Dlaczego zarządzanie pamięcią wpływa na wydajność i bezpieczeństwo
Zarządzanie pamięcią to zbiór reguł i mechanizmów, których program używa, aby przydzielać pamięć, korzystać z niej i zwalniać. Każdy działający program potrzebuje pamięci na zmienne, dane użytkownika, bufory sieciowe, obrazy i wyniki pośrednie. Ponieważ pamięć jest ograniczona i współdzielona z systemem operacyjnym oraz innymi aplikacjami, języki muszą zdecydować kto odpowiada za jej zwalnianie i kiedy to się dzieje.
Te decyzje kształtują dwa wyniki, na których zwykle zależy: jak szybko program działa i jak niezawodnie zachowuje się pod obciążeniem.
Co tu oznacza „wydajność”
Wydajność to nie jedna liczba. Zarządzanie pamięcią może wpływać na:
- Przepustowość: ile pracy wykonasz na sekundę (żądań obsłużonych, klatek wyrenderowanych, plików przetworzonych).
- Opóźnienie: ile trwa pojedyncza operacja, zwłaszcza skoki w najgorszych przypadkach spowodowane pauzami lub wolnymi alokacjami.
- Zajętość pamięci: ile RAM program zajmuje w czasie działania, co wpływa na koszty, żywotność baterii i częstotliwość wymiany przez system operacyjny.
Język, który alokuje szybko, ale czasem zatrzymuje się na sprzątanie, może świetnie wypadać w benchmarkach, ale działać niestabilnie w aplikacjach interaktywnych. Inny model, unikający pauz, może wymagać staranniejszego projektowania, by zapobiec wyciekom i błędom lifetimów.
Co tu oznacza „bezpieczeństwo”
Bezpieczeństwo dotyczy zapobiegania błędom związanym z pamięcią, takim jak:
- Awarie (dostęp do nieprawidłowej pamięci)
- Uszkodzenie danych (zapis w nieodpowiednie miejsce)
- Podatności bezpieczeństwa (błędy, które atakujący mogą wykorzystać)
Wiele głośnych problemów bezpieczeństwa wynika z błędów pamięci, jak use-after-free czy przepełnienia bufora.
Ten przewodnik to nietechniczna wycieczka po głównych modelach pamięci używanych w popularnych językach, czego one faworyzują i jakie kompromisy przyjmujesz wybierając któryś z nich.
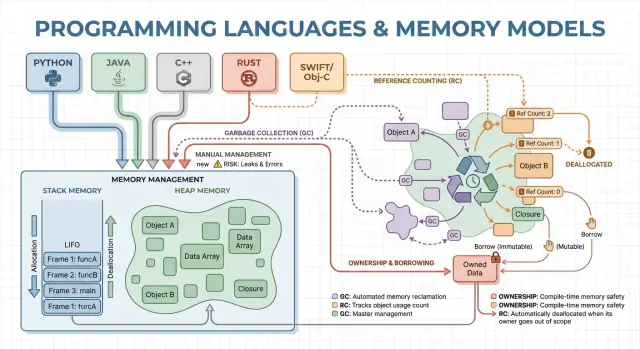
Podstawowe pojęcia: stos, sterta i czasy życia obiektów
Pamięć to miejsce, gdzie program przechowuje dane podczas działania. Większość języków organizuje to wokół dwóch obszarów: stosu i ster ty.
Stos: szybkie, tymczasowe miejsce
Pomyśl o stosie jak o schludnym stosie karteczek używanych do bieżącego zadania. Gdy funkcja się uruchamia, dostaje małą „ramkę” na stosie na zmienne lokalne. Gdy funkcja kończy, cała ramka jest usuwana naraz.
To jest szybkie i przewidywalne — ale działa tylko dla wartości, których rozmiar jest znany i których czas życia kończy się razem z wywołaniem funkcji.
Sterta: elastyczne, dłużej żyjące miejsce
Sterta to bardziej jak magazyn, w którym możesz przechowywać obiekty tak długo, jak potrzebujesz. Jest idealna dla dynamicznie zmieniających się list, łańcuchów czy obiektów współdzielonych między częściami programu.
Ponieważ obiekty na stercie mogą żyć dłużej niż pojedyncza funkcja, kluczowe pytanie brzmi: kto odpowiada za ich zwolnienie i kiedy? To właśnie określa model zarządzania pamięcią języka.
Czasy życia i dlaczego wskaźniki/referencje mają znaczenie
Pointer lub referencja to sposób na dostęp do obiektu pośrednio — jak numer półki z pudełkiem w magazynie. Jeśli pudełko zostanie wyrzucone, a Ty nadal masz numer półki, możesz odczytać śmieciowe dane lub spowodować awarię (klasyczny błąd use-after-free).
Prosty scenariusz
Wyobraź sobie pętlę, która tworzy rekord klienta, formatuje wiadomość i go odrzuca:
- Na stosie: małe zmienne tymczasowe używane podczas formatowania.
- Na stercie: rekord klienta i tekst wiadomości (zróżnicowane rozmiary).
Niektóre języki ukrywają te szczegóły (automatyczne sprzątanie), inne je eksponują (jawne zwalnianie pamięci lub reguły własności). Poniżej omawiamy, jak te wybory wpływają na szybkość, pauzy i bezpieczeństwo.
Ręczne zarządzanie pamięcią: kontrola z większym ryzykiem
Ręczne zarządzanie pamięcią oznacza, że programista jawnie rezerwuje pamięć i potem ją zwalnia. W praktyce to malloc/free w C czy new/delete w C++. Wciąż jest powszechne w programowaniu systemowym, gdzie potrzebna jest precyzja co do momentu przydziału i zwolnienia pamięci.
Do czego używa się jawnej alokacji/zwalniania
Zazwyczaj alokujesz pamięć, gdy obiekt ma żyć dłużej niż bieżące wywołanie funkcji, dynamicznie rośnie (np. bufor) lub potrzebny jest specyficzny układ do współpracy ze sprzętem, systemem operacyjnym czy protokołami sieciowymi.
Zysk wydajności: przewidywalne koszty (jeśli wykonane dobrze)
Bez garbage collectora w tle jest mniej niespodziewanych pauz. Alokacja i dealokacja mogą być bardzo przewidywalne, szczególnie w połączeniu z własnymi alokatorami, pulami czy buforami o stałym rozmiarze.
Ręczna kontrola może też zmniejszyć narzut: brak fazy śledzenia, brak barier zapisu, często mniej metadanych na obiekt. Przy starannym zaprojektowaniu kodu można osiągnąć bardzo niskie opóźnienia i trzymać użycie pamięci w ścisłych granicach.
Ryzyka bezpieczeństwa: klasyczne tryby awarii
Cena za kontrolę to możliwość popełnienia błędów, których środowisko uruchomieniowe nie zatrzyma:
- wycieki pamięci (zapomnienie o zwolnieniu)
- double-free (zwolnienie dwa razy)
- use-after-free (dostęp po zwolnieniu)
Te błędy mogą powodować awarie, uszkodzenia danych i luki bezpieczeństwa.
Typowe środki zaradcze
Zespoły ograniczają ryzyko przez zawężenie miejsc, gdzie dozwolone są surowe alokacje, oraz używają wzorców takich jak:
- RAII w C++ (zasoby zwalniane automatycznie razem z zakresem)
- Smart pointers (np.
std::unique_ptr) do kodowania własności
- standardy kodowania, przeglądy, sanitizery i analiza statyczna
Gdzie to pasuje
Ręczne zarządzanie pamięcią to dobry wybór dla oprogramowania wbudowanego, systemów czasu rzeczywistego, komponentów OS i bibliotek krytycznych wydajnościowo — miejsc, gdzie kontrola i przewidywalna latencja są ważniejsze niż wygoda dewelopera.
Garbage collection: produktywność i przewidywalne bezpieczeństwo
Garbage collection (GC) to automatyczne sprzątanie pamięci: zamiast wymagać od Ciebie free, środowisko śledzi obiekty i odzyskuje te, do których program nie ma już odniesień. Dzięki temu możesz skupić się na zachowaniu i przepływie danych, a system zajmuje się większością decyzji dotyczących alokacji i deallokacji.
Jak GC znajduje nieużywane obiekty
Większość kolektorów najpierw identyfikuje żywe obiekty, a potem odzyskuje pozostałe.
Tracing GC zaczyna od „korzeni” (zmienne na stosie, referencje globalne, rejestry), podąża referencjami, aby oznaczyć wszystko osiągalne, a potem zamiata stertę, by zwolnić nieoznaczone obiekty. Jeśli nic nie wskazuje na obiekt, staje się on kandydatem do zbierania.
Typowe style GC (ogólnie)
Generational GC opiera się na obserwacji, że wiele obiektów umiera wcześnie. Dzieli stertę na generacje i często zbiera obszar młodych obiektów, co zwykle jest tańsze i poprawia efektywność.
Concurrent GC wykonuje części kolekcji równolegle z wątkami aplikacji, aby zredukować długie pauzy. Wymaga dodatkowej księgowości, by zachować spójny widok pamięci przy działającym programie.
Kompromisy wydajnościowe
GC zwykle wymienia ręczną kontrolę na pracę w runtime. Niektóre systemy priorytetyzują wysoką przepustowość (dużo pracy na sekundę), ale mogą wprowadzać pauzy stop-the-world. Inne minimalizują pauzy dla aplikacji wrażliwych na opóźnienia, lecz dodają narzut w normalnym działaniu.
Dlaczego deweloperzy to lubią
GC usuwa całą klasę błędów związanych z czasem życia obiektów (zwłaszcza use-after-free), ponieważ obiekty nie są odzyskiwane, dopóki są osiągalne. Redukuje też wycieki spowodowane zapomnianymi deallokacjami (choć nadal możesz „zatuszować” pamięć przez trzymanie odniesień dłużej niż potrzeba). W dużych bazach kodu, gdzie własność jest trudna do śledzenia ręcznie, często przyspiesza iteracje.
Gdzie go spotkasz
Środowiska z GC są powszechne w JVM (Java, Kotlin), .NET (C#, F#), Go oraz silnikach JavaScript w przeglądarkach i Node.js.
Zliczanie referencji: natychmiastowe zwalnianie z kompromisami
Zliczanie referencji to strategia, w której każdy obiekt śledzi liczbę „właścicieli” (referencji) do niego. Gdy licznik spada do zera, obiekt jest zwalniany natychmiast. Ta natychmiastowość jest intuicyjna: gdy nic nie może już dojść do obiektu, pamięć jest odzyskiwana od razu.
Jak to działa (i dlaczego to atrakcyjne)
Za każdym razem, gdy kopiujesz lub przechowujesz referencję, runtime inkrementuje licznik; gdy referencja znika, dekrementuje. Osiągnięcie zera wywołuje sprzątanie od razu.
To sprawia, że zarządzanie zasobami bywa prostsze: obiekty często zwalniają pamięć blisko momentu, w którym przestajesz ich używać, co może zmniejszać maksymalne użycie pamięci i uniknąć opóźnionych operacji zwalniania.
Charakterystyka wydajności
Zliczanie referencji zwykle generuje stały, rozproszony narzut: operacje inkrementacji/dekrementacji występują przy wielu przypisaniach i wywołaniach funkcji. Ten narzut jest zazwyczaj mały, ale występuje wszędzie.
Zaletą jest zazwyczaj brak dużych pauz typu stop-the-world jak w niektórych tracingowych GC. Latencja jest częściej równomierna, choć może dojść do nagłych fal dealokacji, gdy duży graf obiektów straci ostatnie odniesienie.
Główny problem: cykle
Zliczanie referencji nie poradzi sobie z obiektami w cyklu. Jeśli A referuje B, a B referuje A, oba liczniki pozostaną powyżej zera nawet jeśli nikt inny do nich nie sięga — powstaje wyciek pamięci.
Ekosystemy rozwiązują to na kilka sposobów:
- Słabe referencje (weak references) łamią cykle w typowych wzorcach (delegaci, linki rodzic/dziecko).
- Wykrywanie cykli dodane do zliczania referencji (przejście śledzące cykle).
Gdzie to zobaczysz
- Swift / Objective-C używają ARC (Automatic Reference Counting) z odwołaniami „strong/weak/unowned” do obsługi cykli.
- Python stosuje zliczanie referencji dla natychmiastowego sprzątania i dodatkowo detektor cykli dla zbierania cyklicznych odpadów.
Własność i pożyczanie: bezpieczeństwo pamięci w czasie kompilacji
Zaplanuj czasy życia z wyprzedzeniem
Zmapuj czasy życia obiektów i granice własności zanim wygenerujesz kod.
Model własności i pożyczania kojarzy się najbardziej z Rustem. Idee są proste: kompilator wymusza reguły, które utrudniają tworzenie wiszących wskaźników, double-free i wiele wyścigów danych — bez polegania na garbage collectorze w czasie wykonywania.
Własność: jeden jasny właściciel, deterministyczne sprzątanie
Każda wartość ma dokładnie jednego „właściciela” w danym momencie. Gdy właściciel wychodzi poza zakres, wartość jest natychmiast i przewidywalnie sprzątana. To daje deterministyczne zarządzanie zasobami (pamięć, uchwyty do plików, gniazda) podobne do ręcznego sprzątania, ale z dużo mniejszą liczbą sposobów na popełnienie błędu.
Własność może się też przenosić: przypisanie wartości do nowej zmiennej lub przekazanie jej do funkcji może przenieść odpowiedzialność. Po przeniesieniu stare wiązanie nie może być użyte, co zapobiega use-after-free już na etapie kompilacji.
Pożyczanie: tymczasowy dostęp bez przejmowania własności
Pożyczanie pozwala korzystać z wartości bez zostawania jej właścicielem.
Wspólne pożyczanie umożliwia tylko odczyt i może być kopiowane dowolnie.
Mutowalne pożyczanie pozwala na modyfikacje, ale musi być wyłączne: podczas jego trwania nikt inny nie może czytać ani zapisywać tej samej wartości. Reguła „jeden pisarz lub wielu czytelników” jest sprawdzana przez kompilator.
Korzyści bezpieczeństwa — i koszty
Ponieważ kompilator śledzi lifetimes, odrzuci kod, który odnosiłby się do danych żyjących krócej niż referencja do nich. To eliminuje wiele błędów związanych z wiszącymi referencjami. Te same reguły też ograniczają dużą klasę wyścigów danych w kodzie współbieżnym.
Kosztem jest krzywa uczenia się i pewne ograniczenia projektowe. Czasem trzeba przebudować przepływ danych, wprowadzić wyraźniejsze granice własności lub użyć specjalnych typów dla współdzielonego stanu mutowalnego.
Gdzie to błyszczy
Model ten świetnie nadaje się do kodu systemowego — serwisy, systemy wbudowane, sieciowe i komponenty wrażliwe na wydajność — tam gdzie chcesz przewidywalnego sprzątania i niskich opóźnień bez pauz GC.
Areny, regiony i pule: szybkie wzorce alokacji
Gdy tworzysz dużo krótkotrwałych obiektów — węzły AST w parserze, encje w klatce gry, tymczasowe dane podczas żądania webowego — koszt każdej pojedynczej alokacji i zwolnienia może zdominować czas wykonania. Areny (regiony) i pule to wzorce, które wymieniają drobne zwolnienia na szybkie zarządzanie hurtowe.
Czym są areny/regiony
Arena to „strefa” pamięci, w której alokujesz wiele obiektów w czasie, a potem zwalniasz wszystkie na raz usuwając lub resetując arenę.
Zamiast śledzić życie każdego obiektu indywidualnie, wiążesz ich czasy życia z jasną granicą: „wszystko alokowane dla tego żądania” lub „wszystko alokowane podczas kompilacji tej funkcji”.
Dlaczego to może być szybkie
Areny są szybkie, ponieważ:
- redukują wywołania alokatora (często tylko przesunięcie wskaźnika)
- unikają kosztów zwalniania pojedynczych obiektów
- poprawiają lokalność pamięci, trzymając powiązane obiekty blisko siebie
To może poprawić przepustowość i zmniejszyć skoki opóźnień spowodowane częstym zwalnianiem lub kontencją alokatora.
Typowe zastosowania
Areny i pule pojawiają się w:
- parserach i kompilatorach (drzewa składniowe, tablice symboli)
- danych per-request na serwerze (alokuj podczas żądania, zwolnij na końcu)
- grach (alokacje per-frame resetowane co klatkę)
- symulacjach i przetwarzaniu wsadowym
Zagadnienia bezpieczeństwa
Główna zasada: nie pozwalaj, aby referencje wydostały się poza region właściciela pamięci. Jeśli coś zaalokowane w arenie zostanie zapisane globalnie lub zwrócone poza czas życia areny, ryzykujesz use-after-free.
Języki i biblioteki podchodzą do tego różnie: niektóre polegają na dyscyplinie i API, inne potrafią zakodować granicę regionu w typach.
Jak to uzupełnia inne podejścia
Areny i pule nie zastępują GC czy modelu własności — często je uzupełniają. Języki z GC używają pul dla gorących ścieżek; języki o własności mogą używać aren, by grupować alokacje i jawnie określać lifetimy. Użyte ostrożnie, dają domyślnie szybkie alokacje bez utraty jasności odnośnie momentu zwolnienia pamięci.
Optymalizacje kompilatora i runtime, które zmieniają obraz
Sprawdź opóźnienia widoczne dla użytkownika
Sparuj responsywny front-end React z API, by szybko wykrywać skoki opóźnień.
Model pamięci języka to tylko część historii o wydajności i bezpieczeństwie. Nowoczesne kompilatory i runtime przepisują program, aby alokować mniej, zwalniać wcześniej i unikać dodatkowej księgowości. Dlatego proste regułki typu „GC jest wolny” albo „ręczne zarządzanie jest najszybsze” często zawodzą w praktyce.
Analiza ucieczki (escape analysis): gdy sterta nie jest konieczna
Wiele alokacji istnieje tylko po to, by przekazać dane między funkcjami. Dzięki escape analysis kompilator może udowodnić, że obiekt nigdy nie przetrwa bieżącego zakresu i umieścić go na stosu zamiast na stercie.
To może usunąć alokację na stercie w całości, wraz z kosztem jej śledzenia (GC, zliczanie referencji, blokady alokatora). W zarządzanych językach to ważny powód, dla którego małe obiekty bywają tańsze niż się wydaje.
Inline i usuwanie alokacji
Gdy kompilator inlajnuje funkcję (zastępuje wywołanie ciałem funkcji), może „zajrzeć” przez warstwy abstrakcji. To pozwala na optymalizacje takie jak:
- eliminacja obiektów tymczasowych
- zastąpienie obiektu kilkoma lokalnymi zmiennymi (scalar replacement)
- usunięcie ruchu związanego ze zliczaniem referencji, gdy czasy życia stają się oczywiste
Dobrze zaprojektowane API może stać się „zero-cost” po optymalizacji, nawet jeśli w kodzie wygląda na kosztowne alokacyjnie.
JIT kontra kompilacja AOT
JIT (just-in-time) może optymalizować na podstawie rzeczywistych danych produkcyjnych: które ścieżki są gorące, jakie są typowe rozmiary obiektów i wzorce alokacji. To często poprawia przepustowość, ale może dodawać czas rozruchu i okazjonalne pauzy na rekompilację czy GC.
Kompilacja ahead-of-time musi zgadywać więcej z góry, ale daje przewidywalny rozruch i bardziej stabilne opóźnienia.
Dźwignie strojenia w runtime (kiedy je ruszać)
Runtimey oparte na GC udostępniają ustawienia jak rozmiar sterty, cele pauz czy progi generacji. Dotykaj tych ustawień dopiero po zmierzeniu problemu (np. skoki opóźnień lub presja pamięci).
Dlaczego ten sam algorytm zachowuje się różnie
Dwie implementacje „tego samego” algorytmu mogą różnić się liczbą ukrytych alokacji, obiektów tymczasowych i odwołań. Te różnice wchodzą w interakcję z optymalizacjami, alokatorem i zachowaniem cache’a — dlatego porównania wydajności wymagają profilowania, a nie założeń.
Kompromisy wydajności: przepustowość, opóźnienie i użycie pamięci
Wybory w zarządzaniu pamięcią nie tylko zmieniają sposób pisania kodu — zmieniają, kiedy praca jest wykonywana, ile pamięci trzeba zarezerwować i jak spójnie program zachowuje się dla użytkowników.
Przepustowość kontra opóźnienie (konkretny przykład)
Przepustowość to „ile pracy na jednostkę czasu”. Pomyśl o nocnym jobie przetwarzającym 10 milionów rekordów: jeśli GC lub zliczanie referencji dodaje mały narzut, ale przyspiesza prace deweloperów, możesz i tak skończyć szybciej.
Opóźnienie to „ile czasu trwa jedna operacja end-to-end”. Dla żądania webowego pojedyncza wolna odpowiedź pogarsza UX, nawet jeśli średnia przepustowość jest wysoka. Runtime, który czasem się zatrzymuje, może być ok dla przetworów wsadowych, ale zauważalny w aplikacjach interaktywnych.
Zajętość pamięci: koszt i szybkość
Większa zajętość pamięci zwiększa koszty chmury i może spowalniać programy. Gdy working set nie mieści się w cache CPU, procesor częściej czeka na dane z RAM. Niektóre strategie pożyczają pamięć dla szybkości (np. trzymanie obiektów w pulach), inne oszczędzają pamięć kosztem dodatkowej księgowości.
Fragmentacja i lokalność cache’a (po ludzku)
Fragmentacja występuje, gdy wolna pamięć rozbita jest na wiele małych dziur — jak próba zaparkowania vana na parkingu z porozrzucanymi malutkimi miejscami. Alokatory mogą spędzać więcej czasu na szukaniu miejsca, a pamięć może rosnąć mimo że „technicznym” wystarcza wolnej przestrzeni.
Lokalność cache’a oznacza, że powiązane dane znajdują się blisko siebie. Alokacje z puli/areny często poprawiają lokalność, podczas gdy długowieczne sterty z mieszanymi rozmiarami mogą tracić lokalność i obniżać wydajność.
Wymagania przewidywalnego czasu
Jeśli potrzebujesz spójnych czasów odpowiedzi — gry, aplikacje audio, systemy transakcyjne, sterowniki wbudowane — „zwykle szybkie, ale czasem wolne” może być gorsze niż „trochę wolniejsze, ale przewidywalne”. Tu liczy się przewidywalne deallocowanie i ścisła kontrola alokacji.
Lista kontrolna do pomiarów
- Mierz zarówno przepustowość (joby/sec), jak i ogon opóźnień (p95/p99)
- Profiluj alokacje: tempo alokacji, czas pauz i czas spędzony w alloc/free
- Używaj reprezentatywnego obciążenia (realne kształty ruchu, rozmiary danych, współbieżność)
- Śledź pamięć: peak RSS, rozmiar sterty w czasie, metryki fragmentacji (o ile dostępne)
- Powtarzaj testy, by uchwycić zmienność (efekty rozgrzewki, cykle GC w tle)
Bezpieczeństwo i ochrona: jak modele pamięci zapobiegają typowym błędom
Błędy pamięci to nie tylko „pomyłki programisty”. W wielu systemach zamieniają się w problemy bezpieczeństwa: nagłe awarie (DoS), przypadkowe ujawnienia danych (odczyt zwolnionej lub niezainicjalizowanej pamięci) czy warunki umożliwiające wykonanie niezamierzonego kodu.
Jak błędy mapują się na modele pamięci
Różne strategie zarządzania pamięcią zawodzą na różne sposoby:
- Ręczne zarządzanie (C/C++) często ryzykuje use-after-free, double free i przepełnienia bufora — problemy, które mogą być eksploatowalne.
- Garbage collection eliminuje większość błędów typu use-after-free, bo obiekty nie są zwalniane, gdy są osiągalne, ale nadal możesz mieć wycieki pamięci (trzymanie referencji niepotrzebnie) oraz ryzyko w interop z kodem natywnym.
- Zliczanie referencji zapewnia natychmiastowe zwalnianie, co pomaga w przewidywalnym zwolnieniu zasobów, ale może cierpieć przez cykle (wycieki) i subtelne problemy z czasami życia przy współdzielonym stanie.
- Własność/pożyczanie (np. Rust) zapobiega wielu klasom use-after-free i wyścigów danych już na etapie kompilacji, zmniejszając powierzchnię ataku.
Bezpieczeństwo wątków i współbieżność
Współbieżność zmienia model zagrożeń: pamięć, która jest „bezpieczna” w jednym wątku, może stać się niebezpieczna, gdy inny wątek ją zwolni lub zmodyfikuje. Modele wymuszające reguły dzielenia się (albo wymagające jawnej synchronizacji) zmniejszają ryzyko wyścigów prowadzących do uszkodzeń stanu, wycieków i niestabilnych awarii.
Obrona w głębi nadal jest potrzebna
Żaden model pamięci nie usuwa wszystkich ryzyk — błędy logiczne (błędy autoryzacji, słabe domyślne ustawienia, błędne walidacje) wciąż występują. Silne zespoły stosują warstwy ochronne: sanitizery w testach, bezpieczne biblioteki standardowe, przeglądy kodu, fuzzing i surowe granice dla kodu unsafe/FFI. Bezpieczeństwo pamięci znacząco zmniejsza powierzchnię ataku, ale nie daje gwarancji.
Narzędzia i techniki do wczesnego znajdowania problemów z pamięcią
Wdróż i zweryfikuj zachowanie
Wdróż działającą aplikację i obserwuj, jak zmienia się zajętość pamięci pod realistycznym obciążeniem.
Problemy z pamięcią łatwiej naprawić, gdy złapiesz je blisko momentu wprowadzenia. Kluczem jest najpierw pomiar, potem zawężenie problemu odpowiednim narzędziem.
Podstawy profilowania: co mierzyć (i kiedy)
Zacznij od decyzji, czy gonić szybkość, czy wzrost pamięci.
Dla wydajności mierz czas ściany, czas CPU, tempo alokacji (bajty/sek) i czas w GC/alloc. Dla pamięci śledź peak RSS, stan ustalony RSS i liczby obiektów w czasie. Uruchamiaj te same obciążenia z tymi samymi danymi; małe różnice mogą ukryć duży churn alokacji.
Kategorie narzędzi (co które znajduje)
- Profilery CPU + alokacji: pokazują, gdzie spędzasz czas i które ścieżki alokują najwięcej. Dobre do znalezienia „śmierci przez tysiąc małych alokacji”.
- Detektory wycieków: raportują pamięć zaalokowaną, która nigdy nie została zwolniona (lub nigdy nie stała się nieosiągalna dla GC).
- Sanitizery: łapią use-after-free, przepełnienia bufora, wyścigi danych i niezdefiniowane zachowania podczas testów.
- Fuzzing: podsuwa nieoczekiwane dane, by wywołać awarie i uszkodzenia pamięci, których nie wyłapią zwykłe testy.
Znajdź hotspoty alokacji i zmniejsz churn
Częste objawy: jedno żądanie alokuje znacznie więcej niż oczekiwano, albo pamięć rośnie wraz z ruchem mimo stałej przepustowości. Naprawy to często ponowne użycie buforów, przeniesienie krótkotrwałych alokacji na areny/pule lub uproszczenie grafu obiektów, by mniej obiektów przetrwało cykl.
Praktyczny workflow dla wycieków i awarii
Odtwórz problem minimalnym wejściem, włącz najsurowsze kontrole runtime (sanitizery/walidacja GC), a potem zbierz:
- profil (CPU + alokacje), 2) snapshot sterty lub raport wycieków, 3) stack trace przy awarii.
Traktuj pierwszą poprawkę jako eksperyment; powtórz pomiary, by potwierdzić, że zmniejszyła alokacje lub ustabilizowała pamięć — bez przesuwania problemu gdzie indziej. Dla więcej na temat interpretacji kompromisów zobacz /blog/performance-trade-offs-throughput-latency-memory-use.
Wybór języka: dopasuj model pamięci do swoich celów
Wybór języka to nie tylko składnia czy ekosystem — jego model pamięci kształtuje codzienną szybkość pracy deweloperów, ryzyko operacyjne i przewidywalność wydajności pod rzeczywistym ruchem.
Zacznij od wymagań (nie od preferencji)
Mapuj potrzeby produktu na strategię pamięci, odpowiadając na kilka praktycznych pytań:
- Umiejętności zespołu i tolerancja na złożoność: Czy większość współpracowników czuje się komfortowo z rozumieniem czasów życia i własności, czy wolisz, by runtime robił to za nich?
- Opóźnienie kontra przepustowość: Czy potrzebujesz spójnych ogonów opóźnień (np. trading, audio, sterowanie czasu rzeczywistego), czy priorytetem jest średnia przepustowość (backendy, wsady)?
- Ograniczenia wdrożeniowe: Czy działasz w ciasnym limicie pamięci (embedded, mobile), czy masz miejsce na runtime i większe sterty?
Typowe „dopasowania”
- Garbage collection (GC): Często dobry wybór dla usług backendowych i aplikacji produktowych, gdzie tempo pracy deweloperów i bezpieczeństwo są ważniejsze niż mikrosekunodowe pauzy.
- Własność/pożyczanie (np. Rust): Naturalny wybór dla oprogramowania systemowego, komponentów krytycznych wydajnościowo i kodu wrażliwego na bezpieczeństwo.
- Zliczanie referencji (RC): Dobre dla aplikacji desktopowych/mobilnych i UI, które korzystają z przewidywalnego, przyrostowego sprzątania, akceptując obsługę cykli i narzut przy przypisaniach.
Migracja i interoperacyjność
Jeśli zmieniasz model, planuj tarcia: wywołania do istniejących bibliotek (FFI), mieszane konwencje pamięci, narzędzia i rynek pracy. Prototypy pomagają odkryć ukryte koszty (pauzy, wzrost pamięci, narzut CPU) wcześniej.
Praktyczne podejście to prototypowanie tej samej funkcji w środowiskach, które rozważasz, i porównanie tempa alokacji, ogonów opóźnień i szczytowej pamięci pod reprezentatywnym obciążeniem. Zespoły czasem robią takie „porównania jabłko-do-jabłka” w Koder.ai: można szybko zbudować prosty front React + backend w Go + PostgreSQL, iterować kształty żądań i struktury danych, by zobaczyć, jak zachowuje się usługa oparta na GC pod realistycznym ruchem (i wyeksportować źródła, gdy chcesz iść dalej).
Lekki framework decyzji
Zdefiniuj 3–5 głównych ograniczeń, zbuduj cienki prototyp i zmierz użycie pamięci, ogony opóźnień i tryby awarii.
| Model | Bezpieczeństwo domyślne | Przewidywalność opóźnień | Szybkość pracy dewelopera | Typowe pułapki |
|---|
| Ręczne | Niskie–Średnie | Wysoka | Średnia | wycieki, use-after-free |
| GC | Wysokie | Średnie | Wysoka | pauzy, wzrost sterty |
| RC | Średnio–Wysokie | Wysoka | Średnia | cykle, narzut |
| Własność | Wysokie | Wysokie | Średnia | krzywa uczenia się |