28 aug. 2025·8 min
Autokomplettering och tolerans för stavfel i indisk e‑handelsökning
Lär dig om autokomplettering och tolerans för stavfel i indisk e‑handelsökning med synonymplanering, lokala termer, translitterationer och analys för bättre resultat.
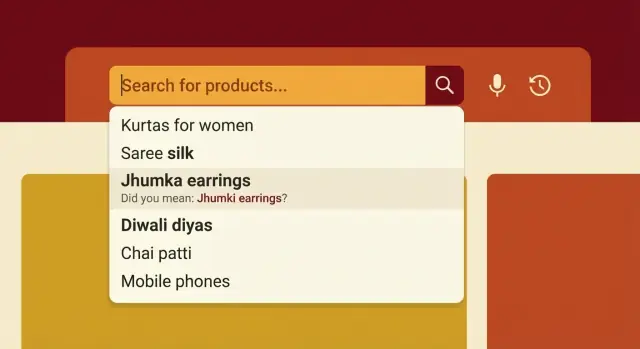
Varför indiska produktnamn bryter sökningar
Indisk e‑handelsökning misslyckas av en enkel anledning: människor namnger inte samma sak på samma sätt. Samma produkt kan skrivas på engelska, hindi, tamil eller en blandning, och varje region har sina vardagliga termer.
En kund kan söka efter “atta”, “aata”, “gehu ka atta” eller bara varumärkesnamnet. En annan skriver “jeera”, “zeera” eller bara “cumin”. Om din katalog bara innehåller en av dessa former kan en helt normal fråga ge inga träffar.
Små stavningsskillnader skadar mer än man tror eftersom sökmotorer ofta behandlar frågan som exakt text. En saknad vokal, ett extra mellanslag eller en annan ordordning kan skjuta rätt produkt ur toppresultaten eller ge noll träffar.
Vanliga orsaker till att indiska produktnamn splittras i många varianter:
- Flera skriftsystem och translitterationer (hindi skrivet med engelska bokstäver, lokala stavningar)
- Regionala termer för samma artikel (mat, kläder, hushållsartiklar)
- Varumärke först vs generiskt först i namngivning (“Surf Excel 1kg” vs “detergent powder”)
- Förkortningar och talspråk (“kurti” vs “kurta top”, “1 ltr” vs “1L”)
- Tangentbordsfel och autokorrigering (“pista” blir “pita”, “saree” vs “sarri”)
Autokomplettering och tolerans för stavfel förändrar vad kunden upplever. Autokomplettering minskar ansträngningen genom att vägleda användaren mot de formuleringar din butik förstår, innan de skickar sökningen. Tolerans för stavfel förhindrar att ”nästan rätt” frågor misslyckas, så kunder fortfarande ser relevanta artiklar även när stavningen är ofullständig.
Det praktiska målet med autokomplettering och stavfelstolerans i indisk e‑handelsökning är inte ”perfekt språkstöd”. Det är mätbart: färre nollträffar och snabbare produktupptäckt, så fler kunder når en produktlista istället för en återvändsgränd.
Nyckelidéer på enkel svenska
Bra sök i Indien handlar mindre om avancerade algoritmer och mer om att förstå hur människor faktiskt skriver produktnamn. Många användare blandar engelska med lokala ord, stavar samma sak på flera sätt och förväntar sig ändå att sökningen ska ”förstå”.
Autokomplettering hjälper innan frågan är färdig. När någon skriver “jeer…”, kan du föreslå “jeera rice”, “jeera powder” eller “jeera whole”. Görs det rätt minskar autokomplettering arbetet och leder kunder mot termer som finns i din katalog.
Tolerans för stavfel innebär att du fortfarande matchar när användaren gör ett sannolikt misstag, som “zeera” vs “jeera” eller “shampo” vs “shampoo”. Målet är att rätta vanliga fel utan att ändra meningen. För stor tolerans ger konstiga träffar (till exempel att en kort fråga som “ram” plötsligt matchar orelaterade produkter).
Synonymer är enkelt: olika ord, samma avsikt. “Atta” och “wheat flour” bör leda till samma uppsättning produkter. I indisk e‑handel inkluderar synonymer ofta varianter som ser ut som märkesnamn (“biscuit” vs “cookies”), regionala ord och kategori‑tilltalsnamn.
Translitteration är när folk skriver indiska ord med engelska bokstäver. Någon kan skriva “namkeen”, “nimeen” eller “namkin” beroende på vana och tangentbord. Translitterationsregler hjälper dig matcha dessa varianter även om din katalog bara använder en stavning.
Ett praktiskt sätt att tänka på autokomplettering och stavfelstolerans för indisk e‑handelsökning är:
- Autokomplettering vägleder användaren mot en giltig, populär fråga.
- Stavfelstolerans räddar användaren när de stavar fel en giltig fråga.
- Synonymer kopplar olika ord till samma köpavsikt.
- Translitteration kopplar olika stavningar till samma lokalspråksterm.
När detta är tydligt kan du bygga en liten, kontrollerad mappning och utvidga den med faktisk sökanalys i stället för att gissa.
Bygg din indiska namndatabas (data att samla)
En bra sökdatabas börjar med dina egna data, inte gissningar. Målet är enkelt: fånga hur människor faktiskt namnger produkter i Indien, inklusive lokala termer, stavningar och förkortningar, så att autokomplettering och stavfelstolerans har något stabilt att arbeta mot.
Börja med att gräva i din katalog. Produktnamn, kategorinamn, attribut, variantetiketter, varumärken, förpackningsstorlekar och enheter innehåller ofta den “officiella” formuleringen som kunderna ska kunna hitta. För dagligvaror kan det inkludera både generiska och specifika termer som “toor dal”, “arhar dal” och “split pigeon peas” om du använder sådana.
Samla sedan in verkligt kundspråk. Sökloggar visar vad folk skriver när de har bråttom, medan kundtjänstchattar visar hur de beskriver varor när de inte hittar dem. Redan ett par veckors loggar kan visa upprepade mönster som “aata/atta”, “dahi/curd” eller “chilli/chili”.
Bygg inputs från fem källor och slå ihop dem:
- Katalogtext (titlar, attribut, varianter, varumärken, storlekar)
- Sökuppgifter (inklusive nollträffar)
- Kundtjänstchattar och samtalsanteckningar
- Regionala och lokala termer som ditt team redan använder
- Enhets‑ och paketkortformer (ml, ltr, pcs, combo, 1+1)
Slutligen, separera generiska termer från varumärkesord. “Atta” bör matcha många produkter, medan ett varumärke inte ska dra in orelaterade produkter. Behåll två märkt listor (generiskt vs varumärke) så att senare regler inte suddar ut avsikten och förvirrar rankningen.
Steg‑för‑steg: skapa en synonym‑ och translitterationsplan
Börja smått. Välj 20–50 kategorier som driver mest sök och intäkt, som basvaror, skönhet och populära elektronikartiklar. Det håller arbetet fokuserat och visar effekt snabbt för autokomplettering och stavfelstolerans.
Bygg sedan en gemensam “namntabell” som alla kan redigera (merch, innehåll, support). Ha den i ett kalkylblad först och synka den sedan till ditt sökindex.
1) Gör en kanonisk lista
För varje kategori, välj det term du vill att systemet ska behandla som huvudnamn (kanonisk). Använd det kunder känner igen, inte vad leverantören kallar det.
Skapa rader som dessa:
| Canonical term | Synonyms (same product) | Common misspellings | Transliterations | Notes |
|---|---|---|---|---|
| cumin | jeera | jeera, jeeraa | zeera, zira | Keep “caraway” separate |
| face wash | cleanser | fash wash | fes wash | Don’t map to “face cream” |
Lägg till enheter och packmönster som separata, återanvändbara token: 1kg, 500 g, 2x, combo pack, family pack. Dessa orsakar ofta nollträffar eftersom användare skriver hela frasen.
2) Sätt strikta regler för “samma produkt”
En synonym bör betyda att kunden blir nöjd med samma resultat. Skriv en kort regel som teamet kan följa:
- Tillåtet: regionala varianter, varumärkesförkortningar, vanliga stavningar
- Tillåtet: Hinglish‑translitteration när betydelsen är densamma
- Ej tillåtet: intilliggande produkter (cleanser vs toner, cumin vs carom)
- Ej tillåtet: olika storlekar som synonymer (storlek är en filteregenskap)
- Ej tillåtet: “healthy” eller “premium” som synonym för basprodukten
3) Gör det lätt att underhålla
Tilldela en ägare per kategori och lägg in en enkel granskningsrytm (veckovis i början). När support ser ”kunde inte hitta”‑klagomål, lägger de till termer i tabellen samma dag.
Om du bygger detta i en egen sökstack kan ett verktyg som Koder.ai hjälpa dig att snabbt leverera adminskärm och synk‑workflow, samtidigt som synonymlistan hålls redigerbar för icke‑tekniska team.
Designa autokomplettering som känns rätt för Indien
Autokomplettering ska kännas snabb, bekant och förlåtande. I indisk e‑handelsökning är den största vinsten att få användbara förslag redan på de första bokstäverna. Folk skriver ofta snabbt, växlar mellan engelska och lokala termer och kommer inte ihåg exakt stavning.
Börja med att tunna för prefix. De första 2–4 tecknen bör redan visa starka, högavsiktsförslag. Om någon skriver “sha”, slösa inte toppositionerna på sällsynta artiklar. Visa vad majoriteten menar och vad du faktiskt kan leverera i mängd.
Gör förslagen kategorimedvetna, inte bara ordmedvetna. Om användaren skriver ett lokalt ord som “shakkar”, bör förslagen tydligt peka på produktkategorin (socker) och populära undertyper du har (pulver, ekologiskt etc.). Det minskar förvirring och minskar risken att användaren väljer ett orelaterat resultat.
Håll förslagen korta och lättlästa. Ett bra mönster är: varumärke + produkt (när det verkligen är vanligt) eller produkt + nyckelattribut. Undvik att stoppa in storlekar, långa modellnummer och flera attribut i en rad.
Här är praktiska UI‑regler som brukar fungera bra:
- Visa 5–8 förslag max, med topp 3 optimerade för hög konvertering.
- Normalisera mellanslag och interpunktion, så att “t-shirt”, “tshirt” och “t shirt” leder till samma förslagsuppsättning.
- Föredra artiklar och kategorier du kan leverera nu (i lager och aktiva listningar).
- Blanda typer försiktigt: 1–2 kategoriförslag, sedan produkter, sedan varumärken.
- Visa inte förslag du inte kan sälja (inga döda kategorier, inga utgångna varumärken).
Exempel: en kund skriver “dett”. I Indien menar många “Dettol” (varumärkesavsikt), men vissa vill ha “handwash” eller “sanitizer” (produktavsikt). Din autokomplettering kan visa “Dettol Handwash”, “Dettol Sanitizer” och en kategori som “Handwash” så båda avsikterna täcks utan att gissa för hårt.
När du gör detta konsekvent blir autokomplettering och stavfelstolerans i indisk e‑handelsökning mindre en fråga om smarta algoritmer och mer om att ge kunden nästa uppenbara steg.
Sätt stavfelstolerans utan röriga träffar
Bygg sökregler snabbt
Prototypa autokomplettering, synonymer och stavregler som en verklig tjänst på dagar, inte månader.
Stavfelstolerans hjälper folk hitta produkter även när de skriver fel. Men om du gör den för lös börjar sökningen visa “nästan rätt” artiklar som känns fel. Målet är enkelt: fånga upp uppenbara misstag och vara försiktig när avsikten kan ändras.
Börja med säkra edit‑distance‑regler baserade på ordlängd. Korta ord går lätt sönder, så håll dem strikta. Längre ord kan hantera lite mer flexibilitet.
- 1–4 bokstäver: tillåt 0–1 edit (exempel: “atta” -> “atta”, “atta” -> “attta”)
- 5–8 bokstäver: tillåt upp till 2 edits
- 9+ bokstäver: tillåt upp till 3 edits
- Om en fråga har flera ord, applicera edits per ord, men cappa totala edits för hela frågan
Behandla siffror som en separat klass. “1kg” och “10kg” får aldrig vara utbytbara, och “500ml” bör inte bli “1500ml”. En praktisk regel är: applicera inte stavfelstolerans inom numeriska token, och ändra inte enheter. Tillåt bara formateringsfixar som mellanslag eller versaler (“1 kg”, “1KG”, “1kg”).
Skydda varumärken och högavsiktsord från att ”korrigeras” till generiska ord. Behåll en liten skyddad lista (toppvarumärken, private labels och vanliga varumärkeslika frågor). Om en fråga matchar ett skyddat ord nära, visa hellre ett förslag än att omskriva det.
Tangentgrannfel är vanliga på mobil, särskilt med Hinglish. Lägg till extra tolerans för närliggande tangenter (a‑s, i‑o, n‑m), men bara när resten av ordet är en stark match.
När korrigeringen är tvetydig, visa den som ett förslag istället för att byta tyst. Till exempel, om “dove” kan bli “done” eller “dovee”, visa “Menade du dove?” och behåll originalresultaten synliga. Det bevarar förtroendet och minskar arga bak‑klick.
Translitteration och lokala termer (praktiska regler)
Indiska sökningar blandar ofta skript och vanor i samma rad: “जीरा rice”, “jeera चावल”, “zeera rice” eller “poha nashta”. Din sökning bör behandla dessa som samma avsikt, inte separata världar. Målet är enkelt: koppla många sätt att skriva ett produktnamn till en ren produktbetydelse.
Börja med en liten, praktisk uppsättning regler och utöka bara när du ser att det fungerar.
Praktiska normaliseringsregler
- Acceptera skriptblandning genom att normalisera allt till en delad “sökform” (behåll originalfrågan för analys, men matcha mot en normaliserad version).
- Lägg till translitterationspar endast för dina toppartiklar först (till exempel: namkeen, bhujia, poha, jeera). Inkludera vanliga stavningar användare faktiskt skriver.
- Hantera långa vokalvarianter som explicita par där det spelar roll (poha vs pauha, jeera vs zeera) i stället för att gissa varje vokalförskjutning.
- Använd ljudbyten försiktigt och snävt: v‑w, b‑v, j‑z. Applicera dem bara på kända produkttoken, inte på hela frågan, för att undvika konstiga träffar.
- Behåll varumärkesnamn och SKU:er mestadels “som skrivna” så att du inte av misstag omskriver dem till något annat.
Vilka språk att stödja först
Välj efter trafik och nollträffar, inte efter ambition. Ett vanligt ordningsföljd är engelska plus Hinglish först, sedan lägg till hindi‑skript om en meningsfull andel av frågorna använder det. Om du senare ser efterfrågan i en region, utöka med nästa språk i dina loggar, en kategori i taget.
Analysloop: förbättra sök baserat på verkligt beteende
Sätt din prototyp i produktion
Distribuera och hosta dina sökverktyg så att teamen kan använda dem omedelbart.
Sök kvalitet är inte en engångsinställning. Behandla det som en veckovana: se vad folk skriver, vad de klickar på och var de ger upp. Så förbättras autokomplettering och stavfelstolerans utan gissningar.
Börja med ett litet set kärnmetrik och håll dem konsekventa över veckor:
- Nollträffsfrekvens (övergripande och för toppfrågor)
- Förfinslningsfrekvens (användare skriver om eller lägger till filter direkt efter sökning)
- Lägg‑i‑kundvagn efter sök (eller produktklick efter sök om kundvagnar är brusiga)
- Autokompletteringens användning (klick på förslag vs manuell färdigskrivning)
- Korrigeringspåverkan (stavfelskorrigerade frågor som leder till klick vs studsar)
En gång i veckan, plocka ut dina topp‑nollträffsfrågor och klassificera varje. Håll kategorier enkla så team faktiskt använder dem: saknad synonym (jeera vs zeera), stavningsvariation, varumärkes‑ eller modellmissmatch, fel språk eller skript, eller kataloglucka (produkt inte i lager). Målet är att skilja "sök behöver synonym" från "lager saknas".
Autokompletteringsdata är ofta det snabbaste vinnet. Om användare ofta ignorerar förslag och skriver klart själva kan dina förslag vara för generiska, fel ordning eller sakna lokala termer. Om de klickar förslag men ändå förfinar eller studsar kan förslaget se rätt ut men leda till svaga resultat.
Stavfel behöver en revision, inte bara högre tolerans. Prova 20–50 korrigerade frågor per vecka och märk dem som:
- Hjälpsam (fixade till avsedd produkt)
- Harmlös (tillräckligt nära, användaren hittade saker)
- Skadlig (fixade till en annan produkt eller kategori)
Sätt detta i en enkel dashboard som produkt och marknad kan läsa på 2 minuter: topp nollträffsfrågor med orsak, topp autokompletteringsförslag och klickfrekvens, och en kort lista åtgärder för nästa release. Om du bygger interna verktyg snabbt (till exempel i Koder.ai) är denna dashboard och veckovisa exportpipeline bra första projekt.
Vanliga misstag och fallgropar att undvika
De flesta sökproblem i Indien handlar inte om “fler synonymer”. De kommer från några förutsägbara misstag som sakta skjuter användare till fel resultat och skadar förtroendet.
En av de största fällorna är att använda för vida synonymer som slår ihop olika produkter. Om “cream” och “lotion” blir utbytbara kan en kund som vill ha en tjock ansiktskräm hamna på en lätt kroppslotion och sedan lämna. Håll synonymer snäva: mappa varianter av samma avsikt, inte intilliggande kategorier.
Ett annat vanligt misstag är att ignorera paketstorlek och enhetsavsikt. “Oil 1L” och “oil 5L” är inte samma köpmission, och varken “atta 5 kg” och “atta 10 kg”. Om dina regler ignorerar enheter kan någon som vill fylla på bulk få småförpackningar och din rankning ser slumpmässig ut.
Här är högeffektiva misstag att bevaka:
- Behandla närliggande produkter som synonymer (cream vs lotion, shampoo vs conditioner)
- Ignorera storlek, antal och enhetsord (1L, 5L, 500 ml, 10 pcs)
- Låta stavfelstolerans “fixa” varumärken till andra varumärken
- Visa autokompletteringsförslag som du inte kan leverera till det postnumret
- Sätta regler och glömma dem, särskilt efter kampanjer och säsongsspikar
Varumärken kräver extra omsorg. Om någon skriver “Himalya face wash” och dina stavfelinställningar “korrigerar” det till ett annat varumärke som råkar vara populärt känns det som clickbait. En säkrare regel: var förlåtande med generiska ord (“shampu”), men striktare med varumärken och modell‑lika token.
Autokomplettering kan också slå tillbaka när den föreslår otillgängliga artiklar. Till exempel att föreslå “ghee 2L” för att det är ett frekvent sökord, även om endast 1L finns i lager, skapar besvikelse. Föredra förslag du faktiskt kan leverera idag.
Om du bygger autokomplettering och stavfelstolerans, lägg in en granskningsrutin: efter en försäljningsvecka, kontrollera nya toppfrågor, stigande felstavningar och nollträffsord. Även små säsongsförskjutningar (bröllopssäsong, monsuntid, tentaperioder) kan ändra vad folk skriver.
Vill du testa regeländringar snabbt kan Koder.ai hjälpa dig prototypa en sökregeltjänst och en admin‑sida för att hantera synonymer, enheter och varumärkesskydd, och sedan exportera koden när ni är redo.
Ett realistiskt exempel: fixa “jeera rice” och “zeera rice”
En kund skriver “zeera rice” och får noll träffar. De letar inte efter en annan produkt — de menade “jeera rice” (kumminris), men stavade som de uttalar det.
Du fixar detta med två små, säkra ändringar: en synonym för vanliga stavvarianter och en konservativ stavfelregel. För den här frågan behandla “zeera” som en translitterationsvariant av “jeera”, inte som en annan betydelse.
Här är en praktisk mappning som brukar fungera:
- Query synonym: zeera -> jeera
- Query synonym: zira -> jeera
- Behåll produktnamn i katalogen oförändrade (byt inte SKU‑namn)
Lägg sedan till en stavfelstoleransregel som är strikt på korta ord. Till exempel, tillåt 1 edit (en felaktig, saknad eller ombytt bokstav) endast när tokenlängden är 5+ tecken. Det fångar “jeera” vs “jeeraa” men undviker röriga träffar på väldigt korta token.
Efter ändringen bör autokomplettering vägleda kunden istället för att gissa för hårt. När de skriver “zee…” föreslå:
- “jeera rice”
- “jeera basmati rice”
- “jeera (cumin)”
Och när de skickar “zeera rice” ska resultaten visa dina “jeera rice”‑produkter först, plus relaterade artiklar som kummin och basmati beroende på rankningsregler.
En vecka senare, kontrollera sökanalysen med fokus på beteende, inte bara klick:
- Nollträffsfrekvens för “zeera”, “zira” och “jeera”
- Förfinslningsfrekvens (skrev användare om frågan?)
- Lägg‑i‑kundvagn efter sök för dessa frågor
- Toppklick för att bekräfta att synonymen inte drar in orelaterade artiklar
Om resultat blir sämre (till exempel att “zira” börjar matcha ett varumärke eller annan kategori), rollbacka snabbt genom att inaktivera just den synonymsgruppen, inte hela autokompletterings‑ eller stavfelsystemet. Håll konfigurationen versionshanterad så du kan återställa på minuter. Den här snabba feedbackloopen är kärnan i autokomplettering och stavfelstolerans för indisk e‑handelsökning.
Snabb checklista innan du rullar ut ändringar
Lansera under din domän
Kör dina interna verktyg på en egen domän som passar din e‑handelsdrift.
Innan du pushar nya synonymer, autokomplettering eller stavfelsinställningar, gör en snabb genomgång som blandar verkliga sökdata med praktiska tester. Det hindrar “hjälpsamma” ändringar från att skapa brusiga resultat.
Använd denna pre‑release‑checklista för autokomplettering och stavfelstolerans:
- Hämta dina topp 50 sökfrågor från de senaste 7–14 dagarna och gruppera dem efter avsikt (varumärke, generisk produkt, variant som storlek eller färg, och problem som “hair fall oil”). Om en fråga kan betyda två saker, notera båda.
- Hämta dina topp 50 nollträffsfrågor och bestäm åtgärd för varje: mappa till befintlig kategori, lägg till synonym (lokal term eller stavning), lägg till saknad produkt eller blockera om den är irrelevant. Lämna dem inte som “ska fixas senare”.
- Uppdatera din synonym‑ och translitterationslista med en ägare, senaste uppdateringsdatum och en kort förklaring. Detta förhindrar slumpmässiga redigeringar.
- Testa autokomplettering i dina toppkategorier med verkliga användarfraser: prova engelska, Hinglish och vanliga förkortningar. Kontrollera att förslag inte hoppar till nischprodukter för tidigt och att de inkluderar populära varianter (som “1kg”, “500g”, “pack of 2”).
- Stressa stavfelstoleransen med 20 knepiga frågor: varumärkesstavfel (särskilt dubbla bokstäver), blandade nummer (“iPhone 15 pro 256”) och liknande produkter (“jeera/zeera”, “besan/besan flour”). Bekräfta att toppresultaten fortfarande är korrekta.
Om något misslyckas, rulla ut en mindre ändring först. En strikt utbyggnad är bättre än en stor uppdatering som gör sökningen slumpmässig.
Nästa steg: en enkel utrullningsplan (och hur du bygger snabbare)
Börja med en kategori där sökproblemen är tydliga, till exempel dagligvaror, personlig vård eller mobiltillbehör. Håll omfånget litet under en vecka så du kan se orsak och verkan. Välj 2–3 framgångsmått du faktiskt kan påverka, som nollträffsfrekvens, sök‑till‑produkt‑klick och lägg‑i‑kundvagn efter sök.
En enkel utrullning som brukar fungera:
- Dag 1: Baslinje — fånga nuvarande metrik, toppfrågor och topp nollträffsfrågor för kategorin.
- Dag 2–3: Skicka en liten ordbok — lägg till ett begränsat set synonymer och Hinglish‑translitterationer för topp 50 frågor, plus topp 20 varumärkes‑ eller förpackningsmönster.
- Dag 4: Skyddsräcken — lägg till undantag där betydelsen ändras (t.ex. “atta” bör inte matcha “ATA” om det är ett varumärke eller kod i din katalog).
- Dag 5–6: Övervaka — följ vinster (färre nollträffar, fler klick) och förluster (fler irrelevanta klick, högre tillbaka‑sökning).
- Dag 7: Besluta — behåll, justera eller återställ och planera nästa omgång baserat på vad som förbättrades.
Gör ändringar återställningsbara. Behandla dina synonym‑ och stavfelsregler som kod: versionshantera dem, gör snapshots och ha en tydlig rollback‑väg. Om en ny regel plötsligt gör att “face wash” visar “dishwash liquid” ska du kunna återställa på minuter.
Ägarskap betyder mer än smarta regler. Tilldela en person för en 30‑minuters veckogenomgång: topp nya nollträffsfrågor, topp “bra räddningar” (korrigerade stavfel) och eventuella toppar i lågkvalitetsklick.
Om du vill bygga och iterera snabbare kan Koder.ai hjälpa dig implementera sök‑lagret med ett chattdrivet bygge, använda planeringsläge för att mappa regler och mått innan du rullar, och behålla exporterbar källkod så ditt team kan äga det långsiktigt. Det stödjer snapshots och rollback, vilket är idealiskt när en sökändring behöver snabb återgång.
Planera nästa iteration utifrån mätta resultat. Till exempel: om “zeera rice” började konvertera men “jeera” nu matchar orelaterade “zera”‑produkter, har du en tydlig nästa åtgärd: skärpa just den regeln, inte skriva om allt.