29 okt. 2025·8 min
En AI-genererad kodbas för webb, mobil och API:er
Se hur en enda AI-genererad kodbas kan driva webbappar, mobilappar och API:er med delad logik, konsekventa datamodeller och säkrare releaser.
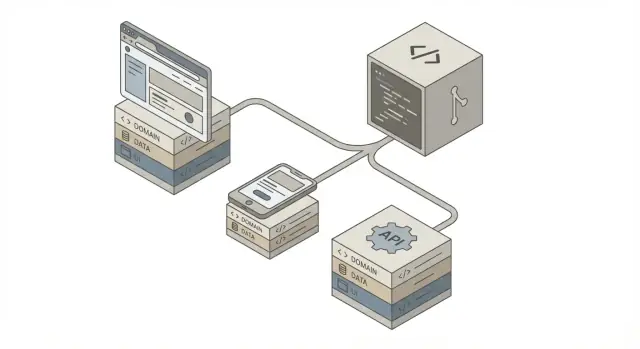
Se hur en enda AI-genererad kodbas kan driva webbappar, mobilappar och API:er med delad logik, konsekventa datamodeller och säkrare releaser.
”En kodbas” betyder sällan en UI som körs överallt. I praktiken betyder det oftast ett arkiv och en uppsättning delade regler — med separata leveransytor (webbapp, mobilapp, API) som alla förlitar sig på samma underliggande affärsbeslut.
Ett användbart mentalmodell är att dela de delar som aldrig bör motsäga varandra:
Samtidigt delar du vanligtvis inte UI-lagret rakt av. Webb och mobil har olika navigationsmönster, tillgänglighetsförväntningar, prestandakrav och plattformsfunktioner. Att dela UI kan vara en vinst i vissa fall, men det är inte definitionen av “en kodbas.”
AI-genererad kod kan dramatiskt snabba upp:
Men AI producerar inte automatiskt en koherent arkitektur. Utan tydliga gränser tenderar den att duplicera logik över appar, blanda ansvarsområden (UI som anropar databaslogik direkt) och skapa “nästan samma” valideringar på flera ställen. Vinsten kommer från att definiera strukturen först — och sedan använda AI för att fylla i repetitiva delar.
En AI-assisterad enad kodbas lyckas när den levererar:
En enad kodbas fungerar bara när du är tydlig med vad den måste uppnå — och vad den inte ska försöka standardisera. Webb, mobil och API tjänar olika användare och användningsmönster, även när de delar samma affärsregler.
De flesta produkter har minst tre “entréer”:
Målet är konsistens i beteende (regler, behörigheter, beräkningar) — inte identiska upplevelser.
Ett vanligt fel är att tolka “en kodbas” som “en UI”. Det ger ofta en webb-liknande mobilapp eller en mobil-liknande webbapp — båda frustrerande.
Sikta istället på:
Offline-läge: Mobil behöver ofta läsa (och ibland skriva) utan nätverk. Det innebär lokal lagring, synkstrategier, konflikt-hantering och tydliga regler för “sanningskälla”.
Prestanda: Webb bryr sig om bundle-storlek och time-to-interactive; mobil om uppstartstid och nätverkseffektivitet; API om latens och genomströmning. Att dela kod ska inte betyda att onödiga moduler skickas till alla klienter.
Säkerhet och compliance: Autentisering, auktorisering, audit-loggar, kryptering och datalagring måste vara konsekventa över alla ytor. I reglerade miljöer, bygg in krav som loggning, samtycke och principen om minsta privilegium från början — inte som efterhandskonstruktioner.
En enad kodbas fungerar bäst när den är organiserad i tydliga lager med strikta ansvarsområden. Den strukturen gör också AI-genererad kod lättare att granska, testa och ersätta utan att bryta orelaterade delar.
Här är formen de flesta team konvergerar mot:
Clients (Web / Mobile / Partners)
↓
API Layer
↓
Domain Layer
↓
Data Sources (DB / Cache / External APIs)
Nyckelidén: användargränssnitt och transportdetaljer sitter i kanterna, medan affärsreglerna är i mitten.
Den “delbara kärnan” är allt som ska bete sig likadant överallt:
När AI genererar nya funktioner är bästa utfallet: den uppdaterar domänreglerna en gång, och alla klienter gynnas automatiskt.
Vissa delar är dyra (eller riskfyllda) att tvinga in i en gemensam abstraktion:
En praktisk regel: om användaren kan se det eller operativsystemet kan bryta det, håll det app-specifikt. Om det är ett affärsbeslut, håll det i domänen.
Det delade domänlagret är den del av kodbasen som bör kännas “tråkig” på ett bra sätt: förutsägbar, testbar och återanvändbar överallt. Om AI hjälper till att generera systemet är detta lagret där du förankrar projektets mening — så webbsidor, mobilflöden och API-endpoints alla speglar samma regler.
Definiera produktens kärnkoncept som entities (ting med identitet över tid, som Account, Order, Subscription) och value objects (värden som definieras av sitt värde, som Money, EmailAddress, DateRange). Fånga sedan beteende som use cases (ibland kallade application services): “Create order”, “Cancel subscription”, “Change email”.
Denna struktur håller domänen begriplig för icke-specialister: substantiv beskriver vad som finns, verb beskriver vad systemet gör.
Affärslogik ska inte veta om den triggas av ett knapptryck, ett webbformulär eller ett API-anrop. Praktiskt innebär det:
När AI genererar kod är det lätt att förlora denna separation — modeller fylls med UI-angelägenheter. Se det som en refaktor-trigger när det händer.
Validering är där produkter ofta driver isär: webben tillåter något som API:t avvisar, eller mobil validerar annorlunda. Lägg konsekvent validering i domänlagret (eller en delad valideringsmodul) så alla ytor tillämpar samma regler.
Exempel:
EmailAddress validerar format en gång, återanvänds över web/mobile/APIMoney förhindrar negativa totalsummor, oavsett var värdet kommer ifrånOm du gör detta väl blir API-lagret en översättare och web/mobile blir presentatörer — medan domänlagret förblir den enda sanningskällan.
API-lagret är systemets “offentliga ansikte” — och i en AI-genererad enad kodbas bör det vara den del som förankrar allt annat. Om kontraktet är tydligt kan webbappen, mobilappen och till och med interna tjänster genereras och valideras mot samma sanningskälla.
Definiera kontraktet innan du genererar handlers eller UI-wiring:
/users, /orders/{id}), förutsägbar filtrering och sortering./v1/... eller header-baserat) och dokumentera deprecationsrutiner.Använd OpenAPI (eller ett schema-centrerat verktyg som GraphQL SDL) som det kanoniska artefaktet. Generera därifrån:
Detta är viktigt för AI-genererad kod: modellen kan skapa mycket kod snabbt, men schemat håller den i linje.
Sätt några icke-förhandlingsbara regler:
snake_case eller camelCase, inte båda; matcha mellan JSON och genererade typer.Idempotency-Key för riskfyllda operationer (betalningar, order-skapande) och definiera retry-beteende.Behandla API-kontraktet som en produkt. När det är stabilt blir allt annat enklare att generera, testa och leverera.
En webbapp tjänar mycket på delad affärslogik — och lider när den logiken trasslas ihop med UI-angelägenheter. Nyckeln är att behandla det delade domänlagret som en “headless” motor: det känner reglerna, valideringarna och arbetsflödena, men inget om komponenter, routes eller browser-API:er.
Om du använder SSR (server-side rendering) måste delad kod vara säker att köra på servern: inga direkta window, document eller webblagrings-anrop. Det är en bra tvångsfunktion: håll browserberoende beteende i ett tunt webbadapterlager.
Med CSR (client-side rendering) har du mer frihet, men samma disciplin lönar sig. CSR-projekt råkar ofta “av misstag” importera UI-kod i domänmoduler eftersom allt körs i browsern — tills du senare lägger till SSR, edge-rendering eller tester som körs i Node.
En praktisk regel: delade moduler ska vara deterministiska och miljö-agnostiska; allt som rör cookies, localStorage eller URL hör hemma i webblagret.
Delad logik kan exponera domänstate (t.ex. order totals, behörighet, härledda flaggor) via vanliga objekt och rena funktioner. Webbappen bör äga UI-state: laddningsindikatorer, formulärfokus, optimistiska animationer, modalers synlighet.
Detta gör React/Vue-state-hantering flexibel: du kan byta bibliotek utan att skriva om affärsregler.
Webblagret bör hantera:
localStorage, caching)Tänk på webbappen som en adapter som översätter användarinteraktioner till domänkommandon — och domänutfall till tillgängliga skärmar.
Mobilappen drar mest nytta av ett delat domänlager: regler för prissättning, behörighet, validering och arbetsflöden bör bete sig lika som webbappen och API:t. Mobil-UI:t blir ett “skal” runt den delade logiken — optimerat för touch, intermittent uppkoppling och enhetsfunktioner.
Även med delad affärslogik har mobil mönster som sällan mappar 1:1 till webb:
Om du förväntar dig verklig mobilanvändning, anta offline:
En “en kodbas” kollapsar snabbt om webb, mobil och API var och en uppfinner egna dataskick och säkerhetsregler. Lösningen är att behandla modeller, autentisering och auktorisering som delade produktbeslut och sedan koda dem en gång.
Välj ett ställe där modeller lever, och låt allt annat härleda från det. Vanliga alternativ:
Nyckeln är inte verktyget — det är konsekvensen. Om “OrderStatus” har fem värden i en klient och sex i en annan, kommer AI-genererad kod gärna att kompileras och ändå leverera buggar.
Autentisering bör kännas likadan för användaren, men mekaniken skiljer per yta:
Designa ett enhetligt flöde: inloggning → kortlivad access → refresh vid behov → utloggning som ogiltigförklarar serverstate. På mobil, lagra hemligheter i säker lagring (Keychain/Keystore), inte i öppna preferenser. På webben, föredra httpOnly-cookies så tokens inte exponeras för JavaScript.
Behörigheter bör definieras en gång — helst nära affärsreglerna — och sedan tillämpas överallt.
canApproveInvoice(user, invoice)).Detta förhindrar “fungerar på mobil men inte på webben”-drift och ger AI-kodgenerering ett tydligt, testbart kontrakt för vem som kan göra vad.
En enad kodbas förblir enad bara om bygg och releaser är förutsägbara. Målet är att team ska kunna skicka API, webbapp och mobilappar oberoende — utan att dela logik eller göra specialfallet i miljöer.
Ett monorepo (ett repo, flera paket/appar) fungerar ofta bäst för en enad kodbas eftersom delad domänlogik, API-kontrakt och UI-klienter utvecklas tillsammans. Du får atomära ändringar (en PR uppdaterar ett kontrakt och alla konsumenter) och enklare refaktorer.
Ett multi-repo kan fortfarande vara enhetligt, men kostar i koordinering: versionshantering av delade paket, publicering av artefakter och synkronisering av brytande ändringar. Välj multi-repo endast om organisationsgränser, säkerhetsregler eller skala gör ett monorepo opraktiskt.
Behandla varje yta som ett separat byggmål som konsumerar delade paket:
Håll byggoutputs explicita och reproducerbara (lockfiles, pinnade toolchains, deterministiska builds).
Ett typiskt pipelineflöde är: lint → typecheck → unit tests → kontraktstester → build → säkerhetsskanning → deploy.
Separera konfig från kod: miljövariabler och hemligheter lever i din CI/CD och secret manager, inte i repot. Använd miljöspecifika overlays (dev/stage/prod) så samma artefakt kan promoveras över miljöer utan att bygga om — särskilt för API och webb-runtime.
När webb, mobil och API släpps från samma kodbas blir testning inte "en checklista" utan mekanismen som förhindrar att en liten ändring bryter tre produkter samtidigt. Målet är enkelt: upptäck problem där de är billigast att fixa, och blockera riskfyllda ändringar innan användare påverkas.
Börja med den delade domänen (din affärslogik) eftersom den återanvänds mest och är enklast att testa utan långsam infrastruktur.
Denna struktur ger mesta förtroendet i den delade logiken, samtidigt som den fångar "wiring"-problem där lager möts.
Även i ett monorepo är det lätt för API att förändras så att det kompilerar men bryter användarupplevelsen. Kontraktstester förhindrar tyst drift.
Bra tester räcker inte — reglerna runt dem gör skillnad.
Med dessa grindar på plats kan AI-assisterade ändringar bli frekventa utan att bli bräckliga.
AI kan accelerera en enad kodbas, men bara om den behandlas som en snabb junioringenjör: utmärkt på att producera utkast, osäker att merga utan granskning. Målet är att använda AI för hastighet samtidigt som människor är ansvariga för arkitektur, kontrakt och långsiktig koherens.
Använd AI för att generera “första versioner” du annars skulle skriva mekaniskt:
En bra regel: låt AI producera kod som är lätt att verifiera genom att läsa eller köra tester, inte kod som tyst ändrar affärsbetydelse.
AI-utdata bör begränsas av explicita regler, inte känslor. Placera dessa regler där koden är:
Om AI föreslår en genväg som bryter gränser, är svaret "nej" även om det kompilerar.
Risken är inte bara dålig kod — det är oregistrerade beslut. Behåll ett audit-logg:
AI är mest värdefull när det är reproducerbart: teamet kan se varför något genererades, verifiera det och återskapa det säkert när kraven förändras.
Om ni adopterar AI-assisterad utveckling på systemnivå (webb + API + mobil) är den viktigaste “funktionen” inte rå genereringshastighet — utan förmågan att hålla utdata i linje med era kontrakt och lager.
Till exempel är Koder.ai en plattform som hjälper team att bygga webb, server och mobilapplikationer via en chattgränssnitt — samtidigt som den producerar verklig, exponerbar källkod. I praktiken är det användbart för arbetsflödet i den här artikeln: du kan definiera ett API-kontrakt och domänregler, och sedan iterera snabbt på React-baserade webbytor, Go + PostgreSQL-backends och Flutter-mobilappar utan att förlora möjligheten att granska, testa och upprätthålla arkitekturgränser. Funktioner som planeringsläge, snapshots och rollback kartläggs också väl till “generera → verifiera → promovera” releaser i en enad kodbas.
En enad kodbas kan minska duplikation, men det är inte alltid standardvalet. Så snart delad kod börjar tvinga fram klumpiga UX, sakta releaser eller dölja plattformsdifferenser, kommer ni att lägga mer tid på att förhandla arkitektur än att leverera värde.
Separata kodbaser (eller åtminstone separata UI-lager) är ofta motiverade när:
Ställ dessa frågor innan ni bestämmer er för en enad kodbas:
Om ni ser varningssignaler, är ett praktiskt alternativ delad domän + API-kontrakt, med separata webb- och mobilappar. Håll delad kod fokuserad på affärsregler och validering, och låt varje klient äga UX och plattformsintegrationer.
Om du vill ha hjälp att välja väg, jämför alternativ på /pricing eller bläddra relaterade arkitekturmönster på /blog.
Det betyder oftast ett arkiv och en uppsättning delade regler, inte en identisk app.
I praktiken delar webb, mobil och API ofta ett domänlager (affärsregler, validering, användningsfall) och ofta ett gemensamt API-kontrakt, medan varje plattform behåller sin egen UI och plattformsintegrationer.
Dela det som aldrig får motsäga sig:
Håll UI-komponenter, navigering och enhets-/webbläsarintegrationer plattformspecifika.
AI snabbar upp uppsättning och repetitivt arbete (CRUD, klienter, tester), men skapar inte automatiskt bra gränser.
Utan en avsiktlig arkitektur tenderar AI-genererad kod att:
Använd AI för att fylla väldefinierade lager, inte för att uppfinna lagren.
En enkel, pålitlig flöde är:
Detta centraliserar affärsregler och gör både testning och AI-genererade tillägg enklare att granska.
Lägg valideringen på ett ställe (domän eller en delad valideringsmodul) och återanvänd den överallt.
Praktiska mönster:
EmailAddress och Money en gångDetta förhindrar att “webben accepterar det men API:t avvisar det”.
Använd ett kanoniskt schema som OpenAPI (eller GraphQL SDL) och generera därifrån:
Lägg sedan till kontraktstester så att schema-brytande ändringar misslyckas i CI innan de når produktion.
Designa offline medvetet:
Håll offline-lagring och synk i mobilskiktet; behåll affärsregler i delad domänkod.
Använd ett konceptuellt flöde, men implementera lämpligt per yta:
Auktorisationsregler bör definieras centralt (t.ex. canApproveInvoice) och tillämpas i API:t; UI speglar kontroller endast för att dölja/inaktivera åtgärder.
Behandla varje yta som ett separat buildmål som konsumerar delade paket:
I CI/CD kör: lint → typecheck → unit tests → kontraktstester → build → säkerhetsskanning → deploy, och håll secrets/konfiguration utanför repot.
Använd AI som en snabb juniorutvecklare: bra för utkast, osäker utan styrning.
Bra styrmedel:
Om AI-genererat förslag bryter arkitekturregler, avvisa det även om det kompilerar.