26 aug. 2025·8 min
Hur man bygger AI-först-produkter med modeller i applikationslogiken
En praktisk guide för att bygga AI-först-produkter där modellen styr beslut: arkitektur, prompts, verktyg, data, utvärdering, säkerhet och övervakning.
Vad det innebär att bygga en AI-först-produkt
Att bygga en AI-först-produkt betyder inte att man bara "lägger till en chatbot." Det innebär att modellen är en verklig, fungerande del av din applikationslogik—på samma sätt som en regelmotor, ett sökindex eller en rekommendationsalgoritm kan vara det.
Din app använder inte bara AI; den är designad kring att modellen kommer att tolka input, välja åtgärder och producera strukturerade resultat som resten av systemet förlitar sig på.
I praktiken: istället för att hårdkoda varje beslutsväg ("om X så gör Y") låter du modellen hantera det suddiga—språk, intention, oklarheter, prioritering—medan din kod tar hand om det som måste vara precist: behörigheter, betalningar, databasändringar och policyimplementering.
När AI-först passar (och när det inte gör det)
AI-först fungerar bäst när problemet har:
- Många giltiga indata (fritekst, röriga dokument, varierande användarmål)
- För många edge cases för att underhålla regler manuellt
- Värde i omdöme, sammanfattning eller syntes snarare än perfekt determinism
Regelbaserad automation är ofta bättre när krav är stabila och exakta—skatteberäkningar, lagerlogik, behörighetskontroller eller efterlevnadsarbetsflöden där utsignalen måste vara densamma varje gång.
Vanliga produktmål som AI-först stödjer
Team väljer ofta modellstyrd logik för att:
- Öka hastigheten: skapa utkast, extrahera fält, dirigera förfrågningar snabbare
- Personalisera upplevelser: anpassa förklaringar, planer eller rekommendationer
- Stödja beslut: belysa kompromisser, generera alternativ, sammanfatta bevis
Kompromisser du måste acceptera (och designa för)
Modeller kan vara oförutsägbara, ibland säkert felaktiga, och deras beteende kan förändras när prompts, leverantörer eller hämtat kontext ändras. De medför också kostnad per anrop, kan öka latens och väcka säkerhets- och förtroendefrågor (sekretess, skadligt innehåll, policybrott).
Rätt inställning är: en modell är en komponent, inte en magisk svarslåda. Behandla den som ett beroende med specifikationer, felmodeller, tester och övervakning—så får du flexibilitet utan att sätta produkten på en önsketänkandeinsats.
Välj rätt användningsfall och definiera framgång
Inte varje funktion tjänar på att sätta en modell i förarsätet. De bästa AI-först-användningsfallen börjar med en tydlig "job-to-be-done" och slutar med ett mätbart utfall du kan spåra vecka för vecka.
Börja med uppgiften, inte modellen
Skriv en enraders jobbhistoria: ”När ___, vill jag ___, så att jag kan ___.” Gör sedan utfallet mätbart.
Exempel: ”När jag får ett långt kundmail, vill jag ha ett föreslaget svar som följer våra riktlinjer, så att jag kan svara på under 2 minuter.” Detta är långt mer handlingsbart än ”lägg till en LLM i e-posten.”
Kartlägg beslutsplatserna
Identifiera de ögonblick där modellen kommer att välja åtgärder. Dessa beslutspunkter bör vara explicita så att du kan testa dem.
Vanliga beslutspunkter inkluderar:
- Klassificera intention och routa till rätt arbetsflöde
- Avgöra om man ska ställa en förtydligande fråga eller gå vidare
- Välja verktyg (sök, CRM-uppslag, utkast, skapa ärende)
- Bestämma när man ska eskalera till en människa
Om du inte kan namnge besluten är du inte redo att skicka modellstyrd logik.
Skriv acceptanskriterier för beteende
Behandla modellbeteende som vilket annat produktkrav som helst. Definiera vad som är "bra" och "dåligt" på enkelt språk.
Till exempel:
- Bra: använder senaste policy, citerar rätt order-ID, ställer en tydlig fråga om information saknas
- Dåligt: hittar på rabatter, refererar till icke-stödda lokaler eller svarar utan att kolla nödvändig data
Dessa kriterier blir grunden för din utvärderingsuppsättning senare.
Identifiera begränsningar tidigt
Lista begränsningar som påverkar dina designval:
- Tid (responslatensmål)
- Budget (kostnad per uppgift)
- Efterlevnad (hantering av PII, revisionskrav)
- Stödda lokaler (språk, ton, kulturella förväntningar)
Definiera framgångsmått du kan övervaka
Välj ett litet antal mätvärden kopplade till uppgiften:
- Uppgiftsfullföljandegrad
- Noggrannhet (eller policyföljsamhet) på representativa fall
- CSAT eller kvalitativ användarbetyg
- Tid sparad per uppgift (eller tid-till-lösning)
Om du inte kan mäta framgång kommer du att argumentera om känslor istället för att förbättra produkten.
Designa AI-drivet användarflöde och systemgränser
Ett AI-först-flöde är inte "en skärm som kallar en LLM." Det är en helhetsresa där modellen fattar vissa beslut, produkten utför dem säkert och användaren hålls orienterad.
Kartlägg end-to-end-loopen
Börja med att rita pipeline som en enkel kedja: inputs → modell → åtgärder → outputs.
- Inputs: vad användaren tillhandahåller (text, filer, val) plus appkontext (kontonivå, workspace, senaste aktivitet).
- Modellsteg: vad modellen ansvarar för att avgöra (klassificera, utforma, sammanfatta, välja nästa åtgärd).
- Åtgärder: vad ditt system kan göra (sök, skapa uppgift, uppdatera ett register, skicka e-post).
- Outputs: vad användaren ser (utkast, förklaring, bekräftelseskärm, fel med nästa steg).
Denna karta tvingar fram tydlighet om var osäkerhet är acceptabel (utkast) kontra var den inte är det (fakturaförändringar).
Rita systemgränser: modell vs deterministisk kod
Separera deterministiska vägar (behörighetskontroller, affärsregler, beräkningar, databasändringar) från modellstyrda beslut (tolkning, prioritering, generering i naturligt språk).
En användbar regel: modellen kan rekommendera, men koden måste verifiera innan något oåterkalleligt händer.
Bestäm var modellen körs
Välj runtime baserat på begränsningar:
- Server: bäst för privata data, konsekvent verktygssvit, revisionsloggar.
- Klient: användbart för lättviktig assistans och integritetsfördelar, men svårare att kontrollera.
- Edge: snabbare global latens, men begränsade beroenden.
- Hybrid: dela upp snabb intent-detektion vid kanten och tungt arbete på servern.
Budgetera latens, kostnad och datapermisssioner
Sätt en per-anrop latens- och kostnadsbudget (inklusive retries och verktygsanrop), och designa UX runt den (streaming, progressiva resultat, "fortsätt i bakgrunden").
Dokumentera datakällor och behörigheter som behövs i varje steg: vad modellen får läsa, vad den får skriva och vad som kräver användarens uttryckliga bekräftelse. Detta blir ett kontrakt för både engineering och förtroende.
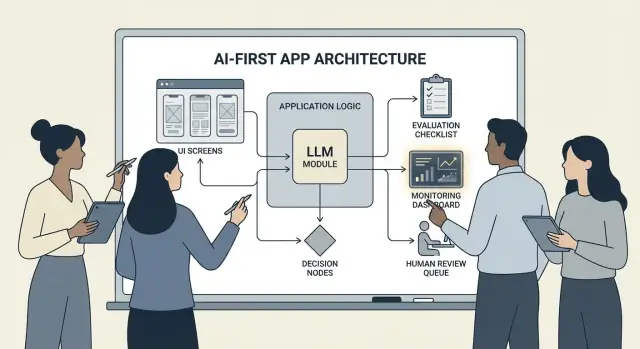
Arkitekturmönster: Orkestrering, tillstånd och spår
När en modell är en del av din applikationslogik är "arkitektur" inte bara servrar och API:er—det handlar om hur du på ett pålitligt sätt kör en kedja av modellbeslut utan att tappa kontroll.
Orkestrering: dirigenten för modellarbete
Orkestrering är lagret som hanterar hur en AI-uppgift utförs end-to-end: prompts och mallar, verktygsanrop, minne/kontext, retries, timeouts och fallback.
Bra orkestratorer behandlar modellen som en komponent i en pipeline. De avgör vilken prompt som ska användas, när ett verktyg ska anropas (sök, databas, e-post, betalning), hur man komprimerar eller hämtar kontext och vad som görs om modellen returnerar något ogiltigt.
Om du vill gå snabbare från idé till fungerande orkestrering kan ett vibe-coding-workflow hjälpa dig att prototypa dessa pipelines utan att bygga om appens grundstomme. Till exempel låter Koder.ai team skapa webbappar (React), backends (Go + PostgreSQL) och till och med mobilappar (Flutter) via chatt—sedan iterera på flöden som "inputs → modell → verktygsanrop → valideringar → UI" med funktioner som planeringsläge, snapshots och rollback, plus källkodsexport när du är redo att äga repo.
Tillståndsmaskiner för flerstegsuppgifter
Flerstegsupplevelser (triage → samla info → bekräfta → utför → sammanfatta) fungerar bäst när du modellerar dem som ett arbetsflöde eller en state machine.
Ett enkelt mönster är: varje steg har (1) tillåtna inputs, (2) förväntade outputs och (3) övergångar. Detta förhindrar att konversationer vandrar och gör edge cases explicita—till exempel vad som händer om användaren ändrar sig eller lämnar ofullständig info.
Single-shot vs. multipel vändors resonemang
Single-shot fungerar bra för avgränsade uppgifter: klassificera ett meddelande, skriva ett kort svar, extrahera fält från ett dokument. Det är billigare, snabbare och lättare att validera.
Multi-turn-resonemang är bättre när modellen måste ställa förtydligande frågor eller när verktyg behövs iterativt (t.ex. planera → söka → förfina → bekräfta). Använd det medvetet och sätt tak på loopar med tids- eller steglimiter.
Idempotens: undvik upprepade sidoeffekter
Modeller gör retries. Nätverk fallerar. Användare dubbelklickar. Om ett AI-steg kan trigga sidoeffekter—skicka e-post, boka, debitera—gör det idempotent.
Vanliga taktiker: bifoga en idempotens-nyckel till varje "utför"-åtgärd, spara åtgärdsresultatet och säkerställ att retries returnerar samma utfall istället för att upprepa det.
Spår (traces): gör varje steg debuggbart
Lägg till spårbarhet så att du kan svara: Vad såg modellen? Vad beslutade den? Vilka verktyg kördes?
Logga ett strukturerat spår per körning: promptversion, inputs, hämtade kontext-ID:n, verktygsbegäranden/svar, valideringsfel, retries och slutligt output. Detta förvandlar "AI gjorde något konstigt" till en auditorbar, fixbar tidslinje.
Prompting som produktlogik: tydliga kontrakt och format
När modellen är en del av din applikationslogik slutar dina prompts vara "copy" och blir exekverbara specifikationer. Behandla dem som produktkrav: tydlig scope, förutsägbara outputs och ändringskontroll.
Börja med en systemprompt som definierar kontraktet
Din systemprompt bör sätta modellens roll, vad den kan och inte kan göra, och de säkerhetsregler som gäller för din produkt. Håll den stabil och återanvändbar.
Inkludera:
- Roll och mål: vem den är (t.ex. "support triage assistant") och vad framgång ser ut som.
- Scope-gränser: vilka förfrågningar den måste neka eller eskalera.
- Säkerhetsregler: hantering av PII, medicinska/juridiska friskrivningar, ingen gissning.
- Verktygspolicy: när den ska anropa verktyg kontra svara direkt.
Strukturera prompts med tydliga inputs/outputs
Skriv prompts som API-definitioner: lista de exakta inputs du ger (användartext, kontonivå, locale, policyutdrag) och de exakta outputs du förväntar dig. Lägg till 1–3 exempel som matchar verklig trafik, inklusive knepiga edge cases.
Ett användbart mönster är: Kontext → Uppgift → Begränsningar → Outputformat → Exempel.
Använd begränsade format för maskinläsbara resultat
Om koden behöver agera på output, förlita dig inte på prosatext. Begär JSON som matchar ett schema och avvisa allt annat.
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
Versionera prompts och rulla ut säkert
Spara prompts i versionskontroll, tagga releaser och rulla ut som funktioner: staged deployment, A/B där det passar, och snabb rollback. Logga promptversion med varje svar för debugging.
Bygg en prompt-testsuite
Skapa ett litet, representativt set av fall (happy path, tvetydiga förfrågningar, policybrott, långa inputs, olika lokaler). Kör dem automatiskt vid varje promptändring och avbryt bygget när outputs bryter kontraktet.
Verktygsanrop: låt modellen avgöra, låt koden utföra
Lansera på ditt varumärke
Sätt din AI-först-app på din egen domän när den är redo för användare.
Verktygsanrop är det renaste sättet att dela ansvar: modellen bestämmer vad som behöver göras och vilken kapacitet som ska användas, medan din applikationskod utför åtgärden och returnerar verifierade resultat.
Detta håller fakta, beräkningar och sidoeffekter (skapa ärenden, uppdatera register, skicka e-post) i deterministisk, reviderbar kod—istället för att lita på fri form-text.
Designa ett litet, avsiktligt verktygsset
Börja med några få verktyg som täcker 80 % av förfrågningarna och är lätta att säkra:
- Sök (din dokumentation/helpcenter) för att svara på produktfrågor
- DB-uppslag (läs-only först) för användar-/konto-/orderstatus
- Kalkylator för prissättning, totalsummor, konverteringar och regelbaserad matematik
- Ticketing för att öppna supportärenden när användaren behöver mänsklig uppföljning
Håll varje verktygs syfte smalt. Ett verktyg som gör "allt" blir svårt att testa och lätt att missbruka.
Validera inputs, sanera outputs
Behandla modellen som en otrustad anropare.
- Validera verktygsinputs med strikta scheman (typer, intervall, enums). Avvisa eller reparera osäkra argument (t.ex. saknade ID:n, för breda sökningar).
- Sanera verktygsoutputs innan du skickar tillbaka dem till modellen: ta bort hemligheter, normalisera format och returnera bara de fält modellen behöver.
Detta minskar prompt-injektionsrisk via hämtad text och begränsar oavsiktlig dataexponering.
Lägg till behörigheter och rate limits per verktyg
Varje verktyg bör upprätthålla:
- Behörighetskontroller (vem kan komma åt vilka poster, vilka åtgärder)
- Rate limits (per användare/session/verktyg) för att minska missbruk och runaway-loopar
Om ett verktyg kan ändra tillstånd (ticketing, återbetalningar), krävs starkare auktorisation och en audit-logg.
Stöd alltid en "inga verktyg"-väg
Ibland är bästa åtgärd ingen åtgärd: svara från befintlig kontext, ställ en förtydligande fråga eller förklara begränsningar.
Gör “inga verktyg” till ett förstklassigt utfall så att modellen inte anropar verktyg bara för att se upptagen ut.
Data och RAG: förankra modellen i din verklighet
Om ditt produktsvar måste matcha era policies, lager, kontrakt eller intern kunskap behöver du ett sätt att förankra modellen i din data—inte bara dess generella träning.
RAG vs. finjustering vs. enkel kontext
- Enkel kontext (klistra in några stycken i prompten) fungerar när kunskapen är liten, stabil och du har råd att skicka den varje gång (t.ex. en kort prislista).
- RAG (Retrieval-Augmented Generation) är bäst när information är stor, ofta ändras eller behöver källhänvisningar (t.ex. helpcenter-artiklar, produktdokumentation, kontospecifik data).
- Finjustering är bäst när du vill ha konsekvent stil/format eller domänspecifika mönster—inte som primärt sätt att "lagra fakta." Använd det för att förbättra hur modellen skriver och följer era regler; kombinera med RAG för att hålla sanningen uppdaterad.
Grundläggande indexering: chunkning, metadata, färskhet
RAG-kvalitet är mest ett indata-/ingestionsproblem.
Dela dokument i bitar anpassade för din modell (ofta några hundra tokens), helst längs naturliga gränser (rubriker, FAQ-entréer). Spara metadata som: dokumenttitel, avsnittsrubrik, produkt/version, målgrupp, locale och behörigheter.
Planera för färskhet: schemalägg re-indexering, spåra "senast uppdaterad" och sätt utgångsdatum på gamla chunkar. En föråldrad chunk som rankas högt försämrar tyst hela funktionen.
Hänvisningar och kalibrerade svar
Låt modellen citera källor genom att returnera: (1) svar, (2) en lista med snippet-ID:n/URL:er och (3) ett förtroendeuttalande.
Om retrieval är tunt, instruera modellen att säga vad den inte kan bekräfta och erbjuda nästa steg ("Jag kunde inte hitta den policyn; här är vem du kan kontakta"). Undvik att låta den fylla i luckor.
Privat data: åtkomstkontroll och redigering
Tvinga igenom åtkomst innan retrieval (filtrera efter användar-/org-behörigheter) och igen innan generering (redigera känsliga fält).
Behandla embeddings och index som känsliga datalager med auditloggar.
När retrieval misslyckas: graciösa fallback
Om top-resultaten är irrelevanta eller tomma, falla tillbaka till: ställ en förtydligande fråga, routa till mänsklig support eller byt till ett icke-RAG-svarsläge som förklarar begränsningar i stället för att gissa.
Tillförlitlighet: skydd, validering och caching
När en modell sitter i din applogik räcker det inte med "bra för det mesta." Tillförlitlighet betyder att användarna ser konsekvent beteende, att systemet kan konsumera outputs säkert, och att fel degraderas graciöst.
Definiera tillförlitlighetsmål (innan du lägger till fixar)
Skriv ner vad "tillförlitlig" betyder för funktionen:
- Konsekventa outputs: liknande inputs bör ge jämförbara svar (ton, detaljnivå, begränsningar).
- Stabila format: responsen måste vara parsbar varje gång (JSON, punktlista, specifika fält).
- Begränsat beteende: klara gränser för vad modellen ska göra (ingen gissning, citera källor, ställ en fråga vid osäkerhet).
Dessa mål blir acceptanskriterier för både prompts och kod.
Skydd: validera, filtrera och verkställ policies
Behandla modellens output som otrustad input.
- Schema-validering: kräva strikt format (t.ex. JSON med obligatoriska nycklar) och avvisa allt som inte parsas.
- Innehållsfilter: kör svordomskontroller, PII-detektorer eller policyvalidatorer på både användarinmatning och modelloutput.
- Affärsregler: verkställ begränsningar i kod (prisspann, behörighetsregler, tillåtna åtgärder), även om prompten nämner dem.
Om validering misslyckas, returnera en säker fallback (ställ en förtydligande fråga, byt till en enklare mall eller routa till en människa).
Retries som verkligen hjälper
Undvik blind repetition. Försök igen med en ändrad prompt som adresserar felmoden:
- "Returnera endast giltig JSON. Ingen markdown."
- "Om osäker, sätt
confidencetill low och ställ en fråga."
Sätt tak för retries och logga orsaken till varje fel.
Deterministisk efterbearbetning
Använd kod för att normalisera vad modellen producerar:
- kanonisera enheter, datum och namn
- ta bort dupliceringar
- tillämpa rankingsregler eller trösklar
Detta minskar varians och gör outputs lättare att testa.
Caching utan att skapa sekretessproblem
Cachea upprepade resultat (t.ex. identiska frågor, delade embeddings, verktygsresultat) för att minska kostnad och latens.
Föredra:
- korta TTL:er för användarspecifika data
- cache-nycklar som exkluderar rå PII (eller hash:a omsorgsfullt)
- "do not cache"-flaggor för känsliga flöden
Görs rätt ökar caching konsistens utan att skada användarförtroendet.
Säkerhet och förtroende: minska risk utan att döda UX
Bygg och tjäna krediter
Få krediter genom att dela det du bygger eller bjuda in andra att prova Koder.ai.
Säkerhet är inte ett separat compliance-lager du sätter på i efterhand. I AI-först-produkter kan modellen påverka åtgärder, formuleringar och beslut—så säkerhet måste vara en del av ditt produktkontrakt: vad assistenten får göra, vad den måste neka och när den måste be om hjälp.
Nyckelrisker att designa för
Namnge de risker din app faktiskt möter och kartlägg varje risk till en kontroll:
- Känsliga data: personliga identifierare, autentiseringsuppgifter, privata dokument och allt som regleras.
- Skadlig vägledning: instruktioner som kan möjliggöra självskada, våld, olagliga handlingar eller osäkra medicinska/finansiella åtgärder.
- Bias och orättvisa utfall: inkonsekvent servicenivå, rekommendationer eller beslut mellan grupper.
Tillåtna/blocked ämnen + eskalationsvägar
Skriv en explicit policy produkten kan verkställa. Håll den konkret: kategorier, exempel och förväntade svar.
Använd tre nivåer:
- Tillåtet: svara normalt.
- Begränsat: svara med begränsningar (t.ex. endast generell info, inga steg-för-steg-instruktioner).
- Blockerat: neka och routa till en eskalationsväg (support, resurser eller en mänsklig agent).
Eskalation bör vara ett produktflöde, inte bara ett nekande meddelande. Ge en "Prata med en person"-option och säkerställ att överlämningen inkluderar kontext användaren redan delat (med samtycke).
Manuell granskning för högpåverkande åtgärder
Om modellen kan trigga verkliga konsekvenser—betalningar, återbetalningar, kontoförändringar, avbokningar, radering av data—lägg till en checkpoint.
Bra mönster inkluderar: bekräftelseskärmar, "utkast sedan godkänn", gränser (beloppsgränser) och en kö för manuell granskning i edge cases.
Öppenhet, samtycke och testbara policies
Berätta för användarna när de interagerar med AI, vilken data som används och vad som sparas. Be om samtycke där det krävs, särskilt för att spara konversationer eller använda data för att förbättra systemet.
Behandla interna säkerhetspolicyer som kod: versionera dem, dokumentera rationella och lägg till tester (exempelprompts + förväntade utfall) så att säkerheten inte regressar vid varje prompt- eller modelluppdatering.
Utvärdering: testa modellen som en annan kritisk komponent
Om en LLM kan ändra vad din produkt gör behöver du ett upprepbart sätt att bevisa att den fortfarande fungerar—innan användare upptäcker regressioner åt dig.
Behandla prompts, modellversioner, verktygsscheman och retrieval-inställningar som releasbara artefakter som kräver testning.
Bygg en utvärderingsuppsättning från verkligheten
Samla verkliga användarintentioner från supportärenden, sökfrågor, chattloggar (med samtycke) och säljsamtal. Gör dem till testfall som innehåller:
- Vanliga happy-path-förfrågningar
- Tvetydiga prompts som kräver förtydligande frågor
- Edge cases (saknad data, konflikterande begränsningar, ovanliga format)
- Policykänsliga scenarier (personuppgifter, otillåtet innehåll)
Varje fall bör innehålla förväntat beteende: svaret, beslutet som togs (t.ex. "anropa verktyg A") och eventuell nödvändig struktur (JSON-fält närvarande, citeringar inkluderade osv.).
Välj mätvärden som matchar produktens risk
En enda poäng fångar inte kvalitet. Använd ett litet set av mått som kartläggs till användarutfall:
- Noggrannhet / uppgiftssucces: löste det användarens mål?
- Grundadhet: stöds påståenden av tillhandahållen kontext eller källor?
- Formatvaliditet: matchar output kontraktet (JSON, tabell, punkter)?
- Nekandefrekvens: nekar den när den ska—och undviker nekat när den inte ska?
Spåra kostnad och latens tillsammans med kvalitet; en "bättre" modell som fördubblar svarstid kan skada konvertering.
Kör offline-evalueringskörningar för varje förändring
Kör offline-utvärderingar innan release och efter varje prompt-, modell-, verktygs- eller retrieval-ändring. Håll resultat versionerade så du kan jämföra körningar och snabbt peka ut vad som bröt.
Lägg till online-testning med skydd
Använd online A/B-tester för att mäta verkliga utfall (fullföljandegrad, redigeringar, användarbetyg), men lägg till säkerhetslinor: definiera stoppvillkor (t.ex. spikar i ogiltiga outputs, nekanden eller verktygsfel) och rulla automatiskt tillbaka när trösklar överskrids.
Övervakning i produktion: drift, fel och feedback
Behåll full kodkontroll
Äg ditt repo när du är redo genom att exportera källkod från Koder.ai.
Att släppa en AI-först-funktion är inte mållinjen. När verkliga användare kommer möter modellen nya formuleringar, edge cases och förändrade data. Övervakning förvandlar "det fungerade i staging" till "det fortsätter fungera nästa månad."
Logga det som betyder något (utan att samla hemligheter)
Fånga tillräcklig kontext för att reproducera fel: användarintention, promptversion, verktygsanrop och modellens slutliga output.
Logga inputs/outputs med integritetssäker redigering. Behandla loggar som känsliga data: ta bort e-postadresser, telefonnummer, tokens och fritekst som kan innehålla personuppgifter. Ha ett "debug-läge" som du kan slå på temporärt för specifika sessioner istället för maximal loggning som standard.
Bevaka rätt signaler
Övervaka felprocent, verktygsfel, schema-brott och drift. Spåra konkret:
- Verktygsanropsframgång och timeouts (valde modellen rätt verktyg och genomfördes det?)
- Outputformat/schema-efterlevnad (avvisade dina validatorer?)
- Fallback-användning (hur ofta routas till en säkrare eller enklare väg)
- Innehållssäkerhetsblock (hur ofta nekade eller sanerades svar)
För drift, jämför aktuell trafik med din baseline: förändringar i ämnesblandning, språk, genomsnittlig promptlängd och "okända" intentioner. Drift är inte alltid dåligt—men det är en signal att utvärdera.
Larm, runbooks och incidentrespons
Sätt larmtrösklar och on-call-runbooks. Larm bör kopplas till åtgärder: rulla tillbaka en promptversion, inaktivera ett bristfälligt verktyg, hårda valideringar eller växla till en fallback.
Planera incidentrespons för osäkert eller felaktigt beteende. Definiera vem som kan slå av säkerhetsbrytare, hur användare informeras och hur du dokumenterar och lär av händelsen.
Stäng loopen med användarfeedback
Använd feedbackloopar: tumme upp/ner, orsaks-koder, buggrapporter. Fråga efter lätta "varför?"-alternativ (felaktiga fakta, följde inte instruktioner, osäkert, för långsamt) så du kan routa problem till rätt åtgärd—prompt, verktyg, data eller policy.
UX för modellstyrd logik: transparens och kontroll
Modellstyrda funktioner känns magiska när de fungerar—och sköra när de inte gör det. UX måste räkna med osäkerhet och ändå hjälpa användare slutföra uppgiften.
Visa "varför" utan att överväldiga
Användare litar mer på AI-resultat när de kan se var det kom ifrån—not för att de vill ha en lektion, utan för att det hjälper dem avgöra om de ska agera.
Använd progressiv avslöjning:
- Visa först resultatet (svar, utkast, rekommendation).
- Erbjud en "Varför?" eller "Visa källor"-knapp som avslöjar nyckelinputs: användarens begäran, vilka verktyg som användes och vilka källor eller poster som konsulterades.
- Om du använder retrieval, visa citeringar som går till exakt utdrag (t.ex. "Baserat på: Policy §3.2"). Håll det skumläsbart.
Om du har en djupare förklaring, länka internt (t.ex. /blog/rag-grounding) istället för att fylla UI med detaljer.
Designa för osäkerhet (utan skrämmande varningar)
En modell är inte en räknemaskin. Gränssnittet bör kommunicera förtroende och bjuda in till verifiering.
Praktiska mönster:
- Förtroendefickor i vardagsspråk ("Troligtvis korrekt", "Behöver granskning") istället för falsk precision.
- Alternativ, inte ett enda svar: "Här är 3 sätt att svara." Detta minskar kostnaden för ett felaktigt första förslag.
- Bekräftelser för högpåverkande åtgärder (skicka e-post, radera data, genomföra betalningar). Ställ en enkel fråga: "Skicka detta meddelande till 12 mottagare?"
Gör korrigering och återhämtning enkel
Användare ska kunna styra output utan att börja om:
- Inline-redigering med "Tillämpa ändringar" så modellen fortsätter från användarens korrigeringar.
- "Generera igen" med kontroller (ton, längd, begränsningar) i stället för en blind ny körning.
- "Ångra" och synlig historik så misstag är reversibla.
Ge en flyktväg
När modellen misslyckas—or användaren är osäker—erbjud en deterministisk väg eller mänsklig hjälp.
Exempel: "Byt till manuellt formulär", "Använd mall" eller "Kontakta support" (t.ex. /support). Det här är inte en skamfylld fallback; det skyddar uppgiftsfullföljande och förtroende.
Från prototyp till produktion (utan att bygga om allt)
De flesta team misslyckas inte för att LLM:er är oförmögna; de misslyckas för att vägen från prototyp till en pålitlig, testbar och övervakbar funktion är längre än väntat.
Ett praktiskt sätt att korta den vägen är att standardisera en "produktstomme" tidigt: state machines, verktygsscheman, validering, spår och en deploy/rollback-story. Plattformar som Koder.ai kan vara användbara när du vill snabba upp ett AI-först-arbetsflöde—bygga UI, backend och databas tillsammans—och sedan iterera tryggt med snapshots/rollback, egna domäner och hosting. När du är redo att operationalisera kan du exportera källkoden och gå vidare med din föredragna CI/CD- och observability-stack.