Definicja problemu i kryteria sukcesu
Śledzenie własności funkcji rozwiązuje konkretny rodzaj niejasności: kiedy coś się zmienia, psuje albo wymaga decyzji, nikt nie jest pewien, kto jest odpowiedzialny — a „właściwa” osoba zależy od kontekstu.
Co oznacza „własność funkcji” (wyjaśnij jasno)
Zdefiniuj własność jako zestaw obowiązków, nie tylko nazwisko w polu. W wielu organizacjach jedna funkcja ma wielu właścicieli:
- Własność produktu: priorytetyzacja, wpływ na klienta, decyzje o roadmapie.
- Własność inżynieryjna: jakość implementacji, niezawodność, obowiązki on-call, decyzje techniczne.
- Wsparcie/Operacje: ścieżka eskalacji, znane problemy, playbooki wsparcia.
Zdecyduj, czy aplikacja wspiera jednego głównego właściciela plus role drugorzędne, czy model oparty na rolach (np. Product Owner, Tech Owner, Support Lead). Jeśli używacie terminologii RACI, wyjaśnij, jak się to mapuje (Responsible/Accountable/Consulted/Informed).
Główni użytkownicy i ich zadania
Wymień grupy, które będą korzystać z systemu na co dzień:
- PM-y: znaleźć decydenta, potwierdzić wpływ na roadmapę, skoordynować przekazania.
- Kierownicy inżynierii i tech leady: zapewnić pokrycie, zarządzać przejściami, zatwierdzać zmiany.
- Liderzy wsparcia: wiedzieć, kogo wezwać, co można przekazać klientom i gdzie są dokumenty.
Zwróć też uwagę na okazjonalnych użytkowników (kadra zarządzająca, QA, bezpieczeństwo). Ich pytania wpłyną na raportowanie, workflowy i uprawnienia.
Najważniejsze pytania, na które aplikacja musi odpowiadać
Sformułuj je jako testy akceptacyjne. Typowe pytania, które muszą mieć odpowiedź:
- Kto jest teraz właścicielem tej funkcji i w jakiej roli?
- Kto zatwierdza zmiany właścicielstwa?
- Do kogo kontaktować się w sprawie awarii, błędu lub pytania o roadmapę?
- Co zmieniło się ostatnio i dlaczego? (log audytu)
Decyzje zakresu, które zapobiegają przeróbkom
Bądź jasny co do jednostki, którą śledzisz:
- Tylko funkcje, czy także komponenty, usługi, API, dokumenty i runbooki.
Jeśli uwzględniasz różne typy zasobów, zdefiniuj relacje (funkcja zależy od usługi; runbook wspiera funkcję), żeby własność nie rozmywała się.
Kryteria sukcesu
Wybierz mierzalne wyniki, np.:
- Zmniejszenie liczby pytań „kto jest właścicielem?” na chacie o X%.
- Własność przypisana dla 95%+ aktywnych funkcji.
- Mediana czasu znalezienia właściwego kontaktu spada poniżej 2 minut.
- Wszystkie zmiany własności mają zatwierdzającego i pojawiają się w historii w ciągu 24 godzin.
Wymagania i zakres MVP
Tracker własności funkcji działa tylko wtedy, gdy odpowiada szybko i wiarygodnie na kilka pytań. Pisz wymagania jako codzienne akcje — co ktoś musi zrobić w 30 sekund, pod presją, podczas wydania lub incydentu.
Core use cases (łatwe w użyciu)
MVP powinno obsługiwać kilka przepływów end-to-end:
- Znaleźć właściciela: wyszukaj po nazwie funkcji, obszarze produktu albo tagu i zobacz aktualny zespół/osobę odpowiedzialną oraz zapas.
- Zaktualizować właściciela: zmień właściciela z jasnym powodem i datą wejścia w życie.
- Zgłosić zmianę: zaproponuj nowego właściciela, jeśli nie masz bezpośrednich uprawnień.
- Ścieżka eskalacji: jeśli wskazany właściciel jest nieprawidłowy lub nieodpowiada, pokaż następny kontakt (menedżer, alias on-call lub lider platformy).
Jeśli aplikacja nie potrafi tych czterech działać niezawodnie, dodatkowe funkcje tego nie uratują.
Nie-do-celu (utrzymaj v1 w ryzach)
Aby uniknąć przekształcenia w kolejne narzędzie planistyczne, wyraźnie wyklucz:
- Pełne zarządzanie projektami (zadania, sprinty, roadmapy)
- Szczegółowe zarządzanie incydentami
- Zastępowanie systemów źródłowych prawdy (HRIS, IAM, org chart)
- Głęboką automatyzację przepływów poza prostymi zatwierdzeniami
Oczekiwania dotyczące świeżości danych
Zdecyduj, co oznacza „dokładne”:
- Manual-first: właściciele utrzymują wpisy ręcznie. Proste, ale wymaga przypomnień i odpowiedzialności.
- Synchronizowane: pobieraj zespoły/osoby z katalogu i opcjonalnie listy funkcji z repo lub narzędzia backlogowego.
Dla MVP częste kompromisy to: synchronizacja ludzi/zespołów nocą, własność aktualizowana manualnie, z widoczną datą „ostatnio potwierdzono”.
MVP kontra późniejsze rozszerzenia
Określ, co wypuszczasz teraz, a co później, by zapobiec rozrastaniu zakresu.
MVP: wyszukiwanie, strona funkcji, pola właściciela, wniosek o zmianę + zatwierdzenie, podstawowa historia audytu i eksporty.
Później: zaawansowane pulpity raportowe, widoki RACI w przekroju inicjatyw, workflowy Slack/Teams, automatyczne wykrywanie przestarzałych danych i rekonsyliacja z wielu źródeł.
Celem v1 jest wiarygodny katalog odpowiedzialności — nie perfekcyjne odwzorowanie wszystkich używanych systemów.
Jeśli chcesz szybko to zwalidować przed pełnym wdrożeniem, platforma typu vibe-coding jak Koder.ai może pomóc w prototypowaniu kluczowych przepływów (wyszukiwanie → strona funkcji → wniosek o zmianę → zatwierdzenie) przez chat, a następnie iterować ze stakeholderami korzystając ze snapshotów i rollbacku.
Katalog funkcji i taksonomia
Tracker działa tylko wtedy, gdy wszyscy zgadzają się, co to znaczy „funkcja”. Zacznij od wyboru spójnej definicji i umieść ją widocznie w UI.
Zdefiniuj, co się liczy jako „funkcja”
Wybierz jedną z opcji i trzymaj się jej:
- Funkcja produktu: funkcjonalność widoczna dla użytkownika („Eksport do CSV”).
- Możliwość (capability): szersza obietnica produktu („Eksport danych”).
- Moduł/komponent: wydzielona część systemu („Serwis raportów”).
Zespół może dyskutować, ale katalog powinien reprezentować jeden poziom. Praktyczny wybór to funkcje widoczne dla użytkownika, bo dobrze mapują do ticketów, notatek wydawniczych i eskalacji wsparcia.
Identyfikatory i konwencje nazewnictwa
Nazwy się zmieniają; identyfikatory nie powinny. Nadaj każdej funkcji stabilny klucz i czytelny slug.
- Klucz funkcji: niezmienny, krótki, unikalny (np.
FEAT-1427 lub REP-EXPORT).
- Slug: generowany z nazwy, ale edytowalny, by uniknąć łamania linków (
export-to-csv).
Zdefiniuj zasady nazewnictwa wcześnie (wielkość liter, brak wewnętrznych skrótów, prefiks obszaru produktu itp.). To zapobiega sytuacjom typu „CSV Export”, „Export CSV” i „Data Export” jako trzech rekordów.
Taksonomia wspierająca wyszukiwanie i raportowanie
Dobra taksonomia to wystarczająco dużo struktury, by filtrować i grupować własność. Typowe pola:
- Obszar produktu (Billing, Reporting, Admin)
- Zespół (aktualny zespół odpowiedzialny)
- Platforma (Web, Mobile, API)
- Segment klienta (SMB, Enterprise, Internal)
- Status cyklu życia (Proposed, Active, Deprecated, Retired)
Utrzymuj wartości skurczone (lista wyboru), aby raporty były czytelne.
Typy właścicieli: wyjaśnij odpowiedzialności
Własność rzadko oznacza jedną osobę. Zdefiniuj role właściciela wyraźnie:
- Główny właściciel: odpowiedzialny za decyzje i roadmapę.
- Właściciel zapasowy: backup dla ciągłości.
- Zatwierdzający: wymagana akceptacja zmian (często manager lub architekt).
- Kontakt on-call: najszybsza ścieżka eskalacji podczas incydentów.
Jeśli używasz modelu RACI, odwzoruj go bezpośrednio, żeby nie trzeba było tłumaczyć pojęć.
Model danych: funkcje, zespoły, osoby i historia
Jasny model danych sprawia, że własność jest wyszukiwalna, raportowalna i godna zaufania w czasie. Celem nie jest odwzorowanie każdej niuansu organizacyjnego — chodzi o uchwycenie „kto co posiada, od kiedy, do kiedy i co się zmieniło”.
Główne encje (rzeczowniki)
Zacznij od małego zestawu pierwszorzędnych encji:
- Feature: rzecz będąca w posiadaniu (np. „Ustawienia rozliczeń”, „Filtry wyszukiwania”). Przechowuj nazwę, opis, status i stabilne ID.
- Team: zespół odpowiedzialny (np. „Payments Squad”).
- Person: osoba, która może być właścicielem, zatwierdzającym lub edytorem.
- OwnershipAssignment: relacja odpowiadająca na pytanie „kto teraz jest właścicielem tej funkcji?”
- Tag: lekkie klasyfikacje, np. obszar produktu, platforma, segment klienta, poziom ryzyka.
- System: zewnętrzne narzędzia do synchronizacji (HRIS, Okta, Jira, GitHub itp.).
Własność jako rekord z ograniczeniem czasowym
Modeluj własność jako rekordy z datami, a nie jako pojedyncze mutowalne pole Feature. Każde OwnershipAssignment powinno zawierać:
feature_idowner_type + owner_id (Team lub Person)role (np. DRI, backup, właściciel techniczny)start_date i opcjonalne end_datehandover_notes (co nowy właściciel powinien wiedzieć)
Taka struktura wspiera czyste przekazania: zakończenie jednego przypisania i rozpoczęcie drugiego zachowuje historię i zapobiega cichym zmianom właściciela.
Historia, której można ufać: log audytu
Dodaj AuditLog (lub ChangeLog), który rejestruje każde ważne zapisywanie:
- kto wykonał zmianę (Person)
- co się zmieniło (encja + ID rekordu)
- kiedy to się stało (timestamp)
- dlaczego to się zmieniło (powód, tekst dowolny)
Trzymaj log audytu jako append-only. To kluczowe dla odpowiedzialności, przeglądów i odpowiadania na pytanie „kiedy własność się zmieniła?”.
Importy i synchronizacja: planuj zewnętrzne ID
Jeśli będziesz importować zespoły lub użytkowników, przechowuj stabilne pola mapowania:
external_system (System)external_id (string)
Zrób to przynajmniej dla Team i Person, opcjonalnie też dla Feature jeśli odzwierciedla epiki Jira lub katalog produktu. Zewnętrzne ID pozwalają synchronizować bez duplikatów, gdy nazwy się zmieniają.
Uwierzytelnianie, role i uprawnienia
Szybko prototypuj MVP
Przekształć specyfikację trackera własności w działającą aplikację, rozmawiając z Koder.ai.
Dobre ustawienie kontroli dostępu to to, co utrzymuje tracker jako źródło zaufania. Jeśli każdy może zmieniać właściciela, nikt mu nie zaufa. Jeśli wszystko jest zbyt zablokowane, zespoły wrócą do arkuszy.
Wybierz methodę logowania zgodną z firmą
Zacznij od metody logowania używanej w organizacji:
- SSO (SAML): najlepsze dla średnich i dużych firm z IdP (Okta, Azure AD). Centralne onboard/offboard i mniej problemów z hasłami.
- OAuth/OIDC: dobre jeśli integrujesz Google Workspace lub Microsoft Entra ID bez pełnego SAML. Zazwyczaj prostsze w implementacji.
- Email/hasło (fallback): rozważaj tylko dla bardzo małych orgów lub zewnętrznych współpracowników. Jeśli go używasz, wymuszaj MFA i silne hasła.
Praktyczna zasada: jeśli HR może wyłączyć konto w jednym miejscu, twoja aplikacja powinna to respektować.
Zdefiniuj proste role (i trzymaj je nudnymi)
Użyj małego zestawu ról, które odzwierciedlają rzeczywistą pracę:
- Viewer: może wyszukiwać, filtrować i eksportować widoki, ale nie edytuje.
- Editor: może proponować aktualizacje własności w obszarach, za które jest odpowiedzialny.
- Approver: może zatwierdzać/odrzucać zmiany (często product lead, manager lub właściciel platformy).
- Admin: zarządza ustawieniami systemu, integracjami i przypisaniami ról.
Zasady uprawnień: ważniejszy jest zakres niż nazwa roli
Sama rola to za mało — potrzebujesz zakresu. Typowe opcje:
- Po obszarze produktu (np. „Checkout”, „Billing”)
- Po zespole (np. „Payments Squad”)
- Po grupie funkcji / węźle taksonomii (użyteczne przy hierarchii)
Np.: Editor może edytować własność tylko dla funkcji w „Billing”, podczas gdy Approver zatwierdza zmiany w całym „Finance Products”.
Zbuduj ścieżkę „zgłoś dostęp” na granicy uprawnień
Kiedy użytkownik próbuje edytować coś, do czego nie ma uprawnień, nie pokazuj tylko błędu. Zapewnij akcję Zgłoś dostęp, która:
- wypełnia automatycznie żądany zakres (zespół/obszar produktu)
- kieruje do właściwego zatwierdzającego/admina
- zbiera krótki powód
Nawet jeśli zaczynasz od prostego workflow opartego na mailu, jasno zdefiniowana ścieżka zapobiega shadow dokumentom i centralizuje dane własności.
Tracker własności działa, gdy ludzie mogą w kilka sekund odpowiedzieć na: „Kto to posiada?” i „Co mam zrobić dalej?” Architektura informacji powinna koncentrować się na kilku stronach z przewidywalną nawigacją i silnym wyszukiwaniem.
Kluczowe ekrany (i do czego służą)
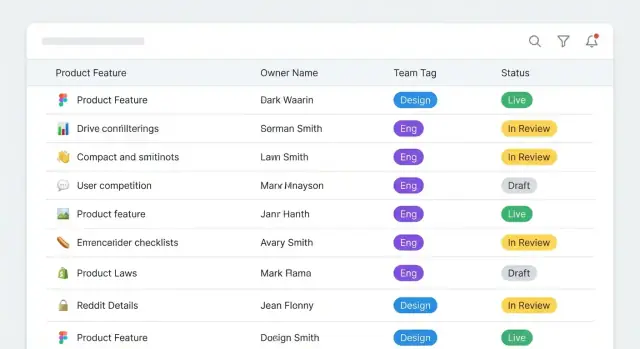
Lista funkcji to domyślna strona startowa. Większość użytkowników zaczyna tutaj, więc optymalizuj ją pod szybkie skanowanie i zawężanie wyników. Pokaż kompaktowy wiersz z: nazwą funkcji, obszarem produktu, aktualnym właścicielem (zespół + osoba główna), statusem i „ostatnio zaktualizowano”.
Szczegóły funkcji to źródło prawdy. Wyraźnie oddziel własność od opisu, aby aktualizacje nie wydawały się ryzykowne. Umieść panel własności na górze z prostymi etykietami jak Accountable, Primary contact, Backup contact i Escalation path.
Strona zespołu odpowiada na „Co posiada ten zespół?”. Dodaj kanały zespołu (Slack/email), info on-call (jeśli istotne) i listę posiadanych funkcji.
Strona osoby odpowiada na „Za co ta osoba odpowiada?”. Pokaż aktywne przypisania własności i jak się z nią skontaktować.
Wyszukiwanie, filtry i czytelność
Uczyń wyszukiwanie zawsze dostępnym (najlepiej pasek w nagłówku) i wystarczająco szybkie, by wydawało się natychmiastowe. Połącz je z filtrami odpowiadającymi sposobowi myślenia ludzi:
- Obszar produktu
- Zespół
- Status
- Tagi
Na listach i stronach szczegółów spraw, by informacje o własności były łatwe do przeskanowania: spójne znaczniki, wyraźne sposoby kontaktu i akcje „Skopiuj wiadomość eskalacyjną” lub „Wyślij e-mail do właściciela” jednym kliknięciem.
Niskoprołakcyjne edycje bez chaosu
Użyj jednego, spójnego przepływu edycji na wszystkich stronach:
- Kliknij Edytuj własność (lub Edytuj w sekcji).
- Formularz z walidacją (wymagane pola, poprawny zespół/osoba, brak konfliktów właścicielskich).
- Podgląd zmian pokazujący „przed → po”, w tym kto zostanie powiadomiony.
- Zapisz, z jasnym potwierdzeniem i linkiem do zaktualizowanego rekordu.
To utrzymuje edycje bezpieczne, redukuje iteracje i zachęca do aktualizowania danych.
Workflowy: aktualizacje, zatwierdzenia i przekazanie
Dane własności będą aktualne tylko wtedy, gdy ich zmiana będzie prostsza niż obchodzenie systemu. Traktuj aktualizacje jako małe, śledzone żądania — żeby można było szybko proponować zmiany, a liderzy ufali danym.
Aktualizacje jako żądania zmian
Zamiast bezpośredniej edycji pól właściciela, większość zmian przepuszczaj przez formularz wniosku o zmianę. Każdy wniosek powinien zawierać:
- Co się zmienia (funkcja, aktualny właściciel, proponowany właściciel)
- Powód (tekst + opcjonalna kategoria, np. „reorg”, „granica serwisu”, „wynik incydentu”)
- Data wejścia w życie (natychmiast vs zaplanowana)
Daty zaplanowane są przydatne przy reorganizacjach: nowy właściciel pojawia się automatycznie w ustalonym dniu, a historia zachowuje poprzednie przypisanie.
Zatwierdzenia dla wrażliwych zmian
Nie każda zmiana wymaga spotkania. Dodaj lekkie zatwierdzenia tylko tam, gdzie ryzyko jest wyższe, np.:
- Zmiana głównego właściciela
- Aktualizacje krytycznych funkcji (oznaczonych jako “tier 0/1”)
- Usunięcie właściciela (potencjalne pozostawienie „braku właściciela”)
Prosty silnik reguł może zadecydować: auto-zatwierdzaj niskie ryzyko, ale wymagaj 1–2 zatwierdzeń dla wrażliwych elementów (np. obecny właściciel + lider zespołu przyjmującego). Ekrany zatwierdzeń powinny być fokusowane: proponowane wartości, widok diff, powód i data wejścia w życie.
Przepływ przekazania (nie pozwól zapomnieć istotnych rzeczy)
Gdy własność przechodzi między zespołami, uruchom checklistę handover przed faktycznym wejściem zmiany w życie. Dodaj strukturalne pola typu:
- Link do dokumentów (design/spec)
- Link do runbooka/on-call
- Otwarte ryzyka (krótki opis + ważność)
- Znane zależności (opcjonalne)
To zamienia własność w wartość operacyjną, nie tylko nazwę.
Reguły konfliktów i flagi w UI
Zdefiniuj konflikty jawnie i sygnalizuj je tam, gdzie pracują ludzie:
- Brak właściciela: wyróżnij na czerwono, dodaj akcję „przejmij właścicielstwo” i eskaluj, jeśli nierozwiązane.
- Wielu głównych właścicieli: blokuj zatwierdzenie, chyba że funkcja dopuszcza współwłasność; w przeciwnym razie wymagaj rozwiązania.
Pokazuj konflikty na stronie funkcji i na dashboardzie, żeby zespoły mogły posprzątać zanim spowodują incydent (zob. /blog/reporting-dashboards).
Powiadomienia i eskalacje
Wystaw to zespołom
Szybko udostępnij wewnętrzne narzędzie z wbudowanym hostingiem i wdrożeniem.
Tracker działa tylko wtedy, gdy ludzie zauważą, że coś wymaga uwagi. Celem jest skłonić do działania bez zasypywania wszystkich powiadomieniami.
Co powinno wyzwalać powiadomienie?
Zacznij od małego zestawu wysokosygnałowych zdarzeń:
- Zmiana własności (przypisanie nowego właściciela, usunięcie właściciela, zmiana zespołu)
- Oczekujące zatwierdzenie (ktoś zaproponował zmianę wymagającą przeglądu)
- Przestarzałe rekordy (brak aktualizacji przez X dni lub właściciel nie potwierdził po reorganizacji)
Dla każdego zdarzenia zadecyduj, kto otrzyma powiadomienie: nowy właściciel, poprzedni właściciel, lider zespołu funkcji i opcjonalnie skrzynka operacji produktu.
Digesty, by ograniczyć hałas
Powiadomienia w czasie rzeczywistym są przydatne do zatwierdzeń i zmian właściciela, ale przypomnienia mogą stać się tłem. Oferuj digesty:
- Codzienny podsumowanie: elementy oczekujące na Twoje zatwierdzenie, funkcje, za które odpowiadasz i które są przestarzałe
- Tygodniowy przegląd: nieprzypisane funkcje w Twoim obszarze, nadchodzące przeglądy własności
Użytkownik i zespół powinni móc skonfigurować digesty, z sensownymi domyślnymi ustawieniami. Proste „wstrzymaj na 7 dni” też pomaga uniknąć powtórnych pingów podczas intensywnej pracy.
Eskalacja, gdy brak właściciela
Brak przypisanego właściciela to miejsce, gdzie projekty stoją. Ustal przewidywalną, widoczną ścieżkę eskalacji:
- Powiadom domyślny kontakt zespołu (np. manager inżynierii odpowiedzialnego zespołu)
- Jeśli nadal brak przypisania po ustalonym czasie, powiadom następny poziom (dyrektor/wiodący) lub wspólny kanał eskalacyjny
- Opcjonalnie utwórz kolejkę „Potrzebna własność”, którą ops może triage'ować
Ujawnij zasady eskalacji w UI (np. „Eskalacja do X po 5 dniach roboczych”), żeby powiadomienia nie wydawały się arbitralne.
Integracje bez hardcodowania
Nie wiąż jednej usługi czatu. Udostępnij generyczny cel powiadomień przez webhook, aby zespoły kierowały alerty do Slack, Microsoft Teams, bramki e-mail lub narzędzi incidentowych.
Przynajmniej zawrzyj: typ zdarzenia, ID/nazwę funkcji, stare/nowe właścicielstwo, timestampy i deep link do rekordu (np. /features/123).
Integracje i strategia synchronizacji danych
Tracker będzie przydatny tylko wtedy, gdy odzwierciedla rzeczywistość. Najszybszym sposobem utraty zaufania są przestarzałe dane: zmiana nazwy zespołu w HR, przesunięcie funkcji w trackerze zadań czy właściciel, który odszedł z firmy. Traktuj integracje jako rdzeń produktu, nie dodatek.
Priorytetyzuj systemy, którym ludzie ufają
Zacznij od małej listy wysokosygnałowych źródeł:
- Katalog (użytkownicy/zespoły): dostawca tożsamości lub katalog HR jako źródło imion, e-maili, członkostw zespołu i statusu aktywności.
- Tracker zadań (Jira, Linear, Azure DevOps): pomocny do linkowania funkcji do epików/projektów, statusu i zespołu odpowiedzialnego.
- Katalog usług (Backstage, OpsLevel): często zawiera „system owner” i informacje on-call, które uzupełniają poziom funkcji.
- Dokumentacja (Confluence, Notion, Google Drive): decyzje własności zwykle są zapisane — przechowuj canonical linki, zamiast duplikować treść.
W pierwszej iteracji przechowuj identyfikatory i URL-e i eksponuj je spójnie. Głębszą synchronizację dodasz, gdy zespoły zaczną polegać na aplikacji.
Wybierz kierunek synchronizacji świadomie
Zdecyduj, czy aplikacja będzie:
- Tylko do odczytu ze źródeł: najbezpieczniejsze. Twoja aplikacja staje się skondensowanym widokiem z dodatkowymi strukturami (np. macierzą własności), a edycje są robione w narzędziach źródłowych.
- Dwukierunkowa (write-back): wygodna, ale ryzykowna. Jeśli aplikacja będzie zapisywać pole „owner” z powrotem do Jira czy katalogu usług, potrzebujesz obsługi konfliktów, mapowania uprawnień i jasnego logu audytu.
Praktyczny kompromis: synchronizacja do odczytu plus workflow „proponuj zmiany”, który powiadamia właściwego właściciela, by zaktualizował źródło.
Obsługuj import/eksport CSV do bootstrapu
Nawet z integracjami potrzebujesz operacji masowych:
- Początkowy import do zasilenia funkcji i właścicieli ze starych arkuszy.
- Masowe aktualizacje przy reorganizacjach.
- Eksport do przeglądów offline i audytów kwartalnych.
Daj ścisłe szablony CSV (wymagane kolumny, poprawne ID zespołu/użytkownika) i raporty błędów zrozumiałe dla nietechnicznych użytkowników.
Pokazuj świeżość danych, żeby nie tracić zaufania
Każde synchronizowane pole powinno pokazywać:
- Ostatni timestamp synchronizacji
- Status synchronizacji (ok, warning, failed)
- Źródło prawdy (katalog, tracker zadań, ręczne przesłonięcie)
Jeśli synchronizacja zawiedzie, pokaż, co jest dotknięte i co nadal może być poprawne. Ta przejrzystość utrzyma zaufanie zamiast powrotu do bocznych arkuszy.
Raportowanie, pulpity i macierz własności
Skonfiguruj historię i audyt
Modeluj ograniczone w czasie przypisania i log audytu, aby zmiany były odtwarzalne.
Raportowanie to moment, gdy baza danych staje się narzędziem codziennym. Cel: odpowiedzieć na najczęstsze pytania w kilka sekund: Kto to posiada? Czy to aktualne? Co jest teraz ryzykowne?
Pulpity pokazujące ryzyko
Zacznij od małego zestawu pulpitów, które wyciągają luki operacyjne, a nie vanity metrics:
- Nieprzypisane funkcje: brak głównego właściciela (opcjonalnie brak zapasowego).
- Przestarzała własność: przypisania, które nie były potwierdzone przez X dni (np. 90) lub gdy zespół właściciela już nie istnieje.
- Obszary wysokiego ryzyka: funkcje powiązane z krytycznymi systemami, dużą liczbą ticketów, ostatnimi incydentami lub nadchodzącymi wydaniami — ale bez jasnej własności.
Każda karta powinna przekierowywać do filtrowanej listy z oczywistym następnym krokiem („Przypisz właściciela”, „Poproś o potwierdzenie”, „Eskaluj”). Traktuj pulpity jako kolejki.
Macierz własności (funkcja × zespół)
Widok macierzy pomaga grupom międzyzespołowym (wsparcie, SRE, release managerowie) zobaczyć wzorce jednym rzutem oka.
Zrób siatkę: wiersze = funkcje, kolumny = zespoły, komórka = relacja (Owner, Contributor, Consulted, Informed). Zachowaj czytelność:
- Pozwól grupować wiersze po obszarze produktu lub systemie.
- Dodaj szybkie filtry: „pokaż tylko luki”, „tylko zakres wydania”, „tylko moje zespoły”.
- Dodaj drill-in do pojedynczej funkcji, który wyjaśnia dlaczego zespół jest oznaczony (linki do serwisu, repo, on-call lub ticketów).
Eksport w stylu RACI (bez ceremonii)
Nie wszyscy muszą korzystać z aplikacji, żeby z niej skorzystać. Dodaj eksport RACI dla wybranego zakresu (obszar produktu, wydanie, tag) z jednym kliknięciem. Dostarcz:
- CSV do arkuszy
- PDF na przeglądy kierownictwa
Utrzymuj spójne definicje w UI i eksportach, aby uniknąć sporów o znaczenie „Accountable”.
Zapisane widoki dla różnych odbiorców
Zapisane widoki zapobiegają eksplozji pulpitów. Oferuj domyślne presety i możliwość zapisu własnych:
- Wsparcie: „Najczęściej kontaktowane funkcje z właścicielem + zapasem + kanałem eskalacji.”
- Release managerowie: „Funkcje w tagu wydania bez potwierdzonej własności.”
- Kierownictwo: „Trend pokrycia i główne kosze ryzyka.”
Widoki audytu i zgodności
Zmiany własności mają wpływ na procesy, więc raportowanie powinno zawierać sygnały zaufania:
- Historia zmian per funkcja (kto, co, kiedy, dlaczego)
- Status zatwierdzeń dla wrażliwych obszarów
- Logi dostępu dla akcji administracyjnych
Powiąż te widoki ze stronami funkcji i ekranami admina (zob. /blog/access-control).
Plan wdrożenia, deployment i bieżące zarządzanie
Tracker własności odnosi sukces, gdy jest łatwy do wdrożenia, bezpieczny do zmiany i ma jasnego właściciela. Traktuj implementację, deployment i governance jako część produktu.
Wybierz stack, który zespół utrzyma
Zacznij od tego, co Wasz zespół potrafi utrzymać.
Dla szybkiego dostarczenia i prostych operacji aplikacja renderowana po stronie serwera (np. Rails/Django/Laravel) z relacyjną bazą danych często wystarcza. Jeśli macie silny front-end i potrzebujecie interaktywnych workflowów (masowe edycje, inline approvals), SPA (React/Vue) + API też się sprawdzi — pamiętaj o wersjonowaniu API i obsłudze błędów.
W obu przypadkach użyj relacyjnej DB (Postgres/MySQL) dla historii własności i ograniczeń (np. „jeden główny właściciel na funkcję”) i trzymaj log audytu niezmiennym.
Jeśli chcesz przyspieszyć dostawę bez budowania pełnej linii na start, Koder.ai może wygenerować działające UI React i backend Go/PostgreSQL z opisem w chatcie, a potem pozwolić na eksport źródła, gdy będziesz gotowy przenieść projekt in-house.
Podstawy deploymentu: środowiska i niezawodność
Ustaw trzy środowiska wcześnie: dev, staging, production. Staging powinien odzwierciedlać uprawnienia i integracje produkcji, by zatwierdzenia i zadania synchronizacji zachowywały się podobnie.
Zaplanuj podstawy:
- Migracje: uruchamiane w CI/CD; ćwicz rollbacky.
- Backupy: automatyczne, testowane przywracanie i zasady retencji.
- Monitoring: checki uptime, śledzenie błędów i alerty dla nieudanych synców/ząbków zatwierdzeń.
Do dokumentów operacyjnych dodaj krótki runbook z „jak wdrożyć”, „jak przywrócić” i „gdzie patrzeć, gdy synchronizacja zawiedzie”.
Testuj najryzykowniejsze elementy najpierw
Priorytetyzuj testy tam, gdzie błąd może wyrządzić szkody:
- Kontrola dostępu: role, poziom widoczności w wierszu, reguły „kto może zmieniać właściciela”.
- Workflowy zatwierdzania: przejścia stanów, odrzucenia i ponowne żądania.
- Zadania synchronizacji: retry, idempotencja i rozwiązanie konfliktów.
Governance: utrzymuj tracker godnym zaufania
Wyznacz opiekunów taksonomii (zespoły, domeny, zasady nazewnictwa). Ustal cykl przeglądu (miesięczny lub kwartalny) na czyszczenie duplikatów i przestarzałej własności.
Na koniec zdefiniuj „definition of done” dla własności, np.: przypisany główny właściciel, właściciel zapasowy, data ostatniego przeglądu i link do kanału zespołu lub rotacji on-call.