09 sie 2025·7 min
Wzorce konfiguracji środowisk dla dev, staging i prod
Wzorce konfiguracji środowisk, które trzymają URL-e, klucze i flagi funkcji poza kodem w aplikacjach web, backend i mobilnych dla dev, staging i prod.
Dlaczego twardo wpisana konfiguracja ciągle powoduje problemy
Twardo wpisana konfiguracja wydaje się w porządku pierwszego dnia. Potem potrzebujesz środowiska staging, drugiego API albo szybkiego przełączenia funkcji i „prosta” zmiana zamienia się w ryzyko wydania. Naprawa jest prosta: trzymaj wartości środowiska poza plikami źródłowymi i umieść je w przewidywalnym układzie.
Najczęstsze problemy są łatwe do zauważenia:
- Bazowe URL-e API „wypieczone” w aplikacji (dzwonisz do produkcji podczas testów, albo do dev po wydaniu)
- Klucze API zatwierdzone do repo (wycieki, niespodziewane rachunki, awaryjne rotacje)
- Przełączniki funkcji zapisane jako stałe (musisz wypuścić kod, żeby coś wyłączyć)
- Identyfikatory analityki i raportowania błędów wpisane na stałe (dane trafiają tam, gdzie nie powinny)
„Po prostu zmień to dla prod” tworzy przyzwyczajenie szybkich, ostatnich zmian. Te edycje często omijają review, testy i powtarzalność. Ktoś zmienia URL, inna osoba zmienia klucz i nagle nie potrafisz odpowiedzieć na podstawowe pytanie: jaka dokładnie konfiguracja została wypchnięta z tym buildem?
Typowy scenariusz: budujesz nową wersję mobilną przeciwko staging, potem ktoś przed wydaniem przestawia URL na prod. Backend zmienia się następnego dnia i trzeba cofnąć. Jeśli URL jest w kodzie, rollback oznacza kolejną aktualizację aplikacji. Użytkownicy czekają, zgłoszenia do wsparcia rosną.
Celem jest prosty schemat działający w aplikacji web, backendzie Go i aplikacji Flutter:
- jasne zasady, co należy do kodu a co do konfiguracji
- bezpieczne domyślne wartości dla dev, staging i prod
- przełączniki funkcji, które można zmieniać bez pełnego rebuildu
- sekrety obsługiwane poza repozytorium, z możliwością rotacji
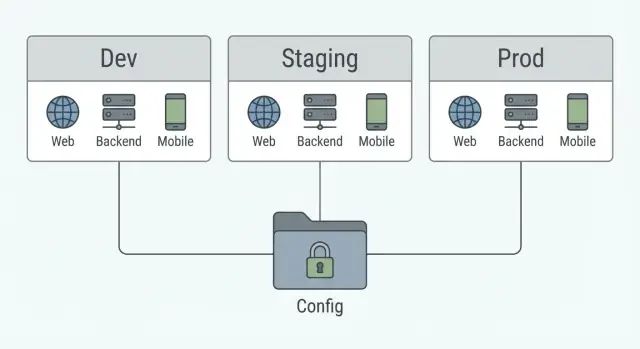
Co naprawdę się zmienia między dev, staging i prod
Dev, staging i prod powinny wyglądać jak ta sama aplikacja uruchomiona w trzech miejscach. Sednem jest zmieniać wartości, nie zachowanie.
Zmieniać się powinno wszystko, co wiąże się z miejscem uruchomienia lub z użytkownikami: bazowe URL-e i hosty, poświadczenia, integracje sandbox vs realne oraz zabezpieczenia jak poziom logowania czy bardziej restrykcyjne ustawienia bezpieczeństwa w prod.
To, co powinno pozostać takie samo, to logika i kontrakt między częściami. Trasy API, kształty żądań i odpowiedzi, nazwy funkcji i podstawowe reguły biznesowe nie powinny różnić się między środowiskami. Jeśli staging zachowuje się inaczej, przestaje być wiarygodną próbą generalną dla produkcji.
Praktyczna reguła dla „nowego środowiska” vs „nowej wartości konfiguracyjnej”: stwórz nowe środowisko tylko wtedy, gdy potrzebujesz izolowanego systemu (oddzielne dane, dostęp i ryzyko). Jeśli potrzebujesz tylko innych endpointów lub innych liczb, dodaj wartość konfiguracyjną zamiast nowego środowiska.
Przykład: chcesz przetestować nowego dostawcę wyszukiwania. Jeśli można go włączyć dla małej grupy, trzymaj jedno środowisko staging i dodaj flagę funkcji. Jeśli wymaga oddzielnej bazy danych i ścisłej kontroli dostępu, wtedy nowe środowisko ma sens.
Praktyczny model konfiguracji, którego możesz używać wszędzie
Dobre ustawienie robi jedną rzecz dobrze: utrudnia przypadkowe wypchnięcie dev URL, testowego klucza lub niedokończonej funkcji.
Używaj tych samych trzech warstw dla każdej aplikacji (web, backend, mobile):
- Domyślny: bezpieczne wartości działające w większości miejsc.
- Nadpisania środowiskowe: to, co zmienia się dla dev, staging, prod.
- Sekrety: wartości wrażliwe, które nigdy nie znajdują się w repo.
Aby uniknąć zamieszania, wybierz jedno źródło prawdy na aplikację i trzymaj się go. Na przykład backend czyta zmienne środowiskowe przy starcie, aplikacja web czyta zmienne w czasie builda lub ma mały runtime config, a aplikacja mobilna czyta mały plik środowiskowy wybrany podczas builda. Spójność wewnątrz każdej aplikacji jest ważniejsza niż wymuszanie dokładnie tego samego mechanizmu wszędzie.
Prosty, wielokrotnego użytku schemat wygląda tak:
- Domyślne wartości żyją w kodzie jako nieczułe stałe (timeouts, page size, retry counts).
- Nadpisania żyją w plikach specyficznych dla środowiska lub zmiennych środowiskowych (API base URL, analytics on/off).
- Sekrety żyją w magazynie sekretów i są wstrzykiwane podczas deployu/builda (JWT secret, hasło do bazy, klucze API zewnętrznych usług).
Nazewnictwo, które ludzie zrozumieją
Nadaj każdemu elementowi konfiguracji jasną nazwę odpowiadającą na trzy pytania: czym jest, gdzie ma zastosowanie i jakiego jest typu.
Praktyczna konwencja:
- Prefiksuj nazwą aplikacji: WEB_, API_, MOBILE_
- Używaj ALL_CAPS z podkreśleniami
- Grupuj po celu: API_BASE_URL, AUTH_JWT_SECRET, FEATURES_NEW_CHECKOUT
- Trzymaj boolea jawne: FEATURES_SEARCH_ENABLED=true
W ten sposób nikt nie musi zgadywać, czy „BASE_URL” jest dla aplikacji React, usługi Go, czy aplikacji Flutter.
Krok po kroku: konfiguracja aplikacji web (React) bez twardego wpisywania
Kod Reacta działa w przeglądarce użytkownika, więc wszystko, co wypuścisz, można odczytać. Celem jest proste: trzymaj sekrety na serwerze, a przeglądarka niech czyta tylko „bezpieczne” ustawienia jak API base URL, nazwa aplikacji czy nieczuła flaga funkcji.
1) Zdecyduj, co jest build-time, a co runtime
Konfiguracja build-time jest wstrzykiwana podczas budowania bundla. Nadaje się do wartości, które rzadko się zmieniają i można je bezpiecznie ujawnić.
Konfiguracja runtime jest ładowana przy starcie aplikacji (np. z małego pliku JSON serwowanego razem z aplikacją lub wstrzykniętego globala). Lepiej nadaje się do wartości, które możesz chcieć zmienić po deployu, jak przełączanie API base URL między środowiskami.
Prosta zasada: jeśli zmiana nie powinna wymagać przebudowy UI, traktuj to jako runtime.
2) Przechowuj bazowy URL API bez commitowania go
Miej lokalny plik dla deweloperów (niecommitowany) i ustaw prawdziwe wartości w pipeline CI/CD.
- Local dev: użyj
.env.local(ignorowany przez git) z czymś w rodzajuVITE_API_BASE_URL=http://localhost:8080 - CI/CD: ustaw
VITE_API_BASE_URLjako zmienną środowiskową w zadaniu builda, albo umieść ją w pliku runtime config tworzonym podczas deployu
Przykład runtime (serwowany obok aplikacji):
{ "apiBaseUrl": "https://api.staging.example.com", "features": { "newCheckout": false } }
Następnie załaduj to raz przy starcie i trzymaj w jednym miejscu:
export async function loadConfig() {
const res = await fetch('/config.json', { cache: 'no-store' });
return res.json();
}
3) Udostępniaj przeglądarce tylko bezpieczne wartości
Traktuj wszystko w React env vars jako publiczne. Nie umieszczaj haseł, prywatnych kluczy API ani URL-i bazy danych w aplikacji web.
Bezpieczne przykłady: API base URL, Sentry DSN (publiczny), numer wersji builda i proste flagi funkcji.
Krok po kroku: konfiguracja backendu (Go), którą możesz walidować
Konfiguracja backendu jest bezpieczniejsza, gdy jest typowana, ładowana ze zmiennych środowiskowych i walidowana zanim serwer zacznie przyjmować ruch.
Zacznij od określenia, czego backend potrzebuje do działania, i jawnie zdefiniuj te wartości. Typowe „must have” to:
APP_ENV(dev, staging, prod)HTTP_ADDR(np.:8080)DATABASE_URL(Postgres DSN)PUBLIC_BASE_URL(używane do callbacków i linków)API_KEY(dla zewnętrznej usługi)
Załaduj je potem do struktury i zakończ działanie natychmiast, jeśli czegoś brakuje lub jest źle sformatowane. Dzięki temu znajdziesz problemy w sekundach, a nie po częściowym deployu.
package config
import (
"errors"
"net/url"
"os"
"strings"
)
type Config struct {
Env string
HTTPAddr string
DatabaseURL string
PublicBaseURL string
APIKey string
}
func Load() (Config, error) {
c := Config{
Env: mustGet("APP_ENV"),
HTTPAddr: getDefault("HTTP_ADDR", ":8080"),
DatabaseURL: mustGet("DATABASE_URL"),
PublicBaseURL: mustGet("PUBLIC_BASE_URL"),
APIKey: mustGet("API_KEY"),
}
return c, c.Validate()
}
func (c Config) Validate() error {
if c.Env != "dev" && c.Env != "staging" && c.Env != "prod" {
return errors.New("APP_ENV must be dev, staging, or prod")
}
if _, err := url.ParseRequestURI(c.PublicBaseURL); err != nil {
return errors.New("PUBLIC_BASE_URL must be a valid URL")
}
if !strings.HasPrefix(c.DatabaseURL, "postgres://") {
return errors.New("DATABASE_URL must start with postgres://")
}
return nil
}
func mustGet(k string) string {
v, ok := os.LookupEnv(k)
if !ok || strings.TrimSpace(v) == "" {
panic("missing env var: " + k)
}
return v
}
func getDefault(k, def string) string {
if v, ok := os.LookupEnv(k); ok && strings.TrimSpace(v) != "" {
return v
}
return def
}
To trzyma DSN bazy danych, klucze API i URL-e callbacków poza kodem i poza gitem. W hostowanych setupach wstrzykujesz te zmienne środowiskowe per środowisko, żeby dev, staging i prod mogły się różnić bez zmiany ani jednej linii.
Krok po kroku: konfiguracja mobilna (Flutter), która pozostaje elastyczna
Own the generated source
Keep control of your stack by exporting source code after you generate and deploy.
Aplikacje Flutter zwykle potrzebują dwóch warstw konfiguracji: flavorów build-time (to, co wypuszczasz) i ustawień runtime (co aplikacja może zmienić bez nowego wydania). Oddzielenie ich powstrzymuje „szybką zmianę URL-a” przed przerodzeniem się w awaryjny rebuild.
1) Używaj flavorów dla tożsamości, nie endpointów
Stwórz trzy flavor-y: dev, staging, prod. Flavors powinny kontrolować rzeczy, które muszą być ustalone na etapie builda, jak nazwa aplikacji, bundle id, podpisy, projekt analityki i czy narzędzia debugowe są włączone.
Następnie przekaż tylko nieczułe domyślne wartości za pomocą --dart-define (lub CI), tak aby nigdy ich nie wpisywać na stałe w kodzie:
ENV=stagingDEFAULT_API_BASE=https://api-staging.example.comCONFIG_URL=https://config.example.com/mobile.json
W Dart czytaj je przez String.fromEnvironment i zbuduj prosty obiekt AppConfig raz przy starcie.
2) Umieść URL-e i przełączniki w pobieranym configu
Jeśli chcesz unikać rebuildów przy małych zmianach endpointów, nie traktuj bazowego URL-a API jako stałej. Pobierz mały plik konfiguracyjny przy uruchomieniu aplikacji (i cache’uj go). Flavor ustawia tylko, skąd pobrać config.
Praktyczny podział:
- Flavor (build-time): tożsamość aplikacji, domyślny URL do configu, projekt do raportowania crashy
- Remote config (runtime): API base URL, flagi funkcji, procent rozsyłania, tryb maintenance
- Sekrety: nigdy nie wysyłane w aplikacji (binarne pliki mobilne można przejrzeć)
Jeśli przeniesiesz backend, zaktualizuj remote config, aby wskazywał nowy base URL. Istniejący użytkownicy pobiorą zmianę przy następnym uruchomieniu, z bezpiecznym fallbackem do ostatniej zbuforowanej wartości.
Flagi funkcji i przełączniki, które nie zamieniają się w chaos
Flagi funkcji są przydatne do stopniowych rolloutów, testów A/B, szybkich kill switchy i testowania ryzykownych zmian w staging przed włączeniem ich w prod. Nie zastępują kontroli bezpieczeństwa. Jeśli flaga chroni coś, co musi być zabezpieczone, to nie jest flaga — to reguła autoryzacji.
Traktuj każdą flagę jak API: jasna nazwa, właściciel i data zakończenia.
Nazewnictwo, które pokazuje intencję
Używaj nazw, które mówią, co się stanie, gdy flaga jest WŁĄCZONA i jaką część produktu dotyczy. Prosty schemat:
feature.checkout_new_ui_enabled(funkcja dla klienta)ops.payments_kill_switch(awaryjny wyłącznik)exp.search_rerank_v2(eksperyment)release.api_v3_rollout_pct(stopniowe wdrażanie)debug.show_network_logs(diagnostyka)
Preferuj pozytywne booleany (..._enabled) zamiast podwójnych zaprzeczeń. Trzymaj stabilny prefix, żeby można było wyszukać i audytować flagi.
Domyślne ustawienia, zabezpieczenia i sprzątanie
Zacznij od bezpiecznych domyślnych ustawień: jeśli serwis flag jest niedostępny, aplikacja powinna zachować się jak wersja stabilna.
Realistyczny wzorzec: wypuść nowe endpointy w backendzie, trzymaj stary w ruchu i użyj release.api_v3_rollout_pct, aby stopniowo przenosić ruch. Jeśli błędy skoczą, wyłącz bez hotfixa.
Aby uniknąć nagromadzenia flag, trzymaj się kilku zasad:
- Każda flaga ma właściciela i datę „usunąć do”
- Usuń flagi w ciągu 1–2 wydań po pełnym rolloutcie
- Loguj wartości flag w kluczowych przepływach dla debugowania
- Przeglądaj flagi co miesiąc jak zależności
Sekrety: przechowywanie, dostęp i podstawy rotacji
Validate backend config early
Generate a Go backend that reads env vars at startup and validates required settings.
„Sekret” to wszystko, co spowodowałoby szkody, gdyby wyciekło. Myśl o tokenach API, hasłach do bazy, sekretach klienta OAuth, kluczach do podpisywania (JWT), sekretach webhooków i prywatnych certyfikatach. Nie są sekretami: bazowe URL-e API, numery builda, flagi funkcji czy publiczne ID analityki.
Oddziel sekrety od reszty ustawień. Deweloperzy powinni móc swobodnie zmieniać bezpieczną konfigurację, podczas gdy sekrety są wstrzykiwane tylko w czasie runtime i tylko tam, gdzie są potrzebne.
Gdzie powinny żyć sekrety (wg środowiska)
W dev trzymaj sekrety lokalnie i łatwo je resetuj. Użyj pliku .env lub lokalnego keychainu i nigdy tego nie commituj.
W staging i prod sekrety powinny być w dedykowanym magazynie sekretów, nie w repo, nie w czacie i nie wypieczone w aplikacjach mobilnych.
- Web (React): nie umieszczaj sekretów w przeglądarce. Jeśli klient potrzebuje tokena, wydawaj krótkożyjący token z backendu.
- Backend (Go): ładuj sekrety ze zmiennych środowiskowych lub menedżera sekretów przy starcie i trzymaj je tylko w pamięci.
- Mobile (Flutter): traktuj aplikację jak publiczną. Każdy „sekret” w aplikacji można wyodrębnić, więc używaj tokenów wydawanych przez backend i bezpiecznego przechowywania sesji urządzenia tylko dla danych sesji użytkownika.
Podstawy rotacji (bez łamania produkcji)
Rotacja zawodzi, gdy zamienisz klucz i zapomnisz, że stare klienty nadal go używają. Zaplanuj okno nakładkowe.
- Wspieraj dwa ważne sekrety jednocześnie (aktywny + poprzedni) przez krótki okres.
- Najpierw wypchnij nowy sekret, potem przestaw wskaźnik „aktywny”.
- Monitoruj błędy autoryzacji, potem usuń stary sekret po zakończeniu okna.
- Loguj wersje sekretów (nie wartości) dla bezpiecznego debugowania.
To podejście nakładkowe działa dla kluczy API, sekretów webhook i kluczy podpisujących. Unika niespodziewanych przestojów.
Przykład rolloutu: zmiana URL-i API bez łamania użytkowników
Masz API staging i nowe API produkcyjne. Celem jest przeniesienie ruchu etapami z możliwością szybkiego cofnięcia. To jest łatwiejsze, gdy aplikacja czyta base URL API z konfiguracji, a nie z kodu.
Traktuj URL API jako wartość deploy-time wszędzie. W aplikacji web (React) często jest to wartość build-time lub plik runtime config. W mobile (Flutter) to zwykle flavor plus remote config. W backendzie (Go) to runtime env var. Ważne jest spójne używanie jednej nazwy zmiennej (np. API_BASE_URL) i nigdy nie osadzaj URL-a w komponentach, serwisach ani ekranach.
Bezpieczny, etapowy rollout może wyglądać tak:
- Wdróż prod API i trzymaj je „dark” (ruch wewnętrzny) podczas gdy staging pozostaje domyślny.
- Najpierw przełącz zależności backendu (jeśli backend wywołuje inne usługi), używając env vars i szybkiego restartu.
- Przenieś ruch webowy w małym wycinku (lub tylko konta wewnętrzne).
- Wypuść aplikację mobilną z nową konfiguracją, ale trzymaj serwerową flagę kontrolującą faktyczne przełączenie.
- Stopniowo zwiększaj ruch i miej gotowy rollback.
Weryfikacja polega głównie na wykrywaniu niespójności wcześnie. Zanim prawdziwi użytkownicy zaczną korzystać, potwierdź, że health endpointy odpowiadają, flowy autoryzacyjne działają, i to samo konto testowe może przejść kluczową ścieżkę end-to-end.
Szybka lista kontrolna przed wypuszczeniem
Większość produkcyjnych błędów konfiguracyjnych jest nudna: pozostawiona wartość staging, odwrócona flaga, albo brakujący klucz API w jednym regionie. Szybkie sprawdzenie łapie większość z nich.
Przed deployem potwierdź, że trzy rzeczy pasują do docelowego środowiska: endpointy, sekrety i domyślne wartości.
- Bazowe URL-e wskazują właściwe miejsce (API, auth, CDN, płatności). Sprawdź web, backend i mobile oddzielnie.
- Żadne klucze testowe w produkcji i żadne produkcyjne w dev/staging. Sprawdź też, czy nazwy kluczy pasują do oczekiwań aplikacji.
- Flagi funkcji mają bezpieczne domyślne wartości. Wszystko ryzykowne powinno domyślnie być wyłączone i włączane świadomie.
- Ustawienia builda i release pasują (bundle ID/nazwa pakietu, custom domain, CORS, OAuth redirect URLs).
- Observability jest skonfigurowana (logi, raportowanie błędów, tracing) i oznaczona właściwym środowiskiem.
Następnie wykonaj szybki smoke test. Wybierz jeden rzeczywisty przepływ użytkownika i przeprowadź go end-to-end na świeżej instalacji lub w czystym profilu przeglądarki, żeby nie polegać na zbuforowanych tokenach.
- Otwórz aplikację i potwierdź, że ładuje się bez błędów w konsoli.
- Zaloguj się i wywołaj jedno API wymagające auth (profil, ustawienia lub prostą listę danych).
- Wywołaj jedno kontrolowane niepowodzenie (błędne dane lub tryb offline) i potwierdź, że widzisz przyjazny komunikat, a nie pusty ekran.
- Sprawdź logi i raporty błędów: jeden testowy błąd powinien pojawić się pod właściwym środowiskiem w ciągu kilku minut.
Praktyczny nawyk: traktuj staging jak produkcję z innymi wartościami. To oznacza ten sam schemat konfiguracji, te same reguły walidacji i tę samą strukturę wdrożenia. Tylko wartości powinny się różnić, nie struktura.
Typowe błędy prowadzące do przestojów
Keep browser config safe
Create a React app that uses safe runtime config for API URLs and feature switches.
Większość awarii konfiguracyjnych nie jest egzotyczna. To proste pomyłki, które prześlizgują się, bo konfiguracja rozsiana jest po plikach, krokach builda i dashboardach i nikt nie potrafi odpowiedzieć: „Jakich wartości ta aplikacja będzie używać teraz?” Dobre ustawienie ułatwia odpowiedź na to pytanie.
Mieszanie ustawień build-time i runtime
Częstą pułapką jest wkładanie wartości runtime w miejsca build-time. Wypieczenie bazowego URL-a API w buildzie Reacta oznacza, że musisz przebudować dla każdego środowiska. Potem ktoś wdraża zły artefakt i produkcja wskazuje na staging.
Bardziej bezpieczna reguła: piecz tylko wartości, które naprawdę nigdy nie zmieniają się po wydaniu (np. wersja aplikacji). Trzymaj szczegóły środowiska (API URL-e, przełączniki funkcji, endpointy analityki) jako runtime gdzie to możliwe i uczyn źródło prawdy oczywistym.
Wysyłanie endpointów deweloperskich lub testowych kluczy
To zdarza się, gdy domyślne wartości są „pomocne”, ale niebezpieczne. Aplikacja mobilna może domyślnie wskazywać na dev API, jeśli nie potrafi odczytać configu, albo backend może wrócić do lokalnej bazy, jeśli zmienna środowiskowa jest brakująca. To zmienia mały błąd konfiguracyjny w pełen outage.
Dwa nawyki pomagają:
- Fail closed: jeśli wymagana wartość jest brakująca, zakończ działanie z jasnym błędem.
- Uczyń produkcję najtrudniejszą do źle skonfigurowania: brak dev domyślnych, brak testowych kluczy, brak włączonych debug endpointów.
Realistyczny przykład: wydanie w piątek wieczorem zawierało przez pomyłkę stagingowy klucz płatności w buildzie produkcyjnym. Wszystko „działa” aż do momentu, gdy płatności zaczynają się niepowodzeniem. Naprawa to nie nowa biblioteka płatności, tylko walidacja odrzucająca nie-produkcyjne klucze w środowisku produkcyjnym.
Pozwolenie, by staging oddalił się od produkcji
Staging, który nie odzwierciedla produkcji, daje fałszywe poczucie bezpieczeństwa. Inne ustawienia bazy, brak zadań background czy dodatkowe flagi powodują, że błędy pojawiają się dopiero po wydaniu.
Trzymaj staging blisko produkcji przez odzwierciedlenie tego samego schematu konfiguracji, tych samych reguł walidacji i tego samego kształtu wdrożenia. Tylko wartości powinny się różnić.
Następne kroki: uczynić konfigurację nudną, powtarzalną i bezpieczną
Cel to nie fantazyjne narzędzia. To nudna spójność: te same nazwy, te same typy, te same reguły w dev, staging i prod. Gdy konfiguracja jest przewidywalna, wydania przestają być ryzykowne.
Zacznij od zapisania jasnego kontraktu konfiguracji w jednym miejscu. Niech będzie krótki, ale konkretny: każda nazwa klucza, jej typ (string, number, boolean), skąd może pochodzić (env var, remote config, build-time) i jej domyślna wartość. Dodaj notatki dla wartości, które nigdy nie powinny być ustawione w aplikacji klienckiej (jak prywatne klucze API). Traktuj ten kontrakt jak API: zmiany wymagają review.
Następnie spraw, by błędy wychodziły szybko. Najlepszy moment, żeby odkryć brakujący API base URL, to CI, nie po deployu. Dodaj automatyczną walidację, która ładuje konfigurację tak samo jak aplikacja i sprawdza:
- wymagane wartości są obecne (bez pustych stringów)
- typy są poprawne (bez błędów "true" vs true)
- reguły prod-only przechodzą (np. wymóg HTTPS)
- flagi funkcji mają znane nazwy (brak literówek)
- sekrety nie są zatwierdzone do repo
Wreszcie, ułatw odzyskiwanie, gdy zmiana konfiguracji pójdzie źle. Snapshotuj co działa, zmieniaj jedną rzecz naraz, szybko weryfikuj i miej gotową ścieżkę rollbacku.
Jeśli budujesz i wdrażasz z platformą taką jak Koder.ai (koder.ai), te same zasady obowiązują: traktuj wartości środowiska jako wejścia do builda i hostingu, trzymaj sekrety poza eksportowanym źródłem i waliduj konfigurację zanim wypchniesz. To ta sama spójność, która sprawia, że redeploye i rollbacks stają się rutynowe.
Gdy konfiguracja jest udokumentowana, walidowana i odwracalna, przestaje być źródłem outage'ów i staje się normalną częścią procesu wydawniczego.