15 juni 2025·8 min
Att låta AI designa backend-scheman, API:er och datamodeller
Utforska hur AI-genererade scheman och API:er snabbar upp leverans, var de brister och en praktisk arbetsrutin för att granska, testa och styra backend-design.
Utforska hur AI-genererade scheman och API:er snabbar upp leverans, var de brister och en praktisk arbetsrutin för att granska, testa och styra backend-design.
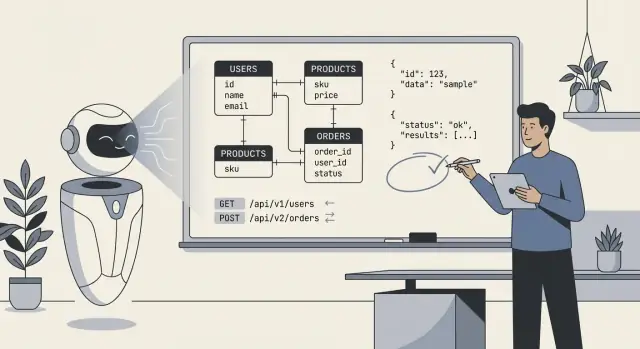
När folk säger “AI designade vår backend” menar de oftast att modellen tog fram ett första utkast till den tekniska blåkopian: databastabeller (eller collections), hur de delarna hänger ihop och API:erna som läser och skriver data. I praktiken är det mindre "AI byggde allt" och mer "AI föreslog en struktur vi kan implementera och förfina."
Minst kan AI generera:
users, orders, subscriptions, plus fält och grundläggande typer.AI kan härleda "typiska" mönster, men den kan inte pålitligt välja den rätta modellen när kraven är oklara eller domänspecifika. Den kommer inte veta dina verkliga policies för:
cancelled vs refunded vs voided).Behandla AI-output som en snabb, strukturerad startpunkt—användbar för att utforska alternativ och hitta utelämnanden—men inte som en spec du kan leverera oförändrad. Din roll är att tillföra tydliga regler och edge cases, och sedan granska det AI producerat på samma sätt som du skulle granska en junioringenjörs första utkast: hjälpsamt, ibland imponerande, ibland subtilt felaktigt.
AI kan skissa ett schema eller API snabbt, men den kan inte uppfinna de saknade fakta som får en backend att "passa" din produkt. De bästa resultaten uppstår när du behandlar AI som en snabb juniordesigner: du ger tydliga begränsningar och den föreslår alternativ.
Innan du ber om tabeller, endpoints eller modeller, skriv ner det väsentliga:
När kraven är vaga tenderar AI att "gissa" standarder: valfria fält överallt, generiska statuskolumner, otydligt ägarskap och inkonsekvent namngivning. Det leder ofta till scheman som ser rimliga ut men som går sönder under verklig användning—särskilt kring behörigheter, rapportering och edge cases (refunds, cancellations, delleveranser, flerstegs-godkännanden). Du får betala för det senare med migrationer, workarounds och förvirrande API:er.
Använd detta som startpunkt och klistra in i din prompt:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
AI är som bäst när du behandlar den som en snabb utkastsmaskin: den kan skissa en rimlig första datamodell och en matchande mängd endpoints på några minuter. Den här hastigheten förändrar hur du arbetar—inte för att outputen är magiskt "korrekt", utan för att du kan iterera på något konkret direkt.
Den största vinsten är att eliminera kalla starten. Ge AI en kort beskrivning av entiteter, nyckelflöden och begränsningar, så kan den föreslå tabeller/collections, relationer och en bas-API-yta. Detta är särskilt värdefullt när du behöver en demo snabbt eller utforskar krav som inte är stabila ännu.
Hastigheten lönar sig mest vid:
Människor blir trötta och driver. AI gör inte det—så den är fantastisk på att upprepa konventioner över hela backend:
createdAt, updatedAt, customerId)/resources, /resources/:id) och payloadsDenna konsekvens gör din backend enklare att dokumentera, testa och överlämna till en annan utvecklare.
AI är också bra på fullständighet. Om du ber om ett komplett CRUD-set plus vanliga operationer (sök, lista, bulk-uppdateringar) kommer den oftast att generera en mer omfattande startyta än ett stressat mänskligt utkast.
En vanlig snabbvinst är standardiserade fel: en enhetlig error-envelope (code, message, details) över endpoints. Även om du senare förfinar den, förhindrar en enhetlig form en rörig blandning av ad-hoc-responser.
Nyckelinställningen: låt AI producera de första 80 % snabbt, spendera sedan resten av tiden på de 20 % som kräver omdöme—affärsregler, edge cases och "varför" bakom modellen.
AI-genererade scheman ser ofta "rena" ut vid första anblick: prydliga tabeller, rimliga namn och relationer som matchar happy path. Problemen visar sig vanligtvis när verkliga data, användare och arbetsflöden träffar systemet.
AI kan svänga mellan ytterligheter:
Ett snabbt lukttest: om dina vanligaste sidor behöver 6+ joins kan du vara över-normaliserad; om uppdateringar kräver att samma värde ändras i många rader kan du vara under-normaliserad.
AI utelämnar ofta "tråkiga" krav som styr verklig backend-design:
AI kan anta felaktigt:
Dessa fel dyker upp som besvärliga migrationer och applikationssidos-lösningar.
De flesta genererade scheman reflekterar inte hur du kommer att fråga:
Om modellen inte kan beskriva de 5 viktigaste frågorna din app kör, kan den inte pålitligt designa schemat för dem.
AI är ofta överraskande bra på att ta fram ett API som "ser standard ut." Den speglar bekanta mönster från populära ramverk och publika API:er, vilket kan spara mycket tid. Risken är att den optimerar för vad som ser sannolikt ut snarare än vad som är rätt för din produkt, din datamodell och framtida förändringar.
Resursmodelleringens grunder. Givet ett tydligt domänval väljer AI rimliga substantiv och URL-strukturer (t.ex. /customers, /orders/{id}, /orders/{id}/items). Den är också bra på att upprepa konsekventa namngivningskonventioner över endpoints.
Vanligt endpoint-scaffolding. AI inkluderar ofta det väsentliga: lista vs detalj-endpoints, skapa/uppdatera/ta bort-operationer och förutsägbara request/response-former.
Baslinjekonventioner. Om du ber uttryckligen kan den standardisera paginering, filtrering och sortering. Till exempel: ?limit=50\u0026cursor=... (cursor-paginering) eller ?page=2\u0026pageSize=25 (sidsbaserad), plus ?sort=-createdAt och filter som ?status=active.
Läckande abstraktioner. Ett klassiskt fel är att exponera interna tabeller direkt som “resources,” särskilt när schemat har join-tabeller, denormaliserade fält eller auditkolumner. Du får endpoints som /user_role_assignments som speglar implementationsdetaljer snarare än det användarorienterade konceptet ("roller för en användare"). Det gör API:t svårare att använda och svårare att ändra senare.
Inkonsekvent felhantering. AI kan blanda stilar: ibland returnera 200 med en error-body, ibland använda 4xx/5xx. Du vill ha ett klart kontrakt:
400, 401, 403, 404, 409, 422){ "error": { "code": "...", "message": "...", "details": [...] } })Versionering som eftertanke. Många AI-genererade designer hoppar över en versioneringsstrategi tills det gör ont. Bestäm från dag ett om du använder path-versionering (/v1/...) eller header-baserad versionering, och definiera vad som utgör en breaking change. Även om du aldrig uppdaterar versionen, förhindrar tydliga regler oavsiktliga brott.
Använd AI för hastighet och konsekvens, men behandla API-design som ett produktgränssnitt. Om en endpoint speglar din databas istället för användarens mentala modell, är det en indikation på att AI optimerade för enkel generering—inte för långsiktig användbarhet.
Behandla AI som en snabb juniordesigner: utmärkt på att producera utkast, inte ansvarig för slutgiltigt system. Målet är att använda dess hastighet samtidigt som du håller arkitekturen avsiktlig, granskbar och testdriven.
Om du använder ett vibe-coding-verktyg som Koder.ai blir denna ansvarsseparation ännu viktigare: plattformen kan snabbt skissa och implementera en backend (t.ex. Go-tjänster med PostgreSQL), men du måste fortfarande definiera invariants, auktoriseringsgränser och migrationsregler du kan leva med.
Börja med en koncentrerad prompt som beskriver domänen, begränsningarna och "vad som räknas som framgång." Be om en konceptuell modell först (entiteter, relationer, invariants), inte tabeller.
Iterera sedan i en fast loop:
Denna loop fungerar eftersom den förvandlar "AI-förslag" till artefakter som kan bevisas eller förkastas.
Behåll tre lager distinkta:
Be AI att leverera dessa som separata sektioner. När något ändras (t.ex. en ny status eller regel) uppdaterar du det konceptuella lagret först och förenar sedan schema och API. Det minskar oavsiktlig koppling och gör refaktorer mindre smärtsamma.
Varje iteration bör lämna ett spår. Använd korta, ADR-liknande sammanfattningar (en sida eller mindre) som fångar:
deleted_at").När du klistrar feedback tillbaka till AI, inkludera relevanta beslutstexter verbatim. Det förhindrar att modellen "glömmer" tidigare val och hjälper ditt team att förstå backend månader senare.
AI är lättast att styra när du behandlar prompting som en spec-skrivningsövning: definiera domänen, ange begränsningar och insistera på konkreta leverabler (DDL, endpoint-tabeller, exempel). Målet är inte "vara kreativ"—det är "vara precis."
Be om en datamodell och reglerna som håller den konsekvent.
Om du redan har konventioner, säg det: namngivningsstil, ID-typ (UUID vs bigint), nullable-policy och indexeringsförväntningar.
Be om en API-tabell med explicita kontrakt, inte bara en lista med rutter.
Lägg till affärsbeteende: pagineringsstil, sorteringsfält och hur filtrering fungerar.
Få modellen att tänka i releaser.
billing_address till Customer. Ge en säker migrationsplan: forward migration SQL, backfill-steg, feature-flag-rollout och rollback-strategi. API måste vara kompatibelt i 30 dagar; gamla klienter kan utelämna fältet."Vaga prompts ger vaga system.
När du vill ha bättre output, skärp prompten: specificera reglerna, edge-cases och formatet på leverabeln.
AI kan skissa en hyfsad backend, men att släppa det säkert kräver fortfarande en mänsklig genomgång. Behandla denna checklista som en "release-gate": om du inte kan svara säkert på en punkt, pausa och åtgärda innan det blir produktdata.
(tenant_id, slug))._id-suffixer, tidsstämplar) och tillämpa dem enhetligt.Bekräfta systemets regler skriftligt:
Innan merge, kör en snabb "happy path + worst path"-granskning: en normal begäran, en ogiltig begäran, en obehörig begäran, ett högvolymsscenario. Om API:ts beteende överraskar dig, kommer det också att överraska dina användare.
AI kan generera ett plausibelt schema och API-yta snabbt, men den kan inte bevisa att backend fungerar korrekt under verklig trafik, verkliga data och framtida förändringar. Behandla AI-output som ett utkast och förankra det med tester som låser beteendet.
Börja med kontraktstester som validerar requests, responses och error-semantik—inte bara "happy paths." Bygg en liten svit som körs mot en verklig instans (eller container) av tjänsten.
Fokusera på:
Om du publicerar ett OpenAPI-spec, generera tester från det—lägg även till handskrivna fall för de svåra delarna som spec:en inte kan uttrycka (auktoriseringsregler, affärsconstraints).
AI-genererade scheman missar ofta operationella detaljer: säkra standarder, backfills och reversibilitet. Lägg till migrationstester som:
Behåll en skriptad rollback-plan för produktion: vad gör du om en migration är långsam, låser tabeller eller bryter kompatibilitet.
Benchmarka inte generiska endpoints. Fånga representativa query-mönster (topp-listvyer, sök, joins, aggregation) och load-testa dem.
Mät:
Här faller AI-design ofta isär: "rimliga" tabeller som ger dyra joins under belastning.
Lägg till automatiska kontroller för:
Även grundläggande säkerhetstester förhindrar den mest kostsamma klassen av AI-misstag: endpoints som fungerar men exponerar för mycket.
AI kan skissa ett bra "version 0"-schema, men din backend lever genom version 50. Skillnaden mellan en backend som åldras väl och en som kollapsar under förändring är hur du utvecklar den: migrationer, kontrollerade refaktorer och tydlig dokumentation av avsikt.
Behandla varje schemaändring som en migration, även om AI föreslår "ändra tabellen direkt." Använd explicita, reversibla steg: lägg till nya kolumner först, backfilla, och tajta sedan constraints. Föredra additiva ändringar (nya fält, nya tabeller) framför destruktiva (byt namn/drop) tills du bevisat att inget beror på det gamla formatet.
När du ber AI om schemauppdateringar, inkludera det nuvarande schemat och migrationsreglerna ni följer (t.ex. "inga kolumner får tas bort; använd expand/contract"). Det minskar risken att den föreslår en ändring som är teoretiskt korrekt men riskfylld i produktion.
Breaking changes är sällan ett ögonblick; det är en övergång.
AI kan hjälpa till att ta fram steg-för-steg-planen (inklusive SQL-snippets och rullningsordning), men du bör validera runtime-påverkan: låsningar, långkörande transaktioner och om backfill kan återupptas.
Refaktorer bör syfta till att isolera ändringar. Om du behöver normalisera, dela en tabell eller införa en event-logg, behåll kompatibilitetslager: vyer, översättningskod eller "shadow"-tabeller. Be AI att föreslå en refaktor som bevarar existerande API-kontrakt och lista vad som måste ändras i queries, index och constraints.
De flesta långa driftsdriftproblem uppstår för att nästa prompt glömmer ursprunglig avsikt. Håll ett kort "data model contract"-dokument: namngivningsregler, ID-strategi, tidsstämdemantik, soft-delete-policy och invariants ("en order total härleds, inte sparas"). Länka det i era interna docs (t.ex., /docs/data-model) och återanvänd det i framtida AI-prompter så systemet designas inom samma gränser.
AI kan skissa tabeller och endpoints snabbt, men den "äger" inte din risk. Behandla säkerhet och integritet som förstklassiga krav du lägger in i prompten, och verifiera sedan i granskning—särskilt kring känslig data.
Innan du accepterar något schema, märk fält efter känslighet (public, internal, confidential, regulated). Den klassificeringen bör styra vad som krypteras, maskas eller minimeras.
Till exempel: lösenord ska aldrig sparas i klartext (endast saltade hashes), tokens bör vara kortlivade och krypterade i vila, och PII som e-post/telefon kan behöva maskeras i admin-vyer och exporter. Om ett fält inte behövs för produktvärde, spara det inte—AI lägger ofta till "trevliga att ha"-attribut som ökar exponeringen.
AI-genererade API:er standardiserar ofta på enkla "rollchecks." Role-based access control (RBAC) är lätt att resonera kring men brister vid ägarskapsregler ("användare kan bara se sina fakturor") eller kontextregler ("support får se data bara under ett aktivt ticket"). Attribute-based access control (ABAC) hanterar dessa bättre men kräver explicita policies.
Var tydlig om mönstret ni använder och säkerställ att varje endpoint upprätthåller det konsekvent—särskilt list-/sök-endpoints som är vanliga läckagepunkter.
Genererad kod kan logga fulla request-bodies, headers eller databasrader vid fel. Det kan läcka lösenord, auth-tokens och PII till loggar och APM-verktyg.
Sätt standarder som: strukturerade loggar, allowlistade fält att logga, redigera hemligheter (Authorization, cookies, reset tokens), och undvik att logga råa payloads vid valideringsfel.
Designa för radering från dag ett: användarraderingar, kontostängning och "right to be forgotten"-flöden. Definiera retention-fönster per dataklass (t.ex. audit-händelser vs marknadsföringshändelser) och se till att du kan bevisa vad som raderats och när.
Om du behåller auditloggar, lagra minimala identifierare, skydda dem med striktare åtkomst och dokumentera hur man exporterar eller raderar data när det krävs.
AI är som bäst när du behandlar den som en snabb juniorarkitekt: bra på att producera ett första utkast, svagare på att göra domänkritiska avvägningar. Rätt fråga är mindre "Kan AI designa min backend?" och mer "Vilka delar kan AI skissa säkert, och vilka kräver expertans?"
AI kan spara verklig tid när du bygger:
Här är AI värdefull för hastighet, konsekvens och täckning—särskilt när du redan vet hur produkten ska bete sig och kan upptäcka fel.
Var försiktig (eller använd AI endast som inspiration) när du arbetar inom:
I dessa områden överväger domänexpertis AI-hastighet. Subtila krav—juridiska, kliniska, bokföringsmässiga—finns ofta inte i prompten, och AI fyller luckor med säker ton.
En praktisk regel: låt AI föreslå alternativ, men kräva en slutlig granskning för datamodell-invariants, auktoriseringsgränser och migrationsstrategi. Om du inte kan säga vem som är ansvarig för schemat och API-kontrakten, skicka inte en AI-designad backend till produktion.
Om du utvärderar arbetsflöden och styrregler, se relaterade guider i /blog. Om du vill hjälp att tillämpa dessa rutiner i ditt teams process, kolla /pricing.
Om du föredrar ett end-to-end-arbetsflöde där du kan iterera via chatt, generera en fungerande app och ändå behålla kontroll genom källkodsexport och rollback-vänliga snapshots, är Koder.ai designat för just den stilen av bygg-och-granska-loop.
Det betyder oftast att modellen genererade ett första utkast av:
Ett mänskligt team måste fortfarande validera affärsregler, säkerhetsgränser, queryprestanda och migrationssäkerhet innan det går i produktion.
Ge AI konkreta inputs som den inte säkert kan gissa:
Ju tydligare begränsningarna är, desto mindre kommer AI att fylla i luckor med sköra standardval.
Börja med en konceptuell modell (affärskoncept + invariants), och härleda sedan:
Att hålla dessa lager separata gör det enklare att ändra lagringen utan att bryta API:t — eller att revidera API:t utan att av misstag korrupta affärsregler.
Vanliga problem inkluderar:
tenant_id och sammansatta unika constraints)deleted_at)Be AI designa runt dina topp-querys och verifiera sedan:
tenant_id + created_at)Om du inte kan lista de fem viktigaste querys/endpoints, behandla alla indexplaner som ofullständiga.
AI är bra på standard-scaffolding, men se upp med:
200 med fel, inkonsekvent 4xx/5xx)Behandla API:t som ett produktgränssnitt: modellera endpoints kring användarkoncept, inte databasens implementation.
Använd en upprepad loop:
Använd konsekventa HTTP-koder och ett enda error-envelope, till exempel:
Prioritera tester som låser beteende:
Tester är hur du "äger" designen istället för att ärva AIs antaganden.
Använd AI främst för utkast när mönstren är väldefinierade (CRUD-MVP:er, interna verktyg). Var försiktig när:
En bra policy: AI får föreslå alternativ, men människor måste godkänna schema-invariants, auktorisering och rollout/migrationsstrategi.
Ett schema kan se "rent" ut men ändå misslyckas under verkliga arbetsflöden och belastning.
Detta gör AI-output till artefakter du kan bevisa eller förkasta istället för att lita på prosa.
400, 401, 403, 404, 409, 422, 429{"error":{"code":"...","message":"...","details":[...]}}
Se också till att felmeddelanden inte läcker interna detaljer (SQL, stacktraces, secrets) och håll formen konsekvent över alla endpoints.