07 apr. 2025·8 min
Hur du bygger en webbapp för interna utvecklarplattformar (IDP)
Steg-för-steg-guide för att planera, bygga och leverera en webbapp för en intern utvecklarplattform: katalog, mallar, arbetsflöden, behörigheter och revisionsbarhet.
Steg-för-steg-guide för att planera, bygga och leverera en webbapp för en intern utvecklarplattform: katalog, mallar, arbetsflöden, behörigheter och revisionsbarhet.
En IDP-webbapp är en intern “entré” till ert tekniska system. Det är platsen där utvecklare går för att hitta vad som redan finns (tjänster, bibliotek, miljöer), följa den föredragna vägen för att bygga och köra mjukvara, och begära förändringar utan att leta igenom ett dussin verktyg.
Lika viktigt är att det inte är en ytterligare allt-i-ett-ersättare för Git, CI, molnkonsoler eller ärendehantering. Målet är att minska friktion genom att orkestrera det ni redan använder — göra rätt väg till den enklaste vägen.
De flesta team bygger en IDP-webbapp eftersom vardagsarbetet försenas av:
Webbappen bör omvandla detta till upprepbara arbetsflöden och tydlig, sökbar information.
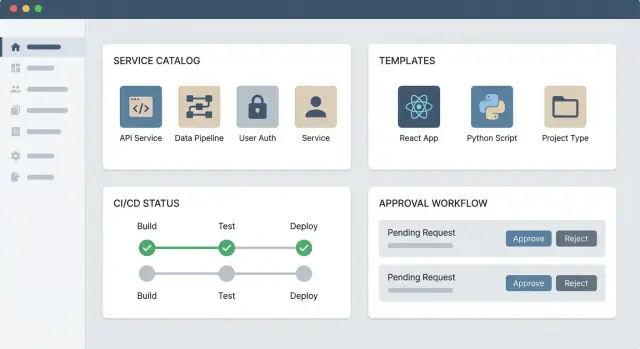
En praktisk IDP-webbapp har vanligtvis tre delar:
Platform team äger vanligtvis portalprodukten: upplevelsen, API:erna, mallarna och guardrails.
Produktteam äger sina tjänster: hålla metadata korrekta, underhålla docs/runbooks och adoptera tillhandahållna mallar. En sund modell är delat ansvar: plattforms-teamet bygger den asfalterade vägen; produktteamen kör på den och hjälper till att förbättra den.
En IDP-webbapp lyckas eller misslyckas beroende på om den tjänar rätt personer med rätt “happy paths”. Innan du väljer verktyg eller ritar arkitekturdiagram, var klar över vem som kommer använda portalen, vad de försöker åstadkomma, och hur du ska mäta framsteg.
De flesta IDP-portaler har fyra kärnpubliker:
Om du inte kan beskriva hur varje grupp gynnas i en mening, bygger du sannolikt en portal som känns valfri.
Välj resor som sker veckovis (inte årligen) och gör dem verkligen end-to-end:
Skriv varje resa som: trigger → steg → berörda system → förväntat utfall → fellägen. Detta blir din produkt-backlog och dina acceptanskriterier.
Bra metrik kopplar direkt till sparad tid och borttagen friktion:
Håll det kort och synligt:
V1 scope: “En portal som låter utvecklare skapa en tjänst från godkända mallar, registrerar den i servicekatalogen med en ägare och visar deploy + hälsostatus. Inkluderar grundläggande RBAC och revisionsloggar. Exkluderar anpassade dashboards, full CMDB-ersättning och skräddarsydda arbetsflöden.”
Det uttalandet är ditt filter mot feature-creep — och din roadmap-ankare för vad som kommer härnäst.
En intern portal lyckas när den löser ett smärtsamt problem end-to-end, och sedan tjänar rätten att expandera. Snabbaste vägen är en smal MVP levererad till ett verkligt team inom veckor — inte kvartal.
Börja med tre byggstenar:
Denna MVP är liten, men levererar ett tydligt utfall: “Jag kan hitta min tjänst och utföra en viktig åtgärd utan att fråga i Slack.”
Om du vill validera UX och arbetsflödes "happy path" snabbt kan en vibe-coding-plattform som Koder.ai vara användbar för att prototypa portalens UI och orkestreringsskärmar från en skriven arbetsflödespecifikation. Eftersom Koder.ai kan generera en React-baserad webapp med en Go + PostgreSQL-backend och stödjer export av källkod, kan team iterera snabbt och ändå behålla långtidsägarskap av kodbasen.
För att hålla roadmap organiserad, gruppera arbete i fyra hinkar:
Denna struktur förhindrar en portal som är “bara katalog” eller “bara automation” utan något som knyter ihop det.
Automatisera bara det som uppfyller minst ett av dessa kriterier: (1) upprepas veckovis, (2) är felbenäget när det görs manuellt, (3) kräver multi-team koordination. Allt annat kan vara en välkurerad länk till rätt verktyg, med tydliga instruktioner och ägarskap.
Designa portalen så att nya arbetsflöden pluggar in som ytterligare “åtgärder” på en tjänst- eller miljösida. Om varje nytt arbetsflöde kräver en navigationsomstart kommer adoptionen att stanna. Behandla arbetsflöden som moduler: konsekventa indata, konsekvent status, konsekvent historik — så du kan lägga till mer utan att ändra mental modell.
En praktisk IDP-portalarkitektur håller användarupplevelsen enkel samtidigt som den hanterar “rörigt” integrationsarbete på ett pålitligt sätt bakom kulisserna. Målet är att ge utvecklare en webapp, även om åtgärder ofta spänner över Git, CI/CD, molnkonton, ärendehantering och Kubernetes.
Det finns tre vanliga mönster, och rätt val beror på hur snabbt ni behöver leverera och hur många team som kommer att utöka portalen:
Som minimum, förvänta dig dessa byggstenar:
Bestäm tidigt vad portalen “äger” kontra vad den endast visar:
Integrationer fallerar av normala skäl (rate limits, tillfälliga avbrott, partiell framgång). Designa för:
Din servicekatalog är sanningskällan för vad som finns, vem som äger det och hur det passar in i resten av systemet. En tydlig datamodell förhindrar “mystery services”, dubbletter och brutna automationer.
Börja med att enas om vad en “service” betyder i er organisation. För de flesta team är det en deploybar enhet (API, worker, webbplats) med en livscykel.
Minst bör ni modellera dessa fält:
Lägg till praktisk metadata som driver portalen:
Behandla relationer som förstaklass, inte bara textfält:
primary_owner_team_id plus additional_owner_team_ids).Denna relationella struktur möjliggör sidor som “allt som ägs av Team X” eller “alla tjänster som rör denna databas.”
Bestäm tidigt kanoniskt ID så dubbletter inte dyker upp efter importer. Vanliga mönster:
payments-api) som är unikgithub_org/repo) om repos är 1:1 med tjänsterDokumentera namngivningsregler (tillåtna tecken, unikhet, policy för namnändring) och validera dem vid skapande.
En servicekatalog fallerar när den blir föråldrad. Välj en eller kombinera:
Behåll ett fält last_seen_at och data_source per post så ni kan visa färskhet och felsöka konflikter.
Om er IDP-webbapp ska vara pålitlig behöver den tre saker som fungerar tillsammans: autentisering (vem är du?), auktorisation (vad får du göra?) och auditbarhet (vad hände, och vem gjorde det?). Få detta rätt tidigt så undviker ni omskrivningar senare — särskilt när portalen börjar hantera produktionsändringar.
De flesta företag har redan identitetsinfrastruktur. Använd den.
Gör SSO via OIDC eller SAML till standardinloggning, och hämta gruppmedlemskap från er IdP (Okta, Azure AD, Google Workspace, osv.). Mappa sedan grupper till portalens roller och team-medlemskap.
Detta förenklar onboarding (“logga in och du är redan i rätt team”), undviker lösenordshantering och låter IT tillämpa globala policyer som MFA och sessionstid.
Undvik en vag “admin vs alla” modell. En praktisk uppsättning roller för en intern utvecklarportal är:
Håll roller små och begripliga. Du kan utöka senare, men en förvirrande modell minskar adoptionen.
Rollbaserad access control (RBAC) är nödvändigt, men inte tillräckligt. Portalen behöver också resursnivå-behörigheter: åtkomst ska kunna begränsas till ett team, en tjänst eller en miljö.
Exempel:
Implementera detta med ett enkelt policymönster: (principal) kan (action) på (resource) om (condition). Börja med team/service-scoping och väx därifrån.
Behandla audit-loggar som en förstaklass-funktion, inte en backend-detalj. Portalen bör registrera:
Gör audit-spår lätta att komma åt från de platser folk arbetar: en servicesida i portalen, en arbetsflödesflik “History” och en adminvy för compliance. Detta snabbar också incidentgranskningar när något går fel.
En bra IDP-portal UX handlar inte om att se snygg ut — det handlar om att minska friktion när någon försöker leverera. Utvecklare ska snabbt kunna svara på tre frågor: Vad finns? Vad kan jag skapa? Vad behöver uppmärksamhet nu?
Istället för att organisera menyer efter backend-system (“Kubernetes”, “Jira”, “Terraform”), strukturera portalen kring jobbet utvecklare faktiskt gör:
Denna uppgiftsbaserade navigation gör också onboarding enklare: nya kollegor behöver inte kunna er verktygskedja för att komma igång.
Varje servicesida bör tydligt visa:
Placera denna “Vem äger detta?”-panel nära toppen, inte gömd i en flik. När incidenter inträffar spelar sekunder roll.
Snabb sökning är portalens kraftfunktion. Stöd filter utvecklare naturligt använder: team, livscykel (experimental/production), tier, språk, plattform och “ägd av mig”. Lägg till klara statusindikatorer (healthy/degraded, SLO i risk, blockerad av godkännande) så användare kan skanna en lista och besluta vad som ska göras.
När du skapar resurser, fråga bara efter det som verkligen behövs nu. Använd mallar (“golden paths”) och förval för att undvika onödiga fel — namngivningskonventioner, logging/metrics-hookar och standard CI-inställningar ska vara förifyllda, inte omtyckta. Om ett fält är valfritt, dölj det bakom “Avancerade alternativ” så happy path förblir snabb.
Självservice är där en intern utvecklarportal tjänar förtroende: utvecklare ska kunna slutföra vanliga uppgifter end-to-end utan att öppna biljetter, samtidigt som plattforms-teamet behåller kontroll över säkerhet, compliance och kostnad.
Börja med ett litet set arbetsflöden som kartläggs mot frekventa, högfriktion-förfrågningar. Typiska “första fyra”:
Dessa arbetsflöden bör vara opinionerade och spegla er golden path, samtidigt som de tillåter kontrollerade val (language/runtime, region, tier, dataklassificering).
Behandla varje arbetsflöde som ett produkt-API. Ett klart kontrakt gör arbetsflöden återanvändbara, testbara och enklare att integrera med verktygskedjan.
Ett praktiskt kontrakt inkluderar:
Håll UX fokuserad: visa bara de inputs utvecklaren faktiskt kan bestämma, och inferera resten från servicekatalogen och policy.
Godkännanden är oundvikliga för vissa åtgärder (produktionsåtkomst, känsliga data, kostnadsökningar). Portalen bör göra godkännanden förutsägbara:
Viktigt är att godkännanden är en del av arbetsflödesmotorn, inte en manuell sidokanallösning. Utvecklaren ska se status, nästa steg och varför ett godkännande krävs.
Varje arbetsflödeskörning bör producera en permanent post:
Denna historik blir ert “paper trail” och supportsystem: när något misslyckas kan utvecklare se exakt var och varför — ofta löser de problemet utan att skapa en biljet. Det ger också plattforms-team data för att förbättra mallar och upptäcka återkommande fel.
En IDP-portal känns först “verklig” när den kan läsa från och agera i de system utvecklare redan använder. Integrationer förvandlar en katalogpost till något ni kan deploya, observera och supporta.
De flesta portaler behöver ett basuppsättning kopplingar:
Var explicit om vad som är read-only (t.ex. pipeline-status) vs write (t.ex. trigga en deployment).
API-first-integrationer är lättare att resonera om och testa: du kan validera auth, scheman och felhantering.
Använd webhooks för near-real-time-event (PR mergad, pipeline färdig). Använd schemalagd sync för system som inte kan pusha events eller där eventual consistency är acceptabelt (t.ex. nattlig import av molnkonton).
Skapa en tunn “connector” eller integrationsservice som normaliserar leverantörsspecifika detaljer till ett stabilt internt kontrakt (t.ex. Repository, PipelineRun, Cluster). Detta isolerar förändringar när ni migrerar verktyg och håller portalens UI/API rent.
Ett praktiskt mönster är:
/deployments/123)Varje integration bör ha en liten runbook: vad “degraderat” ser ut som, hur det visas i UI och vad man gör.
Exempel:
Håll dessa docs nära produkten (t.ex. /docs/integrations) så utvecklare inte behöver gissa.
Er IDP-portal är inte bara en UI — det är ett orkestreringslager som triggar CI/CD-jobb, skapar molnresurser, uppdaterar servicekatalogen och verkställer godkännanden. Observability låter er snabbt svara: “Vad hände?”, “Var gick det fel?” och “Vem behöver agera härnäst?”
Instrumentera varje arbetsflödeskörning med ett correlation ID som följer förfrågan från portal-UI genom backend-API:er, godkännandekontroller och externa verktyg (Git, CI, moln, ärendehantering). Lägg till request tracing så en vy visar hela vägen och tid för varje steg.
Komplettera traces med strukturerade loggar (JSON) som inkluderar: arbetsflödesnamn, run ID, steg-namn, målservice, miljö, aktör och utfall. Detta gör det enkelt att filtrera på “alla failed deploy-template runs” eller “allt som påverkar Service X.”
Grundläggande infra-metrik räcker inte. Lägg till arbetsflödes-metrik som kopplar till verkliga utfall:
Ge plattforms-team “på en blick”-sidor:
Länka varje status till drill-down-detaljer och exakta loggar/traces för den körningen.
Sätt alerts för brutna integrationer (t.ex. upprepade 401/403), fastnade godkännanden (inga åtgärder på N timmar) och sync-fel. Planera dataretention: behåll högvolymsloggar kortare, men behåll audit-händelser längre för compliance och utredningar, med tydliga åtkomstkontroller och exportmöjligheter.
Säkerhet i en IDP-portal fungerar bäst när det känns som “räcke”, inte grindar. Målet är att minska riskfyllda val genom att göra den säkra vägen enklast — samtidigt som team har autonomi att leverera.
Det mesta av styrningen kan ske i det ögonblick en utvecklare begär något (en ny tjänst, repo, miljö eller molnresurs). Behandla varje formulär och API-anrop som otillförlitliga indatat.
Verkställ standarder i kod, inte i docs:
Detta håller servicekatalogen ren och gör revisioner mycket enklare senare.
En portal berör ofta credentials (CI-tokens, molnåtkomst, API-nycklar). Behandla secrets som radioaktiva:
Se också till att audit-loggar fångar vem gjorde vad och när — utan att fånga secret-värden.
Fokusera på realistiska risker:
Minska risk med signerad webhook-verifiering, least-privilege-roller och strikt separation mellan “read” och “change” operationer.
Kör säkerhetskontroller i CI för portal-koden och för genererade mallar (linting, policy-checks, dependency-scanning). Schemalägg sedan regelbundna granskningar av:
Styrning är hållbar när den är rutin, automatiserad och synlig — inte ett engångsprojekt.
En utvecklarportal levererar bara värde om team faktiskt använder den. Behandla utrullning som en produktlansering: starta smått, lär snabbt och skala baserat på bevis.
Pilota med 1–3 team som är motiverade och representativa (ett “greenfield”-team, ett legacy-tungt team, ett med striktare compliance-krav). Observera hur de genomför verkliga uppgifter — registrera en tjänst, begära infrastruktur, trigga en deploy — och åtgärda friktion omedelbart. Målet är inte funktionskompletthet; målet är att bevisa att portalen sparar tid och minskar misstag.
Ge migrationssteg som passar in i en normal sprint. T.ex.:
Håll “day 2”-uppgraderingar enkla: tillåt team att gradvis lägga till metadata och ersätta skräddarskrivna skript med portalarbetsflöden.
Skriv koncisa docs för arbetsflöden som betyder något: “Registrera en tjänst”, “Begär en databas”, “Rulla tillbaka en deploy.” Lägg in-produkt-hjälp intill formulärfält och länka till /docs/portal och /support för djupare kontext. Behandla docs som kod: versionera dem, granska dem och rensa dem.
Planera för löpande ägarskap från början: någon måste triagera backloggen, underhålla connectors till externa verktyg och supporta användare när automationer fallerar. Definiera SLA:er för portalincidenter, sätt en regelbunden cadens för connector-uppdateringar och granska audit-loggar för att hitta återkommande smärtpunkter och policybrister.
När portalen mognar vill ni sannolikt funktioner som snapshots/rollback för portalkonfiguration, förutsägbara deployment-processer och enkel miljöpromotion över regioner. Om ni bygger eller experimenterar snabbt kan Koder.ai också hjälpa team att resa interna appar med planning-läge, hosting och kodexport — användbart för att pilota portal-funktioner innan ni hårdforcerar dem till långsiktiga plattforms-komponenter.
En IDP-webbapp är en intern utvecklarportal som orkestrerar era befintliga verktyg (Git, CI/CD, molnkonsoler, ärendehantering, secrets) så att utvecklare kan följa en konsekvent “golden path”. Den är inte avsedd att ersätta dessa system av register; den minskar friktion genom att göra vanliga uppgifter sökbara, standardiserade och självbetjänande.
Börja med problem som sker veckovis:
Om portalen inte gör ett frekvent arbetsflöde snabbare eller säkrare end-to-end kommer den att kännas frivillig och adoptionen stannar av.
Håll V1 litet men komplett:
Skicka detta till ett verkligt team inom veckor, expandera sedan baserat på användning och flaskhalsar.
Behandla resor som acceptanskriterier: trigger → steg → berörda system → förväntat utfall → fellägen. Bra tidiga resor inkluderar:
Använd metrik som speglar borttagen friktion:
En vanlig uppdelning är:
Gör ägarskap explicit i UI (team, on-call, eskalering) och backa upp det med behörigheter så serviceägare kan underhålla sina poster utan plattformsteamets biljetter.
Börja med en enkel, utbyggbar form:
Behåll systemen av register (Git/IAM/CI/moln) som sanningskällor; portalen lagrar förfrågningar och historik.
Modellera tjänster som en förstaklass-entitet med:
Använd ett kanoniskt ID (slug + UUID är vanligt) för att förhindra dubbletter, lagra relationer (service↔team, service↔resurs) och spåra färskhet med fält som och .
Defaulta till företagsidentitet:
Spela in audit-händelser för arbetsflödesindata (med secrets redigerade), godkännanden och resulterande ändringar, och visa historiken på service- och arbetsflödessidor så team kan felsöka själva.
Gör integrationer resilient genom design:
Dokumentera felmoderna i ett kort runbook under något som /docs/integrations så utvecklare vet vad de ska göra när ett extern system är nere.
Välj metrik som går att instrumentera från arbetsflöden, godkännanden och integrationer — inte bara enkäter.
last_seen_atdata_source