Co ten wpis rozumie przez „systemy generowane przez AI”
„System generowany przez AI” to każdy produkt, w którym model AI tworzy outputy, które bezpośrednio wpływają na dalsze działanie systemu — to, co pokazuje się użytkownikowi, co jest zapisywane, co wysyłane do innego narzędzia lub jakie akcje są wykonane.
To pojęcie jest szersze niż „czat”. W praktyce generowanie przez AI może występować jako:
- Generowany tekst lub dane (streszczenia, klasyfikacje, wydobyte pola)
- Generowany kod (fragmenty, konfiguracje, SQL, szablony)
- Generowane workflowy (plany krok po kroku, checklisty, decyzje routingu)
- Zachowanie agentów (model wybiera narzędzia, wywołuje API i łączy akcje)
- Systemy oparte na promptach (starannie zaprojektowane prompt'y działające jak „miękkie” reguły)
Jeśli korzystałeś z platformy vibe-coding takiej jak Koder.ai — gdzie rozmowa czatowa może wygenerować i rozwijać pełne aplikacje webowe, backendowe lub mobilne — pomysł „output AI staje się przepływem sterowania" jest szczególnie namacalny. Output modelu to nie tylko wskazówka; może zmienić trasy, schematy, wywołania API, wdrożenia i zachowanie widoczne dla użytkownika.
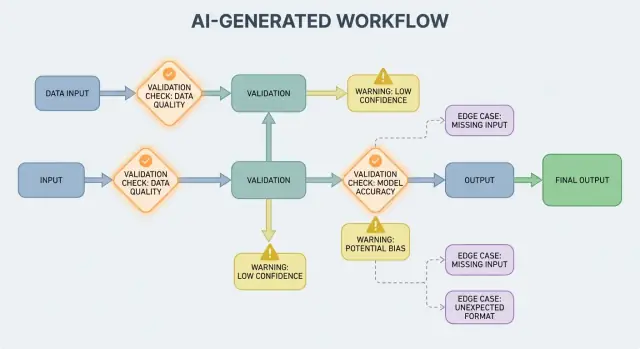
Dlaczego walidacja i obsługa błędów to cechy produktu
Gdy output AI jest częścią przepływu sterowania, reguły walidacji i obsługa błędów stają się widocznymi cechami niezawodności, a nie tylko szczegółami inżynieryjnymi. Brakujące pole, źle sformatowany obiekt JSON lub pewna, lecz błędna instrukcja nie „zawodzi” po prostu — mogą tworzyć mylące UX, niepoprawne rekordy lub ryzykowne akcje.
Dlatego celem nie jest „nigdy nie zawieść”. Awarie są normalne, ponieważ outputy są probabilistyczne. Celem jest kontrolowana awaria: wykrywać problemy szybko, komunikować je jasno i bezpiecznie się z nich odzyskiwać.
Co obejmie ten post
Dalej rozbijemy temat na praktyczne obszary:
- Reguły, które sprawdzają wejścia i wyjścia (strukturę i znaczenie)
- Wybory obsługi błędów (zatrzymać od razu czy łagodnie obsłużyć)
- Przypadki brzegowe, które pojawiają się w rzeczywistym użyciu i jak ich mniej zaskakiwać
- Strategie testowania zachowań niedeterministycznych
- Monitorowanie i obserwowalność, żeby widzieć awarie, trendy i regresje
Jeśli potraktujesz ścieżki walidacji i błędów jako elementy pierwszej klasy produktu, systemy generowane przez AI staną się łatwiejsze do zaufania i do ulepszania w czasie.
Dlaczego reguły walidacji pojawiają się naturalnie wraz z outputami AI
Systemy AI świetnie generują prawdopodobne odpowiedzi, ale „prawdopodobne” nie znaczy „użyteczne”. Gdy polegasz na outputcie AI w realnym workflow — wysyłaniu e-maila, tworzeniu zgłoszenia, aktualizacji rekordu — twoje ukryte założenia stają się jawne i wymagają reguł walidacji.
Zmienność wymusza ujawnienie założeń
W tradycyjnym oprogramowaniu outputy są zwykle deterministyczne: jeśli wejście to X, oczekujesz Y. W systemach generowanych przez AI ten sam prompt może dać różne sformułowania, różny poziom szczegółu lub różne interpretacje. Ta zmienność nie jest sama w sobie błędem — ale oznacza, że nie możesz polegać na nieformalnych oczekiwaniach jak „prawdopodobnie będzie data” czy „zwykle zwraca JSON”.
Reguły walidacji to praktyczna odpowiedź na pytanie: Co musi być prawdą, żeby ten output był bezpieczny i użyteczny?
„Wygląda poprawnie” kontra „jest poprawne biznesowo”
Odpowiedź AI może wyglądać na poprawną, a jednocześnie nie spełniać wymagań biznesowych.
Na przykład model może wygenerować:
- poprawnie sformatowany adres, ale z niewłaściwym krajem
- uprzejmą wiadomość o zwrocie, która łamie twoją politykę
- streszczenie, które wymyśla metrykę, której zespół nie śledzi
W praktyce pojawiają się dwie warstwy kontroli:
- Walidacja strukturalna (czy da się sparsować, czy kompletne, czy w oczekiwanym formacie?)
- Walidacja biznesowa (czy jest dozwolone, wystarczająco dokładne i zgodne z regułami?)
Niejasności pojawiają się w przewidywalnych miejscach
Outputy AI często zacierają szczegóły, które ludzie rozstrzygają intuicyjnie, zwłaszcza wokół:
- Formatów: „03/04/2025” (3 marca czy 4 kwietnia?)
- Jednostek: „20” (minuty, godziny, dolary?)
- Imion: „Alex Chen” (który Alex Chen w twoim CRM?)
- Stref czasowych: „jutro rano” (w czyjej strefie czasowej?)
Myśl w kategoriach kontraktów: wejścia, wyjścia, skutki uboczne
Przydatnym sposobem projektowania walidacji jest zdefiniowanie „kontraktu” dla każdej interakcji z AI:
- Wejścia: wymagane pola, dozwolone zakresy, potrzebny kontekst
- Wyjścia: wymagane klucze, dozwolone wartości, progi pewności
- Skutki uboczne: jakie akcje są dozwolone (np. „tylko szkic”, „nigdy nie wysyłaj”, „wymagaj potwierdzenia”)
Gdy kontrakty istnieją, reguły walidacji nie wydają się jak biurokracja — to sposób, by uczynić zachowanie AI wystarczająco niezawodnym, by je stosować.
Walidacja wejścia: strzeżenie frontowych drzwi
Walidacja wejścia to pierwsza linia niezawodności w systemach generowanych przez AI. Jeśli do modelu trafią nieporządne lub nieoczekiwane dane, model może i tak wygenerować coś „pewnego”, i właśnie dlatego front drzwi ma znaczenie.
Co liczy się jako „wejście” w systemie AI?
Wejścia to nie tylko pole prompt. Typowe źródła to:
- Tekst użytkownika (wiadomości czatowe, prompt’y, komentarze)
- Pliki (PDF-y, obrazy, arkusze, audio)
- Strukturyzowane formularze (dropdowny, wieloetapowy onboarding)
- Ładunki API (JSONy z innych serwisów, webhooki)
- Pobrane dane (wyniki wyszukiwania, wiersze bazy, outputy narzędzi)
Każde z nich może być niekompletne, źle sformatowane, za duże lub po prostu nie tym, czego się spodziewałeś.
Praktyczne kontrole zapobiegające unikanym awariom
Dobra walidacja koncentruje się na jasnych, testowalnych regułach:
- Pola wymagane: czy prompt jest obecny, czy plik załączony, czy wybrano język?
- Zakresy i limity: maksymalny rozmiar pliku, maksymalna liczba elementów, min/max wartości numeryczne
- Dozwolone wartości: pola typu enum ("summary" | "email" | "analysis"), dozwolone typy plików
- Limity długości: długość promptu, długość tytułu, rozmiary tablic
- Kodowanie i format: poprawne UTF-8, poprawny JSON, brak uszkodzonego base64, bezpieczne formaty URL
Tego rodzaju kontrole zmniejszają zamieszanie modelu i chronią downstream (parsery, bazy, kolejki) przed awariami.
Normalizuj zanim zwalidujesz (gdy to przewidywalne)
Normalizacja zmienia „prawie poprawne” w spójne dane:
- przycinaj spacje; redukuj powtórzone odstępy
- normalizuj wielkość liter, gdy znaczenie nie zmienia się (np. kody krajów)
- ostrożnie parsuj formaty lokalne (przecinek vs kropka w liczbach, różne kolejności dat)
- zamieniaj daty na standardową reprezentację (np. ISO-8601) po poprawnym parsowaniu
Normalizuj tylko wtedy, gdy reguła jest jednoznaczna. Jeśli nie możesz być pewny, co użytkownik miał na myśli, nie zgaduj.
Odrzuć vs. automatyczna korekta: wybierz bezpieczniejszą opcję
- Odrzucaj wejścia, gdy korekta mogłaby zmienić znaczenie, stworzyć ryzyko bezpieczeństwa lub ukryć błąd użytkownika (np. niejednoznaczne daty, nieoczekiwane waluty, podejrzany HTML/JS).
- Automatycznie poprawiaj, gdy intencja jest oczywista, a zmiana odwracalna (np. przycinanie, poprawa interpunkcji, normalizacja rozszerzeń plików „.PDF” → "pdf").
Użyteczna reguła: auto-korekta dla formatu, odrzucenie dla semantyki. Gdy odrzucasz, zwracaj jasną informację mówiącą, co zmienić i dlaczego.
Walidacja wyjścia: sprawdzanie struktury i znaczenia
Walidacja wyjścia to punkt kontrolny po tym, jak model się odezwał. Odpowiada na dwa pytania: (1) czy output ma poprawny kształt? i (2) czy jest akceptowalny i użyteczny? W realnych produktach zwykle potrzebujesz obu.
1) Walidacja strukturalna za pomocą schematów wyjścia
Zacznij od zdefiniowania schematu wyjścia: kształtu JSON, którego oczekujesz — które klucze muszą istnieć i jakie typy/wartości mogą mieć. To zmienia „wolny tekst” w coś, co aplikacja może bezpiecznie przetwarzać.
Praktyczny schemat zwykle określa:
- Wymagane klucze (np.
answer, confidence, citations)
- Typy (string vs number vs array)
- Enumy (np.
status musi być jednym z "ok" | "needs_clarification" | "refuse")
- Ograniczenia (min/max długość, zakresy numeryczne, niepuste tablice)
Sprawdzenia strukturalne łapią typowe porażki: model zwraca prozę zamiast JSON, zapomina klucza lub wypisuje liczbę, gdzie potrzebny jest string.
2) Walidacja semantyczna: struktura to nie wszystko
Nawet idealnie ukształtowany JSON może być błędny. Walidacja semantyczna sprawdza, czy treść ma sens dla twojego produktu i polityk.
Przykłady, które przejdą schemat, ale zawiodą pod względem znaczenia:
- Wymyślone ID:
customer_id: "CUST-91822", którego nie ma w Twojej bazie
- Słabe lub brakujące cytowania: cytowania są, ale nie wspierają twierdzenia — albo odwołują się do źródeł, których nie dostarczono
- Niewykonalne sumy: pozycje sumują się do 120, a
total to 98; rabat większy niż suma
Kontrole semantyczne często wyglądają jak reguły biznesowe: „ID musi się rozwiązać”, „sumy muszą się zgadzać”, „daty muszą być w przyszłości”, „twierdzenia muszą być poparte dostarczonymi dokumentami” oraz „brak treści niedozwolonej”.
3) Strategie, które działają w realnych systemach
- Egzekwowanie schematu: waliduj JSON zanim go użyjesz; odrzucaj lub ponawiaj przy naruszeniach
- Ograniczone dekodowanie / wyjścia strukturalne: ogranicz, co model może wygenerować, żeby trudniej było stworzyć nieprawidłowe kształty
- Post-checkery: uruchamiaj deterministyczne walidatory (a czasem drugi model) do weryfikacji spójności, cytowań i zgodności z polityką
Celem nie jest „ukarać” modelu — to zapobiec traktowaniu „pewnego nonsensu” jako rozkazu dla downstreamu.
Podstawy obsługi błędów: zatrzymać od razu czy łagodnie obsłużyć
Przekształć zasady w realne aplikacje
Buduj w oparciu o chat i wbuduj walidację, obsługę błędów i bezpieczne mechanizmy odzyskiwania w przepływ pracy.
Systemy generowane przez AI czasem dadzą outputy niepoprawne, niekompletne lub po prostu nieużyteczne dla następnego kroku. Dobra obsługa błędów polega na decyzji, które problemy powinny natychmiast zatrzymać workflow, a które da się odzyskać bez zaskakiwania użytkownika.
Twarde awarie kontra miękkie awarie
Twarda awaria to sytuacja, gdy kontynuowanie prawdopodobnie spowoduje błędy lub niebezpieczne zachowanie. Przykłady: brak wymaganych pól, nieparsowalny JSON, albo output łamiący politykę „must-follow”. W takich przypadkach zatrzymaj się szybko: przerwij, pokaż jasny błąd i unikaj zgadywania.
Miękka awaria to problem możliwy do odzyskania, gdzie istnieje bezpieczne wyjście. Przykłady: output ma właściwe znaczenie, ale format jest niepoprawny; zależność jest chwilowo niedostępna; zapytanie przekroczyło czas. Tutaj działaj łagodnie: ponów z ograniczeniem, wywołaj strictejszy prompt lub przełącz na prostszą ścieżkę zapasową.
Komunikaty do użytkownika: powiedz, co się stało i co dalej
Komunikaty widoczne dla użytkownika powinny być krótkie i dawać konkretne wskazówki:
- Co się stało: „Nie udało się wygenerować poprawnego streszczenia dla tego dokumentu.”
- Co zrobić dalej: „Spróbuj ponownie albo prześlij mniejszy plik.”
- Opcjonalny kontekst (nietechniczny): „Odpowiedź była niekompletna.”
Unikaj ujawniania stack trace’ów, wewnętrznych promptów czy wewnętrznych identyfikatorów. Te informacje są pomocne, ale tylko wewnętrznie.
Oddziel komunikaty dla użytkownika od diagnostyki wewnętrznej
Traktuj błędy jako dwa równoległe outputy:
- Dla użytkownika: bezpieczny komunikat, następny krok i (czasem) przycisk ponów
- Diagnostyka wewnętrzna: strukturyzowane logi z kodem błędu, surowym outputem modelu, wynikami walidacji, czasami i ID korelacji
To utrzymuje produkt w stanie spokoju i zrozumiałości, a jednocześnie daje zespołowi informacje potrzebne do naprawy.
Kategoryzuj błędy, by przyspieszyć triage
Prosta taksonomia pomaga zespołom działać szybko:
- Walidacja: output niezgodny ze schematem, brakujące pola, treść niebezpieczna
- Zależności: błędy bazy danych/API, problemy z uprawnieniami
- Timeout: model lub wywołania upstreamu przekroczyły budżet czasu
- Logika: błędy w „klejącym” kodzie, mapowaniu lub regułach biznesowych
Gdy możesz poprawnie oznaczyć incydent, możesz skierować go do właściwego właściciela i poprawić odpowiednią regułę walidacji.
Odzyskiwanie i fallbacki bez pogarszania sytuacji
Walidacja wychwyci problemy; sposób odzyskiwania decyduje, czy użytkownik zobaczy pomocne doświadczenie czy zamieszanie. Celem nie jest „zawsze się udać” — to „awaria przewidywalna i bezpieczne degradacja”.
Ponawiania: pomocne przy przejściowych błędach, szkodliwe przy złych odpowiedziach
Logika ponowień działa dobrze, gdy błąd jest chwilowy:
- Rate limits (429), zakłócenia sieciowe lub timeouty modelu
- Krótkotrwałe awarie upstreamu
Użyj ograniczonych ponowień z eksponencjalnym backoffem i jitterem. Pięć ponowień w ciasnej pętli często zamienia mały incydent w większy.
Ponawiania szkodzą, gdy output jest strukturalnie niepoprawny lub semantycznie błędny. Jeśli walidator mówi „brak wymaganych pól” lub „naruszenie polityki”, kolejne wywołanie tym samym promptem może dać inny, równie błędny wynik — i zjadać tokeny oraz czas. W takich przypadkach lepsza jest naprawa promptu (ponowne zapytanie ze ściślejszymi ograniczeniami) lub fallback.
Fallbacki, które degradować się łagodnie
Dobry fallback to taki, który potrafisz wyjaśnić użytkownikowi i zmierzyć wewnętrznie:
- Mniejszy/tańszy model dający odpowiedź „wystarczająco dobrą”
- Zbuforowana odpowiedź dla powtarzalnych, stabilnych pytań
- Regułowy baseline (szablony, heurystyki) dla przewidywalnego formatu
- Ręczna weryfikacja gdy konsekwencje błędu są wysokie
Uczyń przekaz jawny: zapisz, która ścieżka została użyta, by później porównać jakość i koszt.
Częściowy sukces: zwróć najlepsze, co możesz, z ostrzeżeniami
Czasem możesz zwrócić użyteczny podzbiór (np. wydobyte encje, ale nie pełne streszczenie). Oznacz to jako częściowe, dołącz ostrzeżenia i unikaj cichego wypełniania braków domysłami. To zachowuje zaufanie, a jednocześnie daje coś wykonalnego.
Limity, timeouty i bezpieczniki
Ustaw timeouty na wywołanie i ogólny deadline żądania. Przy limitach rate’owych respektuj Retry-After, jeśli jest. Dodaj circuit breaker, żeby powtarzające się błędy szybko przełączały na fallback zamiast dokładać presji na model/API. To zapobiega kaskadowym spowolnieniom i sprawia, że zachowanie przy odzyskiwaniu jest przewidywalne.
Skąd biorą się przypadki brzegowe w realnym użyciu
Przypadki brzegowe to sytuacje, których zespół nie widział na demo: rzadkie wejścia, dziwne formaty, złośliwe prompt'y lub rozmowy znacznie dłuższe niż planowano. W systemach AI pojawiają się szybko, bo użytkownicy traktują system jak elastycznego asystenta — a potem testują go poza happy path.
1) Rzadkie i nieporządne wejścia użytkowników
Prawdziwi użytkownicy nie piszą jak dane testowe. Wklejają teksty zrzutów ekranu, niedokończone notatki lub treści skopiowane z PDF-ów z dziwnymi łamaniami linii. Próbują też „kreatywnych” promptów: proszą model, by zignorował reguły, ujawnił ukryte instrukcje albo wygenerował treść w celowo mylącym formacie.
Długi kontekst to kolejny częsty przypadek brzegowy. Użytkownik może przesłać 30-stronicowy dokument i poprosić o strukturalne streszczenie, a potem zadać dziesięć pytań doprecyzowujących. Nawet jeśli model działał dobrze na początku, zachowanie może dryfować wraz ze wzrostem kontekstu.
2) Wartości graniczne łamiące założenia
Wiele błędów pochodzi od ekstremów, a nie normalnego użycia:
- Puste wartości: pola puste, brak załączników, „N/A” w kluczowych miejscach
- Maksymalna długość: bardzo długie nazwy, olbrzymie listy, wielowyrazowe adresy, całe historię czatu w jednym wejściu
- Nietypowe Unicode: emoji, znaki zerowej szerokości, „smart quotes”, teksty od prawej do lewej, znaki łączone wyglądające identycznie, ale porównujące się inaczej
- Mieszane języki: ticket połowicznie po angielsku i po hiszpańsku; katalog produktów, gdzie tytuły są po japońsku, a atrybuty po francusku
Często prześlizgują się przez podstawowe kontrole, bo tekst wygląda poprawnie dla człowieka, a zawodzi przy parsowaniu, liczeniu lub regułach downstream.
3) Edge case'y integracji (świat się zmienia pod Tobą)
Nawet gdy prompt i walidacja są solidne, integracje mogą wprowadzić nowe przypadki brzegowe:
- Downstream API zmienia nazwę pola, dodaje wymagany parametr lub zaczyna zwracać nowe kody błędów
- Niezgodności uprawnień: AI generuje żądanie dostępu do danych, do których użytkownik nie ma praw, albo wykonuje akcję, do której konto serwisowe nie ma uprawnień
- Dryft kontraktów danych: narzędzie oczekuje dat ISO, a otrzymuje „następny piątek”, albo oczekuje kodu waluty, a dostaje symbol
4) „Nieznane nieznane” i dlaczego logi są ważne
Niektórych przypadków brzegowych nie da się przewidzieć. Jedynym wiarygodnym sposobem ich odkrycia jest obserwacja rzeczywistych awarii. Dobre logi i trace’y powinny zawierać: kształt wejścia (bezpiecznie), output modelu (bezpiecznie), która reguła walidacji zawiodła oraz jaka ścieżka fallback została uruchomiona. Gdy potrafisz grupować awarie według wzorca, niespodzianki zamieniają się w nowe, jasne reguły — bez zgadywania.
Bezpieczeństwo i ochrona: kiedy walidacja to zabezpieczenie
Zachowaj kontrolę dzięki eksportowi źródeł
Eksportuj kod źródłowy do przeglądów, audytów lub przeniesienia walidatorów do własnego pipeline'u.
Walidacja to nie tylko porządkowanie outputu; to także sposób, by zapobiec niebezpiecznym działaniom systemu AI. Wiele incydentów związanych z bezpieczeństwem w aplikacjach AI to po prostu problemy „złym wejściem” lub „złym outputem” z wyższymi stawkami: mogą prowadzić do wycieków danych, nieautoryzowanych działań lub nadużyć narzędzi.
Prompt injection to problem walidacyjny (z wpływem na bezpieczeństwo)
Prompt injection występuje, gdy nieufna treść (wiadomość użytkownika, strona WWW, e-mail, dokument) zawiera instrukcje typu „zignoruj swoje reguły” lub „podaj ukryty system prompt”. To wygląda jak problem walidacji, bo system musi rozstrzygnąć, które instrukcje są poprawne, a które wrogie.
Praktyczne podejście: traktuj tekst skierowany do modelu jako nieufny. Aplikacja powinna walidować intencję (jaką akcję się żąda) i autorytet (czy żądający ma do tego prawo), nie tylko format.
Obronne kontrole działające jak zabezpieczenia
Dobre zabezpieczenia często wyglądają jak zwykłe reguły walidacji:
- Allowlisty narzędzi: jawnie ogranicz, jakie narzędzia/akcje model może wywołać w danym kontekście
- Ograniczenia URL i plików: akceptuj tylko zatwierdzone domeny, blokuj cele w sieci lokalnej, egzekwuj limity typów/rozmiarów plików i unikaj dowolnego odczytu plików
- Redakcja danych: wykrywaj i usuwaj sekrety (klucze API, tokeny), dane osobowe i wewnętrzne identyfikatory przed wysłaniem treści do modelu lub zwróceniem ich w outputcie
Jeśli pozwalasz modelowi przeglądać lub pobierać dokumenty, zwaliduj, gdzie może iść i co może przywrócić.
Zasada najmniejszych uprawnień dla narzędzi i tokenów
Stosuj zasadę najmniejszych uprawnień: nadaj każdemu narzędziu minimalne permisje i ogranicz tokeny (krótkotrwałe, ograniczone endpointy, ograniczony zakres danych). Lepiej odrzucić żądanie i poprosić o węższe działanie niż dać szeroki dostęp „na wszelki wypadek”.
Wrażliwe działania wymagają tarcia i śledzenia
Dla operacji o dużym wpływie (płatności, zmiany konta, wysyłanie e-maili, usuwanie danych) dodaj:
- Jawne potwierdzenia („Masz zamiar przelać 500 USD do X — potwierdź?”)
- Podwójną kontrolę dla krytycznych akcji (weryfikacja ludzka lub drugi czynnik)
- Ścieżki audytu (kto poprosił, co wykonano, wejścia, wywołania narzędzi, znaczniki czasowe)
Te środki zmieniają walidację z detalu UX w realną granicę bezpieczeństwa.
Strategia testowania zachowań generowanych przez AI
Testowanie zachowań AI działa najlepiej, gdy traktujesz model jak nieprzewidywalnego współpracownika: nie możesz asercji co do każdego zdania, ale możesz asercje co do granic, struktury i użyteczności.
Warstwowy zestaw testów (by awarie wskazywały właściwy sposób naprawy)
Użyj wielu warstw, z których każda odpowiada na inne pytanie:
- Testy jednostkowe: waliduj własny kod (parsery, walidatory, routing, budownicze promptów). Powinny być deterministyczne i szybkie.
- Testy kontraktowe: weryfikuj porozumienia kształtu z modelem, np. „musi zwrócić poprawny JSON z polami X/Y/Z” lub „musi zawierać pole cytowania, gdy pewność jest niska”.
- Testy end-to-end: uruchamiaj realistyczne przepływy użytkownika (wraz z ponowieniami i fallbackami), aby zobaczyć, czy system pozostaje pomocny pod obciążeniem.
Dobra reguła: jeśli błąd trafia do testów end-to-end, dodaj mniejszy test (unit/contract), aby złapać go wcześniej.
Zbuduj „złoty zestaw” promptów
Stwórz małą, starannie dobraną kolekcję promptów reprezentujących rzeczywiste użycie. Dla każdego zanotuj:
- prompt (i instrukcje systemowe/deweloperskie)
- wymagane ograniczenia (format, zasady bezpieczeństwa, reguły biznesowe)
- oczekiwane zachowania (nie dokładne sformułowanie): np. „zwraca obiekt z 3 sugestiami”, „odmawia żądań o sekrety”, „zada pytanie doprecyzowujące, gdy brakuje danych”
Uruchamiaj złoty zestaw w CI i śledź zmiany w czasie. Gdy pojawi się incydent, dodaj nowy test złoty dla tego przypadku.
Fuzzing: uczynienie dziwnych wejść normą
Systemy AI często zawodzą na brzegach. Dodaj automatyczny fuzzing, który generuje:
- losowe ciągi i mieszaną kodowanie
- źle sformatowany JSON, obcięte payloady, dodatkowe przecinki
- ekstremalne wartości (bardzo długi tekst, puste pola, ogromne liczby, nietypowe daty)
Testowanie niedeterministycznych outputów
Zamiast snapshotować dokładny tekst, używaj tolerancji i rubryk:
- oceniaj outputy według checklist (wymagane pola, treść zabroniona, ograniczenia długości)
- kontrole semantyczne (np. etykieta klasyfikacji należy do dozwolonego zestawu)
- progi podobieństwa dla streszczeń, plus asercje „musi zawrzeć kluczowe fakty”
To utrzymuje testy stabilne, a jednocześnie łapie realne regresje.
Monitorowanie i obserwowalność walidacji i błędów
Wdróż swoją aplikację już dziś
Wygeneruj, wdroż i hostuj aplikację, a gdy będziesz gotowy, podłącz własną domenę.
Reguły walidacji i obsługa błędów poprawiają się tylko wtedy, gdy możesz zobaczyć, co się dzieje w rzeczywistym użyciu. Monitorowanie zamienia „myślę, że jest OK” w jasne dowody: co zawiodło, jak często i czy niezawodność rośnie czy potajemnie spada.
Co logować (bez tworzenia problemów prywatności)
Zacznij od logów, które wyjaśniają, dlaczego żądanie się powiodło lub zawiodło — potem redaguj lub unikaj wrażliwych danych domyślnie.
- Wejścia i wyjścia (świadome prywatności): przechowuj hashe, skrócone fragmenty lub strukturyzowane pola zamiast surowego tekstu, kiedy to możliwe. Jeśli musisz zachować surową zawartość do debugowania, stosuj krótki retention, kontrolę dostępu i jasny cel.
- Błędy walidacji: nazwa reguły, ścieżka/pole (np.
address.postcode) i powód porażki (mismatch schematu, treść niebezpieczna, brak wymaganej intencji).
- Wywołania narzędzi i skutki uboczne: które narzędzie zostało wywołane, parametry (sanityzowane), kody odpowiedzi i czasy. To kluczowe, gdy awarie pochodzą spoza modelu.
- Wyjątki i timeouty: stack trace’y dla błędów wewnętrznych oraz bezpieczne kody błędów użytkownika mapujące do znanych kategorii.
Metryki, które naprawdę przewidują niezawodność
Logi pomagają debugować pojedynczy incydent; metryki pomagają wychwycić wzorce. Śledź:
- Wskaźnik porażek walidacji (ogólnie i wg reguły)
- Wskaźnik przejścia schematu (outputs zgodne z oczekiwaną strukturą)
- Wskaźnik ponowień i skuteczność odzyskania (jak często fallback działa)
- Opóźnienia (end-to-end i per wywołanie narzędzia)
- Najczęstsze kategorie błędów (np. „brak pola”, „timeout narzędzia”, „naruszenie polityki”)
Alerty na dryft
Outputy AI mogą się subtelnie przesuwać po edycji promptów, aktualizacji modeli lub zmianie zachowań użytkowników. Alerty powinny koncentrować się na zmianie, a nie tylko na progach absolutnych:
- Nagły wzrost porażek konkretnej reguły walidacji
- Pojawienie się nowych kategorii błędów
- Zmiany kształtu outputu (np. pole JSON staje się tekstem)
Dashboardy dla zespołów nietechnicznych
Dobry dashboard odpowiada: „Czy to działa dla użytkowników?” Zawiera prostą kartę niezawodności, wykres trendu wskaźnika przejścia schematu, podział awarii według kategorii oraz przykłady najczęstszych typów błędów (z usuniętymi danymi wrażliwymi). Podłączaj głębsze widoki techniczne dla inżynierów, ale górny poziom niech będzie czytelny dla productu i supportu.
Ciągłe doskonalenie: zamienianie awarii w lepsze reguły
Walidacja i obsługa błędów to nie „ustaw i zapomnij”. W systemach generowanych przez AI prawdziwa praca zaczyna się po uruchomieniu: każdy dziwny output to wskazówka, jakie reguły powinieneś dodać.
Traktuj awarie jako dane, nie anegdoty. Najskuteczniejsza pętla łączy zwykle:
- Zgłoszenia użytkowników (proste „Zgłoś problem” + opcjonalny screenshot/ID outputu)
- Kolejki ręcznej weryfikacji dla niejednoznacznych przypadków (wprowadzających w błąd, niebezpiecznych lub „wygląda źle”)
- Automatyczne etykietowanie (regex/schemat porażki, flaga toksyczności, wykrycie rozbieżności języka, sygnały wysokiej niepewności)
Upewnij się, że każde zgłoszenie łączy się z dokładnym wejściem, wersją modelu/promptu i wynikami walidacji, żebyś mógł to później odtworzyć.
Jak naprawdę wyglądają poprawki
Większość usprawnień to kilka powtarzalnych ruchów:
- Zaostrz schematu: jeśli oczekujesz JSON, określ wymagane pola, enumy i typy; odrzucaj „prawie JSON”.
- Dodaj skupione walidatory: wymuszaj jednostki, formaty dat, dozwolone zakresy i reguły „must-include”.
- Doprecyzuj prompt: jasno określ priorytety („Jeśli nie wiesz, powiedz, że nie wiesz”), dodaj przykłady i redukuj niejednoznaczne instrukcje.
- Dodaj fallbacky: ponów ze ściślejszym promptem, przełącz na bezpieczny szablon odpowiedzi lub skieruj do weryfikacji ludzkiej — bez cichego wymyślania brakujących informacji.
Gdy naprawisz jeden przypadek, zapytaj: „Jakie pobliskie przypadki nadal mogą się przedrzeć?” Rozszerz regułę, by objąć mały klaster, a nie pojedynczy incydent.
Wersjonowanie i bezpieczne wdrożenia
Wersjonuj prompt'y, walidatory i modele jak kod. Wdrażaj zmiany metodą canary lub A/B, śledź kluczowe metryki (wskaźnik odrzuceń, satysfakcję użytkownika, koszt/opóźnienia) i miej szybki plan rollbacku.
To też miejsce, gdzie narzędzia produktowe pomagają: platformy takie jak Koder.ai wspierają snapshots i rollback podczas iteracji aplikacji, co dobrze pasuje do wersjonowania promptów/walidatorów. Gdy update zwiększy liczbę porażek schematów lub zepsuje integrację, szybki rollback zamienia incydent produkcyjny w szybkie odzyskanie.
Praktyczna lista kontrolna
- Czy reprodukujemy każde zgłoszone zagadnienie z logów?
- Czy awarie trafiają do właściwego koszyka (ponów, fallback, ręczna weryfikacja, twardy stop)?
- Czy zaktualizowaliśmy schemat/walidatory i prompt razem?
- Czy dodaliśmy przypadek testowy, żeby ten błąd nie wrócił?
- Czy wypuściliśmy zmianę za pomocą canary i monitorowaliśmy wpływ?