Co rozwiązuje aplikacja do zarządzania wycofaniami
Wycofanie funkcji to każda planowana zmiana, w której coś, na czym polegają użytkownicy, jest ograniczane, zastępowane lub usuwane. Może to oznaczać:
- Zniknięcie lub przeniesienie elementu w UI (przyciski, pulpity, ustawienia)
- Wycofanie endpointu API, wersjonowanie lub zmiana zachowania
- Zmianę planu lub uprawnień (obniżenie limitów, połączenie dodatku, usunięcie poziomu cenowego)
Nawet gdy kierunek produktu jest słuszny, wycofania zawodzą, gdy traktuje się je jako jednorazowe ogłoszenie zamiast zarządzanego workflowu wycofania.
Typowe tryby awarii
Oczywiste są niespodziewane usunięcia, ale prawdziwe szkody zwykle pojawiają się gdzie indziej: uszkodzone integracje, niepełna dokumentacja migracji, niespójne komunikaty w kanałach i skok zapytań do wsparcia tuż po wydaniu.
Zespoły też tracą ślad „kto jest dotknięty” i „kto co zatwierdził”. Bez śladu audytu trudno odpowiedzieć na podstawowe pytania: które konta wciąż używają starego feature flag? Których klientów powiadomiono? Jaka była obiecana data?
Dlaczego dedykowana aplikacja pomaga
Aplikacja do zarządzania wycofaniami centralizuje planowanie wycofań, tak by każde wycofanie miało jasnego właściciela, harmonogram i status. Wymusza spójne komunikaty (email, powiadomienia w aplikacji, automatyzacja release notes), śledzi postęp migracji i tworzy odpowiedzialność poprzez zatwierdzenia i ślad audytu.
Zamiast rozproszonych dokumentów i arkuszy kalkulacyjnych, otrzymujesz jedno źródło prawdy dla wykrywania wpływu, szablonów komunikatów i analityki adopcji.
Kto z tego korzysta
Product managerowie koordynują zakres i daty. Inżynieria wiąże zmiany z feature flags i wydaniami. Support i Customer Success polegają na dokładnych listach klientów i skryptach. Compliance i Security mogą wymagać zatwierdzeń, przechowywania powiadomień i dowodu, że klienci zostali poinformowani.
Cele, zakres i co nie jest celem
Aplikacja do zarządzania wycofaniami powinna istnieć po to, by redukować chaos, nie dorzucać kolejnego miejsca do „sprawdzania”. Zanim zaprojektujesz ekrany lub modele danych, uzgodnij, jak wygląda sukces i co jest wyraźnie poza zakresem.
Cele (na co optymalizujesz)
Zacznij od rezultatów ważnych dla Produktu, Supportu i Inżynierii:
- Mniej zgłoszeń do wsparcia i eskalacji związanych z breaking changes (metryka: wolumen ticketów przypisanych do wycofania).
- Wyższy odsetek ukończonych migracji przed deadline (metryka: % zmigrowanych według kohorty/planu).
- Mniej odwrotów na ostatnią chwilę z powodu odkrytych latek (metryka: liczba przedłużeń terminów lub rollbacków).
Przekuj to w jasne metryki sukcesu i poziomy usług:
- Czas od ogłoszenia → pierwsza akcja klienta
- Czas od ogłoszenia → 80% zmigrowanych
- % zmigrowanych do terminu (ogólnie i według kluczowych kont)
- SLA dla komunikacji: np. „Klienci otrzymują co najmniej 30 dni powiadomienia przy ważnych usunięciach.”
Zakres (czym zarządza aplikacja)
Bądź konkretny odnośnie obiektu wycofania. Możesz zacząć wąsko i rozszerzać:
- Produktowe funkcje (zachowanie UI, ustawienia)
- Endpointy/ pola API
- Integracje (webhooki, konektory zewnętrzne)
- Plany/poziomy (uprawnienia, limity)
- Albo zunifikowany model „zmiany”, który może reprezentować powyższe
Zdefiniuj też, co w twoim kontekście oznacza „migracja”: włączenie nowej funkcji, zmiana endpointu, instalacja nowej integracji albo ukończenie checklisty.
Ograniczenia (reguły, których nie unikniesz)
Typowe ograniczenia kształtujące projekt:
- Prywatność i zgodność: jakie dane użytkownika można przechowywać i wyświetlać
- Przechowywanie danych: czas trzymania śladów audytu, potrzeby eksportu, polityki usuwania
- Wymagania multi-tenant: segmentacja według workspace/org, hosting regionalny
- Zatwierdzenia: kto może publikować terminy, wysyłać komunikaty do klientów lub zmieniać końcowe daty
Co nie jest celem (Non-Goals)
Aby uniknąć rozszerzania zakresu, zdecyduj wcześnie, czego aplikacja nie będzie robić—przynajmniej w v1:
- Zastępowania pełnego systemu helpdesk, serwisu dokumentacji lub CRM
- Działania jako ogólne narzędzie do zarządzania projektami
- Automatycznego migrowania klientów bez wyraźnych zabezpieczeń i przypisanych właścicieli
Jasne cele i granice ułatwiają późniejsze decyzje dotyczące workflowów, uprawnień i powiadomień.
Cykl życia wycofania i etapy workflowu
Aplikacja powinna uczynić cykl życia wycofania oczywistym, aby każdy wiedział, co oznacza „dobrze” i co trzeba zrobić, zanim przejdzie się dalej. Zacznij od odwzorowania aktualnego procesu end-to-end: pierwsze ogłoszenie, zaplanowane przypomnienia, playbooki wsparcia i ostateczne usunięcie. Workflow aplikacji powinien najpierw odzwierciedlać rzeczywistość, a potem ją stopniowo ujednolicać.
Prosty, wykonalny model etapów
Praktyczny domyślny model to:
Proposed → Approved → Announced → Migration → Sunset → Done
Każdy etap powinien mieć jasną definicję, kryteria wyjścia i właściciela. Na przykład „Announced” nie powinno oznaczać „ktoś raz opublikował wiadomość”; powinno oznaczać, że ogłoszenie zostało dostarczone przez uzgodnione kanały i zaplanowano follow-upy.
Punkty kontrolne zapobiegające chaosowi na ostatnią chwilę
Dodaj wymagane punkty kontrolne, które muszą być ukończone (i zarejestrowane) zanim etap zostanie oznaczony jako zakończony:
- Przegląd prawny/komunikacyjny treści, dat i ewentualnych implikacji kontraktowych
- Aktualizacja dokumentacji (docs, FAQ, release notes, wewnętrzne runbooki)
- Plan rollbacku lub łagodzenia gotowy, włącznie z tym, kto decyduje i jak wykonać
- Gotowość wsparcia, włączając makra/skrypty i ścieżki eskalacji
Traktuj te punkty jako elementy pierwszej klasy: checklisty z przypisanymi osobami, terminami i dowodami (linki do ticketów lub dokumentów).
Własność i zatwierdzenia
Wycofania zawodzą, gdy odpowiedzialność jest niejasna. Zdefiniuj, kto jest właścicielem każdego etapu (Product, Engineering, Support, Docs) i wymagaj podpisów przy wysokim ryzyku—zwłaszcza przy przejściu Approved → Announced oraz Migration → Sunset.
Celem jest workflow lekkiego w codziennej pracy, ale rygorystycznego w punktach, gdzie koszt błędu jest wysoki.
Model danych: byty i relacje
Jasny model danych zapobiega temu, żeby wycofania zamieniały się w rozproszone dokumenty, ad-hoc komunikaty i niejasne właścicielstwo. Zacznij od niewielkiego zestawu obiektów, potem dodawaj pola tylko wtedy, gdy mają rzeczywisty wpływ na decyzje.
Podstawowe byty
Funkcja to element, którego doświadcza użytkownik (ustawienie, endpoint API, raport, workflow).
Wycofanie to zdarzenie czasowe dotyczące funkcji: kiedy ogłoszono, kiedy wprowadzono ograniczenia i kiedy ostatecznie wyłączono.
Plan migracji wyjaśnia, jak użytkownicy powinni przejść na zamiennik i jak będziesz mierzyć postęp.
Segment odbiorców definiuje, kto jest dotknięty (np. „Konta na planie X używające funkcji Y w ciągu ostatnich 30 dni”).
Komunikat rejestruje, co zostanie wysłane, gdzie i kiedy (email, in-app, banner, makro wsparcia).
Wymagane pola (których później będziesz pragnąć)
Dla Wycofania i Planu migracji traktuj następujące pola jako obowiązkowe:
- Harmonogramy: data ogłoszenia, data miękkiego końca (ostrzeżenia/ograniczenia), data ostatecznego wyłączenia (sunset) oraz strefa czasowa.
- Dotknięte powierzchnie: obszary UI, trasy API, strony dokumentacji, integracje, billing/uprawnienia.
- Ścieżka zastępcza: link do nowej funkcji, krok-po-kroku instrukcje migracji i znane ograniczenia.
- Poziom ryzyka: niski/średni/wysoki z krótkim uzasadnieniem (np. „łamie automatyzację dla power userów”).
Relacje (jak to wszystko łączyć)
Modeluj hierarchię odwzorowującą rzeczywistość:
- Jedna Funkcja → wiele Wycofań (wiele sunsetów w czasie, regionalne rollouty lub zmiany polityk).
- Jedno Wycofanie → zwykle jeden Plan migracji i wiele Segmentów odbiorców (różne komunikaty i terminy).
- Jedno Wycofanie → wiele Komunikatów (kanały i etapy), każdy opcjonalnie przypisany do konkretnego Segmentu odbiorców.
Pola audytowe i governance
Dodaj pola audytowe wszędzie: created_by, approved_by, created_at, updated_at, approved_at, plus historię zmian (kto co zmienił i dlaczego). To pozwala na dokładny ślad audytu, gdy support, prawny lub leadership zapyta: „Kiedy to zdecydowaliśmy?”.
Role, uprawnienia i zatwierdzenia
Jasne role i lekkie zatwierdzenia zapobiegają dwóm typowym porażkom: „wszyscy mogą zmieniać wszystko” oraz „nic nie wychodzi, bo nikt nie wie, kto decyduje”. Zaprojektuj aplikację tak, by odpowiedzialność była oczywista, a każda widoczna na zewnątrz akcja miała właściciela.
Kluczowe role
- Admin: zarządza ustawieniami workspace, rolami, globalnymi szablonami i regułami compliance.
- Product Manager (PM): jest właścicielem planu wycofania, harmonogramów, docelowych odbiorców i intencji komunikatów.
- Inżynier: wdraża kroki techniczne, waliduje gotowość i aktualizuje status migracji.
- Support: monitoruje wpływ na klientów, przygotowuje FAQ/makra i eskaluje blokery.
- Tylko do odczytu: może przeglądać statusy, harmonogramy i raporty bez możliwości zmian.
Uprawnienia według akcji
Modeluj uprawnienia wokół kluczowych akcji, nie ekranów:
- Tworzenie/edycja wycofań (PM, Admin), z ograniczeniem pól możliwych do edycji po zatwierdzeniu.
- Zatwierdzanie planu, dat i zmian o dużym wpływie (Admin i wyznaczeni approverzy).
- Wysyłanie komunikatów (PM/Support po zatwierdzeniu) i edycja szablonów (Admin).
- Edycja terminów (PM) z wymogiem zatwierdzenia przy istotnych przesunięciach.
- Zamknięcie (PM + podpis inżyniera) gdy progi migracji zostaną osiągnięte.
Flowy zatwierdzeń dla zmian wysokiego ryzyka
Wymagaj zatwierdzeń, gdy zmiana dotyczy wielu użytkowników, klientów regulowanych lub krytycznych workflowów. Typowe punkty: zatwierdzenie początkowego planu, „gotowe do ogłoszenia” i końcowe potwierdzenie „sunset/wyłączenie”. Komunikacja zewnętrzna powinna być pod bramką zatwierdzeń.
Wymagania dotyczące dziennika audytu
Utrzymuj niezmienny ślad audytu: kto co zmienił, kiedy i dlaczego (w tym treść komunikatów, definicja audytorium i edycje harmonogramu). Dodaj linki do powiązanych ticketów i incydentów, aby postmortemy i przeglądy zgodności były szybkie i oparte na faktach.
Przejdź od prototypu do produkcji
Wdróż i hostuj aplikację bez sklejania dodatkowych usług.
Aplikacja odniesie sukces lub porażkę na jasności. Ludzie powinni szybko umieć odpowiedzieć na trzy pytania: Co się zmienia? Kto jest dotknięty? Co mamy zrobić dalej? Architektura informacji powinna odzwierciedlać ten przepływ, używając prostego języka i spójnych wzorców.
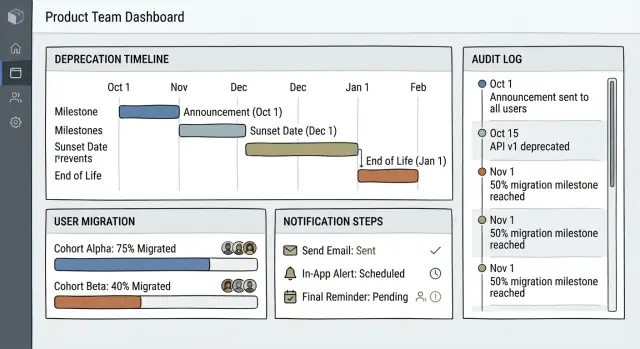
Dashboard: „centrum kontroli”
Dashboard powinien być przejrzysty w mniej niż minutę. Skup się na aktywnej pracy i ryzyku, nie na długim inwentarzu.
Pokaż:
- Aktywne wycofania z bieżącym etapem (Announced → Migration → Removal)
- Nadchodzące terminy (następne 7/14/30 dni) z etykietą „dni pozostało”
- Elementy wysokiego ryzyka: duże dotknięte audytorium, niski wskaźnik migracji lub brak zatwierdzeń
Utrzymaj proste filtry: Status, Właściciel, Obszar produktu, Okno terminów. Unikaj żargonu jak „sunset state”; używaj "Planowane usunięcie" lub „Usunięcie zaplanowane”.
Strona szczegółów wycofania: jedna źródło prawdy
Każde wycofanie potrzebuje jednej kanonicznej strony, do której zespoły się odwołują podczas wykonania.
Ustrukturyzuj ją jako oś czasu z najważniejszymi decyzjami i następnymi krokami na górze:
- Nagłówek podsumowujący: nazwa, właściciel, bieżący etap, data usunięcia, linki do zastępczego rozwiązania
- Oś czasu: data ogłoszenia, rozpoczęcie migracji, cutoff, usunięcie (z edytowalnymi kamieniami milowymi)
- Dotknięci użytkownicy: główne segmenty, liczby i sposób detekcji audytorium
- Komunikaty i dokumentacja: powiadomienia w aplikacji, szablony email, fragment release notes i linki do dokumentacji
Używaj krótkich, bezpośrednich etykiet: „Funkcja zastępcza”, „Kto jest dotknięty”, „Co użytkownicy muszą zrobić.”
Spójność przez szablony
Zmniejsz błędy, dostarczając szablony dla:
- Standardowych harmonogramów (np. plany 30/60/90 dni)
- Checklist (zatwierdzenia, wysłane komunikaty, przeszkolony support, zaktualizowana dokumentacja)
- Kroków migracji (co się zmienia dla użytkowników, FAQ)
Szablony powinny być wybieralne przy tworzeniu i widoczne jako checklisty na stronie szczegółów.
Dostępność i jasność domyślnie
Dąż do minimalnego obciążenia poznawczego:
- Pisz prostym językiem; unikaj wewnętrznych skrótów
- Używaj kolorowych pigułek statusu o wysokim kontraście i czytelnych formatów dat
- Zapewnij nawigację klawiszową i logiczne nagłówki dla czytników ekranu
Dobry UX sprawia, że workflow wydaje się nieuchronny: następne działanie jest zawsze jasne, a strona opowiada tę samą historię produktowi, inżynierii, supportowi i klientom.
Segmentacja audytorium i wykrywanie wpływu
Wycofania zawodzą, gdy informujesz wszystkich tak samo. Aplikacja powinna przede wszystkim odpowiedzieć na dwa pytania: kto jest dotknięty i jak duży jest wpływ. Segmentacja i wykrywanie wpływu umożliwiają precyzyjną komunikację, zmniejszają hałas w supportcie i pomagają priorytetyzować migracje.
Źródła segmentacji (skąd bierze się "audytorium")
Zacznij od segmentów, które odpowiadają temu, jak klienci kupują, używają i operują:
- Plan / poziom umowy (Free, Pro, Enterprise)
- Poziom użycia (power userzy vs okazjonalni użytkownicy)
- Typ integracji (tylko API, tylko UI, konkretny konektor)
- Region / rezydencja danych (istotne dla terminów i ograniczeń prawnych)
- Wiek konta (nowi klienci mogli nigdy nie używać starej funkcji)
Traktuj segmenty jak filtry, które możesz łączyć (np. „Enterprise + EU + używa API”). Przechowuj definicję segmentu, aby była audytowalna później.
Jak obliczać „dotknięte” (jakie dowody używasz)
Wpływ powinien być liczony na podstawie konkretnych sygnałów, zwykle:
- Logi użycia funkcji (feature toggles, odwiedziny stron, kliknięcia)
- Wywołania API (endpointy powiązane ze zdeprecjonowaną funkcją)
- Zdarzenia UI (konkretne workflowy sugerujące zależność)
Użyj okna czasowego („użyte w ostatnich 30/90 dni”) i progu („≥10 zdarzeń”), by oddzielić aktywne zależności od historycznego szumu.
Przypadki brzegowe do obsłużenia
Wspólne środowiska tworzą fałszywe pozytywy, jeśli ich nie zamodelujesz:
- Współdzielone konta / użytkownicy serwisowi: przypisuj użycie API do workspace lub klucza integracji, nie do osoby.
- Wiele workspace'ów: użytkownik może być dotknięty w jednym workspace, a nie w innym.
- Administratorzy vs użytkownicy końcowi: administratorzy potrzebują wcześniejszych, szczegółowych powiadomień; użytkownicy końcowi potrzebują instrukcji nakierowanych na zadania.
Podgląd przed wysyłką
Przed wysłaniem emaila lub powiadomienia w aplikacji zapewnij krok podglądu, który pokazuje przykładową listę dotkniętych kont/użytkowników, dlaczego zostali oznaczeni (główne sygnały) i przewidywany zasięg według segmentu. Ten „dry run” zapobiega kompromitującym wysyłkom i buduje zaufanie do workflowu.
Powiadomienia, komunikacja i szablony
Wycofania najczęściej zawodzą, gdy użytkownicy o nich nie słyszą (albo słyszą za późno). Traktuj komunikaty jako zasób workflowu: zaplanowane, audytowalne i dopasowane do dotkniętego segmentu.
Kanały, by trafić tam, gdzie użytkownicy zwracają uwagę
Obsługuj wiele dróg wyjścia, aby zespoły mogły dotrzeć do użytkowników tam, gdzie już zwracają uwagę:
- Banner w aplikacji dla aktywnych użytkowników w momencie potrzeby
- Email dla szerszego zasięgu i dłuższych instrukcji
- Webhooks do wysyłania zdarzeń do systemów wewnętrznych
- Slack (lub podobne) dla alertów do interesariuszy wewnętrznych
- Link do status page (opcjonalnie) gdy zmiana wpływa na dostępność lub niezawodność
Każde powiadomienie powinno odnosić się do konkretnego rekordu wycofania, by odbiorcy i zespoły mogli prześledzić „co wysłano, do kogo i dlaczego”.
Kadenсa: od zapowiedzi do terminu
Wbuduj domyślny harmonogram, który zespoły mogą dostosować dla każdego wycofania:
- Ogłoszenie: co się zmienia i dlaczego, plus ścieżka zastępcza
- Przypomnienia: na podstawie dni pozostałych i aktywności użytkownika (np. wciąż używa starej funkcji)
- Ostrzeżenie o terminie: dokładna data/godzina, wpływ i opcje wsparcia
- Ostateczne powiadomienie: potwierdzenie przełączenia i gdzie iść dalej
Szablony ze zmiennymi
Dostarcz szablony z wymaganymi polami i podglądem:
- Funkcja:
{{feature_name}}
- Termin:
{{deadline}}
- Zastępstwo:
{{replacement_link}} (np. /docs/migrate/new-api)
- CTA:
{{cta_text}} i {{cta_url}}
Zachowaj zmienne w backtickach i umożliw podgląd przed wysłaniem.
Kontrole bezpieczeństwa
Dodaj ograniczenia, by zapobiec przypadkowym masowym wysyłkom:
- Testowe wysyłki do wewnętrznych kont i zseedowanych segmentów
- Limity szybkości i limity na tenant
- Godziny ciszy według strefy czasowej
- Obsługa wypisów tam, gdzie to stosowne (i alternatywne kanały, gdy użytkownicy rezygnują)
Śledzenie migracji i pomoc użytkownikowi
Zmieniaj specyfikacje bez obaw
Eksperymentuj bez obaw dzięki migawkom i możliwości cofania zmian podczas dopracowywania workflow.
Plan migracji kończy się, gdy użytkownicy wiedzą dokładnie, co zrobić dalej — i gdy twój zespół może potwierdzić, kto faktycznie przeszedł. Traktuj migrację jako zestaw konkretnych, śledzonych kroków, nie ogólne „proszę zaktualizować”.
Kroki migracji w stylu checklisty
Modelewuj każdą migrację jako małą checklistę z jasnymi rezultatami (nie tylko instrukcjami). Na przykład: „Utwórz nowy klucz API”, „Zmień inicjalizację SDK”, „Usuń wywołania legacy endpoint”, „Zweryfikuj sygnaturę webhooka”. Każdy krok powinien zawierać:
- Krótkie opisanie i kryteria „done”
- Linki do właściwego miejsca do wykonania (strona ustawień, kreator lub docs)
- Opcjonalną walidację (np. wykrycie użycia nowego endpointu)
Utrzymuj checklistę widoczną na stronie wycofania i w bannerze w aplikacji, aby użytkownicy zawsze mogli wznowić pracę tam, gdzie przerwali.
Prowadzona migracja (pomoc, nie praca domowa)
Dodaj panel „guided migration”, który gromadzi wszystko, czego użytkownicy zwykle szukają:
- Odpowiednie strony dokumentacji (np.
/docs/migrations/legacy-to-v2)
- Wejścia do kreatora (np.
/settings/integrations/new-setup)
- Przykładowe konfiguracje i fragmenty do kopiowania
- Krótkie FAQ opisujące typowe błędy i jak bezpiecznie cofnąć zmiany
To nie tylko treść; to nawigacja. Najszybsze migracje mają miejsce, gdy aplikacja kieruje ludzi dokładnie tam, gdzie muszą być.
Śledzenie ukończenia na odpowiedniej granularności
Śledź ukończenie na poziomie konta, workspace i integracji (jeśli dotyczy). Wiele zespołów migracja najpierw jedno workspace, potem stopniowo wdraża kolejne.
Przechowuj postęp jako zdarzenia i stan: status kroku, znaczniki czasowe, aktor i wykryte sygnały (np. „endpoint v2 widziany w ciągu ostatnich 24h”). Daj szybki widok „% ukończenia” i możliwośc zagłębienia się, co jest blokowane.
Przekazanie do supportu z automatycznym kontekstem
Gdy użytkownicy ugrzęzną, ułatw eskalację: przycisk „Kontakt z supportem” powinien stworzyć ticket, przypisać CSM (lub kolejkę) i dołączyć kontekst automatycznie — identyfikatory konta, aktualny krok, komunikaty o błędach, typ integracji i ostatnia aktywność migracyjna. To skraca czas rozwiązywania i eliminuje niepotrzebne wymiany informacji.
Analityka i raportowanie adopcji
Projekty wycofań zawodzą cicho, gdy nie widzisz, kto jest dotknięty, kto się przenosi, a kto może odpłynąć. Analityka powinna odpowiadać na te pytania w mig i być na tyle wiarygodna, by dzielić ją z liderami, Supportem i Customer Success.
Podstawowe metryki adopcji
Zacznij od niewielkiego zestawu metryk, które trudno źle interpretować:
- Użytkownicy eksponowani: konta/użytkownicy wciąż używający zdeprecjonowanej funkcji (lub uderzający w stary endpoint) w definiowanym oknie czasowym.
- Rozpoczęli migrację: użytkownicy, którzy rozpoczęli flow aktualizacji (np. włączyli funkcję zastępczą, utworzyli wymagane ustawienia, zainstalowali integrację).
- Ukończyli migrację: użytkownicy spełniający kryteria "done" (użycie zamiennika powyżej progu, stare użycie = 0, ukończona checklist).
- Sygnały ryzyka churnu: rosnąca liczba ticketów dotyczących funkcji, powtarzające się błędy, gwałtowny spadek użycia, nieudane próby migracji lub negatywne tagi NPS związane ze zmianą.
Zdefiniuj każdą metrykę w UI z krótką podpowiedzią „Jak to liczymy”. Jeśli definicje zmieniają się w trakcie projektu, zapisz zmianę w śladzie audytu.
Harmonogramy dopasowane do cyklu życia
Dobry raport czyta się jak plan wycofania:
- Linie postępu w czasie dla eksponowanych/rozpoczętych/ukończonych
- Pionowe markery dla kluczowych dat: ogłoszenie, przypomnienie, ostateczne powiadomienie, sunset
- Wskaźnik „tempo do celu” (np. trend ukończeń vs wymagane tempo, by zdążyć przed sunset)
To pokazuje, czy potrzebne są dodatkowe przypomnienia, ulepszenia narzędzi lub korekta terminu.
Rozbicia, które napędzają działanie
Rollupy są przydatne, ale decyzje zapadają w segmentach. Udostępnij drill-downy według:
- Segmentu odbiorców (persona lub przypadek użycia)
- Poziomu planu (free vs płatne)
- Regionu (strefy czasowe i lokalne święta wpływają na reakcje)
- Typu integracji (klienci API, konektory partnerów, self-built vs marketplace)
Każe rozbicie powinno linkować bezpośrednio do listy dotkniętych kont, by zespoły mogły działać bez uprzedniego eksportu.
Eksporty i zaplanowane raporty
Wspieraj lekkie udostępnianie:
- Eksport CSV dla list kont i rollupów
- Zaplanowane podsumowania email/Slack do interesariuszy
- Cotygodniowy raport „ryzyko przed sunset”, który wyróżnia kluczowe segmenty i konta do kontaktu
Dla automatyzacji i głębszego BI udostępnij te same dane przez endpoint API (i trzymaj go stabilnym między projektami wycofań).
Integracje: feature flags, analityka, docs i narzędzia wsparcia
Wysyłaj narzędzie wewnętrzne szybciej
Wygeneruj aplikację React z backendem w Go i PostgreSQL na podstawie wymagań.
Aplikacja do wycofań jest najprzydatniejsza, gdy staje się "źródłem prawdy", któremu inne systemy mogą ufać. Integracje pozwalają przejść od ręcznych aktualizacji do automatycznego sterowania, pomiaru i workflowów wsparcia.
Feature flags: kontrola i weryfikacja zachowania
Połącz się z dostawcą feature flag, aby każde wycofanie mogło odnosić się do jednego lub więcej flag (stare doświadczenie, nowe doświadczenie, rollback). To umożliwia:
- Gating według środowiska (dev/stage/prod) i segmentu odbiorców
- Automatyczne sprawdzenia (np. „nowy flow włączony dla 90% kwalifikowanych kont”)
- Bezpieczniejsze rollbacki powiązane z rekordem wycofania, a nie osobnym arkuszem
Przechowuj klucze flag i „oczekiwany stan” dla każdego etapu oraz lekki job synchronizujący aktualny status.
Analityka + magazyn danych: mierz adopcję, nie opinie
Podłącz aplikację do analityki produktowej, aby każde wycofanie miało jasną metrykę sukcesu: zdarzenia „użyto starej funkcji”, „użyto nowej funkcji” i „ukończono migrację”. Pobieraj agregowane liczniki, by pokazać postęp według segmentu.
Opcjonalnie przesyłaj te metryki do hurtowni danych do bardziej zaawansowanego krojenia (plan, region, wiek konta). Trzymaj to opcjonalnym, by nie blokować mniejszych zespołów.
Dokumentacja i release notes: jedno kliknięcie z rekordu
Każde wycofanie powinno mieć link do kanonicznej treści pomocy i ogłoszeń, używając wewnętrznych ścieżek jak:
- /docs/migrations/new-checkout
- /release-notes/2026-01
To zmniejsza niespójności: support i PM zawsze odwołują się do tych samych stron.
Webhooki i API: automatyzuj pracę downstream
Udostępnij webhooks (i małe REST API) dla zdarzeń lifecycle takich jak „scheduled”, „email sent”, „flag flipped” i „sunset completed”. Typowi konsumenci to CRM, helpdeski i dostawcy wiadomości — dzięki temu klienci otrzymują spójne, terminowe informacje bez ręcznego przepisywania zmian między narzędziami.
Architektura i plan wdrożenia
Traktuj pierwszą wersję jako skupioną aplikację CRUD: twórz wycofania, definiuj daty, przypisuj właścicieli, listuj dotknięte audytoria i śledź status. Zacznij od tego, co zespół może szybko dostarczyć, potem dodaj automatyzację (ingest zdarzeń, messaging, integracje) gdy workflow zyska zaufanie.
Stack: wybierz to, co zespół już zna
Typowy, niskoryzykowny stack to aplikacja server-rendered lub proste SPA z API (Rails/Django/Laravel/Node). Klucz to niezawodność: solidne migracje, łatwe ekrany admina i dobre jobs w tle. Jeśli macie już SSO (Okta/Auth0), użyjcie go; w przeciwnym razie dodajcie passwordless magic links dla użytkowników wewnętrznych.
Jeśli chcecie przyspieszyć pierwszą działającą wersję (szczególnie dla narzędzi wewnętrznych), rozważ zbudowanie prototypu w Koder.ai. To platforma vibe-coding, gdzie można opisać workflow w czacie, iterować w „planning mode” i wygenerować aplikację React z backendem w Go i PostgreSQL — a następnie eksportować kod, jeśli zdecydujecie się przejąć projekt. Snapshots i rollback są szczególnie przydatne na etapie dopracowywania etapów, uprawnień i reguł powiadomień.
Główne elementy do zbudowania
Będziesz potrzebować:
- Auth + autoryzacja dla właścicieli, recenzentów i widzów
- Relacyjnej bazy danych (Postgres/MySQL) dla rekordów wycofań, zadań, zatwierdzeń i śladu audytu
- Zadań w tle dla zaplanowanych powiadomień, przypomnień i generowania raportów
- Nadawcy email + messaging webhook-based (np. Slack/Teams) za warstwą "message service"
- Endpointu ingestującego zdarzenia produktowe, które napędzają detekcję wpływu i dashboardy adopcji
Przechowywanie danych: workflow vs użycie
Trzymaj system-of-record workflowu w relacyjnej DB. Dla danych użycia zacznij od przechowywania dziennych agregatów w Postgres; jeśli wolumen urośnie, przenieś surowe zdarzenia do event store lub hurtowni i zapytuj zsumowane tabele dla aplikacji.
Niezbędne elementy operacyjne
Upewnij się, że zadania są idempotentne (bezpieczne do ponawiania), stosuj klucze deduplikujące przy wiadomościach wychodzących i polityki retry z backoffem. Loguj każdą próbę dostarczenia i alertuj o błędach. Podstawowy monitoring (głębokość kolejek jobów, wskaźnik błędów, awarie webhooków) zapobiega cichym przegapieniom komunikatów.
Testy, wdrożenie i codzienna operacja
Aplikacja dotyka komunikacji, uprawnień i doświadczenia klienta — więc testy powinny skupiać się na trybach awaryjnych tak samo jak na ścieżkach szczęśliwych.
Testuj workflowy, które mają znaczenie
Zacznij od scenariuszy end-to-end odzwierciedlających realne wycofania: draft, zatwierdzenia, edycje harmonogramu, wysyłanie wiadomości i rollbacki. Uwzględnij przypadki brzegowe jak „przesuń datę po tym, jak wysłano komunikaty” lub „zamień funkcję zastępczą w trakcie” i potwierdź, że UI jasno pokazuje zmiany.
Testuj też zatwierdzenia pod presją: równolegli recenzenci, odrzucone zatwierdzenia, ponowne zatwierdzenie po edycji i co się dzieje, gdy rola approvera ulega zmianie.
Waliduj segmentację i wykrywanie wpływu
Błędy segmentacji są kosztowne. Użyj zestawu przykładowych kont (i znanych „golden” użytkowników), aby zweryfikować, że trafne audytorium jest wybierane. Łącz automatyczne sprawdzenia z ręcznymi przeglądami: wybierz losowe konta i porównaj obliczony wpływ z rzeczywistością produktową.
Jeśli reguły zależą od analityki lub feature flags, testuj przy opóźnionych lub brakujących zdarzeniach, by wiedzieć, jak system zachowa się przy niekompletnych danych.
Kontrole bezpieczeństwa i gotowość audytu
Przeprowadź testy uprawnień dla każdej roli: kto może widzieć wrażliwe segmenty, kto może edytować harmonogramy i kto może wysyłać komunikaty. Potwierdź, że dzienniki audytu rejestrują „kto/co/kiedy” dla edycji i wysyłek, i minimalizuj przechowywane PII — preferuj stabilne ID zamiast adresów email, gdy to możliwe.
Plan rolloutu i operacje
Wdrażaj stopniowo: pilota wewnętrznego, mały zestaw niskoryzykownych wycofań, potem szersze użycie w całej organizacji. Podczas rolloutu wyznacz dyżur lub „właściciela tygodnia” dla pilnych edycji, odbić lub błędnej segmentacji.
Na koniec ustal lekką rytmikę operacyjną: comiesięczne przeglądy zakończonych wycofań, jakości szablonów i metryk adopcji. To utrzymuje zaufanie do aplikacji i zapobiega temu, by stała się narzędziem jednorazowym, którego ludzie unikają.