18 juli 2025·8 min
Hur man bygger en mobilapp för fjärrövervakning av enheter
Lär dig planera, bygga och lansera en mobilapp för fjärrövervakning av enheter: arkitektur, dataflöde, realtidsuppdateringar, larm, säkerhet och testning.
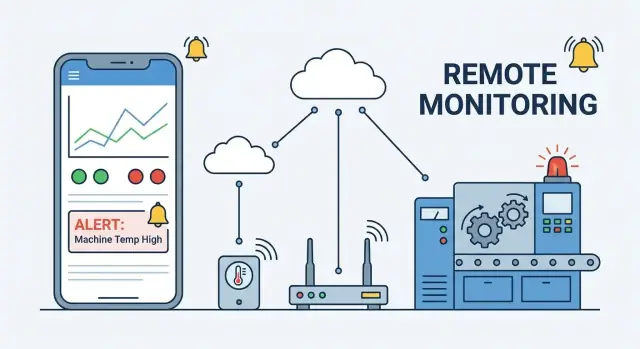
Vad en app för fjärrövervakning av enheter gör
Fjärrövervakning av enheter betyder att du kan se vad en enhet gör — och om den är hälsosam — utan att vara fysiskt nära. En mobil övervakningsapp är “fönstret” in i en flotta enheter: den samlar signaler från varje enhet, omvandlar dem till begriplig status och låter rätt personer agera snabbt.
Vanliga enheter som övervakas
Fjärrövervakning används där utrustning är spridd eller svår att nå. Typiska exempel:
- Sensorer i byggnader, kyla, jordbruk eller vattensystem (temperatur, luftfuktighet, vibration)
- HVAC och byggsystem (körstatus, felkoder, filterlivslängd)
- Industriella maskiner på fabriksgolvet (cykeltal, larm, underhållsindikatorer)
- Fordon och rörliga tillgångar (position, batteri/motordata, utnyttjande)
- Kiosker och digital skyltning (online/offline, appversion, hårdvaruhälsa)
I alla fall är appens uppgift att minska gissningar och ersätta dem med klar, aktuell information.
Vad användarna förväntar sig av appen
En bra fjärrövervakningsapp levererar vanligtvis fyra grundläggande saker:
- Status vid en blick: online/offline, senaste incheckningstid, nyckelmätvärden och en tydlig “behöver åtgärd”-signal.
- Historik och trender: vad som förändrats över tid — så du kan svara på “när började detta?” och “blir det värre?”
- Larm: proaktiva aviseringar när trösklar överskrids eller en enhet slutar rapportera.
- Enkla styrningar: säkra, begränsade åtgärder som omstart, ändra läge, bekräfta ett larm eller köra en diagnostik — utan att förvandla mobilappen till en ingenjörskonsol.
De bästa apparna gör det också enkelt att söka och filtrera efter plats, modell, allvarlighetsgrad eller ägare — eftersom flottövervakning handlar mindre om en enskild enhet och mer om prioriteringar.
Hur man definierar framgång
Innan du bygger funktioner, definiera vad “bättre övervakning” betyder för ditt team. Vanliga framgångsmått inkluderar:
- Synlighet för driftstid: färre okända tillstånd och snabbare upptäckt av offline-enheter
- Snabbare respons: kortare medeltid till bekräftelse och lösning av incidenter
- Färre fel: tidigare ingripanden baserat på telemetrtrender (t.ex. stigande temperatur eller försämrad batterihälsa)
När dessa mått förbättras rapporterar appen inte bara data — den förhindrar aktivt driftstopp och minskar driftkostnader.
Definiera användare, användningsfall och MVP
Innan du väljer protokoll eller designar diagram, bestäm vem appen är för och vad “framgång” ser ut som dag ett. Fjärrövervakningsappar misslyckas ofta när de försöker tillfredsställa alla med samma arbetsflöde.
Kärnroller (och vad varje behöver)
- Operator (NOC/dispatch): snabb triage, tydligt “vad är trasigt”, snabb filtrering efter plats/status och möjlighet att bekräfta ärenden.
- Admin: användarhantering, behörigheter, onboarding-regler för enheter, larmtrösklar och revisionsloggar.
- Fälttekniker: handlingsbara uppgifter, offline-vänliga enhetsdetaljer, senaste kända status och enkla “återhämtade sig?”-kontroller efter en åtgärd.
- Viewer (intressent/kund): read-only-instrumentpaneler, begränsat enhetsscope och hög-nivå hälsosammanfattningar.
Gör roller till användningsfall
Skriv 5–10 konkreta scenarier som din app måste stödja, till exempel:
- “Operator får ett larm för Site A och måste identifiera påverkade enheter på under 30 sekunder.”
- “Fälttekniker skannar enhets-ID på plats och kollar senaste telemetri och senaste kommandoresultat.”
- “Admin lägger till en ny plats och begränsar viewers till endast den platsen.”
Dessa scenarier hjälper dig att undvika funktioner som ser användbara ut men inte minskar svarstiden.
Nyckelskärmar att inkludera i MVP
Minst planera för:
- Enhetslista: sök, filter (status, plats, modell) och tydliga statusmärken.
- Enhetsdetaljer: aktuell status, senaste telemetri, senaste incheckningstid och kommandologg.
- Diagram: enkla trender (batteri, temperatur, signal) med vettiga tidsintervall.
- Larm: aktiva vs bekräftade, allvar, anteckningar och tilldelning.
- Inställningar: profil, aviseringar och (för admins) användare/roller.
MVP-checklista: måste-ha vs trevligt-att-ha
Måste-ha: autentisering + roller, enhetsinventarie, realtids(något)-status, grundläggande diagram, larm + push-notiser och ett minimalt incidentflöde (bekräfta/lös).
Trevligt-att-ha: kartvy, avancerad analys, automationsregler, QR-onboarding, in-app-chatt och anpassade dashboards.
Plattformar: iOS, Android eller båda?
Välj efter vem som faktiskt bär telefonen i verkligheten. Om fälttekniker är standardiserade på ett OS, börja där. Om du behöver båda snabbt kan en cross-platform-lösning fungera — men håll MVP-omfånget snävt så prestanda och notisbeteende är förutsägbart.
Om du vill validera MVP snabbt kan plattformar som Koder.ai hjälpa dig att prototypa en övervaknings-UI och backendarbetsflöden från en chattdriven specifikation (till exempel: enhetslista + enhetsdetalj + larm + roller), och sedan iterera mot produktion när kärnarbetsflöden är bevisade.
Kartlägg datan: telemetri, kommandon och historik
Innan du väljer protokoll eller designar dashboards, var specifik med vilken data som finns, var den kommer ifrån och hur den ska färdas. En tydlig “datakarta” förhindrar två vanliga fel: att samla in allt (och betala för det för evigt), eller att samla för lite (och vara blind vid incidenter).
Identifiera dina datakällor
Börja med att lista vilka signaler varje enhet kan producera och hur tillförlitliga de är:
- Sensorer: temperatur, vibration, batterinivå, strömförbrukning, dörr-öppen-status.
- Loggar: firmwareloggar, felkoder, crash dumps, anslutningshändelser.
- Hälsokontroller: “jag lever”-pings, självtestresultat, watchdog-resets.
- Position: GPS, Wi‑Fi/cell-triangulering, geofences, senaste kända position.
För varje post, notera enheter, förväntade intervall och vad som är “dåligt”. Detta blir ryggraden för senare larmregler och UI-trösklar.
Bestäm uppdateringsfrekvens
Inte all data förtjänar realtidsleverans. Bestäm vad som måste uppdateras i sekunder (t.ex. säkerhetslarm, kritiskt maskintillstånd), vad som kan vara minuter (batteri, signalstyrka) och vad som kan vara timvis/dagligen (användningssammanfattningar). Frekvens påverkar batteripåverkan, datakostnad och hur “live” appen känns.
En praktisk metod är att definiera nivåer:
- Hot telemetri: frekvent, små paket.
- Warm telemetri: periodisk status.
- Cold telemetri: bulkuppladdningar när det är bekvämt.
Bestäm retention: rådata vs sammanfattningar
Retention är ett produktbeslut, inte bara en lagringsinställning. Behåll rådata tillräckligt länge för att utreda incidenter och validera åtgärder, och sammanfatta sedan till aggregeringar (min/max/genomsnitt, percentiler) för trenddiagram. Exempel: rådata 7–30 dagar, timaggregeringar 12 månader.
Planera offline-beteende och fördröjd sync
Enheter och telefoner går offline. Definiera vad som buffras på enheten, vad som kan kastas och hur fördröjd data ska märkas i appen (t.ex. “senast uppdaterad 18 min sedan”). Se till att tidsstämplar kommer från enheten (eller korrigeras server-side) så historiken förblir korrekt efter återanslutning.
Välj en arkitektur som passar dina enheter
En fjärrövervakningsapp är bara så pålitlig som systemet bakom. Innan skärmar och dashboards, välj en arkitektur som matchar enheternas kapabiliteter, nätverksrealitet och hur “realtid” du verkligen behöver vara.
Kärnkomponenter
De flesta uppsättningar ser ut ungefär så här:
Enhet → (valfri) Gateway → Moln-backend → Mobilapp
- Enhet: mäter telemetri (temperatur, batteri, fel) och tar emot kommandon (restart, ändra intervall).
- Gateway: aggregerar lokala enheter (BLE/Zigbee/Modbus), buffrar data och bryggar till internet.
- Moln: autentiserar enheter/användare, lagrar tidsserier, triggar larm och exponerar API:er.
- Mobilapp: visar aktuell status, historik och incidenter; skickar användarkommandon.
Direkt-till-moln vs gateway-baserat
Direkt-till-moln-enheter fungerar bäst när enheter har pålitlig IP-anslutning (Wi‑Fi/LTE) och tillräcklig ström/CPU.
- Fördelar: färre rörliga delar, enklare drift, lägre latens.
- Nackdelar: varje enhet måste hantera säker anslutning, uppdateringar och intermittenta nät.
Gateway-baserade arkitekturer passar begränsade enheter eller industriella installationer.
- Fördelar: gateways kan buffra under avbrott, översätta protokoll och minska mobilkostnader genom batching.
- Nackdelar: extra hårdvara att hantera; gateway-fel kan påverka många enheter.
REST/HTTP vs WebSockets vs MQTT (på hög nivå)
- REST/HTTP: bra för konfiguration, enhetslistor, “hämta senaste status” och tillfälliga kommandon. Enkelt och välkänt.
- WebSockets: idealiskt för mobilappen att få liveuppdateringar medan appen är öppen (strömmande statusändringar).
- MQTT: ofta använt mellan enheter/gateways och moln för frekvent telemetri över opålitliga nät; lättviktigt publish/subscribe.
En vanlig uppdelning är MQTT för enhet→moln, och WebSockets + REST för moln→mobil.
Ett kopierbart dataflödesdiagram
[Device Sensors]
|
| telemetry (MQTT/HTTP)
v
[Gateway - optional] ---- local protocols (BLE/Zigbee/Serial)
|
| secure uplink (MQTT/HTTP)
v
[Cloud Ingest] -> [Rules/Alerts] -> [Time-Series Storage]
|
| REST (queries/commands) + WebSocket (live updates)
v
[Mobile App Dashboard]
Välj den enklaste arkitekturen som fortfarande fungerar under dina värsta nätförhållanden — designa sedan allt annat (datamodell, larm, UI) kring det valet.
Enhetsanslutning och livscykelhantering
En övervakningsapp är bara så pålitlig som sättet den identifierar enheter, spårar deras status och hanterar deras “liv” från onboarding till pensionering. Bra livscykelhantering förhindrar mystiska enheter, dubblettposter och föråldrade statusvyer.
Enhetsidentitet och provisioning
Börja med en tydlig identitetsstrategi: varje enhet måste ha ett unikt ID som aldrig ändras. Det kan vara ett fabriksserienummer, en säker hårdvaruidentifierare eller en genererad UUID lagrad på enheten.
Under provisioning, fånga minimal men användbar metadata: modell, ägare/plats, installationsdatum och kapabiliteter (t.ex. har GPS, stödjer OTA). Håll provisioningflöden enkla — skanna en QR-kod, gör en kravmärkning och bekräfta att enheten syns i flottan.
Enhetsstatusmodell (vad “status” egentligen betyder)
Definiera en konsekvent statusmodell så mobilappen kan visa realtidsstatus utan att gissa:
- Online/offline: baserat på heartbeat eller senaste meddelandetid.
- Senast sett: tidsstämpel, plus var den senast var ansluten (om relevant).
- Firmwareversion: så du kan upptäcka föråldrade enheter.
- Batteri: senaste rapporterade nivå och laddningsstatus (om tillämpligt).
Gör reglerna explicita (t.ex. “offline om ingen heartbeat på 5 minuter”) så support och användare tolkar instrumentpanelen på samma sätt.
Command-and-control-grunder
Kommandon bör ses som spårade uppgifter:
- Skicka kommando (med ett unikt command ID)
- Bekräfta mottagande (enheten ackar)
- Rapportera resultat (succé/fel + detaljer)
Denna struktur hjälper dig att visa framsteg i appen och förhindrar “fungerade det?”-förvirring.
Hantera opålitliga nät
Enheter kommer att koppla ifrån, röra sig och sova. Designa för det:
- Retry och timeouts: försök igen med backoff; visa “pending” när det är lämpligt.
- Idempotens: upprepade förfrågningar med samma command ID ska inte exekveras två gånger.
- Graceful failure: spara kommandon för senare leverans när enheten återansluter.
När du hanterar identitet, status och kommandon på detta sätt blir resten av din övervakningsapp mycket lättare att lita på och driva.
Backend, lagring och API:er för övervakningsdata
Behåll full kodäganderätt
Exportera källkoden när du är redo att gå från prototyp till produktionsarbetsflöden.
Din backend är “kontrollrummet” för en fjärrövervakningsapp: den tar emot telemetri, lagrar den effektivt och serverar snabba, förutsägbara API:er till mobilappen.
Kärntjänster i backenden
De flesta team slutar med en liten uppsättning tjänster (separerade kodbaser eller väl avgränsade moduler):
- Ingest-API: accepterar enhetstelemetri (ofta via MQTT/HTTP-gateways), validerar payloads, tidsstämplar händelser och köar arbete.
- Enhetsregister: sanningskällan för enhetsidentitet, metadata (modell, firmware, plats) och nuvarande livscykelstatus (provisioned, active, retired).
- Användarhantering: organisationer, roller, behörigheter och auditloggar — så rätt personer ser rätt flottor.
Välja lagring: tidsserie vs relationsdatabas
- Tidsserielagring (eller tidsserieoptimerade tabeller/index) är bäst för högvolyms-telemetri: snabba inserts, tidsintervallsökningar och effektiv diagramgenerering.
- Relationslagring är idealisk för “business data”: användare, enheter, platser, larmregler, underhållsärenden och åtkomstkontroll.
Många system använder båda: relationsdata för kontroll, tidsserier för telemetri.
Aggregering och nedprovtagning
Mobilinstrumentpaneler behöver diagram som laddar snabbt. Spara rådata, men förberäkna också:
- Rollups (t.ex. 1-min, 15-min, 1-tim medel/min/max)
- Nedprovade serier för långa datumintervall
- Senast-kända-status per enhet (ett kompakt register som appen kan hämta omedelbart)
API:er som din app faktiskt kommer att anropa
Håll API:erna enkla och cache-vänliga:
GET /devices(lista + filter som plats, status)GET /devices/{id}/status(senast-kända tillstånd, batteri, anslutning)GET /devices/{id}/telemetry?from=&to=&metric=(historikfrågor)GET /alertsochPOST /alerts/rules(visa och hantera larm)
Designa svaren runt mobil-UI: prioritera “vad är aktuell status?” först, sedan tillåt djupare historik när användare borrar vidare.
Realtidsuppdateringar utan att tömma batteriet
“Realtid” i en övervakningsapp betyder sällan “varje millisekund.” Det brukar betyda “tillräckligt färskt för att agera”, utan att hålla radion vaken eller banka på din backend.
Polling vs streaming: välj lättaste verktyget som fungerar
Polling (appen frågar servern med jämna mellanrum efter senaste status) är enkelt och batterivänligt när uppdateringar är sällsynta. Det räcker ofta för dashboards som ses några gånger per dag eller när enheter rapporterar varannan minut.
Streaminguppdateringar (servern pushar förändringar till appen) känns omedelbara, men de håller en anslutning öppen och kan öka strömförbrukningen — särskilt på opålitliga nät.
En praktisk metod är hybrid: polla i bakgrunden med låg frekvens, byt sedan till streaming när användaren aktivt tittar på en skärm.
När WebSockets är lämpligt (och när inte)
Använd WebSockets (eller liknande push-kanaler) när:
- Operatörer behöver övervaka en enhets tillstånd live (t.ex. larm, dörr öppet/stängt).
- Du visar snabbrörliga mätvärden under felsökning.
- Du kan begränsa det till “förgrund endast” och koppla ner när appen är inaktiv.
Använd polling när:
- Användare mest behöver senaste kända status, inte varje mellanliggande förändring.
- Nät är fläckiga (reconnect-loopar kan slösa kraft).
- Appen ofta ligger i bakgrunden.
Designa för skala: minska onödigt trafik
Batteri- och skalningsproblem har ofta samma grund: för många förfrågningar.
Batcha uppdateringar (hämta flera enheter i en anrop), sidanummer för långa historiker och applicera rate limits så en enda skärm inte kan be om hundratals enheter varje sekund. Om du har högfrekvent telemetri, nedprovta för mobil (t.ex. 1 punkt per 10–30 sek) och låt backenden aggregera.
Gör färskhet tydligt i UI
Visa alltid:
- Senast uppdaterad-tidsstämpel per enhet (och per widget om behövligt)
- Anslutningsstatus (online/offline/okänt)
- En tydlig skillnad mellan live data och cachead data
Detta bygger förtroende och förhindrar att användare agerar på föråldrad “realtids”-data.
Larm, aviseringar och incidentflöde
Skapa flottans UI
Skapa en React-instrumentpanel för flottor med filter, statusmärken och enhetssidor snabbt.
Larm är där en övervakningsapp bygger förtroende — eller förlorar det. Målet är inte “fler notiser”; det är att få rätt person att göra rätt sak med tillräcklig kontext för att lösa problemet snabbt.
Larmtyper som är viktiga
Börja med en liten uppsättning larmkategorier som mappas till verkliga operativa problem:
- Tröskellarm: en mätare överskrider en gräns (temperatur, batteri, felmängd). Använd separata “varning” och “kritisk” nivå när det ändrar vad som behöver göras.
- Anomaliflaggor: tjänster upptäcker ovanligt beteende (plötsliga effektspikar, sensor som fastnat). Dessa är användbara, men bara om appen visar varför det flaggades.
- Offline / saknad heartbeat: enheten har inte checkat in. Hantera detta annorlunda än “dåliga data” och inkludera senaste-sen-tid plus senaste anslutningshistorik.
Aviseringskanaler (och när man använder dem)
Använd in-app-notiser som den kompletta loggen (sökbar, filtrerbar). Lägg till push-notiser för tidskritiska ärenden och överväg e-post/SMS endast för hög-severitet eller efter-timmars eskalering. Push bör vara kort: enhetsnamn, allvar och en tydlig åtgärd.
Hantera larmbrus
Buller dödar svarsfrekvensen. Bygg in:
- Cooldowns (larm inte om och om varje minut)
- Deduplicering (gruppera upprepade fel till en incident)
- Eskalationsregler (om obekräftat i X minuter, notifiera nästa ansvariga)
Incidentflöde och revisionsspår
Behandla larm som incidenter med tillstånd: Triggered → Acknowledged → Investigating → Resolved. Varje steg bör registreras: vem bekräftade, när, vad ändrades och frivilliga anteckningar. Detta revisionsspår hjälper vid efterhandsgranskningar, efterspel och justering av trösklar så din /blog/monitoring-best-practices-sektion kan baseras på verkliga data senare.
Mobil-UI: Instrumentpaneler som gör status uppenbar
En övervakningsapp lyckas eller misslyckas på en fråga: kan någon förstå vad som är fel på några sekunder? Sikta på blickvänliga skärmar som prioriterar undantag först, med detaljer en knapptryckning bort.
Börja med en enhetslista som skalar
Din startsida är ofta en enhetslista. Gör den snabb att avgränsa flottan:
- Sök efter enhetsnamn, ID eller serienummer
- Filter för status (Online/Offline/Warning), modell, firmware och senaste-seentid
- Taggar och gruppering efter plats, kund eller byggnad (t.ex. “Lager A → Kalla rum 2”)
Använd tydliga statuschips (Online, Degraderad, Offline) och visa en enda viktig sekundär rad, som senaste heartbeat (“Sågs för 2m sedan”).
Enhetsdetaljvy: berätta en historia
På enhetsdetaljskärmen, undvik långa tabeller. Använd statuskort för det viktigaste:
- Anslutning (signal, senaste check-in)
- Energi (batteri, laddning, spänning)
- Hälsa (felkoder, temperatur, uptime)
Lägg till en Senaste händelser-panel med mänskligt läsbara meddelanden (“Dörr öppnad”, “Firmware-uppdatering misslyckades”) och tidsstämplar. Om kommandon är tillgängliga, håll dem bakom en tydlig åtgärd (t.ex. “Starta om enhet”) med bekräftelse.
Diagram som folk kan läsa
Diagram ska svara på “vad förändrades?” inte visa upp datavolym.
Inkludera en tidsintervalls-väljare (1h / 24h / 7d / Eget), visa enheter överallt och använd läsbara etiketter (undvik kryptiska förkortningar). Annotera anomalier när möjligt med markörer som matchar din händelselog.
Tillgänglighet och läsbarhet
Lita inte bara på färg. Kombinera kontrast med statusikoner och text (“Offline”). Öka tryckyta, stöd Dynamic Type och håll kritisk status synlig även i starkt ljus eller låg batteriläge.
Säkerhet och åtkomstkontroll för fjärrövervakning
Säkerhet är inte en “sen” funktion för en övervakningsapp. Så fort du visar realtidsstatus eller tillåter fjärrkommandon hanterar du känslig driftdata — och eventuellt styr fysisk utrustning.
Autentisering: välj en tydlig väg (magic links)
För de flesta team är magic link-inloggning ett bra standardval: användare anger e-post, får en tidsbegränsad länk och du undviker lösenordsproblem.
Håll magic-länkar kortlivade (minuter), engångsbruk och knutna till enhet/webbläsarkontext när det går. Om du stödjer flera organisationer, gör organisationsvalet explicit så folk inte av misstag får åtkomst till fel flotta.
Auktorisation: vem kan se vs kontrollera
Autentisering bevisar vem någon är; auktorisation definierar vad de kan göra. Använd RBAC med minst två roller:
- Viewer: kan se telemetri, historik och dashboards
- Operator/Admin: kan skicka kommandon (starta om enhet, ändra inställningar) och hantera larm
I praktiken är den mest riskfyllda åtgärden “kontroll”. Behandla kommandoendpoints som en separat behörighetssats, även om UI visar en enkel knapp.
Dataskydd: transport, lagring och API:er
Använd TLS överallt — mellan mobilapp och backend-API:er och mellan enheter och ingest-tjänster (MQTT vs HTTP spelar ingen roll om det inte är krypterat).
På telefonen, lagra tokens i OS keychain/keystore, inte i vanliga inställningar. På backenden, designa least-privilege API:er: en dashboard-förfrågan bör inte returnera hemliga nycklar, och en device-control-endpoint bör inte acceptera breda “gör vad du vill”-payloads.
Operativ säkerhet: revision och säkra admin-åtgärder
Logga säkerhetsrelevanta händelser (inloggningar, rolländringar, kommando-försök) som audit events som går att granska senare. För farliga åtgärder — som att inaktivera en enhet, byta ägarskap eller tysta aviseringar — lägg till bekräftelsesteg och tydlig attribuering (“vem gjorde vad, när”).
Testning med realistiska enhets- och nätverkstillstånd
Gå snabbare tvärplattform
Bygg en cross-platform Flutter-app för operatörer och fälttekniker utan att börja från noll.
En övervakningsapp kan se perfekt ut i labbet men ändå misslyckas i fält. Skillnaden är ofta “verkliga livet”: fläckiga nät, bullrig telemetri och enheter som beter sig oväntat. Testning bör spegla dessa förhållanden så noggrant som möjligt.
Täcka rätt testlager
Börja med enhetstester för parsing, validering och statustransitioner (t.ex. hur en enhet går från online till stale till offline). Lägg till API-tester som verifierar autentisering, paginering och filtrering för enhetshistorik.
Kör sedan end-to-end-tester för de viktigaste användarflödena: öppna en flottdashboard, borra ner i en enhet, visa senaste telemetri, skicka ett kommando och bekräfta resultatet. Dessa fångar brutna antaganden mellan mobil-UI, backend och enhetsprotokoll.
Simulera enheter och nätverksbeteende
Lita inte bara på ett fåtal fysiska enheter. Bygg en falsk telemetrigenerator som kan:
- Skicka realistiska mätvärden (inklusive spikar och sensorvärden som fastnar)
- Växla offline/online, inklusive långa avbrott och reconnect-stormar
- Skicka ack eller fel för kommandon
Para detta med nätverkssimulering på mobilen: flygplansläge, paketförlust och byte mellan Wi‑Fi och mobilnät. Målet är att bekräfta att din app förblir begriplig när data är sen, ofullständig eller saknas.
Prova svåra kantfall
Fjärrövervakningssystem stöter regelbundet på:
- Klockskifte mellan enheter och server-tidsstämplar
- Dubbla meddelanden (ofta efter återanslutning) som inte får skapa dubbla händelser
- Saknade datapunkter som bör visas som luckor, inte missvisande linjer
Skriv fokuserade tester som bevisar att historikvyer, “senast sett”-etiketter och larmtriggers beter sig korrekt under dessa förhållanden.
Kontrollera prestanda i flotte-skala
Slutligen, testa med stora flottor och långa datumintervall. Verifiera att appen förblir responsiv på långsamma nät och äldre telefoner, och att backenden kan leverera tidsseriehistorik effektivt utan att tvinga mobilappen att ladda mer än nödvändigt.
Lansera, drifta och förbättra över tid
Att skicka en fjärrövervakningsapp är inte ett mål — det är starten på att drifta en tjänst som folk kommer att förlita sig på när något går fel. Planera för säkra releaser, mätbar drift och förutsägbara förändringar.
Release-plan: gradvis utrullning, feature flags, rollback
Börja med en gradvis utrullning: interna testare → en liten pilotflotta → större andel användare/enheter → full release. Para detta med feature flags så du kan slå på nya dashboards, larmregler eller anslutningslägen per kund, enhetsmodell eller appversion.
Ha en rollback-strategi som täcker mer än mobilappen i app-store:
- Backend rollback: håll API:er bakåtkompatibla i minst en releasecykel.
- Konfig-rollback: lagra larmtrösklar och enhetspolicys som versionsbara konfigurationer du kan återställa.
- Kill switches: kunna stänga av en bullrig larmtyp eller en ny realtidsström omedelbart.
Övervaka din övervakning
Om din app rapporterar enhetstillgänglighet men din ingest-pipeline är försenad, kommer användare se “offline” enheter som i själva verket är fina. Spåra hälsan i hela kedjan:
- Tjänsteuptime (API, MQTT/HTTP-gateway, notifikationsworkrar)
- Ingest-lagg (tid från enhetstidsstämpel till tillgänglighet i appen)
- Notisframgång (push-leveransgrad, öppningsgrad, tid-till-bekräftelse)
- Datagap (saknad telemetri per enhetskohort)
Underhåll: firmware, scheman och versionering
Räkna med löpande uppdateringar: firmwareändringar kan ändra telemetrifält, kommandomöjligheter och timing. Behandla telemetri som ett versionskontrakt — lägg till fält utan att bryta gamla, dokumentera deprecieringar och håll parsers toleranta för okända värden. För kommando-API:er, versionera endpoints och validera payloads per enhetsmodell och firmwareversion.
Nästa steg och resurser
Om du planerar budget och tidslinjer, se /pricing. För djupare genomgångar, utforska ämnen som MQTT vs HTTP och tidsserielagring i /blog, och omvandla sedan insikterna till en kvartalsplan som prioriterar färre, högre-förtroende förbättringar.
Om du vill snabba upp tidig leverans kan Koder.ai vara användbart för att förvandla MVP-kraven ovan (roller, enhetsregister, larmflöde, dashboards) till en fungerande webb-backend + UI och till och med en cross-platform mobilupplevelse, med möjlighet att exportera källkod och iterera från planeringsspecifikationer — så ditt team kan lägga mer tid på att validera enhetsarbetsflöden och mindre tid på grundläggande infrastruktur.
Vanliga frågor
Vad innebär "framgång" för en app för fjärrövervakning av enheter?
Börja med att definiera vad “bättre övervakning” betyder för ditt team:
- Färre okända tillstånd (tydligt online/offline och senaste incheckning)
- Snabbare respons (kortare tid till bekräftelse/lösning)
- Färre fel (tidigare ingripanden baserat på trender)
Använd dessa som acceptanskriterier för MVP så att funktioner kopplas till operativa resultat, inte bara snygga diagram.
Vilka användarroller bör jag designa för först?
Vanliga roller motsvarar olika arbetsflöden:
- Operator/NOC: triage, filtrering, bekräfta problem snabbt
- Admin: användare/roller, provisionsregler, larmtrösklar, revisioner
- Fälttekniker: senaste kända status, offline-vänliga detaljer, verifiera återhämtning
- Viewer: read-only, begränsat omfång, hög-nivå hälsosammanfattningar
Designa skärmar och behörigheter per roll så att du inte tvingar alla in i samma arbetsflöde.
Vad bör ingå i MVP för en mobil övervakningsapp?
Inkludera det grundläggande flödet för att se problem, förstå dem och agera:
- Enhetsinventarie med sök + filter (site/status/modell)
- Senast kända status och “senast sett” per enhet
- Enkla diagram för några nyckelmetrik (batteri/temperatur/signal)
Hur bestämmer jag vilken telemetri jag ska samla in och hur ofta?
Gör en datakarta per enhetsmodell:
- Tillgängliga signaler (telemetri, loggar, hälsokontroller, plats)
- Enheter, förväntade intervall och vad som är “dåligt”
- Nödvändig färskhet (sekunder vs minuter vs dagligen)
- Vad som måste sparas som rådata vs aggregerat
Detta förhindrar överinsamling (kostnad) eller underinsamling (blinda fläckar vid incidenter).
Hur länge bör jag behålla enhetstelemetri?
Använd en tierad strategi:
- Rådata kortsiktigt för utredningar (t.ex. 7–30 dagar)
- Rollups/aggregeringar långsiktigt för diagram (t.ex. timvis i 12 månader)
- Ett kompakt senast kända status-register per enhet för snabba mobilhämtningar
Detta håller appen responsiv samtidigt som du kan analysera incidenter i efterhand.
Ska jag använda direkt-till-moln-enheter eller gateway-arkitektur?
Välj efter enhetens begränsningar och nätverksrealitet:
- Direkt-till-moln: bäst när enheter har pålitlig IP-anslutning och tillräcklig ström/CPU; enklare och lägre latens.
- Gateway-baserat: bäst för begränsade enheter eller industriella protokoll; gateways kan buffra och översätta, men är en extra felpunkt.
Välj den enklaste lösningen som fungerar i dina värsta anslutningsförhållanden.
Vilka protokoll bör jag använda: REST, WebSockets eller MQTT?
En praktisk uppdelning är:
- MQTT för device/gateway → cloud (lättviktigt, resilient)
- REST/HTTP för mobilfrågor/konfiguration och tillfälliga kommandon
- WebSockets för liveuppdateringar när appen är öppen
Undvik “alltid streaming” om användarna mest behöver senast kända status; hybrid (bakgrundspollning, streaming i förgrunden) fungerar ofta bäst.
Hur bör command-and-control fungera i en övervakningsapp?
Behandla kommandon som spårade uppgifter så att användare kan lita på resultat:
- Skicka kommando med ett unikt command ID
- Enheten bekräftar mottagandet
- Enheten rapporterar resultat (succé/fel + detaljer)
Lägg till retries/timeouts och (samma command ID ska inte köras två gånger), och visa tillstånd som vs vs i UI.
Hur hanterar jag offline-enheter och fördröjd synk?
Designa för opålitlig anslutning på både enhet och telefon:
- Definiera vad enheten buffrar vs tappar
- Märk fördröjd data tydligt (t.ex. “Senast uppdaterad 18 min sedan”)
- Använd enhetstidsstämplar (eller serverkorrigering) för att hålla historiken korrekt
- Gör offline-tillstånd explicita (online/offline/okänt)
Målet är tydlighet: användarna ska omedelbart veta när data är föråldrad.
Hur säkrar jag en fjärrövervakningsapp och kontrollerar åtkomst?
Använd RBAC och separera “visa” från “kontroll” kapabiliteter:
- Viewer: read-only dashboards och historik
- Operator/Admin: bekräfta incidenter, hantera larm, skicka kommandon
Skydda hela kedjan med TLS, lagra tokens i OS keychain/keystore och håll en audit trail för inloggningar, rolländringar och kommando-försök. Behandla device-control endpoints som mer riskfyllda än statusförfrågningar.