Bazy danych SQL vs NoSQL: kluczowe różnice i zastosowania
Poznaj rzeczywiste różnice między bazami SQL i NoSQL: modele danych, skalowalność, spójność oraz kiedy warto użyć każdego z nich.
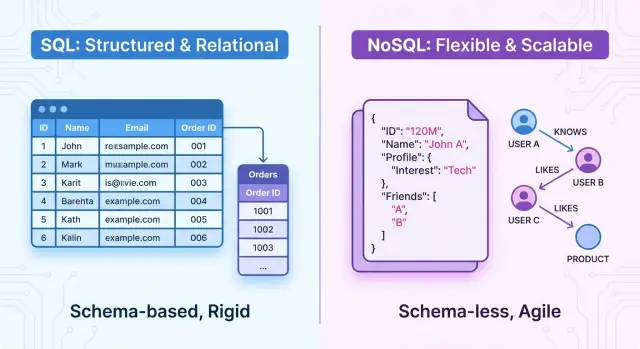
Przegląd: SQL i NoSQL w pigułce
Wybór między bazą SQL a NoSQL wpływa na sposób projektowania, budowy i skalowania aplikacji. Model bazy determinuje wszystko — od struktury danych i wzorców zapytań po wydajność, niezawodność i tempo, w jakim zespół może rozwijać produkt.
Na wysokim poziomie bazy SQL to systemy relacyjne. Dane organizowane są w tabele ze stałym schematem, wierszami i kolumnami. Relacje między encjami są jawne (przez klucze obce), a zapytania wykonuje się za pomocą SQL — potężnego deklaratywnego języka. Systemy te podkreślają transakcje ACID, silną spójność i dobrze zdefiniowaną strukturę.
Bazy NoSQL to systemy nierelacyjne. Zamiast jednego sztywnego modelu tabelarycznego oferują różne modele danych dopasowane do potrzeb, np:
- magazyny klucz–wartość
- bazy dokumentowe
- szerokokolumnowe (column-family)
- bazy grafowe
Oznacza to, że „NoSQL” to nie jedna technologia, a parasol pojęć obejmujący różne podejścia, z własnymi kompromisami dotyczącymi elastyczności, wydajności i modelowania danych. Wiele systemów NoSQL rozluźnia ścisłe gwarancje spójności, by zyskać większą skalowalność, dostępność lub niskie opóźnienia.
Ten artykuł skupia się na różnicach między SQL i NoSQL — modelach danych, językach zapytań, wydajności, skalowalności i spójności (ACID vs spójność ostateczna). Celem jest pomóc wybrać między SQL i NoSQL dla konkretnych projektów oraz zrozumieć, kiedy który typ bazy sprawdzi się najlepiej.
Nie musisz wybierać tylko jednego podejścia. W wielu nowoczesnych architekturach stosuje się polyglot persistence, gdzie SQL i NoSQL współistnieją w jednym systemie, każdy obsługując obciążenia, do których jest najlepiej dopasowany.
Czym jest baza SQL (relacyjna)?
Baza SQL (relacyjna) przechowuje dane w ustrukturyzowanej, tabelarycznej formie i używa Structured Query Language (SQL) do definiowania, zapytywania i manipulacji tymi danymi. Opiera się na koncepcji relacji, które można rozumieć jako dobrze zorganizowane tabele.
Podstawowa struktura: tabele, wiersze, kolumny i schematy
Dane organizowane są w tabele. Każda tabela reprezentuje jeden typ encji, np. customers, orders czy products.
- Wiersz (rekord) to pojedynczy egzemplarz encji, np. jeden klient.
- Kolumna (pole) to konkretna właściwość, np.
emailluborder_date.
Każda tabela ma stały schemat: z góry określoną strukturę, która definiuje
- jakie kolumny istnieją
- ich typy danych (np.
INTEGER,VARCHAR,DATE) - ograniczenia (np.
NOT NULL,UNIQUE)
Schemat jest egzekwowany przez bazę, co pomaga utrzymywać spójność i przewidywalność danych.
Klucze i relacje
Bazy relacyjne świetnie nadają się do modelowania powiązań między encjami.
- Klucz główny (primary key) jednoznacznie identyfikuje każdy wiersz w tabeli (np.
customer_id). - Klucz obcy (foreign key) to kolumna odwołująca się do klucza głównego innej tabeli, łącząca powiązane wiersze.
Dzięki tym kluczom możesz definiować relacje takie jak:
- jeden‑do‑wielu (np. jeden klient, wiele zamówień)
- wiele‑do‑wielu (np. produkty w wielu zamówieniach, zamówienia z wieloma produktami)
Transakcje i własności ACID
Bazy relacyjne obsługują transakcje — grupy operacji zachowujące się jak jedna jednostka. Transakcje definiuje się przez własności ACID:
- Atomicity: wszystkie operacje się powiodą albo żadna.
- Consistency: transakcje przenoszą bazę ze stanu poprawnego do innego poprawnego stanu.
- Isolation: współbieżne transakcje nie wpływają na siebie w widoczny sposób.
- Durability: po zatwierdzeniu dane są trwale zapisane.
Te gwarancje są kluczowe w systemach finansowych, zarządzaniu magazynem i wszędzie tam, gdzie poprawność ma znaczenie.
Popularne bazy SQL
Do popularnych systemów relacyjnych należą:
- MySQL i MariaDB
- PostgreSQL
- Microsoft SQL Server
- Oracle Database
Wszystkie udostępniają SQL, dodając własne rozszerzenia i narzędzia do administracji, optymalizacji wydajności i bezpieczeństwa.
Czym jest baza NoSQL (nierelacyjna)?
Bazy NoSQL to nierelacyjne magazyny danych, które nie stosują tradycyjnego modelu tabela–wiersz–kolumna. Skupiają się na elastycznych modelach danych, skalowaniu poziomym i wysokiej dostępności, często kosztem ścisłych gwarancji transakcyjnych.
Elastyczne modele danych
Wiele baz NoSQL określa się jako bezschematowe lub o elastycznym schemacie. Zamiast narzucać sztywny schemat z góry, można przechowywać rekordy o różnej strukturze w tej samej kolekcji.
To jest szczególnie przydatne do:
- ewolucji wymagań aplikacji
- obsługi półustrukturalnych danych (logi, zdarzenia, profile użytkowników)
- przechowywania zagnieżdżonych danych, np. dokumentów JSON
Dzięki temu pola można dodawać lub pomijać dla poszczególnych rekordów bez konieczności migracji schematu. Niektóre systemy NoSQL oferują jednak opcjonalne lub wymuszane schematy.
Główne typy NoSQL
NoSQL to zbiór modeli:
- Bazy dokumentowe: przechowują dane jako dokumenty podobne do JSON. Przykłady: MongoDB, Couchbase.
- Magazyny klucz–wartość: proste mapy klucz→wartość, świetne do cache i sesji. Przykłady: Redis, Amazon DynamoDB (w trybie klucz–wartość).
- Szerokokolumnowe (column-family): organizacja danych według rodzin kolumn dla dużego przepływu zapisów. Przykłady: Apache Cassandra, HBase.
- Bazy grafowe: skupiają się na węzłach i relacjach, idealne dla danych silnie połączonych. Przykłady: Neo4j, Amazon Neptune.
Modele spójności
Wiele systemów NoSQL stawia na dostępność i tolerancję partycji, oferując spójność ostateczną zamiast ścisłych transakcji ACID. Niektóre z nich pozwalają jednak konfigurować poziomy spójności lub oferują ograniczone transakcje (np. per dokument, partycję lub zakres kluczy), dzięki czemu możesz wybierać między silniejszymi gwarancjami a wyższą wydajnością dla wybranych operacji.
Modele danych: struktura, schematy i relacje
Modelowanie danych to obszar, gdzie SQL i NoSQL różnią się najbardziej. To ono kształtuje sposób projektowania funkcji, zapytywania danych i ewolucji aplikacji.
Struktura i schematy
Bazy SQL stosują struktury z góry zdefiniowane. Projektujesz tabele i kolumny, ze ścisłymi typami i ograniczeniami:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
Każdy wiersz musi odpowiadać schematowi. Zmiany wymagają zazwyczaj migracji (ALTER TABLE, backfill itd.).
Bazy NoSQL zwykle wspierają elastyczny schemat. W bazie dokumentowej każdy dokument może mieć inne pola:
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
Pola można dodawać per dokument bez centralnej migracji. Niektóre systemy NoSQL pozwalają na opcjonalne walidacje schematu, ale ogólnie są luźniejsze.
Normalizacja kontra denormalizacja
Modele relacyjne promują normalizację: rozdzielanie danych na powiązane tabele, by uniknąć duplikacji i utrzymać integralność. To sprzyja szybszym, spójnym zapisom i mniejszemu zużyciu miejsca, lecz odczyty mogą wymagać złożonych joinów.
NoSQL często promuje denormalizację: osadzanie powiązanych danych razem pod kątem najważniejszych zapytań. To poprawia wydajność odczytów i upraszcza zapytania, ale zapisy mogą być wolniejsze lub bardziej złożone, bo ta sama informacja może występować w wielu miejscach.
Modelowanie relacji
W SQL relacje są jawne i egzekwowane:
- jeden‑do‑wielu: klucze obce (users → orders)
- wiele‑do‑wielu: tabele łączące (users_roles)
W NoSQL relacje modeluje się przez:
- osadzenie (embedding) — dokument użytkownika zawiera tablicę zamówień dla danych ściśle powiązanych
- referencje —
user_idw dokumencie zamówienia dla danych luźniej powiązanych
Wybór zależy od wzorców dostępu:
- Jeśli zawsze pobierasz użytkownika wraz z jego 10 najnowszymi zamówieniami, osadzenie może być idealne.
- Jeśli zamówienia są duże, często aktualizowane lub dostępne niezależnie, referencje i oddzielne zapytania będą lepsze.
Wpływ na zmieniające się wymagania
W SQL zmiany schematu wymagają więcej planowania, ale dają silne gwarancje i spójność w całym zbiorze danych. Refaktory są jawne: migracje, backfille, aktualizacje ograniczeń.
W NoSQL ewolucja wymagań jest zwykle łatwiejsza krótko‑ i średnioterminowo. Możesz od razu przechowywać nowe pola i stopniowo aktualizować stare dokumenty. Minusem jest konieczność, by kod aplikacji obsługiwał różne kształty dokumentów i przypadki brzegowe.
Wybór między znormalizowanym modelem SQL a zdenormalizowanym modelem NoSQL to nie kwestia "lepszości", lecz dopasowania struktury danych do wzorców zapytań, obciążenia zapisami i częstotliwości zmian modelu domenowego.
Języki zapytań i wzorce dostępu
SQL: deklaratywny i ustandaryzowany
Bazy SQL zapytuje się deklaratywnie: opisujesz co chcesz, a nie jak to pobrać. Konstrukcje takie jak SELECT, WHERE, JOIN, GROUP BY i ORDER BY pozwalają sformułować złożone pytania obejmujące wiele tabel jednym zapytaniem.
SQL jest częściowo ustandaryzowany (ANSI/ISO), więc większość systemów relacyjnych dzieli wspólne składniki. Dostawcy dodają własne rozszerzenia, ale umiejętności i zapytania są względnie przenośne między PostgreSQL, MySQL, SQL Server i innymi.
Ta standaryzacja przynosi bogaty ekosystem narzędzi: ORM‑y, budowniczych zapytań, narzędzia BI, frameworki migracji i optymalizatory zapytań. Można wiele z tych narzędzi podłączyć do dowolnej bazy SQL przy niewielkich zmianach, co zmniejsza vendor lock‑in i przyspiesza development.
NoSQL: API zapytań i specyficzne wzorce
NoSQL udostępnia zapytania w bardziej zróżnicowany sposób:
- Bazy dokumentowe używają obiektów zapytań podobnych do JSON i czasem własnych języków zapytań.
- Magazyny klucz–wartość skupiają się na odczytach po kluczu i ograniczonej liczbie zapytań na indeksach pobocznych.
- Szerokokolumnowe optymalizują zapytania zgodne z wcześniej zdefiniowanymi kluczami głównymi i klastrującymi.
- Silniki wyszukiwania (Elasticsearch, Solr) stosują DSL nastawiony na pełnotekstowe zapytania i ranking.
Niektóre bazy NoSQL oferują potoki agregacji lub mechanizmy typu MapReduce do analiz, ale joiny między kolekcjami lub partycjami są ograniczone lub nieobecne. Zamiast tego powiązane dane często są osadzone w tym samym dokumencie lub zdenormalizowane.
Wzorce dostępu i produktywność
Relacyjne zapytania często opierają się na join‑ach: normalizujesz dane, a następnie rekonstruujesz encje przy odczycie za pomocą joinów. To potężne narzędzie do ad‑hocowych raportów, ale złożone joiny mogą być trudniejsze do optymalizacji.
NoSQL faworyzuje wzorce dokument‑/klucz‑centryczne: projektujesz dane wokół najczęstszych zapytań aplikacji. Odczyty są szybkie i proste — często jeden odczyt po kluczu — ale zmiana wzorców dostępu później może wymagać przekształcenia danych.
Dla nauki i produktywności:
- Deklaratywny model SQL i ogrom materiałów edukacyjnych czynią go przystępnym i trwałym w zastosowaniu.
- Zapytania NoSQL bywają prostsze dla prostych, znanych wzorców dostępu, lecz każde rozwiązanie ma własną składnię i ograniczenia, więc umiejętności są mniej przenośne.
Zespoły potrzebujące bogonych, ad‑hocowych zapytań przez relacje zwykle wybierają SQL. Zespoły o stabilnych, przewidywalnych wzorcach dostępu na bardzo dużą skalę często wolą modele NoSQL.
Spójność, transakcje i kompromisy CAP
ACID: ścisłe gwarancje w systemach SQL
Większość baz SQL projektowana jest wokół transakcji ACID:
- Atomicity: transakcja albo się w całości powiedzie, albo się wycofa.
- Consistency: każda zatwierdzona transakcja przenosi dane do poprawnego stanu.
- Isolation: współbieżne transakcje nie wpływają na siebie w widoczny sposób (poziomy izolacji: READ COMMITTED, REPEATABLE READ, SERIALIZABLE).
- Durability: po zatwierdzeniu dane przetrwają awarie (logi zapisu, replikacja itp.).
To czyni bazy SQL dobrym wyborem tam, gdzie poprawność jest ważniejsza niż surowa przepustowość zapisów.
BASE i spójność ostateczna w wielu systemach NoSQL
Wiele baz NoSQL skłania się ku BASE:
- Basically Available: system stara się być dostępny i odpowiadać.
- Soft state: dane mogą być tymczasowo niespójne między replikami.
- Eventual consistency: jeśli nie będzie nowych aktualizacji, repliki zbiegną do tej samej wartości.
Zapisy mogą być bardzo szybkie i rozproszone, ale odczyt może chwilowo zwrócić przestarzałe dane.
CAP w praktyce
CAP mówi, że w rozproszonym systemie podczas partycji sieciowej trzeba wybrać między:
- Consistency (C): wszyscy klienci widzą te same dane jednocześnie.
- Availability (A): każde żądanie otrzymuje odpowiedź.
Nie da się zagwarantować obu podczas partycji.
Typowe wzorce:
- Wiele wdrożeń SQL faworyzuje silną spójność: lepsze dla płatności, zapasów, sald kont, rezerwacji, czyli gdy przestarzały odczyt może kosztować pieniądze lub naruszyć przepisy.
- Wiele systemów NoSQL stawia na dostępność i spójność ostateczną: odpowiednie dla analityki, feedów społecznościowych, katalogów produktów, logów, cache'a, gdzie krótkotrwała niespójność jest akceptowalna, a krytyczne są szybkość i dostępność.
Nowoczesne systemy często mieszają tryby (np. konfigurowalna spójność per operacja), by różne części aplikacji mogły wybierać gwarancje, których potrzebują.
Różnice w skalowalności i wydajności
Jak zwykle skaluje się SQL
Tradycyjne bazy SQL projektowane są pod pojedynczy, wydajny węzeł.
Zwykle zaczynasz od skalowania wertykalnego: więcej CPU, RAM i szybsze dyski dla jednego serwera. Wiele silników wspiera też replikę do odczytów — dodatkowe węzły obsługujące ruch tylko do odczytu, gdy wszystkie zapisy trafiają na główny węzeł. Ten wzorzec sprawdza się dla:
- umiarkowanego ruchu zapisów
- ciężkich zapytań analitycznych i raportów
- obciążeń, gdzie spójność jest krytyczna
Jednak skalowanie wertykalne ma granice sprzętowe i kosztowe, a repliki do odczytów mogą wprowadzać opóźnienia replikacji.
NoSQL i skalowanie poziome
NoSQL zwykle projektowany jest pod skalowanie poziome: rozproszenie danych po wielu węzłach przy użyciu shardingu lub partycjonowania. Każdy shard przechowuje fragment danych, więc odczyty i zapisy mogą być rozdzielone, co zwiększa przepustowość.
To pasuje do:
- ogromnych, zapisowo‑intensywnych obciążeń
- bardzo dużych zbiorów danych przekraczających pojemność pojedynczej maszyny
- aplikacji globalnych, które potrzebują danych blisko użytkowników
Kosztem jest większa złożoność operacyjna: wybór klucza shardowania, balansowanie, obsługa zapytań między shardami.
Wzorce wydajności i indeksowania
Dla obciążeń odczytowych z złożonymi joinami i agregacjami, dobrze zaprojektowana baza SQL z indeksami może być bardzo szybka, bo optymalizator używa statystyk i planów zapytań.
Wiele systemów NoSQL faworyzuje proste wzorce dostępu po kluczu. Świetnie sprawdzają się przy niskich opóźnieniach i dużej przepustowości, gdy zapytania są przewidywalne, a dane modelowane pod kątem dostępu, a nie dowolnych zapytań.
Opóźnienia w klastrach NoSQL mogą być bardzo niskie, ale zapytania między partycjami, indeksy poboczne i operacje wielodokumentowe mogą być wolniejsze lub ograniczone. Operacyjnie skalowanie NoSQL często oznacza więcej pracy nad klastrem, podczas gdy skalowanie SQL zwykle wymaga mocniejszego sprzętu i starannego indeksowania na mniejszej liczbie węzłów.
Kiedy zwykle wybrać bazę SQL
Systemy transakcyjne i krytyczne dla biznesu
Bazy relacyjne błyszczą, gdy potrzebujesz niezawodnego OLTP (online transaction processing):
- systemy finansowe (płatności, księgowość, trading)
- zarządzanie zamówieniami i zapasami
- ERP, CRM i systemy rozliczeniowe
Te systemy polegają na transakcjach ACID, ścisłej spójności i jasnym zachowaniu rollbacku. Jeśli transfer nie może nigdy podwójnie obciążyć konta lub stracić środków między dwoma rachunkami, baza SQL zwykle jest bezpieczniejsza niż większość rozwiązań NoSQL.
Ustrukturyzowane dane i złożone relacje
Jeśli model danych jest dobrze zdefiniowany i stabilny, a encje są mocno powiązane, baza relacyjna jest naturalnym wyborem. Przykłady:
- Klienci, zamówienia, faktury, produkty i wysyłki
- Rekordy medyczne z pacjentami, wizytami, receptami i wynikami badań
Normalizowane schematy SQL, klucze obce i joiny ułatwiają wymuszanie integralności i zapytania o złożone relacje bez duplikowania danych.
Analityka na dobrze zdefiniowanych schematach
Do raportów i BI nad uporządkowanymi danymi (schematy gwiazdy/śnieżynki, data mart) bazy SQL i hurtownie kompatybilne z SQL są zwykle preferowane. Analitycy znają SQL, a istniejące narzędzia (dashboardy, ETL, governance) integrują się bezpośrednio z systemami relacyjnymi.
Dojrzałość, umiejętności i zgodność
Dyskusja o relacyjnych vs nierelacyjnych bazach często pomija dojrzałość operacyjną. Bazy SQL oferują:
- długo udowodnioną niezawodność i narzędzia
- dużą pulę inżynierów, DBA i analityków znających SQL
- funkcje audytu, kontroli dostępu, szyfrowania i kopii zapasowych spełniające wymagania regulacyjne (finanse, administracja, opieka zdrowotna)
Gdy audyty, certyfikacje lub ekspozycja prawna są istotne, baza SQL bywa łatwiejszym i lepiej uzasadnialnym wyborem w kompromisie SQL vs NoSQL.
Kiedy zwykle wybrać bazę NoSQL
Bazy NoSQL są często lepsze, gdy skalowalność, elastyczność i ciągła dostępność są ważniejsze niż złożone joiny i ścisłe gwarancje transakcyjne.
Systemy o dużym ruchu i skali
Jeśli spodziewasz się ogromnego wolumenu zapisów, nieprzewidywalnych skoków ruchu lub danych rosnących do terabajtów i dalej, systemy NoSQL (klucz–wartość, szerokokolumnowe) są zwykle łatwiejsze do poziomego skalowania. Sharding i replikacja są często wbudowane, więc możesz dodawać pojemność przez doklejanie węzłów zamiast ciągłego rozbudowywania jednego serwera.
Typowe zastosowania:
- ruchliwe aplikacje web i mobilne
- backendy do gier i rankingi w czasie rzeczywistym
- ad tech, silniki rekomendacji, personalizacja
Elastyczność przy szybkim rozwoju produktu
Gdy model danych często się zmienia, elastyczny lub bezschematowy projekt ma wartość. Bazy dokumentowe pozwalają rozwijać pola i struktury bez migracji przy każdej zmianie.
Dobrze sprawdza się to w:
- systemach zarządzania treścią i katalogach produktów
- profilach użytkowników i preferencjach
- feedach aktywności i logach zdarzeń, gdzie pojawiają się nowe typy zdarzeń
IoT, cache i dane time‑series
NoSQL dobrze radzi sobie z append‑heavy i czasowo uporządkowanymi obciążeniami:
- telemetryka IoT i dane z czujników
- metryki, logowanie, monitoring
- warstwy cache (sesje, tokeny, feature flags)
Bazy klucz–wartość i dedykowane time‑series DB są zoptymalizowane pod bardzo szybkie zapisy i proste odczyty.
Dystrybucja globalna i zawsze‑dostępne doświadczenia
Wiele platform NoSQL priorytetuje replikację geo‑rozproszoną i zapisy wieloregionalne, pozwalając użytkownikom na odczyt i zapis z niskimi opóźnieniami lokalnie. To przydatne, gdy:
- aplikacja musi być dostępna podczas regionalnych awarii
- użytkownicy w różnych kontynentach oczekują lokalnych czasów odpowiedzi
Kosztem jest akceptacja spójności ostatecznej zamiast ścisłych semantyk ACID między regionami.
Kompromisy i ograniczenia
Wybierając NoSQL zgadzasz się często na utratę niektórych cech znanych z SQL:
- słabsza lub konfigurowalna spójność; nie każdy odczyt zobaczy najnowszy zapis
- ograniczone zapytania ad‑hoc i joiny; projektujesz dane pod kątem wzorców dostępu z góry
- większa odpowiedzialność warstwy aplikacji za zapewnienie integralności danych
Gdy te kompromisy są akceptowalne, NoSQL może dostarczyć lepszą skalowalność, elastyczność i zasięg globalny niż tradycyjna baza relacyjna.
Wzorce hybrydowe i poliglotyczna persistencja
Poliglotyczna persistencja oznacza świadome użycie wielu technologii bazodanowych w tym samym systemie — wybierasz najlepsze narzędzie dla danego zadania zamiast upychać wszystko w jednym store.
Typowa hybrydowa konfiguracja
Częsty wzorzec:
- SQL dla danych krytycznych: zamówienia, płatności, profile użytkowników, konfiguracja — tam potrzebujesz spójności, transakcji i bogatych zapytań.
- NoSQL dla sesji i cache: magazyn klucz–wartość (np. w stylu Redis) dla sesji użytkownika, limitów, flag funkcji czy gorących agregatów; czasem baza dokumentowa dla preferencji i feedów aktywności.
To utrzymuje „system of record” w relacyjnej bazie, a odciążone, lotne lub intensywnie odczytywane obciążenia obsługuje NoSQL.
Łączenie różnych typów NoSQL
Możesz łączyć różne NoSQL:
- Klucz–wartość dla cache i sesji.
- Dokument dla treści i danych użytkowników o zmiennych strukturach.
- Szerokokolumnowe / time‑series dla metryk i logów.
- Silnik wyszukiwania (np. oparty na Lucene) dla pełnotekstowych zapytań i analiz.
Celem jest dopasowanie każdego magazynu danych do konkretnego wzorca dostępu: szybkie odczyty, agregaty, wyszukiwanie lub odczyty czasowe.
Integracja i koszty operacyjne
Architektury hybrydowe opierają się na punktach integracji:
- ETL lub streaming do synchronizacji danych między magazynami lub budowy modeli odczytowych.
- Strumienie zdarzeń do propagowania zmian (np. z SQL do cache lub magazynów analitycznych).
- API, które ukrywają szczegóły przechowywania, aby serwisy nie musiały znać miejsca przechowywania danych.
Kompromis to koszt operacyjny: więcej technologii do poznania, monitorowania, zabezpieczenia, backupu i debugowania. Poliglotyczna persistencja najlepiej sprawdza się, gdy każdy dodatkowy magazyn rozwiązuje konkretny, mierzalny problem — nie tylko dlatego, że wygląda nowocześnie.
Jak wybrać między SQL a NoSQL dla projektu
Wybór to dopasowanie wzorców danych i dostępu do odpowiedniego narzędzia, a nie podążanie za modą.
1. Zacznij od danych i relacji
Zadaj sobie pytania:
- Czy moje dane są naturalnie tabelaryczne z jasnymi encjami (użytkownicy, zamówienia, faktury)?
- Czy mam dużo joinów i bogatych relacji (1→N, N→M)?
Jeśli tak, baza relacyjna jest zwykle domyślnym wyborem. Jeśli dane mają formę dokumentu, są zagnieżdżone lub różnią się między rekordami, model dokumentowy lub inny NoSQL może być lepszy.
2. Wyjaśnij potrzeby spójności i transakcji
- Czy potrzebuję transakcji ACID obejmujących wiele wierszy/tabel (np. płatności, zapasy)?
- Czy akceptuję, że niektóre odczyty mogą być lekko przestarzałe?
Ścisła spójność i skomplikowane transakcje zwykle faworyzują SQL. Wysoka przepustowość zapisów z luźniejszą spójnością może skłaniać do NoSQL.
3. Zrozum skalę i wydajność
- Jaki jest spodziewany wolumen odczytów/zapisów teraz i za 2–3 lata?
- Czy potrzebuję niskich opóźnień globalnie?
Większość projektów poradzi sobie z SQL przy dobrym indeksowaniu i sprzęcie. Jeśli przewidujesz ogromną skalę z prostymi wzorcami dostępu (odczyty po kluczu, time‑series, logi), niektóre systemy NoSQL mogą być bardziej ekonomiczne.
4. Wzorce zapytań i raportowanie
- Czy potrzebuję zapytań ad‑hoc, joinów i elastycznego raportowania?
- Kto będzie zapytywał dane (tylko inżynierowie czy też analitycy biznesowi)?
SQL jest lepszy dla analiz, narzędzi BI i eksploracji ad‑hoc. Wiele baz NoSQL optymalizuje przewidywalne ścieżki dostępu i utrudnia nowe typy zapytań.
5. Umiejętności zespołu, narzędzia i hosting
- Co zespół już potrafi: SQL, projektowanie schematów czy konkretne systemy NoSQL?
- Co jest dostępne w środowisku hostingowym (zarządzany PostgreSQL/MySQL, MongoDB, DynamoDB itd.)?
- Które ekosystemy mają lepsze biblioteki, sterowniki i monitoring dla naszego stosu?
Wybieraj technologie, które zespół umie obsługiwać, szczególnie w produkcji.
6. Koszty i złożoność operacyjna
- Czy stać nas na zarządzanie rozproszonymi klastrami NoSQL, czy wystarczy zarządzana instancja SQL?
- Jak porównują się koszty przechowywania i operacji dla przewidywanego obciążenia?
Pojedyncza zarządzana baza SQL często jest tańsza i prostsza, dopóki naprawdę jej nie przerosną.
7. Testuj na realistycznych obciążeniach
Zanim zdecydujesz:
- Zamodeluj reprezentatywną część danych w SQL i w wybranym modelu NoSQL.
- Zaimplementuj krytyczne zapytania i zapisy.
- Przeprowadź testy obciążeniowe z realistycznymi wolumenami.
- Mierz opóźnienia, przepustowość, wskaźniki błędów i nakład operacyjny.
Nie opieraj decyzji na przypuszczeniach. Dla wielu projektów zaczęcie od SQL jest najbezpieczniejsze, z opcją dodania komponentów NoSQL tam, gdzie jest to uzasadnione.
Powszechne mity o bazach SQL i NoSQL
Mit 1: NoSQL zastąpi SQL
NoSQL nie pojawił się po to, by zabić bazy relacyjne — pojawił się, by je uzupełnić.
Bazy relacyjne nadal dominują jako systemy zapisu: finanse, HR, ERP, magazyny i wszędzie tam, gdzie transakcje i spójność mają znaczenie. NoSQL błyszczy tam, gdzie elastyczne schematy, ogromny wolumen zapisów lub globalne odczyty są ważniejsze niż złożone joiny i gwarancje ACID.
W praktyce organizacje używają obu podejść, wybierając narzędzie do danego zadania.
Mit 2: SQL nie da się skalować poziomo
Relacyjne bazy historycznie skalowały się przez zwiększanie mocy pojedynczej maszyny, ale nowoczesne silniki oferują:
- repliki do odczytów
- sharding/partycyjowanie
- rozproszone SQL (systemy typu NewSQL)
Skalowanie relacyjnego systemu może być bardziej angażujące niż dodanie węzłów do klastra NoSQL, ale jest możliwe przy odpowiednim zaprojektowaniu i narzędziach.
Mit 3: NoSQL nie ma schematów ani zasad
„Bezschematowość” oznacza często, że schemat jest wymuszany przez aplikację, nie przez bazę.
Bazy dokumentowe, klucz–wartość i szerokokolumnowe wciąż mają strukturę. Pozwalają jednak ewoluować ją per rekord lub kolekcję. Bez jasnych kontraktów danych, walidacji i zarządzania szybko pojawi się niespójność.
Mit 4: Jeden typ zawsze jest szybszy
Wydajność zależy bardziej od modelowania danych, indeksów i wzorców zapytań niż od samej kategorii.
Źle zaindeksowana kolekcja NoSQL będzie wolniejsza niż dobrze wyczyszczona tabela relacyjna w wielu zapytaniach. Analogicznie, relacyjny schemat zignorowany pod kątem wzorców dostępu będzie gorszy niż zoptymalizowany model NoSQL.
Mit 5: SQL jest zawsze bezpieczniejszy i bardziej niezawodny niż NoSQL
Wiele baz NoSQL wspiera trwałość, szyfrowanie, audyt i kontrolę dostępu. Z drugiej strony źle skonfigurowana baza relacyjna może być niebezpieczna. Bezpieczeństwo i niezawodność to cechy konkretnej implementacji, konfiguracji i dojrzałości operacyjnej — nie samej kategorii.
Strategie migracji i współistnienia
Zespoły zwykle przechodzą między SQL a NoSQL z dwóch powodów: skalowania i elastyczności. Produkt o dużym ruchu może zachować relacyjną bazę jako zaufany system zapisu, a następnie wprowadzić NoSQL do obsługi odczytów na dużą skalę lub nowych funkcji o elastycznym schemacie.
Wzorce migracji
Ryzykowna jest migracja typu big‑bang. Bezpieczniejsze opcje:
- Migracja inkrementalna: wyodrębnij jeden bounded context (np. katalog produktów) i przenieś tylko te dane i ruch do NoSQL, reszta zostaje w SQL.
- Dual writes: przez pewien czas serwisy zapisują do obu baz. Kiedy nowy magazyn sprawdzi się w produkcji, stopniowo odłączasz stary.
- Pipeline’y synchronizujące: jedna baza jako źródło, a zmiany przesyłane do drugiej za pomocą CDC, kolejek wiadomości lub zadań ETL.
Pułapki schematów i modelu
Przenosząc dane z SQL do NoSQL zespoły często próbują odwzorować tabele jako dokumenty lub pary klucz–wartość. To prowadzi do:
- nadmiernej normalizacji w NoSQL i zbyt wielu joinów w warstwie aplikacji
- dokumentów rosnących poza kontrolę
Projektuj nowy model wokół rzeczywistych wzorców dostępu, a nie kopiuj struktury tabeli 1:1.
Współistnienie i zabezpieczenia
Częsty wzorzec: SQL jako autorytatywne źródło (billing, konta) i NoSQL jako widoki odczytowe (feed, wyszukiwanie, cache). Niezależnie od wyboru inwestuj w:
- powtarzalne backfille i strategie rollbacku
- walidację danych między magazynami
- testy obciążeniowe odzwierciedlające rzeczywiste wzorce zapytań
To pozwala, by migracje SQL vs NoSQL były kontrolowane, a nie nieodwracalne.
Podsumowanie i praktyczne rekomendacje
SQL i NoSQL różnią się głównie w czterech obszarach:
- Model danych – SQL używa tabel, wierszy i dobrze zdefiniowanych schematów; NoSQL stawia na dokumenty, pary klucz–wartość, szerokie kolumny lub grafy z większą elastycznością.
- Zapytania – SQL oferuje jeden, ekspresyjny język zapytań; NoSQL zwykle używa specyficznych API lub składni.
- Spójność i transakcje – SQL koncentruje się na transakcjach ACID i silnej spójności; wiele systemów NoSQL oddaje część tych gwarancji na rzecz dostępności, skali i niskich opóźnień.
- Skalowanie – SQL tradycyjnie skalował się wertykalnie (i obecnie też poziomo przez klastrowanie); NoSQL często projektowany jest od początku do shardingu i replikacji po wielu węzłach.
Żadna kategoria nie jest uniwersalnie lepsza. "Właściwy" wybór zależy od rzeczywistych wymagań, nie od modnych haseł.
Jak wybrać w praktyce
-
Spisz wymagania:
- Struktura danych i relacje
- Wzorce zapytań i potrzeby raportowe
- Oczekiwania spójności vs dostępności
- Ruch szczytowy, rozmiar danych i cele opóźnień
- Umiejętności zespołu i dostępne narzędzia
-
Domyślnie sensownie:
- Preferuj SQL do systemów transakcyjnych, analityki i stabilnych, ustrukturyzowanych danych.
- Rozważ NoSQL dla bardzo dużej skali zapisów, danych półstrukturalnych lub szybko zmieniających się modeli.
-
Zacznij mało i mierz:
- Zbuduj pionowy wycinek (proof‑of‑concept).
- Zbieraj metryki: opóźnienia zapytań, przepustowość, wskaźniki błędów, wysiłek operacyjny.
- Iteruj nad schematem, indeksami i partycjonowaniem na podstawie rzeczywistego użycia.
-
Pozostań otwarty na hybrydy:
- Używaj wielu baz, jeśli różne części systemu mają odmienne potrzeby.
- Dokumentuj decyzje, kompromisy i wzorce w wewnętrznej bazie wiedzy (np. pod ścieżką
/docs/architecture/datastores).
Dla pogłębienia tematu rozbuduj ten przegląd o wewnętrzne standardy, checklisty migracyjne i dalsze lektury w firmowym podręczniku inżynierii lub na stronie /blog.
Często zadawane pytania
Jaka jest podstawowa różnica między bazami SQL a NoSQL?
SQL (relacyjne) bazy danych:
- Używają tabel z wierszami i kolumnami.
- Wymagają stałego schematu (zdefiniowane kolumny, typy, ograniczenia).
- Korzystają ze standardowego języka zapytań SQL.
- Kładą nacisk na transakcje ACID i silną spójność.
NoSQL (nierelacyjne) bazy danych:
- Stosują elastyczne modele (dokumenty, pary klucz–wartość, szerokie kolumny, grafy).
- Często pozwalają na schematy elastyczne lub brak schematu.
- Używają specyficznych dla bazy API lub DSL do zapytań.
- Często kosztem spójności oferują lepszą skalowalność i dostępność.
Kiedy zazwyczaj lepiej wybrać bazę SQL?
Użyj bazy SQL, gdy:
- Dane są dobrze ustrukturyzowane i relacyjne (użytkownicy, zamówienia, faktury).
- Potrzebujesz transakcji ACID obejmujących wiele wierszy lub tabel.
- Poprawność i spójność są ważniejsze niż surowa przepustowość.
- Spodziewasz się wielu zapytań ad‑hoc, joinów i potrzeb raportowania.
- Zgodność, audyt i długoterminowa utrzymywalność są krytyczne.
Dla większości nowych systemów będących systemem zapisu danych, SQL jest rozsądnym wyborem domyślnym.
Kiedy zazwyczaj lepsza jest baza NoSQL?
NoSQL sprawdza się najlepiej, gdy:
- Musisz skalować zapisy i przechowywanie poziomo po wielu węzłach.
- Dane są półustrukturalne, zagnieżdżone lub często zmieniają kształt.
- Wzorce dostępu są znane i można je modelować jako odczyty po kluczu lub dokumentach.
- Tymczasowe niespójności są akceptowalne (np. kanały, logi, widoki analityczne).
- Obsługujesz telemetrykę IoT, dane time‑series, cache lub treści generowane przez użytkowników w dużej skali.
Jak różnią się schematy i modelowanie danych między SQL a NoSQL?
Bazy SQL:
- Używają z góry zdefiniowanych schematów; każdy wiersz musi pasować do definicji tabeli.
- Zachęcają do normalizacji, by zmniejszyć duplikację i wymusić integralność.
- Korzystają z kluczy obcych i ograniczeń do zarządzania relacjami.
Bazy NoSQL:
- Pozwalają dokumentom/rekordom mieć różne pola w tej samej kolekcji.
- Często promują denormalizację i osadzanie powiązanych danych.
- Więcej reguł spoczywa w warstwie aplikacji.
Oznacza to, że kontrola schematu przesuwa się z bazy (SQL) do aplikacji (NoSQL).
Jak SQL i NoSQL różnią się pod względem spójności i transakcji?
Bazy SQL:
- Koncentrują się na transakcjach ACID ze silną spójnością.
- Są idealne, gdy każdy odczyt musi widzieć aktualny, poprawny stan.
Wiele systemów NoSQL:
- Stawia na dostępność i tolerancję partycji.
- Stosuje podejście BASE i spójność ostateczną: repliki zbiegną do tej samej wartości w czasie.
- Może oferować konfigurowalną spójność dla poszczególnych operacji lub zakresów kluczy.
Wybierz SQL, gdy przestarzałe odczyty są niebezpieczne; wybierz NoSQL, gdy krótkotrwała niespójność jest akceptowalna w zamian za skalę i dostępność.
Jak SQL i NoSQL zwykle się skalują?
Bazy SQL zazwyczaj:
- Zaczynają od skalowania wertykalnego (mocniejszy serwer).
- Dodają replikę do odczytów, by rozładować główny węzeł.
- Czasem używają sharding/partitioningu lub rozproszonych SQL (NewSQL) do skalowania poziomego.
Bazy NoSQL zazwyczaj:
- Są projektowane od początku do skalowania poziomego.
- Fragmentują i replikują dane po wielu węzłach.
- Ułatwiają dodawanie mocy przez dołączanie kolejnych maszyn.
Kosztem jest większa złożoność operacyjna w NoSQL, podczas gdy SQL wcześniej napotka limity pojedynczego węzła.
Czy można używać SQL i NoSQL razem w tym samym systemie?
Tak. Poliglotyczna persistencja jest powszechna:
- Użyj SQL jako systemu zapisu (płatności, konta, kluczowe encje).
- Dodaj NoSQL dla sesji, cache, kanałów, logów lub wyszukiwania.
Wzorce integracji obejmują:
- Change data capture lub strumienie zdarzeń z SQL do NoSQL.
- Okresowe zadania ETL budujące widoki zoptymalizowane pod odczyt.
- Usługi, które ukrywają szczegóły przechowywania za stabilnym API.
Kluczowe: dodawaj kolejne datastore tylko wtedy, gdy rozwiązują konkretny problem.
Jak podejść do migracji między SQL a NoSQL?
Aby przeprowadzić migrację bezpiecznie:
- Wybierz ograniczony kontekst domenowy (np. katalog produktów) do migracji.
- Projektuj dane wokół nowych wzorców dostępu, nie kopiuj tabel 1:1.
- Użyj dual writes lub CDC, by tymczasowo zapisywać w obu systemach.
- Waliduj dane między magazynami i zaplanuj powtarzalne backfille.
- Przenoś ruch stopniowo, mając przygotowane rollbacky.
Unikaj „big‑bang” migracji; preferuj inkrementalne, monitorowane kroki.
Jakie czynniki powinienem ocenić przy wyborze między SQL a NoSQL?
Rozważ:
- Strukturę danych: tabelaryczna z jasnymi relacjami vs elastyczne dokumenty/wydarzenia.
- Wymogi spójności: ścisłe ACID vs akceptowalna stęchłość odczytów.
- Skalę i opóźnienia: przewidywany wolumen zapisów, rozmiar danych, użytkownicy globalni.
- Wzorce zapytań: zapytania ad‑hoc i analizy vs przewidywalne odczyty po kluczu.
- Umiejętności zespołu i narzędzia: co zespół potrafi utrzymywać.
- Koszty i operacje: opcje zarządzane kontra prowadzenie rozproszonych klastrów.
Wdroż prototypy krytycznych przepływów i mierz wydajność, zanim podejmiesz decyzję.
Jakie są powszechne mity dotyczące baz SQL i NoSQL?
Typowe mity:
- "NoSQL zastąpi SQL" – w praktyce uzupełniają się nawzajem.
- "SQL nie da się skalować poziomo" – nowoczesne systemy obsługują repliki, sharding i rozproszone SQL.
- "NoSQL nie ma schematu" – schemat istnieje, tylko jest wymuszany częściej w aplikacji.
- "Jeden typ zawsze jest szybszy" – wydajność zależy od modelowania danych, indeksów i wzorców zapytań.
Zamiast wierzyć w kategorie, oceniaj konkretne produkty i architektury.