23 wrz 2025·3 min
ZSTD vs Brotli vs GZIP: wybór kompresji dla API
Porównanie ZSTD, Brotli i GZIP dla API: szybkość, współczynnik kompresji, koszt CPU i praktyczne domyślne ustawienia dla JSON i binarnych payloadów w produkcji.
Porównanie ZSTD, Brotli i GZIP dla API: szybkość, współczynnik kompresji, koszt CPU i praktyczne domyślne ustawienia dla JSON i binarnych payloadów w produkcji.
Kompresja odpowiedzi API oznacza, że serwer koduje ciało odpowiedzi (często JSON) do mniejszego strumienia bajtów zanim wyśle je po sieci. Klient (przeglądarka, aplikacja mobilna, SDK lub inna usługa) potem dekompresuje. Przez HTTP negocjuje się to nagłówkami takimi jak Accept-Encoding (co klient obsługuje) i Content-Encoding (co wybrał serwer).
Kompresja przede wszystkim przynosi trzy korzyści:
Koszt jest prosty: kompresja oszczędza pasmo, ale kosztuje CPU (kompresja/dekompresja) i czasem pamięć (bufory). Czy się opłaca zależy od Twojego wąskiego gardła.
Kompresja błyszczy, gdy odpowiedzi są:
Jeśli zwracasz duże listy JSON (katalogi, wyniki wyszukiwania, analityka), kompresja często jest jednym z najprostszych usprawnień.
Kompresja zwykle źle wykorzystuje CPU, gdy odpowiedzi są:
Wybierając między ZSTD vs Brotli vs GZIP dla kompresji API, praktyczna decyzja zwykle sprowadza się do:
Reszta artykułu dotyczy balansowania tych trzech czynników dla Twojego API i wzorców ruchu.
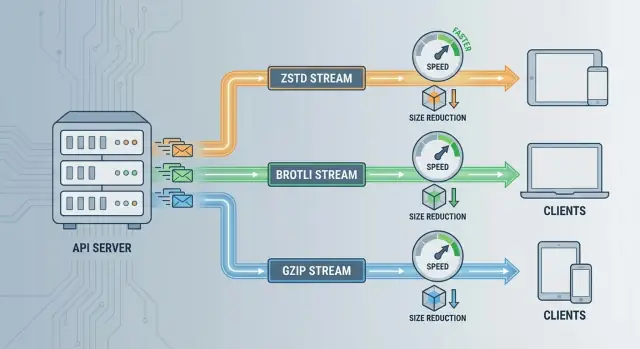
Wszystkie trzy redukują rozmiar payloadu, ale optymalizują różne rzeczy — szybkość, współczynnik kompresji i kompatybilność.
Szybkość ZSTD: Świetne, gdy API jest wrażliwe na tail latency lub serwery są obciążone CPU. Potrafi kompresować na tyle szybko, że narzut często jest znikomy względem czasu sieci — szczególnie dla średnich i dużych odpowiedzi JSON.
Współczynnik Brotli: Najlepszy, gdy pasmo jest najważniejsze (klienci mobilni, drogi egress, dostawa przez CDN) i odpowiedzi są głównie tekstowe. Mniejsze payloady mogą być warte kosztu dłuższej kompresji.
Kompatybilność GZIP: Najlepsza, gdy potrzebujesz maksymalnego wsparcia po stronie klienta bez ryzyka negocjacji (stare SDK, wbudowane urządzenia, legacy proxies). To bezpieczny baseline, nawet jeśli nie jest top‑performerem.
„Poziomy” kompresji to presety, które wymieniają czas CPU na mniejszy wynik:
Dekompressja jest zwykle znacznie tańsza niż kompresja dla wszystkich trzech, ale bardzo wysokie poziomy mogą nadal obciążać CPU klienta/baterię — ważne na urządzeniach mobilnych.
Kompresja często jest sprzedawana jako „mniejsze odpowiedzi = szybsze API”. To zwykle prawda w wolnych sieciach — ale nie automatycznie. Jeśli kompresja doda wystarczająco dużo czasu CPU po stronie serwera, możesz otrzymać wolniejsze żądania pomimo mniejszej ilości bajtów.
Pomaga rozdzielić dwa koszty:
Wysoki współczynnik kompresji może skrócić transfer, ale jeśli kompresja doda np. 15–30 ms CPU na odpowiedź, możesz stracić więcej niż zyskasz — szczególnie na szybkich połączeniach.
Pod obciążeniem kompresja może pogorszyć p95/p99 bardziej niż p50. Gdy użycie CPU rośnie, żądania są kolejkowane. Kolejkowanie wzmacnia małe koszty na żądanie w duże opóźnienia — średnia może wyglądać dobrze, ale najsłabsi użytkownicy cierpią.
Nie zgaduj. Zrób A/B test lub staged rollout i porównaj:
Testuj z realistycznymi wzorcami ruchu i payloadami. „Najlepszy” poziom to ten, który zmniejsza całkowity czas, nie tylko bajty.
Kompresja nie jest „darmowa” — przenosi pracę z sieci na CPU i pamięć po obu stronach. W API objawia się to dłuższym czasem obsługi żądania, większym użyciem pamięci i czasami spowolnieniami po stronie klienta.
Większość CPU idzie na kompresję odpowiedzi. Kompresor szuka wzorców, buduje stany/słowniki i zapisuje zakodowany wynik.
Dekompressja jest zwykle tańsza, ale nadal istotna:
Jeśli Twoje API jest już ograniczone CPU (zajęte serwery aplikacyjne, ciężkie auth, kosztowne zapytania), włączenie wysokiego poziomu kompresji może podnieść tail latency nawet przy mniejszych payloadach.
Kompresja może zwiększyć użycie pamięci przez:
W środowiskach kontenerowych wyższe szczytowe użycie pamięci może skutkować OOM‑ami lub węższą gęstością instancji.
Kompresja dodaje cykle CPU na odpowiedź, zmniejszając przepustowość na instancję. To może szybciej wywoływać autoscaling i podnosić koszty. Często obserwuje się: spadek transferu, ale wzrost zużycia CPU—dlatego właściwy wybór zależy od tego, który zasób masz ograniczony.
Na urządzeniach mobilnych dekompresja konkuruje o zasoby z renderingiem, wykonywaniem JS i baterią. Format, który oszczędza kilka KB, ale dłużej się dekompresuje, może wydawać się wolniejszy, szczególnie gdy liczy się „czas do używalnych danych”.
Zstandard (ZSTD) to nowoczesny format zaprojektowany tak, aby dawać dobry współczynnik bez spowalniania API. Dla wielu API ciężkich od JSON jest silnym „domyślnym” wyborem: zauważalnie mniejsze odpowiedzi niż GZIP przy podobnej lub niższej latencji oraz bardzo szybka dekompresja po stronie klienta.
ZSTD jest wartościowy, gdy dbasz o czas end‑to‑end, nie tylko o najmniejszą liczbę bajtów. Zazwyczaj kompresuje szybko i dekompresuje ekstremalnie szybko — przydatne tam, gdzie każdy milisekundowy koszt CPU konkuruje z obsługą żądania.
Dobrze sprawdza się dla różnych rozmiarów payloadów: małe‑średnie JSONy często zyskują, a duże odpowiedzi jeszcze bardziej.
Dla większości API zacznij od niskich poziomów (zazwyczaj 1–3). One często dają najlepszy stosunek latencji do rozmiaru.
Wyższe poziomy stosuj tylko gdy:
Pragmatyczne podejście: niski globalny default, a potem selektywne podniesienie poziomu dla kilku endpointów zwracających duże odpowiedzi.
ZSTD wspiera streaming, co może zmniejszyć szczytowe użycie pamięci i pozwolić na wcześniejsze wysyłanie danych dla dużych odpowiedzi.
Tryb słownika może przynieść duże korzyści, gdy API zwraca wiele podobnych obiektów (powtarzające się klucze, stabilne schematy). Najlepiej działa gdy:
Wsparcie po stronie serwera jest proste w wielu stackach, ale kompatybilność klienta może decydować. Niektóre HTTP clienty, proxy i bramy nadal nie deklarują ani nie akceptują Content-Encoding: zstd domyślnie.
Jeśli obsługujesz zewnętrznych konsumentów, trzymaj fallback (zwykle GZIP) i włącz ZSTD tylko gdy Accept-Encoding wyraźnie go zawiera.
Używaj kompresji, gdy odpowiedzi są bogate w tekst (JSON/GraphQL/XML/HTML), średnie do duże, a Twoi użytkownicy korzystają z wolnych/drogich sieci lub płacisz znaczące koszty egressu. Pomiń ją (lub ustaw wysoki próg) dla malutkich odpowiedzi, już skompresowanych mediów (JPEG/MP4/ZIP/PDF) oraz dla usług obciążonych CPU, gdzie dodatkowa praca na żądanie pogorszy p95/p99 latency.
Ponieważ wymienia ona szerokość pasma na CPU (i czasem pamięć). Czas kompresji może opóźnić moment, kiedy serwer zaczyna wysyłać bajty (TTFB), a pod obciążeniem zwiększa kolejki—często pogarszając tail latency nawet gdy średnia latencja się poprawia. Najlepsze ustawienie to takie, które skraca czas end‑to‑end, nie tylko liczbę bajtów.
Praktyczny priorytet dla wielu API to:
zstd najpierw (szybki, dobry stosunek)br (często najmniejsze dla tekstu, może kosztować więcej CPU)gzip (najszersza kompatybilność)Zawsze opieraj ostateczny wybór na klienta i miej bezpieczny fallback (zwykle lub ).
Zacznij od niskich poziomów i mierz.
Użyj progu minimalnego rozmiaru, żeby nie marnować CPU na malutkie payloady.
Dostrój per endpoint, porównując zaoszczędzone bajty vs dodany czas serwera i wpływ na p50/p95/p99.
Skup się na treściach, które są uporządkowane i powtarzalne:
Kompresja powinna stosować się do negocjacji HTTP:
Accept-Encoding (np. zstd, br, gzip)Content-EncodingJeśli klient nie wysyła , najbezpieczniej jest zwykle . Nigdy nie odsyłaj , którego klient nie zadeklarował, bo możesz uniemożliwić mu odczyt ciała.
Dodaj nagłówek:
Vary: Accept-EncodingTo zapobiega sytuacji, w której CDN/proxy zcache’uje np. gzip i poda go klientowi, który tego nie zażądał lub nie potrafi go dekodować (albo dla zstd/br). Jeśli obsługujesz wiele kodowań, ten nagłówek jest konieczny dla poprawnego cache’owania.
Typowe problemy produkcyjne to:
Wprowadź to jako funkcję wydajności:
Accept-EncodinggzipidentityWyższe poziomy przynoszą malejące korzyści rozmiarowe, a mogą znacząco podnieść zużycie CPU i pogorszyć p95/p99.
Często sensowne jest włączenie kompresji tylko dla typów Content-Type przypominających tekst i wyłączenie jej dla znanych, już skompresowanych formatów.
Accept-EncodingContent-EncodingContent-Encoding mówi gzip, ale ciało nie jest gzip)Accept-Encoding)Content-Length przy streamingu/kompresjiPodczas debugowania przechwyć surowe nagłówki odpowiedzi i sprawdź dekompresję za pomocą znanego, poprawnego narzędzia/klienta.
Jeśli tail latency rośnie pod obciążeniem, obniż poziom, zwiększ próg lub przejdź na szybszy kodek (często ZSTD).