21 wrz 2025·7 min
Wzorzec Disruptor dla niskich opóźnień: projektowanie przewidywalnego czasu rzeczywistego
Poznaj wzorzec Disruptor dla niskich opóźnień i dowiedz się, jak projektować systemy czasu rzeczywistego z przewidywalnymi czasami reakcji, używając kolejek, pamięci i właściwych wyborów architektury.
Dlaczego aplikacje czasu rzeczywistego wydają się wolne nawet gdy kod jest szybki
Szybkość ma dwa oblicza: przepustowość i opóźnienie. Przepustowość to ile pracy kończysz na sekundę (żądania, wiadomości, klatki). Opóźnienie to ile czasu zajmuje pojedyncza jednostka pracy od początku do końca.
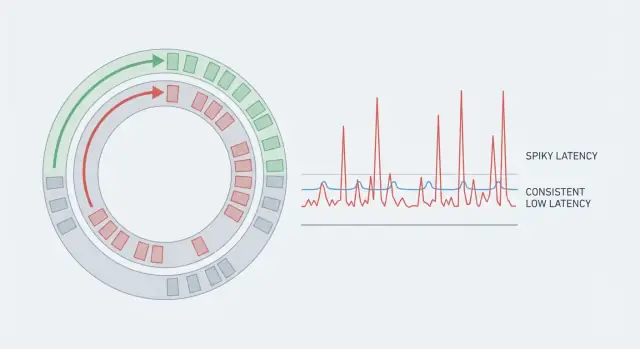
System może mieć świetną przepustowość i mimo to sprawiać wrażenie powolnego, jeśli niektóre żądania trwają znacznie dłużej niż inne. Dlatego średnie wartości wprowadzają w błąd. Jeśli 99 akcji trwa 5 ms, a jedna 80 ms, średnia wygląda dobrze, ale osoba, która trafiła na przypadek 80 ms, odczuje zacięcie. W systemach czasu rzeczywistego te rzadkie skoki to cała historia, bo przerywają rytm.
Przewidywalne opóźnienie oznacza, że nie celujesz tylko w niską średnią. Celu jesz w konsekwencję, tak by większość operacji kończyła się w wąskim przedziale. Dlatego zespoły obserwują ogon rozkładu (p95, p99). Tam kryją się pauzy.
Skok 50 ms może mieć znaczenie w miejscach takich jak głos i wideo (zakłócenia audio), gry multiplayer (rubber-banding), trading w czasie rzeczywistym (przegapione ceny), monitoring przemysłowy (spóźnione alarmy) czy dashboardy na żywo (liczby skaczą, alerty wydają się niewiarygodne).
Prosty przykład: aplikacja czatu może dostarczać wiadomości szybko większość czasu. Ale jeśli tło zatrzyma się na moment i jedna wiadomość przyjdzie o 60 ms później, wskaźniki pisania zamarzają i rozmowa wydaje się opóźniona, mimo że serwer wygląda „szybko” średnio.
Jeśli chcesz, by czas rzeczywisty naprawdę tak działał, potrzebujesz mniej niespodzianek, nie tylko szybszego kodu.
Podstawy opóźnień: gdzie naprawdę ucieka czas
Większość systemów czasu rzeczywistego nie jest wolna, bo CPU kuleje. Wydają się wolne, bo praca spędza większość życia czekając: na zaplanowanie, w kolejce, na sieć lub na magazyn.
End-to-end latency to pełny czas od „coś się stało” do „użytkownik widzi wynik”. Nawet jeśli twój handler działa 2 ms, żądanie może trwać 80 ms, jeśli pauzuje w pięciu różnych miejscach.
Użyteczny podział ścieżki to:
- Czas sieciowy (klient do edge, serwis do serwisu, ponowienia)
- Czas planowania (twój wątek czeka na uruchomienie)
- Czas w kolejce (praca stoi za inną pracą)
- Czas magazynowania (dysk, blokady bazy, cache missy)
- Czas serializacji (kodowanie i dekodowanie danych)
Te oczekiwania się kumulują. Kilka milisekund tu i tam zamienia „szybką” ścieżkę w powolne doświadczenie.
Tail latency to miejsce, gdzie użytkownicy zaczynają narzekać. Średnie opóźnienie może wyglądać w porządku, ale p95 lub p99 to najwolniejsze 5% lub 1% żądań. Outliery zwykle pochodzą z rzadkich pauz: cykl GC, hałaśliwy sąsiad na hoście, krótkie zatory na blokadzie, ponowne napełnienie cache lub nagły napływ, który tworzy kolejkę.
Konkret: update ceny przychodzi przez sieć w 5 ms, czeka 10 ms na obciążonego worker'a, spędza 15 ms za innymi zdarzeniami, a potem natrafia na problem z bazą na 30 ms. Twój kod nadal wykonał się w 2 ms, ale użytkownik czekał 62 ms. Celem jest uczynienie każdego kroku przewidywalnym, nie tylko przyspieszenie obliczeń.
Zwykłe źródła jitteru poza szybkością kodu
Szybki algorytm może nadal wydawać się wolny, jeśli czas na żądanie skacze. Użytkownicy zauważają skoki, nie średnie. Te wahania to jitter i często pochodzą z rzeczy, którymi twój kod nie zawsze może zarządzać.
Cache CPU i zachowanie pamięci to ukryte koszty. Jeśli „gorące” dane nie mieszczą się w cache, CPU zatrzymuje się oczekując RAM. Struktury pełne obiektów, rozproszona pamięć i kolejne „jeszcze jedno odwołanie” zamieniają się w powtarzające się cache missy.
Alokacja pamięci dodaje losowość. Tworzenie wielu krótkotrwałych obiektów zwiększa presję na stertę, co później objawia się pauzami (GC) lub kontencją alokatora. Nawet bez GC częste alokacje mogą fragmentować pamięć i pogorszyć lokalność.
Planowanie wątków to kolejne źródło. Kiedy wątek zostaje odstawiony, płacisz koszt przełączenia kontekstu i tracisz „rozgrzanie” cache. Na obciążonej maszynie twój wątek „real-time” może czekać za obcą pracą.
Kontencja na blokadach to miejsce, gdzie przewidywalne systemy często się rozsypują. Blokada, która „zwykle jest wolna”, może zamienić się w konwój: wątki budzą się, walczą o lock i kładą się z powrotem do snu. Praca nadal się wykonuje, ale tail latency się wydłuża.
Oczekiwania I/O mogą przytłoczyć wszystko inne. Pojedyncze wywołanie systemowe, pełny bufor sieciowy, handshake TLS, flush dysku czy wolne zapytanie DNS mogą stworzyć ostry skok, którego nie naprawi żadna mikropoprawka.
Jeśli polujesz na jitter, zacznij od szukania cache missów (często spowodowanych strukturami wskaźnikowymi i losowym dostępem), częstych alokacji, przełączeń kontekstu z powodu zbyt wielu wątków lub hałaśliwych sąsiadów, kontencji na lockach oraz wszelkiego blokującego I/O (sieć, dysk, logowanie, wywołania synchroniczne).
Przykład: serwis tickera cenowego może obliczać aktualizacje w mikrosekundach, ale pojedyncze synchroniczne wywołanie loggera lub kontencja na locku metryk może okresowo dodać dziesiątki milisekund.
Martin Thompson i co to jest wzorzec Disruptor
Martin Thompson jest znany w inżynierii niskich opóźnień za skupienie na zachowaniu systemów pod obciążeniem: nie tylko średniej szybkości, lecz przewidywalności. Wraz z zespołem LMAX pomógł spopularyzować wzorzec Disruptor — referencyjne podejście do przesyłania zdarzeń przez system z małymi i spójnymi opóźnieniami.
Podejście Disruptor to reakcja na to, co czyni wiele „szybkich” aplikacji nieprzewidywalnymi: kontencję i koordynację. Typowe kolejki często opierają się na blokadach lub ciężkich atomikach, budzą wątki w górę i w dół oraz tworzą skoki oczekiwania, gdy producenci i konsumenci walczą o współdzielone struktury.
Zamiast zwykłej kolejki, Disruptor używa bufora pierścieniowego: stałej, okrągłej tablicy, która przechowuje zdarzenia w slotach. Producenci rezerwują następny slot, zapisują dane, a potem publikują numer sekwencji. Konsumenci czytają kolejno śledząc tę sekwencję. Ponieważ bufor jest prealokowany, unikasz częstych alokacji i zmniejszasz presję na garbage collector.
Kluczowa idea to zasada jednego piszącego: trzymaj jedną odpowiedzialną za dany kawałek współdzielonego stanu (np. kursor przesuwający się po pierścieniu). Mniej piszących oznacza mniej momentów „kto idzie następny?”.
Backpressure jest jawny. Gdy konsumenci zostają w tyle, producenci w pewnym momencie trafiają na jeszcze używany slot. Wtedy system musi czekać, odrzucić lub zwolnić, ale robi to w kontrolowany i widoczny sposób, zamiast ukrywać problem w rosnącej kolejce.
Podstawowe pomysły projektowe, które utrzymują opóźnienie spójnym
To, co czyni projekty w stylu Disruptor szybkimi, to nie żaden sprytny trik mikrooptymalizacyjny. To usuwanie nieprzewidywalnych pauz, które pojawiają się, gdy system walczy z własnymi ruchomymi częściami: alokacjami, cache missami, kontencją na lockach i wolną pracą w gorącym ścieżce.
Użyteczny mentalny model to linia montażowa. Zdarzenia poruszają się po stałej trasie z jasnymi przekazaniami. To zmniejsza współdzielony stan i ułatwia utrzymanie prostoty i mierzalności każdego kroku.
Utrzymuj pamięć i dane przewidywalne
Szybkie systemy unikają niespodzianych alokacji. Jeśli prealokujesz bufory i ponownie używasz obiektów wiadomości, redukujesz „czasami” skoki powodowane GC, wzrostem sterty i blokadami alokatora.
Pomaga też utrzymywać wiadomości małe i stabilne. Gdy dane dotykane na zdarzenie mieszczą się w cache CPU, spędzasz mniej czasu czekając na pamięć.
W praktyce najważniejsze zwyczaje to: ponownie używaj obiektów zamiast tworzyć nowe dla każdego zdarzenia, utrzymuj dane zdarzeń zwarte, preferuj jednego piszącego dla współdzielonego stanu i ostrożnie batchuj, aby koszty koordynacji płacić rzadziej.
Uczyń ścieżki wolne od opóźnień oczywistymi
Aplikacje czasu rzeczywistego często potrzebują dodatków jak logowanie, metryki, retry czy zapisy do bazy. Filozofia Disruptor polega na izolowaniu tych elementów od pętli krytycznej, żeby nie mogły jej zablokować.
W feedzie cen gorąca ścieżka może tylko walidować tick i publikować kolejną snapshotę ceny. Wszystko, co może zablokować (dysk, wywołania sieciowe, ciężka serializacja), przenosimy do oddzielnego konsumenta lub kanału bocznego, aby ścieżka przewidywalna pozostała przewidywalna.
Wybory architektoniczne dla przewidywalnego opóźnienia
Sprawdź krytyczną ścieżkę
Zdobądź kod źródłowy i przejrzyj gorące ścieżki, alokacje i blokujące wywołania.
Przewidywalne opóźnienie to głównie problem architektury. Możesz mieć szybki kod i mimo to otrzymywać skoki, jeśli zbyt wiele wątków walczy o te same dane lub jeśli wiadomości bezsensownie skaczą po sieci.
Zacznij od decyzji, ilu piszących i czytających dotyka tej samej kolejki lub bufora. Pojedynczy producent jest łatwiejszy do utrzymania gładkim, bo unika koordynacji. Konfiguracje multi-producer zwiększają przepustowość, ale często dodają kontencję i utrudniają przewidywalność najgorszego przypadku. Jeśli potrzebujesz wielu producentów, zmniejsz współdzielenie zapisu przez sharding zdarzeń po kluczu (np. userId czy instrumentId), tak by każdy shard miał własną gorącą ścieżkę.
Po stronie konsumentów, pojedynczy konsument daje najbardziej stabilne timing, gdy kolejność ma znaczenie, bo stan pozostaje lokalny dla jednego wątku. Pule workerów pomagają, gdy zadania są naprawdę niezależne, ale dodają opóźnienia planowania i mogą zmieniać kolejność pracy, jeśli nie będziesz ostrożny.
Batching to kolejny kompromis. Małe partie redukują narzut (mniej budzeń, mniej cache missów), ale batchowanie może też dodać oczekiwanie, jeśli przytrzymujesz zdarzenia, by wypełnić partię. Jeśli batchujesz w systemie czasu rzeczywistego, ogranicz maksymalny czas oczekiwania (np. „do 16 zdarzeń lub 200 mikrosekund, które nadejdzie pierwsze”).
Granice usług też się liczą. Messaging w procesie jest zwykle najlepszy, gdy potrzebujesz niskiego opóźnienia. Hopy sieciowe są opłacalne dla skalowania, ale każdy hop dodaje kolejki, ponowienia i zmienną latencję. Jeśli potrzebujesz takiego hopa, utrzymuj protokół prosty i unikaj fan-outu na gorącej ścieżce.
Praktyczna zasada: gdy możesz, trzymaj jednego piszącego na shard, skaluj przez sharding kluczy zamiast jedną gorącą kolejkę, batchuj tylko z twardym limitem czasu, dodawaj pule workerów tylko dla równoległej i niezależnej pracy, i traktuj każdy hop sieciowy jako potencjalne źródło jitteru, dopóki go nie zmierzysz.
Krok po kroku: projektowanie potoku o niskim jitterze
Zacznij od zapisanego budżetu opóźnienia zanim dotkniesz kodu. Wybierz cel (co „dobrze” znaczy) i p99 (czego musisz się trzymać). Podziel tę wartość na etapy: wejście, walidacja, dopasowanie, trwałość i aktualizacje wychodzące. Jeśli etap nie ma budżetu, nie ma limitu.
Następnie narysuj pełny przepływ danych i oznacz każde przekazanie: granice wątków, kolejki, skoki sieciowe i wywołania do magazynu. Każde przekazanie to miejsce, gdzie kryje się jitter. Gdy je widzisz, możesz je ograniczyć.
Praktyczny workflow, który trzyma projekt w ryzach:
- Napisz budżet na etap (target i p99), plus mały margines na nieznane.
- Zmapuj pipeline i oznacz kolejki, locki, alokacje i blokujące wywołania.
- Wybierz model współbieżności, który potrafisz przemyśleć (single writer, partycjonowani workerzy po kluczu lub dedykowany wątek I/O).
- Zdefiniuj kształt wiadomości wcześnie: stabilne schematy, zwarte ładunki i minimalne kopiowanie.
- Zdecyduj reguły backpressure z góry: drop, delay, degrade lub shed load. Uczyń je widocznymi i mierzalnymi.
Potem zdecyduj co może być asynchroniczne bez psucia doświadczenia użytkownika. Prosta zasada: wszystko, co zmienia to, co użytkownik widzi „teraz”, pozostaje na ścieżce krytycznej. Resztę przenieś na bok.
Analizy, logi audytowe i indeksowanie wtórne często można przenieść poza gorącą ścieżkę. Walidacja, ordering i kroki potrzebne do wygenerowania następnego stanu zwykle nie.
Wybory runtime i OS wpływające na tail latency
Szybki kod może nadal wydawać się wolny, gdy runtime lub OS zatrzyma twoją pracę w niewłaściwym momencie. Cel to nie tylko wysoka przepustowość. To mniej niespodzianek w najwolniejszym 1% żądań.
Runtimy z GC (JVM, Go, .NET) mogą być świetne dla produktywności, ale mogą wprowadzać pauzy, gdy pamięć wymaga sprzątania. Nowoczesne kolektory są dużo lepsze niż kiedyś, lecz tail latency nadal może skakać, jeśli tworzysz dużo krótkotrwałych obiektów pod obciążeniem. Języki bez GC (Rust, C, C++) unikają pauz GC, ale przenoszą koszt na manualne zarządzanie własnością i dyscyplinę alokacji. Tak czy inaczej, zachowanie pamięci liczy się tak samo jak szybkość CPU.
Praktyczny nawyk jest prosty: znajdź miejsca alokacji i uczyn je nudnymi. Reużywaj obiektów, wstępnie rozmiaruj bufory i unikaj zamieniania gorących danych na tymczasowe stringi czy mapy.
Wybory dotyczące wątków też pokazują się jako jitter. Każda dodatkowa kolejka, asynchroniczny hop lub przekazanie puli dodaje oczekiwanie i zwiększa wariancję. Preferuj niewielką liczbę długowiecznych wątków, trzymaj granice producent-konsument jasne i unikaj blokujących wywołań na gorącej ścieżce.
Kilka ustawień OS i kontenerów często decyduje, czy ogon jest czysty czy skokowy. Dławienie CPU przez zbyt ciasne limity, hałaśliwi sąsiedzi na współdzielonych hostach oraz źle umieszczone logowanie lub metryki mogą tworzyć nagłe spowolnienia. Jeśli zmieniasz tylko jedną rzecz, zacznij od mierzenia szybkości alokacji i przełączeń kontekstu podczas skoków latency.
Dane, magazyn i granice usług bez niespodziewanych pauz
Mierz w rzeczywistych warunkach
Szybko postaw środowisko stagingowe, aby mierzyć rzeczywiste zakłócenia sieciowe.
Wiele skoków opóźnienia to nie „wolny kod”, lecz oczekiwania, których nie zaplanowano: blokada w bazie, sztorm ponowień, skok do innej usługi, który się zawiesił, lub cache miss zamieniający się w pełen round-trip.
Trzymaj ścieżkę krytyczną krótką. Każdy dodatkowy hop dodaje planowanie, serializację, kolejki sieciowe i więcej miejsc do blokowania. Jeśli możesz odpowiedzieć z jednego procesu i jednego magazynu danych, zrób to najpierw. Dziel na więcej usług tylko wtedy, gdy każde wywołanie jest opcjonalne lub ściśle ograniczone.
Ograniczone oczekiwanie to różnica między szybkimi średnimi a przewidywalnym opóźnieniem. Nakładaj twarde timeouty na wywołania zdalne i szybko odmawiaj, gdy zależność jest niezdrowa. Circuit breakery to nie tylko ochrona serwerów — ograniczają też, jak długo użytkownicy mogą być zablokowani.
Gdy dostęp do danych blokuje, oddziel ścieżki. Odczyty często chcą kształtów indeksowanych, denormalizowanych i cache-friendly. Zapisom zależy od trwałości i porządku. Oddzielenie ich może usunąć kontencję i skrócić czas blokad. Jeśli potrzeby spójności na to pozwalają, zapisy append-only (log zdarzeń) zachowują się częściej przewidywalnie niż aktualizacje in-place, które wywołują hot-row locking lub tło konserwacyjne.
Prosta zasada dla aplikacji czasu rzeczywistego: persistencja nie powinna siedzieć na ścieżce krytycznej, chyba że jest to naprawdę konieczne dla poprawności. Często lepszy kształt to: zaktualizuj w pamięci, odpowiedz, a potem zapisz asynchronicznie z mechanizmem replay (np. outbox lub write-ahead log).
W wielu potokach z buforem pierścieniowym kończy się to tak: opublikuj do bufora w pamięci, zaktualizuj stan, odpowiedz, a potem oddzielny konsument batchuje zapisy do PostgreSQL.
Realistyczny przykład: aktualizacje na żywo z przewidywalnym opóźnieniem
Wyobraź sobie aplikację współpracy na żywo (lub małą grę multiplayer), która wypycha aktualizacje co 16 ms (około 60 razy na sekundę). Celem nie jest „szybko średnio”. Celem jest „zwykle poniżej 16 ms”, nawet gdy połączenie jednego użytkownika jest słabe.
Prosty przepływ w stylu Disruptor wygląda tak: wejście od użytkownika staje się małym zdarzeniem, jest publikowane do prealokowanego bufora pierścieniowego, a następnie przetwarzane przez stały zestaw handlerów po kolei (waliduj -> zastosuj -> przygotuj wiadomości wychodzące) i w końcu broadcast do klientów.
Batching pomaga na krawędziach. Na przykład, batchuj wysyłki wychodzące per klient raz na tick, aby wołać warstwę sieciową rzadziej. Ale nie batchuj wewnątrz gorącej ścieżki w sposób, który „czeka jeszcze chwilę” na więcej zdarzeń. Czekanie to sposób na spóźnienie ticku.
Gdy coś zwalnia, traktuj to jako problem izolacji. Jeśli jeden handler zwalnia, odizoluj go za własnym buforem i zamiast blokować główną pętlę, publikuj lekkie zadanie robocze. Jeśli jeden klient jest wolny, nie pozwól mu zapchać broadcastera; daj każdemu klientowi małą kolejkę wysyłek i odrzucaj lub łącz stare aktualizacje, aby zachować najnowszy stan. Jeśli głębokość bufora rośnie, zastosuj backpressure na brzegu (przestań przyjmować dodatkowe wejścia na ten tick lub degraduj funkcje).
Wiesz, że to działa, gdy liczby pozostają nudne: backlog bliski zeru, rzadkie i wytłumaczalne odrzucenia/koalescencje, a p99 pozostaje poniżej budżetu ticka przy realistycznym obciążeniu.
Typowe błędy, które tworzą skoki opóźnień
Uczyń testy opóźnień uczciwymi
Wdróż i hostuj aplikację, aby testy obciążeniowe odzwierciedlały zachowanie produkcyjne.
Większość skoków opóźnień jest samo zadana. Kod może być szybki, ale system wciąż pauzuje, gdy czeka na inne wątki, OS lub cokolwiek poza cache CPU.
Kilka powtarzających się błędów:
- Używanie współdzielonych locków wszędzie, bo wydaje się proste. Jedna kontendowana blokada może zablokować wiele żądań.
- Mieszanie wolnego I/O w gorącej ścieżce, jak synchroniczne logowanie, zapisy do bazy lub zdalne wywołania.
- Trzymanie nieograniczonych kolejek. Ukrywają przeciążenie, aż masz sekundy backlogu.
- Obserwowanie średnich zamiast p95 i p99.
- Nadmierne strojenie za wcześnie. Przypięcie wątków nie pomoże, jeśli opóźnienia pochodzą z GC, kontencji lub czekania na socket.
Szybki sposób na redukcję skoków to uczynienie oczekiwań widocznymi i ograniczonymi. Przenieś wolną pracę na oddzielną ścieżkę, ogranicz kolejki i zdecyduj, co się stanie, gdy jesteś pełny (drop, shed, degrade).
Szybka lista kontrolna dla przewidywalnego opóźnienia
Traktuj przewidywalne opóźnienie jak cechę produktu, nie przypadek. Zanim stroisz kod, upewnij się, że system ma jasne cele i zabezpieczenia.
- Ustal jawny cel p99 (i p99.9, jeśli ma znaczenie), a potem napisz budżet opóźnienia na etap.
- Trzymaj gorącą ścieżkę wolną od blokującego I/O. Jeśli I/O musi być, przenieś je na ścieżkę boczną i ustal zachowanie, gdy się opóźnia.
- Używaj ograniczonych kolejek i zdefiniuj zachowanie przy przeciążeniu (drop, shed, coalesce, backpressure).
- Mierz ciągle: głębokość backlogu, czas na etap i tail latency.
- Minimalizuj alokacje w gorącej pętli i ułatw ich wykrywanie w profilach.
Prosty test: zasymuluj nagły napływ (10x normalnego ruchu przez 30 sekund). Jeśli p99 eksploduje, zapytaj gdzie pojawiają się oczekiwania: rosnące kolejki, wolny consumer, pauza GC czy współdzielony zasób.
Następne kroki: jak to zastosować w twojej aplikacji
Traktuj wzorzec Disruptor jako workflow, nie bibliotekę. Udowodnij przewidywalne opóźnienie za pomocą cienkiego plastra funkcjonalności zanim dodasz funkcje.
Wybierz jedną akcję użytkownika, która musi być natychmiastowa (np. „nowa cena przychodzi, UI się aktualizuje”). Zapisz budżet end-to-end, potem mierz p50, p95 i p99 od pierwszego dnia.
Sekwencja, która zwykle działa:
- Zbuduj cienki pipeline z jednym wejściem, jedną pętlą rdzeniową i jednym wyjściem. Waliduj p99 pod obciążeniem wcześnie.
- Uczyń odpowiedzialności jawne (kto posiada stan, kto publikuje, kto konsumuje) i trzymaj współdzielony stan małym.
- Dodawaj współbieżność i buforowanie krokami, i zachowaj możliwość cofnięcia zmian.
- Deployuj blisko użytkowników, gdy budżet jest napięty, a potem zmierz ponownie przy realistycznym obciążeniu (te same rozmiary payloadów, te same wzorce burstów).
Jeśli budujesz na Koder.ai (koder.ai), pomocne może być najpierw zmapowanie przepływu zdarzeń w Planning Mode, aby kolejki, locki i granice usług nie pojawiły się przypadkowo. Snapshoty i rollback ułatwiają też powtarzalne eksperymenty latency i cofanie zmian, które poprawiają przepustowość, ale pogarszają p99.
Trzymaj pomiary uczciwe. Użyj stałego skryptu testowego, zagrzej system i rejestruj zarówno przepustowość, jak i opóźnienie. Gdy p99 rośnie z obciążeniem, nie zaczynaj od „optymalizacji kodu”. Szukaj pauz pochodzących z GC, hałaśliwych sąsiadów, wybuchów logowania, planowania wątków lub ukrytych wywołań blokujących.
Często zadawane pytania
Dlaczego moja aplikacja wydaje się opóźniona, gdy średnie opóźnienie wygląda dobrze?
Średnie wartości ukrywają rzadkie przerwy. Jeśli większość działań jest szybka, ale kilka zajmuje znacznie dłużej, użytkownicy odczuwają to jako zająknięcie lub „lag”, zwłaszcza w przepływach czasu rzeczywistego, gdzie rytm ma znaczenie.
Monitoruj tail latency (np. p95/p99), ponieważ tam kryją się zauważalne przerwy.
Jaka jest różnica między przepustowością a opóźnieniem w systemach czasu rzeczywistego?
Przepustowość to ilość pracy wykonanej na sekundę. Opóźnienie to czas od początku do końca pojedynczej operacji.
Możesz mieć wysoką przepustowość, a jednocześnie sporadyczne długie oczekiwania — to one powodują, że aplikacje czasu rzeczywistego wydają się powolne.
Co właściwie mówi p95/p99 i dlaczego powinno mnie to obchodzić?
Tail latency (p95/p99) mierzy najsłabsze zapytania, nie typowe. p99 oznacza, że 1% operacji trwa dłużej niż ta wartość.
W aplikacjach czasu rzeczywistego ten 1% często objawia się jako zauważalny jitter: trzaski audio, "rubber-banding", migotanie wskaźników lub pominięte ticki.
Skąd zwykle bierze się opóźnienie end-to-end, jeśli mój kod jest szybki?
Większość czasu spędzona jest zwykle na czekaniu, nie na obliczeniach:
- Opóźnienia sieciowe i ponowienia
- Kolejkowanie za inną pracą
- Planowanie wątków i przełączanie kontekstu
- Zatory na magazynie danych (blokady, cache missy, flushy dysku)
- Serializacja i kopiowanie
Handler trwający 2 ms może dać łącznie 60–80 ms end-to-end, jeśli gdzieś czeka.
Jakie są najczęstsze przyczyny skoków opóźnienia (jitter) poza algorytmami?
Najczęstsze źródła jitteru to:
- Garbage collection lub kontencja alokatora
- Kontencja na blokadach (konwoje na „zwykle wolnych” lockach)
- Cache missy spowodowane strukturami wskaźnikowymi lub rozproszoną pamięcią
- Blokujące I/O w gorącym ścieżce (logowanie, DNS, dysk, wywołania synchroniczne)
- Zbyt wiele przekazań między wątkami i kolejek
Aby debugować, koreluj skoki z tempem alokacji, liczbą przełączeń kontekstu i głębokością kolejek.
Czym jest wzorzec Disruptor w prostych słowach?
Disruptor to wzorzec przesyłania zdarzeń przez potok z małymi, przewidywalnymi opóźnieniami. Wykorzystuje prealokowany bufor pierścieniowy i numery sekwencji zamiast typowej współdzielonej kolejki.
Celem jest redukcja nieprzewidywalnych przerw wynikających z kontencji, alokacji i budzenia wątków — tak, aby opóźnienia były „nudne”, a nie tylko szybkie średnio.
W jaki sposób prealokacja i ponowne użycie obiektów pomagają w przewidywalnym opóźnieniu?
Prealokacja i ponowne użycie obiektów/buforów w gorącym pętli zmniejsza:
- Presję na garbage collector
- Niespodziewany wzrost sterty
- Losowe spowolnienia alokatora
Również utrzymuj kompaktowe dane zdarzeń, aby CPU dotykało mniej pamięci (lepsze zachowanie cache).
Czy powinienem użyć pętli single-threaded, sharding czy worker pool do przetwarzania w czasie rzeczywistym?
Zacznij od ścieżki z jednym piszącym na shard, gdy to możliwe (łatwiej przewidzieć, mniej kontencji). Skaluj poprzez sharding kluczy (np. userId, instrumentId) zamiast dzielenia jednej gorącej kolejki.
Pule workerów używaj tylko do pracy naprawdę niezależnej; w przeciwnym razie często zyskujesz przepustowość kosztem gorszego tail latency i trudniejszego debugowania.
Kiedy batchowanie pomaga, a kiedy szkodzi opóźnieniu?
Batching zmniejsza narzut, ale może dodać oczekiwanie, jeśli trzymasz zdarzenia, by wypełnić paczkę.
Praktyczne podejście: ogranicz batch po rozmiarze i czasie (np. „do 16 zdarzeń lub 200 mikrosekund, które nadejdzie pierwsze”), by batch nie łamał cichego budżetu opóźnienia.
Jaki jest praktyczny krok po kroku sposób na zaprojektowanie potoku o niskim jitterze?
Najpierw zapisz budżet opóźnienia (target i p99), a potem podziel go na etapy. Zmapuj każde przekazanie (kolejki, pule, skoki sieciowe, zapisy) i mierz je: głębokość kolejek, czas na etap.
Trzymaj I/O poza ścieżką krytyczną, używaj ograniczonych kolejek i ustal z góry zachowanie przy przeciążeniu (drop, shed, coalesce, backpressure). Jeśli prototypujesz na Koder.ai, Planning Mode pomaga narysować granice wcześniej, a snapshoty/rollback ułatwiają eksperymenty wpływające na p99.