27 sep. 2025·8 min
Blue/Green & Canary-utrullningar: En tydlig release-strategi
Lär dig när du ska använda Blue/Green kontra Canary, hur trafikförskjutning fungerar, vad du bör övervaka och praktiska steg för utrullning och rollback för säkrare releaser.
Vad Blue/Green och Canary-utrullningar betyder
Att skicka ny kod är riskabelt av en enkel anledning: du vet inte riktigt hur den beter sig förrän riktiga användare börjar använda den. Blue/Green och Canary är två vanliga sätt att minska den risken samtidigt som du håller driftstopp nära noll.
Blue/Green enkelt förklarat
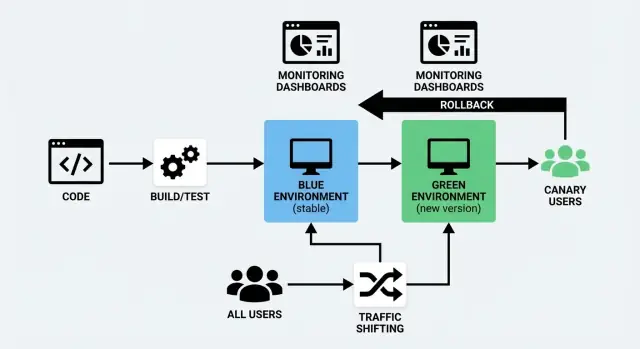
En blue/green-utrullning använder två separata men liknande miljöer:
- Blue: versionen som för närvarande servar användare (den “live” miljön).
- Green: en andra, redo-miljö där du deployar den nya versionen.
Du förbereder Green i bakgrunden—deployerar ny build, kör kontroller, värmer upp—sedan byter du trafik från Blue till Green när du är säker. Om något går fel kan du snabbt byta tillbaka.
Den viktiga idén är inte “två färger”, utan en ren, reversibel övergång.
Canary enkelt förklarat
En canary-release är en gradvis utrullning. Istället för att byta alla samtidigt skickar du den nya versionen till en liten andel användare först (till exempel 1–5%). Om allt ser sunt ut utökar du stegvis tills 100% av trafiken kör den nya versionen.
Huvudidén är att lära från verklig trafik innan du helt binder dig.
Det gemensamma målet: säkrare releaser med mindre driftstopp
Båda metoderna är strategier för att släppa ändringar utan att störa användare—men de skiljer sig i hur trafiken flyttas till den nya versionen.
- minska användarpåverkan när något går sönder
- stödja en utrullning utan driftstopp (eller så nära noll som ditt system tillåter)
- göra rollback mindre stressigt och mer förutsägbart
De gör detta på olika sätt: Blue/Green fokuserar på ett snabbt switch mellan miljöer, medan Canary fokuserar på kontrollerad exponering genom trafikomfördelning.
Ingen enskild “bäst” option
Ingen metod är automatiskt överlägsen. Rätt val beror på hur din produkt används, hur säker du är på dina tester, hur snabbt du behöver feedback och vilken typ av fel du försöker undvika.
Många team kombinerar dem—använder Blue/Green för enkelheten i infrastrukturen och Canary-tekniker för gradvis användarexponering.
I nästa avsnitt jämför vi dem direkt och visar när varje metod brukar fungera bäst.
Blue/Green vs Canary: Snabb jämförelse
Blue/Green och Canary är båda sätt att släppa ändringar utan att avbryta användare—men de skiljer sig i hur trafiken flyttas till den nya versionen.
Hur trafiken byter
Blue/Green kör två fulla miljöer: “Blue” (nuvarande) och “Green” (ny). Du verifierar Green och byter all trafik på en gång—som att slå om en kontrollerad strömbrytare.
Canary släpper den nya versionen till en liten andel användare först (till exempel 1–5%) och skiftar sedan gradvis trafik medan du observerar verklig prestanda.
För- och nackdelar som verkligen betyder något
| Faktor | Blue/Green | Canary |
|---|---|---|
| Hastighet | Mycket snabb övergång efter validering | Långsammare avsiktligt (stegvis utrullning) |
| Risk | Medellåg: en dålig release påverkar alla efter bytet | Lägre: problem visar sig ofta innan full utrullning |
| Komplexitet | Måttlig (två miljöer, ren switch) | Högre (trafikdelning, analys, gradvisa steg) |
| Kostnad | Högre (du dubblar kapacitet under utrullningen) | Ofta lägre (du kan rampa med befintlig kapacitet) |
| Bäst för | Stora, koordinerade förändringar | Frekventa, små förbättringar |
En enkel beslutsguide
Välj Blue/Green när du vill ha ett rent, förutsägbart tillfälle att byta—särskilt för större förändringar, migreringar eller releaser som kräver en tydlig “gammal vs ny” separation.
Välj Canary när du shippar ofta, vill lära av verklig användning säkert och föredrar att minska blast-radius genom att låta mätvärden styra varje steg.
Om du är osäker: börja med Blue/Green för operativ enkelhet och lägg till Canary för högre risktjänster när övervakning och rollback-vanor är på plats.
När Blue/Green är rätt val
Blue/Green är ett starkt val när du vill att releaser ska kännas som en “slagom-scenario”. Du kör två produktionslika miljöer: Blue (nuvarande) och Green (ny). När Green är verifierad routar du användarna dit.
Du behöver nära noll driftstopp
Om din produkt inte tål synliga underhållsfönster—kassan, bokningssystem, inloggade dashboards—hjälper Blue/Green eftersom den nya versionen startas, värms upp och kontrolleras innan riktiga användare skickas dit. Mest av “deploy-tiden” sker vid sidan om, inte inför kunderna.
Du vill ha den enklaste rollbacken möjligt
Rollback är ofta bara att routa tillbaka till Blue. Det är värdefullt när:
- en release måste vara reversibel inom minuter
- du vill undvika panik-fixar under press
- du behöver ett tydligt, repeterbart fel-svar
Nyckeln är att rollback inte kräver att bygga om eller redeploya—det är en trafik-switch.
Dina databasmigreringar kan hållas kompatibla
Blue/Green är enklast när databasmigreringar är bakåtkompatibla, eftersom Blue och Green för en kort stund kan samexistera (och båda kan läsa/skriva beroende på routing och job-setup).
Bra passningar inkluderar:
- additiva schemamodifieringar (nya nullable-kolumner, nya tabeller)
- utökade dataformat som gammal kod kan ignorera
Riskfyllda fall är att ta bort kolumner, byta namn på fält eller förändra betydelser—det kan bryta “switch-back”-garantin om du inte planerar flerstegs-migrationer.
Du har råd med dubbla miljöer och routing-kontroll
Blue/Green kräver extra kapacitet (två stackar) och en metod för att dirigera trafik (load balancer, ingress eller plattformsrouting). Om du redan har automation för att provisionera miljöer och en ren routing-spak blir Blue/Green ett praktiskt default för högförtroende, lågdramatisk utsläpp.
När Canary-releaser är mer lämpliga
En canary-release är en strategi där du rullar ut en ändring till en liten andel riktiga användare först, lär av vad som händer och sedan expanderar. Det är rätt val när du vill minska risk utan att stoppa världen för en stor "alla på en gång"-release.
Du har mycket trafik—och tydliga signaler
Canary fungerar bäst för trafikstarka appar eftersom redan 1–5% trafik kan ge meningsfull data snabbt. Om du redan mäter tydliga mätvärden (felkvot, latens, konvertering, kassa-slutföranden, API-timeouter) kan du validera releasen på verklig användning istället för enbart testmiljöer.
Du oroar dig för prestanda och edge-fall
Vissa problem visar sig bara under verklig belastning: långsamma databasfrågor, cache-missar, regional latens, ovanliga enheter eller sällsynta användarflöden. Med en canary kan du bekräfta att ändringen inte ökar fel eller försämrar prestanda innan den når alla.
Du behöver stegvisa utrullningar, inte ett enda cutover
Om din produkt levereras ofta, har flera team som bidrar eller innehåller förändringar som kan introduceras gradvis (UI-justeringar, prisexperiment, rekommendationslogik) passar canary naturligt. Du kan öka från 1% → 10% → 50% → 100% beroende på vad mätvärden visar.
Feature-flaggor är en del av din verktygslåda
Canary går särskilt bra ihop med feature-flaggor: du kan deploya kod säkert och sedan aktivera funktionalitet för en delmängd användare, regioner eller konton. Det gör rollback mindre dramatisk—ofta kan du bara stänga av flaggan istället för att göra en ny deploy.
Om du bygger mot progressiv leverans är canary ofta det mest flexibla startpunkten.
Se även: /blog/feature-flags-and-progressive-delivery
Trafikomfördelning i praktiken (utan jargong)
Trafikomfördelning innebär helt enkelt att styra vem som får den nya versionen av din app och när. Istället för att slå över alla på en gång flyttar du förfrågningar gradvis (eller selektivt) från den gamla versionen till den nya. Detta är den praktiska kärnan i både en blue/green-utrullning och en canary-release—och det är också vad som gör en utrullning utan driftstopp realistisk.
"Rattspaken": var trafiken routas
Du kan skifta trafik på några vanliga punkter i din stack. Rätt val beror på vad du redan kör och hur finstyrd kontroll du behöver.
- Load balancer: delar inkommande förfrågningar mellan två miljöer eller serverset.
- Ingress-controller (Kubernetes): routar trafik till olika Services baserat på regler.
- Service mesh: styr trafik mellan tjänster med precisa regler och bättre synlighet.
- CDN / edge-routing: användbart när du vill att routingbeslut sker nära användarna, ofta för webbtrafik.
Du behöver inte alla lager. Välj en "sanningens källa" för routingbeslut så att din release-hantering inte blir gissningslek.
Vanliga sätt att dela trafik
De flesta team använder ett (eller en mix) av dessa för trafikomfördelning:
- Procentbaserat: 1% → 5% → 25% → 50% → 100%. Klassisk canary.
- Header-baserat: routa förfrågningar med en specifik header (t.ex. från QA-verktyg eller interna testare) till nya versionen.
- Användarkohorter: flytta specifika grupper först—anställda, betatestare, en region eller en kundnivå.
Procent är enklast att förklara, men kohorter är ofta säkrare eftersom du kan kontrollera vilka användare som ser ändringen (och undvika att överraska dina största kunder i den första timmen).
Sessions och caches: två vanliga fallgropar
Två saker bryter ofta annars solida deployments:
Sticky sessions (session affinity). Om ditt system binder en användare till en server/version kanske en 10% trafikdelning inte beter sig som 10%. Det kan också orsaka förvirrande buggar när användare studsar mellan versioner mitt i en session. Använd delad sessionslagring eller säkerställ att routingen håller en användare konsekvent på en version om möjligt.
Cache-warming. Nya versioner träffar ofta kalla caches (CDN, applikationscache, databasfrågors cache). Det kan se ut som en prestandaregression även när koden är okej. Planera tid för att värma caches innan du ramar upp trafiken, särskilt för högtrafiksidor och kostsamma endpoints.
Gör trafikändringar till en kontrollerad operation
Behandla routing-ändringar som produktionsändringar, inte en ad-hoc knapptryckning.
Dokumentera:
- vem får ändra trafikdelningar
- hur det godkänns (on-call? release manager? ändringsärende?)
- var det görs (load balancer-config, ingressregler, mesh-policy)
- vad "stop" betyder (triggaren för att pausa utrullningen och följa rollback-planen)
Denna lilla governance förhindrar välmenande personer från att “bara nudda det till 50%” medan du fortfarande undersöker om canaryn är frisk.
Vad du ska övervaka under en utrullning
Genomför en release-övning
Bygg ett arbetsflöde, driftsätt det och öva en rollback så release-dagen känns lugn.
En utrullning är inte bara “gick deployen igenom?” Det är “får riktiga användare en sämre upplevelse?” Det enklaste sättet att hålla sig lugn under Blue/Green eller Canary är att titta på en liten uppsättning signaler som berättar: är systemet hälsosamt, och skadar ändringen kunderna?
Fyra kärnsignaler: fel, latens, saturation, användarpåverkan
Felkvot: Följ HTTP 5xx, request-fel, timeouter och beroendefel (databas, betalningar, tredjeparts-API). En canary som ökar ”små” fel kan ändå skapa mycket supportarbete.
Latens: Titta på p50 och p95 (och p99 om du har det). En ändring som håller genomsnittlig latens stabil kan fortfarande skapa långsvans-förseningar som användarna känner.
Saturation: Se hur ”fullt” ditt system är—CPU, minne, disk IO, DB-anslutningar, kö-djup, trådpooler. Saturationsproblem visar sig ofta före fulla outage.
Användarpåverkanssignaler: Mät vad användare faktiskt upplever—kassa-fel, inloggningsframgång, sökresultat, appkrascher, laddningstider för nyckelsidor. Dessa är ofta mer meningsfulla än infrastrukturstatistik ensam.
Bygg en "release-dashboard" som alla kan läsa
Skapa en liten dashboard som får plats på en skärm och delas i din release-kanal. Håll den konsekvent över varje utrullning så folk inte slösar tid på att leta efter grafer.
Inkludera:
- felkvot (totalt + nyckelendpoints)
- latens (p50/p95 för kritiska vägar)
- saturation (topp 3 begränsningar för din stack, t.ex. app-CPU, DB-anslutningar, kö-djup)
- användarpåverkan-KPI:er (dina 1–3 mest affärskritiska flöden)
Om du kör en canary-release, segmentera mätvärden efter version/instansgrupp så du kan jämföra canary vs baseline direkt. För blue/green-utrullning, jämför den nya miljön mot den gamla under cutover-fönstret.
Sätt tydliga trösklar för paus/rollback-beslut
Bestäm reglerna innan du börjar flytta trafik. Exempeltrösklar kan vara:
- felkvot ökar med X% över baseline under Y minuter
- p95-latens överstiger en fast gräns (eller stiger X% över baseline)
- en användarpåverkans-KPI faller under en miniminivå
De exakta siffrorna beror på din tjänst, men det viktiga är samsyn. Om alla vet rollback-planen och triggarna undviker du debatt medan kunder påverkas.
Alerts som fokuserar på utrullningsfönstret
Lägg till (eller skärp temporärt) alerts särskilt under utrullningsfönster:
- oväntade toppar i 5xx/timeouter
- plötslig latensregression på nyckelvägar
- snabb ökning i saturation-signaler (anslutningspooler, köer)
Håll alerts åtgärdbara: “vad förändrades, var, och vad gör du härnäst.” Om dina alerts är högljudda missas den signal som verkligen betyder något när trafikomfördelning pågår.
Förkontroller som fångar problem tidigt
De flesta utrullningsfel orsakas inte av stora buggar. De orsakas av små mismatchningar: en saknad config, en dålig databasmigration, ett utgånget certifikat eller en integration som beter sig annorlunda i den nya miljön. Förkontroller är din chans att upptäcka de problemen medan blast-radius fortfarande är nära noll.
Börja med health checks och smoke tests
Innan du flyttar någon trafik (oavsett blue/green eller liten canary), bekräfta att den nya versionen i grunden är vid liv och kan svara på förfrågningar.
- Säkerställ att appens health endpoints rapporterar OK (inte bara att processen körs)
- Validera beroenden: databas, cache, köer, object storage, e-post/SMS-leverantörer
- Bekräfta att hemligheter och miljövariabler finns och är korrekt scope:ade
Kör snabba end-to-end-tester mot den nya miljön
Unit-tester är bra, men de bevisar inte att det deployade systemet fungerar. Kör en kort, automatiserad end-to-end-svit mot den nya miljön som avslutas på minuter, inte timmar.
Fokusera på flöden som korsar servicelagren (webb → API → databas → tredjepart) och inkludera åtminstone en "riktig" förfrågan per nyckelintegration.
Verifiera kritiska användarresor (de som betalar räkningarna)
Automatiska tester missar ibland det uppenbara. Gör en riktad, människovänlig verification av era kärnflöden:
- inloggning och lösenordsåterställning
- checkout eller betalningsflöde (inklusive felvägar)
- grundläggande "create / update / delete"-åtgärder som användare gör dagligen
Om ni stödjer flera roller (admin vs kund), prova åtminstone en resa per roll.
Behåll en pre-release-checklista
En checklista omvandlar tyst kunskap till en repeterbar strategi. Håll den kort och handlingsbar:
- databasmigrationer applicerade och reversibla (eller tydligt säkra)
- observability redo: logs, dashboards, alerts för nyckelmått
- rollback-plan genomgången (vem, hur och vad "stop" innebär)
När dessa kontroller är rutin blir trafikomfördelning ett kontrollerat steg—inte ett hopp i mörkret.
Blue/Green-utrullning: En praktisk playbook
Äg din release-väg
Ha kontroll genom att kunna exportera källkoden när som helst.
En blue/green-utrullning är enklast att genomföra när du behandlar den som en checklista: förbered, deploya, validera, byt, observera, och städa upp.
1) Deploaya till Green (utan att röra användarna)
Skicka den nya versionen till Green medan Blue fortsätter att serva riktig trafik. Håll konfigurationer och hemligheter i linje så Green är en sann spegel.
2) Validera Green innan du byter trafik
Gör snabba, högsignal-kontroller först: appen startar rent, nyckelsidor laddas, betalningar/inloggning fungerar och loggar ser normala ut. Kör automatiska smoke-tester om du har dem. Detta är också stunden att verifiera att övervakningsdashboards och alerts är aktiva för Green.
3) Planera databasmigrationer på ett säkert sätt (expand/contract)
Blue/Green blir knepigt när databasen förändras. Använd en expand/contract-metod:
- Expand: lägg till nya kolumner/tabeller på ett bakåtkompatibelt sätt.
- Deploaya Green så den kan fungera med både gammal och ny schema.
- Contract: ta bort gamla fält först efter att Blue är pensionerad och du är säker på att den nya koden är stabil.
Detta undviker ett "Green fungerar, Blue fallerar"-scenario under bytet.
4) Värm caches och hantera bakgrundsjobb
Före switchen, värm kritiska caches (startsida, vanliga frågor) så användare slipper betala för en "cold start". För bakgrundsjobb/cron-workers, bestäm vem som kör dem:
- kör jobb i en miljö endast under cutover för att undvika dubbelbearbetning
5) Byt trafik och observera
Vrid routing från Blue till Green (load balancer/DNS/ingress). Titta på felkvot, latens och affärsmått under ett kort fönster.
6) Verifiera efter bytet och städa upp
Gör en verklig-användar-stil spotcheck, håll sedan Blue tillgänglig en kort stund som fallback. När det är stabilt, stäng av Blue-jobb, arkivera loggar och ta ner Blue för att minska kostnader och förvirring.
Canary-utrullning: En praktisk playbook
Canary handlar om att lära sig säkert. Istället för att skicka alla användare till den nya versionen exponerar du en liten del av verklig trafik, tittar noga, och utökar först när du ser bevis. Målet är inte att "gå långsamt"—det är att "bevisa att det är säkert" med bevis i varje steg.
En enkel rampplan (1–5% → 25% → 50% → 100%)
- Förbered canaryn
Deploaya den nya versionen bredvid den stabila versionen. Se till att du kan routa en definierad procent av trafiken till vardera och att båda versionerna syns i övervakningen (separata dashboards eller taggar hjälper).
- Steg 1: 1–5%
Börja litet. Här visar sig ofta uppenbara problem snabbt: brutna endpoints, saknade konfigurationer, databasmigrationsöverraskningar eller oväntade latensspikar.
Håll anteckningar för steget:
- vad som ändrades i releasen (inklusive "små" config-ändringar)
- vad du förväntade dig
- vad du observerade (fel, latens, användarpåverkan)
- Steg 2: 25%
Om första steget är rent, öka till cirka en fjärdedel av trafiken. Nu ser du mer verklig variation: olika användarbeteenden, långsvans-enheter, edge-fall och högre samtidighet.
- Steg 3: 50%
Halv trafik är där kapacitets- och prestandaproblem blir tydligare. Om du når en skalningsgräns ser du ofta tidiga varningssignaler här.
- Steg 4: 100% (promotion)
När mätvärdena är stabila och användarpåverkan acceptabel, flytta all trafik till den nya versionen och deklarera den som promoverad.
Välja rampintervaller (hur länge stanna i varje steg)
Tidsåtgång per steg beror på risk och trafikvolym:
- Hög-riskändring eller låg trafik: vänta längre per steg för att få tillräckligt med signal (t.ex. 30–60 minuter eller mer). Lågtrafiktjänster kan behöva timmar för meningsfulla mönster.
- Låg-riskändring med hög trafik: kortare steg funkar (t.ex. 5–15 minuter), eftersom du samlar data snabbt.
Tänk också på affärscykler. Om er produkt har toppar (lunch, helger, faktureringskörningar) kör canaryn tillräckligt länge för att täcka de förhållanden som brukar orsaka problem.
Automatisera promotion och rollback
Manuella utrullningar skapar tvekan och inkonsekvens. Automatisera där det är möjligt:
- promovation när nyckelmått ligger inom trösklar under ett definierat fönster
- rollback när trösklar överskrids (t.ex. felkvot eller latens)
Automation tar inte bort mänskligt omdöme—den tar bort fördröjning.
Behandla varje steg som ett experiment
För varje rampsteg, skriv ner:
- ändringssammanfattning (vad som är annorlunda)
- succeskriterier (vilka mått måste vara stabila)
- observerade resultat (vad du såg, inklusive "inget ovanligt")
- beslut (promotera, håll eller rollback) och varför
Dessa anteckningar förvandlar din utrullningshistorik till en playbook för nästa release—och gör framtida incidenter mycket enklare att utreda.
Rollback-planer och felhantering
Rollback är enklare när du bestämmer i förväg vad som räknas som "dåligt" och vem som får trycka på knappen. En rollback-plan är inte pessimism—det är hur du hindrar små problem från att bli långvariga outage.
Definiera tydliga rollback-triggers
Välj en kort lista signaler och sätt explicita trösklar så ni inte börjar debattera under en incident. Vanliga triggers inkluderar:
- felkvot: toppar i 5xx, misslyckade kassor, inloggningsfel eller API-timeouter
- latens: p95/p99 över en överenskommen gräns under ett varaktigt fönster (t.ex. 5–10 minuter)
- affärs-KPI:er: plötsliga fall i konvertering, betalningsframgång, registreringar eller ökning av avbokningar
Gör trigern mätbar ("p95 > 800ms i 10 minuter") och knyt den till en ägare (on-call, release manager) med befogenhet att agera omedelbart.
Håll rollback snabb (och tråkig)
Hastighet är viktigare än elegans. Din rollback bör vara en av dessa:
- vänd trafikförskjutningen (typiskt för blue/green och canary): flytta trafik tillbaka till föregående, kända bra version
- re-deploya föregående version: om infrastrukturen ändrats, pusha senaste stabila build och kör hälsokontroller igen
Undvik "manuellt fixa och fortsätt utrullningen" som första åtgärd. Stabilsera först, undersök sen.
Planera för partiella utrullningar
Med canary kan vissa användare ha skapat data under den nya versionen. Bestäm i förväg:
- routas "canary"-användare tillbaka omedelbart, eller hålls de kvar på canaryn medan ni undersöker?
- om dataformat ändrats, är databasen bakåtkompatibel? Om inte kan rollback kräva särskild mitigering.
Efterhandsgranskning som förbättrar nästa release
När allt är stabilt, skriv en kort efterhandsrapport: vad utlöste rollbacken, vilka signaler saknades, och vad ni ska ändra i checklistan. Behandla det som en produktförbättringscykel för er release-process, inte en skuldbeläggning.
Feature-flaggor och progressiv leverans
Lansera din nästa tjänst
Förvandla din nästa serviceidé till en riktig app via chat—utan lång uppsättning.
Feature-flaggor låter dig separera "deploy" (skicka kod till produktion) från "release" (aktivera den för användare). Det är stort eftersom du kan använda samma pipeline—blue/green eller canary—samtidigt som du styr exponeringen med en enkel switch.
Deploya utan press, gör release med avsikt
Med flaggor kan du merge:a och deploaya säkert även om en funktion inte är redo för alla. Koden finns på plats men är inaktiv. När du är säker aktiverar du flaggan gradvis—ofta snabbare än att pusha en ny build—och om något går fel kan du avaktivera den lika snabbt.
Målstyrd aktivering (inte allt-eller-inget)
Progressiv leverans handlar om att öka tillgång i avsiktliga steg. En flagga kan aktiveras för:
- en specifik användargrupp (intern personal, betatestare, betalande nivå)
- en region (börja i ett land eller datacenter)
- en procent av användarna (1% → 10% → 50% → 100%)
Detta är särskilt användbart när en canary säger att den nya versionen är hälsosam, men du fortfarande vill hantera funktionens risk separat.
Styrmekanismer som förhindrar "flag-debt"
Feature-flaggor är kraftfulla, men bara om de styrs. Några skydd håller dem ordnade och säkra:
- ägarskap: varje flagga har ett ansvarigt team eller person
- utgångsdatum: sätt ett borttagningsdatum (eller granskningsdatum) så gamla flaggor inte samlas på hög
- dokumentation: skriv vad flaggan gör, vem den påverkar och hur man rollbackar
En praktisk regel: om någon inte kan svara på "vad händer om vi stänger av det här?" är flaggan inte redo.
För djupare vägledning om att använda flaggor i en release-strategi, se /blog/feature-flags-release-strategy.
Hur du väljer strategi och kommer igång
Att välja mellan blue/green och canary handlar inte om "vilken som är bäst". Det handlar om vilken typ av risk du vill kontrollera och vad du realistiskt kan hantera med ditt nuvarande team och verktyg.
Ett snabbt sätt att bestämma
Om din högsta prioritet är ett rent, förutsägbart cutover och en enkel "tillbaka till gammal version"-knapp, passar blue/green oftast bäst.
Om din högsta prioritet är att minska blast-radius och lära av verklig användartrafik innan du går vidare, är canary ett säkrare val—särskilt när ändringar är frekventa eller svåra att fullt testa i förväg.
En praktisk regel: välj den metod ditt team kan köra konsekvent klockan 02:00 när något går fel.
Börja smått: pilota en sak
Välj en tjänst (eller ett användargränssnitt) och kör en pilot under några releaser. Välj något tillräckligt viktigt för att det spelar roll, men inte så kritiskt att alla parar ihop sig. Målet är att bygga vana kring trafikomfördelning, övervakning och rollback.
Skriv ett enkelt runbook (och tilldela ägarskap)
Håll det kort—en sida räcker:
- vad "bra" ser ut som (nyckelmått och trösklar)
- vem som är ansvarig under en utrullning
- hur man pausar, rollbackar och kommunicerar
Gör ägarskapet tydligt. En strategi utan ägare blir bara ett förslag.
Använd det du redan har först
Innan du lägger till nya plattformar, titta på verktygen du redan använder: load balancer-inställningar, deploy-skript, befintlig övervakning och er incidentprocess. Lägg till ny verktygssvit bara när det faktiskt tar bort friction ni upplevt i piloten.
Om ni snabbt bygger och levererar nya tjänster kan plattformar som kombinerar appgenerering med driftsättningskontroller också minska operativt arbete. Till exempel är Koder.ai en vibe-coding-plattform som låter team skapa webb-, backend- och mobilappar från en chatt och sedan driftsätta och hosta dem med praktiska säkerhetsfunktioner som snapshots och rollback, plus stöd för custom domains och export av källkod. De funktionerna stämmer väl överens med artikelns huvudmål: gör releaser repeterbara, observerbara och reversibla.
Föreslagna nästa steg
Om du vill se implementeringsalternativ och stödda arbetsflöden, granska /pricing och /docs/deployments. Schemalägg sedan din första pilotrelease, fånga vad som fungerade och iterera på runbooken efter varje utrullning.