Bygga en webbapp för efterlevnadsstyrning & revisionsspår
En praktisk plan för att bygga en efterlevnadswebbapp med tillförlitliga revisionsspår: krav, datamodell, loggning, åtkomstkontroll, retention och rapportering.
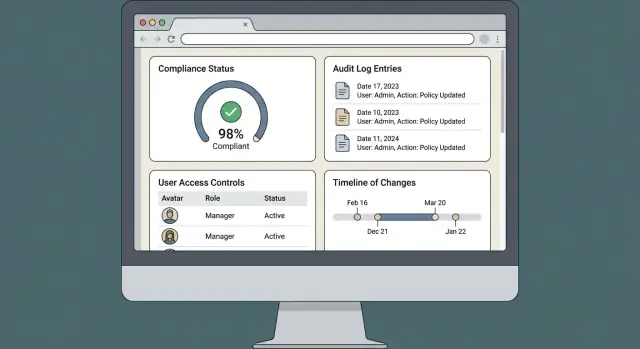
Att bygga en webapp för efterlevnadsstyrning handlar mindre om ”skärmar och formulär” och mer om att göra revisioner repeterbara. Produkten lyckas när den hjälper dig visa avsikt, behörighet och spårbarhet — snabbt, konsekvent och utan manuell avstämning.
Börja med efterlevnadsmålen och user stories
Innan du väljer databas eller skissar UI, skriv ner vad “efterlevnadsstyrning” egentligen betyder i din organisation. För några team är det ett strukturerat sätt att spåra kontroller och bevis; för andra är det främst en arbetsflödesmotor för godkännanden, undantag och periodiska granskningar. Definitionen spelar roll eftersom den avgör vad du måste kunna bevisa under en revision — och vad din app måste göra enkelt.
Definiera målet i enkelt språk
Ett användbart startuttalande är:
“Vi måste visa vem som gjorde vad, när, varför och under vems befogenhet — och hämta bevis snabbt.”
Det håller projektet fokuserat på resultat, inte funktioner.
Identifiera rollerna (och vad var och en behöver)
Lista de personer som kommer åt systemet och vilka beslut de fattar:
- Admins: konfigurerar policyer, användare, integrationer och retention-inställningar.
- Chefer / kontrollägare: godkänner ändringar, granskar bevis, signerar undantag.
- Slutanvändare: lämnar in bevis, begär undantag, utför tilldelade uppgifter.
- Revisorer (intern/extern): läsbehörighet, exporter och tydlig spårbarhet.
Fånga kärnflödena
Dokumentera “happy path” och vanliga avvikelser:
- Godkännanden (policyuppdateringar, kontrolländringar, åtkomstbegäranden)
- Undantag (tillfälliga avvikelser med utgångsdatum och motivering)
- Bevisinsamling (uppladdningar, länkar, intyg, systemgenererade loggar)
- Rapportering (kontrollstatus, förfallna objekt, ändringshistorik)
Definiera framgångskriterier för v1
För en efterlevnadsapp är v1:ans framgång vanligtvis:
- Spårbarhet: komplett ändringshistorik och ansvariga aktörer
- Sökbarhet: hitta ett beslut eller bevis på sekunder
- Manipulationsskydd: upptäcka obehöriga ändringar och bevara original
Håll v1 snävt: roller, grundläggande arbetsflöden, audit-trail och rapportering. Skjut upp “nice-to-haves” (avancerad analys, anpassade dashboards, breda integrationer) till senare releaser när revisorer och kontrollägare bekräftar att grunderna fungerar.
Mappa regelverk till konkreta appkrav
Efterlevnadsarbete går fel när regelverk förblir abstrakta. Målet här är att göra “vara compliant med SOC 2 / ISO 27001 / SOX / HIPAA / GDPR” till en tydlig backlog med funktioner din app måste erbjuda — och det bevis som måste skapas.
Börja med att avgränsa vad som gäller (och inte)
Lista de ramverk som är relevanta för er och varför. SOC 2 kan drivas av kundenkäter, ISO 27001 av en certifieringsplan, SOX av finansiell rapportering, HIPAA av hantering av PHI och GDPR av EU-användare.
Definiera sedan gränser: vilka produkter, miljöer, affärsenheter och datatyper som är in-scope. Det förhindrar att du bygger kontroller för system som revisorerna ändå inte kommer att granska.
Översätt krav till systemfunktioner
För varje ramverkskrav, skriv “appkravet” i enkelt språk. Vanliga översättningar inkluderar:
- Loggning & audit trail: visa vem gjorde vad, när och från var.
- Åtkomstkontroll: rollbaserad åtkomst, minst privilegium och uppdelning av ansvar för känsliga åtgärder.
- Retention & livscykel: behåll register den tid som krävs, arkivera eller radera säkert.
- Godkännanden & granskningar: stöd för sign-offs, periodiska åtgranskningscykler och kontrollintyg.
- Bevisinsamling: lagra exportfiler, skärmdumpar, bilagor och “proof of operation”.
En praktisk teknik är att skapa en mappningstabell i ditt kravdokument:
Ramverkskontroll → appfunktion → data som fångas → rapport/export som bevisar det
Definiera auditerbara händelser och hur länge de ska vara tillgängliga
Revisorer säger ofta “komplett ändringshistorik”, men du måste definiera det precist. Bestäm vilka händelser som är audit-relevanta (t.ex. inloggning, behörighetsändringar, kontrolländringar, bevisuppladdningar, godkännanden, exporter, retention-åtgärder) och vilka minimifält varje händelse ska innehålla.
Dokumentera också retention-krav per händelstyp. Till exempel kan åtkomständringar kräva längre retention än rutinmässiga vyhändelser, medan GDPR kan begränsa hur länge personuppgifter får behållas.
Klargör bevisbehoven tidigt
Behandla bevis som ett förstklassigt produktkrav, inte en eftertänkt bilaga. Specificera vilket bevis som måste stödja varje kontroll: skärmdumpar, ticket-länkar, exporterade rapporter, signerade godkännanden och filer.
Definiera metadata som behövs för auditbarhet — vem laddade upp det, vad det stödjer, versionering, tidsstämplar och om det granskats och godkänts.
Linja upp med revisorerna innan ni bygger
Planera en kort arbetsession med intern revision eller er externa revisor för att bekräfta förväntningar: vad som räknas som “bra”, vilken sampling som används och vilka rapporter de förväntar sig.
Denna tidiga samordning kan spara månader av omarbete — och hjälper dig bygga bara det som faktiskt stödjer en revision.
Designa datamodellen för kontroller, bevis och granskningar
En efterlevnadsapp lever eller dör på sin datamodell. Om kontroller, bevis och granskningar inte är tydligt strukturerade blir rapportering smärtsam och revisioner förvandlas till skärmdumpsjakter.
Kärn-entiteter att modellera
Börja med ett litet set väldefinierade tabeller/kollektioner:
- Users och roles (plus en join-tabell för many-to-many)
- Policies (övergripande dokument, t.ex. “Access Control Policy”)
- Controls (de åtgärdbara krav ni testar och samlar bevis för)
- Tasks (arbetsuppgifter som “Ladda upp kvartalsvis access-review-bevis”)
- Evidence (filer, länkar, poster, skärmdumpar, tickets)
- Reviews/Tests (en kontrollgranskningsinstans: vem, när, utfall)
Relationer som förenklar revisioner
Modellera relationer explicit så att du kan svara “visa hur ni vet att denna kontroll fungerar” i en fråga:
- Control ↔ Evidence: ofta many-to-many (ett bevis kan stödja flera kontroller)
- Control ↔ Tests/Reviews: one-to-many (varje period skapar en ny granskningspost)
- Owner ↔ Control: användare kan äga flera kontroller; kontroller kan ha primär och backup-ägare
- Policy ↔ Controls: one-to-many (kontroller grupperade under en policy)
Identifierare och versionering
Använd stabila, läsbara ID:n för nyckelposter (t.ex. CTRL-AC-001) tillsammans med interna UUID:er.
Versionera allt som revisorer förväntar sig vara oföränderligt över tid:
- policyversioner (publiceringsdatum, ikraftträdandedatum)
- kontroll-definitioner (ordalydelse, frekvens, scope)
- bevismetadataändringar (behåll en ändringshistorik pekare, inte överskrivningar)
Bilagor: lagra filer, inte blobbar
Lagra bilagor i objektlagring (t.ex. S3-kompatibel) och spara metadata i databasen: filnamn, MIME-typ, hash, storlek, uppladdare, uploaded_at och retention-tag. Bevis kan också vara en URL-referens (ticket, rapport, wiki-sida).
Fält som driver rapportering och filtrering
Designa för de filter som revisorer och chefer faktiskt använder: ramverk/kartläggning, system/app i scope, kontrollstatus, frekvens, ägare, senast testad datum, nästa förfallodatum, testresultat, undantag och bevisets ålder. Denna struktur gör /reports och exporter enkla att bygga senare.
Definiera en audit trail som svarar revisorns frågor
En revisors första frågor är förutsägbara: Vem gjorde vad, när och under vilken befogenhet — och kan ni bevisa det? Innan du implementerar loggning, definiera vad en “audit event” betyder i er produkt så att alla team (engineering, compliance, support) spelar in samma berättelse.
Definiera minimun för “vem/vad/när/varför/var”
För varje audit-händelse, fånga ett konsekvent kärnset fält:
- Vem: användar-ID, roll vid tidpunkten och (om relevant) agerande-å-andra/via servicekonto
- Vad: åtgärden och objektet (t.ex. “uppdatera Control #184”)
- När: server-tidsstämpel (UTC) och, vid behov, användarens lokala tid för visning
- Var: tenant/org, miljö och request origin (IP)
- Varför: motivering/justificationstext för känsliga åtgärder (behörighetsändringar, godkännanden, raderingar)
Standardisera händelstyper att rapportera
Revisorer förväntar sig tydliga kategorier, inte friformade meddelanden. Minst definiera händelstyper för:
- Create / update / delete av nyckelposter (kontroller, bevis, policies, findings)
- Autentisering: inloggning lyckad/misslyckad, logout, MFA-enrollment/reset
- Auktorisationsändringar: rolländringar, behörighetsgivningar/återkallanden, gruppmedlemskap
- Arbetsflödesåtgärder: godkännanden, avslag, review sign-offs, “redo för revision”-inlämningar
Fånga före/efter-värden (med säker redigering)
För viktiga fält, spara före och efter-värden så att ändringar går att förklara utan gissningar. Redigera eller hash:a känsliga värden (t.ex. lagra “ändrades från X till [REDACTED]”) och fokusera på fält som påverkar efterlevnadsbeslut.
Lägg till request-context för undersökningar
Inkludera request-metadata för att knyta händelser till verkliga sessioner:
- IP-adress, user agent
- Session-ID (eller enhets-ID)
- Correlation ID / request ID (så support kan spåra hela transaktionen)
Var tydlig med vad som aldrig loggas
Skriv ner denna regel tidigt och handha den i kodgranskningar:
- Lösenord, MFA-seed, hemliga nycklar, access tokens
- Fullständiga betalningskortsdata, CVV eller liknande reglerade data
Ett enkelt event-objekt att samordna kring:
{
"event_type": "permission.change",
"actor_user_id": "u_123",
"target_user_id": "u_456",
"resource": {"type": "user", "id": "u_456"},
"occurred_at": "2026-01-01T12:34:56Z",
"before": {"role": "viewer"},
"after": {"role": "admin"},
"context": {"ip": "203.0.113.10", "user_agent": "...", "session_id": "s_789", "correlation_id": "c_abc"},
"reason": "Granted admin for quarterly access review"
}
Implementera append-only, manipulationsbar audit-logging
En audit-logg är bara användbar om folk litar på den. Det innebär att behandla den som skriv-en-gång-posta: du kan lägga till poster, men aldrig “fixa” gamla. Om något var fel, logga en ny händelse som förklarar korrigeringen.
Börja med en append-only event store
Använd en append-only audit-logg-tabell (eller ett eventstream) där varje post är immutabel. Undvik UPDATE/DELETE på audit-rader i applikationskod, och förstärk immutabilitet på databasenivå när det är möjligt (behörigheter, triggers eller separat lagringssystem).
Varje post bör inkludera: vem/vad som agerade, vad som hände, vilket objekt som påverkades, före/efter-pekarvärden (eller diff-referens), när det hände och varifrån det kom (request ID, IP/enhet om relevant).
Lägg till integritet så manipulation blir upptäckt
För att göra ändringar uppenbara, lägg till integritetsåtgärder som:
- Hashning och kedjning: spara en hash av posten plus föregående postens hash för att skapa en kedja.
- Signering (när lämpligt): signera loggbatcher/punkter med en nyckel lagrad utanför applikationskörningen.
- Write-once-lagring för exporter/arkiv: försegla och lagra loggsegment i oföränderlig lagring regelbundet.
Målet är inte kryptografi för dess egen skull — det är att kunna visa för en revisor att saknade eller ändrade händelser skulle vara uppenbara.
Separera användaråtgärder från systemåtgärder
Logga systemåtgärder (bakgrundsjobb, importer, automatiska godkännanden, schemalagda synkar) separat från användaråtgärder. Använd ett tydligt “actor type” (user/service) och en service-identity så att “vem gjorde det” aldrig blir tvetydigt.
Gör tid och retries förutsägbara
Använd UTC-tidsstämplar överallt och lita på en tillförlitlig tidkälla (t.ex. databas-timestamps eller synkroniserade servrar). Planera för idempotens: tilldela en unik event-nyckel (request ID / idempotency-nyckel) så att retries inte skapar förvirrande dubbletter, samtidigt som verkliga upprepade åtgärder kan registreras.
Bygg åtkomstkontroll och separation of duties
Åtkomstkontroll är där efterlevnad blir vardagsbeteende. Om appen gör det enkelt att göra fel — eller svårt att bevisa vem som gjorde vad — blir revisioner diskussioner. Sikta på enkla regler som speglar hur organisationen faktiskt fungerar, och verkställ dem konsekvent.
Börja med RBAC och minst privilegium
Använd rollbaserad åtkomstkontroll (RBAC) för att hålla behörighetsstyrningen begriplig: roller som Viewer, Contributor, Control Owner, Approver och Admin. Ge varje roll endast vad den behöver. Till exempel kan en Viewer läsa kontroller och bevis men inte ladda upp eller redigera något.
Undvik en “super-user”-roll som alla får. Lägg istället till temporär elevation (tidbegränsad admin) vid behov och gör den elevationen auditerbar.
Definiera behörigheter per åtgärd och per scope
Behörigheter ska vara explicita per åtgärd — visa / skapa / redigera / exportera / radera / godkänna — och begränsade av scope. Scope kan vara:
- En affärsenhet eller avdelning
- Ett system/applikation
- Ett specifikt ramverk (t.ex. SOX vs interna kontroller)
- Ett projekt eller revisionsperiod
Detta förhindrar ett vanligt fel: någon har rätt åtgärd men över ett för brett område.
Gör separation of duties verkställbar
Separation of duties bör inte vara ett policydokument — det bör vara en regel i koden.
Exempel:
- Den som begär en kontrolländring kan inte godkänna den.
- Den som laddar upp bevis kan inte markera det som granskat för samma kontroll.
- Admins kan hantera användaråtkomst men får inte redigera efterlevnadsposter utan en andra godkännare.
När en regel blockerar en åtgärd, visa ett tydligt meddelande (“Du kan begära denna ändring, men en Approver måste godkänna.”) så användare inte försöker kringgå systemet.
Behandla roll-/behörighetsändringar som högt prioriterade audit-händelser
Varje ändring av roller, gruppmedlemskap, behörighetsscope eller godkännandekedjor bör skapa en framträdande audit-post med vem/vad/när/varför. Inkludera tidigare och nya värden samt ticket eller motivering om den finns.
Lägg till step-up-autentisering för känsliga åtgärder
För högriskoperationer (exportera fullt bevisarkiv, ändra retention-inställningar, ge admin-åtkomst) kräva step-up-autentisering — ange lösenord igen, MFA-prompt eller SSO-omautentisering. Det minskar oavsiktligt missbruk och stärker audit-berättelsen.
Hantera retention, arkivering och radering säkert
Retention är där efterlevnadsverktyg ofta fallerar i verkliga revisioner: poster finns kvar, men du kan inte bevisa att de behölls rätt tid, skyddades mot förtida radering och rensades förutsägbart.
Definiera retention per posttyp (inte “hela databasen”)
Skapa explicita retentionperioder per postkategori och spara den valda policyn tillsammans med varje post (så att policyn går att granska senare). Vanliga buckets:
- Audit-loggar (ofta längst): säkerhet, access och admin-aktivitet
- Bevis och bilagor: skärmdumpar, PDF:er, exporter, godkännanden
- Granskningar och sign-offs: kontrolltester, undantag, ledningsintyg
- Användarkonton och roller: join/leave-datum, rollhistorik
Visa policyn i UI (t.ex. “bevaras i 7 år efter stängning”) och gör den oföränderlig när posten är slutgiltig.
Gör legal hold till en förstklassig funktion
Legal hold ska åsidosätta alla automatiska rensningar. Behandla det som ett tillstånd med tydlig motivering, scope och tidsstämplar:
- vem som satte hold, när och varför
- vad det omfattar (tenant, projekt, kontrollset, specifika poster)
- vem som kan häva det (vanligtvis en begränsad roll)
Om appen stödjer raderingsförfrågningar måste legal hold tydligt förklara varför raderingen pausas.
Automatisera retention-scheman (arkivera, exportera, purga)
Retention är enklare att försvara när den är konsekvent:
- Auto-arkivera äldre poster till billigare lagring men håll dem sökbara
- Exportera före radering (när det krävs): generera ett signerigt exportpaket och logga överlämningen
- Purge-regler som körs schemalagt, producerar en rapport och skriver en audit-händelse för varje batch
Backups och restaureringstester är en del av retention
Dokumentera var backups finns, hur länge de sparas och hur de skyddas. Schemalägg återställningstester och dokumentera resultaten (datum, dataset, succékriterier). Revisorer frågar ofta efter bevis att “vi kan återställa” är mer än ett löfte.
Radering vs. redigering för integritet
För integritetskrav, definiera när du raderar, när du redigerar och vad som måste finnas kvar för integritet (t.ex. behåll en audit-händelse men redigera personliga fält). Redigeringar ska loggas som ändringar, med “varför” fångat och granskad.
Skapa rapporter, sök och exporter som revisorer förväntar sig
Revisorer vill sällan se en rundtur i UI — de vill snabba svar som går att verifiera. Dina rapport- och sökfunktioner bör minska fram och tillbaka: “Visa alla ändringar av denna kontroll”, “Vem godkände detta undantag”, “Vad är förfallet” och “Hur vet ni att detta bevis granskats?”
Sökbara auditloggvyer (känns som ett undersökningsverktyg)
Tillhandahåll en auditloggvy som är lätt att filtrera på användare, tidsintervall, objekt (kontroll, policy, bevispost, användarkonto) och åtgärd (create/update/approve/login/permission change). Lägg till fri-textsök över nyckelfält (t.ex. kontroll-ID, bevisnamn, ticketnummer).
Gör filter länkbara (kopiera/klistra in URL) så en revisor kan referera till exakt vy. Överväg en “Sparade vyer”-funktion för vanliga förfrågningar som “Åtkomständringar senaste 90 dagarna.”
Rapporter som matchar verkliga revisorsfrågor
Skapa ett litet set högsignalerade compliance-rapporter:
- Kontrollstatus (implementerad / pågående / ej tillämplig), med ägare och senaste granskningsdatum
- Förfallna granskningar per team och allvarlighetsgrad
- Beviskompletthet (krävt bevis vs tillhandahållet bevis), inklusive gransknings-/godkännandestatus
Varje rapport bör tydligt visa definitioner (vad räknas som “komplett” eller “förfallen”) och as-of-tidsstämpel för datasetet.
Exporter revisorer kan lita på (och du kan försvara)
Stöd exporter till CSV och PDF, men behandla export som en reglerad åtgärd. Varje export ska generera en audit-händelse som innehåller: vem exporterade, när, vilken rapport/vy, använda filter, postantal och filformat. Om möjligt, inkludera en checksum för den exporterade filen.
För att hålla rapportdata konsekvent och reproducerbar, säkerställ att samma filter ger samma resultat:
- Använd stabil sortering (t.ex. efter ID + uppdaterad tid)
- Fånga “as-of”-tidpunkt och query-parametrar
- Undvik att blanda live-uppdaterande data i en enda export utan att deklarera det
“Förklara denna post”-vyer
För varje kontroll, bevispost eller användarbehörighet, lägg till en “Förklara denna post”-panel som översätter ändringshistorik till enkelt språk: vad ändrades, vem ändrade, när och varför (med kommentars-/motiveringsfält). Detta minskar förvirring och förhindrar att revisioner blir en gissningslek.
Lägg till säkerhetskontroller som stödjer efterlevnad
Säkerhetskontroller är vad som gör era efterlevnadsfunktioner trovärdiga. Om appen kan redigeras utan ordentliga kontroller — eller data kan läsas av fel person — kommer audit-trailen inte att uppfylla SOX, GxP-krav eller interna granskare.
Behandla varje request som ovetrodd
Validera indata på varje endpoint, inte bara i UI. Använd server-side validering för typer, intervall och tillåtna värden, och förkasta okända fält. Para validering med starka auktoriseringskontroller på varje operation (visa, skapa, uppdatera, exportera). En enkel regel: “Om det förändrar efterlevnadsdata måste det kräva en explicit behörighet.”
För att minska brutna accesskontroller, undvik “säkerhet genom att dölja UI”. Verkställ åtkomstregler i backend, inklusive vid nedladdningar och API-filter (t.ex. en export för en kontroll får inte läcka bevis för en annan).
Skydda mot vanliga webbrisker
Täcker grunderna konsekvent:
- Injection: parametriserade queries, säkert ORM-användande och strikt inputvalidering.
- XSS: output-encoding, HTML-sanitization för rich text-fält och Content Security Policy.
- CSRF: anti-CSRF-tokens för cookie-baserade sessioner, plus same-site cookie-inställningar.
- Sessionssäkerhet: kortlivade sessioner för admins, omautentisering för känsliga åtgärder.
Kryptera, isolera och hantera hemligheter
Använd TLS överallt (inklusive intern service-till-service). Kryptera känsliga data i vila (databas och backups) och överväg fältkryptering för saker som API-nycklar eller identifierare.
Lagra hemligheter i en dedikerad secrets manager (inte i källkod eller build-loggar). Rotera credentials och nycklar enligt schema och direkt efter personaländringar.
Övervaka och larma på misstänkt aktivitet
Efterlevnadsteam värdesätter synlighet. Skapa larm för misslyckade inloggningsspikar, upprepade 403/404-mönster, privilegieändringar, nya API-token och ovanlig exportvolym. Gör larmen åtgärdsbara: vem, vad, när och vilka objekt påverkades.
Rate limits och lockout-regler
Använd rate limiting för inloggning, lösenordsåterställning och export-endpoints. Lägg till konto-låsning eller step-up-verifiering baserat på risk (t.ex. lås efter upprepade misslyckanden, men ge en säker återställningsväg för legitima användare).
Testa spårbarhet, behörigheter och audit-readiness
Att testa en efterlevnadsapp är inte bara “fungerar det?” — det är “kan vi bevisa vad som hände, vem gjorde det och om de hade rätt att göra det?” Behandla audit readiness som ett förstklassigt acceptanskriterium.
Verifiera audit-loggning med före/efter-precision
Skriv automatiserade tester som påstår:
- Rätt händelse skapas (t.ex.
CONTROL_UPDATED,EVIDENCE_ATTACHED,APPROVAL_REVOKED). - Aktören, tidsstämpel, tenant/org och objekt-ID:n finns alltid med.
- Före/efter-värden fångas för ändringar (inklusive rensade fält).
- Känsliga fält hanteras korrekt (maskerade eller exkluderade enligt policy).
Testa också negativa fall: misslyckade försök (behörighet nekad, valideringsfel) bör antingen skapa en separat “denied action”-händelse eller medvetet exkluderas — vad än er policy anger — så att det är konsekvent.
Testa behörigheter som “kan inte”, inte bara “kan”
Behörighetstestning bör fokusera på att förhindra cross-scope access:
- En användare får inte visa, exportera eller söka data utanför sin organisation, program eller tilldelade system.
- Godkännande-flöden upprätthåller separation of duties (ingen själv-godkännande om reglerna förbjuder det).
- Rolländringar träder i kraft omedelbart och reflekteras i audit-händelser.
Inkludera API-nivå tester (inte bara UI), eftersom revisorer ofta bryr sig om den faktiska verkställningspunkten.
Spårbarhetsdrillor: återskapa berättelsen
Kör spårbarhetskontroller där du utgår från ett utfall (t.ex. en kontroll markerades “Effektiv”) och bekräftar att du kan återskapa:
- vilket bevis som stödde det,
- vem som granskade det,
- vilken policy/version som gällde,
- och vad som förändrats över tid.
Prestandatester för växande loggar
Auditloggar och rapporter växer snabbt. Load-testa:
- event-ingestion under peak-aktivitet,
- sök-/rapportsökningar över stora tidsintervall,
- och exporter (CSV/PDF) för realistiska datavolymer.
Bygg en “audit-ready” checklista och ett bevispaket
Underhåll en repeterbar checklista (länkad i ditt interna runbook, t.ex. /docs/audit-readiness) och generera ett exempel på ett bevispaket som inkluderar: nyckelrapporter, accesslistor, förändringshistorik-exempel och steg för att verifiera logg-integritet. Detta gör revisioner till rutin snarare än panik.
Distribuera, övervaka och drifta appen med kontroll
Att skicka ut en efterlevnadswebbapp är inte bara “release och glöm”. Driften är där goda intentioner antingen blir repeterbara kontroller — eller luckor du inte kan förklara under en revision.
Skydda historik med säker change management
Schema- och API-ändringar kan tyst krossa spårbarheten om de skriver över eller omtolkar gamla poster.
Använd databasmigrationer som kontrollerade, granskbara förändringsenheter och föredra additiva ändringar (nya kolumner, nya tabeller, nya händelstyper) framför destruktiva. När ni måste förändra beteende, håll API:er bakåtkompatibla tillräckligt länge för att stödja äldre klienter och replay/report-jobb. Målet är enkelt: historiska audit-händelser och bevis måste förbli läsbara och konsekventa över versioner.
Separera miljöer och kontrollera deployment
Behåll tydlig miljöseparation (dev/stage/prod) med distinkta databaser, nycklar och åtkomstpolicyer. Staging ska spegla produktion tillräckligt för att validera behörighetsregler, loggning och exporter — utan att kopiera känslig produktionsdata om ni inte har godkänd sanering.
Håll deployment kontrollerad och repeterbar (CI/CD med godkännanden). Behandla en deployment som en auditerbar händelse: dokumentera vem som godkände, vilken version som skickades och när.
Logga deployment- och konfigändringar
Revisorer frågar ofta “Vad ändrades och vem godkände det?” Spåra deployment, feature-flag flips, behörighetsmodelländringar och integrationskonfigurationsändringar som förstaklassiga audit-poster.
Ett bra mönster är en intern “system change”-händelstyp:
SYSTEM_CHANGE: {
actor, timestamp, environment, change_type,
version, config_key, old_value_hash, new_value_hash, ticket_id
}
Övervaka det som hotar efterlevnad
Sätt upp övervakning kopplad till risk: felkvoter (speciellt skrivfel), latens, kö-backlogs (bevisbearbetning, notifieringar) och lagringstillväxt (audit-log-tabeller, filbuckets). Larma på saknade loggar, oväntade droppar i event-volym och 403-spikar som kan indikera felkonfiguration eller missbruk.
Förbered incidenthantering för integritet och åtkomst
Dokumentera “first hour”-steg för misstänkta dataintegritetsproblem eller obehörig åtkomst: frys riskfyllda skrivningar, bevara loggar, rotera credentials, validera audit-loggens kontinuitet och fånga en tidslinje. Håll runbooks korta, handlingsbara och länkade från dina ops-dokument (t.ex. /docs/incident-response).
Stöd löpande styrning och kontinuerlig förbättring
En efterlevnadsapp är inte “klar” när den släpps. Revisorer kommer att fråga hur ni håller kontroller aktuella, hur ändringar godkänns och hur användare håller sig i linje med processerna. Bygg styrningsfunktioner i produkten så kontinuerlig förbättring blir normal drift — inte panik före en revision.
Håll change management synligt och auditerbart
Behandla app- och kontrolländringar som förstaklassposter. För varje ändring, fånga ticket eller förfrågan, godkännare, release notes och en rollback-plan. Koppla dessa direkt till påverkade kontroller så en revisor kan spåra:
varför det ändrades → vem godkände → vad ändrades → när det gick live
Om ni redan använder ett ticket-system, spara referenser (ID/URL) och spegla viktig metadata i appen så beviset förblir konsistent även om externa verktyg förändras.
Versionera policies och kontroller (skriv inte över historiken)
Undvik att redigera en kontroll “på plats”. Skapa versioner med ikraftträdandedatum och tydliga diffar (vad som ändrades och varför). När användare lämnar bevis eller gör en granskning, länka det till den specifika kontrollversion de svarade mot.
Detta förhindrar ett vanligt revisionsproblem: bevis som samlats in under ett äldre krav verkar inte matcha dagens ordalydelse.
Gör utbildning och bevisinlämning enkel
Majoriteten av efterlevnadsgap är processproblem. Lägg in kortfattad, in-app vägledning där användarna agerar:
- Vad bra bevis ser ut som (exempel, accepterade format)
- Namngivningskonventioner och obligatoriska fält
- Vanliga orsaker till att inlämningar avvisas
Spåra utbildningsbekräftelser (vem, vilket modul, när) och visa just-in-time-påminnelser när en användare tilldelas en kontroll eller granskning.
Dokumentera systemet som en produkt, inte en pärm
Underhåll levande dokumentation i appen (eller länkad via /help) som täcker:
- Dataflöden (var bevis kommer ifrån, var det lagras, vem kan visa/exportera)
- Behörighetsmodell och rolldeskriptioner
- En katalog över audit-händelser (vad ni loggar och vilka fält som fångas)
Detta minskar fram och tillbaka med revisorer och snabbar upp onboarding för nya admins.
Schemalägg periodiska granskningar i arbetsflödet
Baka in styrning i återkommande uppgifter:
- Access reviews: certifiera användare/roller periodiskt, med godkännanden och undantag dokumenterade.
- Kontrollgranskningar: bekräfta kontrollägare, frekvens och bevisförväntningar; avsluta kontroller med dokumenterad motivering.
När dessa granskningar hanteras i appen blir kontinuerlig förbättring mätbar och enkel att visa.
Prototypa snabbare (utan att äventyra audit-berättelsen)
Efterlevnadsverktyg börjar ofta som interna arbetsflödesappar — och snabbast väg till värde är en tunn, auditerbar v1 som teamen faktiskt använder. Om du vill påskynda första bygget (UI + backend + databas) samtidigt som du följer arkitekturen ovan kan en vibe-coding-approach vara praktisk.
Till exempel låter Koder.ai team skapa webapplikationer via ett chattdrivet arbetsflöde samtidigt som det genererar en riktig kodbas (React i frontend, Go + PostgreSQL i backend). Det kan passa bra för efterlevnadsappar där du behöver:
- en tydlig RBAC-modell och separation of duties implementerad i backend,
- strukturerade entiteter för kontroller, bevis och granskningar,
- append-only audit-logging-mönster från dag ett,
- och möjligheten att exportera källkod eller deploya/hosta med kontrollerade miljöer.
Nyckeln är att behandla efterlevnadskraven (händelsekatalog, retention-regler, godkännanden och exporter) som explicita acceptanskriterier — oavsett hur snabbt du genererar första implementationen.
Vanliga frågor
Vad är bästa sättet att definiera “efterlevnadsarbete” innan man bygger appen?
Börja med en tydlig, vardaglig formulering som: “Vi måste visa vem som gjorde vad, när, varför och under vems befogenhet — och snabbt kunna hämta bevis.”
Sedan omvandla det till user stories per roll (admins, kontrollägare, slutanvändare, revisorer) och ett kort v1-scope: roller + kärnflöden + audit trail + grundläggande rapportering.
Vad bör ingå i v1 av en efterlevnadswebbapplikation?
En praktisk v1 innehåller vanligtvis:
- Kontroller + ägarskap (vem ansvarar för vad)
- Bevisinsamling (filer/länkar + nödvändig metadata)
- Granskningar/attestationer (vem granskade, när, resultat)
- Godkännanden/undantag (med motivering och utgångsdatum)
- Audit trail (vem/vad/när/vart/varför)
- Sök + några kärnrapporter (status, förfallna, beviskompletthet)
Skjut upp avancerade instrumentpaneler och breda integrationer tills revisorer och kontrollägare bekräftar att grunderna fungerar.
Hur översätter jag SOC 2 / ISO 27001 / SOX / HIPAA / GDPR till appkrav?
Skapa en mappningstabell som översätter abstrakta kontroller till byggbara krav:
- Ramverkskontroll → appfunktion → data som fångas → rapport/export som bevisar det
Gör detta per i-scope produkt, miljö och datatyp så att du inte bygger kontroller för system som revisorerna inte kommer att granska.
Vilken datamodell fungerar bra för kontroller, bevis och periodiska granskningar?
Modellera ett litet set kärn-entiteter och gör relationerna explicita:
- Användare, Roller (ofta many-to-many)
- Policies → Kontroller (one-to-many)
- Kontroller ↔ Bevis (ofta many-to-many)
- Kontroller → Granskningar/Tester (one-to-many per period)
- Uppgifter för återkommande arbete (t.ex. kvartalsvisa granskningar)
Använd stabila, mänskligt läsbara ID:n (t.ex. CTRL-AC-001) och versionera policy-/kontrolldefinitioner så att gammalt bevis förblir knutet till den kravversion som gällde då.
Vad bör ett audit-spår fånga för att tillfredsställa revisorer?
Definiera ett “audit event”-schema och håll det konsekvent:
- Vem: aktörs-ID + roll vid tidpunkten (och service-identity om automatiserat)
- Vad: åtgärd + resurstyp/ID
- När: server-tidsstämpel (UTC)
- Var: tenant/org + request origin (IP) + correlation/request ID
- Varför: motivering för känsliga åtgärder
Standardisera händelstyper (auth, permission-ändringar, workflow-godkännanden, CRUD för nyckelposter) och fånga före/efter-värden med säker redigering.
Hur implementerar jag append-only, manipuleringssäkra audit-loggar?
Behandla audit-loggar som oföränderliga:
- Använd en append-only event store (inga UPDATE/DELETE från applikationskod)
- Lägg till manipulation-detektion (t.ex. hash + previous-hash chaining)
- Valfritt: signera/försegla batcher och lagra arkiv i oföränderlig/WORM-lagring
- Logga systemåtgärder separat från användaråtgärder (actor type: user/service)
Om något måste “korrigeras”, skriv en ny händelse som förklarar det istället för att ändra historiken.
Hur bör åtkomstkontroll och separation of duties genomdrivas?
Börja med RBAC och least privilege (t.ex. Viewer, Contributor, Control Owner, Approver, Admin). Därefter handfasta scope-regler:
- Affärsenhet / system / ramverk / revisionsperiod
Gör separation of duties till en kodregel, inte bara en policy:
- Begäraren ≠ godkännaren
- Den som laddar upp bevis ≠ den som granskar samma bevis
Behandla roll-/scope-ändringar och exporter som högprioriterade audit-händelser och använd step-up-autentisering för känsliga åtgärder.
Hur hanterar jag retention, arkivering, legal hold och radering säkert?
Definiera retention per posttyp och lagra den tillämpade policyn med varje post så att den går att revidera senare.
Vanliga behov:
- Lång retention: audit-loggar, access/admin-ändringar
- Mellan: granskningar/sign-offs, undantag
- Varierande: bevis/bilagor (beroende på ramverk och avtal)
Lägg till legal hold för att åsidosätta rensningar, och logga retention-åtgärder (arkiv/export/rensning) med batchrapporter. För integritetskrav: avgör när du raderar vs. redigerar medan du håller integriteten (t.ex. behåll audit-händelsen men redigera personliga fält).
Vilka rapport-, sök- och exportfunktioner förväntar sig revisorer vanligtvis?
Bygg undersökningsvänlig sökning och ett litet set rapporter som svarar på revisorsfrågor:
- Filtrera auditloggar på användare/datum/objekt/åtgärd, plus fri-textsökning
- Rapporter: kontrollstatus, förfallna granskningar, beviskompletthet
För exporter (CSV/PDF) logga:
- vem exporterade, när, vilken vy/rapport, filter, antal poster, format
Inkludera ett “as-of”-tidsstämplar och stabil sortering så att exporter är reproducerbara.
Hur testar och driver jag appen så att den förblir audit-ready över tid?
Testa audit-readiness som ett produktkrav:
- Automatiska kontroller att rätt händelstyper skapas med nödvändiga fält
- Före/efter-loggningens korrekthet (inklusive rensade fält)
- Negativa tester för förbjudna åtgärder (och om förnekanden loggas enligt policy)
- API-nivå auktorisationstester för att förhindra cross-scope access
Operationellt: behandla deployment/konfigändringar som auditerbara händelser, håll miljöer åtskilda och underhåll runbooks (t.ex. /docs/incident-response, /docs/audit-readiness) som visar hur du bevarar integritet vid incidenter.