02 okt. 2025·8 min
Brendan Burns och Kubernetes: idéer som formade orkestrering
En praktisk genomgång av Brendan Burns’ idéer under Kubernetes‑eran—deklarativt önskat tillstånd, controllers, skalning och tjänstedrift—och varför de blev standard.
En praktisk genomgång av Brendan Burns’ idéer under Kubernetes‑eran—deklarativt önskat tillstånd, controllers, skalning och tjänstedrift—och varför de blev standard.
Kubernetes introducerade inte bara ett nytt verktyg—det förändrade hur ”daglig drift” ser ut när du kör tiotals (eller hundratals) tjänster. Före orkestrering satte team ofta samman skript, manuella runbooks och tribal knowledge för att svara på samma återkommande frågor: Var ska den här tjänsten köras? Hur rullar vi ut en ändring säkert? Vad händer när en nod dör klockan 02:00?
I grunden är orkestrering koordineringslagret mellan din avsikt ("kör den här tjänsten så här") och maskinernas stökiga verklighet—noder som fallerar, trafik som skiftar och kontinuerliga driftsättningar. Istället för att behandla varje server som en unik snöflinga, ser orkestrering compute som en pool och arbetslaster som schemaläggbara enheter som kan flyttas.
Kubernetes populariserade en modell där team beskriver vad de vill ha, och systemet kontinuerligt arbetar för att få verkligheten att matcha den beskrivningen. Denna förskjutning är viktig eftersom den gör drift mindre av en hjälteinsats och mer om upprepbara processer.
Kubernetes standardiserade operativa utfall som de flesta serviceteam behöver:
Den här artikeln fokuserar på idéerna och mönstren kopplade till Kubernetes (och ledare som Brendan Burns), inte en personlig biografi. När vi pratar om "hur det började" eller "varför det designades så" bör påståenden grundas i offentliga källor—konferensföredrag, design‑dokument och upstream‑dokumentation—så berättelsen förblir verifierbar snarare än mytisk.
Brendan Burns är allmänt erkänd som en av de tre ursprungliga medgrundarna av Kubernetes, tillsammans med Joe Beda och Craig McLuckie. I det tidiga Kubernetes‑arbetet på Google bidrog Burns till både den tekniska riktningen och hur projektet förklarades för användare—särskilt kring ”hur man driver programvara” snarare än bara ”hur man kör containers”. (Källor: Kubernetes: Up & Running, O’Reilly; Kubernetes‑projektets AUTHORS/maintainers‑listor)
Kubernetes släpptes inte som ett färdigt internt system; det byggdes öppet med en växande grupp bidragsgivare, användningsfall och begränsningar. Denna öppenhet pressade projektet mot gränssnitt som kunde överleva i olika miljöer:
Detta samarbetstryck är viktigt eftersom det påverkade vad Kubernetes optimerade för: delade primitiv och upprepbara mönster som många team kunde enas om, även om de var oense om verktyg.
När folk säger att Kubernetes "standardiserade" driftsättning och drift menar de vanligtvis inte att allt blev identiskt. De menar att det gav ett gemensamt vokabulär och en uppsättning arbetsflöden som kan upprepas över team:
Denna delade modell gjorde det enklare för dokumentation, verktyg och team‑praxis att överföras från ett företag till ett annat.
Det är användbart att skilja på Kubernetes (open‑source‑projektet) och Kubernetes‑ekosystemet.
Projektet är kärn‑API:erna och kontrollplane‑komponenterna som implementerar plattformen. Ekosystemet är allt som växte runt det—distributioner, managed services, tillägg och angränsande CNCF‑projekt. Många verkliga "Kubernetes‑funktioner" som folk litar på (observability‑stackar, policylösningar, GitOps‑verktyg) lever i det ekosystemet, inte i kärnprojektet självt.
Deklarativ konfiguration är ett enkelt byte i hur du beskriver system: istället för att lista steg att ta, säger du vad du vill ha som slutresultat.
I Kubernetes‑termer säger du inte åt plattformen "starta en container, öppna en port, starta om om den kraschar." Du deklarerar "det ska finnas tre kopior av den här appen igång, nåbar på den här porten, med den här containerimagen." Kubernetes tar ansvar för att få verkligheten att matcha den deklarationen.
Imperativa operationer liknar en runbook: en sekvens kommandon som fungerade förra gången, körs igen när något förändras.
Önskat tillstånd är närmare ett kontrakt. Du sparar den avsedda utgången i en konfigurationsfil, och systemet arbetar kontinuerligt för att uppnå det. Om något glider ur fas—en instans dör, en nod försvinner, en manuell ändring smyger sig in—upptäcker plattformen mismatchen och korrigerar den.
Före (imperativ runbook‑tänk):
Denna metod fungerar, men det är lätt att få "snöflingservrar" och en lång checklista som bara några få litar på.
Efter (deklarativt önskat tillstånd):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Du ändrar filen (t.ex. uppdaterar image eller replicas), applicerar den, och Kubernetes' controllers jobbar för att göra det som deklarerats till verklighet.
Deklarativt önskat tillstånd minskar operationellt slit genom att förvandla "gör de här 17 stegen" till "håll det så här." Det minskar också konfigurationsdrift eftersom sanningskällan är tydlig och granskbar—ofta i versionskontroll—så överraskningar blir lättare att hitta, auditera och rulla tillbaka på ett konsekvent sätt.
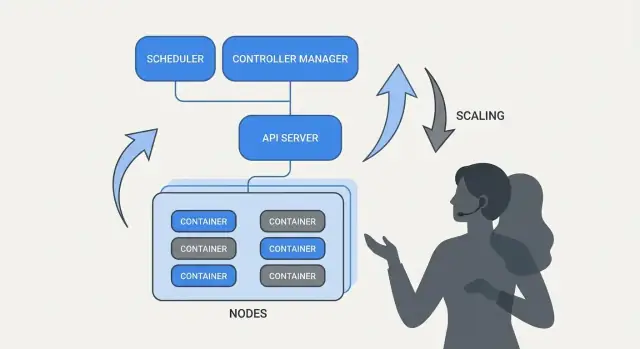
Kubernetes upplevs som "självhanterande" eftersom det bygger på ett enkelt mönster: du beskriver vad du vill ha, och systemet arbetar kontinuerligt för att få verkligheten att matcha den beskrivningen. Motorn i det mönstret är controllern.
En controller är en loop som bevakar det aktuella tillståndet i klustret och jämför det med det önskade tillstånd du deklarerat i YAML (eller via API). När den ser ett gap tar den åtgärder för att minska det.
Det är inte ett engångsskript och den väntar inte på att en människa ska klicka; den körs upprepade gånger—observera, bestäm, agera—så att den kan reagera på förändringar när som helst.
Den upprepade jämför‑och‑korrigera‑beteendet kallas reconciliation. Det är mekanismen bakom det vanliga löftet om "självläkning." Systemet förhindrar inte magiskt fel; det upptäcker drift och korrigerar den.
Drift kan ske av triviala skäl:
Reconciliation innebär att Kubernetes behandlar dessa händelser som signaler att kontrollera din avsikt och återställa den.
Controllers översätts till välkända operativa resultat:
Nyckeln är att du inte jagar symptom manuellt. Du deklarerar målet, och kontrolllooparna gör det kontinuerliga arbetet att "hålla det så."
Detta tillvägagångssätt begränsas inte till en resurstyp. Kubernetes använder samma controller‑och‑reconciliation‑idé över många objekt—Deployments, ReplicaSets, Jobs, Nodes, endpoints med flera. Denna konsekvens är en stor anledning till att Kubernetes blev en plattform: när du förstår mönstret kan du förutse hur systemet beter sig när du lägger till nya kapabiliteter (inklusive custom resources som följer samma loop).
Om Kubernetes bara gjorde "köra containers" skulle team fortfarande behöva ta det svåraste beslutet: var varje arbetslast ska köras. Schemaläggning är det inbyggda systemet som placerar Pods på rätt noder automatiskt, baserat på resursbehov och regler du definierar.
Det spelar roll eftersom placeringsbeslut direkt påverkar upptid och kostnad. En webbtjänst på en överbelastad nod kan bli långsam eller krascha. Ett batchjobb nära latenskänsliga tjänster kan skapa noisy‑neighbor‑problem. Kubernetes gör detta till en upprepbar produktkapacitet istället för ett spreadsheet‑och‑SSH‑rutiner.
På grundläggande nivå letar schemaläggaren efter noder som kan tillfredsställa en Pods krav.
Denna vana—att sätta realistiska requests—minskar ofta "slumpmässig" instabilitet eftersom kritiska tjänster slutar konkurrera med allt annat.
Utöver resurser förlitar sig de flesta produktionskluster på några praktiska regler:
Schemaläggningsfunktioner hjälper team att koda in driftavsikt:
Den praktiska slutsatsen: behandla schemaläggningsregler som produktkrav—skriv ner dem, granska dem och tillämpa dem konsekvent—så att tillförlitlighet inte beror på att någon minns "rätt nod" klockan 02:00.
En av Kubernetes mest praktiska idéer är att skalning inte ska kräva ändringar i applikationskoden eller en ny driftsättningsmetod. Om appen kan köras som en container kan samma arbetslastefinition oftast växa till hundratals eller tusentals kopior.
Kubernetes separerar skalning i två relaterade beslut:
Den uppdelningen spelar roll: du kan begära 200 pods, men om klustret bara har plats för 50 blir "skalning" en kö av väntande arbete.
Kubernetes använder vanligtvis tre autoscalers, var och en fokuserad på en annan spak:
Tillsammans gör detta skalning till policy: "håll latens stabil" eller "håll CPU runt X%", istället för ett manuellt pagingscenario.
Skalning fungerar bara så bra som insignalernas kvalitet:
Två misstag dyker upp ofta: skala på fel metric (CPU låg medan requests time‑out:ar) och saknade resursrequests (autoscalers kan’t planera kapacitet, pods packas för tätt och prestanda blir inkonsekvent).
En stor förskjutning som Kubernetes populariserade är att se "driftsättning" som ett pågående kontrollproblem, inte ett engångsskript du kör klockan 17 på fredagen. Rollouts och rollbacks är förstklassiga beteenden: du deklarerar vilken version du vill ha, och Kubernetes flyttar systemet mot den samtidigt som den kontinuerligt kontrollerar om ändringen är säker.
Med en Deployment är en rollout en gradvis ersättning av gamla Pods med nya. Istället för att stoppa allt och starta om kan Kubernetes uppdatera i steg—behålla kapacitet samtidigt som den nya versionen visar att den klarar verklig trafik.
Om den nya versionen börjar misslyckas är rollback ingen nödförfarande. Det är en normal operation: du kan återgå till en tidigare ReplicaSet (senast kända goda version) och låta controllern återställa det gamla tillståndet.
Hälsokontroller är vad som gör rollouts från "hopp‑baserade" till mätbara.
Används rätt minskar probes falska framgångar—driftsättningar som ser bra ut eftersom Pods startade, men som i själva verket misslyckas i förfrågningar.
Kubernetes stödjer en rullande uppdatering ur lådan, men team lägger ofta lager ovanpå:
Säkra driftsättningar beror på signaler: fel‑frekvens, latens, saturation och användarpåverkan. Många team kopplar rollout‑beslut till SLO:er och error budgets—om en canary förbrukar för mycket budget stoppas promotion.
Målet är automatiserade rollback‑triggers baserade på verkliga indikatorer (misslyckade readiness, stigande 5xx, latensspikar), så att "rollback" blir ett förutsägbart systemsvar—inte en nattlig hjälteinsats.
En containerplattform känns bara "automatisk" om andra delar av systemet fortfarande kan nå din app efter att den flyttat. I produktionskluster skapas, tas bort, reschemaläggs och skalas pods hela tiden. Om varje förändring krävde att IP‑adresser uppdaterades i konfigurationer skulle drift bli konstant manuellt arbete—och avbrott skulle vara rutin.
Tjänsteupptäckt handlar om att ge klienter ett pålitligt sätt att nå en föränderlig mängd backends. I Kubernetes är den stora förändringen att du slutar rikta enskilda instanser ("anropa 10.2.3.4") och istället riktar en namngiven tjänst ("anropa checkout"). Plattformen hanterar vilka pods som just nu svarar för det namnet.
En Service är en stabil entré för en grupp pods. Den har ett konsekvent namn och en virtuell adress i klustret, även när de underliggande pods ändras.
En selector avgör vilka pods som är "bakom" den entrén. Oftast matchar den labels, som app=checkout.
Endpoints (eller EndpointSlices) är den levande listan av faktiska pod‑IP:er som för närvarande matchar selectorn. När pods skalar upp, rullar ut eller reschemaläggs uppdateras listan automatiskt—klienter fortsätter använda samma Service‑namn.
Operationellt ger detta:
För north–south‑trafik (från utanför klustret) används vanligtvis en Ingress eller den nyare Gateway‑metoden. Båda ger en kontrollerad ingångspunkt där du kan routa efter hostname eller path och ofta centralisera t.ex. TLS‑terminering. Poängen är densamma: håll extern åtkomst stabil medan backends förändras under ytan.
"Självläkning" i Kubernetes är ingen magi. Det är en uppsättning automatiska reaktioner på fel: starta om, reschemalägga och ersätta. Plattformen bevakar det du sagt att du vill ha (ditt önskade tillstånd) och puttar kontinuerligt verkligheten tillbaka mot det.
Om en process avslutas eller en container blir ohälsosam kan Kubernetes starta om den på samma nod. Detta drivs vanligtvis av:
Ett vanligt produktionsmönster är: en container kraschar → Kubernetes startar om den → din Service routar endast till hälsosamma Pods.
Om en hel nod går ner (hårdvarufel, kernel panic, nätverksbortfall) upptäcker Kubernetes noden som otillgänglig och börjar flytta arbete annanstans. Högnivå:
Detta är självläkning på klusternivå: systemet ersätter kapacitet istället för att vänta på att en människa ska SSH:a in.
Självläkning spelar roll bara om du kan verifiera det. Team brukar övervaka:
Även med Kubernetes kan "läkningen" misslyckas om skyddsräcken är fel:
När självläkning är korrekt konfigurerad blir avbrott mindre och kortare—och viktigast av allt, mätbara.
Kubernetes vann inte bara för att det kunde köra containers. Det vann för att det erbjöd standardiserade API:er för de vanligaste operativa behoven—driftsättning, skalning, nätverk och observation. När team enas om samma "form" på objekt (som Deployments, Services, Jobs) kan verktyg delas mellan organisationer, utbildning blir enklare och överlämningar mellan dev och ops slutar bero på tribal knowledge.
Ett konsekvent API betyder att din driftsättningspipeline inte behöver kunna varje apps egenheter. Den kan utföra samma åtgärder—skapa, uppdatera, rulla tillbaka och kontrollera hälsa—med samma Kubernetes‑begrepp.
Det förbättrar också alignment: säkerhetsteam kan uttrycka guardrails som policies; SREs kan standardisera runbooks kring vanliga hälsosignaler; utvecklare kan resonera om releaser med ett gemensamt vokabulär.
"Plattformsförskjutningen" blir tydlig med Custom Resource Definitions (CRDs). En CRD låter dig lägga till en ny typ av objekt i klustret (t.ex. Database, Cache eller Queue) och hantera det med samma API‑mönster som inbyggda resurser.
En Operator parar dessa custom objects med en controller som kontinuerligt reconciler verkligheten med det önskade tillståndet—hanterar uppgifter som tidigare var manuella, som backup, failover eller versionsuppgraderingar. Nyckelfördelen är inte magisk automation; det är återanvändningen av samma kontrollslinga som Kubernetes använder överallt.
Eftersom Kubernetes är API‑drivet integreras det väl med moderna arbetsflöden:
Om du vill ha mer praktiska guider om driftsättning och drift baserade på dessa idéer, bläddra i /blog.
De största Kubernetes‑idéerna—många kopplade till Brendan Burns tidiga formuleringar—översätts väl även om du kör på VMs, serverless eller en mindre containerlösning.
Skriv ner det "önskade tillståndet" och låt automation upprätthålla det. Oavsett om det är Terraform, Ansible eller en CI‑pipeline, behandla konfiguration som sanningskälla. Resultatet blir färre manuella driftsättningssteg och färre "det fungerade på min maskin"‑överraskningar.
Använd reconciliation, inte engångsskript. Istället för skript som körs en gång och hoppas på bästa, bygg slingor som kontinuerligt verifierar viktiga egenskaper (version, konfig, antal instanser, hälsa). Det är så du får upprepbar drift och förutsägbar återhämtning efter fel.
Gör schemaläggning och skalning till explicita produktfunktioner. Definiera när och varför du lägger till kapacitet (CPU, ködjup, latens‑SLO:er). Även utan Kubernetes‑autoscaling kan team standardisera skalregler så tillväxt inte kräver omskrivning eller att någon väcks.
Standardisera rollouts. Rullande uppdateringar, health checks och snabba rollback‑rutiner minskar risk. Detta går att implementera med lastbalanserare, feature flags och pipelines som portar releaser baserat på verkliga signaler.
Dessa mönster fixar inte dålig appdesign, osäkra datamigrationer eller kostkontroll. Du behöver fortfarande versionshanterade API:er, migrationsplaner, budgetgränser och observability som kopplar driftsättningar till kundpåverkan.
Välj en kundvänd tjänst och implementera checklistan end‑to‑end, expandera sedan.
Om du bygger nya tjänster och vill nå "något driftsättbart" snabbare kan Koder.ai hjälpa dig generera en fullständig webb/backend/mobil‑app från en chattstyrd spec—vanligtvis React på frontend, Go med PostgreSQL på backend och Flutter för mobil—och sedan exportera källkoden så att du kan tillämpa samma Kubernetes‑mönster som diskuteras här (deklarativa konfigurationer, upprepbara rollouts och rollback‑vänlig drift). För team som utvärderar kostnad och styrning kan ni också granska /pricing.
Orkestrering koordinerar din avsikt (vad som ska köras) med verklig churn (nodfel, rullande driftsättningar, skalningshändelser). Istället för att hantera individuella servrar hanterar du arbetslaster och låter plattformen placera, starta om och ersätta dem automatiskt.
I praktiken minskar det:
Deklarativ konfiguration uttrycker det slutliga resultatet du vill ha (t.ex. “3 repliker av denna image, exponerad på denna port”), inte en steg‑för‑steg‑procedur.
Fördelar du kan använda direkt:
Controllers är kontinuerligt körande kontrollslingor som jämför aktuell status mot önskat tillstånd och agerar för att minska gapet.
Detta är varför Kubernetes kan "självhantera" vanliga utfall:
Schemaläggning bestämmer var varje Pod ska köras baserat på begränsningar och tillgänglig kapacitet. Utan styrning riskerar du noisy neighbors, hotspots eller att repliker hamnar på samma nod.
Vanliga regler för att koda driftavsikt:
Requests talar om för schemaläggaren vad en Pod behöver; limits sätter en övre gräns för vad den får använda. Utan realistiska requests blir placering gissning, vilket ofta leder till instabilitet.
Ett praktiskt första steg:
En Deployment‑rollout ersätter gamla Pods med nya stegvis och försöker bibehålla tillgänglighet.
För att hålla rollouts säkra:
Kubernetes erbjuder rullande uppdateringar som standard, men team lägger ofta på fler mönster:
Välj efter risktolerans, trafikmönster och hur snabbt ni kan detektera regressioner (fel‑frekvens/latens/SLO‑burn).
En Service ger ett stabilt namn och en virtuell adress för en föränderlig mängd Pods. Labels/selectors bestämmer vilka Pods som ligger bakom Service, och EndpointSlices håller den faktiska listan med Pod‑IP:er.
Operationellt innebär detta:
service-name istället för att jaga Pod‑IP:erAutoscaling fungerar bäst när varje lager har tydliga signaler:
Vanliga fallgropar:
CRDs låter dig definiera nya API‑objekt (t.ex. Database, Cache) så att du kan hantera högre‑nivå system via samma Kubernetes‑API.
Operators parar ihop CRDs med controllers som reconciler verkligheten mot det önskade tillståndet och automatiserar ofta:
Behandla dem som produktionsmjukvara: utvärdera mognad, observerbarhet och felmod innan du förlitar dig på dem.