05 maj 2025·8 min
Zbuduj aplikację webową do zarządzania harmonogramami eskalacji klientów
Krok po kroku: jak zbudować aplikację webową śledzącą eskalacje klientów — terminy, SLA, właścicieli, powiadomienia, raporty i integracje.
Krok po kroku: jak zbudować aplikację webową śledzącą eskalacje klientów — terminy, SLA, właścicieli, powiadomienia, raporty i integracje.
Zanim zaprojektujesz ekrany lub wybierzesz stack technologiczny, ustal dokładnie, co w waszej organizacji oznacza „escalation”. Czy to zgłoszenie supportowe, które się przedłuża, incydent zagrażający dostępności, skarga kluczowego klienta, czy każde żądanie przekraczające próg ważności? Jeśli różne zespoły inaczej rozumieją to pojęcie, aplikacja utrwali niejasności.
Napisz jednozdaniową definicję, z którą zgodzi się cały zespół, i dodaj kilka przykładów. Na przykład: „Eskalacją jest każde zgłoszenie klienta wymagające wyższego poziomu wsparcia lub zaangażowania kierownictwa i objęte zobowiązaniem czasowym.”
Zdefiniuj też, co nie jest eskalacją (np. rutynowe bilety, zadania wewnętrzne), żeby v1 nie rozrósł się niepotrzebnie.
Kryteria sukcesu powinny odzwierciedlać to, co chcesz poprawić — nie tylko to, co chcesz zbudować. Typowe cele to:
Wybierz 2–4 metryki, które możesz śledzić od pierwszego dnia (np. wskaźnik naruszeń, czas w każdej fazie eskalacji, liczba reasignacji).
Wypisz głównych użytkowników (agenci, liderzy, menedżerowie) oraz udziałowców (opiekunowie kont, on-call inżynierowie). Dla każdego zapisz, co musi zrobić szybko: przejąć własność, przedłużyć termin z uzasadnieniem, sprawdzić co dalej lub podsumować status dla klienta.
Zbieraj aktualne przypadki awarii w formie konkretnych historii: przegapione przekazania między poziomami, niejasne czasy po reasignacji, spory „kto zatwierdził przedłużenie?”.
Użyj tych historii, aby oddzielić must-have (oś czasu + własność + audytowalność) od późniejszego rozszerzenia (zaawansowane pulpity, złożona automatyzacja).
Gdy cele są jasne, zapisz jak eskalacja przechodzi przez zespół. Wspólny workflow zapobiega traktowaniu „specjalnych przypadków” w sposób niespójny i przegapieniom SLA.
Zacznij od prostego zestawu etapów i dozwolonych przejść:
Udokumentuj, co każdy etap znaczy (kryteria wejścia) i co musi być prawdą, żeby z niego wyjść (kryteria wyjścia). To zapobiega niejasnościom typu „Rozwiązane, ale wciąż czekamy na klienta”.
Eskalacje powinny być tworzone przez reguły, które da się wytłumaczyć w jednym zdaniu. Typowe wyzwalacze:
Zdecyduj, czy wyzwalacze tworzą eskalację automatycznie, sugerują ją agentowi, czy wymagają zatwierdzenia.
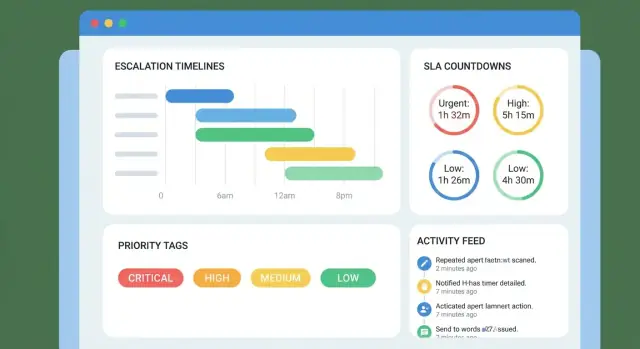
Oś czasu jest tylko tak dobra, jak jej zdarzenia. Minimum to:
Zapisz reguły zmiany własności: kto może przekazać, kiedy potrzebne jest zatwierdzenie (np. przekaz między zespołami lub zewnętrznym dostawcą) i co się dzieje, gdy właściciel kończy zmianę zmiany.
Na koniec zaplanuj zależności wpływające na terminy: grafiki on-call, poziomy (T1/T2/T3) i zewnętrzni dostawcy (wraz z oknami odpowiedzi). To będzie napędzać obliczenia terminów i macierz eskalacji później.
Niezawodna aplikacja eskalacyjna to w dużej mierze problem danych. Jeśli modele dla osi czasu, SLA i historii nie będą jasne, UI i powiadomienia zawsze będą wyglądać „nie tak”. Zacznij od nazw rdzeniowych encji i ich relacji.
Minimum planu to:
Traktuj każdy kamień milowy jako timer z polami:
start_at (kiedy zegar się zaczyna)due_at (obliczony termin)paused_at / pause_reason (opcjonalne)completed_at (kiedy dotrzymano)Przechowuj dlaczego istnieje termin (reguła), nie tylko obliczoną wartość. To ułatwi późniejsze spory.
SLA rzadko oznacza „zawsze”. Zmodeluj kalendarz dla każdej polityki SLA: godziny pracy vs 24/7, święta i harmonogramy specyficzne dla regionu.
Obliczaj terminy w spójnym czasie serwera (UTC), ale zawsze przechowuj strefę czasową sprawy/klienta, żeby UI mogło wyświetlać terminy poprawnie i użytkownicy mogli je sensownie interpretować.
Zdecyduj wczesnie między:
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED), lubDla zgodności i odpowiedzialności preferuj log zdarzeń (nawet jeśli trzymasz też kolumny aktualnego stanu dla wydajności). Każda zmiana powinna zapisać kto, co się zmieniło, kiedy i źródło (UI, API, automatyzacja), plus ID korelacji do śledzenia powiązanych działań.
Uprawnienia to miejsce, gdzie narzędzia eskalacyjne albo zyskują zaufanie, albo są omijane arkuszami. Określ, kto może co robić wcześnie, a potem egzekwuj to spójnie w UI, API i eksportach.
Utrzymaj v1 prosty, z rolami odzwierciedlającymi pracę zespołów wsparcia:
Wprowadzaj wyraźne blokady w produkcie: wyłączaj kontrolki zamiast pozwalać użytkownikom na kliknięcie i otrzymanie błędu.
Eskalacje często obejmują wiele grup (Tier 1, Tier 2, CSM, incident response). Zaplanuj widoczność wielozakresową używając jednego lub więcej wymiarów:
Dobry domyślny model: użytkownicy mają dostęp do spraw, w których są przypisani, obserwatorami lub należą do zespołu właściciela — plus do kont jawnie udostępnionych ich roli.
Nie wszystkie dane powinny być widoczne dla wszystkich. Typowe pola wrażliwe to PII klienta, szczegóły umowy i notatki wewnętrzne. Wprowadź reguły poziomu pól, np.:
Dla v1 email/hasło z obsługą MFA zwykle wystarcza. Zaprojektuj model użytkownika tak, by można było dodać SSO później (SAML/OIDC) bez przepisywania uprawnień (np. przechowuj role/zespoły lokalnie i mapuj grupy SSO przy logowaniu).
Traktuj zmiany uprawnień jako działania audytowalne. Zapisuj zdarzenia takie jak aktualizacje ról, reasignacje zespołów, pobrania eksportów i edycje konfiguracji — kto, kiedy i co zmienił. To chroni w incydentach i ułatwia przeglądy dostępu.
Aplikacja eskalacyjna odniesie sukces lub porażkę na codziennych ekranach: co widzi lider wsparcia jako pierwsze, jak szybko rozumie sprawę i czy następny termin jest niemożliwy do przeoczenia.
Zacznij od niewielkiego zestawu stron, które pokrywają ~90% pracy:
Utrzymaj przewidywalną nawigację: lewy pasek lub górne zakładki z „Kolejka”, „Moje sprawy”, „Raporty”. Uczyń kolejkę domyślną stroną startową.
W liście spraw pokaż tylko pola, które pomagają zdecydować, co dalej. Dobry wiersz zawiera: klient, priorytet, aktualny właściciel, status, następny termin i wskaźnik ostrzegawczy (np. „Termin za 2h” lub „Zaległe o 1d”).
Dodaj szybkie, praktyczne filtry i wyszukiwanie:
Projektuj pod kątem szybkiego skanowania: spójne szerokości kolumn, czytelne chipy statusu i jeden kolor wyróżnienia używany tylko dla pilności.
Widok sprawy powinien odpowiedzieć od razu:
Umieść szybkie akcje blisko góry (nie ukryte w menu): Przypisz ponownie, Eskaluje, Dodaj kamień milowy, Dodaj notatkę, Ustaw następny termin. Każda akcja powinna potwierdzić zmianę i odświeżyć oś czasu natychmiast.
Oś czasu powinna czytać się jak sekwencja zobowiązań. Zawierać powinna:
Używaj stopniowego ujawniania: pokaż najnowsze zdarzenia na górze z opcją rozwinięcia starszej historii. Jeśli masz ślad audytu, podlinkuj go z osi czasu (np. „Pokaż log zmian”).
Używaj czytelnego kontrastu kolorów, łącz kolor z tekstem („Zaległe”), zapewnij dostępność klawiaturą dla wszystkich akcji i pisz etykiety w języku użytkownika („Ustaw następny termin aktualizacji dla klienta”, zamiast „Update SLA”). To zmniejsza błędy przy presji.
Alerty to „serce” osi czasu eskalacji: poruszają sprawy bez potrzeby ciągłego pilnowania dashboardu. Cel jest prosty — powiadomić właściwą osobę we właściwym momencie przy minimalnym hałasie.
Zacznij od kilku zdarzeń mapowanych bezpośrednio na akcję:
Dla v1 wybierz kanały, które możesz dostarczyć niezawodnie i zmierzyć:
SMS lub narzędzia chatowe mogą pojawić się później, gdy reguły i wolumen będą stabilne.
Reprezentuj eskalację jako progi czasowe powiązane z osią czasu sprawy:
Uczyń macierz konfigurowalną per priorytet/kolejkę, by P1 nie podążą tymi samymi regułami co pytania billingowe.
Wprowadź deduplikację (nie wysyłaj tego samego alertu dwa razy), batche (podsumowanie podobnych alertów) i godziny ciszy, które opóźniają niekrytyczne przypomnienia, ale dalej je logują.
Każdy alert powinien obsługiwać:
Przechowuj te akcje w śladzie audytu, by raporty mogły rozróżnić „nikt tego nie widział” od „ktoś to zobaczył i odroczył”.
Większość aplikacji eskalacyjnych zawodzą, gdy zmuszają ludzi do przepisywania danych, które już gdzieś istnieją. Dla v1 integruj tylko to, co potrzebne do utrzymania poprawnych osi czasu i terminów.
Zdecyduj, które kanały mogą tworzyć/aktualizować sprawę:
Trzymaj payloady przychodzące małe: ID sprawy, ID klienta, status, priorytet, znaczniki czasu i krótkie streszczenie.
Aplikacja powinna powiadamiać inne systemy, gdy coś ważnego się dzieje:
Używaj webhooków z podpisanymi żądaniami i ID zdarzenia do deduplikacji.
Jeśli synchronizujesz obie strony, zadeklaruj źródło prawdy per pola (np. narzędzie ticketowe rządzi statusem; twoja aplikacja rządzi timerami SLA). Zdefiniuj reguły konfliktów („last write wins” rzadko jest poprawne) i dodaj logikę retry z backoffem oraz dead-letter queue dla błędów.
Dla v1 importuj klientów i kontakty używając stabilnych zewnętrznych ID i minimalnego schematu: nazwa konta, tier, kluczowe kontakty i preferencje eskalacyjne. Unikaj głębokiego mirrorowania CRM.
Udokumentuj krótką checklistę (metoda autoryzacji, wymagane pola, limity, retry, środowisko testowe). Opublikuj minimalny kontrakt API (nawet strona A4) i wersjonuj go, aby integracje nie psuły się niespodziewanie.
Backend musi robić dwie rzeczy dobrze: utrzymywać poprawność czasową eskalacji i być szybki wraz ze wzrostem wolumenu spraw.
Wybierz najprostszy możliwy architektury, którą zespół może utrzymać. Klasyczna aplikacja MVC z REST API często wystarcza dla v1. Jeśli już używasz GraphQL z powodzeniem, też może działać — ale unikaj dodawania go „bo modne”. Paruj z zarządzaną bazą (np. Postgres), żeby poświęcić czas na logikę eskalacji zamiast operacji bazodanowych.
Jeśli chcesz szybko zweryfikować przepływ przed tygodniami pracy inżynierskiej, platforma typu vibe-coding jak Koder.ai może pomóc w prototypowaniu podstawowego loopa (kolejka → szczegóły sprawy → oś czasu → powiadomienia) z interfejsem czatowym, iterować w trybie planowania i eksportować kod, gdy będziesz gotów. Jej domyślny stack (React na froncie, Go + PostgreSQL na backendzie) dobrze pasuje do aplikacji o wysokich wymaganiach audytowych.
Eskalacje opierają się na zaplanowanej pracy, więc potrzebujesz background processing dla:
Implementuj zadania idempotentne (bezpieczne przy wielokrotnym uruchomieniu) i retryowalne. Przechowuj last evaluated at per sprawa/os czasu, by zapobiec duplikacji działań.
Przechowuj wszystkie znaczniki czasu w UTC. Konwertuj do strefy użytkownika tylko na granicy UI/API. Dodaj testy na przypadki brzegowe: zmiana czasu letniego, dni przestępne i „pauzy” zegara (np. SLA zatrzymane, gdy czekamy na klienta).
Używaj paginacji w kolejkach i widokach historii. Dodaj indeksy dopasowane do filtrów i sortowań — typowe: (due_at), (status), (owner_id) oraz kompozyty jak (status, due_at).
Planuj przechowywanie plików oddzielnie od bazy: narzucaj limity rozmiaru/typów, skanuj uploady (lub używaj integracji), i ustal zasady retencji (np. usuwaj po 12 miesiącach chyba że jest legal hold). Przechowuj metadane w tabelach sprawy; plik w object storage.
Raportowanie to moment, gdy aplikacja eskalacyjna przestaje być skrzynką wspólną, a staje się narzędziem zarządczym. Dla v1 celuj w jedną stronę raportową odpowiadającą na dwa pytania: „Czy spełniamy SLA?” i „Gdzie eskalacje stoją w miejscu?”. Utrzymuj to proste, szybkie i oparte na wspólnych definicjach.
Raport jest tylko tak wiarygodny jak definicje pod spodem. Zapisz je prostym językiem i odwzoruj w modelu danych:
Zdecyduj też, które zegary SLA raportujesz: pierwsza odpowiedź, następna aktualizacja czy rozwiązanie (lub wszystkie trzy).
Pulpit może być lekki, ale użyteczny:
Dodaj widoki operacyjne do codziennego balansowania pracy:
CSV wystarcza zwykle dla v1. Powiąż eksporty z uprawnieniami (dostęp zespołowy, sprawdzenie roli) i zapisuj w audycie każdy eksport (kto, kiedy, użyte filtry, liczba wierszy). To zapobiega „tajnym arkuszom” i wspiera zgodność.
Szybko wypuść pierwszą stronę raportową, a potem przeglądaj ją z liderami wsparcia cotygodniowo przez miesiąc. Zbieraj uwagi o brakujących filtrach, mylących definicjach i momentach „nie mogę odpowiedzieć na X” — to najlepsze wejścia do v2.
Testowanie aplikacji osi czasu eskalacji to nie tylko „czy działa?”. To „czy zachowuje się tak, jak zespoły wsparcia oczekują pod presją?”. Skup się na realistycznych scenariuszach obciążających reguły, powiadomienia i przekazania spraw.
Większość wysiłku testowego poświęć na obliczenia osi czasu — małe błędy tu powodują duże spory SLA.
Pokryj przypadki: liczenie godzin pracy, święta, strefy czasowe. Testuj pauzy (oczekiwanie na klienta, zależności inżynieryjne), zmiany priorytetu w trakcie sprawy i eskalacje, które przesuwają docelowe czasy. Testuj też przypadki brzegowe: sprawa utworzona minutę przed zamknięciem biura lub pauza zaczynająca się dokładnie na granicy SLA.
Powiadomienia często zawodzą w lukach między systemami. Napisz testy integracyjne, które weryfikują:
Jeśli używasz e-maili, chatu lub webhooków, asercje powinny sprawdzać payloady i timing — nie tylko że „coś wysłano”.
Stwórz realistyczne sample data ujawniające problemy UX: klienci VIP, długotrwałe sprawy, częste reasignacje, ponownie otwarte incydenty i okresy „gorące” z nagłymi skokami kolejki. To pomaga zweryfikować, czy kolejki, widok sprawy i oś czasu są czytelne bez wyjaśnień.
Przeprowadź pilotaż z jednym zespołem przez 1–2 tygodnie. Zbieraj problemy codziennie: brakujące pola, mylące etykiety, hałas powiadomień i wyjątki od reguł osi czasu.
Śledź też, co użytkownicy robią poza aplikacją (arkusze, kanały boczne), aby wyłapać luki.
Spisz, co oznacza „gotowe” przed szerokim wdrożeniem: kluczowe metryki SLA zgadzają się z oczekiwaniami, krytyczne powiadomienia są niezawodne, ślady audytu kompletne, a zespół pilotażowy potrafi przeprowadzić eskalacje end-to-end bez obejść.
Wypuszczenie pierwszej wersji to nie koniec. Aplikacja osi czasu eskalacji staje się „prawdziwa” dopiero, gdy przetrwa codzienne awarie: przegapione zadania, wolne zapytania, źle skonfigurowane powiadomienia i zmiany reguł SLA. Traktuj wdrożenia i operacje jako część produktu.
Utrzymuj proces wydawania nudny i powtarzalny. Minimum do udokumentowania i zautomatyzowania:
Jeśli masz środowisko staging, zseeduj je realistycznymi danymi (sanitized), by zweryfikować zachowanie osi czasu i powiadomień przed produkcją.
Tradycyjne checks uptime nie złapią najgorszych problemów. Dodaj monitoring tam, gdzie eskalacje mogą się cicho psuć:
Stwórz małą procedurę on-call: „Jeśli przypomnienia SLA nie wysyłają się, sprawdź A → B → C.” To skraca czas przywrócenia działania podczas incydentów.
Dane eskalacyjne często zawierają imiona, e-maile i wrażliwe notatki. Określ polityki wcześnie:
Uczyń retencję konfigurowalną, żeby nie wprowadzać zmian kodu przy zmianie polityk.
Nawet w v1 admini potrzebują sposobów utrzymania systemu:
Napisz krótkie, zadaniowe instrukcje: „Utwórz eskalację”, „Zawieś oś czasu”, „Nadpisz SLA”, „Sprawdź kto co zmienił”.
Dodaj lekki onboarding w aplikacji wskazujący kolejki, widok sprawy i akcje osi czasu oraz link do strony /help jako odniesienie.
Wersja 1 powinna udowodnić podstawowy loop: sprawa ma jasną oś czasu, zegar SLA zachowuje się przewidywalnie, a właściwe osoby otrzymują powiadomienia. Wersja 2 może dodać możliwości bez zamieniania v1 w skomplikowany „system wszystkiego”. Kluczem jest krótka, explicite lista usprawnień, które wprowadzasz dopiero po zobaczeniu rzeczywistego użytkowania.
Dobry element v2 to taki, który (a) redukuje ręczną pracę w skali lub (b) zapobiega kosztownym błędom. Jeśli głównie dodaje opcje konfiguracyjne, odłóż go, aż będzie dowód, że wiele zespołów tego potrzebuje.
Kalendarze SLA per klient to często pierwsze znaczące rozszerzenie: różne godziny pracy, święta lub kontraktowe czasy reakcji.
Dalej: playbooki i szablony — predefiniowane kroki eskalacji, rekomendowani interesariusze i szkice wiadomości, które ułatwiają spójne reakcje.
Gdy przypisywanie staje się wąskim gardłem, rozważ routing oparty na umiejętnościach i harmonogramach on-call. Zachowaj pierwszą iterację prostą: mały zestaw umiejętności, domyślny właściciel zapasowy i jasne kontrole nadpisania.
Auto-escalation można uruchamiać przy wykryciu określonych sygnałów (zmiana ważności, słowa-klucze, sentyment, powtarzające się kontakty). Zacznij od „sugerowanej eskalacji” (podpowiedź) zanim wprowadzisz „automatyczną eskalację”, i loguj powód każdego triggera dla zaufania i audytowalności.
Wymagaj pól przed eskalacją (wpływ, ważność, tier klienta) i wprowadź kroki zatwierdzające przy wysokiej ważności. To redukuje hałas i pomaga utrzymać poprawność raportowania.
Jeśli chcesz przetestować wzorce automatyzacji przed wdrożeniem, zobacz /blog/workflow-automation-basics. Jeśli dopasowujesz zakres do ofert, sprawdź jak funkcje mapują się do planów na /pricing.
Zacznij od jednego zdania, które wszyscy zaakceptują (i kilku przykładów). Dodaj wyraźne przykłady, które nie są eskalacją (np. rutynowe zgłoszenia, zadania wewnętrzne), by v1 nie stał się ogólnym systemem zgłoszeń.
Następnie zapisz 2–4 metryki, które można mierzyć od razu, np. wskaźnik naruszeń SLA, czas w każdej fazie czy liczba przekazań sprawy.
Wybierz wyniki, które odzwierciedlają poprawę operacyjną, nie tylko ukończenie funkcji. Praktyczne metryki v1 to:
Wybierz niewielki zestaw, który można obliczyć z dostępnych od początku znaczników czasu.
Użyj małego, wspólnego zestawu etapów z jasnymi kryteriami wejścia/wyjścia, na przykład:
Zapisz, co musi być prawdą, żeby wejść i wyjść z każdego etapu. To zapobiega niejasnościom typu „Rozwiązane, ale wciąż czekamy na klienta”.
Zarejestruj minimalne zdarzenia potrzebne do odtworzenia historii i obrony decyzji SLA:
Jeśli nie potrafisz wyjaśnić, do czego używasz znacznika czasu, nie zbieraj go w v1.
Modeluj każdy kamień milowy jako timer z polami:
start_atdue_at (obliczany)paused_at i pause_reason (opcjonalne)completed_atPrzechowuj też regułę, która wygenerowała (polityka + kalendarz + powód). To ułatwia audyty i rozstrzyganie sporów bardziej niż trzymanie tylko ostatecznego terminu.
Przechowuj wszystkie znaczniki czasu w UTC, ale zapamiętuj strefę czasową sprawy/klienta do wyświetlania i rozumienia terminów. Modeluj kalendarze SLA jawnie (24/7 vs godziny pracy, święta, harmonogramy regionalne).
Testuj przypadki brzegowe: zmiany czasu letniego, dni przestępne i pauzy SLA (np. oczekiwanie na klienta).
Uprość role v1 i dopasuj je do rzeczywistej pracy zespołów:
Dodaj reguły zakresu (zespół/region/kontrakt) i kontrolę pól dla danych wrażliwych jak notatki wewnętrzne czy PII.
Zaprojektuj najważniejsze ekrany, które obsługują większość pracy:
Optymalizuj pod szybkie skanowanie i ogranicz przełączanie kontekstu — szybkie akcje nie powinny być ukryte w menu.
Zacznij od niewielkiego zestawu sygnałów wysokiej wartości:
Wybierz 1–2 kanały dla v1 (zwykle powiadomienia w aplikacji + e-mail). Stwórz macierz eskalacji z jasnymi progami (T–2h, T–0h, T+1h). Zapobiegaj zmęczeniu alertami przez deduplikację, batchowanie i godziny ciszy; dodaj potwierdzanie (acknowledge) i drzemkę (snooze) z zapisem w audycie.
Integruj tylko to, co utrzymuje harmonogramy aktualne:
Jeśli synchronizujesz dwukierunkowo, zdefiniuj źródło prawdy dla każdego pola i reguły konfliktu (unikaj prostego „last write wins”). Opublikuj minimalną, wersjonowaną specyfikację API.
Dodatkowo: zobacz /blog/workflow-automation-basics oraz /pricing.
due_at