21 juli 2025·8 min
Bygg en webbapp för analys av incidentpåverkan, steg för steg
Lär dig hur du designar och bygger en webbapp som beräknar incidentpåverkan med tjänstberoenden, realtidsignaler och tydliga paneler för team.
Lär dig hur du designar och bygger en webbapp som beräknar incidentpåverkan med tjänstberoenden, realtidsignaler och tydliga paneler för team.
Innan du bygger beräkningar eller paneler, bestäm vad “påverkan” egentligen betyder i din organisation. Hoppar du över det här steget får du en poäng som ser vetenskaplig ut men som inte hjälper någon att agera.
Påverkan är den mätbara konsekvensen av en incident på något som verksamheten bryr sig om. Vanliga dimensioner inkluderar:
Välj 2–4 primära dimensioner och definiera dem uttryckligen. Till exempel: “Påverkan = påverkade betalande kunder + SLA‑minuter i risk”, inte “Påverkan = allt som ser dåligt ut på grafer”.
Olika roller fattar olika beslut:
Designa ”påverkan”‑utdata så varje målgrupp kan besvara sin viktigaste fråga utan att översätta mätvärden.
Bestäm vilken latens som är acceptabel. “Realtid” är dyrt och ofta onödigt; near‑real‑time (t.ex. 1–5 minuter) räcker många gånger för beslutsfattande.
Skriv ner det här som ett produktkrav eftersom det påverkar ingestion, caching och UI.
Din MVP bör direkt stödja åtgärder som:
Om ett mätvärde inte förändrar ett beslut är det troligen inte “påverkan”—det är bara telemetri.
Innan du designar skärmar eller väljer databas, skriv ner vad “påverkansanalys” måste svara under en verklig incident. Målet är inte perfekt precision dag ett—det är konsekventa, förklarliga resultat som respondenter kan lita på.
Börja med datan du måste inhämta eller referera för att beräkna påverkan:
De flesta team har inte perfekt beroende‑ eller kundmappning dag ett. Bestäm vad ni tillåter att mata in manuellt så appen ändå är användbar:
Designa dessa som tydliga fält (inte fria anteckningar) så de är sökbara senare.
Din första release bör pålitligt generera:
Påverkansanalys är ett beslutsverktyg, så begränsningar spelar roll:
Skriv dessa krav som testbara uttalanden. Om du inte kan verifiera det kan du inte lita på det under ett avbrott.
Din datamodell är kontraktet mellan ingestion, beräkning och UI. Får du den rätt kan du byta verktygskällor, förfina poängsättning och ändå svara samma frågor: “Vad bröt?”, “Vem påverkas?” och “Hur länge?”.
Som minimum, modellera dessa som förstaklassposter:
Håll ID:erna stabila och konsekventa över källor. Om ni redan har en servicekatalog, behandla den som sanningskälla och mappa externa verktygsidentifierare till den.
Spara flera tidsstämplar på incidenten för att stödja rapportering och analys:
Spara också beräknade tidsfönster för poängsättning (t.ex. 5‑minuters buckets). Det gör replay och jämförelser enkla.
Modellera två nyckelgrafer:
Ett enkelt mönster är customer_service_usage(customer_id, service_id, weight, last_seen_at) så du kan ranka påverkan efter “hur mycket kunden förlitar sig på den”.
Beroenden utvecklas, och påverkningsberäkningar bör spegla vad som var sant vid tidpunkten. Lägg till giltighetsdatum på kanter:
dependency(valid_from, valid_to)Gör samma för kundprenumerationer och användningssnapshotar. Med historiska versioner kan du korrekt köra om tidigare incidenter under post‑incident review och generera konsekvent SLA‑rapportering.
Din påverkningsanalys är bara så bra som de inputs som matar den. Målet är enkelt: hämta signaler från de verktyg ni redan använder och konvertera dem till en konsekvent händelseström appen kan resonera kring.
Börja med en kort lista källor som pålitligt beskriver “något förändrades” under en incident:
Försök inte att ta in allt på en gång. Välj källor som täcker detektion, eskalation och bekräftelse.
Olika verktyg stödjer olika integrationsmönster:
Ett praktiskt tillvägagångssätt: webhooks för kritiska signaler, plus batch‑importer för att fylla luckor.
Normalisera varje inkommande objekt till ett enda “event”‑format, även om källan kallar det alert, incident eller annotation. Standardisera åtminstone:
Förvänta dig rörig data. Använd idempotensnycklar (source + external_id) för att deduplicera, tolerera out‑of‑order händelser genom att sortera på occurred_at (inte ankomsttid), och applicera säkra standardvärden när fält saknas (samt flagga dem för granskning).
En liten kö i UI för “omatchade tjänster” förhindrar tysta fel och behåller förtroendet i dina påverkningsresultat.
Om din beroendekarta är fel kommer din blast radius vara fel—even om signaler och poängsättning är perfekta. Målet är att bygga en beroendegraf du kan lita på under incidenten och efteråt.
Innan du mappar kanter, definiera noderna. Skapa en servicekatalogpost för varje system du kan referera i en incident: APIs, bakgrundsjobb, datalager, tredjepartsleverantörer och andra kritiska delade komponenter.
Varje tjänst bör åtminstone inkludera: ägare/team, nivå/kritikalitet (t.ex. kundvänd vs intern), SLA/SLO‑mål och länkar till runbooks och on‑call‑dokumentation (t.ex. /runbooks/payments-timeouts).
Använd två kompletterande källor:
Behandla dem som separata kanttyper så folk kan förstå konfidens: “deklarerad av team” vs. “observerad senaste 7 dagarna”.
Beroenden bör vara riktade: Checkout → Payments är inte samma som Payments → Checkout. Riktning styr resonemang (“om Payments är degraderat, vilka upstreams kan falla?”).
Modellera också hårda vs. mjuka beroenden:
Denna distinktion förhindrar att påverkan överdrivs och hjälper respondenter att prioritera.
Er arkitektur förändras veckovis. Om ni inte lagrar snapshots kan ni inte korrekt analysera en incident från två månader sedan.
Persistenta versioner av beroendegrafen över tid (dagligen, per deploy eller vid förändring). När du räknar blast radius, lös ut incidentens tidsstämpel mot närmaste graf‑snapshot så ”vem som påverkades” speglar verkligheten då—inte dagens arkitektur.
När du matar in signaler (alerts, SLO‑burn, syntetiska kontroller, kundtickets) behöver appen ett konsekvent sätt att göra om röriga inputs till ett klart påstående: vad är trasigt, hur illa är det och vem påverkas?
Du kan nå en användbar MVP med något av dessa mönster:
Oavsett metod, spara mellanvärden (tröskelträff, vikter, nivå) så folk kan förstå varför poängen uppstod.
Undvik att slå ihop allt till ett nummer för tidigt. Spåra några dimensioner separat, och härled sedan en övergripande allvar:
Detta hjälper respondenter att kommunicera precist (t.ex. “tillgänglig men långsam” vs. “felaktiga resultat”).
Påverkan är inte bara tjänsthälsa—det är vem som kände av det.
Använd användningsmappning (tenant → tjänst, kundplan → funktioner, användartrafik → endpoint) och beräkna påverkade kunder inom ett tidsfönster anpassat till incidenten (starttid, mitigationstid och eventuellt backfill‑fönster).
Var tydlig med antaganden: sampling av loggar, uppskattad trafik eller partiell telemetri.
Operatörer kommer behöva override: en falsk positiv alert, en partiell rollout, en känd kundsubset.
Tillåt manuella ändringar av allvar, dimensioner och påverkade kunder, men kräva:
Denna revisionsspårning skyddar förtroendet i panelen och snabbar upp post‑incidentgranskning.
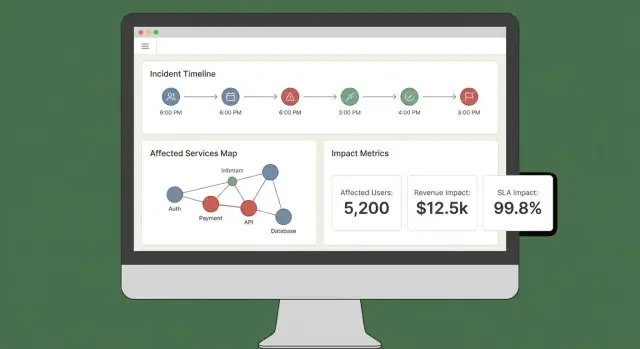
En bra påverkningspanel svarar snabbt på tre frågor: Vad påverkas? Vem påverkas? Hur säkra är vi? Om användare måste öppna fem flikar för att pussla ihop det kommer de inte lita på resultatet eller agera utifrån det.
Börja med ett litet antal ”alltid‑närvarande” vyer som matchar verkliga incidentarbetsflöden:
Poäng utan förklaring känns godtyckligt. Varje poäng ska kunna länkas tillbaka till inputs och regler:
En enkel ”Förklara påverkan”‑panel kan göra detta utan att röran huvudvyn.
Gör det enkelt att skiva påverkan efter tjänst, region, kundnivå och tidsintervall. Låt användare klicka på vilket diagram eller rad som helst för att borra ner till råa bevis (exakt vilka monitorkontroller, loggar eller händelser som drev förändringen).
Under en aktiv incident behöver folk portabla uppdateringar. Inkludera:
Om ni redan har en status‑sida, referera till den via en relativ route som /status så kommunikationsteam kan korsreferera snabbt.
Påverkansanalys är bara användbar om folk litar på den—det betyder att kontrollera vem som ser vad och ha en tydlig logg över ändringar.
Definiera ett litet antal roller som speglar hur incidenter hanteras i verkligheten:
Håll behörigheter knutna till åtgärder, inte jobbtitlar. Exempel: “kan exportera kundpåverkansrapport” är en permission du kan ge commanders och en liten grupp admins.
Påverkansanalys berör ofta kundidentifierare, kontraktsnivåer och ibland kontaktuppgifter. Tillämpa least privilege som standard:
Logga nyckelåtgärder med tillräcklig kontext för att stödja granskningar:
Spara revisionsloggar append‑only, med tidsstämplar och aktörsidentitet. Gör dem sökbara per incident så de används i post‑incidentgranskningar.
Dokumentera vad ni kan stödja nu—retentionstid, åtkomstkontroller, kryptering och revisionsomfång—och vad som finns på roadmap.
En kort “Security & Audit”‑sida i appen (t.ex. /security) hjälper till att sätta förväntningar och minskar ad‑hoc frågor under kritiska incidenter.
Påverkansanalys spelar bara roll under en incident om den driver nästa handling. Appen bör fungera som en ”co‑pilot” för incidentkanalen: den gör inkommande signaler till tydliga uppdateringar och puttar folk när påverkan ändras väsentligt.
Börja med att integrera med den plats där respondenter redan jobbar (ofta Slack, Microsoft Teams eller ett dedikerat incidentverktyg). Målet är inte att ersätta kanalen—utan att posta kontextmedvetna uppdateringar och behålla en gemensam historik.
Ett praktiskt mönster är att behandla incidentkanalen som både input och output:
Om du prototypar snabbt, överväg att bygga arbetsflödet end‑to‑end först (incidentvy → summera → notifiera) innan du finslipar poängsättningen. Plattformar som Koder.ai kan vara användbara här: du kan iterera på en React‑dashboard och en Go/PostgreSQL‑backend genom ett chattdrivet arbetsflöde, och sedan exportera källkoden när incidentteamet godkänner UX.
Undvik alert‑spam genom att trigga notiser endast när påverkan korsar explicita trösklar. Vanliga triggers inkluderar:
När en tröskel korsas, skicka ett meddelande som förklarar varför (vad ändrades), vem som bör agera och vad som bör göras härnäst.
Varje notifikation bör innehålla ”nästa‑stegs” referenser så respondenter kan agera snabbt:
Håll dessa referenser stabila och relativa så de fungerar över miljöer.
Generera två sammanfattningsformat från samma data:
Stöd schemalagda sammanfattningar (t.ex. var 15–30:e minut) och on‑demand ”generera uppdatering” med ett godkännandesteg innan extern utskick.
Påverkansanalys är bara användbar om folk litar på den under incidenten och efter. Validering ska bevisa två saker: (1) systemet ger stabila, förklarliga resultat, och (2) resultaten matchar vad organisationen senare kommer överens om faktiskt hände.
Börja med automatiska tester som täcker de två mest felbenägna områdena: poänglogik och dataingestion.
Håll testfixtures läsbara: när någon ändrar en regel ska det vara lätt att förstå varför en poäng ändrade sig.
Ett replay‑läge är en snabb väg till förtroende. Kör historiska incidenter genom appen och jämför vad systemet skulle ha visat ”i stunden” mot vad respondenter senare kom fram till.
Praktiska tips:
Verkliga incidenter ser sällan ut som rena avbrott. Din valideringssvit bör inkludera scenarier som:
För varje scenario, testa inte bara poängen utan också förklaringen: vilka signaler och vilka beroenden/kunder drev resultatet.
Definiera noggrannhet i operativa termer och följ upp.
Jämför beräknad påverkan med post‑incidentgranskning: påverkade tjänster, varaktighet, kundantal, SLA‑brott och allvar. Logga avvikelser som valideringsärenden med kategori (saknad data, fel beroende, dålig tröskel, fördröjd signal).
Med tiden är målet inte perfektion—det är färre överraskningar och snabbare samsyn under incidenter.
Att leverera en MVP för incidentpåverkansanalys handlar mest om tillförlitlighet och feedback‑loopar. Ditt första driftsättningsval bör optimera för förändringstakt, inte teoretisk framtida skala.
Börja med en modulär monolit om ni inte redan har ett starkt plattforms‑team och tydliga servicegränser. En deploybar enhet förenklar migrationer, felsökning och end‑to‑end‑testning.
Dela upp i tjänster först när ni verkligen känner smärta:
En pragmatisk mellanväg är en app + bakgrundsworkers (köer) + en separat ingestion‑edge vid behov.
Om du vill röra dig snabbt utan stor egen plattformsinvestering kan Koder.ai hjälpa: dess chattdrivna ”vibe‑coding” arbetsflöde passar bra för att bygga en React‑UI, en Go‑API och en PostgreSQL‑datamodell, med snapshots/rollback när ni itererar på regler och arbetsflöden.
Använd relationell lagring (Postgres/MySQL) för kärnentiteter: incidenter, tjänster, kunder, ägarskap och beräknade påveranssnapshots. Det är enkelt att fråga, revidera och utveckla.
För högvolyms‑signaler (metrics, loggderiverade events) lägg till en time‑series store eller kolumnlager när rå retention och rollups blir dyra i SQL.
Överväg en grafdatabas endast om beroendeförfrågningar blir en flaskhals eller ert beroendemodell blir mycket dynamiskt. Många team klarar sig långt med adjacens‑tabeller plus caching.
Din påverkningsapp blir en del av incidentkedjan, så instrumentera den som produktionsmjukvara:
Exponera en “health + freshness”‑vy i UI så respondenter kan lita på (eller ifrågasätta) siffrorna.
Definiera MVP‑scope tajt: ett litet verktyg att ta in, en tydlig poäng och en panel som svarar “vem påverkas och hur mycket.” Iterera sedan:
Behandla modellen som en produkt: versionshantera den, migrera säkert och dokumentera ändringar för post‑incidentgranskning.
Impact är den mätbara konsekvensen av en incident på affärs‑kritiska utfall.
En praktisk definition namnger 2–4 primära dimensioner (t.ex. påverkade betalande kunder + SLA‑minuter i risk) och utesluter uttryckligen ”allt som ser dåligt ut på grafer”. Det håller utdata kopplade till beslut, inte bara telemetri.
Välj dimensioner som kopplar till de åtgärder era team tar under de första 10 minuterna.
Vanliga, MVP‑vänliga dimensioner:
Begränsa till 2–4 så poängen förblir förklarbar.
Designa utdata så varje roll kan besvara sin huvudfråga utan att översätta mätvärden:
Om ett mått inte används av någon av dessa målgrupper är det troligen inte ”påverkan”.
”Realtime” är dyrt; många team klarar sig med near‑real‑time (1–5 minuter).
Skriv ett latensmål som krav eftersom det påverkar:
Visa också förväntningar i UI (t.ex. “data uppdaterad för 2 minuter sedan”).
Börja med att lista besluten respondenter måste fatta, och säkerställ att varje utdata stödjer ett av dem:
Om ett mått inte ändrar ett beslut, behåll det som telemetri, inte påverkan.
Minimala nödvändiga inputs brukar omfatta:
Tillåt explicita, sökbara manuella fält så appen är användbar när data saknas:
Kräv vem/när/varför för ändringar så förtroendet inte försämras.
Ett tillförlitligt MVP bör producera:
Normalisera varje källa till ett gemensamt händelseschema så beräkningar blir konsistenta.
Minst standardisera:
occurred_at, detected_at, Börja enkelt och gör det förklarbart:
Spara mellanvärden (tröskelträffar, vikter, nivå, konfidens) så användare ser varför poängen ändrades. Spåra dimensioner (tillgänglighet/latens/fel/datakvalitet/säkerhet) innan du slår ihop till ett tal.
Detta räcker för att beräkna ”vad bröt”, ”vem påverkas” och ”hur länge”.
Valfritt: kostnadsuppskattningar (SLA‑krediter, supportbelastning, intäktsrisk) med konfidensintervall.
resolved_atservice_id (mappa från taggar/namn)source + original rå‑payload (för revision/debug)Hantera rörighet med idempotensnycklar (source + external_id) och tåla out‑of‑order händelser baserat på occurred_at.