25 cze 2025·8 min
Dlaczego zarządzanie stanem jest jednym z najtrudniejszych problemów frontendowych
Zarządzanie stanem jest trudne, ponieważ aplikacje żonglują wieloma źródłami prawdy, danymi asynchronicznymi, interakcjami UI i kompromisami wydajności. Poznaj wzorce, które zmniejszają liczbę błędów.
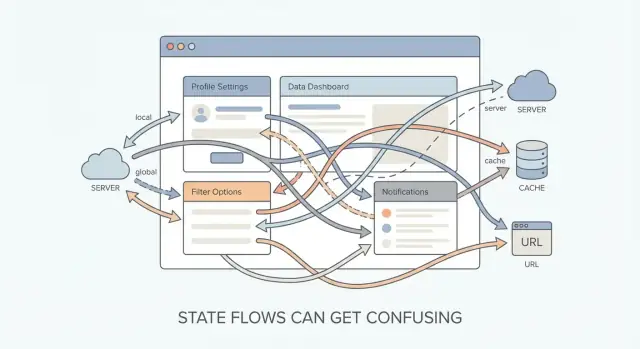
Co naprawdę oznacza „stan” w aplikacji frontendowej
Definicja prostym językiem
W aplikacji frontendowej stan to po prostu dane, od których zależy interfejs i które mogą się zmieniać w czasie.
Gdy stan się zmienia, ekran powinien zaktualizować się, by to odzwierciedlić. Jeśli ekran się nie aktualizuje, aktualizuje się niespójnie lub pokazuje mieszankę starych i nowych wartości, od razu odczuwasz „problemy ze stanem” — przyciski pozostające nieaktywne, sumy, które się nie zgadzają, albo widok, który nie odzwierciedla tego, co użytkownik właśnie zrobił.
Typowe przykłady, które widzisz codziennie
Stan pojawia się w małych i dużych interakcjach, takich jak:
- Pola formularzy: co użytkownik wpisał, czy checkbox jest zaznaczony, jakie błędy pokazać
- Wybory nawigacyjne: wybrana karta, bieżący krok w kreatorze, sekcje rozwinięte/zwiniete
- Dane koszyka: przedmioty, ilości, zastosowane kupony, obliczone sumy
- Sesja użytkownika: informacje o zalogowanym użytkowniku, uprawnienia, feature flagi, preferencje „zapamiętaj mnie”
Niektóre z nich są „tymczasowe” (np. wybrana karta), inne wydają się „ważne” (np. koszyk). Wszystkie są stanem, bo wpływają na to, co UI renderuje teraz.
Dlaczego stan to coś więcej niż „zmienne w komponencie”
Zwykła zmienna ma znaczenie tylko tam, gdzie żyje. Stan jest inny, bo ma zasady:
- Własność: która część aplikacji może go zmieniać
- Przepływ aktualizacji: kiedy i jak zmiany wywołują ponowne renderowanie
- Spójność: zapewnienie, że różne części UI nie będą dryfować względem siebie
Prawdziwym celem zarządzania stanem nie jest przechowywanie danych — to sprawienie, by aktualizacje były przewidywalne, tak by UI pozostał spójny. Jeśli potrafisz odpowiedzieć na pytanie „co się zmieniło, kiedy i dlaczego”, stan staje się możliwy do opanowania. Jeśli nie, nawet proste funkcje stają się źródłem niespodzianek.
Dlaczego stan wydaje się prosty na początku (a potem nagle nie jest)
Na początku projektu frontendowego stan wydaje się wręcz nudny — i to dobrze. Masz jeden komponent, jedno pole i jedną oczywistą aktualizację. Użytkownik wpisuje wartość, zapisujesz ją i UI się renderuje. Wszystko jest widoczne, natychmiastowe i zamknięte.
Przypadek prosty: jeden komponent, jedna aktualizacja
Wyobraź sobie pojedyncze pole tekstowe, które pokazuje podgląd wpisanego tekstu:
- Stan żyje w tym samym komponencie, który renderuje pole.
- Aktualizacja następuje bezpośrednio w odpowiedzi na akcję użytkownika.
- Nie ma sporu o to, „kto jest właścicielem” danych.
W takim układzie stan to zasadniczo: zmienna, która się zmienia w czasie. Wskazujesz, gdzie jest przechowywana i gdzie jest aktualizowana — i po sprawie.
Dlaczego lokalny stan wydaje się prosty
Lokalny stan działa, bo model mentalny pasuje do struktury kodu:
- Zakres jest mały (jeden komponent, może parę dzieci).
- Aktualizacje są synchroniczne z punktu widzenia użytkownika.
- Przepływ danych jest oczywisty: input → aktualizacja → render.
Nawet jeśli używasz frameworka takiego jak React, nie musisz głęboko myśleć o architekturze. Domyślne rozwiązania wystarczają.
Co się zmienia, gdy aplikacja rośnie
Gdy aplikacja przestaje być „stroną z widgetem” i staje się produktem, stan przestaje żyć w jednym miejscu.
Teraz ta sama informacja może być potrzebna na:
- wielu ekranach (nawigacja)
- daleko położonych komponentach (wspólne UI)
- przeładowaniach i restartach (persistencja)
- wielu użytkownikach/urządzeniach (synchronizacja z serwerem)
Nazwa profilu może być pokazywana w nagłówku, edytowana na stronie ustawień, cachowana dla szybszego ładowania i używana do personalizacji komunikatu powitalnego. Nagle pytanie brzmi nie „jak przechować tę wartość?”, lecz „gdzie powinna żyć, by była poprawna wszędzie?”.
Złożoność rośnie nieliniowo
Złożoność stanu nie rośnie stopniowo wraz z funkcjami — skacze.
Dodanie drugiego miejsca, które odczytuje te same dane, nie jest „dwa razy trudniejsze”. Wprowadza problemy koordynacji: utrzymanie zgodności widoków, zapobieganie przestarzałym wartościom, decyzja, co co aktualizuje i obsługa czasu. Gdy masz kilka współdzielonych kawałków stanu plus pracę asynchroniczną, możesz otrzymać zachowanie trudne do rozumienia — nawet jeśli każda funkcja z osobna wygląda prosto.
Zbyt wiele źródeł prawdy
Stan staje się bolesny, gdy ten sam „fakt” jest przechowywany w więcej niż jednym miejscu. Każda kopia może dryfować, a wtedy UI zaczyna się ze sobą kłócić.
Zwykli podejrzani
Większość aplikacji ma kilka miejsc, które mogą przechowywać „prawdę”:
- Dane serwera (API/baza): kanoniczny rekord
- Cache klienta (np. cache biblioteki do fetchowania): lokalne lustrzenie do odświeżania
- Lokalny stan UI (stan komponentu): co użytkownik robi teraz
- URL (ścieżka, parametry zapytania, hash): stan, który można zapisać w zakładce, udostępnić i przywrócić
Wszystkie te miejsca są właściwymi właścicielami dla pewnych rodzajów stanu. Problem zaczyna się, gdy próbują być właścicielem tego samego kawałka stanu.
Jak dochodzi do duplikacji
Typowy wzorzec: pobierz dane z serwera, a potem skopiuj je do lokalnego stanu „żeby móc edytować”. Na przykład ładujesz profil użytkownika i ustawiasz formState = userFromApi. Później serwer ponownie pobiera dane (lub inna karta je zmienia) i masz dwie wersje: cache mówi jedno, a formularz mówi coś innego.
Duplikacja także wkrada się przez „pomocne” transformacje: przechowywanie zarówno items, jak i itemsCount, albo selectedId i selectedItem.
Objawy, które rozpoznasz
Gdy są wiele źródeł prawdy, błędy zwykle brzmią tak:
- „Działa tylko na tym ekranie.”
- UI jest niespójne po nawigacji lub odświeżeniu.
- Dane wyglądają poprawnie w jednym komponencie, a w innym są przestarzałe.
- Zapis udaje się, ale widok listy nie aktualizuje się (albo aktualizuje się dwukrotnie).
Zasada kciuka
Dla każdej części stanu wybierz jednego właściciela — miejsce, w którym dokonuje się aktualizacji — i traktuj wszystko inne jako projekcję (do odczytu, pochodną lub synchronizowaną w jednym kierunku). Jeśli nie potrafisz wskazać właściciela, prawdopodobnie przechowujesz tę samą prawdę podwójnie.
Praca asynchroniczna i efekty uboczne komplikują stan
Wiele stanów w frontendzie wydaje się prostych, ponieważ są synchroniczne: użytkownik kliknął, ustawiasz wartość, UI się aktualizuje. Efekty uboczne burzą tę przewidywalną historię krok po kroku.
Co liczy się jako efekt uboczny?
Efekty uboczne to wszystkie działania, które wychodzą poza czysty model „renderuj na podstawie danych” komponentu:
- Wywołania sieciowe (fetch, zapis, ponawianie)
- Timery i debouncing (setTimeout, interval)
- Subskrypcje (web sockety, nasłuchiwacze zdarzeń)
- Przechowywanie w przeglądarce (localStorage/sessionStorage)
Każde z nich może uruchomić się później, nie powieźć się nieoczekiwanie lub wykonać się wielokrotnie.
Dlaczego stan asynchroniczny jest trudniejszy niż synchroniczny
Aktualizacje asynchroniczne wprowadzają czas jako zmienną. Nie rozumujesz już „co się wydarzyło”, lecz „co może nadal się dziać”. Dwa żądania mogą kolidować. Wolna odpowiedź może przyjść po nowszej. Komponent może odmontować się, podczas gdy callback asynchroniczny nadal próbuje aktualizować stan.
Dlatego błędy często wyglądają tak:
- Flagi ładowania zablokowane na zawsze (ścieżka błędu ich nie wyczyściła lub żądanie zostało anulowane)
- UI miga starymi danymi (przestarzała wartość z cache pokazana jako „ostateczna”)
- Przestarzałe odpowiedzi nadpisują nowe (żądanie A kończy się po B)
Prosta strategia: modeluj żądanie explicite
Zamiast rozsypywać boole jak isLoading po UI, traktuj pracę asynchroniczną jako małą maszynę stanów:
- idle (nic nie rozpoczęte)
- loading (w toku)
- success (dane dostępne)
- error (błąd złapany)
Śledź dane i status razem i trzymaj identyfikator (np. id żądania lub klucz zapytania), by móc ignorować późne odpowiedzi. To upraszcza pytanie „co UI powinno teraz pokazywać?” — staje się ono jasną decyzją, nie domysłem.
Stan UI kontra stan serwera (wyglądają podobnie, ale nimi nie są)
Wiele problemów ze stanem zaczyna się od prostego nieporozumienia: traktowania „tego, co użytkownik robi teraz” tak samo jak „tego, co mówi backend”. Oba mogą się zmieniać w czasie, ale rządzą nimi różne zasady.
Stan UI: co robi interfejs
Stan UI jest tymczasowy i napędzany interakcjami. Istnieje, by renderować ekran tak, jak użytkownik oczekuje w tej chwili.
Przykłady: modal otwarty/zamknięty, aktywne filtry, roboczy tekst wyszukiwania, hover/focus, która karta jest wybrana i UI paginacji (bieząca strona, rozmiar strony, pozycja przewijania).
Ten stan zwykle jest lokalny dla strony lub drzewa komponentów. Jest w porządku, jeśli zresetuje się po nawigacji.
Stan serwera: to, co pobrałeś (i co może się zmienić gdzie indziej)
Stan serwera to dane z API: profile użytkowników, listy produktów, uprawnienia, powiadomienia, zapisane ustawienia. To „zdalna prawda”, która może się zmienić bez udziału twojego UI (ktoś inny to edytuje, serwer to przelicza, proces tła aktualizuje).
Ponieważ jest zdalny, potrzebuje też metadanych: stany ładowania/błędów, znaczniki czasu cache, ponawiania i inwalidacji.
Dlaczego ich mieszanie powoduje zamieszanie
Jeśli przechowujesz robocze wersje UI wewnątrz danych serwera, refetch może skasować lokalne edycje. Jeśli przechowujesz odpowiedzi serwera w stanie UI bez zasad cache, będziesz walczyć ze starymi danymi, podwójnymi pobraniami i niespójnymi ekranami.
Typowy scenariusz awarii: użytkownik edytuje formularz, a w międzyczasie kończy się refetch — przychodząca odpowiedź nadpisuje szkic.
Praktyczna wskazówka
Zarządzaj stanem serwera za pomocą wzorców cache (fetch, cache, unieważnij, refetch on focus) i traktuj go jako współdzielony i asynchroniczny.
Zarządzaj stanem UI narzędziami UI (lokalny stan komponentu, context dla naprawdę współdzielonych kwestii UI) i trzymaj szkice osobno, dopóki świadomie ich nie „zapiszesz” z powrotem na serwer.
Stan pochodny i zasada „nie przechowuj tego, co możesz obliczyć”
Refaktoryzuj bez obaw
Zrób migawkę przed refaktoryzacją, aby bezpiecznie eksperymentować z reducerami, pamięcią podręczną (cache) i selektorami.
Stan pochodny to każda wartość, którą możesz obliczyć z innego stanu: suma koszyka z pozycji, filtrowana lista z oryginalnej listy + zapytania, czy flaga canSubmit z wartości pól i reguł walidacji.
Kusi, by przechowywać te wartości, bo jest wygodnie („po prostu trzymam też total w stanie”). Ale gdy wejścia zmieniają się w więcej niż jednym miejscu, ryzykujesz dryf: zapisany total nie zgadza się już z pozycjami, filtrowana lista nie odzwierciedla aktualnego zapytania, przycisk submit pozostaje nieaktywny po naprawieniu błędu. Te błędy są irytujące, bo nic nie wygląda „źle” w izolacji — każda zmienna ma sens, tylko że są niespójne.
Preferuj selektory / wartości obliczane
Bezpieczniejszy wzorzec: przechowuj minimalne źródło prawdy i licz wszystko przy odczycie. W React może to być prosta funkcja lub memoizowane obliczenie.
const items = useCartItems();
const total = items.reduce((sum, item) => sum + item.price * item.qty, 0);
const filtered = products.filter(p => p.name.includes(query));
W większych aplikacjach „selektory” (lub gettery obliczane) formalizują ten pomysł: jedno miejsce definiuje, jak wyprowadzić total, filteredProducts, visibleTodos, i wszystkie komponenty używają tej samej logiki.
Kiedy cache'owanie stanu pochodnego jest OK
Liczenie przy każdym renderze zwykle jest w porządku. Cache'uj, gdy zmierzysz realny koszt: kosztowne transformacje, ogromne listy lub wartości pochodne współdzielone przez wiele komponentów. Użyj memoizacji (useMemo, memoizacja selektorów) tak, by klucze cache były prawdziwymi wejściami — inaczej wracasz do dryfu, tylko pod inną przykrywką wydajności.
Globalne kontra lokalne: wybór właściwego właściciela
Stan staje się bolesny, gdy nie jest jasne, kto właściwie za niego odpowiada.
Co oznacza „własność”
Właściciel stanu to miejsce w aplikacji, które ma prawo go aktualizować. Inne części UI mogą go czytać (przez props, context, selektory itp.), ale nie powinny go zmieniać bezpośrednio.
Jasna własność odpowiada na dwa pytania:
- Kto może zaktualizować tę wartość? (właściciel)
- Kto może ją odczytać? (konsumenci)
Gdy te granice się zacierają, masz sprzeczne aktualizacje, momenty „dlaczego to się zmieniło?” i komponenty trudne do ponownego użycia.
Globalny stan: wygoda, ale skrywane sprzężenia
Umieszczenie stanu w globalnym store (lub kontekście najwyższego poziomu) może wydawać się czyste: wszystko ma do niego dostęp i unikasz przekazywania propsów przez wiele poziomów. Kosztem jest niezamierzone sprzężenie — nagle niepowiązane ekrany zależą od tych samych wartości, a drobne zmiany rozprzestrzeniają się po aplikacji.
Globalny stan pasuje do rzeczy naprawdę przekrojowych: bieżąca sesja użytkownika, globalne feature flagi czy wspólna kolejka powiadomień.
Podnoś stan — tylko tak daleko, jak trzeba
Częsty wzorzec to zaczynać lokalnie i „podnosić” stan do najbliższego wspólnego rodzica tylko wtedy, gdy dwie sąsiednie części muszą się zsynchronizować.
Jeśli tylko jeden komponent potrzebuje stanu, trzymaj go tam. Jeśli wiele komponentów, podnieś do najmniejszego wspólnego właściciela. Jeśli wiele odległych obszarów potrzebuje dostępu, wtedy rozważ globalny store.
Prosta heurystyka
Trzymaj stan blisko miejsca jego użycia, chyba że współdzielenie jest konieczne.
To sprawia, że komponenty są łatwiejsze do zrozumienia, zmniejsza przypadkowe zależności i ułatwia przyszłe refaktory, bo mniej części aplikacji ma prawo mutować te same dane.
Współbieżność, wyścigi i aktualizacje poza kolejnością
Udostępnij działające demo
Opublikuj działające demo z hostingiem i własną domeną, gdy potrzebujesz materiału do udostępnienia.
Aplikacje frontendowe wydają się „jednowątkowe”, ale wejścia użytkownika, timery, animacje i żądania sieciowe działają niezależnie. To oznacza, że wiele aktualizacji może być w locie jednocześnie — i niekoniecznie kończą się w kolejności, w jakiej je rozpoczęto.
Gdy aktualizacje kolidują
Typowa kolizja: dwie części UI aktualizują ten sam stan.
- Pole wyszukiwania aktualizuje
queryprzy każdym naciśnięciu klawisza. - Dropdown filtrów aktualizuje
query(lub tę samą listę wyników) przy zmianie.
Każda aktualizacja z osobna jest prawidłowa. Razem mogą się one nadpisywać w zależności od czasu. Jeszcze gorzej: możesz pokazywać wyniki dla poprzedniego zapytania, podczas gdy UI pokazuje nowe filtry.
Warunki wyścigu: szybcy użytkownicy, wolne sieci
Warunki wyścigu pojawiają się, gdy uruchamiasz żądanie A, a potem szybko żądanie B — ale żądanie A wraca jako ostatnie.
Przykład: użytkownik wpisuje „c”, „ca”, „cat”. Jeśli żądanie dla „c” jest wolne, a żądanie dla „cat” szybkie, UI może chwilowo pokazywać wyniki dla „cat”, a potem zostać nadpisane przestarzałymi wynikami dla „c”, gdy starsza odpowiedź w końcu przyjdzie.
Błąd jest subtelny, bo wszystko „zadziałało” — tylko w złej kolejności.
Techniki zmniejszające błędy poza kolejnością
Zwykle chcesz jedną z tych strategii:
- Anuluj poprzednie żądanie, gdy nowe je zastępuje (np.
AbortController). - Ignoruj przestarzałe odpowiedzi sprawdzając, czy odpowiedź dalej pasuje do najnowszych danych wejściowych.
- Używaj identyfikatorów żądań / numerów sekwencji i akceptuj tylko najnowsze.
Proste podejście z id żądania:
let latestRequestId = 0;
async function fetchResults(query) {
const requestId = ++latestRequestId;
const res = await fetch(`/api/search?q=${encodeURIComponent(query)}`);
const data = await res.json();
if (requestId !== latestRequestId) return; // przestarzała odpowiedź
setResults(data);
}
Aktualizacje optymistyczne (i dlaczego zawodzą)
Aktualizacje optymistyczne sprawiają, że UI jest natychmiastowy: aktualizujesz ekran zanim serwer potwierdzi. Ale współbieżność może złamać założenia:
- Użytkownik klika „Lubię to” szybko dwa razy (polub → cofnij), ale żądania rozwiążą się poza kolejnością.
- Optymistycznie zmniejszasz stan magazynowy, a potem późniejsza porażka wymaga rollbacku — tylko użytkownik już opuścił stronę albo zrobił kolejne zmiany.
Aby optymizm był bezpieczny, zwykle potrzebujesz jasnej reguły reconciliacji: śledź oczekiwaną akcję, stosuj odpowiedzi serwera w kolejności i jeśli trzeba cofać, rób to do znanego punktu kontrolnego (nie „do tego, jak UI wygląda teraz”).
Wydajność: gdy zmiany stanu są zbyt kosztowne
Aktualizacje stanu nie są „za darmo”. Gdy stan się zmienia, aplikacja musi ustalić, które części ekranu mogły się zmienić, a potem wykonać pracę, by obraz nowej rzeczywistości był widoczny: przeliczyć wartości, ponownie wyrenderować UI, ponownie wykonać formatowanie i czasami ponownie pobrać lub zwalidować dane. Jeśli ta reakcja jest większa niż potrzeba, użytkownik to odczuje jako opóźnienie, szarpanie animacji lub przyciski „myślące” przed reakcją.
Dlaczego mała zmiana może być duża
Pojedynczy przełącznik może niechcący wywołać mnóstwo dodatkowej pracy:
- Duże sekcje UI renderują się ponownie, mimo że zmienił się tylko mały fragment.
- Listy rysują się i mierzą ponownie, powodując przycięcia przy przewijaniu.
- Obiekty i tablice są odtwarzane przy każdej aktualizacji („deep churn”), więc aplikacja nie potrafi łatwo rozpoznać, co faktycznie się zmieniło.
Rezultatem nie jest tylko kwestia techniczna — to doświadczenie: pisanie wydaje się opóźnione, animacje zacinają się, a interfejs traci „responsywność”, którą użytkownicy kojarzą z dopracowanymi produktami.
Typowe pułapki wydajnościowe
Jedną z najczęstszych przyczyn jest zbyt szeroki stan: „duże kubełek” obiekt przechowujący dużo niepowiązanych informacji. Aktualizacja dowolnego pola sprawia, że cały kubełek wygląda na nowy, więc więcej części UI się budzi, niż to konieczne.
Inna pułapka to przechowywanie wartości obliczonych w stanie i aktualizowanie ich ręcznie. To często tworzy dodatkowe aktualizacje (i dodatkową pracę UI) tylko po to, by wszystko było zgodne.
Taktyki, które utrzymują UI szybkim
Podziel stan na mniejsze kawałki. Trzymaj niepowiązane obszary osobno, by zmiana pola wyszukiwania nie odświeżała całej strony wyników.
Normalizuj dane. Zamiast przechowywać ten sam element w wielu miejscach, przechowuj go raz i odwołuj się do niego. To redukuje powtarzające się aktualizacje i zapobiega „burzom zmian”, gdy jedna edycja powoduje przepisywanie wielu kopii.
Memoizuj wartości pochodne. Jeśli wartość można obliczyć z innych danych (np. filtrowane wyniki), cachuj obliczenie, by wykonywało się tylko wtedy, gdy wejścia faktycznie się zmienią.
Cel: mniej zacięć, mniej niespodzianek
Dobre zarządzanie stanem pod kątem wydajności to głównie kwestia ograniczenia zasięgu: aktualizacje powinny wpływać na jak najmniejszy obszar, a kosztowna praca powinna zachodzić tylko wtedy, gdy jest to naprawdę potrzebne. Gdy to prawda, użytkownicy przestają zauważać framework i zaczynają ufać interfejsowi.
Debugowanie i testowanie stanu bez domysłów
Błędy stanu często wydają się osobiste: UI jest „zły”, ale nie potrafisz odpowiedzieć na najprostsze pytanie — kto zmienił tę wartość i kiedy? Jeśli liczba się przełącza, baner znika albo przycisk się dezaktywuje, potrzebujesz linii czasowej, nie przeczucia.
Spraw, by zmiany były śledzalne (nie tajemnicze)
Najszybsza droga do jasności to przewidywalny przepływ aktualizacji. Niezależnie od tego, czy używasz reducerów, zdarzeń czy store'a, dąż do wzorca, w którym:
- Zmiany zachodzą przez niewielki zestaw dobrze nazwanych akcji (nie przypadkowe mutacje)
- Każda akcja ma jasny payload (
setShippingMethod('express'), a nieupdateStuff) - Możesz logować akcje i wynikające z nich przejścia stanu w sposób konsekwentny
Jasne logowanie akcji zmienia debugowanie z „gapienia się w ekran” w „śledzenie paragonu”. Nawet proste console.logi (nazwa akcji + kluczowe pola) biją próbę odtwarzania tego, co się stało na podstawie objawów.
Testuj logikę tam, gdzie jest stabilna
Nie próbuj testować każdego renderu. Zamiast tego testuj części, które powinny zachowywać się jak czysta logika:
- Testy jednostkowe reducerów / updaterów stanu: mając poprzedni stan + akcję, sprawdź następny stan
- Testy jednostkowe selektorów / obliczeń pochodnych: mając stan, sprawdź wynik obliczenia
- Testy integracyjne kluczowych ścieżek użytkownika: logowanie → ładowanie danych → edycja → zapis → potwierdzenie
To połączenie łapie zarówno „błędy obliczeń”, jak i rzeczywiste problemy z okablowaniem.
Dodaj lekką instrumentację dla problemów asynchronicznych
Problemy asynchroniczne chowają się w szczelinach. Dodaj minimalne metadane, które czynią linie czasowe widocznymi:
- znaczniki czasu na ważnych aktualizacjach
- id żądań (załącz id do akcji i odpowiedzi)
Wtedy gdy późna odpowiedź nadpisuje nowszą, możesz to natychmiast udowodnić — i poprawić z pewnością.
Wybór podejścia do zarządzania stanem (bez wojen narzędziowych)
Otrzymuj nagrody za naukę
Zarabiaj kredyty, tworząc treści o tym, co zbudowałeś i jak zaprojektowałeś stan.
Wybór narzędzia do stanu jest prostszy, gdy traktujesz go jako wynik decyzji projektowych, a nie punkt startowy. Zanim porównasz biblioteki, zmapuj granice stanu: co jest czysto lokalne dla komponentu, co trzeba współdzielić i co właściwie jest „danymi serwera”, które pobierasz i synchronizujesz.
Kryteria wyboru, które mają znaczenie
Praktyczny sposób decyzji to spojrzenie na kilka ograniczeń:
- Rozmiar i czas życia aplikacji: małe narzędzie wewnętrzne może pozostać proste; produkt długożyjący zyska na silniejszych konwencjach.
- Przyzwyczajenia zespołu: wybierz coś, czego zespół będzie konsekwentnie używał (i umie przeglądać).
- Potrzeby asynchroniczne: intensywne fetchowanie, cache'owanie, paginacja i mutacje zmieniają równanie.
- Złożoność stanu: przepływy przez różne strony, undo/redo i wieloetapowe formularze często wymagają więcej struktury.
Wysokopoziomowe porównanie (bez ideologii)
- Context + hooks: świetne do wstrzykiwania zależności i rzadko zmieniających się współdzielonych wartości (theme, auth). Może działać dla stanu, ale częste aktualizacje mogą być hałaśliwe bez dodatkowych wzorców.
- Store w stylu Redux: silne konwencje, przewidywalne aktualizacje i świetne narzędzia. Najlepsze, gdy potrzebujesz jasnej ścieżki audytu lub skomplikowanej koordynacji między funkcjami.
- Atomowe store'y (fine-grained state): ergonomiczne dla współdzielonego stanu bez okablowania wielu reducerów. Często łatwiej skalowalne stopniowo.
- Query caches (narzędzia do server-state): wyspecjalizowane do fetchowania, cache'owania, deduplikacji, tła refetchowania i mutacji. Eliminują dużą część „kleju asynchronicznego”.
Unikaj myślenia narzędzie-na-pierwszym-miejscu
Jeśli zaczynasz od „używamy X wszędzie”, będziesz przechowywać złe rzeczy w złych miejscach. Zacznij od własności: kto aktualizuje tę wartość, kto ją czyta i co ma się stać, gdy się zmieni.
Łączenie narzędzi często jest najlepszą opcją
Wiele aplikacji dobrze działa z biblioteką server-state dla danych API plus małym rozwiązaniem dla UI-state dotyczącego rzeczy tylko po stronie klienta, jak modale, filtry czy robocze wartości formularzy. Cel to jasność: każdy typ stanu żyje tam, gdzie najłatwiej go rozumieć.
Gdzie Koder.ai pasuje
Jeśli iterujesz nad granicami stanu i przepływami asynchronicznymi, Koder.ai może przyspieszyć pętlę „spróbuj, obserwuj, popraw”. Ponieważ generuje frontendy React (i backendy w Go + PostgreSQL) z czatu w agentowym workflow, możesz szybko prototypować alternatywne modele własności (lokalne vs globalne, cache serwera vs szkice UI) i zostawić to, co jest przewidywalne.
Dwie praktyczne funkcje pomagają przy eksperymentach ze stanem: Planning Mode (do zaplanowania modelu stanu przed budową) oraz snapshots + rollback (by bezpiecznie testować refaktory jak „usuń stan pochodny” lub „wprowadź id żądań” bez utraty działającej bazy).
Praktyczna lista kontrolna, by stan bolał mniej
Stan staje się łatwiejszy, gdy traktujesz go jak problem projektowy: zdecyduj, kto go posiada, co reprezentuje i jak się zmienia. Używaj tej listy, gdy komponent zaczyna być „tajemniczy”.
1) Wyjaśnij własność i pojedyncze źródło prawdy
Zapytaj: Która część aplikacji jest odpowiedzialna za te dane? Umieść stan jak najbliżej miejsca użycia i podnoś tylko wtedy, gdy wiele części naprawdę go potrzebuje.
- Jeden właściciel na kawałek stanu.
- Przekazuj dane w dół; wysyłaj zmiany w górę przez callbacki/zdarzenia.
- Jeśli dwa miejsca mogą aktualizować tę samą wartość, nie masz źródła prawdy — masz konflikt gotowy do eksplozji.
2) Unikaj duplikacji i modeluj wartości pochodne
Jeśli możesz coś obliczyć z innych danych, nie przechowuj tego.
- Przechowuj minimalne wejścia (np.
items,filterText). - Oblicz wyjścia (np.
visibleItems) w czasie renderu lub przez memoizację.
3) Uczyń stany asynchroniczne explicite (nie domyślne)
Praca asynchroniczna jest jaśniejsza, gdy modelujesz ją bezpośrednio:
- Preferuj mały kształt „request state”:
status: 'idle' | 'loading' | 'success' | 'error', orazdataierror. - Traktuj
loadingierrorjako stany UI pierwszej klasy, a nie rozsypane boole.
4) Uważaj na typowe antywzorce
- Kopiowanie props do stanu „na wszelki wypadek” (tworzy dryf).
- Globalizowanie wszystkiego (powoduje sprzężenie niepowiązanych ekranów).
- Zupa boole (
isLoading,isFetching,isSaving,hasLoaded, …) zamiast pojedynczego statusu.
5) Refaktoruj małymi, bezpiecznymi krokami
- Rozdziel zmieszany stan: oddziel troski UI (otwarte/zamknięte, tekst inputu) od danych serwera.
- Usuń przechowywane wartości pochodne i obliczaj je z prawdziwego źródła.
- Centralizuj efekty uboczne (fetching, subskrypcje) w jednym miejscu na feature.
Cele praktyczne
Dąż do mniejszej liczby błędów „jak to się w ogóle znalazło w tym stanie?”, zmian, które nie wymagają edycji pięciu plików i modelu mentalnego, w którym możesz wskazać jedno miejsce i powiedzieć: to jest miejsce, gdzie mieszka prawda.