24 aug. 2025·8 min
Hur du bygger en webbapp för flerstegs-onboarding av användare
Lär dig designa och bygga en webbapp som skapar, spårar och förbättrar flerstegs-onboarding med tydliga steg, datamodeller och testning.
Lär dig designa och bygga en webbapp som skapar, spårar och förbättrar flerstegs-onboarding med tydliga steg, datamodeller och testning.
Ett flerstegs-onboarding-flöde är en guidad sekvens av skärmar som hjälper en ny användare att gå från “registrerad” till “redo att använda produkten”. Istället för att be om allt på en gång delar du upp uppsättningen i mindre steg som kan göras i ett svep eller över tid.
Du behöver flerstegs-onboarding när uppsättningen är mer än ett enda formulär—särskilt när den inkluderar val, förutsättningar eller kontrollkrav. Om din produkt kräver kontext (bransch, roll, preferenser), verifiering (e-post/telefon/identitet) eller initial konfiguration (workspaces, fakturering, integrationer) håller ett steg-baserat flöde saker begripliga och minskar fel.
Flerstegs-onboarding är överallt eftersom det stödjer uppgifter som naturligt sker i etapper, till exempel:
Ett bra onboardingflöde handlar inte om att “färdiga skärmar”, utan om att användare når värde snabbt. Definiera framgång i termer som passar din produkt:
Flödet bör också stödja återupptagning och kontinuitet: användare kan lämna och återvända utan att förlora progress, och de bör landa på nästa logiska steg.
Flerstegs-onboarding misslyckas på förutsägbara sätt:
Ditt mål är att få onboarding att kännas som en guidad väg, inte ett prov: tydligt syfte per steg, tillförlitlig progress-uppföljning och ett enkelt sätt att plocka upp där användaren slutade.
Innan du skissar skärmar eller skriver kod, bestäm vad din onboarding försöker uppnå—och för vem. Ett flerstegsflöde är bara “bra” om det konsekvent får rätt personer till rätt slutstatus med minimal förvirring.
Olika användare kommer med olika kontext, rättigheter och brådska. Börja med att namnge dina primära inträdespersonas och vad som redan är känt om dem:
För varje typ, lista begränsningar (t.ex. “kan inte redigera företagsnamn”), obligatoriska data (t.ex. “måste välja workspace”) och potentiella genvägar (t.ex. “redan verifierad via SSO”).
Din onboarding-slutstatus bör vara explicit och mätbar. “Färdig” är inte “klarade alla skärmar”; det är en affärsredo status, såsom:
Skriv uppfyllelkriterierna som en checklista backend kan utvärdera, inte ett vagt mål.
Kartlägg vilka steg som är obligatoriska för slutstatusen och vilka som är valfria förbättringar. Dokumentera sedan beroenden (“kan inte bjuda in kollegor innan workspace finns”).
Slutligen, definiera skip-regler med precision: vilka steg kan hoppas över, av vilken användartyp, under vilka villkor (t.ex. “hoppa över e-postverifiering om autentiserad via SSO”), och om hoppade steg kan återbesökas senare i inställningar.
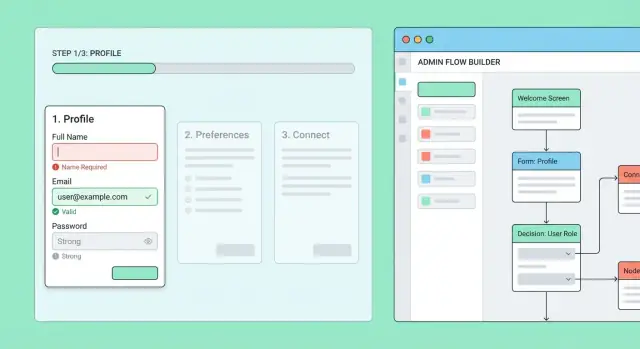
Innan du bygger skärmar eller API:er, rita onboarding som en flödeskarta: en liten diagram som visar varje steg, vart en användare kan gå härnäst och hur de kan återvända senare.
Skriv stegen som korta, handlingsfokuserade namn (verb hjälper): “Skapa lösenord”, “Bekräfta e-post”, “Lägg till företagsuppgifter”, “Bjud in kollegor”, “Koppla fakturering”, “Avsluta.” Håll första versionen enkel, och lägg sedan till detaljer som obligatoriska fält och beroenden (t.ex. fakturering kan inte ske före planval).
En hjälpsam kontroll: varje steg bör svara på en fråga—antingen “Vem är du?” “Vad behöver du?” eller “Hur ska produkten konfigureras?” Om ett steg försöker göra alla tre, dela upp det.
De flesta produkter tjänar på en i huvudsak linjär ryggrad med villkorliga grenar endast när upplevelsen verkligen skiljer sig. Typiska grenregler:
Dokumentera dessa som “om/då”-anteckningar på kartan (t.ex. “If region = EU → show VAT step”). Detta håller flödet begripligt och undviker att bygga en labyrint.
Lista varje plats en användare kan komma in i flödet:
/settings/onboarding)Varje inträde bör landa användaren på rätt nästa steg, inte alltid på steg ett.
Anta att användare lämnar mitt i ett steg. Bestäm vad som händer när de återvänder:
Din karta bör visa en tydlig “återuppta”-väg så upplevelsen känns tillförlitlig, inte skör.
Bra onboarding känns som en guidad väg, inte ett prov. Målet är att minska beslutströtthet, göra förväntningarna uppenbara och hjälpa användare återhämta sig snabbt när något går fel.
En wizard fungerar bäst när steg måste slutföras i ordning (t.ex. identitet → fakturering → behörigheter). En checklista passar onboarding som kan göras i valfri ordning (t.ex. “Lägg till logotyp”, “Bjud in kollegor”, “Koppla kalender”). Guidad uppgift (inbäddade tips och callouts i produkten) är bra när lärande sker genom att göra, inte genom att fylla i formulär.
Om du är osäker, börja med en checklista + deep links till varje uppgift, och gatewaya endast de verkligen obligatoriska stegen.
Progress-feedback bör svara på: “Hur mycket återstår?” Använd en av:
Lägg också till en “Spara och slutför senare”-signal, särskilt för längre flöden.
Använd enkla etiketter (“Företagsnamn”, inte “Entity identifier”). Lägg till microcopy som förklarar varför du frågar (“Vi använder detta för att anpassa fakturor”). Där det är möjligt, förifyll från befintliga data och välj säkra standardvärden.
Designa fel som en väg framåt: markera fältet, förklara vad man ska göra, behåll användarens inmatning och fokusera första ogiltiga fältet. Vid serverfel, visa ett retry-alternativ och bevara progress så användaren inte behöver upprepa redan slutförda steg.
Gör tryckytor stora, undvik multikolumnformulär och håll primära åtgärder synliga. Säkerställ full tangentbordsnavigering, synliga fokusindikatorer, etiketterade inputfält och skärmläsarvänlig progress-text (inte bara en visuell stapel).
Ett smidigt flerstegs-onboardingflöde beror på en datamodell som kan svara på tre frågor pålitligt: vad användaren ska se härnäst, vad de redan lämnat, och vilken definition av flödet de följer.
Börja med en liten uppsättning tabeller/kollektioner och väx bara vid behov:
Denna separation håller “konfiguration” (Flow/Step) åtskild från “användardata” (StepResponse/Progress).
Bestäm tidigt om flöden ska vara versionerade. I de flesta produkter är svaret ja.
När du redigerar steg (byter namn, omordnar, lägger till obligatoriska fält) vill du inte att användare mitt i onboarding plötsligt ska misslyckas med validering eller förlora sin plats. Ett enkelt tillvägagångssätt:
id och version (eller ett immutabelt flow_version_id).flow_version_id för alltid.För att spara progress, välj mellan autosave (spara medan användaren skriver) och explicit “Nästa”-spara. Många team kombinerar båda: autosave utkast, och markera steg “complete” först vid Nästa.
Spåra tidsstämplar för rapportering och felsökning: started_at, completed_at och last_seen_at (plus per-steg saved_at). Dessa fält driver onboarding-analytics och hjälper support att förstå var någon fastnade.
Ett flerstegs-onboardingflöde blir enklare att resonera kring när du behandlar det som en tillståndsmaskin: användarens onboarding-session är alltid i ett ”tillstånd” (aktuellt steg + status), och du tillåter bara specifika övergångar mellan tillstånd.
Istället för att frontend hoppar till vilken URL som helst, definiera en liten uppsättning statusar per steg (till exempel: not_started → in_progress → completed) och en tydlig mängd övergångar (till exempel: start_step, save_draft, submit_step, go_back, reset_step).
Detta ger förutsägbart beteende:
Ett steg är bara “completed” när båda villkoren är uppfyllda:
Spara serverns beslut tillsammans med steget, inklusive eventuella felkoder. Detta undviker fall där UI tror att ett steg är klart men backend håller inte med.
Ett lätt att missa kantfall: en användare redigerar ett tidigare steg och gör senare steg ogiltiga. Exempel: ändra “Land” kan ogiltigförklara “Skattedetaljer” eller “Tillgängliga planer.”
Hantera detta genom att spåra beroenden och utvärdera downstream-steg efter varje submit. Vanliga utfall:
needs_review (eller återställ till in_progress).“Back” bör stödjas, men det måste vara säkert:
Detta håller upplevelsen flexibel samtidigt som sessionens state förblir konsekvent och genomdrivbar.
Din backend-API är sanningskällan för var en användare befinner sig i onboarding, vad de lämnat hittills och vad de får göra härnäst. Ett bra API håller frontenden enkel: den kan rendera aktuellt steg, skicka data säkert och återhämta sig efter refresh eller nätverkshaverier.
Minst, designa för dessa handlingar:
GET /api/onboarding → returnerar aktuell steg-nyckel, completion %, och eventuella sparade utkastvärden som behövs för att rendera steget.PUT /api/onboarding/steps/{stepKey} med { "data": {…}, "mode": "draft" | "submit" }POST /api/onboarding/steps/{stepKey}/nextPOST /api/onboarding/steps/{stepKey}/previousPOST /api/onboarding/complete (server verifierar att alla obligatoriska steg är uppfyllda)Håll svar konsekventa. Till exempel, efter sparning, returnera uppdaterad progress plus serverbestämt nästa steg:
{ "currentStep": "profile", "nextStep": "team", "progress": 0.4 }
Användare dubbelklickar, retryar vid dålig uppkoppling eller frontend kan återskicka requests efter timeout. Gör “spara” säkert genom att:
Idempotency-Key-header för PUT/POST-requests och deduplicera genom (userId, endpoint, key).PUT /steps/{stepKey} som en fullständig overwrite av det stegets lagrade payload (eller dokumentera tydligt partial merge-regler).version (eller etag) för att förhindra att nyare data skrivs över av gamla retries.Returnera åtgärdsbara meddelanden som UI kan visa intill fälten:
{
"error": "VALIDATION_ERROR",
"message": "Please fix the highlighted fields.",
"fields": {
"companyName": "Company name is required",
"teamSize": "Must be a number"
}
}
Särskilj också 403 (not allowed) från 409 (conflict / wrong step) och 422 (validation) så frontend kan reagera korrekt.
Separera användar- och adminkapabiliteter:
GET /api/admin/onboarding/users/{userId} eller overrides) måste roll-gränssnittas och auditeras.Denna gräns förhindrar oavsiktliga privilege-leaks samtidigt som support och ops kan hjälpa användare som fastnar.
Frontendens jobb är att få onboarding att kännas smidig även när nätverket svajar. Det betyder förutsägbar routing, pålitligt återupptagningsbeteende och tydlig feedback när data sparas.
En URL per steg (t.ex. /onboarding/profile, /onboarding/billing) är oftast enklast att resonera kring. Det stödjer browserns back/forward, deep linking från e-post och gör det lätt att refresha utan att tappa kontext.
En singelsida med intern state kan fungera för mycket korta flöden, men det ökar riskerna vid refresh, krascher och “kopiera länk för att fortsätta”-scenarion. Om du använder detta tillvägagångssätt behöver du stark persistens (se nedan) och noggrann history-hantering.
Spara stegs-slutförande och senaste sparade data på serversidan, inte bara i local storage. Vid sidladdning, hämta aktuell onboarding-state (aktuellt steg, slutförda steg och eventuella utkastvärden) och rendera utifrån det.
Det möjliggör:
Optimistisk UI kan minska friktionen, men behöver skydd:
När en användare återvänder, dumpa dem inte till steg ett. Visa ett förslag som: “Du är 60 % klar—fortsätt där du slutade?” med två åtgärder:
/onboarding)Denna lilla touch minskar avhopp samtidigt som den respekterar användare som inte är redo att avsluta allt direkt.
Validering är där onboarding antingen känns smidig eller frustrerande. Målet är att fånga misstag tidigt, hålla användare rörliga och ändå skydda systemet när data är ofullständig eller misstänkt.
Använd klientvalidering för att förhindra uppenbara fel innan nätverksanrop. Det minskar churn och gör varje steg responsivt.
Typiska kontroller inkluderar obligatoriska fält, maxlängder, grundläggande format (e-post/telefon) och enkla tvärfältregler (lösenordsbekräftelse). Håll meddelanden specifika (“Ange en giltig arbets-e-post”) och placera dem intill fältet.
Behandla server-side validering som sanningskällan. Även om UI validerar perfekt kan användare kringgå den.
Servervalidering bör upprätthålla:
Returnera strukturerade fel per fält så frontend kan markera exakt vad som behöver fixas.
Vissa valideringar beror på externa eller fördröjda signaler: e-post-unikhet, inbjudningskoder, bedrägerisignaler eller dokumentverifiering.
Hantera dessa med explicita statusar (t.ex. pending, verified, rejected) och en tydlig UI-state. Om en kontroll är pending, låt användaren fortsätta där det är möjligt och visa när du kommer meddela dem eller vilket steg som kommer låsas upp senare.
Flerstegs-onboarding betyder ofta att partiell data är normalt. Bestäm per steg om du ska:
Ett praktiskt tillvägagångssätt är “spara utkast alltid, blockera endast vid stegslutförande.” Detta stödjer återupptagning utan att sänka datakvalitetskraven.
Analytics för flerstegs-onboarding bör svara på två frågor: “Var fastnar folk?” och “Vilken ändring förbättrar slutförandet?” Nyckeln är att spåra en liten uppsättning konsekventa event över varje steg och göra dem jämförbara även när flödet ändras över tid.
Spåra samma kärnevent för varje steg:
step_viewed (användaren såg steget)step_completed (användaren skickade in och klarade validering)step_failed (användaren försökte skicka men misslyckades med validering eller serverkontroller)flow_completed (användaren nådde slutlig success-status)Inkludera en minimal, stabil kontextpayload med varje event: user_id, flow_id, flow_version, step_id, step_index och en session_id (så du kan separera “en sittning” från “flera dagar”). Om du stödjer återupptagning, inkludera också resume=true/false på step_viewed.
För att mäta avhopp per steg, jämför antalet step_viewed vs. step_completed för samma flow_version. För att mäta tid, fånga tidsstämplar och beräkna:
step_viewed → step_completedstep_viewed → nästa step_viewed (användbart när användare hoppar över)Håll tidsmått grupperade per version; annars kan förbättringar döljas av att blanda gamla och nya flöden.
Om du A/B-testar copy eller omordnar steg, behandla det som en del av analytics-identity:
experiment_id och variant_id på varje eventstep_id stabilt även om visningstext ändrasstep_id och använd step_index för positionBygg en enkel dashboard som visar completion rate, avhopp per steg, median-tid per steg och “top felande fält” (från step_failed metadata). Lägg till CSV-exporter så team kan granska progress i kalkylblad och dela uppdateringar utan direkt åtkomst till analytics-verktyget.
Ett flerstegs-onboardingsystem kommer så småningom behöva operativ kontroll: produktändringar, support-fallen och säker experimentering. Ett enkelt internt adminområde hindrar engineering från att bli flaskhalsen.
Börja med en enkel “flow builder” som låter auktoriserad personal skapa och redigera onboardingflöden och deras steg.
Varje steg bör vara redigerbart med:
Lägg till en preview-läge som renderar steget som en slutanvändare skulle se det. Detta fångar förvirrande copy, saknade fält och brutna grenar innan det når riktiga användare.
Undvik att redigera ett live-flöde på plats. Publicera versioner istället:
Rollouts bör kunna konfigureras per version:
Detta minskar risk och ger rena jämförelser när du mäter completion och avhopp.
Supportteam behöver verktyg för att lösa användarfall utan manuella databasändringar:
Varje adminåtgärd ska loggas: vem ändrade vad, när och before/after-värden. Begränsa åtkomst med roller (enbart vy, redigerare, publicerare, support-override) så känsliga åtgärder—som att återställa progress—kontrolleras och går att spåra.
Innan du släpper ett flerstegs-onboardingflöde, anta två saker: användare tar oväntade vägar, och något kommer att gå fel halvvägs (nätverk, validering, behörigheter). En bra launch-checklista bevisar att flödet är korrekt, skyddar användardata och ger tidiga varningssignaler när verkligheten avviker från din plan.
Börja med enhetstester för din workflow-logik (tillstånd och övergångar). Dessa tester bör verifiera att varje steg:
Lägg sedan till integrationstester som övar ditt API: spara steg-payloads, återuppta progress och avvisa ogiltiga övergångar. Integrationstester fångar “fungerar lokalt” problem som saknade index, serialiseringsbuggar eller versionsmismatch mellan frontend och backend.
E2E-tester bör åtminstone täcka:
Håll E2E-scenarion små men meningsfulla—fokusera på de få vägar som representerar flest användare och mest intäkt/aktiveringspåverkan.
Tillämpa minst privilegium: onboarding-admins ska inte automatiskt få full åtkomst till användarposter, och servicekonton ska bara nå tabeller och endpoints de behöver.
Kryptera där det behövs (t.ex. tokens, känsliga identifierare, reglerade fält) och behandla loggar som en potentiell dataläcka. Undvik att logga råa formulärpayloads; logga istället steg-ID, felkoder och timing. Om du måste logga utdrag för debugging, redacta fält konsekvent.
Instrumentera onboarding både som en produkttratt och som ett API.
Spåra fel per steg, spara latens (p95/p99) och återupptagningsfel. Sätt upp larm för plötsliga fall i completion rate, toppar i valideringsfel på ett enda steg eller förhöjda API-fel efter release. Detta låter dig åtgärda det brutna steget innan supportärenden hopar sig.
Om du implementerar ett steg-baserat onboardingssystem från grunden, går mesta tiden åt till samma byggstenar som beskrivs ovan: steg-routing, persistens, valideringar, progress-/state-logik och en admingränssnitt för versionering och rollouts. Koder.ai kan hjälpa dig att prototypa och leverera dessa delar snabbare genom att generera fullstack-webbappar från en chattdriven specifikation—vanligtvis med en React-front, en Go-backend och en PostgreSQL-datamodell som kartlägger flöden, steg och step-responses.
Eftersom Koder.ai stöder källa-export, hosting/distribution och snapshots med rollback är det också användbart när du vill iterera på onboarding-versioner säkert (och återhämta dig snabbt om en rollout skadar completion).
Använd ett flerstegsflöde när uppsättning kräver mer än ett enda formulär—särskilt om det finns förutsättningar (t.ex. skapande av workspace), verifiering (e-post/telefon/KYC), konfiguration (fakturering/integrationer) eller grenar beroende på roll/plan/region.
Om användare behöver kontext för att svara rätt minskar uppdelning i steg fel och avhopp.
Definiera framgång som att användare når värde, inte enbart att de klickar igenom skärmar. Vanliga mätvärden:
Spåra också återupptagning (att användare kan lämna och fortsätta utan att förlora progress).
Börja med att lista användartyper (t.ex. självbetjänande ny användare, inbjuden användare, admin-skapad konto) och definiera för varje:
Koda sedan skip-regler så varje persona hamnar på rätt nästa steg, inte alltid på steg ett.
Skriv “done” som backend-kontrollerbara kriterier, inte bara UI-komplettering. Exempel:
Det låter servern avgöra om onboarding är klar—även om UI ändras över tid.
Börja med en mestadels linjär ryggrad och lägg till villkorliga grenar bara när upplevelsen faktiskt skiljer sig (roll, plan, region, användningsfall).
Dokumentera grenar som tydliga om/då-regler (t.ex. “Om region = EU → visa VAT-steg”) och håll stegnamnen handlingsinriktade (“Bekräfta e-post”, “Bjud in kollegor”).
Föredra en URL per steg (t.ex. /onboarding/profile) när flödet är mer än ett par skärmar. Det stödjer refresh-säkerhet, deep links (från e-post) och back/forward i browsern.
Använd en singelsida med intern state bara för väldigt korta flöden—och endast om du har stark persistens för att klara refresh/rascher.
Behandla servern som sanningskällan:
Det ger refresh-säkerhet, fortsättning på flera enheter och stabilitet när flöden uppdateras.
Ett praktiskt minimalt datamodell är:
Versionera flödesdefinitionerna så pågående användare inte bryts när du lägger till/omordnar steg. Progress ska referera en specifik .
Behandla onboarding som en tillståndsmaskin med explicita övergångar (t.ex. start_step, save_draft, submit_step, go_back).
Ett steg är “completed” endast när:
En solid baseline-API innehåller:
GET /api/onboarding (aktuellt steg + progress + utkast)PUT /api/onboarding/steps/{stepKey} med mode: draft|submitPOST /api/onboarding/complete (server verifierar krav)Lägg till (t.ex. ) för att skydda mot retries/dubbelklick, och returnera strukturerade fältfel (använd 403/409/422 meningsfullt) så UI kan reagera korrekt.
flow_version_idNär tidigare svar ändras, re-evaluera beroenden och markera downstream-steg som needs_review eller återställ dem till in_progress.
Idempotency-Key