03 paź 2025·6 min
Podejście „snapshot-first” do bezpieczniejszych dużych zmian
Dowiedz się, jak stosować workflow 'snapshot-first' — twórz bezpieczne punkty zapisu przed zmianami schematu, uwierzytelniania i UI i cofnij się bez utraty postępów.
Dowiedz się, jak stosować workflow 'snapshot-first' — twórz bezpieczne punkty zapisu przed zmianami schematu, uwierzytelniania i UI i cofnij się bez utraty postępów.
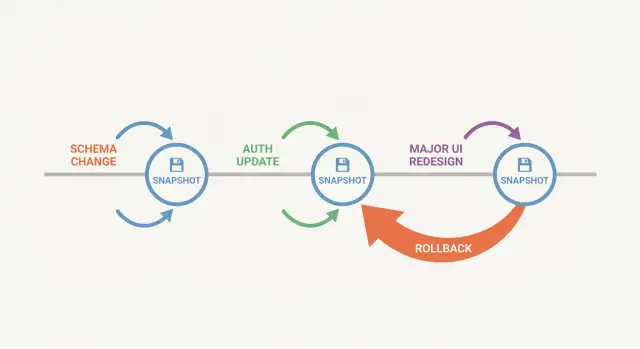
Workflow snapshot-first oznacza, że tworzysz punkt zapisu przed dokonaniem zmiany, która może zepsuć aplikację. Snapshot to zamrożona kopia projektu w danym momencie. Jeśli następny krok pójdzie nie tak, możesz wrócić do tego dokładnego stanu zamiast ręcznie naprawiać bałagan.
Duże zmiany rzadko zawodzą w jeden oczywisty sposób. Aktualizacja schematu może zepsuć raport trzy ekrany dalej. Zmiana w auth może zablokować dostęp. Przebudowa UI może wyglądać dobrze na przykładowych danych, a rozpaść się przy prawdziwych kontach i przypadkach brzegowych. Bez jasnego punktu zapisu zgadujesz, która zmiana spowodowała problem, albo ciągle łatasz uszkodzoną wersję, aż zapomnisz, jak wyglądało działanie.
Snapshoty pomagają, bo dają znaną-dobrą bazę, obniżają koszt próbowania odważnych pomysłów i upraszczają testy. Kiedy coś się psuje, możesz odpowiedzieć: „Czy było OK zaraz po Snapshot X?”
Warto też być jasnym, czego snapshot nie naprawi. Snapshot zachowuje kod i konfigurację tak, jak były (a na platformach takich jak Koder.ai może zachować nawet pełny stan aplikacji, nad którym pracujesz). Nie cofa jednak złych założeń. Jeśli nowa funkcja oczekuje kolumny w bazie, której nie ma w produkcji, cofnięcie kodu nie unieważni migracji, która już się wykonała. Nadal potrzebujesz planu dla zmian danych, kompatybilności i kolejności wdrożenia.
Zmiana myślenia polega na traktowaniu snapshotowania jako nawyku, a nie guzika ratunkowego. Rób snapshoty tuż przed ryzykownymi ruchami, nie po awarii. Będziesz pracować szybciej i spokojniej, bo zawsze masz czysty „ostatni znany dobry” punkt do powrotu.
Snapshot najbardziej się opłaca, gdy zmiana może zepsuć wiele rzeczy naraz.
Prace nad schematem są oczywiste: zmiana nazwy kolumny może po cichu zepsuć API, zadania w tle, eksporty i raporty, które wciąż oczekują starej nazwy. Prace przy auth to kolejny przykład: mała zmiana reguły może zablokować administratorów lub nieumyślnie przyznać dostęp. Przebudowy UI są podstępne, bo często łączą zmiany wizualne z funkcjonalnymi — regresje chowają się w stanach brzegowych.
Jeśli chcesz prostą regułę: zrób snapshot przed wszystkim, co zmienia kształt danych, tożsamość i dostęp, lub kilka ekranów naraz.
Niskoryzykowne poprawki zwykle nie wymagają zatrzymania i snapshotu. Zmiany tekstu, drobne poprawki odstępów, małe reguły walidacji czy drobne czyszczenie pomocniczych funkcji mają zazwyczaj mały promień rażenia. Możesz nadal robić snapshot, jeśli pomaga ci to się skupić, ale nie musisz przerywać każdej drobnej edycji.
Z kolei zmiany wysokiego ryzyka często działają w testach „happy path”, ale zawodzą przy nullach w starych wierszach, użytkownikach z nietypowymi kombinacjami ról albo stanach UI, których nie testujesz ręcznie.
Snapshot pomaga tylko wtedy, gdy szybko go rozpoznasz pod presją. Nazwa i notatki zamieniają rollback w spokojną, szybką decyzję.
Dobra etykieta odpowiada na trzy pytania:
Trzymaj nazwę krótką, ale konkretną. Unikaj mylących nazw typu „before update” czy „try again”.
Wybierz jeden wzorzec i się go trzymaj. Na przykład:
[WIP] Auth: add magic link (prep for OAuth)[GOLD] DB: users table v2 (passes smoke tests)[WIP] UI: dashboard layout refactor (next: charts)[GOLD] Release: billing fixes (deployed)Hotfix: login redirect loop (root cause noted)Status najpierw, potem obszar, akcja, a na końcu krótki „następny krok”. Ta ostatnia część bywa zaskakująco pomocna po tygodniu.
Sama nazwa to za mało. Używaj notatek, by zapisać to, co przyszłe ja zapomni: założenia, co testowałeś, co wciąż jest zepsute i co celowo zignorowałeś.
Dobre notatki zwykle zawierają założenia, 2–3 szybkie kroki testowe, znane problemy i wszelkie ryzykowne szczegóły (zmiany schematu, uprawnienia, routing).
Oznaczaj snapshot jako GOLD tylko wtedy, gdy jest bezpieczny do powrotu bez niespodzianek: podstawowe przepływy działają, błędy są zrozumiane i możesz kontynuować pracę od tego miejsca. Wszystko inne to WIP. Ten drobny nawyk zapobiega cofnięciu się do punktu, który tylko wyglądał stabilnie, bo zapomniałeś o jednym dużym błędzie.
Solidny cykl jest prosty: poruszaj się naprzód tylko z znanych-dobrych punktów.
Zanim zrobisz snapshot, upewnij się, że aplikacja faktycznie działa i kluczowe przepływy zachowują się prawidłowo. Trzymaj to proste: czy możesz otworzyć główny ekran, zalogować się (jeśli aplikacja to ma) i wykonać jedną podstawową akcję bez błędów? Jeśli coś już jest niestabilne, napraw to najpierw — w przeciwnym razie snapshot zachowa problem.
Stwórz snapshot, a potem dodaj jednowersową notatkę, dlaczego on istnieje. Opisz nadchodzące ryzyko, nie bieżący stan.
Przykład: „Przed zmianą tabeli users + dodaniem organization_id” lub „Przed przebudową middleware auth, by wspierać SSO”.
Unikaj stosowania wielu dużych zmian w jednej iteracji (schemat + auth + UI). Wybierz pojedynczy kawałek, dokończ go i zatrzymaj się.
Dobry „jeden krok” to np. „dodaj nową kolumnę i utrzymaj działanie starego kodu”, a nie „zamień cały model danych i zaktualizuj każdy ekran”.
Po każdym kroku uruchom te same szybkie kontrole, aby wyniki były porównywalne. Trzymaj je krótkie, żeby faktycznie to robić.
Gdy zmiana działa i masz czystą bazę, zrób kolejny snapshot. To stanie się nowym bezpiecznym punktem startowym do następnego kroku.
Zmiany w bazie danych wydają się „małe” aż do momentu, gdy psują rejestrację, raporty lub zadanie w tle, o którym zapomniałeś. Traktuj prace nad schematem jako sekwencję bezpiecznych checkpointów, a nie jeden wielki skok.
Zacznij od snapshotu przed dotknięciem czegokolwiek. Potem zapisz prostym językiem: które tabele są zaangażowane, które ekrany lub wywołania API je czytają i jak wygląda „poprawne” (pola wymagane, reguły unikalności, spodziewane liczby wierszy). To zajmuje minuty, a oszczędza godziny przy porównywaniu zachowania.
Praktyczny zestaw punktów zapisu dla większości prac nad schematem wygląda tak:
Unikaj jednej ogromnej migracji, która zmienia wszystko naraz. Podziel ją na mniejsze kroki, które możesz testować i wycofać.
Po każdym checkpointcie weryfikuj nie tylko happy path. Przepływy CRUD zależne od zmienionych tabel są ważne, ale eksporty (CSV, faktury, raporty admins) też — często używają starych zapytań.
Zaplanuj ścieżkę rollbacku zanim zacznisz. Jeśli dodasz nową kolumnę i zaczniesz do niej zapisywać, zdecyduj, co się stanie po rewercie: czy stary kod bezpiecznie ją zignoruje, czy potrzebna będzie migracja wsteczna? Jeśli możesz skończyć z częściowo zmigrowanymi danymi, zdecyduj, jak to wykryć i dokończyć, albo jak to porzucić czysto.
Zmiany w auth to jeden z najszybszych sposobów na zablokowanie siebie (i użytkowników). Punkt zapisu pomaga, bo możesz spróbować ryzykownej zmiany, przetestować ją i szybko się cofnąć, jeśli trzeba.
Zrób snapshot tuż przed dotknięciem auth. Potem zapisz, co masz dziś, nawet jeśli wydaje się oczywiste. To zapobiega „myślałem, że admini nadal mogą się logować” niespodziankom.
Zapisz podstawy:
Zmieniając, rób jedną regułę na raz. Jeśli zmienisz sprawdzanie ról, logikę tokenów i ekrany logowania naraz, nie poznasz przyczyny awarii.
Dobry rytm: zmień jedną część, uruchom te same krótkie kontrole, a jeśli jest czysto, zrób snapshot. Na przykład przy dodawaniu roli „editor” — najpierw zaimplementuj tworzenie i przypisywanie ról i potwierdź logowanie, potem dodaj jedno sprawdzenie uprawnień i przetestuj.
Po zmianie zweryfikuj kontrolę dostępu z trzech perspektyw. Zwykli użytkownicy nie powinni widzieć akcji tylko dla adminów. Admini muszą mieć dostęp do ustawień i zarządzania użytkownikami. Testuj też stany brzegowe: wygasłe sesje, reset hasła, wyłączone konta i logowanie metodą, której nie używałeś w testach.
Jedna pomijana rzecz: sekrety często są poza kodem. Jeśli cofniesz kod, ale zostawisz nowe klucze i ustawienia callback, auth może się psuć w mylący sposób. Zostaw jasne notatki o wszelkich zmianach środowiskowych, które zrobiłeś lub trzeba cofnąć.
Przebudowy UI są ryzykowne, bo łączą pracę wizualną z funkcjonalnymi zmianami. Zrób punkt zapisu, gdy UI jest stabilne i przewidywalne, nawet jeśli nie jest ładne. Ten snapshot stanie się twoją bazą roboczą: ostatnią wersją, którą wysłałbyś, gdyby trzeba było.
Przebudowy UI zawodzą, gdy traktuje się je jako jeden wielki przełącznik. Podziel pracę na kawałki, które mogą przetrwać same: jeden ekran, jedna trasa lub jeden komponent.
Jeśli przebudowujesz koszyk, podziel na: Koszyk, Adres, Płatność i Potwierdzenie. Po każdym kawałku najpierw odwzoruj stare zachowanie. Potem popraw układ, treść i drobne interakcje. Gdy dany kawałek jest „wystarczająco gotowy”, zrób snapshot.
Po każdym kawałku wykonaj szybkie retesty skupione na tym, co zwykle się psuje przy przebudowach:
Typowa awaria wygląda tak: nowy ekran Profil jest ładniejszy, ale jedno pole już nie zapisuje, ponieważ komponent zmienił kształt payloadu. Z dobrym checkpointem możesz cofnąć się, porównać i ponownie wprowadzić poprawki wizualne bez tracenia dni pracy.
Rollback powinien być kontrolowany, a nie paniką. Najpierw zdecyduj, czy potrzebujesz pełnego cofnięcia do znanego-dobrego punktu, czy częściowego cofnięcia jednej zmiany.
Pełny rollback ma sens, gdy aplikacja jest popsuta w wielu miejscach (testy padają, serwer nie startuje, logowanie zablokowane). Częściowe cofnięcie pasuje, gdy problem dotyczy jednego elementu, np. migracji, guardu trasy lub komponentu powodującego crash.
Traktuj ostatni stabilny snapshot jako bazę:
Potem poświęć pięć minut na podstawowe kontrole. Łatwo cofnąć się i nadal przeoczyć cichy błąd, np. zadanie w tle, które już nie działa.
Szybkie kontrole, które łapią większość problemów:
Przykład: zrobiłeś dużą refaktoryzację auth i zablokowałeś konto admina. Cofnij do snapshotu zrobionego tuż przed zmianą, sprawdź, że możesz się zalogować, potem ponownie wprowadzaj zmiany małymi krokami: najpierw role, potem middleware, potem blokady UI. Jeśli znów się popsuje, będziesz wiedzieć dokładnie, który krok to spowodował.
Na koniec zostaw krótką notatkę: co się zepsuło, jak to zauważyłeś, co to naprawiło i co zrobisz następnym razem. To zamienia rollbacky w naukę zamiast straconego czasu.
Ból przy rollbacku zwykle wynika z niejasnych punktów zapisu, mieszanych zmian i pominiętych kontroli.
Zbyt rzadkie zapisywanie to klasyczny błąd. Ludzie robią „szybką” poprawkę schematu, małą zmianę auth i drobną poprawkę UI, a potem odkrywają, że aplikacja jest popsuta bez czystego punktu do powrotu.
Przeciwieństwem jest zapisywanie non-stop bez notatek. Dziesięć snapshotów nazwanych „test” to praktycznie jeden snapshot, bo nie widać, który jest bezpieczny.
Mieszanie wielu ryzykownych zmian w jednej iteracji to kolejna pułapka. Jeśli schemat, uprawnienia i UI wylądują razem, rollback staje się zgadywanką. Tracisz też opcję zachowania dobrej części (np. poprawki UI) i wycofania tylko ryzykownej części (np. migracji).
Jeszcze jeden problem: cofanie bez sprawdzenia założeń dotyczących danych i uprawnień. Po rollbacku baza może nadal zawierać nowe kolumny, nieoczekiwane null-e lub częściowo zmigrowane wiersze. Albo możesz przywrócić starą logikę auth, podczas gdy role użytkowników zostały utworzone według nowych zasad. Ten brak zgodności może wyglądać jak „rollback nie zadziałał”, mimo że tak naprawdę działał.
Jeśli chcesz prosty sposób, by uniknąć większości tego:
Snapshoty działają najlepiej w parze z szybkimi kontrolami. Te kontrole to nie pełny plan testów. To mały zestaw akcji, które szybko powiedzą ci, czy możesz iść dalej, czy powinieneś się wycofać.
Wykonaj je tuż przed zrobieniem snapshotu. Udowadniasz, że bieżąca wersja jest warta zapisania.
Jeśli coś już jest zepsute, napraw to najpierw. Nie zapisuj problemu, chyba że celowo chcesz go zachować do debugowania.
Celuj w jedną ścieżkę szczęścia, jedną ścieżkę błędu i kontrolę uprawnień.
Wyobraź sobie, że dodajesz nową rolę „Manager” i przerabiasz ekran Ustawień.
Zacznij od stabilnej wersji. Uruchom pre-change checks, zrób snapshot z jasną nazwą, np.: „pre-manager-role + pre-settings-redesign”.
Najpierw zrób pracę backendową nad rolami (tabele, uprawnienia, API). Kiedy role i reguły dostępu działają poprawnie, zrób kolejny snapshot: „roles-working”.
Potem zacznij przebudowę UI Ustawień. Przed dużą zmianą layoutu zrób snapshot: „pre-settings-ui-rewrite”. Jeśli UI stanie się chaotyczne, cofnij się do tego punktu i spróbuj czystsze podejście bez utraty dobrej pracy nad rolami.
Gdy nowe Ustawienia są używalne, zrób snapshot: „settings-ui-clean”. Dopiero potem przejdź do dopracowywania.
Wypróbuj to przy małej funkcji w tym tygodniu. Wybierz jedną ryzykowną zmianę, umieść dwa snapshoty wokół niej (przed i po) i przećwicz rollback celowo.
Jeśli budujesz na Koder.ai (koder.ai), wbudowane snapshoty i rollback ułatwiają utrzymanie tego workflow podczas iteracji. Cel jest prosty: sprawić, by duże zmiany były odwracalne, żebyś mógł działać szybko, nie ryzykując działającej wersji.
Snapshot to zamrożony punkt zapisu projektu w określonym momencie. Domyślny nawyk to: zrób snapshot tuż przed ryzykowną zmianą, aby móc wrócić do znanego, działającego stanu, jeśli coś się zepsuje.
Jest to najbardziej pomocne, gdy awarie są pośrednie (zmiana schematu psująca raport, tweak w auth blokujący dostęp, przebudowa UI, która zawodzi przy prawdziwych danych).
Rób snapshot przed zmianami o dużym zasięgu:
Drobne edycje (zmiany tekstu, niewielkie odstępy, małe refaktory) zwykle nie wymagają robienia snapshotu za każdym razem.
Użyj spójnego wzoru, który odpowiada na trzy pytania:
Praktyczny format: STATUS + Obszar + Akcja (+ następny krok).
Przykłady:
Oznaczaj snapshot jako GOLD tylko wtedy, gdy możesz do niego wrócić i kontynuować pracę bez niespodzianek.
Dobry snapshot GOLD zwykle oznacza:
Wszystko inne traktuj jako WIP. Ten drobny nawyk zapobiega powrotom do punktu, który wyglądał stabilnie tylko dlatego, że zapomniałeś o jednym dużym błędzie.
Utrzymuj krótkie, powtarzalne kontrole:
Celem nie jest pełne testowanie — tylko potwierdzenie, że masz bezpieczną bazę do dalszej pracy.
Praktyczny zestaw punktów zapisu wygląda tak:
Zrób snapshot zanim dotkniesz auth, a potem zapisz, jak to teraz wygląda:
Zmieniając, rób jedną regułę na raz. Jeśli zmienisz sprawdzanie ról, logikę tokenów i ekran logowania jednocześnie, nie będziesz wiedział, co poszło nie tak.
Pamiętaj: sekrety często żyją poza kodem. Cofnięcie kodu nie przywróci nowych kluczy czy ustawień callback — zanotuj wszystkie zmiany środowiskowe.
Podziel przebudowę UI na kawałki, które mogą istnieć samodzielnie: jeden ekran, jedną trasę lub jeden komponent.
Najpierw odwzoruj stare zachowanie (formularze, payloady, nawigacja), potem popraw układ i interakcje. Po zakończeniu kawałka zrób snapshot.
Po każdym kawałku szybko przetestuj typowe miejsca awarii:
Ustal, czy potrzebujesz pełnego rollbacku do znanego stanu, czy częściowego cofnięcia jednej zmiany.
Pełny rollback ma sens, gdy aplikacja jest zepsuta w wielu miejscach. Częściowe cofnięcie — gdy wadliwy jest pojedynczy element (migracja, guard trasy, komponent powodujący crash).
Bezpieczna sekwencja rollbacku:
Typowe błędy, które komplikują rollback:
Proste zasady, które pomagają uniknąć większości problemów:
[WIP] Auth: add magic link (next: OAuth)[GOLD] DB: users v2 (passes smoke tests)Unikaj nazw typu „test” lub „before update” — pod presją trudno na nie polegać.
Domyślna zasada: unikaj jednej wielkiej migracji zmieniającej wszystko na raz. Dziel zmiany na mniejsze kroki, które możesz testować i wycofać.
Dobrze ustawiony checkpoint pozwala cofnąć się, porównać i poprawić wygląd bez utraty dni pracy.
stable-after-rollback.Po rollbacku spędź pięć minut na podstawowych kontrolach — łatwo cofnąć się, a przeoczyć cichy błąd np. w zadaniach background.