02 cze 2025·8 min
Zbuduj aplikację webową do zarządzania zgłoszeniami komunikacji między zespołami
Dowiedz się, jak zaplanować, zaprojektować i zbudować aplikację webową, która zbiera, kieruje i śledzi zgłoszenia komunikacyjne między zespołami z jasną własnością, statusami i SLA.
Zdefiniuj problem i zakres
Zanim cokolwiek zbudujesz, określ dokładnie, co chcesz naprawić. „Komunikacja między zespołami” może znaczyć wszystko, od szybkiej wiadomości na Slacku po pełne ogłoszenie o premierze produktu. Jeśli zakres jest rozmyty, aplikacja albo zamieni się w śmietnik zgłoszeń — albo nikt jej nie będzie używał.
Czym jest „zgłoszenie komunikacyjne” w tym kontekście?
Napisz prostą definicję, którą ludzie zapamiętają, oraz kilka przykładów i przeciwprzykładów. Typowe rodzaje zgłoszeń to:
- Ogłoszenia skierowane do klientów (konserwacje, zmiany polityk)
- Zatwierdzenia odpowiedzi wsparcia w wrażliwych przypadkach
- Notatki wydawnicze i changelogi
- Materiały dla działu handlowego (nowe ceny, pozycjonowanie)
- Oświadczenia poddane przeglądowi prawnemu lub przez kadrę zarządzającą
Udokumentuj też, co nie należy wyrzucać do systemu (np. doraźne burze mózgów, ogólne informacje „do wiadomości” albo „możesz wskoczyć na call?”). Jasne granice zapobiegają przemianie systemu w ogólną skrzynkę odbiorczą.
Kto jest zaangażowany i jaką rolę pełni?
Wypisz zespoły, które mają do czynienia ze zgłoszeniami, oraz odpowiedzialności każdej z ról:
- Zgłaszający (przesyła potrzebę, dostarcza kontekst i materiały)
- Zatwierdzający (potwierdza priorytet, ryzyko, zgodność i komunikat)
- Wykonawca (przygotowuje treść/kreacje, publikuje lub wysyła)
- Recenzent (ostateczna kontrola dokładności, tonu i marki)
Jeśli rola zmienia się w zależności od typu zgłoszenia (np. dział prawny tylko w niektórych przypadkach), zanotuj to teraz — wpłynie to później na reguły routingu.
Skąd będziesz wiedzieć, że się udało?
Wybierz kilka mierzalnych rezultatów, na przykład:
- Mniej pytań „jak tam aktualizacja?” na czacie
- Szybszy czas realizacji od zgłoszenia do publikacji
- Mniej zgubionych lub zdublowanych zgłoszeń
Na koniec zapisz dzisiejsze bolączki prostym językiem: niejasna odpowiedzialność, brak informacji, prośby na ostatnią chwilę i zgłoszenia ukryte w DM-ach. To będzie twoja baza odniesienia i uzasadnienie zmiany.
Zmapuj przepływ i historie użytkowników
Zanim zaczniesz budować, uzgodnij ze stronami zaangażowanymi, jak zgłoszenie przechodzi z „ktoś potrzebuje pomocy” do „zadanie wykonane”. Prosta mapa przepływu zapobiega przypadkowemu skomplikowaniu i pokazuje miejsca, gdzie zazwyczaj zawodzą przekazania.
Historie użytkowników (bądź konkretny)
Oto pięć przykładowych historii, które możesz dopasować:
- Jako zgłaszający, chcę przesłać krótkie streszczenie i od razu widzieć kto to obsługuje oraz kiedy mogę oczekiwać terminu realizacji.
- Jako właściciel triage, chcę szybko zweryfikować zgłoszenie, zadać jedno pytanie uzupełniające lub odrzucić z jasnym uzasadnieniem.
- Jako zatwierdzający, chcę przejrzeć zgłoszenie, zatwierdzić/odrzucić i zostawić komentarz, który stanie się częścią zapisu.
- Jako planista/publisher, chcę umieścić zatwierdzoną pracę w kalendarzu, wykrywać konflikty i potwierdzać datę publikacji.
- Jako interesariusz, chcę śledzić status i aktualizacje bez gonienia ludzi na czacie.
Zmapuj cykl życia zgłoszenia
Typowy cykl życia dla aplikacji do zarządzania zgłoszeniami komunikacyjnymi wygląda tak:
złóż → triage → zatwierdź → zaplanuj → opublikuj → zamknij
Dla każdego kroku zapisz:
- Kryteria wejścia (co musi być prawdą na start)
- Właściciela (osoba lub rola)
- Oczekiwany rezultat (co oznacza „ukończone”)
- Dozwolone wyjścia (przejście dalej, odesłanie do poprawek, odrzucenie)
Decyzje konfigurowalne vs. stałe
Uczyń konfigurowalnymi: zespoły, kategorie, priorytety i pytania w formularzu wg kategorii. Trzymaj jako stałe (przynajmniej na początku): podstawowe statusy i definicję „zamknięte”. Zbyt wiele opcji na początku utrudni raportowanie i szkolenie.
Najbardziej ryzykowne etapy—projektuj je ostrożnie
Zwróć uwagę na punkty awarii: zablokowane zatwierdzenia, konflikty terminów między kanałami oraz przeglądy prawne/zgodności, które wymagają ścieżki audytu i ścisłej własności. Te ryzyka powinny bezpośrednio wpływać na reguły workflow i przejścia statusów.
Zaprojektuj formularz zgłoszeniowy (zdobądź właściwe informacje od razu)
Aplikacja działa tylko wtedy, gdy formularz zgłoszeniowy konsekwentnie wychwytuje użyteczny brief. Celem nie jest pytanie o wszystko — to zadawanie właściwych pytań, żeby zespół nie spędzał dni na doprecyzowywaniu.
Zacznij od minimalnego briefu
Utrzymaj pierwszy ekran zwięzły. Co najmniej, zbieraj:
- Tytuł zgłoszenia (jednozdaniowe podsumowanie)
- Opis (czego potrzebujesz i dlaczego)
- Odbiorcy (kto powinien otrzymać komunikat)
- Kanał (email, w aplikacji, social, prasa itp.)
- Żądana data (kiedy to musi być wysłane)
- Załączniki (wstępne treści, materiały kreatywne, zrzuty ekranu, notatki prawne)
Dodaj krótkie podpowiedzi pod każdym polem, np.: „Przykład odbiorców: ‚Wszyscy klienci w USA na planie Pro’.” Te mikro-przykłady redukują dopytywania bardziej niż długie wytyczne.
Dodaj pola pomocne w unikaniu pracy ponownej
Gdy podstawy są stabilne, uwzględnij pola ułatwiające priorytetyzację i koordynację:
- Priorytet (np. Niski/Średni/Wysoki)
- Wpływ biznesowy (co się zmienia, jeśli to nie zostanie wysłane)
- Linki (PRD, ticket w Jira, analizy, dokument marki)
- Interesariusze (zatwierdzający i osoby do wiadomości)
- Język/region (jeśli dotyczy lokalizacji)
Stosuj pytania warunkowe, by formularz był krótki i kompletny
Logika warunkowa utrzymuje formę zwięzłą. Przykłady:
- Jeśli Kanał = Prasa, zapytaj o rzecznik prasowy, datę embarga i listę mediów.
- Jeśli Odbiorcy zawierają Klientów, zapytaj o kryteria segmentacji i gotowość wsparcia.
Waliduj kompletność (bez irytowania)
Użyj jasnych reguł walidacji: pola wymagane, data nie może być w przeszłości, załączniki wymagane dla „Wysoki” priorytet oraz minimalna liczba znaków w opisie.
Kiedy odrzucasz zgłoszenie, odeślij je z konkretną wskazówką (np. „Dodaj docelową grupę odbiorców i link do ticketu źródłowego”), aby zgłaszający uczyli się oczekiwanego standardu.
Ustal statusy, właścicieli i jasne reguły
System działa tylko wtedy, gdy wszyscy ufają statusowi. To oznacza, że aplikacja musi być jedynym źródłem prawdy — a nie „prawdziwy status” ukryty w rozmowach bocznych, DM-ach czy mailach.
Zdefiniuj prosty, wspólny zestaw statusów
Trzymaj statusy krótkie, jednoznaczne i powiązane z działaniami. Praktyczny domyślny zestaw statusów dla zgłoszeń komunikacyjnych to:
- Nowe — przesłane i oczekujące na triage
- Wymaga informacji — zablokowane do czasu dostarczenia brakujących danych przez zgłaszającego
- W trakcie przeglądu — oceniane pod kątem wykonalności, priorytetu lub polityki
- Zatwierdzone — przyjęte i gotowe do zaplanowania
- Zaplanowane — przypisane do daty/grafiku
- Zakończone — dostarczone i zamknięte
- Odrzucone — odrzucone z zapisanym powodem
Kluczowe jest, że każdy status odpowiada na pytanie: Co jest dalej i kto na kogo czeka?
Przypisz właścicieli dla każdego kroku (by nic nie pływało)
Każdy status powinien mieć jasną rolę „właściciela”:
- Właściciel triage (często rotacyjny dyżur) dba, żeby każde Nowe zgłoszenie było szybko obsłużone.
- Zatwierdzający podejmuje decyzję w W trakcie przeglądu.
- Osoba przypisana odpowiada za wykonanie po Zatwierdzeniu/Zaplanowaniu.
Własność zapobiega sytuacji, w której wszyscy są „zaangażowani”, ale nikt nie jest odpowiedzialny.
Napisz reguły zapobiegające chaosowi statusów
Dodaj lekkie reguły bezpośrednio w aplikacji:
- Kto może przesuwać zgłoszenie (np. tylko triage może przenieść poza Nowe; tylko zatwierdzający mogą ustawić Zatwierdzone/Odrzucone).
- Kiedy można ponownie otworzyć (np. ponowne otwarcie ze Zakończone tylko w ciągu 14 dni i z podaniem powodu).
- Co jest wymagane przy przejściu (np. przejście do Zaplanowane wymaga daty; przejście do Odrzucone wymaga uzasadnienia).
Te reguły utrzymują dokładność raportowania, redukują dopytywania i czynią przekazania przewidywalnymi.
Zaplanuj model danych i kluczowe pola
Przejrzysty model danych utrzyma twój system elastycznym, gdy pojawią się nowe zespoły, typy zgłoszeń i kroki zatwierdzania. Dąż do niewielkiego zestawu podstawowych tabel, które obsłużą wiele workflowów, zamiast tworzyć osobne schematy dla każdego zespołu.
Podstawowe tabele (zacznij prosto)
Na początek zaplanuj:
- Users: imię, email, rola, flaga aktywności
- Teams: nazwa zespołu, domyślna polityka SLA, reguły routingu
- Requests: samo zgłoszenie (szczegóły poniżej)
- Comments: dyskusja powiązana ze zgłoszeniem
- Attachments: pliki lub linki, wraz z autorem i znacznikiem czasu
- StatusHistory: każda zmiana statusu (a najlepiej także zmiany właściciela)
Taka struktura wspiera przekazania między zespołami i znacznie ułatwia raportowanie w porównaniu z poleganiem na „aktualnym stanie” jedynie.
Kluczowe pola w rekordzie Request
Tabela Requests powinna zawierać podstawy routingu i odpowiedzialności:
- requesting_team i/lub requester_user
- category (kampania, ogłoszenie, prasa, przegląd prawny itp.)
- priority (lub wpływ/pilność)
- due_date (kiedy zgłaszający potrzebuje)
- sla_target_at (obliczany termin na podstawie polityki SLA)
- current_status
- current_owner_user (lub właściciel zespołu + wykonawca)
Rozważ także: podsumowanie/tytuł, opis, żądane kanały (email, Slack, intranet) i wymagane zasoby.
Tagowanie + wyszukiwanie do filtrowania w praktyce
Dodaj tagi (relacja wiele-do-wielu) i pole searchable_text (lub indeksowane kolumny), żeby zespoły mogły szybko filtrować kolejki i raportować trendy (np. „product-launch” lub „executive-urgent”).
Audytowalność to nie opcja
Zaplanuj potrzeby audytu od początku:
- Przechowuj created_at / updated_at / closed_at
- Zachowaj StatusHistory z informacją kto co zmienił i kiedy
- Zachowaj poprzednie wartości dla krytycznych pól (status, właściciel, terminy)
Gdy interesariusze zapytają: „Dlaczego to się spóźniło?”, będziesz mieć jasną odpowiedź bez szukania w logach czatu.
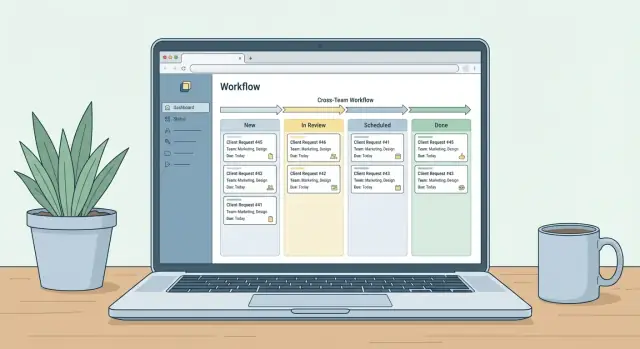
Zaprojektuj główne ekrany i nawigację
Spraw, by inwestycja się zwróciła
Podziel się tym, co zbudowałeś z Koder.ai i zarób kredyty za treści lub polecenia.
Dobra nawigacja to nie ozdoba — to sposób, by zapobiec pytaniom „gdzie to sprawdzić?”. Projektuj ekrany wokół ról, które ludzie naturalnie przyjmują w pracy ze zgłoszeniami, i trzymaj każdy widok skupiony na kolejnym działaniu.
Widok zgłaszającego (składanie i śledzenie)
Doświadczenie zgłaszającego powinno przypominać śledzenie przesyłki: jasne, spokojne i zawsze aktualne. Po zgłoszeniu pokaż stronę pojedynczego zgłoszenia ze statusem, właścicielem, docelowymi terminami i kolejnym oczekiwanym krokiem.
Ułatw:
- Złożenie zgłoszenia i dodanie załączników
- Śledzenie postępu w czasie (prosta oś czasu działa dobrze)
- Szybką odpowiedź na Wymaga informacji z komentarzami/plikami
- Otrzymywanie aktualizacji bez śledzenia (email + powiadomienia w aplikacji)
Widok triage (kolejka i decyzje)
To jest centrum dowodzenia. Domyślnie pokaż dashboard kolejki z filtrami (zespół, kategoria, status, priorytet) i akcjami masowymi.
Zawierać powinno:
- Priorytetyzowaną kolejkę z widocznym „czasem w statusie”
- Szybkie przypisywanie i przekazywanie
- Wykrywanie duplikatów (porównanie tytułu + zgłaszający + linki)
- Kontrole priorytetu i terminu bez konieczności otwierania każdego zgłoszenia
Widok wykonawcy (realizacja pracy)
Wykonawcy potrzebują ekranu obciążenia osobistego: „co jest moje, co dalej, co jest zagrożone?”. Pokaż nadchodzące terminy, zależności i checklistę zasobów, by uniknąć niepotrzebnego dopytywania.
Widok admina (konfiguruj bez psucia przepływu)
Administratorzy powinni zarządzać zespołami, kategoriami, uprawnieniami i SLA z jednego miejsca ustawień. Trzymaj zaawansowane opcje pod jednym kliknięciem i zapewnij bezpieczne domyślne ustawienia.
Nawigacja, która pozostaje spójna
Użyj lewego paska nawigacyjnego (lub górnych zakładek) odwzorowującego obszary według ról: Zgłoszenia, Kolejka, Moja praca, Raporty, Ustawienia. Jeśli użytkownik ma wiele ról, pokaż wszystkie istotne sekcje, ale pierwszy ekran dostosuj do roli (np. triagerzy lądują w Kolejce).
Uprawnienia, bezpieczeństwo i audytowalność
Uprawnienia to nie tylko wymagania IT — to sposób na zapobieganie przypadkowemu nadmiernemu udostępnianiu i utrzymanie płynności pracy. Zacznij prosto, potem zaostrzaj w miarę potrzeby.
Dostęp oparty na rolach (trzymaj to przewidywalne)
Zdefiniuj niewielki zestaw ról i spraw, by każda była oczywista w UI:
- Zgłaszający: może składać zgłoszenia, przeglądać swoje własne, odpowiadać na pytania i sprawdzać status.
- Członek zespołu (realizujący): może przeglądać kolejkę swojego zespołu, komentować, prosić o zmiany i aktualizować status.
- Zatwierdzający: może zatwierdzać/odrzucać określone kroki (np. zatwierdzenie komunikacji lub przegląd prawny).
- Admin: zarządza szablonami, polami, zespołami i regułami uprawnień.
Unikaj „przypadków specjalnych” na początku. Jeśli ktoś potrzebuje dodatkowego dostępu, potraktuj to jako zmianę roli — nie jednorazowy wyjątek.
Chroń wrażliwe zgłoszenia bez spowalniania pracy
Domyślnie stosuj widoczność zespołową: zgłoszenie widoczne jest dla zgłaszającego oraz przypisanych zespołów. Dodaj dwie opcje:
- Pola prywatne (np. budżet, dane pracownika) widoczne tylko dla określonych ról.
- Zgłoszenia ograniczone, gdzie tylko nazwana grupa ma dostęp do pełnego rekordu.
To pozwala zachować współpracę w większości przypadków, a jednocześnie chronić sytuacje wyjątkowe.
Zdecyduj, jak działają goście (jeśli w ogóle)
Jeśli potrzebujesz zewnętrznych recenzentów lub okazjonalnych interesariuszy, wybierz jeden model:
- Linki tylko do podglądu z wygaśnięciem (dobrze do udostępniania finalnej wersji).
- Konta wymagane (lepsze do zatwierdzeń, komentarzy i śledzenia).
Mieszanka obu może działać, ale udokumentuj kiedy który model jest dozwolony.
Audytowalność: automatyzuj odpowiedzialność
Loguj kluczowe działania ze znacznikiem czasu i autorem: zmiany statusów, edycje krytycznych pól, zatwierdzenia/odrzucenia oraz ostateczne potwierdzenie publikacji. Ułatw eksport ścieżki audytu dla zgodności i pokaż historię na tyle czytelnie, by zespoły ufały zapisowi bez dodatkowych pytań.
Powiadomienia i przypomnienia, które nie tworzą hałasu
Przyspiesz tworzenie podstawowych ekranów
Stwórz widoki zgłaszającego, triage i wykonawcy bez ręcznego kodowania każdej tabeli i filtra.
Powiadomienia powinny przesuwać zgłoszenie do przodu — nie tworzyć drugiej skrzynki, której ludzie będą ignorować. Cel jest prosty: powiadomić właściwą osobę o właściwej rzeczy we właściwym momencie, z jasnym kolejnym krokiem.
Powiadamiaj tylko przy kluczowych zdarzeniach workflow
Zacznij od krótkiego zestawu zdarzeń, które bezpośrednio zmieniają to, co ktoś ma zrobić dalej:
- Złożono (potwierdzenie dla zgłaszającego + co dalej)
- Przypisano (właściciel otrzymuje kontekst + link do zgłoszenia)
- Wymaga informacji (zgłaszający otrzymuje konkretne pytania i termin)
- Zatwierdzono/odrzucono (zgłaszający + zespół wykonawczy jeśli istotne)
- Wkrótce termin i przeterminowane (właściciel + opcjonalna eskalacja do managera)
Jeśli zdarzenie nie wymaga akcji, trzymaj je w logu aktywności zamiast wysyłać powiadomienie.
Wybierz 1–2 kanały i zrób je dobrze
Unikaj rozsyłania wszędzie. Większość zespołów odnosi sukces, zaczynając od jednego głównego kanału (często email) oraz jednego kanału w czasie rzeczywistym (Slack/Teams) dla właścicieli.
Praktyczna zasada: wiadomości w czasie rzeczywistym dla pracy, którą posiadasz, a email dla widoczności i zapisów. Powiadomienia w aplikacji są przydatne, gdy ludzie pracują w narzędziu codziennie.
Reguły przypomnień redukują hałas
Przypomnienia powinny być przewidywalne i konfigurowalne:
- Codzienne lub dwa razy w tygodniu podsumowania dla „wymaga informacji” i „czeka na Ciebie”
- Ciche godziny (brak pingu po godzinach; wysyłka rano)
- Eskalacja tylko po wyraźnym progu (np. 48 godzin po terminie)
Używaj szablonów, by aktualizacje były wykonalne
Szablony utrzymują komunikaty spójne i czytelne. Każde powiadomienie powinno zawierać:
- Tytuł zgłoszenia + ID
- Bieżący status i właściciela
- Co się zmieniło
- Jedno jasne CTA (np. „Dodaj informacje”, „Przejrzyj”, „Oznacz jako ukończone”)
To sprawia, że każda wiadomość wygląda jak krok naprzód — a nie szum informacyjny.
SLA, terminy i planowanie
Jeśli zgłoszenia nie są realizowane na czas, zwykle winne są niejasne oczekiwania: „Ile to powinno trwać?” i „Na kiedy?”. Wbuduj czas w workflow, żeby był widoczny, spójny i sprawiedliwy.
Zdefiniuj SLA według typu zgłoszenia
Ustal oczekiwania czasowe dopasowane do pracy. Na przykład:
- Ogłoszenia: 5 dni roboczych
- Elementy newslettera: 3 dni robocze
- Komunikacja wykonawcza: 10 dni roboczych
Uczyń pole SLA sterowane przez wybór typu: w momencie, gdy zgłaszający wybierze typ, aplikacja pokaże oczekiwany czas realizacji i najwcześniejszą możliwą datę publikacji.
Automatycznie obliczaj daty docelowe
Unikaj ręcznych obliczeń. Przechowuj dwie daty:
- Żądana data publikacji (czego chce zgłaszający)
- Docelowa data ukończenia (na co zespół się zobowiązuje)
Następnie obliczaj datę docelową na podstawie czasu realizacji dla typu zgłoszenia (dni robocze) i wymaganych kroków (np. zatwierdzeń). Jeśli ktoś zmieni datę publikacji, aplikacja powinna natychmiast zaktualizować datę docelową i oznaczyć „ciasny harmonogram”, gdy żądana data jest wcześniejsza niż możliwa do wykonania.
Planowanie zapobiegające kolizjom
Sama kolejka nie pokaże konfliktów. Dodaj prosty widok kalendarza, który grupuje pozycje według daty publikacji i kanału (email, intranet, social itp.). To pomaga wykryć przeciążenia (np. za dużo wysyłek we wtorek) i wynegocjować alternatywy zanim praca się rozpocznie.
Śledź powody opóźnień
Gdy zgłoszenie się opóźnia, zanotuj jeden „powód opóźnienia”, żeby raportowanie miało sens: czeka na zgłaszającego, czeka na zatwierdzenia, brak zdolności przerobowych lub zmiana zakresu. Z czasem to zamieni brakujące terminy w wzorce do naprawienia, a nie powtarzające się niespodzianki.
Zbuduj MVP i wybierz praktyczne podejście technologiczne
Najszybsza droga do wartości to wypuszczenie małego, użytecznego MVP, które zastępuje doraźne czaty i arkusze — bez próby rozwiązania każdego przypadku brzegowego.
Zacznij od MVP, którego ludzie będą używać
Celuj w najmniejszy zestaw funkcji, który wspiera pełny cykl zgłoszenia:
- Formularz zgłoszeniowy zbierający podstawy (typ zgłoszenia, odbiorcy, termin, priorytet, załączniki)
- Wspólna kolejka zgłoszeń (jedno miejsce, by zobaczyć „co czeka”)
- Proste statusy dopasowane do workflow (np. Nowe → W trakcie przeglądu → Zatwierdzone → Zaplanowane → Zakończone, z Wymaga informacji i Odrzucone jako ścieżkami bocznymi)
- Komentarze i @wzmianki dla doprecyzowań
- Podstawowe powiadomienia (potwierdzenie dla zgłaszającego, przypisanie właściciela, zmiany statusów)
Jeśli te elementy działają dobrze, od razu zmniejszysz liczbę dopytywań i stworzysz jedno źródło prawdy.
Wybierz stack pasujący do twojego zespołu (nie wishlisty)
Wybierz podejście zgodne z umiejętnościami, potrzebą prędkości i wymaganiami governance:
- Low-code (najszybsze): świetne dla formularzy + zatwierdzeń + prostych dashboardów.
- Platformy do narzędzi wewnętrznych: dobre dla aplikacji z autentykacją, tabelami, filtrami i panelem admina.
- Pełny stos: najlepszy, gdy potrzebujesz niestandardowych integracji, złożonych uprawnień lub rozbudowanej automatyzacji.
Jeśli chcesz przyspieszyć ścieżkę full-stack bez wracania do kruchego arkusza, platformy takie jak Koder.ai mogą pomóc w uzyskaniu działającej aplikacji wewnętrznej z opisu w formie czatu. Możesz prototypować formularz, kolejkę, role/uprawnienia i dashboardy szybko, potem iterować ze stronami zainteresowanymi — mając jednocześnie opcję eksportu kodu źródłowego i wdrożenia zgodnie z własnymi zasadami.
Wdróż wyszukiwanie i filtry od początku
Nawet przy 50–100 zgłoszeniach ludzie będą kroić kolejkę po zespole, statusie, dacie i priorytecie. Dodaj filtry od pierwszego dnia, żeby narzędzie nie zamieniło się w przewijany chaos.
Dodaj analitykę później (gdy dane będą czyste)
Gdy workflow się ustabilizuje, dołóż raportowanie: przepustowość, czas cyklu, rozmiar backlogu i odsetek trafień SLA. Uzyskasz lepsze wnioski, gdy zespoły będą konsekwentnie używać tych samych statusów i zasad terminów.
Wdrażanie, adopcja i plan iteracji
Przejdź z prototypu do produkcji
Hostuj i wdrażaj swoje narzędzie wewnętrzne zgodnie z własnymi zasadami i domenami.
Aplikacja do zgłoszeń zadziała tylko wtedy, gdy ludzie będą jej używać — i robić to nadal. Traktuj pierwsze wydanie jako fazę uczenia się, nie wielkie wdrożenie. Celem jest ustanowienie nowego „źródła prawdy” dla komunikacji między zespołami, a potem dopracowywanie workflow na podstawie rzeczywistego zachowania.
Zacznij od małego pilotażu
Przetestuj z 1–2 zespołami i 1–2 kategoriami zgłoszeń. Wybierz zespoły z częstymi przekazaniami i managerem, który może wzmocnić proces. Utrzymuj wolumen na poziomie, który pozwala szybko reagować na problemy i budować zaufanie.
W trakcie pilota uruchamiaj stary proces równolegle tylko wtedy, gdy jest to absolutnie konieczne. Jeśli aktualizacje będą nadal trafiać na czat czy mail, aplikacja nigdy nie stanie się domyślna.
Opublikuj lekkie wytyczne
Stwórz proste wytyczne odpowiadające na pytania:
- Co powinno być zgłaszane (a co nie)
- Wymagany czas lead (np. „72 godziny dla standardowych zgłoszeń”)
- Gdzie są aktualizacje (w aplikacji, nie w DM-ach)
Przypnij wytyczne w hubie zespołu i linkuj do nich z aplikacji (np. /help/requests). Zadbaj, by były krótkie i czytelne.
Zbuduj pętlę informacji zwrotnej, na którą możesz reagować
Zbieraj feedback co tydzień od zgłaszających i właścicieli. Pytaj konkretnie o brakujące pola, mylące statusy i spam powiadomień. Połącz to z szybkim przeglądem realnych zgłoszeń: gdzie ludzie się zawahali, porzucili formularz lub ominęli workflow?
Iteruj, nie burząc nawyków
Wprowadzaj zmiany małe i przewidywalne: modyfikuj pola formularza, SLA i uprawnienia na podstawie rzeczywistego użycia. Ogłaszaj zmiany w jednym miejscu z krótką notką „co się zmieniło / dlaczego”. Stabilność buduje adopcję; ciągłe prace ją osłabiają.
Jeśli chcesz, by rozwiązanie przyjęło się na stałe, mierz adopcję (zgłoszenia przez aplikację vs. poza nią), czas cyklu i pracę do poprawki. Potem użyj wyników, by priorytetyzować kolejne iteracje.
Mierz wyniki i ulepszaj z czasem
Wdrożenie aplikacji nie jest metą — to początek pętli informacji zwrotnej. Jeśli nie mierzysz systemu, może powoli zamienić się w „czarną skrzynkę”, gdzie zespoły przestaną ufać statusom i wrócą do bocznych komunikatów.
Zacznij od dashboardów, z których ludzie faktycznie korzystają
Stwórz niewielki zestaw widoków odpowiadających na codzienne pytania:
- Otwartych zgłoszeń (co jest teraz w kolejce)
- Przeterminowane (po terminie lub SLA)
- Nadchodzące (wkrótce termin, żeby zespoły mogły planować)
- Obciążenie według zespołu/właściciela (by wykrywać wąskie gardła i nierównomierne obciążenie)
Trzymaj dashboardy widoczne i spójne. Jeśli zespoły nie rozumieją ich w 10 sekund, nie będą ich sprawdzać.
Przeglądaj metryki co miesiąc — i decyduj, co zmienić
Ustal comiesięczne spotkanie (30–45 minut) z reprezentantami głównych zespołów. Użyj krótkiego, stabilnego zestawu metryk, np.:
- Średni czas do pierwszej odpowiedzi
- Średni czas do ukończenia
- Trafienie w SLA
- Wskaźnik ponownego otwarcia (zgłoszenia, które wracają)
- Wolumen wg typu zgłoszenia
Zakończ spotkanie konkretnymi decyzjami: dostosować SLA, wyjaśnić pytania w formularzu, dopracować statusy lub zmienić zasady własności. Dokumentuj zmiany w prostym changelogu, by ludzie wiedzieli, co jest inne.
Utrzymuj lekką taksonomię
Taksonomia zgłoszeń ma sens tylko wtedy, gdy pozostaje mała. Celuj w kilka kategorii plus opcjonalne tagi. Unikaj setek typów wymagających ciągłego nadzoru.
Planuj ulepszenia na podstawie dowodów
Gdy podstawy są stabilne, priorytetyzuj usprawnienia zmniejszające pracę ręczną:
- Szablony dla powtarzalnych zgłoszeń
- Integracje (czat, email, kalendarz, system ticketowy)
- Zatwierdzenia napędzane polityką (tylko gdy potrzebne)
- API do raportowania lub tworzenia zgłoszeń z innych narzędzi
Pozwól, by użycie i metryki — nie opinie — decydowały o kolejnych krokach rozwoju.