21 cze 2025·8 min
Jak wstrzykiwanie zależności zwiększa testowalność i modularność
Dowiedz się, jak wstrzykiwanie zależności ułatwia testowanie, refaktoryzację i rozbudowę kodu. Poznaj praktyczne wzorce, przykłady i typowe pułapki do unikania.
Dowiedz się, jak wstrzykiwanie zależności ułatwia testowanie, refaktoryzację i rozbudowę kodu. Poznaj praktyczne wzorce, przykłady i typowe pułapki do unikania.
Dependency Injection (DI) to prosta idea: zamiast kod tworzył rzeczy, których potrzebuje, dostajesz je z zewnątrz.
Te „rzeczy” to jego zależności — na przykład połączenie z bazą, serwis płatności, zegar, logger czy wysyłacz e-maili. Jeśli twój kod sam buduje te zależności, utajenie określa jak one działają.
Pomyśl o ekspresie do kawy w biurze. Potrzebuje wody, ziaren i prądu.
DI to to drugie podejście: „ekspres” (twoja klasa/funkcja) skupia się na robieniu kawy (swoim zadaniu), a „dostawy” (zależności) są zapewniane przez tego, kto go uruchamia.
DI nie wymaga konkretnego frameworka i nie jest tym samym co kontener DI. Możesz robić DI ręcznie, przekazując zależności jako parametry (lub przez konstruktor) i to wystarczy.
DI to też nie „mockowanie”. Mockowanie to jedna z technik używanych dzięki DI w testach, ale samo DI to decyzja projektowa o tym, gdzie tworzy się zależności.
Gdy zależności dostarczane są z zewnątrz, kod staje się łatwiejszy do uruchomienia w różnych kontekstach: produkcja, testy jednostkowe, demonstracje czy przyszłe funkcje.
Ta sama elastyczność upraszcza moduły: części mogą być wymieniane bez przekształcania całego systemu. W efekcie testy są szybsze i czytelniejsze (bo można podmienić proste duble), a baza kodu łatwiejsza do zmiany (bo części są mniej splątane).
Silne powiązanie występuje, gdy jedna część kodu bezpośrednio decyduje, z czego musi korzystać inna część. Najczęstsza forma to wywoływanie new wewnątrz logiki biznesowej.
Wyobraź sobie funkcję checkout, która wewnątrz robi new StripeClient() i new SmtpEmailSender(). Na początku wydaje się wygodne — wszystko, czego potrzebujesz, jest pod ręką. Ale blokuje to workflow do tych konkretnych implementacji, szczegółów konfiguracji, a nawet reguł tworzenia (klucze API, timeouty, zachowanie sieciowe).
To powiązanie jest „ukryte”, bo nie widać go w sygnaturze metody. Funkcja wygląda jak przetwarzająca zamówienie, a w rzeczywistości zależy od bramek płatności, dostawców e-maili i być może połączenia z bazą.
Gdy zależności są zakodowane na stałe, nawet drobne zmiany powodują fale:
Zakodowane zależności sprawiają, że testy jednostkowe wykonują rzeczywiste operacje: wywołania sieci, I/O plików, zegary, losowe ID czy współdzielone zasoby. Testy stają się wolne, bo nie są izolowane, oraz kruche, bo wyniki zależą od czasu, usług zewnętrznych lub kolejności wykonania.
Jeśli widzisz te wzory, prawdopodobnie już tracisz czas przez silne powiązania:
new rozsiane „wszędzie” w kluczowej logiceDependency Injection rozwiązuje to, robiąc zależności jawne i wymienne — bez przepisywania reguł biznesowych za każdym razem, gdy świat się zmienia.
Inversion of Control (IoC) to prosty przesunięcie odpowiedzialności: klasa powinna skupiać się na tym, co musi robić, a nie jak zdobyć rzeczy, których potrzebuje.
Gdy klasa tworzy swoje zależności (np. new EmailService() lub otwiera połączenie z bazą bezpośrednio), bierze na siebie dwie role: logikę biznesową i konfigurację. To sprawia, że klasa jest trudniejsza do zmiany, ponownego użycia i testowania.
W IoC twój kod zależy od abstrakcji — jak interfejsy lub małe typy „kontraktowe” — zamiast od konkretnych implementacji.
Na przykład CheckoutService nie musi wiedzieć, czy płatności są przetwarzane przez Stripe, PayPal czy fałszywy procesor testowy. Potrzebuje jedynie „czegoś, co potrafi obciążyć kartę”. Jeśli CheckoutService przyjmuje IPaymentProcessor, może współpracować z każdą implementacją zgodną z tym kontraktem.
To utrzymuje twoją logikę w ryzach nawet, gdy pod spodem zmieniają się narzędzia.
Praktyczna część IoC to wyprowadzenie tworzenia zależności poza klasę i przekazanie ich (często przez konstruktor). Tu wchodzi DI: to popularny sposób osiągnięcia IoC.
Zamiast:
Masz:
Efekt to elastyczność: zamiana zachowania staje się decyzją konfiguracyjną, a nie przepisywaniem kodu.
Jeśli klasy nie tworzą swoich zależności, ktoś inny musi to zrobić. Tym „kimś” jest composition root: miejsce, gdzie aplikacja jest składana — zwykle kod startowy.
Composition root to miejsce, w którym decydujesz: „W produkcji użyj RealPaymentProcessor; w testach użyj FakePaymentProcessor.” Trzymanie okablowania w jednym miejscu zmniejsza niespodzianki i pozwala reszcie kodu koncentrować się na zachowaniu.
IoC upraszcza testy jednostkowe, bo można dostarczyć małe, szybkie duble testowe zamiast wywoływać prawdziwe sieci czy bazy.
Ułatwia też refaktory: gdy odpowiedzialności są rozdzielone, zmiana implementacji rzadko wymusza zmianę klas ją używających — pod warunkiem, że abstrakcja pozostanie taka sama.
Dependency Injection (DI) to nie pojedyncza technika — to zbiór sposobów „karmienia” klasy rzeczami, których potrzebuje (logger, klient DB, bramka płatności). Styl, który wybierzesz, wpływa na czytelność, testowalność i ryzyko nadużyć.
W constructor injection zależności są wymagane do zbudowania obiektu. To duża zaleta: nie można ich przypadkowo pominąć.
Pasuje, gdy zależność:
Constructor injection daje zwykle najbardziej przejrzysty kod i najprostsze testy jednostkowe, bo w teście możesz przekazać fałszywy lub mock już przy tworzeniu.
Czasem zależność jest potrzebna tylko do jednej operacji — np. tymczasowy formatter, specjalna strategia lub wartość w zakresie żądania. W takich przypadkach przekaż ją jako parametr metody. Zmniejsza to rozmiar obiektu i zapobiega „promocji” jednorazowej potrzeby do trwałego pola.
Setter injection bywa wygodne, gdy nie da się dostarczyć zależności w konstruktorze (pewne frameworki lub legacy). Kosztem jest to, że może ukryć wymagania: klasa wygląda jak nadająca się do użycia, nawet gdy nie jest w pełni skonfigurowana.
Często prowadzi to do niespodzianek w czasie wykonywania („dlaczego to jest undefined?”) i sprawia testy bardziej kruche, bo łatwo pominąć konfigurację.
Testy jednostkowe są najbardziej użyteczne, gdy są szybkie, powtarzalne i skupione na jednym zachowaniu. Gdy test „jednostkowy” zależy od prawdziwej bazy, sieci, systemu plików czy czasu, zaczyna się zwalniać i stawać niestabilny. Porażki przestają być informacyjne: czy kod się zepsuł, czy środowisko się potknęło?
Dependency Injection (DI) rozwiązuje to, pozwalając kodowi przyjmować rzeczy, których potrzebuje (dostęp do DB, klient HTTP, dostawca czasu) z zewnątrz. W testach możesz je zamienić na lekkie substytuty.
Prawdziwa baza lub wywołanie API dodaje czas i opóźnienia. Dzięki DI możesz wstrzyknąć repozytorium w pamięci lub fałszywy klient, który zwraca przygotowane odpowiedzi natychmiast. To oznacza:
Bez DI kod często „new()uje” swoje zależności, zmuszając testy do ćwiczenia całej stosu. Dzięki DI możesz wstrzyknąć:
Bez hacków i globalnych przełączników — po prostu przekaż inną implementację.
DI sprawia, że konfiguracja jest jawna. Zamiast szukać konfiguracji, łańcuchów połączeń czy zmiennych środowiskowych testu, czytasz test i od razu widzisz, co jest realne, a co podmienione.
Typowy test przyjazny DI wygląda tak:
Ta bezpośredniość redukuje szum i sprawia, że błędy są łatwiejsze do zdiagnozowania.
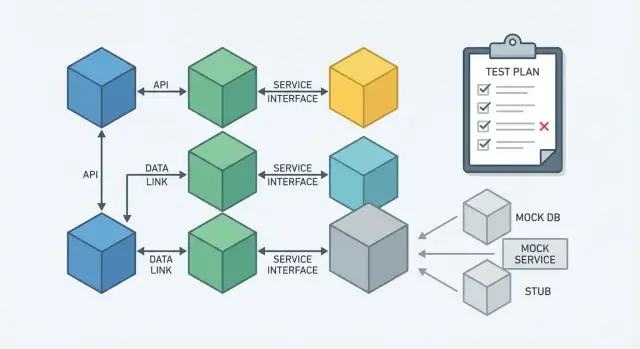
Seam testowy to celowe „otwarcie” w kodzie, gdzie możesz podmienić jedno zachowanie na inne. W produkcji podłączasz prawdziwą rzecz. W testach podłączasz bezpieczny, szybki substytut. DI jest jednym z najprostszych sposobów tworzenia takich seamów bez sztuczek.
Seamy są przydatne wokół części systemu trudnych do kontrolowania w teście:
Jeśli logika biznesowa wywołuje te rzeczy bezpośrednio, testy stają się kruche: zawodzą z powodów niezwiązanych z logiką (awarie sieci, różnice stref czasowych, brak plików) i są trudniejsze do szybkiego uruchamiania.
Seam często ma postać interfejsu — albo w językach dynamicznych prostego kontraktu, np. „obiekt musi mieć metodę now()”. Klucz: zależ od tego, czego potrzebujesz, nie skąd to pochodzi.
Na przykład zamiast odczytywać zegar systemowy wewnątrz serwisu zamówień, możesz zależeć od Clock:
SystemClock.now()FakeClock.now() zwraca stały czasTen sam wzorzec działa dla odczytu plików (FileStore), wysyłania e-maili (Mailer) czy obciążania kart (PaymentGateway). Logika biznesowa zostaje niezmienna; zmienia się tylko wtyczka.
Gdy możesz świadomie podmienić zachowanie:
Dobrze umieszczone seams redukują potrzebę szerokiego mockowania — dostajesz kilka czystych punktów zamiany, które utrzymują testy szybkie, skupione i przewidywalne.
Modularność oznacza, że oprogramowanie jest zbudowane z niezależnych części (modułów) o jasnych granicach: każdy moduł ma skupioną odpowiedzialność i dobrze zdefiniowany sposób interakcji z resztą systemu.
DI wspiera to, czyniąc te granice jawne. Zamiast modułu, który sięga po to, by stworzyć lub znaleźć wszystko, czego potrzebuje, otrzymuje zależności z zewnątrz. Ta mała zmiana zmniejsza wiedzę jednego modułu o drugim.
Gdy kod konstruuje zależności wewnętrznie (np. new-ing klienta bazy w serwisie), wywołujący i zależność są mocno związane. DI zachęca do polegania na interfejsie (lub prostym kontrakcie), nie na implementacji.
To oznacza, że moduł zazwyczaj musi wiedzieć:
PaymentGateway.charge()),W efekcie moduły rzadziej zmieniają się razem, bo szczegóły wewnętrzne przestają przepływać przez granice.
Modularny kod pozwala zamienić komponent bez przepisywania konsumentów. DI to umożliwia praktycznie:
We wszystkich przypadkach wywołujący używają tego samego kontraktu. „Okablowanie” zmienia się w jednym miejscu (composition root), zamiast rozproszonych edycji.
Jasne granice zależności ułatwiają pracę równoległą. Jeden zespół może budować nową implementację za zgadzającym się interfejsem, podczas gdy inny rozwija funkcje zależne od tego interfejsu.
DI wspiera też stopniowy refaktor: możesz wyodrębnić moduł, wstrzyknąć go i stopniowo podmieniać — bez wielkiej migracji.
Zobaczenie DI w kodzie szybciej rozjaśnia niż definicje. Oto mały „przed i po” dla funkcji powiadomień.
Gdy klasa wywołuje new wewnątrz, decyduje którą implementację użyć i jak ją zbudować.
class EmailService {
send(to, message) {
// talks to real SMTP provider
}
}
class WelcomeNotifier {
notify(user) {
const email = new EmailService();
email.send(user.email, "Welcome!");
}
}
Ból przy testowaniu: test jednostkowy ryzykuje wywołanie prawdziwego zachowania e-mail (albo wymaga niezręcznego globalnego podmieniania).
test("sends welcome email", () => {
const notifier = new WelcomeNotifier();
notifier.notify({ email: "[email protected]" });
// Hard to assert without patching EmailService globally
});
Teraz WelcomeNotifier akceptuje dowolny obiekt, który spełnia wymagane zachowanie.
class WelcomeNotifier {
constructor(emailService) {
this.emailService = emailService;
}
notify(user) {
this.emailService.send(user.email, "Welcome!");
}
}
Test staje się mały, szybki i jawny.
test("sends welcome email", () => {
const fakeEmail = { send: vi.fn() };
const notifier = new WelcomeNotifier(fakeEmail);
notifier.notify({ email: "[email protected]" });
expect(fakeEmail.send).toHaveBeenCalledWith("[email protected]", "Welcome!");
});
Chcesz SMS zamiast e-mail? Nie dotykasz WelcomeNotifier. Przekazujesz inną implementację:
const smsService = { send: (to, msg) => {/* SMS provider */} };
const notifier = new WelcomeNotifier(smsService);
Praktyczny zysk: testy przestają walczyć z detalami tworzenia, a nowe zachowanie dodaje się przez zamianę zależności zamiast przepisywania istniejącego kodu.
DI może być tak proste, jak „przekazanie tego, czego potrzebujesz, tam gdzie tego potrzebujesz.” To jest ręczne DI. Kontener DI to narzędzie automatyzujące okablowanie. Oba mogą być dobrym wyborem — trick to dobrać poziom automatyzacji do aplikacji.
W ręcznym DI tworzysz obiekty samodzielnie i przekazujesz zależności przez konstruktory (lub parametry). To proste:
Ręczne okablowanie też wymusza dobre praktyki projektowe. Jeśli obiekt potrzebuje siedmiu zależności, od razu poczujesz ból — często znak do podziału odpowiedzialności.
Gdy liczba komponentów rośnie, ręczne okablowanie może stać się powtarzalnym „rurociągiem”. Kontener DI pomaga:
Kontenery sprawdzają się w aplikacjach z jasnymi granicami i cyklami życia — aplikacje webowe, długotrwające serwisy lub systemy, gdzie wiele funkcji zależy od wspólnej infrastruktury.
Kontener może sprawić, że silnie powiązana architektura poczuje się uporządkowana, bo okablowanie znika. Ale problemy pozostają:
Jeśli dodanie kontenera sprawia, że kod staje się mniej czytelny, lub deweloperzy przestają wiedzieć, co zależy od czego, to oznaka przedawkowania.
Zacznij od ręcznego DI, by zachować jasność przy kształtowaniu modułów. Dodaj kontener, gdy okablowanie stanie się powtarzalne lub zarządzanie cyklem życia stanie się problemem.
Praktyczna zasada: używaj ręcznego DI wewnątrz rdzenia/biznesu, a (opcjonalnie) kontenera na granicy aplikacji (composition root) do złożenia wszystkiego. To utrzymuje projekt czytelny, redukując jednocześnie boilerplate w miarę wzrostu projektu.
Dependency injection może ułatwić testowanie i zmiany — pod warunkiem dyscypliny. Oto najczęstsze sposoby, w jakie DI zawodzi, i praktyki, które pomagają.
Jeśli klasa potrzebuje długiej listy zależności, często robi za dużo. To nie błąd DI — to DI ujawniające zapach projektowy.
Praktyczna reguła: jeśli nie potrafisz opisać zadania klasy w jednym zdaniu lub konstruktor rośnie, rozważ podział klasy, wyodrębnienie mniejszego współpracownika lub zgrupowanie powiązanych operacji za jednym interfejsem (uważnie — nie twórz kolejnych „bogów-serwisów”).
Service Locator wygląda jak wywoływanie container.get(Foo) wewnątrz kodu biznesowego. Wygodne, ale ukrywa zależności: nie da się rozczytać, czego klasa potrzebuje, patrząc na konstruktor.
Testowanie robi się trudniejsze, bo trzeba ustawiać stan globalny (locator) zamiast dostarczać lokalny zestaw dubli. Lepiej przekazywać zależności jawnie (constructor injection jest najprostsze).
Kontenery DI mogą zawieść przy runtime, gdy:
To frustrujące, bo pojawia się dopiero, gdy okablowanie się wykona.
Trzymaj konstruktory małe i skupione. Jeśli lista zależności rośnie, potraktuj to jako sygnał do refaktoru.
Dodaj testy integracyjne dla okablowania. Nawet lekki test kompozycji, który buduje container aplikacji (lub ręczne okablowanie), może złapać brakujące rejestracje i cykle wcześniej — zanim trafi do produkcji.
Wreszcie, trzymaj tworzenie obiektów w jednym miejscu (zwykle start/ composition root) i trzymaj wywołania kontenera z dala od logiki biznesowej. Ta separacja zachowuje główną korzyść DI: jasność, co od czego zależy.
DI najłatwiej wprowadzać jako serię małych, niskoryzykownych refaktorów. Zacznij tam, gdzie testy są wolne lub kruche, i tam, gdzie zmiany często rozlewają się na niepowiązany kod.
Szukaj zależności, które utrudniają testowanie lub rozumienie kodu:
Jeśli funkcja nie może działać bez wyjścia poza proces, zwykle warto ją wydzielić.
To podejście sprawia, że każda zmiana jest łatwo przeglądalna i pozwala zatrzymać się po dowolnym kroku bez łamania systemu.
DI łatwo może zmienić kod w „wszystko zależy od wszystkiego”, jeśli wstrzykujesz zbyt wiele.
Dobra zasada: wstrzykuj możliwości, nie szczegóły. Na przykład wstrzyknij Clock zamiast „SystemTime + TimeZoneResolver + NtpClient”. Jeśli klasa potrzebuje pięciu niepowiązanych serwisów, prawdopodobnie robi za dużo — rozważ podział.
Unikaj też przekazywania zależności przez wiele warstw „na zapas”. Wstrzykuj tylko tam, gdzie są używane; centralizuj okablowanie w jednym miejscu.
Jeśli korzystasz z generatora kodu lub workflow do szybkiego spin-upu funkcji, DI staje się jeszcze cenniejsze, bo zachowuje strukturę w miarę wzrostu projektu. Na przykład, gdy zespoły używają Koder.ai do tworzenia frontendów React, serwisów Go i backendów opartych na PostgreSQL z opisów w czacie, jasny composition root i interfejsy przyjazne DI pomagają, by wygenerowany kod pozostał łatwy do testowania, refaktoryzacji i zmiany integracji (e-mail, płatności, storage) bez przepisywania logiki biznesowej.
Zasada pozostaje ta sama: trzymaj tworzenie obiektów i środowiskowe okablowanie na granicy, a logikę biznesową skupioną na zachowaniu.
Powinieneś móc wskazać konkretne usprawnienia:
Jeśli chcesz kolejnego kroku, udokumentuj swój „composition root” i trzymaj go nudnym: jeden plik składający zależności, podczas gdy reszta kodu pozostaje skupiona na zachowaniu.
Dependency Injection (DI) oznacza, że Twój kod otrzymuje rzeczy, których potrzebuje (baza danych, logger, zegar, klient płatności) z zewnątrz, zamiast tworzyć je wewnątrz.
Praktycznie najczęściej wygląda to jak przekazywanie zależności do konstruktora lub parametru funkcji, dzięki czemu są jawne i wymienne.
Inversion of Control (IoC) to szersza idea: klasa powinna skupiać się na tym, co robi, a nie jak zdobywa swoich współpracowników.
DI to powszechna technika realizująca IoC — przenosi tworzenie zależności na zewnątrz i przekazuje je do używających ich klas.
Jeśli zależność jest tworzona za pomocą new wewnątrz logiki biznesowej, trudniej ją potem podmienić.
To prowadzi do:
DI pomaga testom pozostać szybkimi i deterministycznymi, bo możesz wstrzykiwać duble testowe zamiast używać prawdziwych zewnętrznych systemów.
Typowe podmiany:
Kontener DI jest opcjonalny. Zacznij od ręcznego DI (przekazywanie zależności jawnie) gdy:
Rozważ kontener, gdy okablowanie staje się powtarzalne lub potrzebujesz zarządzania żywotnością (singleton/per-request).
Użyj constructor injection, gdy zależność jest wymagana, by obiekt działał i jest używana w wielu metodach.
Użyj parameter/method injection, gdy jest potrzebna tylko dla pojedynczego wywołania (np. wartość specyficzna dla żądania, jednorazowa strategia).
Unikaj setter/property injection chyba że naprawdę potrzebujesz późnego powiązania; dodaj walidację, by natychmiast zgłosić brak zależności.
Composition root to miejsce, gdzie składasz aplikację: tworzysz implementacje i przekazujesz je do usług, które ich potrzebują.
Trzymaj to blisko startu aplikacji (punkt wejścia), żeby reszta kodu skupiła się na zachowaniu, a nie na okablowaniu.
Seam testowy to świadome miejsce, gdzie można podmienić zachowanie.
Dobre miejsca na seams to trudne do testowania obszary:
Clock.now())DI tworzy seams, pozwalając w testach wstrzyknąć zamiennik implementacji.
Typowe pułapki:
container.get() w kodzie biznesowym ukrywa zależności; preferuj jawne parametry.Wykonuj małe, powtarzalne refaktory:
Powtarzaj dla kolejnego seamu; możesz przerwać po każdym kroku bez wielkiego przebudowywania systemu.