20 juli 2025·8 min
API-utveckling & bakåtkompatibilitet i AI-backends
Lär dig hur AI-genererade backends utvecklar API:er säkert: versionering, kompatibla ändringar, migrationer, avvecklingssteg och tester som förhindrar att klienter bryts.
Lär dig hur AI-genererade backends utvecklar API:er säkert: versionering, kompatibla ändringar, migrationer, avvecklingssteg och tester som förhindrar att klienter bryts.
API-utveckling är den löpande processen att ändra ett API efter att det redan används av verkliga klienter. Det kan innebära att lägga till fält, justera valideringsregler, förbättra prestanda eller införa nya endpoints. Det blir viktigt när klienter är i produktion—eftersom även en “liten” ändring kan slå sönder en mobilapp, ett integrationsskript eller en partnerarbetsflöde.
En ändring är bakåtkompatibel om befintliga klienter fortsätter fungera utan några uppdateringar.
Till exempel, anta att ditt API returnerar:
{ "id": "123", "status": "processing" }
Att lägga till ett nytt valfritt fält är vanligtvis bakåtkompatibelt:
{ "id": "123", "status": "processing", "estimatedSeconds": 12 }
Äldre klienter som ignorerar okända fält fortsätter fungera. Däremot är det vanligt att byten som att byta namn på status till state, ändra ett fälts typ (string → number) eller göra ett tidigare valfritt fält obligatoriskt blir brytande ändringar.
En AI-genererad backend är inte bara en kodsnutt. I praktiken inkluderar den:
Eftersom AI snabbt kan regenerera delar av systemet kan API:t “drifta” om du inte aktivt hanterar ändringar.
Detta är särskilt sant när hela appar genereras från en chattbaserad workflow. Till exempel kan Koder.ai (en vibe-coding-plattform) skapa webb, server och mobilappar från en enkel chatt—ofta med React på webben, Go + PostgreSQL på backend och Flutter för mobil. Den hastigheten är värdefull, men den kräver kontraktdisciplin (och automatiserad diff/test) så att en regenererad release inte av misstag ändrar vad klienter förlitar sig på.
AI kan automatisera mycket: producera OpenAPI-specar, uppdatera boilerplate-kod, föreslå säkra defaults och till och med skissa migrationssteg. Men mänsklig granskning är fortfarande avgörande för beslut som påverkar klientkontrakt—vilka ändringar som är tillåtna, vilka fält som är stabila, och hur man hanterar kantfall och affärsregler. Målet är hastighet med förutsägbart beteende, inte hastighet på bekostnad av överraskningar.
API:er har sällan en enda “klient.” Även en liten produkt kan ha flera konsumenter som förlitar sig på samma endpoints:
När ett API går sönder är kostnaden inte bara utvecklartid. Mobilanvändare kan fastna på äldre appversioner i veckor, så en brytande ändring kan ge en lång svans av fel och supportärenden. Partners kan drabbas av driftstopp, missa data eller stoppa kritiska arbetsflöden—ibland med kontrakts- eller ryktemässiga konsekvenser. Interna tjänster kan tyst falla och skapa röriga backloggar (t.ex. saknade events eller ofullständiga poster).
AI-genererade backends lägger till en twist: kod kan ändras snabbt och ofta, ibland i stora diffs, eftersom generation är optimerad för att producera fungerande kod—not för att bevara beteende över tid. Denna hastighet är värdefull, men ökar risken för oavsiktliga brytande ändringar (ombetygda fält, andra defaults, striktare validering, nya auth-krav).
Därför måste bakåtkompatibilitet vara ett medvetet produktbeslut, inte en bästa-försöks-vana. Den praktiska inställningen är att definiera en förutsägbar förändringsprocess där API:t behandlas som ett produktgränssnitt: du kan lägga till kapabiliteter, men du överraskar inte befintliga klienter.
Ett användbart tankesätt är att betrakta API-kontraktet (t.ex. en OpenAPI-spec) som “sanningskällan” för vad klienter kan förlita sig på. Generering blir då en implementeringsdetalj: du kan regenerera backenden, men kontraktet—och löftena det ger—förblir stabilt om du inte uppsåtligt versionerar och kommunicerar ändringar.
När ett AI-system kan generera eller modifiera backendkod snabbt är det enda pålitliga ankaret API-kontraktet: den skriftliga beskrivningen av vad klienter kan anropa, vad de måste skicka och vad de kan förvänta sig tillbaka.
Ett kontrakt är en maskinläsbar spec som till exempel:
Detta kontrakt är vad du lovar yttre konsumenter—även om implementationen bakom ändras.
I en contract-first workflow designar eller uppdaterar du OpenAPI/GraphQL-schemat först och genererar sedan serverstubs och fyller i logik. Detta är vanligtvis säkrare för kompatibilitet eftersom ändringar är avsiktliga och granskbara.
I en code-first workflow produceras kontraktet från kodannoteringar eller runtime-introspektion. AI-genererade backends lutar ofta åt code-first som standard, vilket är okej—så länge den genererade specen behandlas som ett artefakt att granska, inte som en eftertanke.
Ett praktiskt hybridmönster är: låt AI föreslå kodändringar, men kräva att den också uppdaterar (eller regenererar) kontraktet, och behandla kontraktsdiffar som huvudsignalen för ändringar.
Förvara dina API-specar i samma repo som backenden och granska dem via pull requests. En enkel regel: ingen merge om inte kontraktsändringen är förstådd och godkänd. Detta gör bakåtinkompatibla redigeringar synliga tidigt, innan de når produktion.
För att minska drift, generera serverstubs och client SDKs från samma kontrakt. När kontraktet uppdateras uppdateras båda sidor tillsammans—vilket gör det mycket svårare för en AI-genererad implementation att av misstag “uppfinna” beteenden som klienterna inte byggts för.
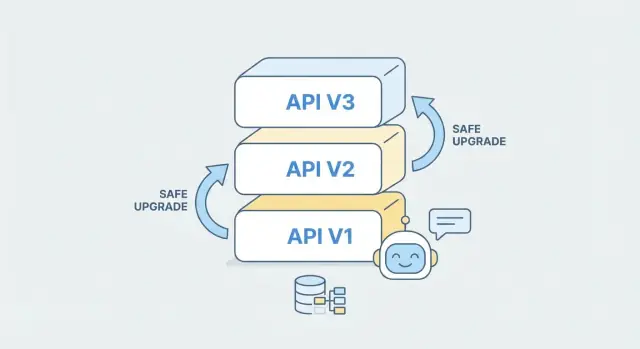
API-versionering handlar inte om att förutsäga varje framtida ändring—det handlar om att ge klienter ett klart, stabilt sätt att fortsätta fungera medan du förbättrar backenden. I praktiken är den “bästa” strategin den som dina konsumenter förstår direkt och som ditt team konsekvent kan tillämpa.
URL-versionering placerar versionen i sökvägen, som /v1/orders och /v2/orders. Det syns i varje anrop, är enkelt att felsöka och fungerar bra med caching och routing.
Header-versionering håller URL:en ren och flyttar versionen till en header (t.ex. Accept: application/vnd.myapi.v2+json). Det kan vara elegant, men mindre uppenbart vid felsökning och kan missas i exempel som kopieras.
Query-parameter-versionering använder något som /orders?version=2. Det är enkelt, men kan bli rörigt när klienter eller proxies stryker/ändrar querysträngar, och det är lättare att av misstag blanda versioner.
För de flesta team—särskilt om du vill ha enkel klientförståelse—standardisera på URL-versionering. Det är minst överraskande, lätt att dokumentera och gör det uppenbart vilken version en SDK, mobilapp eller partnerintegration anropar.
När du använder AI för att generera eller utöka en backend, behandla varje version som en separat “kontrakt + implementation”-enhet. Du kan skaffa en ny /v2 från en uppdaterad OpenAPI-spec samtidigt som du behåller /v1 intakt, och dela affärslogik under där det är möjligt. Det minskar risken: befintliga klienter fortsätter fungera medan nya klienter antar v2 medvetet.
Versionering fungerar bara om din dokumentation hänger med. Håll versionspecifik API-dokumentation, ha konsekventa exempel per version och publicera en changelog som tydligt anger vad som ändrats, vad som avvecklas och migrationsanvisningar (helst med sida-vid-sida request/response-exempel).
När en AI-genererad backend uppdateras är det säkraste sättet att tänka på kompatibilitet: “Kommer en befintlig klient fortfarande fungera utan ändringar?” Använd checklistan nedan för att klassificera ändringar innan du släpper dem.
Dessa ändringar bryter vanligtvis inte befintliga klienter eftersom de inte ogiltigförklarar vad klienter redan skickar eller förväntar sig:
middleName eller metadata). Befintliga klienter bör fortsätta fungera så länge de ignorerar okända fält.Behandla dessa som brytande om du inte har starka skäl annars:
nullable → non-nullable).Uppmuntra klienter att vara toleranta läsare: ignorera okända fält och hantera oväntade enum-värden graciöst. Detta låter backenden utvecklas genom att lägga till fält utan att tvinga klientuppdateringar.
En generator kan förhindra oavsiktliga brytande ändringar genom policy:
API-ändringar är vad klienter ser: request/response-former, fältnamn, valideringsregler och felbeteende. Databasändringar är vad din backend lagrar: tabeller, kolumner, index, constraints och dataformat. De hör ihop, men är inte identiska.
Ett vanligt misstag är att betrakta en databasmigration som “endast intern.” I AI-genererade backends genereras ofta API-lagret från schemat (eller är tätt kopplat till det), så en schemaändring kan tyst bli en API-ändring. Det är så äldre klienter går sönder även när du inte tänkt röra API:t.
Använd en flerstegsmetod som håller både gamla och nya kodvägar fungerande under rullande uppgraderingar:
Detta mönster undviker “big bang”-releaser och ger rollback-alternativ.
Gamla klienter antar ofta att ett fält är valfritt eller har en stabil betydelse. När du lägger till en ny icke-null kolumn, välj mellan:
Var försiktig: ett DB-default hjälper inte alltid om din API-serializer fortfarande returnerar null eller ändrar valideringsregler.
AI-verktyg kan skissa migrationsskript och föreslå backfills, men du behöver fortfarande mänsklig validering: bekräfta constraints, kolla prestanda (locks, indexbyggnader) och kör migrationer mot staging-data för att säkerställa att äldre klienter fungerar.
Feature flags låter dig byta beteende utan att ändra endpointens form. Det är särskilt användbart i AI-genererade backends där intern logik kan regenereras eller optimeras ofta, men klienter fortfarande förlitar sig på konsekventa request/response.
Istället för att släppa en “stor strömbrytare” skickar du ny kod med beteendet avstängt, och slår sedan på gradvis. Om något går fel, stänger du av det—utan en panik-återdistribution.
En praktisk utrullningsplan kombinerar ofta tre tekniker:
För API:er är nyckeln att hålla svaren stabila medan du experimenterar internt. Du kan byta implementation (ny modell, ny routinglogik, ny DB-query-plan) samtidigt som du returnerar samma statuskoder, fältnamn och felformer som kontraktet lovar. Om du behöver lägga till ny data, föredra additiva fält som klienter kan ignorera.
Tänk dig en POST /orders-endpoint som idag accepterar phone i många format. Du vill kräva E.164-format, men hårdare validering kan bryta befintliga klienter.
Ett säkrare tillvägagångssätt:
strict_phone_validation).Detta låter dig förbättra datakvalitet utan att oavsiktligt göra din bakåtkompatibla API brytande.
Avveckling är en “hövlig exit” för gammalt API-beteende: du slutar uppmuntra det, varnar klienter tidigt och ger en förutsägbar väg framåt. Sunsetting är sista steget: en gammal version stängs av på ett publicerat datum. För AI-genererade backends—där endpoints och scheman kan utvecklas snabbt—är en strikt avvecklingsprocess det som håller uppdateringar säkra och förtroendet intakt.
Använd semantisk versionering på kontraktsnivå, inte bara i repo:
Sätt upp denna definition i din dokumentation och tillämpa den konsekvent. Det förhindrar “tysta majors” där en AI-assisterad ändring ser liten ut men bryter en verklig klient.
Välj en standardpolicy och håll dig till den så användare kan planera. Ett vanligt upplägg:
Om du är osäker, välj ett något längre fönster; kostnaden för att hålla en version aktiv kort tid är ofta lägre än kostnaden för nödflytt av klienter.
Lita på flera kanaler eftersom inte alla läser release-notes.
Deprecation: true och Sunset: Wed, 31 Jul 2026 00:00:00 GMT, plus en Link-signal med migrationsguiden (t.ex. /docs/api/v2/migration).Inkludera också avvecklingsnotiser i changelogs och statusuppdateringar så inköp och ops ser dem.
Behåll gamla versioner igång tills sunset-datumet, och stäng sedan av dem medvetet—not gradvis via oavsiktliga brott.
Vid sunset:
410 Gone) med ett meddelande som pekar mot nyare version och migrationssida.Viktigast: behandla sunset som en schemalagd ändring med ägare, övervakning och rollback-plan. Den disciplinen gör frekvent evolution möjlig utan att överraska klienter.
AI-genererad kod kan ändras snabbt—och ibland på oväntade ställen. Det säkraste sättet att hålla klienter fungerande är att testa kontraktet (vad du lovar externt), inte bara implementationen.
En praktisk baseline är en kontraktstest som jämför tidigare OpenAPI-spec med den nygenererade. Behandla det som en “före vs efter”-koll:
Många team automatiserar en OpenAPI-diff i CI så att ingen genererad ändring kan driftsättas utan granskning. Detta är extra användbart när prompts, templates eller modellversioner skiftar.
Konsumentdriven kontraktstestning vänder perspektivet: istället för att backend-teamet gissar hur klienter använder API:t delar varje klient ett litet uppsättning förväntningar (requests de skickar och responses de förlitar sig på). Backenden måste bevisa att den fortfarande uppfyller dessa förväntningar innan release.
Det fungerar bra när du har flera konsumenter (web, mobil, partners) och vill uppdatera utan att koordinera varje distribution.
Lägg till regressionstester som låser:
Om du publicerar ett felformat, testa det uttryckligen—klienter parser ofta fel mer än vi skulle önska.
Kombinera OpenAPI-diffkontroller, konsumentkontrakt och shape/error-regressionstester i en CI-gate. Om en genererad ändring misslyckas är en vanlig åtgärd att justera prompten, generationsreglerna eller lägga in ett kompatibilitetslager—innan användare märker något.
När klienter integrerar mot ditt API läser de sällan felmeddelanden—de reagerar på felformer och koder. Ett stavfel i ett människovänligt meddelande är irriterande men överlevbart; en ändrad statuskod, saknat fält eller omdöpt felidentifierare kan göra en återhämtningsbar situation till ett brutet checkoutflöde, en misslyckad synk eller en oändlig retry-loop.
Sikta på en konsekvent felkuvert (JSON-struktur) och en stabil uppsättning identifierare som klienter kan förlita sig på. Till exempel, om du returnerar { code, message, details, request_id }, ta inte bort eller döpa om dessa fält i en ny version. Du kan förbättra formuleringen i message fritt, men håll code-semantiken stabil och dokumenterad.
Om du redan har flera format i farten, motstå frestelsen att “städa upp” på plats. Lägg i stället till ett nytt format bakom en versionsgräns eller ett förhandlingssätt (t.ex. Accept-header), samtidigt som du fortsätter stödja det gamla.
Nya felkoder är ibland nödvändiga, men introducera dem så att befintliga integrationer inte blir förvånade.
En säker strategi:
VALIDATION_ERROR, ersätt inte den över en natt med INVALID_FIELD.code, men inkludera också bakåtkompatibla ledtrådar i details (eller mappa till den äldre generaliserade koden för äldre versioner).message.Viktigast: ändra aldrig betydelsen av en befintlig kod. Om NOT_FOUND tidigare betydde “resurs finns inte”, börja inte använda den för “åtkomst nekad” (det är 403).
Bakåtkompatibilitet handlar också om “samma request, samma resultat”. Till synes små defaultändringar kan slå sönder klienter som aldrig uttryckligen satt parametrar.
Paginering: ändra inte standard limit, page_size eller cursor-beteende utan versionering. Att byta från sida-baserad till cursor-baserad paginering är brytande om du inte behåller båda.
Sortering: standard sorteringsordning bör vara stabil. Att byta från created_at desc till relevance desc kan ändra ordning och bryta UI-antar eller inkrementella syncs.
Filtrering: undvik att ändra implicita filter (t.ex. plötsligt exkludera “inactive” items som standard). Om du behöver nytt beteende, lägg till en explicit flagga som include_inactive=true eller status=all.
Vissa kompatibilitetsproblem handlar inte om endpoints utan om tolkning.
"9.99" till 9.99 (eller vice versa) i samma version.include_deleted=false eller send_email=true bör inte växla. Om du måste ändra ett default, kräv att klienten opt-in via en ny parameter.För AI-genererade backends i synnerhet: lås dessa beteenden med explicita kontrakt och tester—modellen kan “förbättra” svaren om du inte tvingar stabilitet som ett förstklassigt krav.
Bakåtkompatibilitet är inte något du verifierar en gång och glömmer. Med AI-genererade backends kan beteendet ändras snabbare än i handbyggda system, så du behöver feedbackloopar som visar vem som använder vad och om en uppdatering skadar klienter.
Börja med att tagga varje request med en explciti API-version (i path som /v1/..., i header som X-Api-Version eller genom schemaförhandling). Samla sedan metrics segmenterat per version:
Det låter dig upptäcka exempelvis att /v1/orders är 5% av trafiken men 70% av felen efter en utrullning.
Instrumentera gateway eller applikation för att logga vad klienter faktiskt skickar och vilka routes de anropar:
/v1/legacy-search)Om ni kontrollerar SDK:er, lägg till en lätt klientidentifierare + SDK-version-header för att upptäcka föråldrade integrationer.
När fel ökar vill du svara: “Vilket deployment ändrade beteendet?” Korrelera spikar med:
Ha rollbacks tråkiga: kunna alltid redeploya föregående genererade artefakt (container/image) och vända trafiken tillbaka via din router. Undvik rollbacks som kräver datarollbacks; om schemaändringar är inblandade, föredra additiva DB-migrationer så äldre versioner fortsätter fungera medan du återställer API-lagret.
Om din plattform stödjer environment-snapshots och snabb rollback, använd dem. Till exempel inkluderar Koder.ai snapshots och rollback i workflowen, vilket passar naturligt med “expand → migrate → contract” DB-ändringar och gradvisa API-utrullningar.
AI-genererade backends kan ändras snabbt—nya endpoints dyker upp, modeller skiftar och valideringar skärps. Det säkraste sättet att hålla klienter stabila är att behandla API-ändringar som en liten, upprepbar releaseprocess istället för “engångsändringar.”
Skriv ner “varför”, avsett beteende och exakt kontraktsinverkan (fält, typer, obligatoriskt/valfritt, felkoder).
Markera som kompatibel (säkert) eller brytande (kräver klientändringar). Om osäker, anta brytande och designa en kompatibilitetsväg.
Bestäm hur du stödjer gamla klienter: alias, dual-write/dual-read, defaultvärden, tolerant parsing eller en ny version.
Lägg till ändringen med feature flags eller konfiguration så att du kan rulla ut gradvis och snabbt rulla tillbaka.
Kör automatiska kontraktskontroller (t.ex. OpenAPI-diff-regler) plus golden “kända klient”-request/response-tester för att fånga drift.
Varje release bör innehålla: uppdaterad referensdokumentation i /docs, en kort migrationsnotis vid behov och en changelog som anger vad som ändrats och om det är kompatibelt.
Annonsera avveckling med datum, lägg till responsheaders/varningar, mät återstående användning och ta bort efter sunset-fönstret.
Om du vill byta namn last_name till family_name:
family_name.family_name och håll last_name som aliasfält).last_name som avvecklat och sätt ett borttagningsdatum.Om ditt erbjudande inkluderar planbaserat stöd eller långsiktig versionsstöd, tydliggör det i texten om prissättning (t.ex. pricing).
Bakåtkompatibilitet betyder att befintliga klienter fortsätter fungera utan några ändringar. I praktiken kan du oftast:
Vanligtvis kan du inte byta namn på eller ta bort fält, ändra typer eller skärpa validering utan att någon går sönder.
Räkna en ändring som brytande om den kräver att någon redan driftsatt klient måste uppdateras. Vanliga brytande ändringar är:
status → state)Använd ett API-kontrakt som ankare, vanligtvis:
Sedan:
Detta hindrar att AI-regenerering tyst ändrar klientexponerat beteende.
I contract-first uppdaterar du specen först och genererar/implementerar kod efteråt. I code-first produceras specen från koden.
Ett praktiskt hybridmönster för AI-workflows:
Automatisera en OpenAPI-diff i CI och misslyckas byggen när ändringar ser brytande ut, till exempel:
Tillåt merge endast när (a) ändringen bekräftats kompatibel, eller (b) ni ökar till en ny major-version.
URL-versionering (t.ex. /v1/orders, /v2/orders) är oftast minst förvånande:
Header- eller query-versionering kan fungera, men är lättare att missa vid felsökning.
Anta att vissa klienter är strikta. Säkra mönster:
Om du måste ändra betydelse eller ta bort ett enum-värde, gör det bakom en ny version.
Använd “expand → migrate → contract” så gammal och ny kod kan köras under rollout:
Detta minskar driftstopp och gör rollback möjlig.
Feature flags låter dig förändra intern logik utan att ändra endpointens form. En praktisk utrullning:
Detta är särskilt användbart för strängare validering eller prestanda-omskrivningar.
Gör avveckling svår att missa och tidsbestämd:
Deprecation: true, Sunset: <date>, )Link: /docs/api/v2/migration410 Gone) med migrationsvägledning