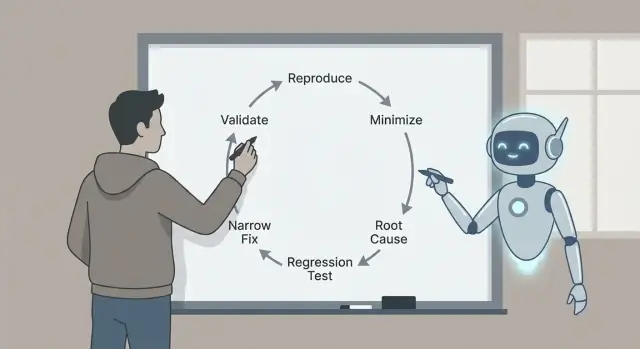
Co to jest triage błędów i dlaczego ta pętla ma znaczenie
Błędy wydają się losowe, gdy każde zgłoszenie zamienia się w jednorazową zagadkę. Grzebiesz w kodzie, próbujesz kilka pomysłów i masz nadzieję, że problem zniknie. Czasem znika, ale niewiele się uczysz i ten sam problem pojawia się znowu w innej formie.
Triage błędów to przeciwieństwo. To szybki sposób na zmniejszenie niepewności. Celem nie jest naprawić wszystko od razu. Celem jest zamienić niejasne zgłoszenie w jasne, testowalne stwierdzenie, a potem wprowadzić najmniejszą zmianę, która udowodni, że to stwierdzenie jest już nieprawdziwe.
Dlatego ta pętla ma znaczenie: odtwórz, zminimalizuj, zidentyfikuj prawdopodobne przyczyny z dowodami, dodaj test regresyjny, zaimplementuj wąską poprawkę i zwaliduj. Każdy krok usuwa konkretny rodzaj zgadywania. Pomijaj kroki, a często zapłacisz za to później większymi poprawkami, skutkami ubocznymi lub „naprawionymi” błędami, które nigdy nie były naprawdę naprawione.
Oto realistyczny przykład. Użytkownik mówi: „Przycisk Zapisz czasami nic nie robi.” Bez pętli możesz przeszukiwać kod UI i zmieniać timingi, stan lub wywołania sieciowe. Z pętlą najpierw zamieniasz „czasami” na „za każdym razem, w tych dokładnych warunkach”, np.: „Po edycji tytułu, a potem szybkim przełączeniu zakładek, Zapisz pozostaje wyłączony.” To jedno zdanie to już postęp.
Claude Code może przyspieszyć część myślową: zamienianie zgłoszeń w precyzyjne hipotezy, sugerowanie, gdzie szukać, i proponowanie minimalnego testu, który powinien nie przejść. Szczególnie przydatne jest skanowanie kodu, logów i ostatnich diffów, by szybko wygenerować prawdopodobne wyjaśnienia.
Musisz jednak sam weryfikować, co ma znaczenie. Potwierdź, że błąd jest realny w twoim środowisku. Preferuj dowody (logi, trace’y, nieudane testy) nad dobrze brzmiącą historią. Trzymaj poprawkę jak najmniejszą, udowodnij ją testem regresyjnym i zwaliduj jasnymi checkami, żeby nie wymienić jednego błędu na inny.
Zysk to mała, bezpieczna poprawka, którą możesz wytłumaczyć, obronić i utrzymać od regresji.
Przygotuj przestrzeń do triage (przed dotknięciem kodu)
Dobre poprawki zaczynają się od czystego workspace'u i jednego, jasnego stwierdzenia problemu. Zanim zapytasz Claude’a, wybierz jedno zgłoszenie i przepisz je jako:
„Kiedy robię X, oczekuję Y, ale otrzymuję Z.”
Jeśli nie potrafisz napisać tego zdania, nie masz jeszcze błędu. Masz zagadkę.
Zbierz podstawowe informacje z góry, by nie wracać do nich potem. Te szczegóły sprawiają, że sugestie są testowalne zamiast niejasnych: wersja aplikacji lub commit (i czy to lokalnie, na stagingu, czy w produkcji), szczegóły środowiska (OS, przeglądarka/urządzenie, feature flagi, region), dokładne wejścia (pola formularza, payload API, akcje użytkownika), kto to widzi (wszyscy, jakaś rola, pojedyncze konto/tenant) oraz co oznacza „oczekiwane” (tekst, stan UI, kod statusu, reguła biznesowa).
Zachowaj dowody, póki są świeże. Jeden timestamp może zaoszczędzić godziny. Zrób zrzut logów wokół zdarzenia (klient i serwer, jeśli możliwe), zrzut ekranu lub krótkie nagranie, ID żądania lub trace ID, dokładne timestampt'y (z strefą czasową) i najmniejszy fragment danych, który wywołuje problem.
Przykład: aplikacja React wygenerowana przez Koder.ai pokazuje „Płatność zakończona sukcesem”, ale zamówienie pozostaje „Pending”. Zapisz rolę użytkownika, dokładne ID zamówienia, ciało odpowiedzi API i linie logów serwera dla tego request ID. Teraz możesz poprosić Claude’a, by skupił się na jednym flow zamiast na ogólnikach.
Na koniec ustal regułę zatrzymania. Zdecyduj, co będzie oznaczać, że jest naprawione zanim zaczniesz kodować: konkretny test przechodzący, zmiana stanu UI, błąd niepojawiający się w logach, plus krótka checklista walidacyjna, którą uruchomisz za każdym razem. To uchroni cię przed „naprawą” objawu i wprowadzeniem nowego błędu.
Zamień zgłoszenie błędu w precyzyjne pytanie dla Claude
Nieporządne zgłoszenie zwykle miesza fakty, przypuszczenia i frustrację. Zanim poprosisz o pomoc, przekształć je w zwięzłe pytanie, na które Claude może odpowiedzieć z dowodami.
Zacznij od jednosekundowego streszczenia, które nazywa funkcję i usterkę. Dobre: „Zapis szkicu czasami usuwa tytuł na mobile.” Niedobre: „Szkice są zepsute.” To zdanie staje się kotwicą dla całego wątku triage.
Potem oddziel to, co zobaczyłeś, od tego, czego oczekiwałeś. Trzymaj się nudnych i konkretnych faktów: dokładny przycisk, który kliknąłeś, komunikat na ekranie, linia logu, timestamp, urządzenie, przeglądarka, branch, commit. Jeśli tego nie masz, powiedz to wprost.
Prosta struktura, którą możesz wkleić:
- Streszczenie (jedno zdanie)
- Obserwowane zachowanie (co się stało, wliczając tekst błędu)
- Oczekiwane zachowanie (co powinno się zdarzyć)
- Kroki reprodukcji (ponumerowane, najmniejszy zestaw, który znasz)
- Środowisko (wersja aplikacji, urządzenie, OS, przeglądarka, flagi konfiguracyjne)
Jeśli brakuje szczegółów, zadawaj je jako pytania tak/nie, aby ludzie mogli szybko odpowiedzieć: Dzieje się to na świeżym koncie? Tylko na mobile? Tylko po odświeżeniu? Czy zaczęło się po ostatnim wydaniu? Da się powtórzyć w incognito?
Claude jest też użyteczny jako „czyściciel zgłoszeń”. Wklej oryginalne zgłoszenie (wraz z tekstem skopiowanym ze screenshotów, logów i fragmentów czatu), a potem poproś:
„Przepisz to jako ustrukturyzowaną checklistę. Zaznacz sprzeczności. Wypisz 5 najważniejszych brakujących faktów jako pytania tak/nie. Nie zgaduj przyczyn jeszcze.”
Jeśli kolega mówi „To się psuje losowo”, naciskaj, by to stało się testowalne: „Pada 2/10 razy na iPhone 14, iOS 17.2, gdy dwukrotnie szybko stuknę Zapisz.” Teraz możesz odtworzyć to celowo.
Krok 1 - Odtwórz błąd niezawodnie
Jeśli nie potrafisz wywołać błędu na żądanie, każdy kolejny krok to zgadywanie.
Zacznij od odtworzenia go w najmniejszym środowisku, które nadal pokazuje problem: lokalny build, minimalny branch, mały dataset i jak najmniej usług włączonych.
Zapisz dokładne kroki, aby ktoś inny mógł je wykonać bez pytań. Zrób to kopiowalne: polecenia, ID i przykładowe payloady powinny być wklejane dokładnie tak, jak użyłeś.
Prosty szablon zapisu:
- Setup: branch/commit, flagi konfiguracyjne, stan bazy danych (pusta, seeded, kopia produkcji)
- Kroki: ponumerowane akcje z dokładnymi danymi wejściowymi
- Oczekiwane vs rzeczywiste: co miało się stać, co się stało zamiast tego
- Dowody: tekst błędu, zrzuty ekranu, timestampt'y, request ID
- Częstotliwość: zawsze, czasami, tylko pierwszy raz, tylko po odświeżeniu
Częstotliwość zmienia strategię. Błędy „zawsze” są świetne do szybkiej iteracji. Błędy „czasami” często wskazują na timingi, cache, race conditions lub ukryty stan.
Gdy masz notatki reprodukcji, poproś Claude’a o szybkie sondy, które zmniejszą niepewność bez przepisywania aplikacji. Dobre sondy są małe: jedna ukierunkowana linia logu wokół punktu awarii (wejścia, wyjścia, kluczowy stan), flaga debug dla jednego komponentu, sposób wymuszenia deterministycznego zachowania (ustalone ziarno losowości, stały czas, pojedynczy worker), maleńki seed danych, który powoduje problem, lub jedno żądanie/odpowiedź do odtworzenia.
Przykład: flow rejestracji pada „czasami”. Claude może zasugerować logowanie wygenerowanego ID użytkownika, wyniku normalizacji emaila i szczegółów błędu unique constraint, a potem ponowne wysłanie tego samego payloadu 10 razy. Jeśli awaria występuje tylko przy pierwszym uruchomieniu po deployu, to silna wskazówka, by sprawdzić migracje, warmup cache’a lub brakujące dane seed.
Krok 2 - Zminimalizuj do małego, powtarzalnego case'u
Reprodukuj problemy mobilne
Odtwórz błędy występujące tylko na mobilnych w Flutter i zweryfikuj dokładną sekwencję stuknięć.
Dobre odtworzenie jest przydatne. Minimalne odtworzenie jest potężne. Przyspiesza zrozumienie, ułatwia debug i zmniejsza ryzyko „naprawy” przez przypadek.
Usuń wszystko, co nie jest wymagane. Jeśli błąd występuje po długim flow UI, znajdź najkrótszą ścieżkę, która go nadal wywołuje. Usuń opcjonalne ekrany, flagi funkcji i niepowiązane integracje, aż błąd zniknie (usunąłeś coś istotnego) lub pozostanie (to hałas).
Potem zmniejsz dane. Jeśli błąd wymaga dużego payloadu, spróbuj najmniejszego payloadu, który nadal łamie. Jeśli wymaga listy 500 elementów, sprawdź, czy 5 pada, potem 2, potem 1. Usuwaj pola jedno po drugim. Celem jest jak najmniej poruszających się części, które nadal reprodukują błąd.
Praktyczna metoda to „usuń połowę i przetestuj”:
- Podziel kroki na połowy i sprawdź, czy bug nadal zachodzi.
- Jeśli tak, trzymaj tę połowę i tnij dalej.
- Jeśli nie, przywróć połowę tego, co usunąłeś, i tnij inaczej.
- Powtarzaj, aż nie będziesz mógł nic usunąć bez utraty błędu.
Przykład: strona checkout crashuje „czasami” przy stosowaniu kuponu. Odkrywasz, że pada tylko gdy koszyk ma przynajmniej jeden przedmiot z rabatem, kupon ma małe litery, a wysyłka ustawiona jest na „odbiór”. To twój minimalny case: jeden zdyskontowany przedmiot, kupon z małymi literami, opcja odbioru.
Gdy minimalny case jest jasny, poproś Claude’a o zbudowanie małego scaffoldu repro: minimalny test wywołujący wadliwą funkcję z najmniejszym wejściem, krótki skrypt uderzający jeden endpoint z zredukowanym payloadem lub mały test UI, który odwiedza jedną trasę i wykonuje jedną akcję.
Krok 3 - Zidentyfikuj prawdopodobne root-cause (z dowodami)
Gdy możesz odtworzyć problem i masz mały test case, przestań zgadywać. Celem jest dojść do krótkiej listy prawdopodobnych przyczyn, a potem dowieść lub obalić każdą z nich.
Użyteczne jest trzymać listę do trzech hipotez. Jeśli masz więcej, twój test case jest prawdopodobnie nadal za duży lub obserwacje zbyt niejasne.
Mapuj symptomy na komponenty
Przetłumacz to, co widzisz, na to, gdzie to mogło się wydarzyć. Symptom w UI nie zawsze oznacza bug w UI.
Przykład: strona React pokazuje toast „Zapisano”, ale rekord później znika. To może wskazywać na (1) stan UI, (2) zachowanie API lub (3) ścieżkę zapisu do bazy.
Zbuduj dowody dla każdej hipotezy
Poproś Claude’a, by wyjaśnił prawdopodobne tryby awarii prostym językiem, a potem zapytaj, jaki dowód potwierdziłby każdą z nich. Celem jest zamienić „może” w „sprawdź tę konkretną rzecz”.
Trzy typowe hipotezy i dowody do zebrania:
- Niezgodność UI/stanu: klient aktualizuje lokalny stan przed potwierdzeniem serwera. Dowód: zrób snapshot stanu przed i po akcji i porównaj go z rzeczywistą odpowiedzią API.
- Krawędź API: handler zwraca 200, ale cicho odrzuca pracę (walidacja, parsowanie ID, feature flag). Dowód: dodaj logi request/response z correlation ID i zweryfikuj, że handler doszedł do wywołania zapisu z oczekiwanymi argumentami.
- Błąd DB lub timing: transakcja się wycofuje, występuje konflikt, lub „read after write” jest serwowane z cache/replicy. Dowód: sprawdź zapytanie DB, liczbę zmienionych wierszy i kody błędów; loguj granice transakcji i zachowanie retry.
Trzymaj notatki zwięzłe: symptom, hipoteza, dowód, werdykt. Gdy jedna hipoteza pasuje do faktów, możesz zablokować test regresyjny i naprawić tylko to, co konieczne.
Krok 4 - Dodaj test regresyjny, który pada z właściwego powodu
Dobry test regresyjny to pas bezpieczeństwa. Udowadnia, że błąd istnieje i mówi, kiedy naprawdę go naprawiłeś.
Zacznij od wyboru najmniejszego testu, który odzwierciedla prawdziwą awarię. Jeśli błąd pojawia się tylko wtedy, gdy wiele części współpracuje, test jednostkowy może to przeoczyć.
Wybierz poziom testu, który pasuje do błędu
Użyj testu jednostkowego, gdy pojedyncza funkcja zwraca złą wartość. Użyj testu integracyjnego, gdy granica między częściami jest problemem (handler + baza albo UI + API). Użyj end-to-end tylko wtedy, gdy błąd zależy od pełnego flow użytkownika.
Zanim poprosisz Claude’a o napisanie czegokolwiek, przekształć zminimalizowany case w ścisłe oczekiwane zachowanie. Przykład: „Gdy użytkownik zapisuje pusty tytuł, API musi zwrócić 400 z wiadomością 'title required'.” Teraz test ma jasny cel.
Poproś Claude’a o szkic nieudanego testu jako pierwszy. Trzymaj setup minimalny i kopiuj tylko dane, które wywołują błąd. Nazwij test od doświadczenia użytkownika, nie od wewnętrznej funkcji.
Zweryfikuj szkic (nie ufaj mu w ciemno)
Szybko sprawdź:
- Czy pada na obecnym kodzie z zamierzonym powodem (nie z powodu brakującego fixture’a czy błędnego importu).
- Czy asercje są specyficzne (dokładny kod statusu, komunikat, renderowany tekst).
- Czy test pokrywa jeden błąd, nie pakiet zachowań.
- Nazwa testu skupiona na użytkowniku, np. „odrzuca pusty tytuł przy zapisie” zamiast „obsługuje walidację”.
Gdy test pada z właściwego powodu, jesteś gotowy wprowadzić wąską poprawkę z pewnością.
Krok 5 - Wdróż wąską poprawkę
Napraw, a potem eksportuj źródło
Zachowaj pełną kontrolę podczas szybkiego iterowania z pomocą czatu.
Mając mały repro i nieudany test regresyjny, opieraj się pokusie „posprzątania”. Celem jest zatrzymać błąd najmniejszą możliwą zmianą, która sprawia, że test przechodzi z właściwego powodu.
Dobra wąska poprawka zmienia jak najmniejszą powierzchnię. Jeśli błąd jest w jednej funkcji, napraw tę funkcję, nie cały moduł. Jeśli brakuje kontroli granicznej, dodaj ją na granicy, nie w całym łańcuchu wywołań.
Jeśli używasz Claude’a do pomocy, poproś o dwie opcje naprawy, potem porównaj je pod kątem zakresu i ryzyka. Przykład: jeśli formularz React crashuje przy pustym polu, możesz dostać:
- Opcja A: Dodaj straż w handlerze submit, która blokuje puste wejście i pokazuje błąd.
- Opcja B: Zrefaktoruj obsługę stanu tak, by pole nigdy nie było puste.
Opcja A jest zwykle wyborem triage: mniejsza, łatwiejsza do review i mniej ryzykowna.
Aby utrzymać poprawkę wąską, dotknij jak najmniej plików, preferuj lokalne poprawki nad refaktoryzacjami, dodaj straże i walidację tam, gdzie zła wartość wchodzi, i zachowaj zmianę zachowania jawną z jednym wyraźnym before/after. Zostaw komentarze tylko gdy powód nie jest oczywisty.
Konkretny przykład: endpoint API w Go panicuje, gdy opcjonalny parametr query jest brakujący. Wąska poprawka to obsłużyć pusty string na granicy handlera (parsuj z domyślną wartością albo zwróć 400 z jasnym komunikatem). Unikaj zmiany wspólnych utili parsowania, chyba że test regresyjny udowodni, że błąd leży w kodzie współdzielonym.
Po zmianie uruchom nieudany test i jeden lub dwa pobliskie testy. Jeśli twoja poprawka wymaga zmiany wielu niepowiązanych testów, to sygnał, że zmiana jest za szeroka.
Krok 6 - Zwaliduj poprawkę jasnymi checkami
Walidacja to moment, w którym łapiesz małe, łatwo przeoczone problemy: poprawkę, która przechodzi jeden test, ale psuje pobliski path, zmienia komunikat o błędzie lub dodaje wolne zapytanie.
Najpierw uruchom ponownie test regresyjny, który dodałeś. Jeśli przechodzi, uruchom najbliższe testy: te w tym samym pliku, tym samym module i wszystko, co obejmuje te same wejścia. Błędy często chowają się w helperach współdzielonych, parsowaniu, kontrolach granicznych lub cache’u, więc najbardziej istotne porażki zwykle pojawiają się blisko.
Następnie wykonaj krótką, ręczną weryfikację używając oryginalnych kroków zgłoszenia. Trzymaj to krótkie i konkretne: to samo środowisko, te same dane, ta sama sekwencja kliknięć lub wywołań API. Jeśli zgłoszenie było niejasne, przetestuj dokładny scenariusz, którego użyłeś do reprodukcji.
Prosta checklista walidacyjna
- Test regresyjny przechodzi, plus powiązane testy w tej samej okolicy.
- Ręczne kroki reprodukcji nie wywołują już błędu.
- Obsługa błędów nadal ma sens (komunikaty, kody statusu, retry).
- Przypadki brzegowe nadal działają (puste wejście, maks. rozmiary, nietypowe znaki).
- Brak oczywistych pogorszeń wydajności (dodatkowe pętle, dodatkowe wywołania, wolne zapytania).
Jeśli chcesz pomocy w utrzymaniu koncentracji, poproś Claude’a o krótki plan walidacji oparty na twojej zmianie i na scenariuszu, który padał. Podaj, jaki plik zmieniłeś, jakie zachowanie miałeś na myśli i co mogło zostać potencjalnie dotknięte. Najlepsze plany są krótkie i wykonalne: 5–8 checków, które możesz skończyć w minutach, każdy z jasnym pass/fail.
Na koniec zanotuj, co zwalidowałeś w PR lub notatkach: które testy uruchomiłeś, jakie kroki ręczne wykonałeś i jakie ograniczenia (np. „nie testowano na mobile”). To sprawia, że poprawka jest łatwiejsza do zaufania i ponownego przejrzenia później.
Częste błędy i pułapki (i jak ich unikać)
Testuj poprawki po stronie serwera
Prototypuj przepływy Go + PostgreSQL i odtwarzaj krawędziowe przypadki API z mniejszą frykcją.
Najszybszy sposób na zmarnowanie czasu to zaakceptować „naprawę” zanim potrafisz odtworzyć problem na żądanie. Jeśli nie możesz go powtórzyć niezawodnie, nie wiesz, co naprawdę się poprawiło.
Praktyczna zasada: nie pros o poprawki, dopóki nie będziesz potrafił opisać powtarzalnego setupu (dokładne kroki, wejścia, środowisko i jak wygląda „źle”). Jeśli zgłoszenie jest niejasne, spędź pierwsze minuty, zamieniając je w checklistę, którą możesz uruchomić dwa razy i uzyskać ten sam wynik.
Pułapki, które spowalniają
Naprawianie bez powtarzalnego przypadku. Wymagaj minimalnego skryptu „pada za każdym razem” lub zestawu kroków. Jeśli pada tylko „czasami”, zbieraj dane o timingach, rozmiarze danych, flagach i logach, aż przestanie być losowy.
Minimalizowanie za wcześnie. Jeśli zdążysz zredukować case zanim potwierdzisz oryginalne zachowanie, możesz stracić sygnał. Najpierw zablokuj bazowe odtworzenie, potem zmniejszaj krok po kroku.
Pozwalanie Claude’owi zgadywać. Claude może proponować prawdopodobne przyczyny, ale to ty musisz dostarczyć dowody. Żądaj 2–3 hipotez i dokładnych obserwacji, które potwierdzą lub odrzucą każdą z nich (linia logu, breakpoint, wynik zapytania).
Testy regresyjne, które przechodzą z niewłaściwego powodu. Test może „przechodzić”, bo nigdy nie trafia na ścieżkę prowadzącą do awarii. Upewnij się, że pada przed poprawką i że pada z oczekiwanym komunikatem lub asercją.
Leczenie objawów zamiast triggera. Jeśli dodasz null check, ale prawdziwy problem to „ta wartość nigdy nie powinna być null”, możesz ukryć głębszy błąd. Lepiej naprawić warunek tworzący zły stan.
Szybkie sanity check zanim zakończysz
Uruchom nowy test regresyjny i oryginalne kroki reprodukcji przed i po zmianie. Jeśli błąd checkout występuje tylko przy zastosowaniu kodu promocyjnego po zmianie wysyłki, zachowaj tę pełną sekwencję jako swoją „prawdę”, nawet jeśli zminimalizowany test jest mniejszy.
Jeśli twoja walidacja opiera się na „wygląda dobrze teraz”, dodaj jeden konkretny check (log, metrykę lub konkretny output), żeby następna osoba mogła szybko zweryfikować.
Szybka checklista, szablony promptów i następne kroki
Gdy masz mało czasu, mała powtarzalna pętla bije heroiczną diagnostykę.
Jednostronicowa checklista triage
- Reproduce: zdobądź niezawodne repro i zanotuj dokładne wejścia, środowisko oraz oczekiwane vs rzeczywiste.
- Minimize: zredukuj do najmniejszych kroków lub testu, który nadal pada.
- Explain: wypisz 2–3 prawdopodobne przyczyny i dowody dla każdej.
- Lock it in: dodaj test regresyjny, który pada z właściwego powodu.
- Fix + validate: wprowadź najwęższą zmianę, potem uruchom krótką check-listę walidacyjną.
Zapisz ostateczną decyzję w kilku zdaniach, aby następna osoba (często przyszły ty) mogła jej zaufać. Przydatny format to: „Przyczyna: X. Trigger: Y. Poprawka: Z. Dlaczego bezpieczne: W. Czego nie zmieniliśmy: Q.”
Szablony promptów, które możesz wkleić
- „Mając to zgłoszenie i logi, zadaj mi tylko brakujące pytania potrzebne do niezawodnej reprodukcji.”
- „Pomóż mi zminimalizować: zaproponuj mniejszy test case i powiedz, co usuwać najpierw, po jednym kroku.”
- „Uszereguj prawdopodobne przyczyny i podaj dokładne pliki, funkcje lub warunki wspierające każde twierdzenie.”
- „Napisz test regresyjny, który pada tylko z powodu tego błędu. Wyjaśnij, dlaczego pada z właściwego powodu.”
- „Zaproponuj najwęższą poprawkę, plus checklistę walidacyjną (unit, integration, manual), która udowodni, że nie połamało to zachowań bliskich.”
Następne kroki: zautomatyzuj, co możesz (zapisany skrypt repro, standardowe polecenie testowe, szablon notatek root-cause).
Jeśli budujesz aplikacje z Koder.ai (koder.ai), Planning Mode może pomóc w zarysowaniu zmiany zanim dotkniesz kodu, a snapshoty/rollback ułatwiają bezpieczne eksperymenty w trakcie pracy nad trudnym repro. Gdy poprawka będzie zwalidowana, możesz wyeksportować kod źródłowy lub wdrożyć i hostować zaktualizowaną aplikację, łącznie z opcją własnej domeny gdy potrzeba.