblioteka kontrolek: kontrolki/łagodzenia do ponownego użycia, by zespoły nie wymyślały tego samego tekstu.
- Śledzenie działań: lista zadań z właścicielami i terminami, oddzielona od narracji ryzyka.
- Dashboard: szybki przegląd z mapą cieplną, zaległymi działaniami i najważniejszymi zmianami.
Trzymaj nawigację spójną (pasek po lewej lub zakładki u góry) i spraw, by główna akcja była widoczna wszędzie (np. „Nowe ryzyko”).
Szybkie wprowadzanie danych: domyślne wartości, szablony i mniej pisania
Wprowadzanie danych powinno przypominać wypełnienie krótkiego formularza, nie pisanie raportu.
Używaj sensownych domyślnych wartości (np. status = Szkic dla nowych elementów; prawdopodobieństwo/ wpływ ustawione na środek) i szablonów dla częstych kategorii (ryzyko dostawcy, ryzyko projektu, ryzyko zgodności). Szablony mogą wstępnie uzupełniać pola takie jak kategoria, typowe kontrolki i sugerowane typy działań.
Pomóż też użytkownikom unikać powtarzalnego pisania:
- listy rozwijane dla kategorii, statusu, sposobu leczenia
- typeahead dla właściciela i powiązanych kontrolek
- „Zapisz i dodaj następne” dla szybkiego rejestrowania podczas warsztatów
Filtrowanie i wyszukiwanie, które działają wszędzie jednakowo
Zespół zaufa narzędziu, gdy będzie można niezawodnie odpowiedzieć na „pokaż mi wszystko, co mnie dotyczy”. Zbuduj jeden wzorzec filtrowania i używaj go na liście ryzyk, w śledzeniu działań i w drill‑downach pulpitu.
Priorytetowe filtry, o które ludzie naprawdę proszą: kategoria, właściciel, wynik, status i terminy. Dodaj proste wyszukiwanie słów kluczowych, które sprawdza tytuł, opis i tagi. Ułatw czyszczenie filtrów i zapisywanie widoków (np. „Moje ryzyka”, „Zaległe działania”).
Spraw, by widok szczegółów ryzyka był czytelny
Strona szczegółów powinna czytać się od góry do dołu bez szukania:
- Podsumowanie (tytuł, opis w prostym języku, kategoria, właściciel)
- Punktacja (biezące prawdopodobieństwo/ wpływ, wynik ogólny, trend)
- Kontrolki (powiązane kontrolki ze skutecznością)
- Działania (otwarte zadania z terminami i właścicielami)
- Historia (kluczowe zmiany dla śledzenia)
- Pliki (dowody, screenshoty, polityki)
Użyj czytelnych nagłówków sekcji, zwięzłych etykiet pól i wyróżnij to, co pilne (np. zaległe działania). To utrzymuje scentralizowane zarządzanie ryzykiem zrozumiałym nawet dla osób pierwszy raz korzystających z systemu.
Uprawnienia, ślad audytu i podstawy bezpieczeństwa
Rejestr ryzyk często zawiera wrażliwe informacje (ekspozycja finansowa, problemy z dostawcami, kwestie pracownicze). Jasne uprawnienia i wiarygodny ślad audytu chronią osoby, budują zaufanie i ułatwiają przeglądy.
Poziomy dostępu odpowiadające pracy zespołów
Zacznij od prostego modelu, potem rozszerzaj tylko jeśli potrzeba. Typowe zakresy widoczności:
- Ryzyka ogólnofirmowe: widoczne dla większości pracowników, edytowane przez właścicieli i adminów.
- Ryzyka jednostki biznesowej: widoczne w obrębie działu (np. Finanse, Operacje).
- Ryzyka projektowe: ograniczone do zespołu projektowego i interesariuszy.
- Ryzyka poufne: dostęp tylko dla małej grupy (np. Prawo, HR), z dodatkowymi ograniczeniami eksportu/udostępniania.
Łącz zakresy z rolami (Viewer, Contributor, Approver, Admin). Trzymaj „kto może zatwierdzać/zamykać ryzyko” oddzielnie od „kto może edytować pola”, aby rozliczalność była spójna.
Ślad audytu: kto zmienił co, kiedy i dlaczego
Każda istotna zmiana powinna być zapisywana automatycznie:
- Aktor (użytkownik/konto serwisowe)
- Znacznik czasu (z informacją o strefie czasowej)
- Różnica na poziomie pola (stare → nowe)
- Notatki zmian (wymagane przy zmianie statusu, punktacji i zamknięcia)
To wspiera wewnętrzne przeglądy i redukuje nieporozumienia podczas audytów. Uczyń historię czytelną w UI i możliwą do eksportu dla zespołów governance.
Podstawy bezpieczeństwa planowane od początku
Traktuj bezpieczeństwo jako funkcje produktowe, nie szczegóły infrastruktury:
- SSO (SAML/OIDC) dla większych organizacji; zachowaj lokalne logowanie dla małych zespołów.
- Zasady haseł (długość, ograniczenia ponownego użycia) i MFA tam, gdzie to możliwe.
- Szyfrowanie w tranzycie (TLS) i w spoczynku (baza/dysk).
- Limity sesji i wylogowanie dla udostępnionych maszyn.
Zasady retencji i usuwania (unikaj przypadkowej utraty)
Zdefiniuj, jak długo przechowywane są zamknięte ryzyka i dowody, kto może usuwać rekordy i co oznacza „usuń”. Wiele zespołów preferuje miękkie usuwanie (archiwizacja + możliwość odzyskania) i retencję czasową, z wyjątkami na potrzeby prawne.
Jeśli później dodasz eksporty lub integracje, upewnij się, że ryzyka poufne są chronione tymi samymi regułami.
Współpraca i powiadomienia
Uprość UX i czytelność
Twórz listy, strony szczegółów, pulpity i filtry, z których zespoły nietechniczne faktycznie będą korzystać.
Rejestr ryzyk pozostaje aktualny tylko wtedy, gdy właściwi ludzie mogą szybko omawiać zmiany — i gdy aplikacja delikatnie je do tego namawia we właściwych momentach. Funkcje współpracy powinny być lekkie, strukturalne i związane z rekordem ryzyka, aby decyzje nie znikały w wątkach e‑mail.
Współpraca powiązana z ryzykiem
Zacznij od wątku komentarzy przy każdym ryzyku. Trzymaj go prostym, ale użytecznym:
- @wzmianki aby przyciągnąć właścicieli, liderów kontrolek, Finanse, Prawo lub kogokolwiek potrzebnego do weryfikacji zmiany.
- Prośby o przegląd jako działania pierwszej klasy (np. „Poproś o przegląd Security” lub „Poproś o zatwierdzenie Komitet Ryzyka”). To czytelniejsze niż „proszę zerknąć” w komentarzu.
- Kontekst inline: pokaż, co się zmieniło (wynik, termin, status działania) obok dyskusji, aby recenzenci nie musieli ręcznie porównywać wersji.
Jeśli ślad audytu jest planowany gdzie indziej, nie duplikuj go tutaj — komentarze są do współpracy, nie do compliance.
Powiadomienia dopasowane do pracy nad ryzykiem
Powiadomienia powinny uruchamiać się przy zdarzeniach wpływających na priorytety i odpowiedzialność:
- Terminy działań łagodzących (nadchodzące, na dziś i zaległe).
- Zmiany punktacji (zaktualizowane prawdopodobieństwo/ wpływ, przeliczenie ryzyka), bo to często determinuje eskalację.
- Zatwierdzenia (poproszono, zatwierdzono, odrzucono), aby workflow się nie zatrzymywał.
- Zaległe działania z jasnym wezwaniem do działania (otwórz zadanie, przypisz ponownie, przedłuż termin z uzasadnieniem).
Dostarczaj powiadomienia tam, gdzie ludzie pracują: skrzynka w aplikacji + e‑mail i opcjonalnie Slack/Teams przez integracje później.
Okresowe przypomnienia przeglądów bez natarczywości
Wiele ryzyk wymaga okresowych przeglądów nawet, gdy nic „nie pali”. Wspieraj cykliczne przypomnienia (miesięczne/kwartalne) na poziomie kategorii ryzyka (np. Dostawcy, InfoSec, Operacje), aby zespoły wyrównały się z kadencjami governance.
Ogranicz hałas za pomocą kontroli użytkownika
Nadmiar powiadomień zabija adopcję. Pozwól użytkownikom wybrać:
- Digest vs w czasie rzeczywistym (codzienny/tygodniowy skrót)
- Jakie zdarzenia ich interesują (zmiany punktacji, wzmianki, zatwierdzenia)
- Ciche godziny i strefę czasową
Dobre domyślne ustawienia mają znaczenie: powiadamiaj domyślnie właściciela ryzyka i właściciela działania; reszta opcji na życzenie.
Dashboardy, raporty i eksporty
To na dashboardach aplikacja udowadnia wartość: zamienia długą listę ryzyk w krótką listę decyzji. Celuj w kilka „zawsze użytecznych” kafelków, potem pozwól zagłębiać się w rekordy.
Podstawowe dashboardy do wdrożenia wcześnie
Zacznij od czterech widoków odpowiadających typowym pytaniom:
- Najważniejsze ryzyka: elementy o najwyższym priorytecie (wg punktacji), z aktualnym statusem i datą następnego przeglądu.
- Ryzyka według właściciela: prosty podział pokazujący, kto za co odpowiada.
- Zaległe działania: zadania łagodzące po terminie, pogrupowane według zespołu lub właściciela.
- Trend w czasie: liczba otwartych ryzyk i średni wynik w miesiącu/kwartale, aby pokazać, czy ekspozycja się poprawia.
Mapa cieplna (i jak ją obliczyć)
Mapa cieplna to siatka Prawdopodobieństwo × Wpływ. Każde ryzyko trafia do komórki na podstawie bieżących ocen (np. 1–5). Aby obliczyć to, co wyświetlasz:
- Umieszczanie w komórce:
wiersz = wpływ, kolumna = prawdopodobieństwo.
- Wynik ryzyka:
wynik = prawdopodobieństwo * wpływ.
- Intensywność komórki: pasma kolorów według progów (np. 1–6 zielone, 7–14 bursztynowe, 15–25 czerwone).
- Liczby i drill‑down: pokazuj ile ryzyk jest w każdej komórce; kliknięcie filtruje rejestr do tej podgrupy.
Jeśli wspierasz ryzyko pozostałe i wrodzone, pozwól użytkownikom przełączać Wrodzone vs Pozostałe, by nie mieszać ekspozycji przed i po kontrolkach.
Raporty, pakiety zarządcze i eksporty przyjazne audytowi
Kierownictwo często potrzebuje snapshotu, audytorzy dowodów. Zapewnij eksport jednym kliknięciem do CSV/XLSX/PDF, który zawiera zastosowane filtry, datę/godzinę wygenerowania oraz kluczowe pola (wynik, właściciel, kontrolki, działania, ostatnia aktualizacja).
Zapisane widoki dla typowych odbiorców
Dodaj „zapisane widoki” z ustawionymi filtrami i kolumnami, takie jak Podsumowanie wykonawcze, Właściciele ryzyk i Szczegóły audytu. Uczyń je udostępnialnymi przez link względny (np. /risks?view=executive), aby zespoły mogły wracać do tego samego, uzgodnionego obrazu.
Import danych i integracje
Większość rejestrów ryzyk nie zaczyna pustych — zaczyna się od „kilku arkuszy” i kawałków informacji rozsianych po narzędziach biznesowych. Traktuj import i integracje jako priorytet, bo to decyduje, czy twoja aplikacja stanie się jedynym źródłem prawdy.
Typowe źródła danych do planowania
Zwykle importujesz lub odwołujesz się do danych z:
- istniejących arkuszy kalkulacyjnych (logi ryzyk, ustalenia audytu, rejestry RAID projektów)
- narzędzi ticketowych (np. Jira/ServiceNow) dla incydentów, problemów lub zadań usuwających kontrolki
- CMDB/inwentarza zasobów dla systemów, aplikacji, właścicieli, krytyczności
- HR lub katalogu organizacyjnego dla działów, menedżerów, przypisań ról
- list dostawców dla ryzyk zewnętrznych i właścicieli kontraktów
Praktyczny proces importu (dla zespołów nietechnicznych)
Dobry kreator importu ma trzy etapy:
- Mapowanie kolumn: załaduj CSV/XLSX, potem zmapuj kolumny do pól (Tytuł ryzyka → Title, „Owner email” → Owner). Zapisz mapowania jako szablony do powtarzalnych importów.
- Walidacja: pokaż problemy na poziomie wierszy przed zapisaniem — brak wymaganych pól, błędne wartości enum (np. „Highh”), złe daty, nieznani właściciele.
- Raport błędów: zaimportuj poprawne wiersze i wygeneruj plik z błędami do pobrania z jasnymi komunikatami i oryginalnym wierszem.
Zachowaj krok podglądu, pokazujący jak pierwsze 10–20 rekordów wygląda po imporcie. Zapobiega to niespodziankom i buduje zaufanie.
Integracje: zacznij prosto, potem skaluj
Celuj w trzy tryby integracji:
- API do zapytań i zapisów na żądanie (np. utwórz ryzyko z incydentu).
- Webhooks do powiadamiania innych systemów o zmianach statusu lub priorytetu.
- Synchronizację harmonogramową dla danych referencyjnych (zasoby, użytkownicy, dostawcy), aby listy rozwijane były aktualne.
Jeśli dokumentujesz to dla administratorów, odwołaj się do zwięzłej strony konfiguracji integracji w dokumentacji, np. /docs/integrations.
Zapobieganie duplikatom (bez blokowania postępu)
Używaj kilku warstw:
- Unikalne ID: wewnętrzne ID ryzyka plus opcjonalne zewnętrzne ID (klucz ticketu, ID dostawcy).
- Reguły dopasowania: flaguj potencjalne duplikaty przez znormalizowany tytuł + zasób/dostawcę + podobne daty.
- Proces scalania: pozwól administratorowi scalić dwa ryzyka, zachowując historię i przenosząc powiązania do kontrolek/zadań.
Stos technologiczny i opcje architektury
Szybciej migracja z arkuszy
Wczytaj istniejące CSV lub XLSX i zwaliduj pola, aby zacząć z czystym rejestrem.
Masz trzy praktyczne podejścia do budowy aplikacji rejestru ryzyk; „właściwe” zależy od tego, jak szybko potrzebujesz wartości i ile zmian spodziewasz się w przyszłości.
To dobre krótkoterminowe rozwiązanie, jeśli potrzebujesz jednego miejsca do logowania ryzyk i podstawowych eksportów. Jest tanie i szybkie, ale psuje się, gdy potrzebujesz granularnych uprawnień, śladu audytu i niezawodnych workflowów.
Low‑code jest idealne, gdy chcesz MVP w tygodniach i zespół ma już licencje na platformę. Możesz modelować ryzyka, tworzyć proste zatwierdzenia i budować dashboardy szybko. Kosztem jest elastyczność długoterminowa: złożona logika punktacji, niestandardowe mapy cieplne i głębokie integracje mogą stać się niewygodne lub kosztowne.
Opcja 3: Własne development
Budowy od zera trwają dłużej, ale pasują do twojego modelu governance i mogą rosnąć w pełną aplikację GRC. To zwykle najlepsza droga, gdy potrzebujesz rygorystycznych uprawnień, szczegółowego śladu audytu lub wielu jednostek biznesowych z różnymi workflowami.
Prosta, niezawodna architektura
Trzymaj to nudne i czytelne:
- Frontend: UI webowe do logowania, przeglądu i zatwierdzania ryzyk.
- API: obsługuje reguły biznesowe (punktacja, stany workflow, powiadomienia).
- Baza danych: przechowuje ryzyka, kontrolki, właścicieli i historię.
- Magazyn plików: dowody i załączniki (polityki, zrzuty ekranu, raporty).
- Serwis e‑mail: przypisania, przypomnienia i eskalacje.
Sensowny stos startowy (uzasadnienie w prostym języku)
Powszechny, utrzymywalny wybór to React (frontend) + dobrze zorganizowana warstwa API + PostgreSQL (baza danych). Jest popularny, łatwo znaleźć developerów i dobry do aplikacji z intensywnymi danymi jak rejestr ryzyk. Jeśli organizacja jest już zunifikowana na Microsoft, .NET + SQL Server też jest praktyczne.
Jeśli chcesz szybciej prototypować — bez wiązania się z platformą low‑code — zespoły często używają Koder.ai jako „vibe‑coding” drogi do MVP. Opisujesz przepływ ryzyka, role, pola i punktację w czacie, iterujesz ekrany szybko i nadal możesz wyeksportować kod źródłowy, gdy chcesz przejąć pełne utrzymanie. Pod spodem Koder.ai dobrze pasuje do tego typu aplikacji: React na froncie i backend w Go + PostgreSQL, z wdrożeniem/hostingiem oraz snapshotami/rollbackem dla bezpieczniejszej iteracji.
Środowiska i podstawy wdrożenia
Planuj dev / staging / prod od początku. Staging powinien odzwierciedlać produkcję, aby testować uprawnienia i automatyzacje workflow bez ryzyka. Skonfiguruj automatyczne wdrożenia, codzienne kopie zapasowe (z testami przywracania) i lekkie monitorowanie (dostępność + alerty błędów). Jeśli potrzebujesz checklisty gotowości do wydania, odwołaj się do wewnętrznej strony jak /blog/mvp-testing-rollout.
MVP, testy i plan wdrożenia
Wypuszczenie scentralizowanego rejestru ryzyk to mniej budowa wszystkich funkcji, a bardziej udowodnienie, że workflow działa dla prawdziwych ludzi. Wąskie MVP, realistyczny plan testów i etapowy rollout wyprowadzą cię z chaosu arkuszy bez tworzenia nowych problemów.
Zdefiniuj zakres MVP (co zbudować najpierw)
Zacznij od najmniejszego zestawu funkcji, który pozwoli zespołowi logować ryzyka, oceniać je spójnie, przeprowadzać przez prosty lifecycle i widzieć podstawowy przegląd.
Elementy MVP:
- Minimalne pola ryzyka: tytuł, opis, właściciel, dział/zespół, kategoria, status, daty (utworzenia/następnego przeglądu), kontrolki, działania i notatki o ryzyku pozostałym.
- Punktacja: jedna metoda (np. prawdopodobieństwo 1–5 i wpływ 1–5) z automatycznym wynikiem i prostą klasyfikacją mapy cieplnej (niska/średnia/wysoka).
- Podstawowy workflow: Szkic → Przegląd → Zatwierdzone → Monitorowane → Zamknięte (zachowaj możliwość konfiguracji później, ale najpierw zaimplementuj jedną czytelną ścieżkę).
- Jeden dashboard: „Otwarte wysokie ryzyka pozostałe według zespołu” plus lista z filtrami.
Zostaw funkcje typu zaawansowana analityka, niestandardowe budownicze workflowów czy głębokie integracje na później — po potwierdzeniu, że fundamenty pasują do rzeczywistej pracy zespołów.
Stwórz praktyczny plan testów
Twoje testy powinny koncentrować się na poprawności i zaufaniu: ludzie muszą wierzyć, że rejestr jest dokładny, a dostęp kontrolowany.
Pokryj te obszary:
- Dostęp oparty na rolach: sprawdź, kto może przeglądać, tworzyć, edytować, zatwierdzać i zamykać ryzyka w różnych zespołach.
- Reguły workflow: upewnij się, że pola wymagane są egzekwowane przy kluczowych przejściach (np. właściciel i termin wymagane przed „Zatwierdzone”).
- Importy/eksporty: przetestuj import z nieuporządkowanego szablonu arkusza i eksport do CSV/XLSX z oczekiwanymi kolumnami.
- Auditowalność: potwierdź, że zmiany (wynik, status, właściciel) są zapisywane i widoczne dla uprawnionych użytkowników.
Przeprowadź pilotaż, potem dopracuj
Pilotaż zrób z jednym zespołem (najlepiej zmotywowanym, ale nie power‑userami). Trzymaj pilotaż krótki (2–4 tygodnie) i mierz:
- czas potrzebny na zarejestrowanie ryzyka
- liczbę niekompletnych zgłoszeń
- jak często punktacja jest kwestionowana
- które pola są ignorowane lub źle rozumiane
Użyj informacji zwrotnych do dopracowania szablonów (kategorie, pola wymagane) i dostosowania skal (np. co oznacza „Wpływ = 4”) przed szerszym wdrożeniem.
Szkolenie, dokumentacja i harmonogram migracji
Zaprojektuj lekkie wsparcie doceniając zajętość zespołów:
- Jednostronicowy „Jak punktujemy ryzyka” i dwuminutowe wideo przewodnik
- Krótkie podpowiedzi w aplikacji (co jest wymagane, jak działają zatwierdzenia)
- Jasny harmonogram migracji: zablokuj edycje arkuszy, zaimportuj dane bazowe, zweryfikuj właścicieli, potem przełącz na aplikację
Jeśli masz standardowy format arkusza, opublikuj go jako oficjalny szablon importu i odwołaj się do niego na wewnętrznej stronie pomocy, np. /help/importing-risks.