Dlaczego cache pomaga — i dlaczego komplikuje systemy
Cache przechowuje kopię danych blisko miejsca, gdzie są potrzebne, dzięki czemu żądania mogą być obsłużone szybciej i bez częstych odwołań do rdzenia systemu. Zysk to zwykle mieszanka szybkości (mniejsze opóźnienia), kosztów (mniej drogich odczytów z bazy lub zewnętrznych wywołań) i stabilności (origin przetrzymuje szczyty ruchu).
Zaleta: mniejsze obciążenie originu
Gdy cache odpowiada na żądanie, twój „origin” (serwery aplikacji, bazy danych, zewnętrzne API) wykonuje mniej pracy. Redukcja może być dramatyczna: mniej zapytań, mniej cykli CPU, mniej skoków sieciowych i mniejsze ryzyko timeoutów.
Cache wygładza też nagłe skoki — pozwala systemom wymiarowanym na średnie obciążenie obsłużyć chwile szczytowe bez natychmiastowego skalowania (albo awarii).
Ukryty kompromis: więcej pracy dla inżynierów
Cache nie usuwa pracy; przenosi ją do projektowania i operacji. Pojawiają się nowe pytania:
- Co powinno być cache’owane?
- Na jak długo?
- Co się dzieje, gdy dane się zmienią?
- Jak zapobiegać przestarzałym lub błędnym wynikom?
- Jak debugować problemy, gdy cache „ukrywa” zachowanie originu?
Każda warstwa cache dodaje konfigurację, monitoring i przypadki brzegowe. Cache, który przyspiesza 99% żądań, nadal może spowodować bolesne incydenty w tym 1%: zsynchronizowane wygaśnięcia, niespójne doświadczenia użytkownika czy nagłe zalewy ruchu do originu.
Warstwa cache vs pojedynczy cache
Pojedynczy cache to jedno repozytorium (np. cache w pamięci obok aplikacji). Warstwa cache to odrębny punkt kontrolny w ścieżce żądania — CDN, cache przeglądarki, cache aplikacji, cache bazy danych — każda z własnymi regułami i trybami awarii.
Ten tekst skupia się na praktycznej złożoności wynikającej z wielu warstw: poprawności, unieważnianiu i operacjach (nie na niskopoziomowych algorytmach cache czy dostrajaniu pod konkretnego dostawcę).
Prosty model: przepływ żądania przez wiele warstw
Łatwiej zrozumieć cache, gdy wyobrazisz sobie żądanie przechodzące przez stos „może już to mam” punktów kontrolnych.
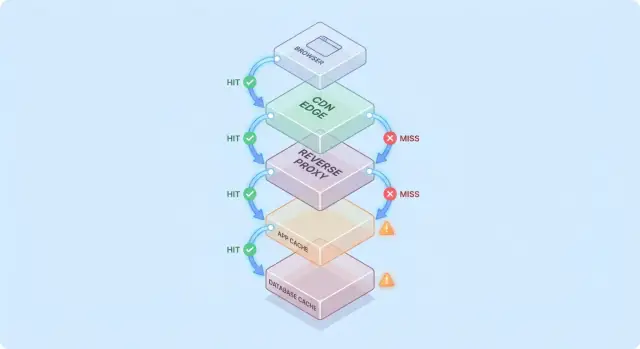
Typowa ścieżka żądania
Powszechna ścieżka wygląda tak:
- Klient → Edge (CDN) → Aplikacja → Baza danych
Na każdym etapie system albo zwraca odpowiedź z cache (hit), albo przesyła żądanie dalej (miss). Im wcześniej wystąpi hit (np. na edge), tym więcej obciążenia unikasz głębiej w stosie.
Hity są miłe; grosse testują missy
Hity ładnie wyglądają na dashboardach. Missy to miejsce, gdzie pojawia się złożoność: uruchamiają rzeczywistą pracę (logika aplikacji, zapytania do DB) i dodają narzut (sprawdzenia cache, serializacja, zapisy do cache).
Użyteczny model mentalny: każdy miss płaci za cache dwukrotnie — nadal wykonujesz oryginalną pracę oraz pracę związaną z obsługą cache.
Jak warstwy przesuwają wąskie gardła
Dodanie warstwy cache rzadko likwiduje wąskie gardło; często je przesuwa:
- CDN może przenieść presję z aplikacji, ale zwiększa wrażliwość na konfigurację cache i szybkość purge.
- Cache aplikacji zmniejsza obciążenie bazy, ale czyni CPU/pamięć warstwy aplikacyjnej nowym ograniczeniem.
- Cache bazy (buffer pool, plan cache) może ukryć wolne zapytania, aż zestaw roboczy przestanie się mieścić.
Prosty przykład „cache dwa razy”
Załóżmy, że strona produktu jest cache’owana w CDN na 5 minut, a aplikacja dodatkowo cache’uje szczegóły produktu w Redis na 30 minut.
Jeśli zmieni się cena, CDN może odświeżyć się szybko, podczas gdy Redis nadal podaje starą cenę. Teraz „prawdą” jest to, która warstwa odpowiedziała — to wczesny przykład, dlaczego warstwy cache obniżają obciążenie, ale zwiększają złożoność systemu.
Typowe warstwy cache i do czego się nadają
Cache to nie jedna funkcja — to stos miejsc, gdzie dane można zapisać i ponownie wykorzystać. Każda warstwa może obniżyć obciążenie, ale każda ma inne reguły świeżości, unieważniania i widoczności.
Cache przeglądarki i systemu operacyjnego (co kontrolujesz vs czego nie)
Przeglądarki cache’ują obrazy, skrypty, CSS, a czasem odpowiedzi API na podstawie nagłówków HTTP (np. Cache-Control i ETag). To może całkowicie wyeliminować powtarzające się pobrania — świetne dla wydajności i zmniejszenia ruchu CDN/origin.
Słowo ostrzeżenia: gdy odpowiedź jest zakache’owana po stronie klienta, nie kontrolujesz w pełni czasu ponownej walidacji. Niektórzy użytkownicy mogą trzymać stare zasoby dłużej (albo czyścić cache niespodziewanie), dlatego wersjonowane adresy URL (np. app.3f2c.js) są powszechną metodą zabezpieczającą.
Cache CDN/edge dla treści statycznych i półstatycznych
CDN cache’uje treść blisko użytkowników. Świetnie sprawdza się dla plików statycznych, stron publicznych i „przeważnie stabilnych” odpowiedzi jak obrazy produktów czy dokumentacja.
CDN może też cache’ować półstatyczne HTML, jeśli ostrożnie zarządzasz wariantami (ciasteczka, nagłówki, geo, urządzenie). Błędnie skonfigurowane reguły wariantów często skutkują serwowaniem nieprawidłowej treści niewłaściwemu użytkownikowi.
Cache reverse proxy (poziom gateway)
Reverse proxy (np. NGINX, Varnish) stoi przed aplikacją i może cache’ować całe odpowiedzi. Przydaje się, gdy chcesz scentralizowanej kontroli, przewidywalnego usuwania i szybkiej ochrony originu podczas skoków ruchu.
Zwykle nie jest tak globalnie rozproszony jak CDN, ale łatwiej dopasować go do tras i nagłówków aplikacji.
Cache na poziomie aplikacji (in‑memory, Redis, Memcached)
Ten cache celuje w obiekty, wyniki obliczeń i kosztowne wywołania (np. „profil użytkownika po id” lub „zasady cenowe dla regionu”). Jest elastyczny i może znać logikę biznesową.
Wprowadza też punkty decyzyjne: projekt klucza, wybór TTL, logikę unieważniania oraz potrzeby operacyjne jak sizing i failover.
Cache bazy danych i cache zapytań/wyników
Większość baz cache’uje strony, indeksy i plany zapytań automatycznie; niektóre wspierają cache wyników. To przyspiesza powtarzające się zapytania bez zmian w kodzie aplikacji.
Lepiej traktować to jako bonus, nie gwarancję: cache bazy jest zwykle najmniej przewidywalny przy różnorodnych wzorcach zapytań i nie usuwa kosztów zapisów, blokad czy kontencji tak, jak robią to upstreamowe cache.
Gdzie cache daje największe zmniejszenie obciążenia
Cache najbardziej się opłaca, gdy zamienia powtarzalne, kosztowne operacje backendu na tani lookup. Sztuka polega na dopasowaniu cache do obciążeń, gdzie żądania są wystarczająco podobne — i wystarczająco stabilne — by dało się je ponownie wykorzystać.
Obciążenia z przewagą odczytów i kosztowne obliczenia
Jeśli system obsługuje znacznie więcej odczytów niż zapisów, cache może usunąć dużą część pracy bazy i aplikacji. Strony produktu, profile publiczne, artykuły pomocy i wyniki wyszukiwania często są powtarzane z tymi samymi parametrami.
Cache pomaga też przy „kosztownych” operacjach, które niekoniecznie są związane z bazą danych: generowanie PDF‑ów, zmiana rozmiaru obrazów, renderowanie szablonów czy obliczanie agregatów. Nawet krótkotrwały cache (sekundy–minuty) może skompresować powtarzającą się pracę w okresach dużego ruchu.
Ruch skokowy i ochrona przed nagłymi napływami
Cache jest szczególnie skuteczny, gdy ruch jest nierównomierny. Gdy mailing, wzmianka w mediach czy post społecznościowy ściąga falę użytkowników na kilka URLi, CDN lub edge może wchłonąć większość tej fali.
To zmniejsza obciążenie poza „szybszymi odpowiedziami”: może zapobiec thrashowi autoskalowania, wyczerpaniu połączeń z bazą i daje czas na działanie limitów i backpressure.
Backend o wysokim opóźnieniu i użytkownicy cross‑region
Jeśli backend jest daleko od użytkowników — dosłownie (cross‑region) lub logicznie (wolne zależności) — cache może obniżyć zarówno obciążenie, jak i odczuwalne opóźnienia. Serwowanie z CDN blisko użytkownika unika powtarzających się dalekosiężnych połączeń z origin.
Cache wewnętrzny też pomaga, gdy wąskim gardłem jest magazyn o wysokim opóźnieniu (zdalna baza, zewnętrzne API). Zmniejszenie liczby wywołań redukuje presję konkurencyjną i poprawia ogon opóźnień.
Kiedy cache ma mały sens
Cache ma mniejszą wartość, gdy odpowiedzi są mocno spersonalizowane (dane per‑użytkownik, wrażliwe szczegóły konta) albo gdy dane zmieniają się non‑stop (dashboardy na żywo, szybko zmieniające się stany magazynowe). W takich przypadkach współczynnik trafień jest niski, koszty unieważniania rosną, a oszczędność pracy backendu może być niewielka.
Praktyczna zasada: cache najbardziej się opłaca, gdy wielu użytkowników pyta o to samo w oknie, w którym „to samo” jest nadal ważne. Jeśli ten nakład nie istnieje, kolejna warstwa cache może dodać złożoność bez realnego zmniejszenia obciążenia.
Unieważnianie cache: główne źródło złożoności
Cache jest prosty, gdy dane się nie zmieniają. Gdy się zmieniają, pojawia się najtrudniejsza część: decyzja kiedy dane w cache przestają być zaufane i jak wszystkie warstwy dowiadują się o zmianie.
TTL: proste, ale rzadko „właściwe”
Time‑to‑live (TTL) jest atrakcyjny, bo to jedna liczba bez koordynacji. Problem w tym, że „poprawny” TTL zależy od użycia danych.
Jeśli ustawisz 5‑minutowy TTL na cenę produktu, niektórzy użytkownicy zobaczą starą cenę po zmianie — potencjalny problem prawny lub wsparcia. Jeśli ustawisz 5 sekund, możesz niewiele oszczędzić. Co gorsza, różne pola tej samej odpowiedzi zmieniają się w różnym tempie, więc pojedynczy TTL wymusza kompromis.
Unieważnianie zdarzeniowe: dokładne, ale wymagające koordynacji
Unieważnianie zdarzeniowe mówi: gdy źródło prawdy się zmienia, opublikuj zdarzenie i wyczyść/odśwież wszystkie powiązane klucze cache. To może być bardzo poprawne, ale wprowadza nową pracę:
- Każda ścieżka zapisu musi niezawodnie emitować zdarzenia.
- Każda warstwa cache musi subskrybować, retryować, deduplikować i radzić sobie z dostawą poza kolejnością.
- Potrzebujesz jasnego mapowania „co się zmieniło” → „które klucze unieważnić”.
To mapowanie jest miejscem, gdzie „dwie trudne rzeczy: nazywanie i unieważnianie” stają się praktycznie bolesne. Jeśli cache’ujesz /users/123 i jednocześnie listy „top contributors”, zmiana nazwy użytkownika dotyczy więcej niż jednego klucza. Jeśli nie śledzisz relacji, będziesz serwować mieszaną rzeczywistość.
Wzorce: cache‑aside vs write‑through vs write‑back
Cache‑aside (aplikacja czyta/pisze DB, a cache jest populowany) jest powszechne, ale unieważnianie leży po twojej stronie.
Write‑through (zapisujesz cache i DB razem) redukuje ryzyko stężałości, ale dodaje opóźnienie i złożoność obsługi błędów.
Write‑back (zapis najpierw do cache, potem flush) przyspiesza, ale czyni poprawność i odzyskiwanie dużo trudniejszym.
Stale‑while‑revalidate: świadomie „wystarczająco dobre”
Stale‑while‑revalidate serwuje lekko przestarzałe dane, odświeżając je w tle. Wygładza skoki i chroni origin, ale to decyzja produktowa: wybierasz „szybko i w większości aktualne” zamiast „zawsze najnowsze”.
Kompromisy spójności i poprawność użytkownika
Prototype caching safely
Zbuduj aplikację testową i wypróbuj reguły CDN oraz cache aplikacji przed zmianami w produkcji.
Cache zmienia to, co znaczy „poprawne”. Bez cache użytkownicy widują zazwyczaj najnowsze zatwierdzone dane (z zastrzeżeniami DB). Z cache’ami użytkownicy mogą zobaczyć dane nieco opóźnione albo niespójne między ekranami — czasem bez oczywistego błędu.
Silna vs ostateczna spójność (i co użytkownicy faktycznie zauważają)
Silna spójność dąży do „read‑after‑write”: jeśli użytkownik zaktualizuje adres wysyłkowy, kolejne ładowanie strony powinno pokazać nowy adres wszędzie. To intuicyjne, ale kosztowne, jeśli każdy zapis musi natychmiast oczyścić lub odświeżyć wiele cache’ów.
Ostateczna spójność dopuszcza krótką stężałość: aktualizacja pojawi się wkrótce, ale nie natychmiast. Użytkownicy tolerują to przy małej wadze (np. licznik odsłon), ale nie przy pieniądzach, uprawnieniach czy wszystkim, co wpływa na dalsze działania użytkownika.
Warunki wyścigu między zapisami a odświeżaniem cache
Częsty problem: zapis występuje jednocześnie z repopulacją cache:
- Użytkownik aktualizuje profil.
- Cache jest unieważniany.
- Inne żądanie ponownie wypełnia cache z repliki, która jeszcze nie otrzymała zapisu.
W efekcie cache zawiera stare dane przez cały TTL, mimo że baza jest poprawna.
Niespójność między warstwami: edge mówi A, aplikacja mówi B
Przy wielu warstwach różne części systemu mogą się nie zgadzać:
- CDN zwraca starszą stronę HTML („Adres: Stara ul.”).
- Cache aplikacji zwraca nowsze JSON („Adres: Nowa ul.”).
- UI staje się mieszaniną obu wersji.
Użytkownicy odbierają to jako „system jest zepsuty”, a nie „system jest ostatecznie spójny”.
Wersjonowanie zmniejsza niejednoznaczność:
- ETags pozwalają klientom/CDN efektywnie rewalidować i unikać serwowania przestarzałej treści, gdy reprezentacja się zmieni.
- Wersjonowane klucze cache (np.
user:123:v7) pozwalają bezpiecznie iść do przodu: zapis zwiększa wersję, a odczyty naturalnie przechodzą na nowy klucz bez konieczności idealnie synchronizowanych skasowań.
Definiowanie akceptowalnej stężałości per funkcji
Kluczowa decyzja to nie „czy stare dane są złe?”, ale gdzie są złe.
Ustal jawne budżety stężałości per funkcję (sekundy/minuty/godziny) i dopasuj je do oczekiwań użytkownika. Wyniki wyszukiwania mogą się opóźniać minutę; salda kont i uprawnienia nie powinny. To zamienia „poprawność cache” w wymaganie produktowe, które można testować i monitorować.
Tryby awarii: stampedy, hot keys i awarie cache
Cache często zawodzi w sposób „wszystko było ok, a potem wszystko przestało działać naraz”. Te awarie nie oznaczają, że cache jest zły — oznaczają, że cache koncentruje wzorce ruchu, więc małe zmiany mogą wywołać duże efekty.
Zimne starty i nierównomierne obciążenie po deployu
Po wdrożeniu, zdarzeniu autoskalowania lub purge cache, możesz mieć prawie pusty cache. Kolejna fala ruchu zmusza wiele żądań do trafienia do bazy lub zewnętrznych API.
To szczególnie boli przy szybkim wzroście ruchu, bo cache nie zdążył się nagrzać popularnymi elementami. Jeśli deployy pokrywają się ze szczytem ruchu, możesz przypadkowo wykonać własny test obciążeniowy.
Stampedy cache (thundering herd)
Stampede występuje, gdy wiele użytkowników żąda tego samego elementu dokładnie w chwili jego wygaśnięcia (lub gdy nie jest jeszcze w cache). Zamiast jedno zapytanie odbudowujące wartość, setki lub tysiące robią to naraz, przytłaczając origin.
Typowe środki zaradcze:
- Kolejkowanie żądań (request coalescing): pierwsze żądanie odbudowuje, inne czekają na wynik.
- Blokady / single‑flight: egzekwuj „tylko jeden builder” na klucz.
- Jitterowane TTL: randomizuj wygaśnięcia, by klucze nie wygasały jednocześnie.
Jeśli poprawność na to pozwala, stale‑while‑revalidate również wygładza piki.
Hot keys i nierównomierne rozłożenie
Niektóre klucze stają się nadmiernie popularne (strona główna, trendujący produkt, globalna konfiguracja). Hot keys powodują nierównomierne obciążenie: jeden węzeł cache lub jedna ścieżka backendu jest zalewana, podczas gdy inne są bezczynne.
Mitigacje: dzielić duże „globalne” klucze na mniejsze, wprowadzić sharding/partycjonowanie lub przenieść cachowanie na inną warstwę (np. udostępnić treść publiczną bliżej użytkownika przez CDN).
Gdy cache jest niedostępny: wybierz fallback
Awarie cache mogą być gorsze niż brak cache, bo aplikacje bywają zależne od niego. Zdecyduj wcześniej:
- Fail open (pominąć cache, trafić do origin): lepsza dostępność, większe ryzyko obciążenia
- Fail closed (zwracać błędy): chroni origin, gorsze UX
- Degradacja łagodna (serwować stare/domyslne): często najlepszy kompromis
Cokolwiek wybierzesz, rate limiting i circuit breakers pomagają, by awaria cache nie stała się awarią origin.
Narzut operacyjny: więcej elementów do zarządzania
Experiment with quick rollback
Używaj snapshotów i rollbacku, aby iterować nad zmianami cache bez utknięcia.
Cache może zmniejszyć obciążenie originu, ale zwiększa liczbę usług, które musisz prowadzić codziennie. Nawet „zarządzane” cache’y wymagają planowania, strojenia i reakcji na incydenty.
Więcej komponentów do utrzymania
Nowa warstwa cache to często nowy klaster (albo przynajmniej nowa warstwa) z własnymi limitami pojemności. Zespół musi ustalić rozmiar pamięci, politykę wywalania i zachowanie pod obciążeniem. Jeśli cache jest za mały, zaczyna churnować: spada hit rate, rośnie latencja, a origin i tak zostaje zalany.
Dryf konfiguracji między warstwami
Cache rzadko żyje w jednym miejscu. Możesz mieć CDN, cache aplikacji i cache bazy — każdy interpretuje reguły inaczej.
Małe rozbieżności kumulują się:
- CDN respektuje nagłówki, cache aplikacji ma twardo zakodowane TTL
- Jedna warstwa pomija na ciasteczkach, inna nie
- Reguły purge istnieją w jednym miejscu, ale nie w drugim
Z czasem pytanie „dlaczego to żądanie jest cache’owane?” staje się projektem archeologicznym.
Zadania operacyjne, których wcześniej nie było
Cache tworzy powtarzalną pracę: rozgrzewanie krytycznych kluczy po deployu, czyszczenie lub rewalidacja przy zmianach danych, resharding przy dodawaniu/usuwaniu węzłów i ćwiczenie scenariusza pełnego flushu.
Złożoność on‑call podczas incydentów
Gdy użytkownicy zgłaszają stare dane lub nagłą wolność, osoby reagujące mają teraz wielu podejrzanych: CDN, klaster cache, klient cache w aplikacji i origin. Debugowanie oznacza sprawdzanie hit rate, spike’ów eviction i timeoutów przez warstwy — a potem decyzję, czy ominąć, wyczyścić czy skalować.
Observability: udowodnij, że cache faktycznie pomaga
Cache jest wygrany tylko wtedy, gdy redukuje pracę backendu i poprawia postrzeganą przez użytkownika szybkość. Ponieważ żądania mogą być serwowane przez wiele warstw, potrzebujesz obserwowalności, która odpowie:
- Która warstwa obsłużyła to żądanie?
- Co się zmieniło, gdy nie zadziałało?
Metryki, które naprawdę wyjaśniają sytuację
Wysoki współczynnik trafień brzmi dobrze, ale może ukrywać problemy (wolne odczyty cache, ciągły churn). Monitoruj niewielki zestaw metryk per warstwa:
- Hit ratio i miss ratio, rozdzielone per endpoint lub namespace
- Latencja per warstwa (czas odczytu cache vs czas origin), idealnie p50/p95/p99
- Wskaźnik eviction i wiek przedmiotów (jak długo wpisy przeżywają)
- Wskaźniki obciążenia origin (DB QPS, CPU, nasycenie puli połączeń) skorelowane z zachowaniem cache
Jeśli hit ratio rośnie, a całkowita latencja się nie poprawia, cache może być wolny, nadmiernie seryjny lub zwracać zbyt duże ładunki.
Trace’y rozproszone przez warstwy
Distributed tracing powinien pokazywać, czy żądanie zostało obsłużone na edge, przez cache aplikacji czy przez bazę. Dodaj spójne tagi jak cache.layer=cdn|app|db i cache.result=hit|miss|stale, aby filtrować trace’y i porównywać czasy ścieżek hit vs miss.
Logi i alerty bez wycieku danych
Loguj klucze cache ostrożnie: unikaj surowych identyfikatorów użytkowników, emaili, tokenów czy pełnych URLi z query stringami. Lepiej normalizować lub hashować klucze i logować tylko krótki prefiks.
Alertuj przy nienormalnych skokach miss‑rate, nagłych wzrostach latencji na missach i sygnałach stampede (wiele jednoczesnych missów dla tego samego wzorca klucza). Oddziel dashboardy na widoki edge, app i db, plus jeden end‑to‑end łączący je wszystkie.
Ryzyka bezpieczeństwa i prywatności w cache’owanych odpowiedziach
Cache świetnie powtarza odpowiedzi szybko — ale może też powtarzać złą odpowiedź dla złego odbiorcy. Incydenty związane z cache często są ciche: wszystko wygląda szybko i zdrowo, podczas gdy dane wyciekają.
Jak wrażliwe dane trafiają do cache
Częstym błędem jest cachowanie spersonalizowanej lub poufnej treści (szczegóły konta, faktury, ticket’y supportowe, strony admina). Dzieje się to na każdej warstwie — CDN, reverse proxy czy cache aplikacji — zwłaszcza przy szerokich regułach „cacheuj wszystko”.
Inny subtelny wyciek: cachowanie odpowiedzi, która zawiera stan sesji (np. nagłówek Set-Cookie) i serwowanie tej odpowiedzi innym użytkownikom.
Błędy autoryzacji: poprawne żądanie, niewłaściwy odbiorca
Klasyczny bug: cache’ujesz HTML/JSON dla Użytkownika A i potem serwujesz go Użytkownikowi B, bo klucz cache nie uwzględniał kontekstu użytkownika. W systemach multi‑tenant tożsamość tenant musi być częścią klucza.
Zasada: jeśli odpowiedź zależy od uwierzytelnienia, ról, geo, planu cenowego czy feature flagów, klucz cache (lub logika omijająca cache) musi to uwzględniać.
Pułapki nagłówków, których nie można ignorować
Zachowanie HTTP cache jest silnie zależne od nagłówków:
Cache-Control: zapobiegaj przypadkowemu przechowywaniu z private / no-store tam, gdzie trzebaVary: upewnij się, że cache rozdziela odpowiedzi wg istotnych nagłówków (np. Authorization, Accept-Language)Set-Cookie: często sygnał, że odpowiedź nie powinna być cache’owana publicznie
Kiedy unikać cachowania całkowicie
Jeśli zgodność lub ryzyko jest wysokie — PII, dane zdrowotne/finansowe, dokumenty prawne — preferuj Cache-Control: no-store i optymalizuj po stronie serwera zamiast cachować. Dla stron mieszanych cache’uj tylko nieczułe fragmenty lub zasoby statyczne, a dane personalizowane trzymaj poza współdzielonym cache.
Koszt i ROI: czy kolejna warstwa jest warta tego?
Make ops less painful
Utwórz aplikację stagingową odzwierciedlającą stos, aby zespół mógł dopracować runbooki cache.
Warstwy cache mogą obniżyć obciążenie origin, ale rzadko są „darmowym przyspieszeniem”. Traktuj każdą nową warstwę jako inwestycję: płacisz za niższe opóźnienia i mniejszą pracę backendu w zamian za pieniądze, czas inżynierów i większą powierzchnię poprawności.
Co płacisz vs co oszczędzasz
Dodatkowe koszty infrastruktury vs zredukowane koszty origin. CDN może zredukować egress i odczyty bazy, ale zapłacisz za żądania CDN, storage cache i czasem za wywołania unieważniania. Cache aplikacji (Redis/Memcached) to koszt klastra, aktualizacji i dyżuru. Oszczędności mogą się pojawić w mniejszej liczbie replik bazy, mniejszych instancjach lub opóźnionym skalowaniu.
Zyski latency vs koszty świeżości. Każdy cache wprowadza „jak bardzo przestarzałe jest akceptowalne?”. Surowa świeżość wymaga więcej unieważnianiowej logiki (więcej missów). Tolerowana stężałość oszczędza compute, ale może kosztować zaufanie użytkownika — zwłaszcza przy cenach, dostępności czy uprawnieniach.
Czas inżynierów: tempo wprowadzania funkcji vs praca nad niezawodnością. Nowa warstwa zwykle oznacza dodatkowe ścieżki kodu, więcej testów i więcej klas incydentów do zapobiegania (stampedy, hot keys, częściowe unieważnienia). Zarezerwuj budżet na utrzymanie, nie tylko implementację.
Uruchamiaj małe eksperymenty, aby zmierzyć ROI
Zanim wdrożysz szeroko, uruchom ogranicione trial:
- Wybierz jedno endpoint lub stronę z wyraźnym ruchem (np. top 5%)
- Zdefiniuj metryki sukcesu: p95 latency, DB QPS, error rate, hit ratio cache
- Równomiernie zwiększaj obciążenie; śledź zmiany kosztów obok wydajności
- Ogranicz czas eksperymentu i miej przełącznik rollback
Prosta lista kontrolna decyzji
Dodaj nową warstwę cache tylko jeśli:
- Wąskie gardło jest udowodnione metrykami (nie domniemane)
- Jest jasny cel (np. zmniejszyć odczyty DB o 40%)
- Reguły stężałości i unieważniania są jawnie akceptowalne
- Możesz to monitorować (hit rate, evictions, latency, errors)
- Oczekiwane oszczędności przewyższają dodatkowe koszty operacyjne i inżynierskie w realistycznym horyzoncie
Praktyczne wskazówki, by zmniejszyć złożoność przy cachowaniu
Cache zwraca najszybciej, gdy traktujesz go jak funkcję produktu: potrzebuje właściciela, jasnych reguł i bezpiecznego sposobu wyłączenia.
Zaczynaj od małych zmian, wyznacz właściciela
Dodawaj jedną warstwę naraz (np. najpierw CDN lub cache aplikacji) i przypisz bezpośrednio odpowiedzialny zespół/osobę.
Zdefiniuj, kto odpowiada za:
- zmiany konfiguracji (TTL, reguły bypass)
- pojemność i zachowanie eviction
- reakcję na incydenty (co robić, gdy jest źle)
Nie komplikuj kluczy — miej je przewidywalne
Większość błędów cache to de facto „błędy kluczy”. Stosuj udokumentowaną konwencję uwzględniającą wejścia, które zmieniają odpowiedź: zakres tenant/user, locale, klasa urządzenia i istotne feature flagi.
Dodaj jawne wersjonowanie kluczy (np. product:v3:...), aby móc unieważnić bez usuwania milionów wpisów.
Wol preferować ograniczoną stężałość nad perfekcyjną świeżością
Próba utrzymania wszystkiego idealnie świeżym popycha złożoność do każdej ścieżki zapisu.
Zamiast tego zdecyduj, co jest akceptowalnie przestarzałe per endpoint i zakoduj to za pomocą:
- TTL odpowiadających oczekiwaniom biznesowym
- odświeżania w tle (serve stale while updating)
- unieważniania zdarzeniowego tylko dla naprawdę wrażliwych danych
Buduj bezpieczne domyślne zachowania przy awarii
Zakładaj, że cache będzie wolny, błędny lub nieosiągalny.
Używaj timeoutów i circuit breakerów, żeby wywołania cache nie zabiły ścieżki żądania. Zadbaj o łagodną degradację: jeśli cache zawiedzie, odwołaj się do origin z limitami, albo serwuj minimalną odpowiedź.
Wdrażaj z kontrolami i runbookami
Wdrażaj cache za canary lub procentowym rolloutem i miej przełącznik bypass (per trasę lub nagłówek) do szybkiego debugowania.
Udokumentuj runbooki: jak wyczyścić, jak zwiększyć wersję klucza, jak tymczasowo wyłączyć cache i gdzie sprawdzać metryki. Podlinkuj je w wewnętrznych instrukcjach, by on‑call mógł szybko działać.
Prototypowanie zmian cache bez hamowania delivery
Prace nad cache często stoją, bo zmiany dotykają wielu warstw (nagłówki, logika aplikacji, modele danych, plany rollback). Sposób na niższy koszt iteracji to prototypowanie całej ścieżki żądania w kontrolowanym środowisku.
Z Koder.ai, zespoły mogą szybko postawić realistyczny stos aplikacyjny (React web, Go backend z PostgreSQL i nawet Flutter mobile) z chat‑driven workflow, a następnie testować decyzje cache (TTL, projekt klucza, stale‑while‑revalidate) end‑to‑end. Funkcje takie jak planning mode pomagają udokumentować zamierzone zachowanie cache przed implementacją, a snapshots/rollback ułatwiają bezpieczne eksperymenty z konfiguracją cache lub logiką unieważniania. Gdy jesteś gotowy, możesz eksportować kod źródłowy lub wdrożyć/hostować z własnymi domenami — przydatne do prób wydajności, które muszą odzwierciedlać ruch produkcyjny.
Jeśli korzystasz z takiej platformy, traktuj ją jako uzupełnienie obserwowalności produkcyjnej: cel to szybsze iteracje nad projektem cache przy jednoczesnym zachowaniu wymagań poprawności i procedur rollback.