Dlaczego wczesne decyzje Joe Bedy dotyczące Kubernetesa wciąż mają znaczenie
Joe Beda był jedną z kluczowych postaci stojących za wczesnym projektem Kubernetesa — obok innych założycieli, którzy przenieśli wnioski z wewnętrznych systemów Google na otwartą platformę. Jego wpływ nie polegał na gonieniu modnych funkcji, lecz na wyborze prostych prymitywów, które przetrwają prawdziwy chaos produkcyjny i będą zrozumiałe dla zwykłych zespołów.
To dzięki tym wczesnym decyzjom Kubernetes stał się czymś więcej niż „narzędziem do kontenerów”. Zamienił się w powtarzalne jądro współczesnych platform aplikacyjnych.
Orkiestracja kontenerów — prosto i jasno
„Orkiestracja kontenerów” to zestaw reguł i automatyzacji, które utrzymują aplikację w działaniu, gdy maszyny zawodzą, ruch rośnie, lub wdrażasz nową wersję. Zamiast człowieka pilnującego serwerów, system planuje kontenery na maszynach, restartuje je po awarii, rozkłada obciążenie dla odporności oraz organizuje sieć, żeby użytkownicy mogli do nich dotrzeć.
Bałagan przed Kubernetes
Zanim Kubernetes stał się powszechny, zespoły często sklejały skrypty i niestandardowe narzędzia, aby odpowiedzieć na podstawowe pytania:
- gdzie teraz powinien działać ten kontener?
- co się stanie, jeśli węzeł padnie o 2 w nocy?
- jak wdrażać bez przestojów?
- jak usługi odnajdują się nawzajem, gdy adresy IP ciągle się zmieniają?
Takie systemy DIY działały — dopóki nie przestawały. Każda nowa aplikacja czy zespół dodawały więcej jednorazowej logiki, a uzyskanie spójności operacyjnej było trudne.
O czym jest ten artykuł
Ten tekst omawia wczesne decyzje projektowe Kubernetesa ("kształt" Kubernetesa) i dlaczego nadal wpływają na nowoczesne platformy: model deklaratywny, kontrolery, Pody, etykiety, Serwisy, silne API, spójny stan klastra, wtyczkowe planowanie i rozszerzalność. Nawet jeśli nie uruchamiasz Kubernetesa bezpośrednio, prawdopodobnie korzystasz z platformy zbudowanej na tych pomysłach — albo zmagasz się z tymi samymi problemami.
Problem, który Kubernetes miał rozwiązać
Przed Kubernetesem „uruchamianie kontenerów” zwykle oznaczało uruchamianie kilku kontenerów. Zespoły sklejały bashowe skrypty, cron, obrazy golden, i garść narzędzi ad-hoc, żeby wdrożyć. Gdy coś się zepsuło, naprawa często żyła w głowie kogoś lub w README, któremu nikt nie ufał. Operacje były strumieniem jednorazowych interwencji: restartowanie procesów, zmiana konfiguracji load balancerów, czyszczenie dysków i zgadywanie, którą maszynę można bezpiecznie ruszyć.
Kontenery w skali tworzyły nowe tryby awarii
Kontenery ułatwiły pakowanie, ale nie usunęły problemów produkcyjnych. W skali system zawodzi więcej razy i na więcej sposobów: węzły znikają, sieci się dzielą, obrazy wdrażają się niespójnie, a obciążenia dryfują od tego, co myślisz, że działa. „Proste” wdrożenie może przerodzić się w kaskadę — niektóre instancje zaktualizowane, inne nie, niektóre zablokowane, inne zdrowe, ale niedostępne.
Prawdziwy problem nie polegał na uruchamianiu kontenerów. Chodziło o utrzymanie właściwych kontenerów w właściwym kształcie mimo ciągłych zmian.
Spójny model niezależny od infrastruktury
Zespoły też żonglowały różnymi środowiskami: sprzęt on‑prem, maszyny wirtualne, wczesne chmury i różne konfiguracje sieci i storage. Każda platforma miała własny słownik i wzorce awarii. Bez wspólnego modelu każda migracja oznaczała przepisywanie narzędzi operacyjnych i przeszkolenie ludzi.
Kubernetes miał na celu zaoferować jeden, spójny sposób opisu aplikacji i ich potrzeb operacyjnych, niezależnie od miejsca, gdzie znajdują się maszyny.
Deweloperzy chcieli samoobsługi: wdrażać bez ticketów, skalować bez proszenia o zasoby i cofać zmiany bez dramatu. Zespoły operacyjne chciały przewidywalności: standaryzowane health checki, powtarzalne wdrożenia i jasne źródło prawdy o tym, co powinno działać.
Kubernetes nie próbował być jedynie wyrafinowanym schedularem. Chciał być fundamentem niezawodnej platformy aplikacyjnej — takiej, która zamienia chaotyczną rzeczywistość w system, nad którym można się racjonalnie zapanować.
Decyzja 1: Model deklaratywny, desired-state
Jednym z najbardziej wpływowych wczesnych wyborów było uczynienie Kubernetesa deklaratywnym: opisujesz, czego chcesz, a system pracuje, by dopasować rzeczywistość do tego opisu.
Desired state wyjaśniony na przykładzie termostatu
Termostat to prosty przykład: nie włączasz pieca co kilka minut ręcznie. Ustawiasz docelową temperaturę — powiedzmy 21°C — i termostat stale sprawdza pokój i reguluje ogrzewanie, aby utrzymać temperaturę bliską temu celowi.
Kubernetes działa podobnie. Zamiast mówić klastrowi krok po kroku „uruchom ten kontener na tej maszynie, a potem restartuj, jeśli się zepsuje”, deklarujesz wynik: „chcę 3 kopie tej aplikacji”. Kubernetes stale sprawdza, co rzeczywiście działa, i koryguje odchylenia.
Mniej ręcznych kroków, mniej niespodzianek
Konfiguracja deklaratywna redukuje ukryty „checklist” operacyjny, który często żyje w czyjejś głowie lub w częściowo zaktualizowanym runbooku. Zastosujesz konfigurację, a Kubernetes zajmie się mechaniką — umiejscowieniem, restartami i rekonsyliacją zmian.
Ułatwia też przegląd zmian: zmiana widoczna jest jako diff w konfiguracji, a nie jako seria jednorazowych poleceń.
Powtarzalność między środowiskami
Ponieważ stan pożądany jest zapisany, możesz używać tego samego podejścia w dev, staging i prod. Środowisko może się różnić, ale intencja pozostaje spójna, co sprawia, że wdrożenia są bardziej przewidywalne i łatwiejsze do audytu.
Kompromisy
Systemy deklaratywne mają krzywą nauki: trzeba myśleć w kategoriach „co powinno być prawdą”, a nie „co robię dalej”. Polegają też mocno na dobrych domyślnych ustawieniach i jasnych konwencjach — bez nich zespoły mogą tworzyć konfiguracje, które technicznie działają, ale są trudne do zrozumienia i utrzymania.
Decyzja 2: Pętle kontrolne (kontrolery) jako silnik
Kubernetes nie odniósł sukcesu dlatego, że potrafił uruchomić kontenery raz — odniósł sukces, bo potrafił je utrzymać poprawnie w czasie. Duży ruch projektowy to uczynienie „pętli kontrolnych” (kontrolerów) rdzeniem systemu.
Czym jest kontroler
Kontroler to prosta pętla:
- spójrz na stan bieżący (co naprawdę działa)
- porównaj go ze stanem pożądanym (co zadeklarowano)
- podejmij działania, aż obie wartości się zrównają
To bardziej autopilot niż jednorazowe zadanie. Nie „opiekujesz się” obciążeniami; deklarujesz, czego chcesz, a kontrolery stale kierują klastrem ku temu rezultatowi.
Obsługa awarii, utraty węzłów i dryfu
Ten wzorzec tłumaczy, dlaczego Kubernetes jest odporny, gdy zdarzają się realne problemy:
- awarie kontenerów: kontroler zauważa mniej uruchomionych instancji niż jest wymagane i uruchamia zastępcze
- utraty węzła: gdy węzeł znika, kontrolery przerysowują Pody gdzie indziej, aby przywrócić pożądaną liczbę
- dryf konfiguracji: jeśli ktoś zmieni lub usunie zasób, kontrolery rekoncyliują różnicę i naprawiają ją
Zamiast traktować błędy jako wyjątkowe przypadki, kontrolery traktują je jako rutynowe „niedopasowania stanu” i rozwiązują je w ten sam sposób za każdym razem.
Dlaczego skaluje lepiej niż skrypty
Tradycyjne skrypty automatyzujące często zakładają stabilne środowisko: wykonaj krok A, potem B, potem C. W systemach rozproszonych te założenia ciągle zawodzą. Kontrolery skalują się lepiej, bo są idempotentne (bezpieczne do wielokrotnego uruchamiania) i eventualnie spójne (stale próbują doprowadzić stan do celu).
Przykłady codzienne: Deployment i ReplicaSet
Jeśli używałeś Deployment, korzystałeś z pętli kontrolnej. Pod spodem Kubernetes używa kontrolera ReplicaSet, aby zapewnić żądaną liczbę Podów — a kontroler Deployment zarządza bezpiecznymi rolling update’ami i rollbackami.
Decyzja 3: Pody jako najmniejsza jednostka planowania
Kubernetes mógł planować „po prostu kontenery”, ale zespół Joe Bedy wprowadził Pody jako najmniejszą jednostkę, którą klaster umieszcza na maszynie. Kluczowa idea: wiele aplikacji to nie pojedynczy proces, lecz mała grupa ściśle powiązanych procesów, które muszą żyć razem.
Dlaczego Pody zamiast pojedynczych kontenerów?
Pod to opakowanie dla jednego lub kilku kontenerów, które dzielą wspny los: startują razem, działają na tym samym węźle i skalują się razem. Dzięki temu wzorce jak sidecar są naturalne — na przykład przesyłacz logów, proxy, reload konfiguracji czy agent bezpieczeństwa, które zawsze towarzyszą głównej aplikacji.
Zamiast każdej aplikacji uczyć integracji z tymi pomocnikami, Kubernetes pozwala zapakować je jako oddzielne kontenery, które nadal zachowują się jak jedna jednostka.
Co Pody umożliwiły dla sieci i storage
Pody uczyniły praktycznymi dwa ważne założenia:
- Sieć: kontenery w Podzie dzielą tożsamość sieciową (jeden adres IP i przestrzeń portów). Główna aplikacja może rozmawiać z sidecarem przez
localhost, co jest proste i szybkie.
- Storage: kontenery w Podzie mogą dzielić wolumeny. Helper może zapisywać pliki, które główna aplikacja odczytuje, bez skomplikowanych pośredników.
Te wybory zmniejszyły potrzebę tworzenia niestandardowego „kleju”, zachowując jednocześnie izolację procesów.
Gdzie Pody mylą początkujących
Nowi użytkownicy często oczekują „jeden kontener = jedna aplikacja”, a potem potykają się o koncepcje na poziomie Poda: restarty, adresy IP i skalowanie. Wiele platform upraszcza to, dostarczając opiniotwórcze szablony (np. „web service”, „worker”, „job”), które generują Pody w tle — dzięki czemu zespoły korzystają z korzyści sidecarów i współdzielonych zasobów bez codziennego myślenia o mechanice Podów.
Decyzja 4: Etykiety i selektory dla luźnego powiązania
Zachowaj pełną własność kodu
Zachowaj pełną kontrolę nad kodem — pobierz źródła, gdy chcesz głębszej customizacji lub własnego pipeline'u.
Cicho potężnym wczesnym wyborem było traktowanie etykiet jako pierwszorzędnych metadanych i selektorów jako głównego sposobu „znajdowania” zasobów. Zamiast sztywnego wiązania relacji (np. „te dokładnie trzy maszyny uruchamiają moją aplikację”), Kubernetes zachęca do opisywania grup przez wspólne atrybuty.
Etykiety: elastyczne tagi na wszystkim
Etykieta to prosta para klucz/wartość, którą dołączasz do zasobów — Podów, Deploymentów, Węzłów, Namespace’ów i więcej. Działają jak spójne, przeszukiwalne „tagi”:
app=checkoutenv=prodtier=frontend
Ponieważ etykiety są lekkie i definiowane przez użytkownika, możesz modelować rzeczywistość swojej organizacji: zespoły, centra kosztów, strefy zgodności, kanały wydań czy cokolwiek, co ma znaczenie dla operacji.
Selektory: relacje bez ciasnych zależności
Selektory to zapytania po etykietach (np. „wszystkie Pody, gdzie app=checkout i env=prod”). To bije na głowę stałe listy hostów, ponieważ system może dostosować się, gdy Pody są przenoszone, skalowane lub zastępowane podczas rolloutów. Twoja konfiguracja pozostaje stabilna, nawet gdy podstawa się zmienia.
Dynamiczne grupowanie w skali
Ten projekt skaluje się operacyjnie: nie zarządzasz tysiącami tożsamości instancji — zarządzasz kilkoma znaczącymi zestawami etykiet. To istota luźnego powiązania: komponenty łączą się z grupami, których skład może bezpiecznie się zmieniać.
Etykiety robią więcej niż grupowanie
Gdy etykiety istnieją, stają się wspólnym słownikiem platformy. Służą do routingu ruchu (Service), granic polityk (NetworkPolicy), filtrów obserwowalności (metryki/logi), a nawet śledzenia kosztów i rozliczeń. Jeden prosty pomysł — taguj rzeczy konsekwentnie — otwiera cały ekosystem automatyzacji.
Decyzja 5: Serwisy dla stabilnej sieci
Kubernetes potrzebował sposobu, by sieć wydawała się przewidywalna, mimo że kontenery są zmienne. Pody są zastępowane, przenoszone i skalowane — więc ich IP i konkretne maszyny się zmieniają. Główny pomysł Service jest prosty: zapewnij stabilne „wejście” do zmieniającego się zbioru Podów.
Stabilny dostęp do zmieniających się Podów
Service daje stałe wirtualne IP i nazwę DNS (np. payments). Za tą nazwą Kubernetes ciągle śledzi, które Pody pasują do selektora Service i kieruje tam ruch. Jeśli Pod padnie i pojawi się nowy, Service nadal wskazuje właściwe miejsce bez zmian w ustawieniach aplikacji.
Odkrywanie usług, które uprościło konfigurację
To podejście usunęło wiele ręcznych połączeń. Zamiast wypiekać adresy IP w plikach konfiguracyjnych, aplikacje mogą polegać na nazwach. Wdrażasz aplikację, wdrażasz Service, a inne komponenty odnajdują ją przez DNS — bez niestandardowego rejestru czy twardo zakodowanych endpointów.
Wbudowane równoważenie ruchu dla niezawodności
Service wprowadził też domyślne rozkładanie ruchu między zdrowe endpointy. Dzięki temu zespoły nie musiały budować własnych load balancerów dla każdej mikrousługi. Rozkład ruchu zmniejsza blast radius awarii pojedynczego Poda i sprawia, że rolling update’y są mniej ryzykowne.
Ograniczenia — i jak Ingress/Gateway to rozszerzają
Service świetnie sprawdza się dla L4 (TCP/UDP), ale nie modeluje reguł routingu HTTP, terminacji TLS czy polityk brzegowych. Tu wchodzą Ingress i coraz częściej Gateway API: budują na Service’ach, obsługując hostname’y, ścieżki i zewnętrzne punkty wejścia w bardziej uporządkowany sposób.
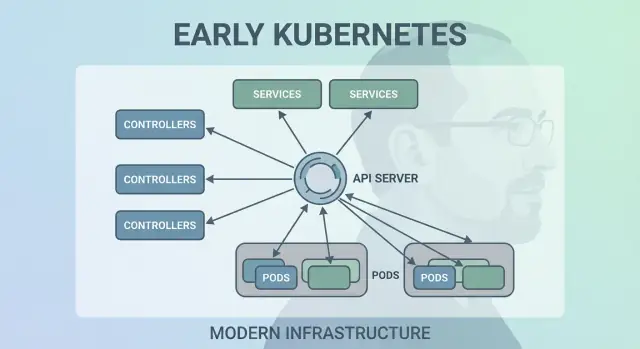
Decyzja 6: API jako powierzchnia produktu
Jednym z cicho radykalnych wczesnych wyborów było traktowanie Kubernetesa jako API, z którym się integrujesz — a nie monolitycznego narzędzia, którego „używasz”. To podejście API-first sprawiło, że Kubernetes działał mniej jak produkt, który klika się w UI, a bardziej jak platforma, którą można rozszerzać, skryptować i rządzić.
Gdy API jest powierzchnią produktu, zespoły platformowe mogą standaryzować jak aplikacje są opisywane i zarządzane, niezależnie od tego, jakie UI, pipeline czy wewnętrzne portale stoją nad tym. „Wdrożenie aplikacji” staje się „złożeniem i aktualizacją obiektów API” (Deploymenty, Service’y, ConfigMapy), co jest czystszym kontraktem między zespołami aplikacyjnymi a platformą.
Narzędzia, UI i automatyzacja bez specjalnych furtek
Ponieważ wszystko przechodzi przez to samo API, nowe narzędzia nie potrzebują uprzywilejowanych backdoorów. Dashboardy, kontrolery GitOps, silniki polityk i systemy CI/CD mogą działać jako normalni klienci API z odpowiednio ograniczonymi uprawnieniami.
Ta symetria ma znaczenie: te same zasady, autoryzacja, audyt i kontroli admission stosują się, bez względu na to, czy żądanie pochodzi od osoby, skryptu czy wewnętrznego UI platformy.
Wersjonowanie i kompatybilność dla długożyjących klastrów
Wersjonowanie API pozwala ewoluować Kubernetes bez łamania każdego klastra i narzędzia z dnia na dzień. Deklaracje można wygaszać stopniowo; kompatybilność testować; aktualizacje planować. Dla organizacji utrzymujących klastry przez lata to różnica między „możemy aktualizować” a „utknęliśmy”.
Co naprawdę reprezentuje kubectl
kubectl to nie Kubernetes — to jeden klient. Ten model mentalny popycha zespoły do myślenia o workflowach API: możesz zamienić kubectl na automatyzację, webowe UI lub customowy portal, a system pozostanie spójny, bo kontraktem jest samo API.
Decyzja 7: Centralny stan klastra (etcd) i spójność
Uruchom stos webowy i API
Stwórz aplikację webową w React oraz backend w Go z PostgreSQL z prostego czatu.
Kubernetes potrzebował jednego „źródła prawdy” o tym, jak klaster powinien wyglądać teraz: które Pody istnieją, które węzły są zdrowe, do czego wskazują Service’y i które obiekty są aktualizowane. To zapewnia etcd.
Co robi etcd (prosto)
etcd to baza danych dla control plane. Gdy tworzysz Deployment, skalujesz ReplicaSet lub aktualizujesz Service, pożądana konfiguracja zapisywana jest w etcd. Kontrolery i inne komponenty kontrolne obserwują ten zapisany stan i pracują, by doprowadzić rzeczywistość do zgodności.
Dlaczego spójność ma znaczenie, gdy wiele komponentów działa równocześnie
Klastr Kubernetes jest pełen poruszających się części: schedulerów, kontrolerów, kubeletów, autoscalerów i admission checks — wszystkie mogą reagować jednocześnie. Jeśli czytają różne wersje „prawdy”, pojawiają się wyścigi — jak dwa komponenty podejmujące sprzeczne decyzje wobec tego samego Podu.
Silna spójność etcd gwarantuje, że gdy control plane mówi „to jest bieżący stan”, wszyscy się z nim zgadzają. Ta zgoda sprawia, że pętle kontrolne są przewidywalne, a nie chaotyczne.
Jak wpływa to na backupy, aktualizacje i odzyskiwanie po awarii
Ponieważ etcd przechowuje konfigurację klastra i historię zmian, to właśnie je chronisz podczas:
- Backupów: bez snapshotu etcd nie przywrócisz wiarygodnie obiektów klastra.
- Aktualizacji: dbanie o zdrowie etcd i snapshottowanie zmniejsza ryzyko podczas upgrade’u.
- Odzyskiwania po awarii: przywrócenie etcd często jest najszybszą drogą do odtworzenia control plane z tą samą intencją.
Praktyczne wskazówki
Traktuj stan control-plane jak dane krytyczne. Rób regularne snapshoty etcd, testuj przywracanie i przechowuj backupy poza klastrem. Jeśli korzystasz z zarządzanego Kubernetesa, dowiedz się, co twój dostawca kopiuje — i co nadal musisz zabezpieczać sam (np. wolumeny trwałe i dane aplikacji).
Decyzja 8: Wtyczkowe planowanie i świadomość zasobów
Kubernetes nie traktował „gdzie uruchomić obciążenie” jako drobiazgu. Wczesne założenie było takie, że scheduler to odrębny komponent z jasnym zadaniem: dopasować Pody do węzłów, które rzeczywiście mogą je uruchomić, korzystając z aktualnego stanu klastra i wymagań Poda.
Jak scheduler dopasowuje obciążenia do węzłów
Na wysokim poziomie planowanie to decyzja w dwóch krokach:
- Filtracja: odrzuć węzły, które nie spełniają twardych ograniczeń (brak CPU/pamięci, brak wymaganych etykiet, niekompatybilne tainty, zajęte porty itp.).
- Skoring: oceń pozostałe węzły według preferencji (rozłożyć po strefach, upchać dla efektywności, unikać głośnych sąsiadów, honorować reguły affinity).
Taka struktura pozwoliła na rozwój planowania bez pisania wszystkiego od nowa.
Rozdział obowiązków: scheduler vs runtime vs networking
Kluczowym wyborem było czyste rozdzielenie odpowiedzialności:
- scheduler decyduje o umiejscowieniu;
- container runtime (i kubelet) wykonuje uruchomienie na wybranym węźle;
- warstwa sieciowa zapewnia łączność po uruchomieniu.
Dzięki temu ulepszenia w jednej warstwie (np. nowy plugin CNI) nie wymuszają zmiany modelu planowania.
Ograniczenia i priorytety rosły naturalnie
Świadomość zasobów zaczęła się od requests i limits, dając schedulerowi sensowne sygnały zamiast zgadywania. Później dodano bogatsze kontrolki — node affinity/anti-affinity, pod affinity, priorities and preemption, taints and tolerations, oraz rozkład uwzględniający topologię — wszystko zbudowane na tej samej podstawie.
Wpływ współczesny: multi-tenant i efektywne kosztowo umieszczanie
Takie podejście umożliwia dzisiejsze współdzielone klastry: zespoły mogą izolować krytyczne usługi za pomocą priorytetów i taintów, a jednocześnie wszyscy korzystają z wyższej wykorzystalności. Dzięki lepszemu bin-packingowi i kontrolom topologicznym platformy mogą umieszczać obciążenia bardziej efektywnie kosztowo, nie tracąc niezawodności.
Decyzja 9: Rozszerzalność zamiast „jednego wbudowanego sposobu”
Chroń postęp podczas iteracji
Zapisz znany, dobry stan przed dużymi zmianami, aby móc szybko przywrócić działający system.
Kubernetes mógł dostarczyć pełne, jednoznaczne doświadczenie PaaS — buildpacki, reguły routingu aplikacji, zadania tła, konwencje konfiguracji i więcej. Zamiast tego Joe Beda i wczesny zespół utrzymali jądro skoncentrowane na mniejszej obietnicy: niezawodnie uruchomić i naprawiać obciążenia, udostępnić je i zapewnić spójne API do automatyzacji.
Dlaczego Kubernetes nie został kompletnym PaaS
„Kompletny PaaS” narzucałby jeden workflow i jedne kompromisy wszystkim. Kubernetes celował w szersze fundamenty, które mogły wspierać różne style platform — prostotę w stylu Heroku, zarządzanie korporacyjne, batch + ML pipeliny czy surową kontrolę infrastruktury — bez zamykania w jednym paradygmacie.
Jak rozszerzenia pozwalają bezpiecznie dodawać funkcje
Mechanizmy rozszerzalności Kubernetesa stworzyły kontrolowany sposób rozbudowy możliwości:
- CRD (CustomResourceDefinitions) pozwalają dodawać nowe typy API (np.
Certificate czy Database), które wyglądają jak natywne.
- Kontrolery/operatorzy rekoncyliują te nowe zasoby tym samym deklaratywnym wzorcem, co wbudowane komponenty.
- Admission controllers/webhooki egzekwują polityki (bezpieczeństwo, nazewnictwo, limity) i ustawiają domyślne wartości na granicy API.
Dzięki temu zespoły platformowe i dostawcy mogą dostarczać funkcje jako dodatki, korzystając jednocześnie z prymitywów Kubernetes jak RBAC, namespaces i logi audytu.
Korzyści i główne ryzyko
Dla dostawców to szansa na wyróżnienie produktu bez forka Kubernetesa. Dla zespołów wewnętrznych to możliwość budowy „platformy na Kubernetesie” dopasowanej do potrzeb organizacji.
Ryzyko to rozrost ekosystemu: za dużo CRD, nakładające się narzędzia i niespójne konwencje. Zarządzanie — standardy, własność, wersjonowanie i reguły wygaszania — staje się częścią pracy platformowej.
Wczesne wybory Kubernetesa nie stworzyły jedynie schedulera kontenerów — stworzyły powtarzalne jądro platformy. Dlatego wiele współczesnych wewnętrznych platform developerskich (IDP) to w istocie „Kubernetes plus opiniotwórcze workflowy”. Model deklaratywny, kontrolery i spójne API pozwoliły budować wyższej warstwy produkty — bez ponownego wynajdywania wdrażania, rekonsyliacji i odkrywania usług za każdym razem.
Kubernetes jako wspólna płaszczyzna kontrolna
Ponieważ API jest powierzchnią produktu, dostawcy i zespoły platformowe mogą standaryzować jedną płaszczyznę kontrolną i budować na niej różne doświadczenia: GitOps, zarządzanie multi-klastrowe, polityki, katalogi usług i automatyzację wdrożeń. To duży powód, dla którego Kubernetes stał się wspólnym mianownikiem dla platform cloud native: integracje celują w API, a nie w konkretne UI.
Co pozostało trudne (dzień-2)
Nawet przy czystych abstrakcjach najtrudniejsza praca to nadal operacje:
- bezpieczeństwo: tożsamość, polityki sieci, sekrety i zaufanie łańcucha dostaw
- aktualizacje: wersje Kubernetesa, CRD i dodatków poruszających się w różnych tempach
- niezawodność: debugowanie kontrolerów, błędnych konfiguracji i głośnych sąsiadów
Zadawaj pytania, które ujawnią dojrzałość operacyjną:
- jak obsługiwane są aktualizacje i jaka jest historia rollbacków?
- które części to standardowy Kubernetes, a które to własne rozszerzenia?
- jakie są zabezpieczenia (polityki, domyślne ustawienia, szablony), by zapobiec błędom?
- jak obserwowalny jest system (zdarzenia, logi, audyt) i kto odpowiada za incydenty?
Dobra platforma redukuje obciążenie poznawcze bez ukrywania control plane lub robienia „escape hatch” bolesnymi.
Jedna praktyczna perspektywa: czy platforma pomaga zespołom przejść od „pomysł → działająca usługa” nie zmuszając wszystkich do zostania ekspertami Kubernetesa od pierwszego dnia? Narzędzia w kategorii „vibe-coding” — jak Koder.ai — idą w tym kierunku, pozwalając zespołom generować rzeczywiste aplikacje z czatu (frontend w React, backend w Go z PostgreSQL, mobilne we Flutter), a następnie szybko iterować przy funkcjach takich jak tryb planowania, migawki i rollback. Niezależnie od tego, czy przyjmiesz coś takiego, czy zbudujesz własne portal, cel jest taki sam: zachować mocne prymitywy Kubernetesa przy jednoczesnym zmniejszeniu narzutu workflowów.
Najważniejsze wnioski i praktyczne lekcje
Kubernetes może wydawać się skomplikowany, ale większość jego „dziwactw” jest intencjonalna: to zbiór małych prymitywów zaprojektowanych do komponowania wielu typów platform.
Dwa powszechne nieporozumienia
Po pierwsze: „Kubernetes to tylko orkiestracja Dockera.” Kubernetes to nie tylko uruchamianie kontenerów. To ciągłe rekonsylowanie stanu pożądanego (co chcesz mieć uruchomione) ze stanem rzeczywistym (co rzeczywiście działa), w obliczu awarii, rolloutów i zmiennego zapotrzebowania.
Po drugie: „Jeśli użyjemy Kubernetesa, wszystko stanie się mikroserwisami.” Kubernetes wspiera mikroserwisy, ale też monolity, zadania wsadowe i wewnętrzne platformy. Jednostki (Pody, Service’y, etykiety, kontrolery i API) są neutralne — to ty decydujesz o architekturze.
Skąd pochodzi złożoność
Trudne rzeczy zwykle nie wynikają z YAML czy Podów — to sieć, bezpieczeństwo i praca wielozespołowa: tożsamość i dostęp, zarządzanie sekretami, polityki, ingress, obserwowalność, kontrola łańcucha dostaw i tworzenie zabezpieczeń, by zespoły mogły wdrażać bez wchodzenia sobie w drogę.
Wnioski na poziomie decyzji, które możesz zastosować
Planując, myśl w kategoriach pierwotnych postanowień:
- preferuj deklaratywne workflowy i automatyzację, która może rekoncyliować dryf
- używaj etykiet/selektorów, by utrzymać niskie sprzężenie między zespołami i komponentami
- traktuj API jak produkt: wersjonowanie, konwencje i jasna odpowiedzialność mają znaczenie
Praktyczny następny krok
Zmapuj swoje rzeczywiste wymagania do prymitywów Kubernetesa i warstw platformy:
-
obciążenia → Pody/Deploymenty/Joby
-
łączność → Service’y/Ingress
-
operacje → kontrolery, polityki i obserwowalność
Jeśli oceniasz lub standaryzujesz, zapisz to mapowanie i przejrzyj je ze stakeholderami — potem buduj platformę stopniowo wokół luk, a nie wokół modnych trendów.
Jeśli chcesz też przyspieszyć stronę „budowy” (nie tylko „uruchamiania”), przemyśl, jak workflow dostarczania zamienia intencję w wdrożone usługi. Dla niektórych zespołów to zestaw kuratorowanych szablonów; dla innych to asystowane AI, jak Koder.ai, które potrafi wygenerować bazową usługę szybko, a potem wyeksportować kod do głębszej customizacji — przy zachowaniu korzyści wynikających z projektowych decyzji Kubernetesa pod spodem.