03 kwi 2025·8 min
Zarządzanie stanem między frontendem i backendem w aplikacjach AI
Dowiedz się, jak stan UI, sesji i danych przepływa między frontendem a backendem w aplikacjach AI — praktyczne wzorce synchronizacji, trwałości, cache’owania i bezpieczeństwa.
Co oznacza „stan” w aplikacji zbudowanej wokół AI
„Stan” to wszystko, co aplikacja musi zapamiętać, aby zachowywać się poprawnie w kolejnych chwilach.
Jeśli użytkownik kliknie Wyślij w interfejsie czatu, aplikacja nie powinna zapomnieć, co napisał, co asystent już odpowiedział, czy żądanie nadal trwa, ani jakie ustawienia (ton, model, narzędzia) są włączone. To wszystko to stan.
Stan, prostym językiem
Praktyczny sposób myślenia o stanie: aktualna prawda aplikacji — wartości wpływające na to, co użytkownik widzi i co system zrobi dalej. Obejmuje to oczywiste rzeczy jak pola formularza, ale także „niewidoczne” fakty, np.:
- W której konwersacji znajduje się użytkownik
- Czy ostatnia odpowiedź jest w trakcie streamu czy zakończona
- Lista wiadomości i ich porządek
- Wywołania narzędzi i ich wyniki (wyniki wyszukiwania, zapytania do bazy, ekstrakcje plików)
- Błędy, ponawianie prób i mechanizmy backoff przy limitach
Dlaczego aplikacje AI mają więcej ruchomych części
Tradycyjne aplikacje często odczytują dane, pokazują je i zapisują aktualizacje. Aplikacje AI dodają dodatkowe kroki i pośrednie wyniki:
- Jedna akcja użytkownika może wywołać wiele operacji po stronie serwera (wywołanie LLM, wywołanie narzędzia, kolejne wywołanie LLM).
- Odpowiedzi mogą przychodzić inkrementalnie (streaming tokenów), więc UI musi zarządzać stanem częściowym.
- Kontekst ma znaczenie: system może potrzebować zachować pamięć konwersacji, wyniki narzędzi i ustawienia modelu w spójny sposób między żądaniami.
Ten dodatkowy ruch to powód, dla którego zarządzanie stanem jest często ukrytą złożonością w aplikacjach AI.
Co obejmie ten przewodnik
W kolejnych sekcjach rozdzielimy stan na praktyczne kategorie (stan UI, stan sesji, trwałe dane i stan modelu/runtime) i pokażemy, gdzie każda część powinna się znajdować (frontend vs. backend). Omówimy także synchronizację, cache’owanie, zadania długotrwałe, aktualizacje streamingowe i bezpieczeństwo — bo stan jest użyteczny tylko wtedy, gdy jest poprawny i chroniony.
Szybki scenariusz przykładowy
Wyobraź sobie aplikację czatu, gdzie użytkownik prosi: „Podsumuj faktury z ostatniego miesiąca i oznacz nietypowe pozycje.” Backend może (1) pobrać faktury, (2) uruchomić narzędzie analityczne, (3) streamować podsumowanie do UI i (4) zapisać końcowy raport.
Aby to wyglądało płynnie, aplikacja musi śledzić wiadomości, wyniki narzędzi, postęp i zapisane wyjście — bez mieszania konwersacji ani wycieków danych między użytkownikami.
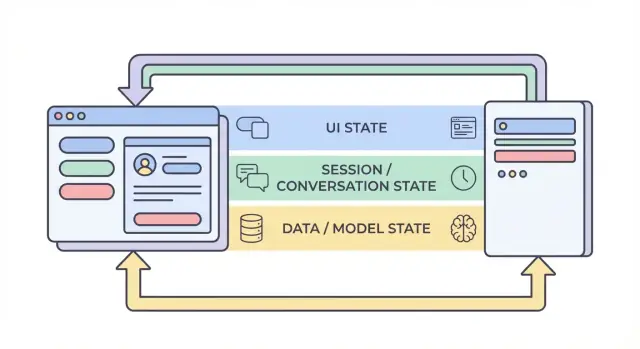
Cztery warstwy stanu: UI, sesja, dane i model
Kiedy ludzie mówią „stan” w aplikacji AI, często mieszają bardzo różne rzeczy. Podział na cztery warstwy — UI, sesja, dane i model/runtime — ułatwia decyzję gdzie coś powinno żyć, kto może to zmieniać i jak to przechować.
1) Stan UI (co użytkownik robi teraz)
Stan UI to żywy, chwilowy stan w przeglądarce lub aplikacji mobilnej: tekst w polach, przełączniki, wybrane elementy, która zakładka jest otwarta i czy przycisk jest wyłączony.
Aplikacje AI dodają kilka specyficznych elementów UI:
- Wskaźniki ładowania i stany „myślenia”
- Streamowane tokeny (cząstkowy tekst pojawiający się w miarę generowania)
- Lokalne szkice wiadomości (przed wysłaniem)
Stan UI powinien być łatwy do zresetowania i bezpieczny do utraty. Jeśli użytkownik odświeży stronę, możesz go stracić — i zwykle jest to akceptowalne.
2) Stan sesji / konwersacji (wspólny kontekst dla przepływu użytkownika)
Stan sesji wiąże użytkownika z trwającą interakcją: tożsamość użytkownika, identyfikator konwersacji i spójny widok historii wiadomości.
W aplikacjach AI często obejmuje to:
- Historię wiadomości (lub referencje do niej)
- Ślady wywołań narzędzi (jakie funkcje/narzędzia zostały wywołane i z jakimi wynikami)
- Zestaw roboczy, np. bieżący projekt/dokument, wybrany model lub workspace
Ta warstwa często rozciąga się na frontend i backend: frontend trzyma lekkie identyfikatory, a backend jest autorytetem dla ciągłości sesji i kontroli dostępu.
3) Stan danych (trwałe rekordy w magazynie)
Stan danych to to, co świadomie przechowujesz w bazie danych: projekty, dokumenty, embeddingi, preferencje, logi audytu, zdarzenia rozliczeniowe i zapisane transkrypcje konwersacji.
W przeciwieństwie do stanu UI i sesji, stan danych powinien być:
- Trwały (przetrwać restarty)
- Możliwy do zapytań (można go przeszukiwać/filtrować)
- Audytowalny (można zrozumieć, co się stało później)
4) Stan modelu / runtime (jak AI jest skonfigurowane teraz)
Stan modelu/runtime to konfiguracja operacyjna używana do wygenerowania odpowiedzi: system prompts, włączone narzędzia, temperatura/max tokens, ustawienia bezpieczeństwa, limity szybkości i tymczasowe cache’e.
Część z tego to konfiguracja (stabilne domyślne wartości); część jest efemeryczna (krótkotrwałe cache’e lub budżety tokenów na żądanie). Większość powinna znajdować się na backendzie, aby można było ją spójnie kontrolować i nie narażać niepotrzebnie.
Dlaczego separacja zmniejsza liczbę błędów
Gdy te warstwy się zacierają, pojawiają się klasyczne awarie: UI pokazuje tekst, który nie został zapisany, backend używa innych ustawień promptów niż oczekuje frontend, albo pamięć konwersacji „wycieka” między użytkownikami. Jasne granice tworzą czytelne źródła prawdy — i ułatwiają zrozumienie, co trzeba przechować, co można przeliczyć i co chronić.
Co powinno żyć po stronie frontend vs backend (i dlaczego)
Dobry sposób na zmniejszenie błędów w aplikacjach AI to zdecydować, dla każdej części stanu, gdzie powinna żyć: w przeglądarce (frontend), na serwerze (backend) lub w obu. Ten wybór wpływa na niezawodność, bezpieczeństwo i to, jak „zaskakująca” będzie aplikacja po odświeżeniu, otwarciu nowej karty lub utracie sieci.
Stan frontend: szybki, tymczasowy i napędzany przez użytkownika
Stan frontend jest najlepszy dla rzeczy, które zmieniają się szybko i nie muszą przetrwać odświeżenia. Trzymanie ich lokalnie sprawia, że UI jest responsywne i unika niepotrzebnych wywołań API.
Typowe przykłady tylko po stronie klienta:
- Tekst szkicu wiadomości, który użytkownik wpisuje
- Lokalne filtry i kolejność sortowania w tabeli
- Stan modali (otwarty/zamknięty), wybrana zakładka, stany hover
Jeśli utracisz ten stan po odświeżeniu, zwykle jest to akceptowalne (i oczekiwane).
Stan backend: autorytatywny, wrażliwy i współdzielony
Backend powinien przechowywać wszystko, co musi być zaufane, audytowane lub konsekwentnie egzekwowane. Wlicza się w to stan, który inne urządzenia/karty muszą widzieć, albo który musi być poprawny nawet jeśli klient zostanie zmodyfikowany.
Typowe przykłady tylko na backendzie:
- Uprawnienia i role (co użytkownik może zrobić)
- Status subskrypcji i limity użycia
- Zadania długotrwałe (indeksowanie dokumentów, duże eksporty, fine-tune) i ich status
Dobra zasada: jeśli niepoprawny stan może kosztować pieniądze, wyciec dane lub złamać kontrolę dostępu, należy trzymać go na backendzie.
Stan współdzielony: skoordynowany, ale z jednym źródłem prawdy
Niektóre elementy stanu naturalnie są współdzielone:
- Tytuł konwersacji
- Wybrane źródła wiedzy dla czatu
- Pola profilu użytkownika używane na wielu urządzeniach
Nawet gdy stan jest współdzielony, wybierz „źródło prawdy”. Zazwyczaj backend jest autorytatywny, a frontend cachuje kopię dla szybkości.
Zasada kciuka (i typowy antywzorzec)
Trzymaj stan jak najbliżej miejsca, gdzie jest potrzebny, ale persystuj to, co musi przetrwać odświeżenie, zmianę urządzenia lub przerwy.
Unikaj antywzorca polegającego na trzymaniu wrażliwego lub autorytatywnego stanu tylko w przeglądarce (np. klient-side isAdmin, plan subskrypcji czy status zakończenia zadania). UI może wyświetlać takie wartości, ale backend musi je weryfikować.
Typowy cykl żądania AI: od kliknięcia do zakończenia
Funkcja AI wydaje się „jedną akcją”, ale tak naprawdę to łańcuch przejść stanu współdzielonych między przeglądarką a serwerem. Zrozumienie tego cyklu ułatwia uniknięcie niespójnego UI, brakującego kontekstu i podwójnych opłat.
1) Akcja użytkownika → frontend przygotowuje intent
Użytkownik klika Wyślij. UI natychmiast aktualizuje lokalny stan: może dodać „oczekującą” bąbelkę wiadomości, wyłączyć przycisk wyślij i uchwycić bieżące dane wejściowe (tekst, załączniki, wybrane narzędzia).
W tym momencie frontend powinien wygenerować lub dołączyć identyfikatory korelacyjne:
- conversation_id: do której nitki należy to zdarzenie
- message_id: klientowski ID nowej wiadomości użytkownika
- request_id: unikalny dla próby (przydatny przy ponawianiu)
Te ID pozwalają obu stronom mówić o tym samym zdarzeniu nawet gdy odpowiedzi przyjdą późno lub podwójnie.
2) Wywołanie API → serwer weryfikuje i persystuje
Frontend wysyła żądanie API z wiadomością użytkownika i ID. Serwer waliduje uprawnienia, limity i kształt payloadu, a następnie zapisuje wiadomość użytkownika (albo przynajmniej niezmienny zapis logu) kluczowany przez conversation_id i message_id.
Ten krok persystencji zapobiega „fantomowej historii”, gdy użytkownik odświeża stronę w trakcie żądania.
3) Serwer rekonstruuje kontekst
Aby wywołać model, serwer odbudowuje kontekst ze swojego źródła prawdy:
- Pobiera ostatnie wiadomości dla conversation_id
- Pobiera powiązane rekordy (dokumenty, preferencje, wyniki narzędzi)
- Stosuje polityki konwersacji (system prompts, reguły pamięci, przycinanie)
Kluczowa idea: nie polegaj na kliencie, aby dostarczył pełną historię. Klient może być nieaktualny.
4) Wykonanie modelu/narzędzi → stan pośredni
Serwer może wywoływać narzędzia (wyszukiwanie, zapytanie do bazy) przed lub podczas generowania modelu. Każde wywołanie narzędzia tworzy stan pośredni, który powinien być śledzony względem request_id, aby można go było audytować i bezpiecznie ponawiać.
5) Odpowiedź (streaming lub nie) → zakończenie w UI
W przypadku streamingu serwer wysyła częściowe tokeny/wydarzenia. UI stopniowo aktualizuje oczekującą wiadomość asystenta, ale traktuje ją jako „w toku” do momentu, gdy zdarzenie końcowe oznaczy zakończenie.
6) Punkty awarii, na które trzeba być przygotowanym
Ponawiania, podwójne wysyłanie i odpowiedzi przychodzące w nieprawidłowej kolejności się zdarzają. Używaj request_id do deduplikacji po stronie serwera i message_id do pogodzenia w UI (ignoruj późne kawałki, które nie pasują do aktywnego żądania). Zawsze pokazuj wyraźny stan „nieudane” z bezpieczną opcją ponowienia, która nie tworzy duplikatów.
Sesje i pamięć konwersacji: zachować kontekst bez chaosu
Earn credits as you build
Dziel się tym, co zbudujesz z Koder.ai lub poleć współpracowników, by zdobyć dodatkowe kredyty.
Sesja to „nitka”, która wiąże działania użytkownika razem: w jakim workspace jest, czego ostatnio szukał, jaki szkic edytował i do której konwersacji ma trafić odpowiedź AI. Dobry stan sesji sprawia, że aplikacja wydaje się ciągła na różnych stronach — i najlepiej między urządzeniami — bez zamieniania backendu w magazyn wszystkiego, co użytkownik kiedykolwiek powiedział.
Cele stanu sesji
Celuj w: (1) ciągłość (użytkownik może odejść i wrócić), (2) poprawność (AI używa właściwego kontekstu dla właściwej konwersacji) i (3) izolację (jedna sesja nie powinna przeciekać do drugiej). Jeśli obsługujesz wiele urządzeń, traktuj sesje jako zakresowane według użytkownika plus urządzenia: „to samo konto” nie zawsze oznacza „to samo otwarte środowisko pracy”.
Cookies vs. tokeny vs. sesje serwerowe
Zazwyczaj wybierzesz jedną z tych metod identyfikacji sesji:
- Cookies: najprostsze dla aplikacji webowych, bo przeglądarka wysyła je automatycznie. Dobre dla tradycyjnych sesji, ale trzeba ustawić bezpieczne flagi (
HttpOnly,Secure,SameSite) i obsłużyć CSRF. - Tokeny (np. JWT): dobre dla API i aplikacji mobilnych, bo klient dołącza je jawnie. Skalują się, ale unieważnianie i rotacja wymagają dodatkowego projektu (i nie powinno się pakować w token wrażliwych stanów).
- Sesje serwerowe: serwer przechowuje dane sesji (często w Redis), a klient trzyma tylko nieprzejrzysty identyfikator sesji. Najłatwiejsze do unieważnienia i aktualizacji, ale trzeba uruchomić i skalować store sesji.
Strategie pamięci konwersacji
„Pamięć” to po prostu stan, który decydujesz się odesłać z powrotem do modelu.
- Pełna historia: najbardziej dokładna, ale kosztowna i może ujawniać stare wrażliwe treści.
- Podsumowana historia: trzymaj bieżące podsumowanie plus kilka ostatnich tur; tańsze i zwykle wystarczające.
- Kontekst okna: tylko ostatnie N wiadomości; najprostsze, ale może tracić ważne wcześniejsze decyzje.
Praktyczny wzorzec to podsumowanie + okno: przewidywalne i pomaga unikać zaskakujących zachowań modelu.
Wywołania narzędzi: powtarzalne i audytowalne
Jeśli AI używa narzędzi (wyszukiwanie, zapytania do bazy, odczyty plików), zapisuj każde wywołanie narzędzia z: wejściami, znacznikami czasu, wersją narzędzia i zwróconym outputem (lub odniesieniem do niego). To pozwala wyjaśnić „dlaczego AI to powiedziało”, odtworzyć wykonania do debugowania i wykryć, kiedy wyniki zmieniły się, bo narzędzie lub zbiór danych się zmieniły.
Zasady prywatności
Nie przechowuj długo żyjącej pamięci domyślnie. Trzymaj tylko to, co potrzebne do ciągłości (ID konwersacji, podsumowania i logi narzędzi), ustaw limity retencji i unikaj przechowywania surowego tekstu użytkownika, chyba że jest jasny powód produktowy i zgoda użytkownika.
Bezpieczna synchronizacja stanu: źródła prawdy i obsługa konfliktów
Stan staje się ryzykowny, gdy ta sama „rzecz” może być edytowana w więcej niż jednym miejscu — UI, druga karta przeglądarki lub zadanie w tle. Naprawa to mniej skomplikowany kod, a więcej jasne przypisanie własności.
Zdefiniuj źródła prawdy
Zdecyduj, który system jest autorytatywny dla każdego fragmentu stanu. W większości aplikacji AI backend powinien trzymać kanoniczny rekord dla wszystkiego, co musi być poprawne: ustawienia konwersacji, uprawnienia narzędzi, historia wiadomości, limity billingowe i status zadań. Frontend może cache’ować i wyprowadzać stan dla szybkości (wybrana zakładka, szkic promptu, wskaźniki „pisze”), ale przy rozbieżności powinien przyjąć, że backend ma rację.
Praktyczna zasada: jeśli byłbyś zdenerwowany jego utratą po odświeżeniu, prawdopodobnie należy to trzymać na backendzie.
Optymistyczne aktualizacje UI (używaj ostrożnie)
Optymistyczne aktualizacje sprawiają, że aplikacja wydaje się natychmiastowa: przełącz ustawienie, zaktualizuj UI od razu, potem potwierdź z serwerem. Dobrze działa to dla niskiego ryzyka, odwracalnych akcji (np. oznaczanie gwiazdką konwersacji).
Mylące może być, gdy serwer odrzuci lub zmieni zmianę (kontrole uprawnień, limity, walidacja, serwerowe domyślne). W takich przypadkach pokaż stan „zapisuję…” i aktualizuj UI po potwierdzeniu.
Obsługa konfliktów (dwie karty, jedna konwersacja)
Konflikty zdarzają się, gdy dwóch klientów aktualizuje ten sam rekord na bazie różnych wersji początkowych. Przykład: Karta A i Karta B zmieniają temperaturę modelu.
Użyj lekkiego wersjonowania, aby backend wykrywał przestarzałe zapisy:
updated_attimestampy (proste, czytelne)- ETag /
If-Matchnagłówki (wbudowane w HTTP) - Inkremantalne numery rewizji (wyraźna detekcja konfliktów)
Jeśli wersja nie pasuje, zwróć odpowiedź konfliktu (często HTTP 409) i odeślij najnowszy obiekt ze serwera.
Projektuj API, by redukować rozbieżności
Po zapisie API powinno zwracać zapisany obiekt tak, jak się utrwalił (włączając serwerowo wygenerowane domyślne, znormalizowane pola i nową wersję). To pozwala frontendowi natychmiast zastąpić swoją kopię cache — jedna aktualizacja źródła prawdy zamiast zgadywania, co się zmieniło.
Cache’owanie i wydajność: przyspieszanie bez przeterminowanego stanu
Cache to szybki sposób, by aplikacja AI wydawała się natychmiastowa, ale równocześnie tworzy drugą kopię stanu. Jeśli skachujesz niewłaściwe rzeczy — albo w złym miejscu — dostarczysz UI, który jest szybki, ale mylący.
Co cachować po stronie klienta
Cache po stronie klienta powinien skupiać się na doświadczeniu, nie na autorytecie. Dobre kandydatury to ostatnie podglądy konwersacji (tytuły, fragmenty ostatnich wiadomości), preferencje UI (motyw, wybrany model, stan paska bocznego) i optymistyczne stany UI (wiadomości w trakcie wysyłania).
Trzymaj cache klienta mały i jednorazowy: jeśli go wyczyszczesz, aplikacja powinna działać ponownie po ponownym pobraniu z serwera.
Co cachować po stronie serwera
Cache serwera powinien skupiać się na kosztownych lub często powtarzanych operacjach:
- Wyniki narzędzi, które są bezpieczne do ponownego użycia (np. prognoza pogody dla tego samego miasta przez 5 minut)
- Wyszukiwania wektorowe i wyniki embeddingów dla powtarzających się zapytań (z krótkimi TTL)
- Stan rate-limitów i liczniki throttlingu (by chronić API i koszty)
Tu też możesz cache’ować pochodne stany, takie jak liczba tokenów, decyzje moderacyjne czy wyniki parsowania dokumentów — cokolwiek deterministycznego i kosztownego.
Podstawy unieważniania cache (bez głupiego kombinowania)
Trzy praktyczne reguły:
- Używaj jasnych kluczy cache kodujących wejścia (
user_id, model, parametry narzędzia, wersja dokumentu). - Ustal TTL w oparciu o to, jak szybko dane się zmieniają. Krótki TTL bije sprytne reguły.
- Omijaj cache, gdy poprawność jest ważniejsza niż prędkość: po aktualizacji dokumentu, zmianie uprawnień lub żądaniu odświeżenia.
Jeśli nie potrafisz wyjaśnić, kiedy wpis cache stanie się niepoprawny, nie cachuj go.
Nie cachuj sekretów ani danych osobowych w współdzielonych cache’ach
Unikaj wkładania kluczy API, tokenów auth, surowych promptów zawierających wrażliwe teksty lub treści specyficznych dla użytkownika do warstw współdzielonych jak CDN. Jeśli musisz cache’ować dane użytkownika, izoluj według użytkownika i szyfruj w spoczynku — albo trzymaj je w głównej bazie danych.
Mierz wpływ: prędkość kontra przeterminowane UI
Cache powinien być dowodzony, nie założony. Mierz p95 latency przed/po, współczynnik trafień cache i błędy widoczne dla użytkownika jak „wiadomość zaktualizowana po renderowaniu”. Szybka odpowiedź, która później zaprzecza UI, bywa gorsza niż nieco wolniejsza, ale spójna.
Trwałość i prace długotrwałe: zadania, kolejki i stan statusu
Turn architecture into code
Opisz swój model stanu, a Koder.ai wygeneruje szkielet w React, Go i PostgreSQL.
Niektóre funkcje AI kończą się w sekundę. Inne trwają minuty: przesyłanie i parsowanie PDF, embedding i indeksowanie bazy wiedzy albo uruchamianie wieloetapowego workflowu narzędzi. Dla nich „stan” to nie tylko to, co na ekranie — to, co przetrwa odświeżenia, ponowienia i czas.
Co przechowywać (i dlaczego)
Persistuj tylko to, co odblokowuje realną wartość produktową.
Historia konwersacji to oczywistość: wiadomości, znaczniki czasu, tożsamość użytkownika i (często) który model/narzędzia były użyte. To umożliwia „wznowienie później”, ścieżki audytu i lepsze wsparcie.
Ustawienia użytkownika i workspace powinny żyć w bazie: preferowany model, domyślne temperatury, przełączniki funkcji, system prompts i preferencje UI, które powinny podążać za użytkownikiem na różnych urządzeniach.
Pliki i artefakty (uploady, wyekstrahowany tekst, wygenerowane raporty) zwykle przechowuje się w object storage z rekordami w bazie wskazującymi na nie. Baza trzyma metadane (właściciel, rozmiar, typ treści, stan przetwarzania), a blob store trzyma bajty.
Prace w tle dla długich zadań
Jeśli żądanie nie może się wiarygodnie zakończyć w normalnym timeout HTTP, przenieś pracę do kolejki.
Typowy wzorzec:
- Frontend wywołuje API jak
POST /jobsz danymi wejściowymi (id pliku, id konwersacji, parametry). - Backend dodaje zadanie do kolejki i natychmiast zwraca
job_id. - Workerzy przetwarzają zadania asynchronicznie i zapisują wyniki w trwałym magazynie.
To utrzymuje UI responsywnym i ułatwia bezpieczne ponawianie.
Stan statusu, któremu UI może zaufać
Uczyń status zadania jawny i możliwy do zapytania: queued → running → succeeded/failed (opcjonalnie canceled). Przechowuj te przejścia po stronie serwera ze znacznikami czasu i szczegółami błędów.
W UI pokaż status czytelnie:
- Queued/running: pokaż spinner i zablokuj duplikaty akcji.
- Failed: pokaż zwięzły błąd i przycisk Retry.
- Succeeded: załaduj wynikowy artefakt lub zaktualizuj konwersację.
Udostępnij GET /jobs/{id} (polling) lub strumień aktualizacji (SSE/WebSocket), aby UI nie musiało zgadywać.
Klucze idempotentności: ponawiania bez duplikatów
Timeouty sieciowe się zdarzają. Jeśli frontend ponawia POST /jobs, nie chcesz dwóch identycznych zadań (i dwóch rachunków).
Wymagaj Idempotency-Key dla każdej logicznej akcji. Backend zapisuje klucz razem z wynikiem job_id/odpowiedzią i zwraca ten sam rezultat dla powtarzających się żądań.
Polityki czyszczenia i wygaśnięcia
Aplikacje AI gromadzą dane szybko. Zdefiniuj zasady retencji wcześnie:
- Wygaszaj stare konwersacje po N dniach (lub daj taką konfigurację użytkownikowi).
- Usuwaj artefakty po usunięciu źródła.
- Okresowo czyść nieudane zadania i pliki pośrednie.
Traktuj sprzątanie jako część zarządzania stanem: redukuje ryzyko, koszty i zamieszanie.
Odpowiedzi streamingowe i aktualizacje w czasie rzeczywistym: zarządzanie stanem częściowym
Streaming komplikuje stan, bo „odpowiedź” przestaje być jednym blobem. Masz do czynienia z częściowymi tokenami (tekst przychodzący słowo po słowie) i czasami częściową pracą narzędzi (wyszukiwanie zaczyna się, a kończy później). To oznacza, że UI i backend muszą się zgadzać, co jest tymczasowe, a co finalne.
Backend: streamuj typowane zdarzenia, nie tylko tekst
Czysty wzorzec to stream sekwencji małych zdarzeń, z typem i payloadem. Na przykład:
token: tekst przyrostowy (lub mały fragment)tool_start: rozpoczęcie pracy narzędzia (np. „Szukam…”, z id)tool_result: wynik narzędzia jest gotowy (to samo id)done: wiadomość asystenta jest kompletnaerror: coś poszło nie tak (dołącz komunikat bezpieczny dla użytkownika i debug id)
Taki strumień zdarzeń łatwiej wersjonować i debugować niż surowy streaming tekstu, bo frontend może dokładnie renderować postęp (i pokazywać status narzędzi) bez zgadywania.
Frontend: aktualizacje tylko dopisywane, potem finalny commit
Na kliencie traktuj streaming jako dopisywanie: utwórz szkic wiadomości asystenta i ciągle go rozszerzaj, gdy przychodzą zdarzenia token. Kiedy nadejdzie done, wykonaj commit: oznacz wiadomość jako finalną, zapisz ją (jeśli trzymasz lokalnie) i odblokuj akcje takie jak kopiowanie, ocenianie czy regeneracja.
To unika przepisywania historii w trakcie streamu i utrzymuje UI przewidywalnym.
Obsługa przerwań (anuluj, rozłączenia, timeouty)
Streaming zwiększa prawdopodobieństwo pół-skończonej pracy:
- Użytkownik anuluje: wyślij sygnał cancel; przestań renderować tokeny; pozostaw szkic wyraźnie anulowany.
- Utrata sieci: zatrzymaj stream; pokaż „ponowne łączenie…” i nie zakładaj zakończenia.
- Timeouty/błędy serwera: sfinalizuj szkic jako nieudany i daj możliwość ponowienia, które zaczyna nowe żądanie (nie łącz strumieni w tle).
Rehydratacja: przeładuj i odbuduj stabilny stan
Jeśli strona zostanie przeładowana w trakcie streamu, odbuduj z ostatniego stabilnego stanu: ostatnie zatwierdzone wiadomości plus dowolne przechowane meta dane szkicu (message id, zgromadzony tekst, statusy narzędzi). Jeśli nie można wznowić streamu, pokaż szkic jako przerwany i pozwól użytkownikowi ponowić, zamiast udawać, że się zakończył.
Bezpieczeństwo i prywatność: ochrona stanu end-to-end
Prototype web and mobile
Stwórz klienty Flutter mobile i React web, które dzielą ten sam backend i stan.
Stan to nie tylko „dane, które przechowujesz” — to prompty użytkownika, uploady, preferencje, wygenerowane wyniki i metadane powiązane z tym wszystkim. W aplikacjach AI stan może być wyjątkowo wrażliwy (dane osobowe, zastrzeżone dokumenty, wewnętrzne decyzje), więc bezpieczeństwo trzeba projektować na każdej warstwie.
Trzymaj sekrety na serwerze
Wszystko, co pozwoli klientowi podszyć się pod twoją aplikację, musi zostać tylko po stronie backendu: klucze API, prywatne konektory (Slack/Drive/DB creds) oraz wewnętrzne system prompts czy logika routingu. Frontend może żądać akcji („podsumuj ten plik”), ale backend powinien decydować, jak ją wykonać i z jakimi poświadczeniami.
Autoryzuj każdy zapis (i większość odczytów)
Traktuj każdą mutację stanu jako uprzywilejowaną operację. Kiedy klient próbuje stworzyć wiadomość, zmienić nazwę konwersacji lub dołączyć plik, backend powinien zweryfikować:
- Użytkownik jest uwierzytelniony.
- Użytkownik jest właścicielem zasobu (konwersacji, workspace, projektu).
- Użytkownik ma prawo do tej akcji (rola, limity planu, polityka organizacji).
To zapobiega atakom typu „zgadywanie ID”, gdzie ktoś podmienia conversation_id i uzyskuje dostęp do historii innego użytkownika.
Nigdy nie ufaj przeglądarce: waliduj i sanityzuj
Zakładaj, że każde dane od klienta są nieufne. Waliduj schemat i ograniczenia (typy, długości, dozwolone enumy) i sanityzuj pod kątem celu docelowego (SQL/NoSQL, logi, renderowanie HTML). Jeśli akceptujesz „aktualizacje stanu” (np. ustawienia, parametry narzędzi), whitelistuj dozwolone pola zamiast scalać dowolne JSON.
Ścieżki audytu dla krytycznych działań
Dla akcji, które zmieniają trwały stan — udostępnianie, eksport, usuwanie, dostęp do konektorów — zapisuj kto, co i kiedy zrobił. Lekki log audytu pomaga przy reakcji na incydenty, wsparciu klienta i zgodności.
Minimalizacja danych i szyfrowanie
Przechowuj tylko to, co potrzebne do dostarczenia funkcji. Jeśli nie potrzebujesz pełnych promptów na zawsze, rozważ okna retencji lub redakcję. Szyfruj wrażliwe stany w spoczynku tam, gdzie to właściwe (tokeny, poświadczenia konektorów, uploady) i używaj TLS w tranzycie. Oddziel metadane operacyjne od treści, by móc restrykcyjniej kontrolować dostęp.
Praktyczna referencyjna architektura i lista kontrolna do budowy
Użyteczny domyślny model dla aplikacji AI jest prosty: backend jest źródłem prawdy, frontend to szybki, optymistyczny cache. UI może wydawać się natychmiastowe, ale wszystko, co byłoby przykre do utraty (wiadomości, status zadań, wyniki narzędzi, zdarzenia billingowe) powinno być potwierdzone i zapisane po stronie serwera.
Jeśli budujesz w szybkim trybie iteracyjnym — gdzie duża część powierzchni produktowej powstaje szybko — model stanu staje się jeszcze ważniejszy. Platformy takie jak Koder.ai mogą pomóc zespołom wypuścić pełne webowe, backendowe i mobilne aplikacje z czatu, ale ta sama zasada pozostaje: szybka iteracja jest bezpieczniejsza, gdy źródła prawdy, ID i przejścia statusów są zaprojektowane wcześniej.
Referencyjna architektura (taka, którą możesz wdrożyć)
Frontend (przeglądarka/mobilnie)
- Stan UI: otwarte panele, szkic promptu, wybrany model, tymczasowe wskaźniki „pisze”.
- Cachowany stan serwera: ostatnie konwersacje, ostatni znany status zadań, bufor częściowych streamów.
- Pojedynczy pipeline żądań, który zawsze dołącza:
session_id,conversation_idi nowyrequest_id.
Backend (API + workerzy)
- Serwis API: waliduje wejście, tworzy rekordy, wydaje odpowiedzi streamingowe.
- Trwały magazyn (SQL/NoSQL): konwersacje, wiadomości, wywołania narzędzi, statusy zadań.
- Kolejka + workerzy: zadania długotrwałe (RAG indexing, parsowanie plików, generacja obrazów).
- Cache (opcjonalnie): gorące odczyty (podsumowania konwersacji, metadane embeddingów), zawsze kluczowane wersjami/timestampami.
Uwaga: praktyczny sposób na spójność to ustandaryzowanie backendu wcześnie. Na przykład, Koder.ai-generated backends często używają Go z PostgreSQL (i React na frontendzie), co upraszcza centralizację „autorytatywnego” stanu w SQL, podczas gdy cache klienta pozostaje jednorazowy.
Zaprojektuj model stanu najpierw
Zanim zbudujesz ekrany, zdefiniuj pola, na których polegasz we wszystkich warstwach:
- ID i własność:
user_id,org_id,conversation_id,message_id,request_id. - Timestamps i porządek:
created_at,updated_atoraz jawnesequencedla wiadomości. - Pola statusu:
queued | running | streaming | succeeded | failed | canceled(dla zadań i wywołań narzędzi). - Wersjonowanie:
etaglubversiondla aktualizacji odpornych na konflikty.
To zapobiega klasycznemu błędowi, gdy UI „wygląda dobrze”, ale nie potrafi pogodzić ponowień, odświeżeń lub jednoczesnych edycji.
Używaj spójnych kształtów API
Utrzymuj endpointy przewidywalne między funkcjami:
GET /conversations(lista)GET /conversations/{id}(pobierz)POST /conversations(utwórz)POST /conversations/{id}/messages(dopisz)PATCH /jobs/{id}(zaktualizuj status)GET /streams/{request_id}lubPOST .../stream(stream)
Zwracaj ten sam styl koperty wszędzie (włącznie z błędami), aby frontend mógł ujednolicone aktualizować stan.
Dodaj obserwowalność tam, gdzie stan może się zepsuć
Loguj i zwracaj request_id dla każdego wywołania AI. Rejestruj wejścia/wyjścia wywołań narzędzi (z redakcją), opóźnienia, ponowienia i końcowy status. Ułatw odpowiadanie na pytanie: „Co model zobaczył, jakie narzędzia się uruchomiły i jaki stan zapisaliśmy?”
Lista kontrolna do budowy (aby uniknąć typowych błędów stanu)
- Backend jest źródłem prawdy; cache frontend jest jasno oznaczony i jednorazowy.
- Każdy zapis jest idempotentny (bezpieczny do ponowienia) przy użyciu
request_id(i/lub Idempotency-Key). - Przejścia statusów są jawne i walidowane (bez cichych skoków z
queueddosucceeded). - Aktualizacje streamingu scalaj po ID/sequence, nie według „ostatnia wiadomość wygrywa”.
- Konflikty obsługuj przez
version/etaglub serwerowe reguły scalania. - PII i sekrety nigdy nie są przechowywane w stanie klienta; logi są domyślnie redagowane.
- Istnieje jedno narzędzie dashboard do debugowania: żądania, wywołania narzędzi, status zadań i błędy.
Kiedy przyjmiesz szybsze cykle budowy (w tym generację wspieraną AI), rozważ dodanie strażników wymuszających elementy z tej listy — walidację schematu, idempotentność i eventowany streaming — aby „szybkie działanie” nie zamieniło się w dryf stanu. W praktyce to miejsce, gdzie platforma end-to-end jak Koder.ai może być przydatna: przyspiesza dostarczanie, a jednocześnie pozwala eksportować kod źródłowy i zachować spójne wzorce obsługi stanu między web, backend i mobile.