03 lis 2025·8 min
Wzorce SaaS wielonajemcowego: izolacja, skalowanie i projektowanie z AI
Poznaj typowe wzorce SaaS wielonajemcowego, kompromisy dotyczące izolacji najemców oraz strategie skalowania. Zobacz, jak architektury generowane przez AI przyspieszają projektowanie i przeglądy.
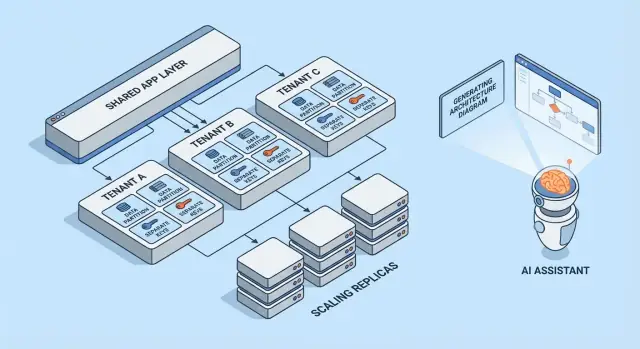
Co oznacza wielonajemczość (bez żargonu)
Wielonajemczość oznacza, że jeden produkt programowy obsługuje wielu klientów (najemców) z tego samego działającego systemu. Każdy najemca ma wrażenie, że „ma własną aplikację”, ale za kulisami współdzielone są elementy infrastruktury — takie jak te same serwery WWW, ten sam kod i często ta sama baza danych.
Przydatny model mentalny to budynek mieszkalny. Każdy ma swoją zamkniętą jednostkę (swoje dane i ustawienia), ale wszyscy dzielą windę, instalacje i ekipę konserwacyjną (obliczenia aplikacji, magazyn i operacje).
Dlaczego zespoły wybierają wielonajemczość
Większość zespołów nie wybiera SaaS wielonajemcowego, bo to modne — wybierają je, bo jest efektywne:
- Niższy koszt na klienta: współdzielana infrastruktura zwykle jest tańsza niż uruchamianie pełnego stosu dla każdego klienta.
- Prostsze operacje: jedna platforma do monitorowania, patchowania i zabezpieczania (zamiast setek małych wdrożeń).
- Szybsze wdrażanie: poprawki trafiają do wszystkich równocześnie, dzięki czemu unikasz „dryfu wersji” między klientami.
Gdzie to może pójść źle
Dwa klasyczne tryby awarii to bezpieczeństwo i wydajność.
W kwestii bezpieczeństwa: jeśli granice między najemcami nie są wszędzie egzekwowane, błąd może przeciekać dane między klientami. Takie wycieki rzadko są efektami spektakularnych „włamań” — zwykle to zwykłe pomyłki, jak brakujący filtr, źle skonfigurowana kontrola uprawnień albo zadanie w tle, które działa bez kontekstu najemcy.
W kwestii wydajności: współdzielone zasoby oznaczają, że jeden obciążony najemca może spowalniać innych. Efekt „hałaśliwego sąsiada” może objawiać się jako wolne zapytania, skoki obciążenia lub pojedynczy klient zużywający nieproporcjonalnie dużo zasobów API.
Krótkie zapowiedzenie omawianych wzorców
W artykule opisano elementy, których zespoły używają, aby zarządzać tymi ryzykami: izolację danych (baza danych, schemat lub wiersze), świadomą tożsamość i uprawnienia dla najemców, mechanizmy przeciw hałaśliwym sąsiadom oraz wzorce operacyjne do skalowania i zarządzania zmianami.
Główny kompromis: izolacja kontra efektywność
Wielonajemczość to wybór miejsca na spektrum: ile współdzielisz między najemcami, a ile dedykujesz dla każdego z nich. Każdy poniższy wzorzec architektoniczny to inny punkt na tej linii.
Współdzielone kontra dedykowane zasoby: sedno sprawy
Na jednym końcu najemcy współdzielą niemal wszystko: te same instance aplikacji, te same bazy, te same kolejki, te same cache — separowane logicznie przez identyfikatory najemcy i reguły dostępu. To zwykle najtańsze i najłatwiejsze w prowadzeniu, bo pulujesz pojemność.
Na drugim końcu najemcy dostają własny „kawałek” systemu: oddzielne bazy danych, oddzielne zasoby obliczeniowe, czasami nawet oddzielne wdrożenia. To zwiększa bezpieczeństwo i kontrolę, ale także nakład operacyjny i koszty.
Dlaczego izolacja i koszty idą w przeciwnych kierunkach
Izolacja zmniejsza prawdopodobieństwo, że jeden najemca będzie miał dostęp do danych innego, wykorzysta cudze zasoby wydajnościowe lub wpłynie na nietypowe wzorce użycia. Ułatwia też spełnienie niektórych wymogów audytowych i zgodności.
Efektywność rośnie, gdy rozkładasz nieużywaną pojemność na wielu najemców. Współdzielana infrastruktura pozwala uruchomić mniej serwerów, utrzymać prostsze pipeline'y wdrożeń i skalować względem zagregowanego zapotrzebowania zamiast najgorszego scenariusza per-najemca.
Typowe czynniki decyzyjne
Twoje „właściwe” miejsce na spektrum rzadko jest filozoficzne — zależy od ograniczeń:
- SLA i oczekiwania klientów: ścisłe wymagania dotyczące dostępności lub opóźnień zmuszają do większej izolacji.
- Zgodność i lokalizacja danych: wymagania mogą wymusić dedykowane magazyny lub środowiska.
- Etap wzrostu: produkty we wczesnej fazie często zaczynają od silniejszego współdzielenia, żeby szybciej się rozwijać; później mogą wprowadzać opcje dedykowane dla dużych klientów.
- Dojrzałość operacyjna: więcej izolacji zwykle oznacza więcej rzeczy do monitorowania, poprawiania i migracji.
Prosty model decyzyjny
Zadaj dwa pytania:
-
Jaki jest promień zniszczeń, jeśli jeden najemca zachowa się źle lub zostanie przejęty?
-
Jaki jest koszt biznesowy zmniejszenia tego promienia?
Jeśli promień musi być minimalny, wybierz więcej komponentów dedykowanych. Jeśli najważniejsze są koszty i szybkość, współdziel więcej — i zainwestuj w silne kontrole dostępu, limity i monitorowanie per-najemca, aby współdzielenie było bezpieczne.
Modele wielonajemczości w pigułce
Wielonajemczość to nie jedna architektura — to zestaw sposobów dzielenia (lub nie) infrastruktury między klientami. Najlepszy model zależy od potrzeb izolacji, liczby oczekiwanych najemców i poziomu nakładu operacyjnego, który zespół może udźwignąć.
1) Pojedynczy najemca (dedykowany) — punkt odniesienia
Każdy klient dostaje własny stos aplikacji (albo przynajmniej własne odizolowane środowisko wykonawcze i bazę danych). To najprostsze do rozumienia pod kątem bezpieczeństwa i wydajności, ale zwykle najdroższe na klienta i może spowolnić skalowanie operacji.
2) Wspólna aplikacja + wspólna baza — najniższy koszt, największa ostrożność
Wszyscy najemcy działają na tej samej aplikacji i bazie danych. Koszty zazwyczaj są najniższe, ale trzeba być bardzo skrupulatnym w kwestii kontekstu najemcy (zapytania, cache, zadania w tle, eksporty analityczne). Jeden błąd może spowodować przeciek danych między najemcami.
3) Wspólna aplikacja + oddzielne bazy — silniejsza izolacja, więcej operacji
Aplikacja jest współdzielona, ale każdy najemca ma własną bazę danych (lub instancję bazy). Poprawia to kontrolę promienia awarii, ułatwia backup/restore na poziomie najemcy i upraszcza rozmowy o zgodności. Kosztem jest operacyjność: więcej baz do provisioningu, monitorowania, migracji i zabezpieczania.
4) Modele hybrydowe dla „dużych” najemców
Wiele produktów SaaS miesza podejścia: większość klientów żyje we współdzielonej infrastrukturze, a duzi lub regulowani klienci dostają dedykowane bazy lub compute. Hybryda to często praktyczne rozwiązanie, ale wymaga jasnych zasad: kto kwalifikuje się, ile to kosztuje i jak przebiegają aktualizacje.
Jeśli chcesz głębszego zanurzenia w techniki izolacji w każdym modelu, zobacz /blog/data-isolation-patterns.
Wzorce izolacji danych (DB, schemat, wiersz)
Izolacja danych odpowiada na proste pytanie: „Czy jeden klient kiedykolwiek może zobaczyć lub wpłynąć na dane innego klienta?” Istnieją trzy powszechne wzorce, każdy o innych implikacjach bezpieczeństwa i operacyjnych.
Izolacja na poziomie wiersza (wspólne tabele + tenant_id)
Wszyscy najemcy współdzielą te same tabele, a każdy wiersz zawiera kolumnę tenant_id. To najbardziej efektywny model dla małych i średnich najemców, bo minimalizuje infrastrukturę i ułatwia raportowanie oraz analitykę.
Ryzyko jest jasne: jeśli którekolwiek zapytanie zapomni filtrować po tenant_id, możesz wyciec dane. Nawet pojedynczy endpoint „admin” lub zadanie w tle może stać się słabym punktem. Ograniczenia obejmują:
- Egzekwowanie filtrowania najemcy w wspólnej warstwie dostępu do danych (żeby deweloperzy nie pisali filtrów ręcznie)
- Używanie funkcji bazy danych typu row-level security (RLS), gdy są dostępne
- Dodawanie testów automatycznych, które celowo próbują uzyskać dostęp do danych innego najemcy
- Indeksowanie dla popularnych ścieżek dostępu (często
(tenant_id, created_at)lub(tenant_id, id)), aby zapytania zakresu najemcy były szybkie
Schemat na najemcę (ta sama baza, oddzielne schematy)
Każdy najemca dostaje własny schemat (przestrzeń nazw jak tenant_123.users, tenant_456.users). To poprawia izolację w porównaniu do współdzielonych wierszy i może ułatwić eksport lub strojenie pod konkretnego najemcę.
Kosztem jest nakład operacyjny. Migracje trzeba uruchamiać w wielu schematach, a awarie stają się bardziej skomplikowane: możesz pomyślnie zmigrować 9 900 najemców i utknąć na 100. Monitoring i narzędzia mają tu znaczenie — proces migracji potrzebuje jasnego retry i raportowania.
Baza danych na najemcę (oddzielne bazy)
Każdy najemca ma osobną bazę danych. Izolacja jest silna: granice dostępu są klarowniejsze, hałaśliwe zapytania jednego najemcy rzadziej wpłyną na innych, a przywrócenie jednego najemcy z backupu jest czystsze.
Koszty i skalowanie to główne minusy: więcej baz do zarządzania, więcej puli połączeń i potencjalnie więcej pracy przy aktualizacjach/migracjach. Wiele zespołów stosuje ten model dla klientów o wysokiej wartości lub regulowanych, podczas gdy mniejsi klienci pozostają we współdzielonej infrastrukturze.
Sharding i strategie umieszczania w miarę wzrostu najemców
Rzeczywiste systemy często mieszają te wzorce. Powszechna ścieżka to izolacja na poziomie wiersza we wczesnym wzroście, a następnie „awans” większych najemców do oddzielnych schematów lub baz.
Sharding dodaje warstwę umieszczania: decydowanie, który klaster bazy będzie gospodarzem najemcy (wg regionu, tieru rozmiaru lub hashowania). Kluczowe jest, aby umieszczanie najemcy było jawne i zmienne — żeby móc przenieść najemcę bez przepisywania aplikacji i skalować przez dodawanie shardów zamiast przeprojektowywania wszystkiego.
Tożsamość, dostęp i kontekst najemcy
Wielonajemczość zawodzi w zaskakująco zwyczajnych przypadkach: brakujący filtr, obiekt w cache współdzielony między najemcami lub narzędzie administracyjne, które „zapomina”, dla kogo jest żądanie. Naprawa to nie jedna wielka funkcja bezpieczeństwa — to spójny kontekst najemcy od pierwszego bajtu żądania do ostatniego zapytania do bazy.
Identyfikacja najemcy (jak wiesz „kto”)
Większość produktów SaaS ustala jeden główny identyfikator i traktuje resztę jako wygodę:
- Subdomena:
acme.yourapp.comjest wygodna dla użytkowników i dobrze współgra z brandowaniem najemcy. - Nagłówek: przydatny dla klientów API i usług wewnętrznych (ale musi być uwierzytelniony).
- Zastrzeżenie w tokenie: podpisane JWT (lub sesja) zawiera
tenant_id, co utrudnia manipulację.
Wybierz jedno źródło prawdy i loguj je wszędzie. Jeśli wspierasz wiele sygnałów (subdomena + token), określ priorytet i odrzucaj niejednoznaczne żądania.
Scope żądania (jak każde zapytanie pozostaje w kontekście najemcy)
Dobra zasada: gdy rozwiążesz tenant_id, wszystko downstream powinno czytać je z jednego miejsca (kontekst żądania), a nie odtwarzać ponownie.
Typowe zabezpieczenia to:
- Middleware, który dołącza
tenant_iddo kontekstu żądania - Pomocniki dostępu do danych, które wymagają
tenant_idjako parametru - Wymuszenie w bazie (np. polityki na poziomie wiersza), żeby błędy kończyły się zamknięciem dostępu
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
Podstawy autoryzacji (role w ramach najemcy)
Oddziel uwierzytelnianie (kto jest użytkownikiem) od autoryzacji (co może robić).
Typowe role SaaS to Owner / Admin / Member / Read-only, ale kluczowe jest zakres: użytkownik może być Adminem w Najemcy A i Członkiem w Najemcy B. Przechowuj uprawnienia per-najemca, nie globalnie.
Zapobieganie wyciekom między najemcami (testy i zabezpieczenia)
Traktuj dostęp między najemcami jak incydent najwyższej rangi i zapobiegaj mu proaktywnie:
- Dodaj testy automatyczne, które próbują odczytać dane Najemcy B, będąc uwierzytelnionym jako Najemca A
- Utrudnij wypuszczenie błędów związanych z brakującym filtrem najemcy (linters, budownicze zapytań, obowiązkowe parametry najemcy)
- Loguj i alertuj podejrzane wzorce (np. niezgodność najemcy między tokenem a subdomeną)
Jeśli chcesz bardziej operacyjną checklistę, połącz te zasady z runbookami inżynieryjnymi w /security i przechowuj je wersjonowane razem z kodem.
Izolacja poza bazą danych
Szybkie prototypowanie wielonajemczości
Wygeneruj szkielet React + Go + PostgreSQL, aby wcześnie przetestować scoping tenantów.
Izolacja bazy danych to tylko połowa historii. Wiele prawdziwych incydentów wielonajemczości wydarza się w wspólnych elementach otaczających aplikację: cache, kolejki i storage. Te warstwy są szybkie, wygodne i łatwo przez nie przypadkowo zrobić coś globalnego.
Wspólne cache: zapobiegaj kolizjom kluczy i wyciekom danych
Jeśli wielu najemców współdzieli Redis lub Memcached, podstawowa zasada jest prosta: nigdy nie przechowuj kluczy niezwiązanych z najemcą.
Praktyczny wzorzec to prefixowanie każdego klucza stabilnym identyfikatorem najemcy (nie domeną e-mail, nie nazwą wyświetlaną). Na przykład: t:{tenant_id}:user:{user_id}. To robi dwie rzeczy:
- Zapobiega kolizjom, gdy dwóch najemców ma takie same wewnętrzne ID
- Ułatwia masowe unieważnianie (usuwanie po prefiksie) podczas incydentów wsparcia lub migracji
Zdecyduj też, co można współdzielić globalnie (np. publiczne feature flagi, statyczne metadane) i udokumentuj to — przypadkowe wartości globalne są częstym źródłem ekspozycji między najemcami.
Świadome limity i kwoty per najemca
Nawet jeśli dane są izolowane, najemcy mogą wpływać na innych poprzez współdzielone obliczenia. Dodaj limity świadome najemcy na krawędziach:
- Limity API per najemca (i często per użytkownik w ramach najemcy)
- Kwoty dla kosztownych operacji (eksporty, generowanie raportów, wywołania AI)
Upewnij się, że limit jest widoczny (nagłówki, komunikaty w UI), żeby klienci wiedzieli, że throttling to polityka, a nie niestabilność.
Zadania w tle: partycjonuj kolejki według najemcy
Jedna współdzielona kolejka może pozwolić jednemu obciążonemu najemcy zdominować czas workerów.
Typowe naprawy:
- Oddzielne kolejki per tier/plan (np.
free,pro,enterprise) - Kolejki partycjonowane według kubełka najemców (hash tenant_id do N kolejek)
- Harmonogramy świadome najemcy, żeby każdy najemca miał uczciwy udział
Zawsze propaguj kontekst najemcy w ładunku zadania i logach, aby uniknąć działań na złym najemcy.
Pliki/obiekty: osobne ścieżki, polityki i klucze
Dla storage typu S3/GCS izolacja zwykle opiera się na ścieżkach i politykach:
- Bucket na najemcę dla ścisłej separacji (silniejsze granice, więcej overheadu)
- Wspólny bucket z prefiksami najemcy (prostsze, wymaga starannego IAM i podpisanych URL)
Niezależnie od wyboru, wymuszaj walidację własności najemcy przy każdym żądaniu pobrania/wgrania, nie tylko w UI.
Radzenie sobie z hałaśliwymi sąsiadami i uczciwym użyciem zasobów
Systemy wielonajemcowe dzielą infrastrukturę, co oznacza, że jeden najemca może przypadkowo (lub celowo) zużyć więcej niż swoją uczciwą część. To problem hałaśliwego sąsiada: jedno głośne obciążenie pogarsza działanie dla wszystkich.
Jak wygląda „hałaśliwy sąsiad”
Wyobraź sobie funkcję eksportu raportu za rok do CSV. Najemca A planuje 20 eksportów o 9:00. Eksporty saturują CPU i I/O bazy, więc ekrany aplikacji dla Najemcy B zaczynają się zawieszać — mimo że B nic nie robi niespodziewanego.
Kontrole zasobów: limity, kwoty i formowanie obciążenia
Zapobieganie zaczyna się od jawnych granic zasobów:
- Limity szybkości (requests per second) per najemca i per endpoint, żeby kosztowne API nie dało się zabić spamem.
- Kwoty (dziennie/miesięcznie) dla eksportów, maili, wywołań AI czy zadań w tle.
- Formowanie obciążenia: umieszczanie ciężkich zadań (eksporty, importy, reindeksy) w kolejkach z limitami współbieżności per najemca i regułami priorytetów.
Praktyczny wzorzec to oddzielić ruch interaktywny od batchowego: trzymać żądania dla użytkownika w „szybkim pasie”, a resztę przekazywać do kontrolowanych kolejek.
Bezpieczniki per najemca i przegrody (bulkheads)
Dodaj zawory bezpieczeństwa, które włączają się, gdy najemca przekroczy próg:
- Bezpieczniki (circuit breakers): tymczasowo odrzucają lub odkładają kosztowne operacje, gdy wskaźniki błędów, opóźnień lub głębokość kolejki przekroczą limity dla danego najemcy.
- Bulkheads: izolują pule współdzielonych zasobów (połączenia DB, wątki workerów, cache), żeby jeden najemca nie wyczerpał globalnej pojemności.
Dobrze przeprowadzone, Najemca A może spowolnić tylko własne eksporty bez zabijania Najemcy B.
Kiedy przenieść najemcę na dedykowane zasoby
Przenieś najemcę na dedykowane zasoby, gdy stale przekracza założenia współdzielonego modelu: utrzymujące się wysokie przepływy, nieprzewidywalne skoki związane z kluczowymi wydarzeniami biznesowymi, ścisłe potrzeby zgodności lub gdy ich obciążenie wymaga strojenia pod konkretny przypadek. Prosta zasada: jeśli ochrona innych najemców wymaga stałego ograniczania wydajności płacącego klienta, czas na dedykowane zasoby (albo wyższy plan), zamiast ciągłego gaszenia pożarów.
Wzorce skalowania, które działają w SaaS wielonajemcowym
Kontroluj hałaśliwych sąsiadów
Buduj ograniczenia na poziomie najemcy i kolejki zadań, aby hałaśliwi sąsiedzi pozostali w ryzach.
Skalowanie wielonajemcowe to mniej „więcej serwerów”, a bardziej unikanie sytuacji, w której wzrost jednego najemcy zaskakuje wszystkich innych. Najlepsze wzorce czynią skalę przewidywalną, mierzalną i odwracalną.
Skalowanie horyzontalne dla usług bezstanowych
Zacznij od uczynienia warstwy web/API bezstanową: przechowuj sesje w współdzielanym cache (lub używaj tokenów), trzymaj uploady w object storage i przerzucaj długotrwałą pracę do zadań w tle. Gdy żądania nie zależą od lokalnej pamięci ani dysku, możesz dodać instancje za load balancerem i szybko skalować.
Praktyczna wskazówka: trzymaj kontekst najemcy na krawędzi (pochodzący z subdomeny lub nagłówków) i przekazuj go dalej do handlerów. Bezstanowość nie znaczy „bez świadomości najemcy” — znaczy świadomość najemcy bez przywiązania do serwera.
Gorące punkty per najemca: ich identyfikacja i wygładzanie
Większość problemów skalowych wynika z „jeden najemca jest inny”. Obserwuj takie miejsca jak:
- Pojedynczy najemca generujący nadmierny ruch
- Kilku najemców z bardzo dużymi zbiorami danych
- Użycie batchowe (raporty na koniec miesiąca, nocne importy)
Sposoby wygładzania: limity per-najemca, ingest do kolejek, cache ścieżek odczytu specyficznych dla najemcy i rozdzielanie ciężkich najemców do oddzielnych pul workerów.
Read replicas, partycjonowanie i asynchroniczne obciążenia
Używaj read replicas dla obciążeń czytających (dashboardy, wyszukiwania, analityka) i trzymaj zapisy na primary. Partycjonowanie (wg najemcy, czasu lub obu) pomaga utrzymać mniejsze indeksy i szybsze zapytania. Dla kosztownych zadań — eksportów, scoringu ML, webhooks — preferuj asynchroniczne zadania z idempotencją, aby powtórzenia nie mnożyły obciążenia.
Sygnały planowania pojemności i proste progi
Trzymaj sygnały proste i per-najemca: p95 latency, rate błędów, głębokość kolejki, CPU bazy i ruch per-najemca. Ustaw proste progi (np. “głębokość kolejki > N przez 10 minut” lub “p95 > X ms”), które wyzwalają autoskalowanie lub tymczasowe ograniczenia najemcy — zanim inni to odczują.
Obserwowalność i operacje per najemca
Systemy wielonajemcowe nie zawodzą najpierw globalnie — zwykle zawodzą dla jednego najemcy, jednego tieru planu lub jednego hałaśliwego obciążenia. Jeśli twoje logi i dashboardy nie pozwalają odpowiedzieć na pytanie „który najemca jest dotknięty?” w ciągu kilku sekund, na dyżurze tracisz czas na zgadywanie.
Logi, metryki i ślady świadome najemcy
Zacznij od spójnego kontekstu najemcy w całej telemetrii:
- Logi: dołącz
tenant_id,request_idi stabilneactor_id(użytkownik/usługa) do każdego żądania i zadania w tle. - Metryki: emituj liczniki i histogramy opóźnień rozbite przynajmniej według tieru najemcy (np.
tier=basic|premium) i według wysokopoziomowego endpointu (nie surowe URL). - Ślady (traces): propaguj kontekst najemcy jako atrybuty śladu, aby móc filtrować wolne ślady do konkretnego najemcy i zobaczyć, gdzie mierzony czas się kumuluje (DB, cache, zewnętrzne wywołania).
Kontroluj kardynalność: metryki per-najemca dla wszystkich najemców mogą być drogie. Typowe kompromisy to metryki per-tier domyślnie i możliwość przejścia do szczegółów per-najemca na żądanie (np. próbkowanie śladów dla „top 20 najemców” lub najemców łamiących SLO).
Unikanie wycieków danych w telemetrii
Telemetria to kanał eksportu danych. Traktuj ją jak dane produkcyjne.
Preferuj ID zamiast treści: loguj customer_id=123 zamiast imion, e-maili, tokenów czy payloadów zapytań. Dodaj redakcję na poziomie loggera/SDK i zablokuj typowe sekrety (nagłówki Authorization, klucze API). Dla workflowów wsparcia przechowuj debugowe payloady w oddzielnym, kontrolowanym dostępie systemie — nie w ogólnych logach.
SLO per tier najemcy (bez nadmiernych obietnic)
Zdefiniuj SLO, które odpowiadają temu, co realnie możesz egzekwować. Najemcy premium mogą mieć bardziej rygorystyczne budżety latencji/błędów, ale tylko jeśli masz też mechanizmy (limity, izolację obciążenia, priorytetowe kolejki). Publikuj SLO per tier jako cele i śledź je per-tier oraz dla wybranej grupy kluczowych najemców.
Runbooki dyżurne: typowe incydenty w SaaS wielonajemcowym
Twoje runbooki powinny zaczynać się od „zidentyfikuj dotkniętych najemców” i potem najszybszej akcji izolującej:
- Hałaśliwy sąsiad: nałóż throttle na najemcę, zatrzymaj ciężkie zadania lub przenieś je do kolejki o niższym priorytecie.
- Hotspoty DB/uciekające zapytania: włącz timeouty zapytań, sprawdź top zapytań per-najemca, zastosuj indeks lub ogranicz endpoint.
- Błędy kontekstu najemcy (mieszanie danych): natychmiast wyłącz flagę funkcji lub endpoint i zweryfikuj zakresowanie najemcy w kontrolach dostępu.
- Nagromadzenie zadań w tle: osusz kolejki per-najemca, ogranicz współbieżność i odtwórz z zabezpieczeniami idempotencji.
Operacyjnie cel jest prosty: wykryć per-najemca, odizolować per-najemca i odzyskać bez wpływu na wszystkich.
Wdrożenia, migracje i wydania per-najemca
Wielonajemczość zmienia rytm wdrażania. Nie wdrażasz „aplikacji” — wdrażasz współdzielone runtime i ścieżki danych, od których zależy wielu klientów jednocześnie. Celem jest dostarczanie nowych funkcji bez wymuszania zsynchronizowanej, wielkiego upgrade'u dla wszystkich najemców.
Rolling deployy i migracje niskiego downtime
Preferuj wzorce wdrażania tolerujące mieszane wersje przez krótki okres (blue/green, canary, rolling). To działa tylko wtedy, gdy zmiany bazy danych też są etapowane.
Praktyczna zasada to rozszerz → zmigruj → skurcz:
- Rozszerz: dodaj nowe kolumny/tabele/indeksy bez łamania istniejącego kodu.
- Zmigruj: backfilluj dane partiami (często per-najemca) i weryfikuj.
- Skurcz: usuń stare pola dopiero, gdy wszystkie instancje aplikacji już z nich nie korzystają.
Dla gorących tabel wykonuj backfill incrementalnie (i throttluj), inaczej możesz stworzyć własne zdarzenie hałaśliwego sąsiada podczas migracji.
Flagi funkcji per-najemca dla bezpieczniejszych wdrożeń
Flagi na poziomie najemcy pozwalają wypuścić kod globalnie, a zachowanie włączać selektywnie.
To wspiera:
- Programy wczesnego dostępu dla kilku najemców
- Szybkie wycofanie przez wyłączenie funkcji tylko dla dotkniętych najemców
- Eksperymenty A/B bez forku wdrożeń
Utrzymuj system flag audytowalny: kto co włączył, dla którego najemcy i kiedy.
Wersjonowanie i oczekiwania kompatybilności wstecznej
Zakładaj, że niektórzy najemcy mogą zostawać w tyle z konfiguracją, integracjami lub wzorcami użycia. Projektuj API i zdarzenia z jasnym wersjonowaniem, żeby nowi producenci nie psuli starych konsumentów.
Typowe oczekiwania wewnętrzne:
- Nowe wydania muszą czytać zarówno stare, jak i nowe kształty danych w oknach migracji.
- Deprecjacje wymagają opublikowanego harmonogramu (nawet jeśli to tylko notatki wewnętrzne plus szablon e-mail dla klientów).
Zarządzanie konfiguracją specyficzną dla najemcy
Traktuj konfigurację najemcy jako powierzchnię produktu: potrzebuje walidacji, domyślnych wartości i historii zmian.
Przechowuj konfigurację oddzielnie od kodu (i najlepiej oddzielnie od sekretów runtime), i wspieraj tryb awaryjny, gdy konfiguracja jest nieprawidłowa. Lekka strona wewnętrzna jak /settings/tenants może uratować godziny podczas incydentów i etapowych wydawnictw.
Jak architektury generowane przez AI pomagają (i gdzie mają ograniczenia)
Wymuś kontekst najemcy wszędzie
Poproś Koder.ai o middleware i wzorce dostępu do danych, które utrzymają spójny kontekst najemcy.
AI może przyspieszyć wczesne rozważania architektoniczne dla SaaS wielonajemcowego, ale nie zastąpi osądu inżynierskiego, testów ani przeglądu bezpieczeństwa. Traktuj je jako wysokiej jakości partnera do burzy mózgów, który generuje szkice — potem zweryfikuj każde założenie.
Co architektura wygenerowana przez AI powinna (i czego nie powinna) robić
AI jest użyteczne do generowania opcji i wskazywania typowych trybów awarii (gdzie kontekst najemcy może zostać zgubiony, albo gdzie współdzielone zasoby mogą zaskoczyć). Nie powinno decydować za ciebie modelu, gwarantować zgodności ani walidować wydajności. Nie widzi twojego rzeczywistego ruchu, zdolności zespołu ani przypadków brzegowych w legacy integracjach.
Dane wejściowe, które mają znaczenie: wymagania, ograniczenia, ryzyka, wzrost
Jakość wyjścia zależy od tego, co mu dasz. Przydatne dane wejściowe to:
- Liczba najemców dziś vs. za 12–24 miesiące oraz oczekiwany wolumen danych per najemca
- Wymagania izolacji (kontraktowe, regulacyjne, oczekiwania klientów)
- Budżet i zdolność operacyjna (dojrzałość on-call, wsparcie SRE, narzędzia)
- Cele latencji, wzorce szczytów i skokowość per najemca
- Tolerancja ryzyka: co się stanie, jeśli jeden najemca wpłynie na innego?
Używanie AI do proponowania opcji wzorców z kompromisami
Poproś o 2–4 projekty kandydujące (np. database-per-tenant vs. schema-per-tenant vs. row-level isolation) i żądaj jasnej tabeli kompromisów: koszt, złożoność operacyjna, promień awarii, wysiłek migracji i limity skalowania. AI dobrze wymienia pułapki, które możesz przekształcić w pytania projektowe dla zespołu.
Jeśli chcesz szybciej przejść od „szkicu architektury” do działającego prototypu, platforma vibe-coding taka jak Koder.ai może pomóc przekształcić te wybory w szkielety aplikacji przez chat — często z frontendem React i backendem Go + PostgreSQL — dzięki czemu możesz wcześniej zweryfikować propagację kontekstu najemcy, limity i procesy migracji. Funkcje takie jak tryb planowania oraz snapshoty/rollbacky są szczególnie przydatne przy iteracji nad modelami danych wielonajemcowych.
Używanie AI do generowania modeli zagrożeń i elementów checklisty
AI może przygotować prosty model zagrożeń: punkty wejścia, granice zaufania, propagacja kontekstu najemcy i typowe pomyłki (np. brak kontroli autoryzacji w zadaniach w tle). Użyj tego do wygenerowania listy kontrolnej dla PR-ów i runbooków — ale zweryfikuj z rzeczywistymi ekspertami ds. bezpieczeństwa i historią incydentów.
Praktyczna lista kontrolna do wyboru dla twojego zespołu
Wybór podejścia do wielonajemczości to mniej sprawa „najlepszej praktyki”, a bardziej dopasowanie: wrażliwość danych, tempo wzrostu i ile złożoności operacyjnej możesz udźwignąć.
Lista krok po kroku (użyj tego na 30-minutowym warsztacie)
-
Dane: Jakie dane są współdzielone między najemcami (jeśli w ogóle)? Co nigdy nie może być współlokowane?
-
Tożsamość: Gdzie żyje tożsamość najemcy (linki zaproszeniowe, domeny, roszczenia SSO)? Jak kontekst najemcy jest ustalany przy każdym żądaniu?
-
Izolacja: Zdecyduj domyślny poziom izolacji (wiersz/schemat/baza) i zidentyfikuj wyjątki (np. klienci enterprise wymagający silniejszej separacji).
-
Skalowanie: Zidentyfikuj pierwszą presję skalową, której oczekujesz (przechowywanie, ruch odczytów, zadania w tle, analityka) i wybierz najprostszy wzorzec, który ją adresuje.
Pytania do weryfikacji z inżynierami i recenzentami bezpieczeństwa
- Jak zapobiegamy dostępowi między najemcami, jeśli deweloper zapomni filtra?
- Jaka jest nasza historia audytu per najemca (kto co zrobił i kiedy)?
- Jak obsługujemy usuwanie danych i retencję per najemca?
- Jaki jest promień awarii złej migracji lub uciekającego zapytania?
- Czy możemy throttle'ować, rate-limitować i budżetować zasoby per najemca?
Czerwone flagi wymagające głębszego projektu
- „Dodamy kontrole najemcy później.”
- Wspólne narzędzia administracyjne, które widzą wszystko bez ścisłych kontroli.
- Brak planu backup/restore per najemca lub reakcji na incydenty.
- Jedna kolejka/pool workerów bez mechanizmów uczciwości per najemca.
Przykładowe „zalecane następne działania”
Zalecenie: Zacznij od izolacji na poziomie wiersza + ścisłego wymuszania kontekstu najemcy, dodaj throttling per najemca i zdefiniuj ścieżkę awansu do izolacji schematu/bazy dla najemców wysokiego ryzyka.
Następne kroki (2 tygodnie): przeprowadź model zagrożeń granic najemców, zrób prototyp wymuszenia na jednym endpointzie i przećwicz migrację na kopii stagingowej. Dla wskazówek wdrożeniowych zobacz /blog/tenant-release-strategies.