21 aug. 2025·7 min
6 SQL-joinar du måste kunna (med enkla, tydliga exempel)
Lär dig de 6 SQL-join-typer varje analytiker bör kunna—INNER, LEFT, RIGHT, FULL OUTER, CROSS och SELF—med praktiska exempel och vanliga fallgropar.
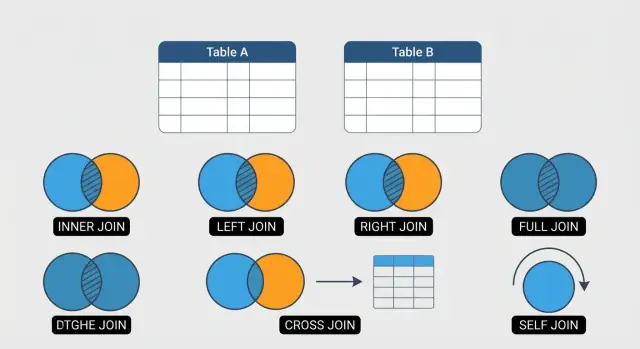
Lär dig de 6 SQL-join-typer varje analytiker bör kunna—INNER, LEFT, RIGHT, FULL OUTER, CROSS och SELF—med praktiska exempel och vanliga fallgropar.
En SQL JOIN låter dig kombinera rader från två (eller fler) tabeller till ett resultat genom att matcha dem på en relaterad kolumn—vanligtvis ett ID.
De flesta riktiga databaser är avsiktligt uppdelade i separata tabeller så att du inte upprepar samma information om och om igen. Till exempel finns en kunds namn i en customers-tabell, medan deras köp finns i en orders-tabell. JOINs är hur du återkopplar de delarna när du behöver svar.
Därför dyker JOINs upp överallt i rapportering och analys:
Utan JOINs skulle du vara tvungen att köra separata frågor och manuellt kombinera resultat—långsamt, benäget för fel och svårt att upprepa.
Om du bygger produkter ovanpå en relationsdatabas (dashboards, adminpaneler, interna verktyg, kundportaler) är JOINs också det som förvandlar “råa tabeller” till vyer som användaren ser. Plattformar som Koder.ai (som genererar React + Go + PostgreSQL-appar från chat) förlitar sig fortfarande på goda JOIN-fundament när du behöver korrekta listvyer, rapporter och rekonsilieringsskärmar—eftersom databaslogiken inte försvinner, även när utvecklingen går snabbare.
Denna guide fokuserar på sex JOINs som täcker majoriteten av dagligt SQL-arbete:
JOIN-syntaxen är mycket likartad i de flesta SQL-databaser (PostgreSQL, MySQL, SQL Server, SQLite). Det finns några skillnader—särskilt kring stöd för FULL OUTER JOIN och vissa specialfall—men koncepten och kärnmönstren överförs tydligt.
För att hålla JOIN-exemplen enkla använder vi tre små tabeller som speglar en vanlig verklig uppsättning: kunder lägger beställningar, och beställningar kan (eller kanske inte) ha betalningar.
En liten notering innan vi börjar: exempel-tabellerna nedan visar bara ett fåtal kolumner, men vissa frågor senare refererar till ytterligare fält (som order_date, created_at, status eller paid_at) för att demonstrera vanliga mönster. Behandla dessa kolumner som typiska fält du ofta har i produktionsschema.
Primary key: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
Primary key: order_id
Foreign key: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
Observera att order_id = 104 refererar till customer_id = 5, som inte finns i customers. Denna ”saknade matchning” är användbar för att se hur LEFT JOIN, RIGHT JOIN och FULL OUTER JOIN beter sig.
Primary key: payment_id
Foreign key: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
Två viktiga ”undervisnings”-detaljer här:
order_id = 102 har två payment-rader (en splitbetalning). När du joinar orders till payments visas den ordern två gånger—här överraskar dubbletter ofta.payment_id = 9004 refererar till order_id = 999, som inte finns i orders. Det skapar ett annat ”omatchat” fall.orders till payments kommer att repetera order 102 eftersom den har två relaterade betalningar.En INNER JOIN returnerar endast de rader där det finns en match i båda tabellerna. Om en kund saknar orders kommer den inte att visas i resultatet. Om en order refererar till en kund som inte finns (dåliga data) visas inte heller den ordern.
Du väljer en ”vänster” tabell, joinar en ”höger” tabell och kopplar dem med en villkor i ON-satsen.
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
Nyckelidéen är raden ON o.customer_id = c.customer_id: den berättar för SQL hur raderna hör ihop.
Om du vill ha en lista med bara de kunder som faktiskt lagt minst en order (och orderdetaljerna), är INNER JOIN naturligt:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
Detta är användbart för saker som ”skicka uppföljningsmejl för order” eller ”beräkna intäkt per kund” (när du bara bryr dig om kunder med köp).
Om du skriver en join men glömmer ON-villkoret (eller joinar på fel kolumner) kan du av misstag skapa ett Kartesiskt produkt (varje kund kombinerad med varje order) eller producera subtilt felaktiga matchningar.
Dåligt (gör inte så här):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
Se alltid till att du har ett tydligt joinvillkor i ON (eller USING i de specifika fall där det passar—det täcks senare).
En LEFT JOIN returnerar alla rader från vänster tabell, och lägger till matchande data från höger tabell när en match finns. Om det inte finns någon match kommer höger-sidans kolumner att vara NULL.
Använd en LEFT JOIN när du vill ha en komplett lista från din primära tabell, plus valfri relaterad data.
Exempel: ”Visa alla kunder, och inkludera deras orders om de har några.”
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
o.order_id (och andra orders-kolumner) blir NULL.Ett mycket vanligt skäl att använda LEFT JOIN är att hitta poster som inte har relaterade rader.
Exempel: ”Vilka kunder har aldrig lagt en order?”
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
Den där WHERE ... IS NULL-satsen behåller endast vänster-tabellens rader där joinen inte hittade någon match.
LEFT JOIN kan ”duplicera” vänster-tabellens rader när det finns flera matchande rader på höger sida.
Om en kund har 3 orders kommer den kunden att visas 3 gånger—en gång per order. Det är förväntat, men kan överraska om du försöker räkna kunder.
Till exempel räknar detta orders (inte kunder):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
Om ditt mål är att räkna kunder räknar du vanligtvis kundnyckeln istället (ofta med COUNT(DISTINCT c.customer_id)), beroende på vad du mäter.
En RIGHT JOIN behåller alla rader från höger tabell, och endast matchande rader från vänster tabell. Om det inte finns någon match visas vänster-tabellens kolumner som NULL. Det är i princip en spegelbild av en LEFT JOIN.
Med våra exempel-tabeller, tänk att du vill lista alla betalningar, även om de inte kan kopplas till en order (kanske är ordern borttagen eller betalningsdata är rörig).
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
Vad du får:
payments är på höger sida).o.order_id och o.customer_id NULL.I de flesta fall kan du skriva om en RIGHT JOIN som en LEFT JOIN genom att byta tabellordning:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
Detta returnerar samma resultat, men många tycker det är lättare att läsa: du börjar med den ”huvud”-tabell du bryr dig om (här payments) och drar sedan in relaterad data valfritt.
Många SQL-stilguider avråder från RIGHT JOIN eftersom det tvingar läsaren att mentalt vända på det vanliga mönstret:
När valfria relationer konsekvent skrivs som LEFT JOIN blir frågor lättare att skumma igenom.
En RIGHT JOIN kan vara praktisk när du redigerar en befintlig fråga och inser att den tabell du måste behålla står till höger. Istället för att skriva om hela frågan (särskilt en lång med flera joins) kan det vara snabbt och låg-risk att byta en join till RIGHT JOIN.
En FULL OUTER JOIN returnerar alla rader från båda tabellerna.
INNER JOIN).NULL för höger tabells kolumner.NULL för vänster tabells kolumner.Ett klassiskt affärsfall är rekonsiliering orders vs. payments:
Exempel:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
FULL OUTER JOIN stöds i PostgreSQL, SQL Server och Oracle.
Det är inte tillgängligt i MySQL och SQLite (då behöver du en work-around).
Om din databas inte stöder FULL OUTER JOIN kan du simulera det genom att kombinera:
orders (med matchande payments när det finns), ochpayments som inte matchade en order.Ett vanligt mönster:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
Tips: när du ser NULL på ena sidan är det din signal att raden saknades i den andra tabellen — precis vad du vill för revisioner och rekonsiliering.
En CROSS JOIN returnerar varje möjlig parning av rader från två tabeller. Om tabell A har 3 rader och tabell B har 4 rader, kommer resultatet att ha 3 × 4 = 12 rader. Detta kallas också en kartesisk produkt.
Det låter skrämmande—och det kan vara det—men det är verkligen användbart när du vill generera kombinationer.
Anta att du håller produktalternativ i separata tabeller:
sizes: S, M, Lcolors: Red, BlueEn CROSS JOIN kan generera alla varianter (användbart för att skapa SKUs, förbygga en katalog eller testning):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
Resultat (3 × 2 = 6 rader):
Eftersom rader multipliceras kan CROSS JOIN explodera snabbt:
Det kan sakta ner frågor, överväldiga minne och producera ett resultat som ingen kan använda. Om du behöver kombinationer, håll ingångstabellerna små och överväg att lägga till gränser eller filter på ett kontrollerat sätt.
En SELF JOIN är precis vad det låter som: du joinar en tabell mot sig själv. Detta är användbart när en rad i en tabell relaterar till en annan rad i samma tabell—oftast i ”parent/child”-relationer som employees och deras chefer.
Eftersom du använder samma tabell två gånger måste du ge varje ”kopia” ett annat alias. Alias gör frågan läsbar och talar om för SQL vilken sida du menar.
Ett vanligt mönster är:
e för employeem för managerFöreställ dig en employees-tabell med:
idnamemanager_id (pekar på en annan anställds id)För att lista varje anställd med sin chefs namn:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
Notera att frågan använder en LEFT JOIN, inte en INNER JOIN. Det spelar roll eftersom vissa anställda kanske inte har någon chef (till exempel VD). I de fallen är manager_id ofta NULL, och en LEFT JOIN behåller anställd-raden samtidigt som manager_name blir NULL.
Om du istället använde en INNER JOIN skulle dessa toppnivåanställda försvinna från resultatet eftersom det inte finns någon matchande chef att joina mot.
En JOIN vet inte ”magiskt” hur två tabeller hör ihop—du måste tala om det. Den relationen definieras i joinvillkoret, och det hör hemma intill JOIN eftersom det förklarar hur tabellerna matchar, inte hur du vill filtrera slutresultatet.
ON: mest flexibelt (och vanligast)Använd ON när du vill ha full kontroll över matchningslogiken—olika kolumnnamn, flera villkor eller extra regler.
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON är också där du kan definiera mer komplexa matchningar (t.ex. matchning på två kolumner) utan att göra frågan till en gissningslek.
USING: kortare, men bara för kolumner med samma namnVissa databaser (som PostgreSQL och MySQL) stödjer USING. Det är en praktisk genväg när båda tabellerna har en kolumn med samma namn och du vill joina på den kolumnen.
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
En fördel: USING returnerar typiskt bara en customer_id-kolumn i utskriften (istället för två kopior).
När du joinar tabeller överlappar ofta kolumnnamn (id, created_at, status). Om du skriver SELECT id kan databasen kasta ett ”ambiguous column”-fel—eller värre, du kan av misstag läsa fel id.
Föredra tabellprefix (eller alias) för tydlighet:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
SELECT * i joined queriesSELECT * blir rörigt snabbt med joins: du drar in onödiga kolumner, riskerar dubbletter av kolumnnamn och gör det svårare att se vad frågan faktiskt ska producera.
Välj istället de exakta kolumner du behöver. Resultatet blir renare, lättare att underhålla och ofta mer effektivt—särskilt när tabellerna är breda.
När du joinar tabeller så ”filtrerar” både WHERE och ON, men de gör det vid olika tidpunkter.
Denna tidsskillnad är anledningen till att folk av misstag gör en LEFT JOIN till en INNER JOIN.
Säg att du vill ha alla kunder, även de utan nyligen betalda orders.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Problem: för kunder utan matchande order är o.status och o.order_date NULL. WHERE-satsen väljer bort dessa rader, så de omatchade kunderna försvinner—din LEFT JOIN beter sig som en INNER JOIN.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Nu visas kunder utan kvalificerande orders fortfarande (med NULL i orderkolumnerna), vilket oftast är poängen med en LEFT JOIN.
WHERE o.order_id IS NOT NULL uttryckligen).Joins lägger inte bara till kolumner—de kan också multiplicera rader. Det är oftast korrekt beteende, men överraskar ofta när totalsummor plötsligt blir dubbla (eller värre).
En join returnerar en output-rad för varje par av matchande rader.
customers till orders kan varje kund synas flera gånger—en gång per order.orders till payments och varje order kan ha flera betalningar, kan du få flera rader per order. Om du dessutom joinar mot en annan ”many”-tabell (som order_items) kan du skapa en multiplikationseffekt: payments × items per order.Om målet är ”en rad per kund” eller ”en rad per order”, summera den many-sidan först, och joina sedan.
-- En rad per order från payments
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
Detta håller joinens ”form” förutsägbar: en order-rad förblir en order-rad.
SELECT DISTINCT kan få dubbletter att verka lösta, men det kan dölja det verkliga problemet:
Använd det bara när du är säker på att dubbletterna är rent oavsiktliga och du förstår varför de uppstod.
Innan du litar på resultat, jämför raderna:
JOINs får ofta skulden för ”långsamma frågor”, men den verkliga orsaken är vanligtvis hur mycket data du ber databasen kombinera och hur lätt den kan hitta matchande rader.
Tänk på ett index som en boks innehållsförteckning. Utan det kan databasen behöva skanna många rader för att hitta matchningar för ditt JOIN-villkor. Med ett index på join-nyckeln (t.ex. customers.customer_id och orders.customer_id) kan databasen hoppa till relevanta rader mycket snabbare.
Du behöver inte känna intern detaljer för att använda detta väl: om en kolumn ofta används för att matcha rader (ON a.id = b.a_id) är det en bra kandidat för indexering.
När det är möjligt, joina på stabila, unika identifierare:
customers.customer_id = orders.customer_idcustomers.email = orders.email eller customers.name = orders.nameNamn ändras och kan upprepas. E-post kan ändras, saknas eller skilja sig i skiftläge/format. IDs är designade för konsekvent matchning och är ofta indexerade.
Två vanor gör JOINs märkbart snabbare:
SELECT * när du joinar flera tabeller—extra kolumner ökar minne och nätverkstrafik.Exempel: begränsa orders först, och joina sedan:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
Om du itererar på dessa frågor inne i en app-build (t.ex. för att skapa en rapportsida mot PostgreSQL) kan verktyg som Koder.ai snabba upp scaffoldingen—schema, endpoints, UI—medan du behåller kontroll över JOIN-logiken som avgör korrektheten.
NULL)NULL när saknas)NULLEn SQL JOIN kombinerar rader från två (eller fler) tabeller till ett resultatset genom att matcha relaterade kolumner—oftast en primärnyckel mot en främmande nyckel (till exempel customers.customer_id = orders.customer_id). På så vis ”återkopplar” du normaliserade tabeller när du behöver rapporter, revisioner eller analyser.
Använd INNER JOIN när du endast vill ha rader där relationen finns i båda tabellerna.
Det är idealiskt för ”bekräftade relationer”, till exempel att lista bara de kunder som faktiskt gjort köp.
Använd LEFT JOIN när du behöver alla rader från din huvudtabell (vänster), plus valfri matchande data från höger tabell.
För att hitta ”saknade matchningar”, joina och filtrera sedan höger sida till NULL:
c.customer_id, c.name
customers c
orders o o.customer_id c.customer_id
o.order_id ;
RIGHT JOIN behåller varje rad från höger tabell och fyller vänsterkolumnerna med NULL när det inte finns någon match. Många team undviker det eftersom det läses ”baklänges”.
I de flesta fall kan du skriva om det som en LEFT JOIN genom att byta tabellordning:
FROM payments p
LEFT orders o o.order_id p.order_id
Använd FULL OUTER JOIN för rekonsiliering: du vill ha träffar, vänster-enda rader och höger-enda rader i samma resultat.
Det är utmärkt för revisioner som ”orders utan payments” och ”payments utan orders”, eftersom den icke-matchede sidan visas som NULL.
Vissa databaser (notera MySQL och SQLite) stödjer inte FULL OUTER JOIN direkt. Ett vanligt alternativ är att kombinera två frågor:
orders LEFT JOIN paymentsDetta görs ofta med UNION (eller UNION ALL med försiktig filtrering) så att både ”vänster-enda” och ”höger-enda” poster behålls.
En CROSS JOIN returnerar varje kombination av rader mellan två tabeller (en kartesisk produkt). Den är användbar för att generera scenarier (t.ex. sizes × colors) eller bygga en kalendergrid.
Var försiktig: radantalet multipliceras snabbt, så använd den bara när ingångstabellerna är små och kontrollerade.
En self join är att joina en tabell mot sig själv för att relatera rader inom samma tabell (vanligt för hierarkier som employee → manager).
Du måste använda alias för att särskilja de två ”kopiorna”:
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
ON definierar hur rader matchas under joinen; WHERE filtrerar efter att joinen bildats. Med en LEFT JOIN kan en WHERE-sats som refererar till höger-tabellen ta bort NULL-matchningar och göra att den beter sig som en INNER JOIN.
Om du vill behålla alla vänster-rader men begränsa vilka höger-rader som får matcha, lägg höger-tabellens filter i istället.
Joins kan multiplicera rader när relationen är one-to-many eller many-to-many. Till exempel kommer en order med två betalningar att visas två gånger när du joinar orders med payments.
För att behålla ”en rad per order/kund”, aggregera den many-sidan först (t.ex. SUM(amount) grupperat per order_id) och joina sedan. Använd DISTINCT endast som sista utväg eftersom det kan dölja verkliga problem och ge felaktiga totaler.
ON